1.本发明属于人工智能领域,尤其涉及一种模型训练方法、系统、终端设备及存储介质。
背景技术:
2.声纹识别和语音识别是语音领域最为重要两个应用,但由于声纹识别偏重于说话人特性,轻说话内容,本质上是一种分类问题,而语音识别偏重于说话内容,轻说话人特性,而且语音识别需要考虑语音和文本前后之间的关系,因此,两种识别方式应用一直都是相互独立进行研究。
3.现有的语音识别和声纹识别过程中,均是分别进行模型的构建和训练,使得语音识别模型和声纹识别模型的训练,均需要大量的已标注数据进行模型训练,导致模型训练繁琐,降低了模型训练效率。
技术实现要素:
4.本发明实施例的目的在于提供一种模型训练方法、系统、终端设备及存储介质,旨在解决现有的语音识别模型和声纹识别模型的训练过程中,由于均需要大量的已标注数据进行模型训练,所导致的模型训练效率低下的问题。
5.本发明实施例是这样实现的,一种模型训练方法,所述方法包括:
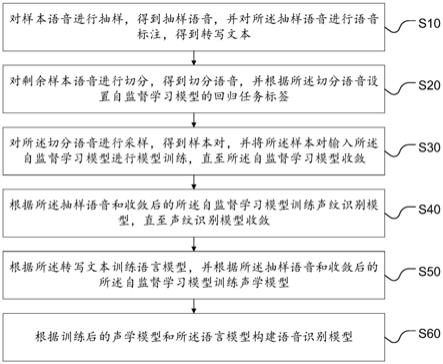
6.对样本语音进行抽样,得到抽样语音,并对所述抽样语音进行语音标注,得到转写文本;
7.对剩余样本语音进行切分,得到切分语音,并根据所述切分语音设置自监督学习模型的回归任务标签;
8.对所述切分语音进行采样,得到样本对,并将所述样本对输入所述自监督学习模型进行模型训练,直至所述自监督学习模型收敛;
9.根据所述抽样语音和收敛后的所述自监督学习模型训练声纹识别模型,直至声纹识别模型收敛;
10.根据所述转写文本训练语言模型,并根据所述抽样语音和收敛后的所述自监督学习模型训练声学模型;
11.根据训练后的声学模型和所述语言模型构建语音识别模型。
12.更进一步的,所述将所述样本对输入所述自监督学习模型进行模型训练,包括:
13.将所述样本对输入所述自监督学习模型中的编码器进行编码,得到编码数据,并将所述编码数据输入所述自监督学习模型中的鉴别器进行数据鉴别;
14.将所述鉴别器的鉴别结果输入所述自监督学习模型中的分类器进行损失计算,得到模型损失参数;
15.根据所述模型损失参数对所述编码器和所述鉴别器进行参数更新,直至所述编码器和所述鉴别器收敛,输出收敛后的所述自监督学习模型。
16.更进一步的,所述样本对包括正样本对和负样本对,所述对切分语音进行采样,得到样本对,包括:
17.对所述切分语音进行采样,得到采样语音,且当同一轮采样到的各采样语音来自同一条语音,则将采样到的各采样语音设置为所述正样本对;
18.当同一轮采样到的各采样语音来自不同语音,则将采样到的各采样语音设置为所述负样本对。
19.更进一步的,所述根据所述切分语音设置自监督学习模型的回归任务标签,包括:
20.分别提取所述切分语音的mfcc特征、mfcc一阶差分特征、mfcc二阶差分特征、fbank特征、lpc特征、韵律特征、时间弯折特征和频率掩码特征;
21.将所述切分语音、所述mfcc特征、所述mfcc一阶差分特征、所述mfcc二阶差分特征、所述fbank特征、所述lpc特征、所述韵律特征、所述时间弯折特征和所述频率掩码特征,分别设置为所述自监督学习模型的回归任务标签。
22.更进一步的,所述将所述鉴别器的鉴别结果输入所述自监督学习模型中的分类器进行损失计算所采用的损失函数为:
[0023][0024]
其中,θ是所述编码器的参数,φ是所述鉴别器的参数,下标p表示正样本,n表示负样本,(x1,x2)表示所述正样本对,(x1,x
rnd
)表示所述负样本对,g函数表示所述鉴别器的输出,l(θ,φ)是所述模型损失参数。
[0025]
更进一步的,所述根据所述模型损失参数对所述编码器和所述鉴别器进行参数更新,包括:
[0026]
根据后向传播算法,计算所述编码器和所述鉴别器的偏微分;
[0027]
根据所述偏微分和最大所述模型损失参数,采用梯度下降算法更新所述编码器和所述鉴别器的参数。
[0028]
更进一步的,所述对剩余样本语音进行切分,得到切分语音,包括:
[0029]
若任一剩余所述样本语音的语音时长小于预设时长,则删除所述样本语音;
[0030]
根据预设时间间隔对剩余所述样本语音进行切分,得到所述切分语音。
[0031]
本发明实施例的另一目的在于提供一种模型训练系统,所述系统包括:
[0032]
回归任务标签设置模块,用于对样本语音进行抽样,得到抽样语音,并对所述抽样语音进行语音标注,得到转写文本;对剩余所述样本语音进行切分,得到切分语音,并根据所述切分语音设置自监督学习模型的回归任务标签;
[0033]
语音采样模块,用于对所述切分语音进行采样,得到样本对,并将所述样本对输入所述自监督学习模型进行模型训练,直至所述自监督学习模型收敛;
[0034]
声纹模型训练模块,用于根据所述抽样语音和收敛后的所述自监督学习模型训练声纹识别模型,直至声纹识别模型收敛;
[0035]
声学模型训练模块,用于根据所述转写文本训练语言模型,并根据所述抽样语音和收敛后的所述自监督学习模型训练声学模型;
[0036]
语音模型训练模块,用于根据训练后的声学模型和所述语言模型构建语音识别模型,并将待识别语音输入所述语音识别模型进行语音识别,得到语音识别结果。
[0037]
本发明实施例的另一目的在于提供一种终端设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述方法的步骤。
[0038]
本发明实施例的另一目的在于提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述方法的步骤。
[0039]
本发明实施例,通过切分语音设置自监督学习模型的回归任务标签,提高了收敛后自监督学习模型的抗噪、抗混响和抗变形失真能力,本发明实施例采用自监督学习的方式进行语音识别模型的构建和声纹识别模型的训练,基于同一个收敛后的自监督学习模型,可以分别训练或构建声纹识别模型和语音识别模型,提高了模型训练效率,无需大量的已标注数据,降低了数据标注的工作量,进一步提高了模型训练效率。
附图说明
[0040]
图1是本发明第一实施例提供的模型训练方法的流程图;
[0041]
图2是本发明第二实施例提供的模型训练方法的流程图;
[0042]
图3是本发明第三实施例提供的模型训练系统的结构示意图;
[0043]
图4是本发明第四实施例提供的终端设备的结构示意图。
具体实施方式
[0044]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0045]
为了说明本发明所述的技术方案,下面通过具体实施例来进行说明。
[0046]
实施例一
[0047]
请参阅图1,是本发明第一实施例提供的模型训练方法的流程图,该模型训练方法可以应用与任一终端设备,该终端设备包括服务器、手机、平板或可穿戴智能设备等,该模型训练方法包括步骤:
[0048]
步骤s10,对样本语音进行抽样,得到抽样语音,并对所述抽样语音进行语音标注,得到转写文本;
[0049]
其中,采用多个不同说话人的语音,以得到该样本语音,该样本语音包括目标语种和至少一个待识别语种,该目标语音和待识别语种均可以根据需求进行设置,本实施例中,该目标语种为普通话,该待识别语种为闽南,可选的,该步骤中,该样本语音还包括编码转换语音,该编码转换语音为待识别语种穿插有目标语种的语音;
[0050]
该步骤中,对样本语音进行抽样的抽样数量可以根据需求进行设置,该步骤中,通过构建语音识别发音词典,基于构建后的语音识别发音词典,对抽样语音进行语音标注,得到各抽样语音对应的转写文本;
[0051]
步骤s20,对剩余样本语音进行切分,得到切分语音,并根据所述切分语音设置自监督学习模型的回归任务标签;
[0052]
其中,通过对剩余样本语音进行切分,提高了后续各个模型训练数据的数据量。
[0053]
该步骤中,所述对剩余样本语音进行切分之前还包括:分别确定各剩余样本语音
的语音时长;若任一剩余样本语音的语音时长小于预设时长时,则删除该样本语音;
[0054]
其中,该预设时长可以根据需求进行设置,例如,该预设时长可以设置为1秒、2秒或3秒等,该步骤中,通过删除语音时长小于预设时长的样本语音,确保了每条样本语音中均可以携带有较多的语音信息。
[0055]
进一步地,该步骤中,根据预设时间间隔对分别对各样本语音进行切分,得到该切分语音,该预设时间间隔可以根据需求进行设置,例如,该预设时间间隔可以设置为1秒、2秒或3秒等。
[0056]
可选的,该步骤中,所述根据所述切分语音设置自监督学习模型的回归任务标签,包括:
[0057]
分别提取所述切分语音的梅尔倒谱系数(mel
‑
scale frequency cepstral coefficients,mfcc)特征、mfcc一阶差分特征、mfcc二阶差分特征、fbank特征、语音信号线性预测特征(lpc)、韵律特征、时间弯折特征和频率掩码特征;
[0058]
将所述切分语音、所述mfcc特征、所述mfcc一阶差分特征、所述mfcc二阶差分特征、所述fbank特征、所述lpc特征、所述韵律特征、所述时间弯折特征和所述频率掩码特征,分别设置为所述自监督学习模型的回归任务标签;
[0059]
其中,通过将mfcc特征、mfcc一阶差分特征、mfcc二阶差分特征、fbank特征、lpc特征、韵律特征、时间弯折特征和频率掩码特征,分别设置为自监督学习模型的回归任务标签,提高了自监督学习模型训练的准确性,是为了让自监督学习模型学习到提取这些特征的参数,且该步骤中,通过将切分语音设置为自监督学习模型的回归任务标签,提高了收敛后自监督学习模型的抗噪、抗混响和抗变形失真能力。
[0060]
步骤s30,对所述切分语音进行采样,得到样本对,并将所述样本对输入所述自监督学习模型进行模型训练,直至所述自监督学习模型收敛;
[0061]
其中,该自监督学习模型中包括编码器、鉴别器和分类器,该编码器用于对输入自监督学习模型的样本对进行特征编码,该鉴别器用于鉴别经编码器编码后的特征是否来自同一个说话人,该分类器对该鉴别器的鉴别结果进行损失计算,以得到表征该编码器和鉴别器参数误差的模型损失参数。
[0062]
可选的,该步骤中,所述样本对包括正样本对和负样本对,所述对切分语音进行采样,得到样本对,包括:
[0063]
对所述切分语音进行采样,得到采样语音,且当同一轮采样到的各采样语音来自同一条语音,则将采样到的各采样语音设置为所述正样本对;
[0064]
其中,每轮采样的数量均可以根据需求进行设置,该步骤中,每轮采样的数量为两个,即,在不同的切分语音中随机采样两个语音,得到两个采样语音,并当同一轮采样中的两个采样语音来自同一条语音时,将采样到的两个采样语音设置为正样本对;
[0065]
当同一轮采样到的各采样语音来自不同语音,则将采样到的各采样语音设置为所述负样本对;
[0066]
其中,当同一轮采样到的两个采样语音来自不同语音,则将采样到的两个采样语音设置为负样本对,该步骤中,基于同一轮采样过程中,各采样语音是否来自同一条语音的判断,以提高对样本对的样本设置,基于设置后的正样本对和负样本对,提高了后续自监督学习模型训练的准确性。
[0067]
进一步地,该步骤中,所述将所述样本对输入所述自监督学习模型进行模型训练,包括:
[0068]
将所述样本对输入所述自监督学习模型中的编码器进行编码,得到编码数据,并将所述编码输入输入所述自监督学习模型中的鉴别器进行数据鉴别;
[0069]
将所述鉴别器的鉴别结果输入所述自监督学习模型中的分类器进行损失计算,得到模型损失参数;
[0070]
根据所述模型损失参数对所述编码器和所述鉴别器进行参数更新,直至所述编码器和所述鉴别器收敛,输出收敛后的所述自监督学习模型。
[0071]
其中,所述将所述鉴别器的鉴别结果输入所述自监督学习模型中的分类器进行损失计算所采用的损失函数为:
[0072][0073]
其中,θ是所述编码器的参数,φ是所述鉴别器的参数,下标p表示正样本,n表示负样本,(x1,x2)表示所述正样本对,(x1,xrnd)表示所述负样本对,g函数表示所述鉴别器的输出,l(θ,φ)是所述模型损失参数。
[0074]
更进一步地,该步骤中,所述将所述样本对输入所述自监督学习模型进行模型训练包括:
[0075]
将样本对输入自监督学习模型中的cnn网络,其中,cnn网络中的激活函数采用sinc函数,通过采用sinc函数,使得cnn网络中的参数数量不会随着卷积核的变化而变化,因此,cnn网络中的卷积核可以设为更大的尺寸,捕获更大区间的上下文信息,另一方面sinc函数可以更好地捕获说话人特性,有利于提升声纹识别效果;
[0076]
将cnn网络的输出输入至自监督学习模型中的34层残差神经网络(resnet网络),并将resnet网络的输出输入至自监督学习模型中的三层全连接层;
[0077]
将全连接层的输出作为声学嵌入特征,将声学嵌入特征分别用于训练自监督学习任务后,通过后向传播算法和梯度下降法迭代更新所有神经网络参数,直至该自监督学习模型收敛。
[0078]
步骤s40,根据所述抽样语音和收敛后的所述自监督学习模型训练声纹识别模型,直至声纹识别模型收敛;
[0079]
其中,基于收敛后的声纹识别模型,能有效地对输入的待识别声纹数据进行声纹识别。
[0080]
步骤s50,根据所述转写文本训练语言模型,并根据所述抽样语音和收敛后的所述自监督学习模型训练声学模型;
[0081]
其中,通过根据转写文本训练语言模型,使得训练后的语言模型能有效地将输入的句子的概率拆解成其中每个词的概率之积,通过根据抽样语音和收敛后的自监督学习模型训练声学模型,使得训练后的声学模型能有效地计算出输入的文字对应的发声概率。
[0082]
步骤s60,根据训练后的声学模型和所述语言模型构建语音识别模型;
[0083]
其中,将待识别语音输入所述语音识别模型进行语音识别,得到语音识别结果,通过根据训练后的声学模型和语言模型构建语音识别模型,使得构建后的语音识别模型,能有效地对输入的待识别语音进行语音识别,得到对应的语音识别结果。
[0084]
本实施例,通过切分语音设置自监督学习模型的回归任务标签,提高了收敛后自监督学习模型的抗噪、抗混响和抗变形失真能力,本发明实施例采用自监督学习的方式进行语音识别模型的构建和声纹识别模型的训练,基于同一个收敛后的自监督学习模型,可以分别训练或构建声纹识别模型和语音识别模型,提高了模型训练效率,无需大量的已标注数据,降低了数据标注的工作量,进一步提高了模型训练效率。
[0085]
实施例二
[0086]
请参阅图2,是本发明第二实施例提供的模型训练方法的流程图,该实施例用于对步骤s30作进一步细化,包括步骤:
[0087]
步骤s31,根据后向传播算法,计算所述编码器和所述鉴别器的偏微分;
[0088]
其中,通过采用后向传播算法,迭代地处理样本对,将每个样本对的网络预测与真实结果相比较进行学习,对于每个样本对,修改编码器和鉴别器的权重,使得自监督学习模型的预测和结果之间的误差最小。
[0089]
步骤s32,根据所述偏微分和最大所述模型损失参数,采用梯度下降算法更新所述编码器和所述鉴别器的参数;
[0090]
其中,可以采用全梯度下降算法(full gradient descent),随机梯度下降算法(stochastic gradient descent),随机平均梯度下降算法(stochastic average gradient descent)或小批量梯度下降算法(mini
‑
batch gradient descent)的方式,更新编码器和鉴别器的参数,梯度下降算法用于正确地调节编码器和鉴别器中的权重向量,通过为每个权重计算一个梯度,从而更新权值,使目标函数尽可能最小化。
[0091]
本实施例中,通过计算编码器和鉴别器的偏微分,基于偏微分和最大模型损失参数,能有效地对编码器和鉴别器中的参数进行更新,以达到更新自监督学习模型的效果,直至自监督学习模型收敛,提高了自监督学习模型的准确性。
[0092]
实施例三
[0093]
请参阅图3,是本发明第三实施例提供的模型训练系统100的结构示意图,包括:回归任务标签设置模块10、语音采样模块11、声纹模型训练模块12、声学模型训练模块13和语音模型训练模块14,其中:
[0094]
回归任务标签设置模块10,用于对样本语音进行抽样,得到抽样语音,并对所述抽样语音进行语音标注,得到转写文本;对剩余所述样本语音进行切分,得到切分语音,并根据所述切分语音设置自监督学习模型的回归任务标签。
[0095]
其中,该回归任务标签设置模块10还用于:分别提取所述切分语音的mfcc特征、mfcc一阶差分特征、mfcc二阶差分特征、fbank特征、lpc特征、韵律特征、时间弯折特征和频率掩码特征;
[0096]
将所述切分语音、所述mfcc特征、所述mfcc一阶差分特征、所述mfcc二阶差分特征、所述fbank特征、所述lpc特征、所述韵律特征、所述时间弯折特征和所述频率掩码特征,分别设置为所述自监督学习模型的回归任务标签。
[0097]
进一步的,该回归任务标签设置模块10还用于:若任一剩余所述样本语音的语音时长小于预设时长,则删除所述样本语音;
[0098]
根据预设时间间隔对剩余所述样本语音进行切分,得到所述切分语音。
[0099]
语音采样模块11,用于对所述切分语音进行采样,得到样本对,并将所述样本对输
入所述自监督学习模型进行模型训练,直至所述自监督学习模型收敛。
[0100]
其中,该语音采集模块11还用于:将所述样本对输入所述自监督学习模型中的编码器进行编码,得到编码数据,并将所述编码输入输入所述自监督学习模型中的鉴别器进行数据鉴别;
[0101]
将所述鉴别器的鉴别结果输入所述自监督学习模型中的分类器进行损失计算,得到模型损失参数;
[0102]
根据所述模型损失参数对所述编码器和所述鉴别器进行参数更新,直至所述编码器和所述鉴别器收敛,输出收敛后的所述自监督学习模型。
[0103]
优选的,该语音采集模块11还用于:根据后向传播算法,计算所述编码器和所述鉴别器的偏微分;
[0104]
根据所述偏微分和最大所述模型损失参数,采用梯度下降算法更新所述编码器和所述鉴别器的参数。
[0105]
进一步地,所述将所述鉴别器的鉴别结果输入所述自监督学习模型中的分类器进行损失计算所采用的损失函数为:
[0106][0107]
其中,θ是所述编码器的参数,φ是所述鉴别器的参数,下标p表示正样本,n表示负样本,(x1,x2)表示所述正样本对,(x1,xrnd)表示所述负样本对,g函数表示所述鉴别器的输出,l(θ,φ)是所述模型损失参数。
[0108]
可选的,该语音采集模块11还用于:对所述切分语音进行采样,得到采样语音,且当同一轮采样到的各采样语音来自同一条语音,则将采样到的各采样语音设置为所述正样本对;
[0109]
当同一轮采样到的各采样语音来自不同语音,则将采样到的各采样语音设置为所述负样本对。
[0110]
声纹模型训练模块12,用于根据所述抽样语音和收敛后的所述自监督学习模型训练声纹识别模型,直至声纹识别模型收敛。
[0111]
声学模型训练模块13,用于根据所述转写文本训练语言模型,并根据所述抽样语音和收敛后的所述自监督学习模型训练声学模型。
[0112]
语音模型训练模块14,用于根据训练后的声学模型和所述语言模型构建语音识别模型,并将待识别语音输入所述语音识别模型进行语音识别,得到语音识别结果。
[0113]
其中,该语音模型训练模块14还用于:根据训练后的声学模型和所述第三语言模型构建语音识别模型。
[0114]
本实施例,通过切分语音设置自监督学习模型的回归任务标签,提高了收敛后自监督学习模型的抗噪、抗混响和抗变形失真能力,本发明实施例采用自监督学习的方式进行语音识别模型的构建和声纹识别模型的训练,基于同一个收敛后的自监督学习模型,可以分别训练或构建声纹识别模型和语音识别模型,提高了模型训练效率,无需大量的已标注数据,降低了数据标注的工作量,进一步提高了模型训练效率。
[0115]
实施例四
[0116]
图4是本技术第四实施例提供的一种终端设备2的结构框图。如图4所示,该实施例
memory)、随机存取存储器(ram,random access memory)、电载波信号、电信信号以及软件分发介质等。需要说明的是,计算机可读存储介质包含的内容可以根据司法管辖区内立法和专利实践的要求进行适当的增减,例如在某些司法管辖区,根据立法和专利实践,计算机可读存储介质不包括电载波信号和电信信号。
[0123]
以上所述实施例仅用以说明本技术的技术方案,而非对其限制;尽管参照前述实施例对本技术进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本技术各实施例技术方案的精神和范围,均应包含在本技术的保护范围之内。