1.本发明属于音频数字水印的领域,具体涉及一种基于音频变频域的嵌入和定位水印的方法。
背景技术:
2.数字水印技术是一种信息隐藏技术,所谓音频数字水印算法,就是将数字水印通过水印嵌入算法,嵌入到音频文件中(如wav,mp3,avi等等),但是又对音频文件原有音质无太大影响,或者人耳感觉不到它的影响。相反的又通过水印提取算法,将音频数字水印从音频宿主文件中完整的提取出来,而这嵌入的水印,和提取出来的水印,就叫音频数字水印。
3.与图像水印技术相比,在数字音频信号中嵌入水印的技术难度较大,主要是因为人类的听觉系统与视觉系统相比,具有更高的灵敏度。人类的听觉系统对加性噪声特别敏感,如果采用加性法则在时域嵌入水印,很难在水印的鲁棒性和不可感知性之间达到合理的折中。虽然听觉系统的动态范围很大,但是理由其它特性,仍有可能在音频信号中嵌入水印。例如,可利用听觉系统的掩蔽效应、听觉系统对绝对相位不敏感等特性来嵌入水印。听觉系统的掩蔽特性表明了在音频信号中添加水印的可行性。
4.音频水印基本上可以分为时域和变换域两大类。时域的思想是在时域新号上直接叠加上水印,比如:lsb方法、echo方法,拼接法,pitch提取方法等。变环域的思想是在计算处理上更加快速和方便,实际上是将一个时域信号变换到其他域上的信号,然后进行加水印,再逆变换到原来域中的信号。如fft、dct、dwt、svd等,而原始的dct水印算法中会增加过多的伪随机噪声,在人耳听感上很明显,并且水印很容易被攻击。
5.有鉴于此,特提出本发明。
技术实现要素:
6.本发明的目的是提供一种基于音频变频域的嵌入和定位水印的方法,其添加的水印具有极好的透明性,没有明显的感知失真。
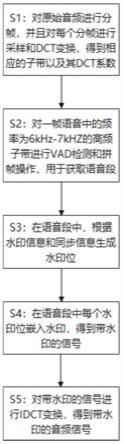
7.为了实现上述目的,本发明提供的一种基于音频变频域的嵌入水印的方法,包括以下步骤:
8.s1:对原始音频进行分帧,并且对每个分帧进行采样和dct变换,得到相应的子带以及其dct系数;
9.s2:对一帧语音中的频率为6khz
‑
7khz的高频子带进行vad检测和拼帧操作,用于获取语音段;其中,vad检测和拼帧操作包括:获取子带的语音能量谱,生成语音信号的fbank特征,以及拼帧形成语音数据;
10.s3:在语音段中,根据水印信息和同步信息生成水印位;
11.s4:在语音段中每个水印位嵌入水印,得到带水印的信号;
12.s5:对带水印的信号进行idct变换,得到带水印的音频信号。
13.进一步地,所述步骤s2还包括以下步骤:判断该语音数据是否为语音段,如果是则
进行步骤s3,如果不是则重新选取下一帧进行vad检测。
14.进一步地,所述步骤s2具体包括以下步骤:
15.s201:对高频子带进行加汉宁窗操作,之后进行fft变换,得到语音能量谱;
16.s202:将语音能量谱通过一组mel尺度的三角形滤波器组之后取对数,生成语音信号的fbank特征,并且根据fbank特征选择语音能量谱的第2到6频带;
17.s203:选取2到6频带对应帧作为当前帧,将其前5帧和后5帧进行拼帧,形成11帧的语音数据;
18.s204:拼帧后的语音数据输入到全连接层,获取语音段。
19.进一步地,所述步骤s3具体包括:在语音段中,根据水印的二进制数进行扩频,使用噪声发生器根据水印信息和同步信息产生m个线性不相关的awgn序列作为水印位,相邻序列向量之间的间距等于高频子带的采样点个数的大小。
20.进一步地,所述步骤s4中,在每个语音段的开始的4帧中依次嵌入同步码、水印、同步码、水印。
21.进一步地,所述步骤s4包括:
22.在频率为6khz
‑
7khz的高频子带中对应的采样点中嵌入水印;嵌入的水印需满足以下条件:当前水印大于0时,如果当前水印的平均值比之前一帧的水印值小,则framedct=dct/var_dct_value*pre_dct_value,否则,不做任何操作;当水印值小于等于0时,不做任何操作;
23.其中,framedct为当前子带范围内嵌入的水印值;dct为当前子带的采样点值;var_dct_value为当前子带对应的采样点的均值;pre_dct_value为前一个子带的采样点的均值。
24.更进一步地,所述步骤s5中的idct变换为步骤s1中dct变换的逆。
25.本发明还提供了一种基于音频变频域的定位水印的方法,包括以下步骤:
26.s11:对带水印的音频进行分帧,并且对每个分帧进行采样和dct变换,得到每个采样点对应的频域子带;
27.s12:对一帧语音中的所有频带进行vad检测和拼帧操作,得到语音段;其中,vad检测和拼帧操作包括:获取子带的语音能量谱,生成语音信号的fbank特征,以及拼帧形成语音数据;
28.s13:利用语音段中的同步码,检测与设置的同步码是否一致,以判断是否为同步帧,如果为同步帧,则进行步骤s14,如果不为同步帧,则返回步骤s12,选择下一帧语音进行判定;
29.s14:基于同步码识别水印段,进而通过计算dct系数获取当前水印的位置。
30.进一步地,所述步骤s12具体包括以下步骤:
31.s1201:对一帧语音中的所有频带进行加汉宁窗操作,之后进行fft变换,得到语音能量谱;
32.s1202:将语音能量谱通过一组mel尺度的三角形滤波器组之后取对数,生成语音信号的fbank特征,并且选根据fbank特征选择语音能量谱的第2到6频带;
33.s1203:取2到6频带对应帧作为当前帧,将其前5帧和后5帧进行拼帧,形成11帧的语音数据;
34.s1204:拼帧后的语音数据输入到全连接层,如果全连接层的输出结果是0,则判断拼帧后的语音为不是语音段;如果全连接层的输出结果是1,则判断拼帧后的语音为是语音段。
35.更进一步地,所述步骤s14中,所述dct系数与伪随机噪声块之间的相关性的计算方法如下所示:
36.r
sg
=s(w).g(w)
37.其中,s(w)表示带水印信号的dct的频域系数矩阵,g(w)代表伪随机噪声块的矩阵,两个矩阵相乘,得到互相关向量r
sg
。
38.本发明提供的一种基于音频变频域的嵌入和定位水印的方法,对比现有技术中的算法,提出的在全频带进行vad操作,使得解水印的时候更加准确;根据筛选出符合条件的子带,根据加水印系统步骤的算法进行添加更加少量的伪随机码噪声,可在水印的透明性更加好,人的不可感知性更强。
附图说明
39.图1为本具体实施方式中的基于音频变频域的嵌入水印的方法的流程图。
40.图2为本具体实施方式中的基于音频变频域的定位水印的方法的流程图。
41.图3为本具体实施方式中的使用的汉明窗函数的示意图。
42.图4为本具体实施方式中的实用的全连接层的示意图。
具体实施方式
43.为了使本技术领域的人员更好地理解本发明方案,下面结合具体实施方式对本发明作进一步的详细说明。
44.如图1所示,本发明的一实施方式为一种基于音频变频域的嵌入水印的方法,其通过对vad操作选取特定频带进行拼帧,并且选取前5帧和后5帧拼帧形成11帧的语音数据来嵌入水印;并且在指定的带宽采样点中嵌入水印,实现新的嵌入水印的方法。
45.该嵌入水印的方法具体包括以下步骤:
46.s1:对原始音频进行分帧,并且对每个分帧进行采样和dct变换(discrete cosine transform,离散余弦变换),得到每个采样点对应的频域子带以及每帧的dct系数。
47.该dct系数的计算方法如下:
[0048][0049][0050]
其中,c(0)表示第0个dct系数;n为信号采样点个数,本发明中,选取n为1024,c(i)表示第i个dct系数,i=1,2,3,
…
,n
‑
1;y(x)表示原始信号。
[0051]
s2:对一帧语音中的dct指定的高频子带范围进行vad检测(voice activity detection,语音活动检测)和拼帧操作,用于获取语音段。本步骤的目的是从语音信号流里识别和消除长时间的静音期。其中,dct指定的高频子带的频率分为为6khz
‑
7khz。
[0052]
在该步骤中,vad检测和拼帧操作包括:获取子带的语音能量谱,生成语音信号的fbank特征,以及拼帧形成语音数据;之后判断该语音数据是否为语音段,如果是则进行步骤s3,如果不是则重新选取下一帧进行vad检测。
[0053]
具体地,该步骤s2具体包括以下步骤:
[0054]
s201:对dct指定的高频子带(6khz
‑
7khz)进行加汉宁窗操作,之后进行fft变换(fast fourier transform,快速傅里叶变换),得到语音能量谱。
[0055]
其中,本步骤中使用的汉宁窗函数如图3所示。
[0056]
并且,本步骤中,加窗操作即与汉宁窗函数相乘;加窗之后是为了进行傅里叶展开。加窗之后的音频分帧具有以下优点:全局更加连续,避免出现吉布斯效应;加窗时候,原本没有周期性的语音信号呈现出周期函数的部分特征。
[0057]
s202:将语音能量谱通过一组mel尺度的三角形滤波器组之后取对数,生成语音信号的fbank特征,并且根据fbank特征选择语音能量谱的第2到6频带。
[0058]
s203:选取2到6频带对应帧作为当前帧,将其前5帧和后5帧进行拼帧,形成11帧的语音数据。
[0059]
s204:拼帧后的语音数据输入到全连接层,如果全连接层的输出结果是0,则判断拼帧后的语音为不是语音段;如果全连接层的输出结果是1,则判断拼帧后的语音为是语音段。
[0060]
其中,全连接层如图4所示,拼帧后的数据经过全连接层,第一层是128个节点,第二层是128个节点,第三层是64个节点,第四层是64个节点,第五层是32个节点,第六层是32个节点,第七层是2个节点,最后输出的标签是0或者1。
[0061]
s3:在语音段中,根据同步码信息和水印信息生成水印位。
[0062]
其中,每个语音段的开始的4帧中依次嵌入同步码、水印、同步码、水印,嵌入信息结构如下表格中所示:
[0063]
同步码水印同步码水印
[0064]
在提取水印的时候,通过同步码信息能够精准定位到当前数据中包含水印,区别于水印信息。
[0065]
具体地,在语音段中,根据水印的二进制数进行扩频,并且根据水印信息和同步信息产生m个线性不相关([
‑
1,1])的序列向量作为水印位,相邻序列向量之间的间距等于dct指定的高频子带(6khz
‑
7khz)的采样点个数的大小。
[0066]
s4:在语音段中每个水印位嵌入水印,得到带水印的信号。
[0067]
具体地,在频率为6khz
‑
7khz的高频子带中对应的采样点中嵌入水印;嵌入的水印需满足以下条件:当前水印值大于0时,如果当前水印的平均值比之前一帧的水印值小,则framedct=dct/var_dct_value*pre_dct_value,否则,不做任何操作;当水印值小于等于0时,不做任何操作。
[0068]
其中,framedct为当前子带范围内嵌入的水印值;dct为当前子带的采样点值;var_dct_value为当前子带对应的采样点的均值;pre_dct_value为前一个子带的采样点的均值。
[0069]
s5:对带水印的信号进行idct变换(逆离散余弦变换),得到带水印的音频信号。
[0070]
idct变换的计算方法如下:
[0071][0072]
其具体算法相当于步骤s1中dct变换的逆,得到的结果为嵌入水印后的音频信号。
[0073]
通过上述基于音频变频域的嵌入水印的方法,能够对字频进行vad操作,能够筛选出合适的子带进行添加水印,并且通过步骤s4来嵌入水印时,能够添加更少量的伪随机码噪声,水印的透明度更高。
[0074]
此外,如图2所示,本发明的一实施方式为一种基于音频变频域的定位水印的方法,其通过对全频道进行vad操作以进行拼帧,并且形成11帧的语音数据来读取水印。
[0075]
该定位水印的方法具体包括以下步骤:
[0076]
s11:对带水印的音频进行分帧,并且对每个分帧进行采样和dct变换,得到每个采样点对应的频域子带。
[0077]
s12:对一帧语音中的所有频带进行vad检测和拼帧操作,得到语音段。其中,vad检测和拼帧操作包括:获取子带的语音能量谱,生成语音信号的fbank特征,以及拼帧形成语音数据。
[0078]
具体地,该vad检测操作包括以下步骤:
[0079]
s1201:对一帧语音中的所有频带进行加汉宁窗操作,之后进行fft变换(fast fourier transform,快速傅里叶变换),得到语音能量谱。
[0080]
其中,本步骤中使用的汉宁窗函数如图3所示。
[0081]
并且,本步骤中,加窗操作即与汉宁窗函数相乘;加窗之后是为了进行傅里叶展开。加窗之后的音频分帧具有以下优点:全局更加连续,避免出现吉布斯效应;加窗时候,原本没有周期性的语音信号呈现出周期函数的部分特征。
[0082]
s1202:将语音能量谱通过一组mel尺度的三角形滤波器组之后取对数,生成语音信号的fbank特征,并且选根据fbank特征选择语音能量谱的第2到6频带。
[0083]
s1203:取2到6频带对应帧作为当前帧,将其前5帧和后5帧进行拼帧,形成11帧的语音数据。
[0084]
s1204:拼帧后的语音数据输入到全连接层,如果全连接层的输出结果是0,则判断拼帧后的语音为不是语音段;如果全连接层的输出结果是1,则判断拼帧后的语音为是语音段。
[0085]
其中,全连接层如图4所示,拼帧后的数据经过全连接层,第一层是128个节点,第二层是128个节点,第三层是64个节点,第四层是64个节点,第五层是32个节点,第六层是32个节点,第七层是2个节点,最后输出的标签是0或者1。
[0086]
s13:利用语音段中的同步码,检测与设置的同步码是否一致,如果一致,则找到同步帧的位置,则判定为同步帧并进行步骤s41,如果不一致,则不为同步帧并返回步骤s12,选择下一帧语音进行判定。
[0087]
s14:基于同步码识别水印段,进而通过计算dct系数获取当前水印的位置。
[0088]
具体地,基于同步码识别水印段,然后计算水印段的dct系数、对应子带的dct系数与伪随机噪声块之间的相关性,提取最大相关的向量索引值,作为当前水印的bit位。
[0089]
该dct系数的计算方法如下:
[0090][0091][0092]
其中,c(0)表示第0个dct系数;n为信号采样点个数;c(i)表示第i个dct系数,i=1,2,3,
…
,n
‑
1;y(x)表示原始信号。
[0093]
该dct系数与伪随机噪声块之间的相关性的计算方法如下所示:
[0094]
r
sg
=s(w).g(w)
[0095]
其中,s(w)表示带水印信号的dct的频域系数矩阵,g(w)代表伪随机噪声块的矩阵,两个矩阵相乘,得到互相关向量r
sg
。
[0096]
通过上述基于音频变频域的定位水印的方法通过在全频带进行vad操作,进而识别语音段,能够快速地筛选出语音段,进而对水印进行识别。
[0097]
本文中应用了具体个例对发明构思进行了详细阐述,以上实施例的说明只是用于帮助理解本发明的核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离该发明构思的前提下,所做的任何显而易见的修改、等同替换或其他改进,均应包含在本发明的保护范围之内。