1.本公开的实施例涉及一种音频评测方法、音频评测装置以及非瞬时性存储介质。
背景技术:
2.口语交流是一种重要的人际交流的方式,在人们的实际生活中具有重要地位。随着社会经济的不断发展,人们对口语学习的效率以及口语评估的客观性、公正性和规模化测试提出了越来越高的要求。传统的人工口语水平评测方法由于评估者的个体差异,往往不能保证评分标准的统一;另外,由于需要大量的人力、物力和财力支持,人工评测方法也不适宜用于大规模的口语测试。
3.随着语音技术的不断成熟,语音技术在各个领域的应用越来越广泛。口语评测是语音技术最早的应用领域之一,越来越多的口语教学者和用户都纷纷借助于这种口语评测的技术来进行口语的教学和学习。
技术实现要素:
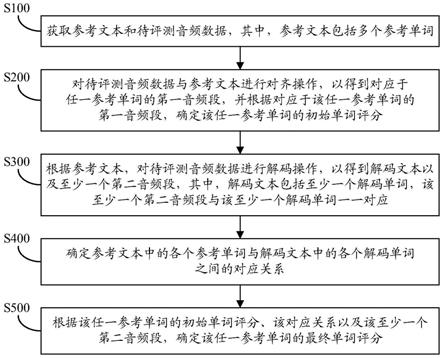
4.本公开至少一个实施例提供一种音频评测方法,包括:获取参考文本和待评测音频数据,其中,所述参考文本包括多个参考单词;对所述待评测音频数据与所述参考文本进行对齐操作,以得到对应于所述多个参考单词中的任一参考单词的第一音频段,并根据对应于所述任一参考单词的第一音频段,确定所述任一参考单词的初始单词评分;根据所述参考文本,对所述待评测音频数据进行解码操作,以得到解码文本以及至少一个第二音频段,其中,所述解码文本包括至少一个解码单词,所述至少一个第二音频段与所述至少一个解码单词一一对应;确定所述参考文本中的各个参考单词与所述解码文本中的各个解码单词之间的对应关系;以及根据所述任一参考单词的初始单词评分、所述对应关系以及所述至少一个第二音频段,确定所述任一参考单词的最终单词评分。
5.例如,在本公开一些实施例提供的音频评测方法中,根据所述任一参考单词的初始单词评分、所述对应关系以及所述至少一个第二音频段,确定所述任一参考单词的最终单词评分,包括:响应于所述任一参考单词的初始单词评分低于评分阈值且所述任一参考单词对应于所述至少一个解码单词中的某一解码单词,根据所述某一解码单词对应的第二音频段,确定所述任一参考单词的中间单词评分,并根据所述任一参考单词的初始单词评分和所述任一参考单词的中间单词评分,确定所述任一参考单词的最终单词评分。
6.例如,在本公开一些实施例提供的音频评测方法中,根据所述任一参考单词的初始单词评分和所述任一参考单词的中间单词评分,确定所述任一参考单词的最终单词评分,包括:响应于所述任一参考单词的所述中间单词评分高于所述任一参考单词的所述初始单词评分,将所述任一参考单词的所述中间单词评分作为所述任一参考单词的最终单词评分;以及响应于所述任一参考单词的所述中间单词评分不高于所述任一参考单词的所述初始单词评分,将所述任一参考单词的所述初始单词评分作为所述任一参考单词的最终单词评分。
7.例如,在本公开一些实施例提供的音频评测方法中,所述某一解码单词与所述任一参考单词相同。
8.例如,在本公开一些实施例提供的音频评测方法中,根据所述任一参考单词的初始单词评分、所述对应关系以及所述至少一个第二音频段,确定所述任一参考单词的最终单词评分,包括:响应于所述任一参考单词的初始单词评分低于评分阈值且所述任一参考单词不对应于所述至少一个解码单词中的任一解码单词,将所述任一参考单词的初始单词评分作为所述任一参考单词的最终单词评分。
9.例如,在本公开一些实施例提供的音频评测方法中,根据所述任一参考单词的初始单词评分、所述对应关系以及所述至少一个第二音频段,确定所述任一参考单词的最终单词评分,包括:响应于所述任一参考单词的初始单词评分不低于评分阈值,将所述任一参考单词的初始单词评分作为所述任一参考单词的最终单词评分。
10.例如,在本公开一些实施例提供的音频评测方法中,对所述待评测音频数据与所述参考文本进行对齐操作,包括:基于强制对齐算法,根据声学模型对所述待评测音频数据与所述参考文本进行强制对齐操作。
11.例如,在本公开一些实施例提供的音频评测方法中,根据所述参考文本,对所述待评测音频数据进行解码操作,包括:以所述参考文本作为训练语料,训练得到与所述参考文本对应的语言模型;根据所述声学模型和所述语言模型,对所述待评测音频数据进行解码操作。
12.例如,在本公开一些实施例提供的音频评测方法中,根据所述声学模型和所述语言模型,对所述待评测音频数据进行所述解码操作,包括:根据所述声学模型和所述语言模型构建带权重的有限状态转换器解码图;以及,根据所述带权重的有限状态转换器解码图,基于维特比算法对所述待评测音频数据进行解码操作,以得到所述解码文本以及所述至少一个第二音频段。
13.例如,在本公开一些实施例提供的音频评测方法中,所述语言模型包括3元语言模型。
14.例如,在本公开一些实施例提供的音频评测方法中,,确定所述参考文本中的各个参考单词与所述解码文本中的各个解码单词之间的对应关系,包括:对所述解码文本与所述参考文本进行编辑距离操作,以确定所述对应关系。
15.例如,在本公开一些实施例提供的音频评测方法中,对所述解码文本与所述参考文本进行编辑距离操作,包括:基于莱文斯坦编辑距离算法,以单词作为编辑元素,对所述解码文本与所述参考文本进行编辑距离操作。
16.例如,在本公开一些实施例提供的音频评测方法中,根据对应于所述任一参考单词的第一音频段,确定所述任一参考单词的初始单词评分,包括:基于发音准确度算法,根据对应于所述任一参考单词的第一音频段,确定所述任一参考单词的初始单词评分。
17.例如,本公开一些实施例提供的音频评测方法,还包括:获取所述多个参考单词的最终单词评分;以及根据所述多个参考单词的最终单词评分,确定所述待评测音频数据的评分。
18.本公开至少一个实施例还提供一种音频评测装置,包括:存储器,用于非暂时性存储计算机可读指令;以及处理器,用于运行所述计算机可读指令,其中,所述计算机可读指
令被所述处理器运行时,执行本公开任一实施例提供的音频评测方法。
19.本公开至少一个实施例还提供一种非瞬时性存储介质,非暂时性地存储计算机可读指令,其中,当所述非暂时性计算机可读指令由计算机执行时,能够执行本公开任一实施例提供的音频评测方法的指令。
附图说明
20.为了更清楚地说明本公开实施例的技术方案,下面将对实施例的附图作简单地介绍,显而易见地,下面描述中的附图仅仅涉及本公开的一些实施例,而非对本公开的限制。
21.图1为一种口语评测技术中的线性解码路径的示意图;
22.图2为一种口语评测技术中的分支解码路径的示意图;
23.图3为本公开至少一实施例提供的一种音频评测方法的流程图;
24.图4为一种对应于图3中所示的步骤s300的示例性流程图;
25.图5为一种对应于图4中所示的步骤s320的示例性流程图;
26.图6为一种漏读情况下的编辑距离操作的效果示意图;
27.图7为一种多读情况下的编辑距离操作的效果示意图;
28.图8为本公开至少一实施例提供的一种对第一权重矩阵进行预训练的流程图;
29.图9为本公开至少一实施例提供的一种音频评测装置的示意性框图;以及
30.图10为本公开至少一实施例提供的一种存储介质的示意图。
具体实施方式
31.为使本公开实施例的目的、技术方案和优点更加清楚,下面将结合本公开实施例的附图,对本公开实施例的技术方案进行清楚、完整地描述。显然,所描述的实施例是本公开的一部分实施例,而不是全部的实施例。基于所描述的本公开的实施例,本领域普通技术人员在无需创造性劳动的前提下所获得的所有其他实施例,都属于本公开保护的范围。
32.除非另外定义,本公开使用的技术术语或者科学术语应当为本公开所属领域内具有一般技能的人士所理解的通常意义。本公开中使用的“第一”、“第二”以及类似的词语并不表示任何顺序、数量或者重要性,而只是用来区分不同的组成部分。“包括”或者“包含”等类似的词语意指出现该词前面的元件或者物件涵盖出现在该词后面列举的元件或者物件及其等同,而不排除其他元件或者物件。“连接”或者“相连”等类似的词语并非限定于物理的或者机械的连接,而是可以包括电性的连接,不管是直接的还是间接的。“上”、“下”、“左”、“右”等仅用于表示相对位置关系,当被描述对象的绝对位置改变后,则该相对位置关系也可能相应地改变。
33.下面通过几个具体的实施例对本公开进行说明。为了保持本公开实施例的以下说明清楚且简明,本公开省略了已知功能和已知部件的详细说明。当本公开实施例的任一部件在一个以上的附图中出现时,该部件在每个附图中由相同或类似的参考标号表示。
34.文本朗读是口语评测中较为常见的一种题型,这种题型要求用户朗读参考文本借以考察用户对基本语音单元发音的标准程度及语句朗读的流利程度。例如,在口语评测中,参考文本通常为一个段落,其包括若干句子,每个句子包括若干单词;用户从头到尾逐个单词地朗读参考文本,由评测算法将用户朗读的语音与参考文本进行对齐(即,使参考文本中
的每个单词对应一个语音片段),进而根据每个单词对应的语音片段自动给每个单词评分,最后给出评测结果。
35.在文本朗读题型的评测过程中,用户可能会出现漏读/多读的状况。例如,用户可能会由于紧张或遇到不熟悉的单词,在朗读过程中漏掉一个或多个单词,从而出现漏读的问题;又例如,用户也可能会由于紧张或失误,在朗读过程中对一个或多个单词多读了一遍(或多遍),或者在朗读过程中朗读了额外的单词,从而出现多读的问题。
36.需要说明的是,为了描述的方便和简洁,本公开中是以参考文本为一个句子“the quick brown fox jumps over the lazy dog”进行说明,而不是以参考文本为段落进行说明,但不应视作对本公开的限制。
37.图1为一种口语评测技术中的线性解码路径的示意图。如图1所示,可以使用强制对齐(forced align)算法基于参考文本“the quick brown fox jumps over the lazy dog”对用户朗读的语音进行线性解码,即将用户朗读的语音按照朗读顺序(如图1中的箭头方向所示)切分为9个语音片段,与参考文本中的9个单词一一对应(第t个语音片段与第t个单词对应,t为正整数,且1≤t≤9);然后可以基于例如发音准确度算法(goodness of pronunciation,gop),根据每个单词对应的语音片段,对每个单词进行评分。最后基于多个单词的评分确定用户朗读的语音的测评结果。
38.需要说明的是,在本公开的实施例中,“单词的评分”表示该单词对应的语音片段的评分,若该单词对应的语音片段中的读音和该单词的基准读音越接近,则该单词的对应的语音片段的评分越高,若该单词对应的语音片段中的读音和该单词的基准读音相差越大,则该单词的对应的语音片段的评分越低。
39.应当理解的是,图1所示的口语评测技术无法处理漏读/多读的问题。例如,假设用户漏读了参考文本中的单词“brown”,而正确朗读了其余的单词,在此情况下,采用图1所示的口语评测技术进行评测时,用户朗读文本“fox jumps over the lazy dog”(6个单词)对应的语音需要切分为7个语音片段,以与文本“brown fox jumps over the lazy dog”中的7个单词一一对应,从而会导致文本“brown fox jumps over the lazy dog”中的7个单词的评分都很低,偏离实际情况(文本“fox jumps over the lazy dog”被正确朗读,该文本中的6个单词应该得到较高的评分,仅漏读的单词“brown”应该得到较低的评分),从而评测结果不够客观、不够合理。又例如,假设用户正确朗读了文本中的各个单词,但是将单词“fox”多读了一遍,在此情况下,采用图1所示的口语评测技术进行评测时,文本“jumps over the lazy dog”中的5个单词对应的语音实际上是用户朗读文本“fox jumps over the lazy dog”(6个单词)对应的语音,即后者需要切分为5个语音片段以与文本“jumps over the lazy dog”中的5个单词一一对应,从而会导致文本“jumps over the lazy dog”中的5个单词的评分都很低,偏离实际情况(文本“jumps over the lazy dog”被正确朗读,其中的5个单词应该得到较高的评分,多读的单词“fox”应该只影响对语句朗读的流利程度的评分),从而评测结果也不够客观、不够合理。
40.为了处理上述漏读/多读的问题,一种口语评测技术是将图1所示的原本只有一条的线性解码路径改造成具有分支路径的解码网络。图2为一种口语评测技术中的分支解码路径的示意图。如图2所示,在该口语评测技术中,弧线1所示的解码路径表示单词“quick”可以重复读(重复的遍数不受限制),弧线2所示的解码路径表示文本“brown fox”可以漏
读,弧线3所示的解码路径表示单词“brown”可以漏读,即在原本的线性解码路径的基础上增加了更多的分支解码路径,从而提高了解码的灵活性,也可以对应处理漏读/多读的问题。例如,在漏读单词“brown”的情况下,可以按照包括弧线3的解码路径对用户朗读的语音进行解码,也即按照文本“the quick fox jumps over the lazy dog”对用户朗读的语音进行解码;又例如,在单词“quick”多读了一遍的情况下,可以按照包括弧线1的解码路径对用户朗读的语音进行解码,也即按照文本“the quick quick brown fox jumps over the lazy dog”对用户朗读的语音进行解码。从而,图2所示的口语评测技术可以处理上述漏读/多读的问题。
41.然而,应当理解的是,图2仅示出了以单词“quick”为起始单词的几个跳转的例子。在实际应用中,图2所示的口语评测技术中需要考虑更多的跳转情况,同时还需要对每一个转移弧上的转移权重进行调试。由于不同单词之间的跳转权重可能也不一样,因此通常需要使用大量的文本和音频数据来进行调参,这样极大地限制了图2所示的口语评测技术的应用和推广。
42.本公开至少一实施例提供一种音频评测方法。该音频评测方法包括:获取参考文本和待评测音频数据,其中,参考文本包括多个参考单词;对待评测音频数据与参考文本进行对齐操作,以得到对应于任一参考单词的第一音频段,并根据对应于该任一参考单词的第一音频段,确定该任一参考单词的初始单词评分;根据参考文本,对待评测音频数据进行解码操作,以得到解码文本以及至少一个第二音频段,其中,解码文本包括至少一个解码单词,该至少一个第二音频段与该至少一个解码单词一一对应;确定参考文本中各个参考单词与解码文本中各个解码单词之间的对应关系;以及根据该任一参考单词的初始单词评分、该对应关系以及该至少一个第二音频段,确定该任一参考单词的最终单词评分。
43.本公开的一些实施例还提供对应于上述音频评测方法的音频评测装置以及非瞬时性存储介质。
44.本公开的实施例提供的音频评测方法,可以快速处理漏读/多读的问题,从而可以为文本朗读的评测提供更加客观、更加合理的评测结果,同时还具有较高的实用性。
45.下面结合附图对本公开的一些实施例及其示例进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本公开,并不用于限制本公开。
46.图3为本公开至少一实施例提供的一种音频评测方法的流程图。例如,该音频评测方法可以应用于计算设备,该计算设备包括具有计算功能的任何电子设备,例如可以为智能手机、笔记本电脑、平板电脑、台式计算机、服务器等,本公开的实施例对此不作限制。例如,该计算设备具有中央处理单元(central processing unit,cpu)或图形处理单元(graphics processing unit,gpu),该计算设备还包括存储器。该存储器例如为非易失性存储器(例如只读存储器(read only memory,rom)),其上存储有操作系统的代码。例如,存储器上还存储有代码或指令,通过运行这些代码或指令,可以实现本公开实施例提供的音频评测方法。
47.例如,如图3所示,该音频评测方法包括步骤s100至步骤s500。
48.步骤s100:获取参考文本和待评测音频数据,其中,参考文本包括多个参考单词。
49.例如,在一些实施例中,图3所示的音频评测方法可以通过例如客户端在本地执行。在此情况下,参考文本可以是用户在客户端存储的文本中任意选择的文本,也可以是客
户端提供的预设文本,本公开的实施例对此不作限制;待评测音频数据可以包括通过客户端的音频采集设备采集的语音,但不限于此。例如,参考文本和待评测音频数据还可以由客户端从网络中获取。
50.例如,客户端包括但不限于智能手机、平板电脑、个人计算机、个人数字助理(personal digital assistant,pda)、可穿戴设备、头戴显示设备等,例如,音频采集设备包括但不限于客户端内置或外接的麦克风。例如,待评测音频数据可以是预先录制的,也可以是实时录制的,本公开的实施例对此不作限制。
51.例如,在另一些实施例中,图3所示的音频评测方法还可以通过例如服务器在远程执行。在此情况下,服务器可以接收用户通过客户端上传的参考文本和待评测音频数据,然后进行音频评测的过程,并将评测结果返回客户端,以供用户参考。
52.例如,参考文本的语言可以为英语、法语、德语、西班牙语、汉语、日语、韩语等语言之一,但不限于此。例如,在参考文本的语言为汉语、日语、韩语等语言的情况下,本公开的实施例中的“一个单词”可以对应理解为“一个字”(例如,汉语中的汉字等)。
53.例如,参考文本通常为一个段落,其包括若干句子,每个句子包括若干单词。本公开的实施例包括但不限于此。
54.例如,一般情况下,待评测音频数据是用户朗读参考文本(允许出现漏读/多读等问题)的语音数据,从而该音频评测方法可以准确地评估用户对基本语音单元发音的标准程度及语句朗读的流利程度。
55.步骤s200:对待评测音频数据与参考文本进行对齐操作,以得到对应于任一参考单词的第一音频段,并根据对应于该任一参考单词的第一音频段,确定该任一参考单词的初始单词评分。
56.例如,在一些实施例中,对待评测音频数据与参考文本进行对齐操作,以得到对应于任一参考单词的第一音频段,可以包括:基于强制对齐算法,根据声学模型(acoustic model)对待评测音频数据与参考文本进行强制对齐操作,以得到对应于任一参考单词的第一音频段。
57.例如,一般地,声学模型是通过大量的发音人的录音训练而成的,利用声学模型可以确定待评测音频数据对应于参考文本的可能性,进而能够将评测音频数据与参考文本进行强制对齐。例如,在一些实施例中,声学模型为基于神经网络的模型,例如神经网络包括但不限于时延神经网络(time-delay neural network,tdnn)、递归神经网络(recurrent neural network,rnn)等。例如,声学模型以及强制对齐算法的具体技术细节均可以参考自然语言处理领域的相关技术,在此不再赘述。
58.例如,通过上述强制对齐操作,可以将待评测音频数据切分为多个第一音频段,以与参考文本中的多个单词一一对应。例如,在一些示例中,每个单词对应的第一音频段可以用该第一音频段在待评测音频数据中的时间边界(time boundary)进行标识,例如,所述时间边界包括该第一音频段的起始时刻和结束时刻。
59.例如,在一些实施例中,根据对应于该任一参考单词的第一音频段,确定该任一参考单词的初始单词评分,包括:基于发音准确度算法(gop),根据该任一参考单词的第一音频段,确定该任一参考单词的初始单词评分。
60.例如,在一些示例中,发音准确度算法可以包括:先提取对应于该任一参考单词的
第一音频段的特征信息,例如,特征信息包括但不限于梅尔倒谱系数(mel-scale frequency cepstral coefficients,mfcc)等;然后将特征信息输入预先训练好的音素评测模型进行音素评估,得到上述第一音频段中的每个音素的gop值;最后基于每个音素的gop值,确定上述第一音频段中的每个音素的音素评分,进而确定每个参考单词的初始单词评分。例如,发音准确度算法的具体细节可以参考自然语言处理领域的相关技术,在此不再赘述。
61.应当理解的是,在本公开的一些实施例中,“任一参考单词”可以指代参考文本中的某一参考单词;又例如,在本公开的另一些实施例中,“任一参考单词”也可以指代参考文本中的每一个参考单词。本公开对此不作限制。
62.应当理解的是,步骤s200可以参考前述图1所示的口语评测技术,从而,步骤s200可以确保该音频评测方法在用户对参考文本进行正确朗读的情况下,对待评测音频数据给出较为合理的评分。
63.步骤s300:根据参考文本,对待评测音频数据进行解码操作,以得到解码文本以及至少一个第二音频段,其中,解码文本包括至少一个解码单词,该至少一个第二音频段与该至少一个解码单词一一对应。
64.例如,在一些实施例中,解码文本中的每个解码单词都是出自于参考文本。也就是说,如果以参考文本中的各个单词为元素构建一个集合,则解码文本中的每个解码单词均为该集合中的元素。
65.图4为一种对应于图3中所示的步骤s300的示例性流程图,以下结合图4对步骤s300进行详细说明。
66.例如,如图4所示,步骤s300可以包括如下步骤s310和步骤s320。
67.步骤s310:以参考文本作为训练语料,训练得到与参考文本对应的语言模型(language model)。
68.例如,在一些实施例中,可以以参考文本作为训练语料,训练得到n元(n-gram)语言模型,例如n元语言模型包括但不限于常用的3元(n=3)语言模型和2元(n=2)语言模型。例如,n元语言模型是一个基于概率的判别模型,n元语言模型的输入是n个单词的顺序序列,n元语言模型的输出是这n个单词的联合概率(joint probability)。例如,n元语言模型的具体技术细节可以参考自然语言处理领域的相关技术,在此不再赘述。
69.需要说明的是,语言模型和参考文本是对应的,也就是说,不同的参考文本对应不同的语言模型。在本公开的实施例中,参考文本可以是任意的文本,因此,在该音频评测方法的每次执行过程中,通常需要基于每次获取的参考文本,训练(即之前的参考文本的信息不会影响本次的语言模型)得到与该获取的参考文本对应的语言模型,进而确保后续解码操作得到的解码文本中的每个解码单词都是出自于参考文本。
70.步骤s320:根据声学模型和语言模型,对待评测音频数据进行解码操作。
71.需要说明的是,步骤s320中使用的声学模型与步骤s200中使用的声学模型通常为同一个模型,步骤s320中使用的语言模型即为步骤s310中得到的语言模型。
72.图5为一种对应于图4中所示的步骤s320的示例性流程图,以下结合图5对步骤s320进行详细说明。
73.步骤s321:根据声学模型和语言模型构建带权重的有限状态转换器解码图。
74.例如,带权重的有限状态转换器(weighted finite state transducer,wfst)提供了一个统一的形式来表示当前业界大规模连续语音识别(lvcsr)系统的不同知识源(knowledge source),比如隐马尔可夫模型、发音词典模型和语言模型。
75.例如,声学模型可以用于将声音信号(例如,待评测音频数据)识别成声学单元(例如,音素等)。例如,在一些实施例中,声学模型通常可以基于高斯混合模型(gaussian mixture model,gmm)—隐马尔可夫模型(hidden markov model,hmm)的架构(gmm-hmm)或者深度神经网络(deep neural network,dnn)—隐马尔可夫模型的架构(dnn-hmm)来进行建模。例如,在一些示例中,可以先对待评测音频数据进行分帧,然后提取每一帧的特征信息(包括但不限于梅尔倒谱系数等),再通过高斯混合模型或深度神经网络确定每一帧对应的hmm状态,并将上述hmm状态作为隐马尔可夫模型的输入,例如隐马尔可夫模型的输出为音素序列。例如,发音词典模型可以用于将音素序列转化为单词序列;例如,语言模型可以用于对单词序列进行筛选,以得到合乎语法的句子(例如,由多个单词构成的词串)。
76.例如,在一些实施例中,语言模型、发音词典模型和声学模型中的隐马尔可夫模型均可以通过wfst来表示。例如,在一些实施例中,表示不同知识源的多个wfst可以通过复合运算整合成一个wfst,这个整合后的wfst表示的解码图(也称为“搜索网络”)的输入是前述hmm状态。这个整合后的wfst可以通过各种优化运算来去掉其中的冗余部分而变成等价的但是更加紧凑高效的wfst来加速解码过程。
77.例如,上述隐马尔可夫模型、发音词典模型和wfst等的具体技术细节均可以参考自然语言处理领域的相关技术,在此不再赘述。
78.步骤s322:根据带权重的有限状态转换器解码图,基于维特比算法对待评测音频数据进行解码操作,以得到解码文本以及至少一个第二音频段。
79.例如,维特比(viterbi)算法是基于令牌传递(token passing)的思想进行解码。例如,基于维特比算法,可以在带权重的有限状态转换器(wfst)解码图中寻找最优解码路径,从而确定解码文本中的各个解码单词,即得到解码文本;又例如,每个解码单词的时间边界可以在维特比算法结束后回溯的过程中得到,从而根据每个解码单词的时间边界(例如,包括起始时刻和结束时刻),可以确定对应于每个解码单词的第二音频段。
80.步骤s400:确定参考文本中的各个参考单词与解码文本中的各个解码单词之间的对应关系。
81.例如,在一些实施例中,可以对解码文本与参考文本进行编辑距离操作,以确定参考文本中的各个参考单词与解码文本中的各个解码单词之间的对应关系。
82.下面简单介绍计算任意两个字符串之间的编辑距离的方式。字符串的编辑距离,又称为莱文斯坦(levenshtein)编辑距离,其是指利用字符操作(即以字符为编辑元素),把字符串a{i}转换成字符串b{j}所需要的最少操作数,其中,字符操作包括:(1)删除一个字符,(2)插入一个字符,(3)修改一个字符。
83.对于字符串a{i}和b{j}而言,i表示字符串a{i}的长度(即包括的字符的个数),j表示字符串b{j}的长度,i、j均为整数,且i≥0、j≥0。lev(a{i},b{j})表示字符串a{i}和b{j}之间的编辑距离,一种莱文斯坦编辑距离算法包括以下公式:
[0084][0085]
其中,max()为取最大值函数,min()为取最小值函数,a{i-1}表示字符串a{i}的前i-1个字符形成的字符串,b{j-1}表示字符串b{j}的前j-1个字符形成的字符串,a[i]表示字符串a{i}中的第i个字符(即最后一个字符),b[j]表示字符串b{j}中的第j个字符(即最后一个字符)。
[0086]
上述公式表示的莱文斯坦编辑距离算法包括:
[0087]
(1)当一个字符串的长度为0的时候(对应于ifmin(i,j)=0的情况),编辑距离就是另一个字符串的长度;
[0088]
(2)当字符串a和b的长度均不为0的时候(对应于ifmin(i,j)≠0的情况):
[0089]
若两个字符串的最后一个字符相同(对应于if[i]=b[j]的情况),则可以删除两个字符串a{i}和b{j}的最后一个字符以得到两个新的字符串a{i-1}和b{j-1},确定字符串a{i}和b{j}之间的编辑距离就转化为确定新的字符串a{i-1}和b{j-1}之间的编辑距离,
[0090]
若两个字符串的最后一个字符不同(对应于if[i]≠b[j]的情况),则确定字符串a{i}和b{j}之间的编辑距离就转化为确定字符串a{i-1}和b{j}之间的编辑距离、字符串a{i}和b{j-1}之间的编辑距离和字符串a{i-1}和b{j-1}之间的编辑距离三者之最小值。
[0091]
应当理解的是,上述莱文斯坦编辑距离算法是从两个字符串的最后一个字符开始进行比较(即比较两个字符串的最后一个字符是否相同),实际应用中包括但不限于此。例如,另一种莱文斯坦编辑距离算法可以从两个字符串的第一个字符开始进行比较。
[0092]
应当理解的是,莱文斯坦编辑距离的确定是一个动态规划问题,其可以根据上述公式通过递归过程进行计算。同时,还应当理解的是,在计算莱文斯坦编辑距离的动态规划过程中,可以确定字符串a{i}中的各个字符与字符串b{j}中的各个字符之间的对应关系(即在编辑距离取最小值的情况下,字符串a{i}中的某个字符与字符串b{j}中的某个字符相同,则二者互相对应)。
[0093]
例如,在一些实施例中,可以基于上述莱文斯坦编辑距离算法,以单词作为编辑元素,对解码文本与参考文本进行编辑距离操作,以确定参考文本中的各个参考单词与解码文本中的各个解码单词之间的对应关系。例如,可以将参考文本视作字符串a{i}(每个参考单词视作一个字符),将解码文本视作字符串b{j}(每个解码单词视作一个字符),则:
[0094]
(1)对应于ifmin(i,j)=0的情况,若i=0,则表示解码文本b{j}中的j个单词都属于多读的情况,若j=0,则表示参考文本a{i}中的i个单词都属于漏读的情况;
[0095]
(2)对应于ifmin(i,j)≠0的情况:
[0096]
若a[i]=b[j],则表示参考文本中的第i个参考单词被正确朗读,从而出现在了解码文本中,因此,需要进一步对新的参考文本a{i-1}和新的解码文本b{j-1}进行编辑距离操作;
[0097]
若a[i]≠b[j],则需要分别进行以下三种编辑距离操作:1)假设参考单词a[i]属于漏读的情况,对新的参考文本a{i-1}和解码文本b{j}进行编辑距离操作;2)假设解码单
词b[j]属于多读的情况,对参考文本a{i}和新的解码文本b{j-1}进行编辑距离操作;3)假设参考单词a[i]属于误读的情况,对新的参考文本a{i-1}和新的解码文本b{j-1}进行编辑距离操作。并通过递归过程确定编辑距离最小的编辑距离操作路径,以确定参考文本中的各个参考单词与解码文本中的各个解码单词之间的对应关系。
[0098]
例如,在一些实施例中,为了使本公开的实施例提供的音频检测方法可以更有针对性地处理漏读/多读的问题,在进行编辑距离操作的过程中,可以将删除一个单词的权值设为1(即视作一次单词操作),将插入一个单词的权值设为1(即视作一次单词操作),而将修改一个单词的权值设为q(q>1,即视作多次单词操作)。例如,q的取值可以根据需要进行设置;例如,q可以取为2、5、10等整数,当然q也可以取为2.5、3.6、8.2等非整数。
[0099]
应当理解的是,在本公开的实施例中,编辑距离操作是以单词作为编辑元素,因此,在进行编辑距离操作时,可以删除参考文本中的标点符号等,使得参考文本中仅保留各个参考单词;另外,由于在用户朗读参考文本时,通常仅朗读参考文本中的各个参考单词,从而,步骤s300的解码操作得到的解码文本通常仅包括各个解码单词,因此,在进行编辑距离操作时,可以不对解码文本进行额外处理。同时,还应当理解的是,在进行编辑距离操作时,对于英语等语言,通常会忽略各个单词中的字母大小写的影响。
[0100]
以下,以参考文本“the quick brown fox jumps over the lazy dog”为例,对出现漏读/多读的状况下的编辑距离操作的效果进行说明。
[0101]
图6为一种漏读情况下的编辑距离操作的效果示意图。假设用户漏读了参考文本中的参考单词“brown”,而正确朗读了其余的参考单词,在此情况下,如图6所示,通过前述步骤s300可以确定解码文本为“the quick fox jumps over the lazy dog”,其中,解码文本中的每个解码单词都是出自于参考文本中的各个参考单词组成的集合。从而,基于莱文斯坦编辑距离算法(以单词作为编辑元素),对解码文本与参考文本进行编辑距离操作,可以确定参考文本中的各个参考单词与解码文本中的各个解码单词之间的对应关系如下:如图6所示,参考文本中的参考单词“the”、“quick”、“fox”、“jumps”、“over”、“the”、“lazy”、“dog”与解码文本中的解码单词“the”、“quick”、“fox”、“jumps”、“over”、“the”、“lazy”、“dog”一一对应,参考文本中的参考单词“brown”对应于删除符号<eps>。即参考单词“brown”属于漏读情况,从而没有出现在解码文本中。
[0102]
图7为一种多读情况下的编辑距离操作的效果示意图。假设用户正确朗读了参考文本中的各个参考单词,但是将参考单词“fox”多读了一遍,,在此情况下,如图7所示,通过前述步骤s300可以确定解码文本为“the quick fox fox jumps over the lazy dog”,其中,解码文本中的每个解码单词都是出自于参考文本中的各个参考单词组成的集合。从而,基于莱文斯坦编辑距离算法(以单词作为编辑元素),对解码文本与参考文本进行编辑距离操作,可以确定参考文本中的各个参考单词与解码文本中的各个解码单词之间的对应关系如下:如图7所示,参考文本中的参考单词“the”、“quick”、“fox”、“jumps”、“over”、“the”、“lazy”、“dog”与解码文本中的解码单词“the”、“quick”、第一个“fox”、“jumps”、“over”、“the”、“lazy”、“dog”一一对应,解码文本中的第二个“fox”对应于插入符号<ins>。即解码文本中的第二个“fox”属于多读情况,其不与参考文本中的任一参考单词对应。需要说明的是,在图7所示的效果图中,编辑距离操作是从参考文本和解码文本的第一个单词开始进行比较;在另一些示例中,若编辑距离操作是从参考文本和解码文本的最后一个单词开始进
行比较,则参考单词“fox”可以与解码文本中的第二个“fox”对应,而解码文本中的第一个“fox”属于多读情况。
[0103]
需要说明的是,图6和图7所示的漏读和多读情况均是示意性的,在实际应用中,可能存在多个单词被漏读的情况,也可能存在多个单词被多读或一个单词被多读好几遍等情况,还可能存在漏读和多读并存的情况,这些情况都可以通过上述编辑距离操作进行应对,从而不会影响本公开的实施例提供的音频评测方法的实现。
[0104]
步骤s500:根据该任一参考单词的初始单词评分、该对应关系以及该至少一个第二音频段,确定该任一参考单词的最终单词评分。
[0105]
图8为一种对应于图3中所示的步骤s500的示例性流程图,以下结合图8对步骤s500进行详细说明。
[0106]
例如,如图8所示,步骤s500可以包括如下步骤s510、步骤s520和步骤s530。
[0107]
步骤s510:响应于该任一参考单词的初始单词评分低于评分阈值且该任一参考单词对应于该至少一个解码单词中的某一解码单词,根据该某一解码单词对应的第二音频段,确定该任一参考单词的中间单词评分,并根据该任一参考单词的初始单词评分和该任一参考单词的中间单词评分,确定该任一参考单词的最终单词评分。
[0108]
例如,在一些实施例中,步骤s510可以用于确定受到漏读/多读影响的参考单词的最终单词评分。
[0109]
例如,在一些实施例中,该任一参考单词对应于该某一解码单词,表示该某一解码单词与该任一参考单词相同。
[0110]
例如,在一些实施例中,根据该任一参考单词的初始单词评分和该任一参考单词的中间单词评分,确定该任一参考单词的最终单词评分,可以包括:响应于该任一参考单词的中间单词评分高于该任一参考单词的初始单词评分,将该任一参考单词的中间单词评分作为该任一参考单词的最终单词评分;以及,响应于该任一参考单词的中间单词评分不高于该任一参考单词的初始单词评分,将该任一参考单词的初始单词评分作为该任一参考单词的最终单词评分。
[0111]
例如,在如图6所示的实施例中,在使用图1所示的口语评测技术进行评测的情况下,参考前述图1所示的口语评测技术的相关描述可知,参考单词“brown”、“fox”、“jumps”、“over”、“the”、“lazy”、“dog”的初始单词评分可能都会很低(例如,低于评分阈值)。相比之下,在步骤s510中,可以基于解码单词“fox”、“jumps”、“over”、“the”、“lazy”、“dog”各自对应的第二音频段确定参考单词“fox”、“jumps”、“over”、“the”、“lazy”、“dog”的中间单词评分,进而可以根据初始单词评分和中间单词评分确定参考单词“fox”、“jumps”、“over”、“the”、“lazy”、“dog”的最终单词评分,由此使得评测结果更加客观、更加合理。
[0112]
例如,在如图7所示的实施例中,在使用图1所示的口语评测技术进行评测的情况下,参考前述图1所示的口语评测技术的相关描述可知,参考单词“jumps”、“over”、“the”、“lazy”、“dog”的初始单词评分可能都会很低(例如,低于评分阈值)。相比之下,在步骤s510中,可以基于解码单词“jumps”、“over”、“the”、“lazy”、“dog”各自对应的第二音频段确定参考单词“jumps”、“over”、“the”、“lazy”、“dog”的中间单词评分,进而可以根据初始单词评分和中间单词评分确定参考单词“jumps”、“over”、“the”、“lazy”、“dog”的最终单词评分,由此使得评测结果更加客观、更加合理。
[0113]
需要说明的是,在一些实施例中,在该任一参考单词的中间单词评分不高于该任一参考单词的初始单词评分的情况下,也可以将该任一参考单词的中间单词评分作为该任一参考单词的最终单词评分。
[0114]
例如,在实际应用中,评分阈值可以根据单词评分的取值范围进行合理设置。例如,在一些实施例中,假设单词评分的取值范围是[0,100],则评分阈值的取值范围可以设置为例如[10,40],本公开包括但不限于此。例如,在上述实施例中,评分阈值可以根据实际需要设置为10、15、20、25、30、35、40等。
[0115]
步骤s520:响应于该任一参考单词的初始单词评分低于评分阈值且该任一参考单词不对应于该至少一个解码单词中的任一解码单词,将该任一参考单词的初始单词评分作为该任一参考单词的最终单词评分。
[0116]
例如,在一些实施例中,步骤s520可以用于确定漏读的参考单词的最终单词评分。
[0117]
例如,在如图6所示的实施例中,在使用图1所示的口语评测技术进行评测的情况下,参考前述图1所示的口语评测技术的相关描述可知,漏读的参考单词“brown”的初始单词评分可能会很低(例如,低于评分阈值),从而可以直接将漏读的参考单词“brown”的初始单词评分作为其最终单词评分。
[0118]
应当理解的是,步骤s520中的确定该任一参考单词的最终单词评分的方式是示例性的,在实际应用中,还可以采用其他合理的方式确定该任一参考单词的最终单词评分。例如,在一些示例中,由于通过步骤s400可以确定参考单词“brown”属于漏读情况,从而可以将参考单词“brown”的最终单词评分设置为0或者低于其初始单词评分,本公开的实施例包括但不限于此。
[0119]
步骤s530:响应于该任一参考单词的初始单词评分不低于评分阈值,将该任一参考单词的初始单词评分作为该任一参考单词的最终单词评分。
[0120]
例如,在一些实施例中,步骤s530可以用于确定未受到漏读/多读影响的参考单词的最终单词评分。
[0121]
例如,在如图6所示的实施例中,在使用图1所示的口语评测技术进行评测的情况下,参考前述图1所示的口语评测技术的相关描述可知,参考单词“the”、“quick”的初始单词评分可能是正常的(例如,不低于评分阈值),从而可以直接将其初始单词评分作为其最终单词评分。类似地,在如图7所示的实施例中,在使用图1所示的口语评测技术进行评测的情况下,参考前述图1所示的口语评测技术的相关描述可知,参考单词“the”、“quick”、“brown”、“fox”的初始单词评分可能是正常的(例如,不低于评分阈值),从而可以直接将其初始单词评分作为其最终单词评分。
[0122]
应当理解的是,步骤s530中的确定该任一参考单词的最终单词评分的方式是示例性的,在实际应用中,还可以采用其他合理的方式确定该任一参考单词的最终单词评分。例如,在一些示例中,对于图6所示的实施例,可以根据解码单词“the”、“quick”各自对应的第二音频段确定参考单词“the”、“quick”的中间单词评分,进而可以根据例如初始单词评分和中间单词评分的加权平均值(例如,平均值)确定参考单词“the”、“quick”的最终单词评分;又例如,在一些示例中,对于图7所示的实施例,可以根据解码单词“the”、“quick”、“brown”、第一个(或第二个)“fox”各自对应的第二音频段确定参考单词“the”、“quick”、“brown”、“fox”的中间单词评分,进而可以根据例如初始单词评分和中间单词评分的加权
平均值(例如,平均值)确定参考单词“the”、“quick”、“brown”、“fox”的最终单词评分。本公开的实施例包括但不限于此。
[0123]
应当理解的是,在基于步骤s500确定某一参考单词的最终单词评分时,步骤s510、步骤s520和步骤s530是根据判断条件择一执行的。
[0124]
例如,在上述步骤s100至步骤s500的基础上,本公开的一些实施例提供的音频评测方法,还可以包括步骤s600(图3中未示出):获取该多个参考单词的最终单词评分;以及根据该多个参考单词的最终单词评分,确定该待评测音频数据的评分。
[0125]
例如,在一些实施例中,步骤s600中的获取该多个参考单词的最终单词评分,是指根据前述步骤s100至步骤s500获取参考文本中的每个参考单词的最终单词评分。从而,可以采用任意合理的评分方式,根据每个参考单词的最终单词评分,确定该待评测音频数据的评分,本公开的实施例对此不作限制。
[0126]
例如,在一些示例中,可以将各个参考单词的最终单词评分的加权平均值作为该待评测音频数据的评分;例如,在另一些示例中,还可以根据漏读/多读的情况,对朗读的流利程度进行评分,例如,可以适当增加或扣减前述示例得到的待评测音频数据的评分。本公开的实施例包括但不限于此。
[0127]
需要说明的是,虽然本公开的实施例均以英语文本为例进行说明,但不应视为对本公开的实施例提供的音频评测方法的限制。本公开的实施例提供的音频评测方法可以适用于英语、法语、德语、西班牙语、汉语、日语、韩语等各种语言的文本朗读题型的评测。
[0128]
需要说明的是,在本公开的实施例中,上述音频评测方法的流程可以包括更多或更少的操作,这些操作可以顺序执行或并行执行。虽然上文描述的音频评测方法的流程包括特定顺序出现的多个操作,但是应该清楚地了解,多个操作的顺序并不受限制。上文描述的音频评测方法可以执行一次,也可以按照预定条件执行多次。
[0129]
本公开的实施例提供的音频评测方法,可以处理漏读/多读的问题,从而可以为文本朗读的评测提供更加客观、更加合理的评测结果;同时,与图2所示的口语评测技术相比,本公开的实施例提供的音频评测方法节省了大量训练、调参的工作量,从而具有较高的实用性。
[0130]
本公开至少一实施例还提供一种音频评测装置。图9为本公开至少一实施例提供的另一种音频评测装置的示意性框图。例如,如图9所示,该音频评测装置100包括存储器110和处理器120。
[0131]
例如,存储器110用于非暂时性存储计算机可读指令,处理器120用于运行该计算机可读指令,该计算机可读指令被处理器120运行时执行本公开任一实施例提供的音频评测方法。
[0132]
例如,存储器110和处理器120之间可以直接或间接地互相通信。例如,在一些示例中,如图9所示,该音频评测装置100还可以包括系统总线130,存储器110和处理器120之间可以通过系统总线130互相通信,例如,处理器120可以通过系统总线130访问存储器110。例如,在另一些示例中,存储器110和处理器120等组件之间可以通过网络连接进行通信。网络可以包括无线网络、有线网络、和/或无线网络和有线网络的任意组合。网络可以包括局域网、互联网、电信网、基于互联网和/或电信网的物联网(internet of things)、和/或以上网络的任意组合等。有线网络例如可以采用双绞线、同轴电缆或光纤传输等方式进行通信,
无线网络例如可以采用3g/4g/5g移动通信网络、蓝牙、zigbee或者wifi等通信方式。本公开对网络的类型和功能在此不作限制。
[0133]
例如,处理器120可以控制音频评测装置中的其它组件以执行期望的功能。处理器120可以是中央处理单元(cpu)、张量处理器(tpu)或者图形处理器gpu等具有数据处理能力和/或程序执行能力的器件。中央处理器(cpu)可以为x86或arm架构等。gpu可以单独地直接集成到主板上,或者内置于主板的北桥芯片中。gpu也可以内置于中央处理器(cpu)上。
[0134]
例如,存储器110可以包括一个或多个计算机程序产品的任意组合,计算机程序产品可以包括各种形式的计算机可读存储介质,例如易失性存储器和/或非易失性存储器。易失性存储器例如可以包括随机存取存储器(ram)和/或高速缓冲存储器(cache)等。非易失性存储器例如可以包括只读存储器(rom)、硬盘、可擦除可编程只读存储器(eprom)、便携式紧致盘只读存储器(cd-rom)、usb存储器、闪存等。
[0135]
例如,在存储器110上可以存储一个或多个计算机指令,处理器120可以运行所述计算机指令,以实现各种功能。在计算机可读存储介质中还可以存储各种应用程序和各种数据,例如参考文本、解码文本、初始单词评分、中间单词评分、最终单词评分以及应用程序使用和/或产生的各种数据等。
[0136]
例如,存储器210存储的一些计算机指令被处理器220执行时可以执行根据上文所述的音频评测方法中的一个或多个步骤。
[0137]
例如,如图9所示,音频评测装置100还可以包括允许外部设备与音频评测装置100进行通信的输入接口140。例如,输入接口140可被用于从外部计算机设备、从用户等处接收指令。音频评测装置100还可以包括使音频评测装置100和一个或多个外部设备相互连接的输出接口150。例如,音频评测装置100可以通过输出接口150输出音频评测结果等。通过输入接口140和输出接口150与音频评测装置100通信的外部设备可被包括在提供任何类型的用户可与之交互的用户界面的环境中。用户界面类型的示例包括图形用户界面、自然用户界面等。例如,图形用户界面可接受来自用户采用诸如键盘、鼠标、遥控器等之类的输入设备的输入,以及在诸如显示器之类的输出设备上提供输出。此外,自然用户界面可使得用户能够以无需受到诸如键盘、鼠标、遥控器等之类的输入设备强加的约束的方式来与音频评测装置100交互。相反,自然用户界面可依赖于语音识别、触摸和指示笔识别、屏幕上和屏幕附近的手势识别、空中手势、头部和眼睛跟踪、语音和语音、视觉、触摸、手势、以及机器智能等。
[0138]
例如,在一些实施例中,该音频评测装置100还包括音频评测方法的实施例中描述的音频采集设备。
[0139]
另外,音频评测装置100尽管在图9中被示出为单个系统,但可以理解,音频评测装置100也可以是分布式系统,还可以布置为云设施(包括公有云或私有云)。因此,例如,若干设备可以通过网络连接进行通信并且可共同执行被描述为由音频评测装置100执行的任务。例如,在一些实施例中,可以通过客户端获取参考文本和采集参考文本的待评测音频数据,并将参考文本和待评测音频数据上传至服务器;服务器执行音频评测的过程后将评测结果(例如,各个参考单词的评分和/或待评测音频数据的评分)返回客户端,以提供给用户。
[0140]
例如,关于音频评测方法的实现过程的详细说明可以参考上述音频评测方法的实
施例中的相关描述,重复之处在此不再赘述。
[0141]
例如,在一些示例中,该音频评测装置可以包括但不限于智能手机、平板电脑、个人计算机、个人数字助理(personal digital assistant,pda)、可穿戴设备、头戴显示设备、服务器等。
[0142]
需要说明的是,本公开的实施例提供的音频评测装置是示例性的,而非限制性的,根据实际应用需要,该音频评测装置还可以包括其他常规部件或结构,例如,为实现音频评测装置的必要功能,本领域技术人员可以根据具体应用场景设置其他的常规部件或结构,本公开的实施例对此不作限制。
[0143]
本公开的实施例提供的音频评测装置的技术效果可以参考上述实施例中关于音频评测方法的相应描述,在此不再赘述。
[0144]
本公开至少一实施例还提供一种非瞬时性存储介质。图10为本公开一实施例提供的一种非瞬时性存储介质的示意图。例如,如图10所示,该非瞬时性存储介质200非暂时性地存储计算机可读指令201,当非暂时性计算机可读指令201由计算机(包括处理器)执行时可以执行本公开任一实施例提供的音频评测方法的指令。
[0145]
例如,在非瞬时性存储介质200上可以存储一个或多个计算机指令。非瞬时性存储介质200上存储的一些计算机指令可以是例如用于实现上述音频评测方法中的一个或多个步骤的指令。
[0146]
例如,非瞬时性存储介质可以包括平板电脑的存储部件、个人计算机的硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦除可编程只读存储器(eprom)、光盘只读存储器(cd-rom)、闪存、或者上述存储介质的任意组合,也可以为其他适用的存储介质。
[0147]
本公开的实施例提供的非瞬时性存储介质的技术效果可以参考上述实施例中关于音频评测方法的相应描述,在此不再赘述。
[0148]
对于本公开,有以下几点需要说明:
[0149]
(1)本公开实施例附图中,只涉及到与本公开实施例涉及到的结构,其他结构可参考通常设计。
[0150]
(2)在不冲突的情况下,本公开的实施例及实施例中的特征可以相互组合以得到新的实施例。
[0151]
以上,仅为本公开的具体实施方式,但本公开的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本公开揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本公开的保护范围之内。因此,本公开的保护范围应以权利要求的保护范围为准。