1.本说明书实施例涉及计算机技术领域,尤其涉及一种利用音频判别模型进行音频判别的方法和装置。
背景技术:
2.随着数据处理技术的进步,计算机技术被广泛地运用于各个领域,其中,包括音频处理领域。而通过对人类发出的音频进行分析可以得到多种信息。例如,通过对音频进行声纹识别可以得到发声者的身份信息。人类发出的咳嗽声作为多种疾病的生理表征,不同疾病所表现出的咳嗽声的特点也各不相同,因此,医生通过对患者咳嗽声的分析,可以得到患者的患病信息。对于一些传染性强、致死率高的疾病,例如新型冠状病毒肺炎(简称,新冠肺炎),为了防止疾病的扩散,往往需要花费大量的人力、物力等进行疾病检测。新冠肺炎患者患病期间一般会伴有咳嗽的发生,而咳嗽声也比较容易采集,所以如果能够通过咳嗽声自动生成某个患者是新冠肺炎患者的概率,并将该概率进行显示以辅助用户进行进一步的疾病诊断,将会对抑制疾病的扩散带来极大帮助。
技术实现要素:
3.本说明书的实施例描述了一种利用音频判别模型进行音频判别的方法和装置,本方法用于判别音频中的咳嗽音属于新冠肺炎的概率,基于新冠肺炎症状的咳嗽声的特点构建并训练相应的音频判别模型,从而使音频判别模型输出的概率更加准确。
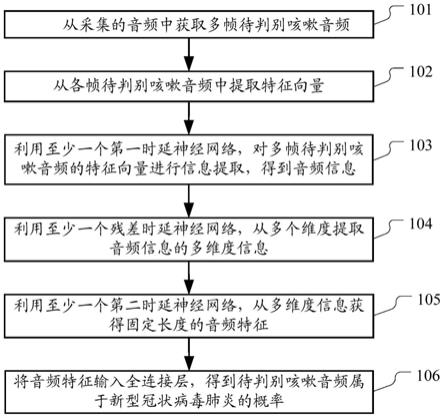
4.根据第一方面,提供了一种利用音频判别模型进行音频判别的方法,用于判别音频中的咳嗽音频属于新型冠状病毒肺炎的概率;上述音频判别模型包括至少一个第一时延神经网络、至少一个第二时延神经网络、至少一个残差时延神经网络和全连接层,上述方法包括:从采集的音频中获取多帧待判别咳嗽音频;从各帧待判别咳嗽音频中提取特征向量;利用至少一个第一时延神经网络,对上述多帧待判别咳嗽音频的特征向量进行信息提取,得到音频信息;利用至少一个残差时延神经网络,从多个维度提取上述音频信息的多维度信息;利用至少一个第二时延神经网络,从上述多维度信息获得固定长度的音频特征;将上述音频特征输入上述全连接层,得到上述待判别咳嗽音频属于新型冠状病毒肺炎的概率。
5.在一个实施例中,上述至少一个残差时延神经网络中的各残差时延神经网络包括挤压激励模块和至少一个时延神经网络,其中,上述挤压激励模块包括第一线性层、第一激活函数、第二线性层和第二激活函数;以及上述至少一个残差时延神经网络中的各残差时延神经网络通过以下方式对输入信息进行处理:利用上述第一线性层,对上述至少一个时延神经网络提取的信息进行降维,以去除新型冠状病毒肺炎的咳嗽音和非新型冠状病毒肺炎的咳嗽音的通用信息;利用上述第二线性层,对上述第一激活函数的输出进行升维,以提升网络参数量;将上述第二激活函数的输出与该残差时延神经网络中最后一个时延神经网络的输出相乘,相乘结果与该残差时延神经网络的输入信息进行加权,将加权结果作为该残差时延神经网络的输出。
6.在一个实施例中,上述至少一个第一时延神经网络包括两个第一时延神经网络;上述至少一个第二时延神经网络包括两个第二时延神经网络;上述至少一个残差时延神经网络包括三个残差时延神经网络。
7.在一个实施例中,上述方法还包括:输出上述概率,以辅助用户判断上述待判别咳嗽音频的发声者是否为新型冠状病毒肺炎的患者。
8.在一个实施例中,上述音频判别模型是通过以下方式训练得到的:获取样本集,其中,上述样本集的样本包括正样本和负样本,正样本包括上述新冠肺炎对应的咳嗽音频的特征向量和概率值1,负样本包括非新冠肺炎对应的咳嗽音频的特征向量和概率值0;将样本的特征向量作为输入,将与输入的特征向量对应的概率值作为期望输出,训练得到音频判别模型。
9.在一个实施例中,上述从采集的音频中获取多帧待判别咳嗽音频,包括:对音频采集设备采集的音频进行预处理,得到处理后音频;使用预先训练的咳嗽声判别模型,确定上述处理后音频中是否包括咳嗽声音频;响应于确定上述处理后音频中包括咳嗽声音频,提取咳嗽声音频作为待判别咳嗽音频。
10.在一个实施例中,上述从各帧待判别咳嗽音频中提取特征向量上述,包括:从上述待判别咳嗽音频中提取梅尔频率倒谱系数,作为特征向量。
11.根据第二方面,提供了一种利用音频判别模型进行音频判别的装置,用于判别音频中的咳嗽音频属于新型冠状病毒肺炎的概率;上述装置包括:获取模块,配置为,从音频采集设备采集的音频中获取多帧待判别咳嗽音频;提取模块,配置为,从各帧待判别咳嗽音频中提取特征向量;第一时延神经网络模块,包括至少一个第一时延神经网络,配置为,接收上述提取模块输出的特征向量,对上述多帧待判别咳嗽音频的特征向量进行信息提取,得到音频信息;残差时延神经网络模块,包括至少一个残差时延神经网络,配置为,接收上述第一时延神经网络模块输出的音频信息,从多个维度提取上述音频信息的多维度信息;第二时延神经网络模块,包括至少一个第二时延神经网络,配置为,接收上述残差时延神经网络模块输出的多维度信息,从上述多维度信息获得固定长度的音频特征;全连接层模块,配置为,接收上述第二时延神经网络模块输出的固定长度的音频特征,得到上述待判别咳嗽音频属于新型冠状病毒肺炎的概率。
12.根据第三方面,提供了一种计算机可读存储介质,其上存储有计算机程序,当上述计算机程序在计算机中执行时,令计算机执行如第一方面中任一项的上述的方法。
13.根据第四方面,提供了一种计算设备,包括存储器和处理器,其特征在于,上述存储器中存储有可执行代码,上述处理器执行上述可执行代码时,实现如第一方面中任一项上述的方法。
14.根据本说明书实施例提供的利用音频判别模型进行音频判别的方法和装置,首先,从采集的音频中获取多帧待判别咳嗽音频,并从各帧待判别咳嗽音频中提取特征向量。而后,利用至少一个第一时延神经网络,对多帧待判别咳嗽音频的特征向量进行信息提取,得到音频信息。之后,利用至少一个残差时延神经网络,从多个维度提取音频信息的多维度信息,并利用至少一个第二时延神经网络,从多维度信息获得固定长度的音频特征。最后,将固定长度的音频特征输入全连接层得到待判别咳嗽音频属于新冠肺炎的概率。从而,实现了根据待判别咳嗽音频自动生成该待判别咳嗽音频属于新冠肺炎的概率,以辅助用户进
行新冠病毒的诊断。
附图说明
15.图1示出了根据一个实施例的利用音频判别模型进行音频判别的方法的流程图;
16.图2示出了音频判别模型的一种实现方式的结构示意图;
17.图3示出了残差时延神经网络的一种实现方式的结构示意图;
18.图4示出了根据一个实施例的利用音频判别模型进行音频判别的装置的示意性框图。
具体实施方式
19.下面结合附图和实施例,对本说明书提供的技术方案做进一步的详细描述。可以理解的是,此处所描述的具体实施例仅仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与有关发明相关的部分。需要说明的是,在不冲突的情况下,本说明书的实施例及实施例中的特征可以相互组合。
20.如图1所示,图1示出了根据一个实施例的利用音频判别模型进行音频判别的方法的流程图。可以理解,该方法可以通过任何具有计算、处理能力的装置、设备、平台、设备集群等来执行。
21.图1所示的利用音频判别模型进行音频判别的方法,用于判别音频中的咳嗽音频属于新冠肺炎的概率。该方法所使用的音频判别模型包括至少一个第一时延神经网络(time delay neural network,tdnn)、至少一个第二时延神经网络、至少一个残差时延神经网络(residual time delay neural network,res_tdnn)和全连接层。
22.在一种实现方式中,上述至少一个第一时延神经网络可以包括两个第一时延神经网络,上述至少一个第二时延神经网络可以包括两个第二时延神经网络,上述至少一个残差时延神经网络可以包括三个残差时延神经网络。由此,构建的音频判别模型可以如图2所示,图2示出了本实现方式中音频判别模型的结构示意图。
23.实践中,经分析发现,相比于普通感冒的咳嗽音频,新冠肺炎的咳嗽音频有断断续续的颤动,咳嗽的持续时间上也比较长。因此,本实现方式的音频判别模型使用两个第一时延神经网络,以提取更多时间上的音频信息。另外,经研究发现,新冠肺炎患者的咳嗽声的能量通常集中在低频和中频区域,此外,新冠肺炎患者的咳嗽声通常比较嘶哑和干燥,通常也伴有痰音。因此,本实现方式的音频判别模型在第一时延神经网络后面挂接三个残差时延神经网络,以从多个维度来提取咳嗽声中的多维度信息,来扩充咳嗽音的整体信息。之后,在残差时延神经网络后挂接两层第二时延神经网络,以获得固定长度的鲁棒的音频特征。最后,第二时延神经网络后端挂接一层包含一个隐藏节点的全连接层,并使用softmax函数作为激活函数,来判断咳嗽音属于新冠肺炎患者的概率。本实现方式在分析新冠肺炎患者咳嗽声特点的基础上构建音频判别模型,从而使构建的音频判别模型更加符合新冠肺炎患者咳嗽声的特点,使音频判别模型的输出结果更加准确。
24.在一种实现方式中,上述至少一个残差时延神经网络中的各残差时延神经网络可以包括挤压激励(squeeze
‑
and
‑
excitation,se)模块和至少一个时延神经网络,其中,上述挤压激励模块可以包括第一线性层、第一激活函数、第二线性层和第二激活函数。作为示
例,图3示出了包括挤压激励模块(如虚线框所示)和三个时延神经网络的残差时延神经网络的结构示意图。在图3的示例中,三个时延神经网络串接在一起,最后一个时延神经网络的输出作为第一线性层的输入,第一线性层的输出作为第一激活函数的输入,第一激活函数的输出作为第二线性层的输入,第二线性层的输出作为第二激活函数的输入,第二激活函数的输出与最后一个时延神经网络的输出相乘。最后,将相乘结果与整个残差时延神经网络的输入组成残差网络。可以理解,图3中的残差时延神经网络仅仅是示意性的,而非对残差时延神经网络中的时延神经网络数量等的限定,实践中可以根据实际需要确定时延神经网络的数量。
25.在本实现方式中,上述至少一个残差时延神经网络中的各个残差时延神经网络可以通过以下方式对输入信息进行处理:首先,利用上述第一线性层,对上述至少一个时延神经网络提取的信息进行降维,以去除新型冠状病毒肺炎的咳嗽音和非新型冠状病毒肺炎的咳嗽音的通用信息。之后,利用上述第二线性层,对上述第一激活函数的输出进行升维,以提升网络参数量。最后,将上述第二激活函数的输出与该残差时延神经网络中最后一个时延神经网络的输出相乘,相乘结果与该残差时延神经网络的输入信息进行加权,将加权结果作为该残差时延神经网络的输出。
26.经实践分析发现,新冠肺炎患者在患病初期通常以干咳为主,随着病情的加重,咳嗽持续时间和频率也会逐渐增强。因此,本实现方式在残差时延神经网络中可以使用多个(例如,三个)时延神经网络,尽可能增大感受野,以更多的利用咳嗽音频的前后文信息。此外,新冠肺炎患者的咳嗽音频还有一些典型的特点,例如咳嗽声音比较嘶哑、干燥和断断续续的颤动,因此,本实现方式在多个时延神经网络后挂接挤压激励模块,从多个维度提取新冠肺炎咳嗽音频的特征信息。实践中,挤压激励模块可以包括第一线性层、第一激活函数、第二线性层和第二激活函数,其网络结构可以如图3中虚线所示。作为示例,第一线性层可以选择一个较小的隐藏节点数,以对音频信息进行降维,去除新冠咳嗽音和普通患者咳嗽音的通用信息。第二线性层可以用于对信息进行升维,其目的是提高整体网络的参数量以提高网络的建模能力和判别能力,增加对咳嗽音频建模的精确性。在本实现方式中,第二线性层可以采用sigmoid函数作为第二激活函数,以得到加权激励系数,加权激励函数与最后一个时延神经网络的输出相乘,以得到咳嗽音各个维度的音频信息。最后,将相乘结果与整个残差时延神经网络的输入组成残差网络,这种残差网络可以使得神经网络在对咳嗽音进行降维的同时也能更好的保证整体咳嗽声音的频谱信息。本实现方式在分析新冠肺炎患者咳嗽声特点的基础上构建残差时延神经网络,从而使构建的残差时延神经网络更加符合新冠肺炎患者咳嗽声的特点,使残差时延神经网络提取的信息更加准确,进而使音频判别模型的输出结果更加准确。
27.作为示例,实际使用中,第一激活函数可以为relu激活函数,第二激活函数可以为sigmoid函数。其中,relu激活函数为:
[0028][0029]
sigmoid函数为:
[0030]
[0031]
其中,sigmoid函数中s(x)的值在0
‑
1之间,且具有很好的对称性。所以,在音频判别模型中可以选择sigmoid函数作为分类器。
[0032]
网络中的tanh激活函数为:
[0033][0034]
网络中的batchnorm函数为:
[0035][0036]
其中,gamma和beta为可学习的参数向量。
[0037]
在一种实现方式中,上述音频判别模型可以是用于训练音频判别模型的设备通过以下方式训练得到的:
[0038]
首先,获取样本集。
[0039]
在本实现方式中,用于训练音频判别模型的设备可以获取样本集。这里,样本集中的样本可以包括正样本和负样本。其中,正样本可以包括新冠肺炎对应的咳嗽音频的特征向量和概率值1。负样本可以包括非新冠肺炎对应的咳嗽音频的特征向量和概率值0。
[0040]
然后,将样本的特征向量作为输入,将与输入的特征向量对应的概率值作为期望输出,训练得到音频判别模型。
[0041]
在本实现方式中,可以将样本的特征向量作为输入,输入到音频判别模型,得到该样本的特征向量的预测概率值,以输入的特征向量对应的概率值作为期望输出,利用机器学习方法训练音频判别模型。举例来说,可以首先利用预设的损失函数计算所得到的预测概率值与期望输出之间的差异。然后,可以基于计算所得的差异,调整音频判别模型的网络参数,并在满足预设的训练结束条件的情况下,结束训练。例如,这里预设的训练结束条件可以包括但不限于以下至少一项:训练时间超过预设时长;训练次数超过预设次数;计算所得的差异小于预设差异阈值等等。这里,可以采用各种实现方式基于预测概率值与期望输出之间的差异调整音频判别模型的网络参数。例如,可以采用bp(back propagation,反向传播)算法或者sgd(stochastic gradient descent,随机梯度下降)算法来调整音频判别模型的网络参数。
[0042]
本实现方式中,使用正样本和负样本两种样本进行模型训练,可以使训练得到的音频判别模型的输出更加准确。
[0043]
回到图1,如图1所示,该利用音频判别模型进行音频判别的方法,可以包括以下步骤:
[0044]
步骤101,从采集的音频中获取多帧待判别咳嗽音频。
[0045]
在本实施例中,用于执行利用音频判别模型进行音频判别的方法的设备,可以从音频采集设备(例如,麦克风)采集的音频中获取多帧待判别咳嗽音频。作为示例,可以使用各种方法对音频采集设备采集的音频进行识别,从中识别出那些音频帧为咳嗽声的音频帧,并将咳嗽声的音频帧作为待判别咳嗽音频。
[0046]
在一种实现方式中,上述步骤101可以具体如下进行:
[0047]
首先,对音频采集设备采集的音频进行预处理,得到处理后音频。举例来说,可以对音频采集设备采集的音频进行去噪、去静音等预处理,得到处理后音频。
[0048]
然后,使用预先训练的咳嗽声判别模型,确定处理后音频中是否包括咳嗽声音频。这里,上述咳嗽声判别模型可以用于从音频中判别哪些音频帧为咳嗽声的音频帧,作为示例,上述咳嗽声判别模型可以为二分类模型。
[0049]
最后,响应于确定处理后音频中包括咳嗽声音频,提取咳嗽声音频作为待判别咳嗽音频。通过本实现方式,可以从采集的音频中获取多帧待判别咳嗽音频,用于后续的处理。从而去除了音频中噪声、静音、非咳嗽音频等的影响,使后续的处理结果更加准确。
[0050]
步骤102,从各帧待判别咳嗽音频中提取特征向量。
[0051]
在本实施例中,对于步骤101中获取的多帧待判别咳嗽音频中的每一帧待判别咳嗽音频,可以从该帧待判别咳嗽音频中提取特征向量。这里,特征向量可以是与音频相关的各种特征向量。
[0052]
在一种实现方式中,上述步骤102可以具体如下进行:从各帧待判别咳嗽音频中提取梅尔频率倒谱系数(mel
‑
frequency cepstral coefficients,mfcc),作为特征向量。
[0053]
步骤103,利用至少一个第一时延神经网络,对多帧待判别咳嗽音频的特征向量进行信息提取,得到音频信息。
[0054]
在本实施例中,可以利用音频判别模型中的至少一个第一时延神经网络,对上述多帧待判别咳嗽音频的特征向量进行信息提取,得到音频信息。
[0055]
步骤104,利用至少一个残差时延神经网络,从多个维度提取音频信息的多维度信息。
[0056]
步骤105,利用至少一个第二时延神经网络,从多维度信息获得固定长度的音频特征。
[0057]
步骤106,将音频特征输入全连接层,得到待判别咳嗽音频属于新型冠状病毒肺炎的概率。
[0058]
在本实施例中,音频判别模型的全连接层输出的概率,可以是一个0
‑
1之间的数值,数值越大表示待判别咳嗽音频属于新冠肺炎的可能性越大。
[0059]
在一种实现方式中,上述利用音频判别模型进行音频判别的方法还可以包括图1中未示出的以下步骤:输出概率,以辅助用户判断待判别咳嗽音频的发声者是否为新型冠状病毒肺炎的患者。
[0060]
在本实现方式中,执行利用音频判别模型进行音频判别的方法的设备,还可以输出音频判别模型生成的概率,以供显示。以辅助用户判别上述待判别咳嗽音频的发声者是否为新冠肺炎患者。作为示例,上述用户可以是使用上述设备的用户,该用户可以与发声者是同一人,也可以与发声者是不同人。可以理解,上述概率用于辅助判断发声者是否为新冠肺炎患者,实践中,为了更准确的判断,还可以结合胸透、ct(computed tomography,电子计算机断层扫描)等的检查结果综合判断发声者是否为新冠肺炎患者。通过本实现方式,可以实现音频判别模型所生成概率的输出和显示,以供用户查看。
[0061]
本说明书的上述实施例提供的利用音频判别模型进行音频判别的方法,使用音频判别模型对待判别咳嗽音频进行判别,实现了根据待判别咳嗽音频自动生成该待判别咳嗽音频属于新冠肺炎的概率。此外,由于所使用的音频判别模型是基于新冠肺炎症状的咳嗽声特点构建的,因此,音频判别模型输出的概率更准确。
[0062]
根据另一方面的实施例,提供了一种利用音频判别模型进行音频判别的装置。上
述利用音频判别模型进行音频判别的装置可以部署在任何具有计算、处理能力的设备、平台或者设备集群中。
[0063]
图4示出了根据一个实施例的利用音频判别模型进行音频判别的装置的示意性框图。如图4所示,该利用音频判别模型进行音频判别的装置400,用于判别音频中的咳嗽音频属于新型冠状病毒肺炎的概率;上述装置400包括:获取模块401,配置为,从采集的音频中获取多帧待判别咳嗽音频;提取模块402,配置为,从各帧待判别咳嗽音频中提取特征向量;第一时延神经网络模块403,包括至少一个第一时延神经网络,配置为,接收上述提取模块402输出的特征向量,对上述多帧待判别咳嗽音频的特征向量进行信息提取,得到音频信息;残差时延神经网络模块404,包括至少一个残差时延神经网络,配置为,接收上述第一时延神经网络模块403输出的音频信息,从多个维度提取上述音频信息的多维度信息;第二时延神经网络模块405,包括至少一个第二时延神经网络,配置为,接收上述残差时延神经网络模块404输出的多维度信息,从上述多维度信息获得固定长度的音频特征;全连接层模块406,配置为,接收上述第二时延神经网络模块405输出的固定长度的音频特征,得到上述待判别咳嗽音频属于新型冠状病毒肺炎的概率。
[0064]
在本实施例的一些可选的实现方式中,上述至少一个残差时延神经网络中的各残差时延神经网络包括挤压激励模块和至少一个时延神经网络,其中,上述挤压激励模块包括第一线性层、第一激活函数、第二线性层和第二激活函数;以及上述至少一个残差时延神经网络中的各残差时延神经网络通过以下方式对输入信息进行处理:利用上述第一线性层,对上述至少一个时延神经网络提取的信息进行降维,以去除新型冠状病毒肺炎的咳嗽音和非新型冠状病毒肺炎的咳嗽音的通用信息;利用上述第二线性层,对上述第一激活函数的输出进行升维,以提升网络参数量;将上述第二激活函数的输出与该残差时延神经网络中最后一个时延神经网络的输出相乘,相乘结果与该残差时延神经网络的输入信息进行加权,将加权结果作为该残差时延神经网络的输出。
[0065]
在本实施例的一些可选的实现方式中,上述至少一个第一时延神经网络包括两个第一时延神经网络;上述至少一个第二时延神经网络包括两个第二时延神经网络;上述至少一个残差时延神经网络包括三个残差时延神经网络。
[0066]
在本实施例的一些可选的实现方式中,上述装置400还包括:输出模块(图中未示出),配置为,输出上述概率,以辅助用户判断上述待判别咳嗽音频的发声者是否为新型冠状病毒肺炎的患者。
[0067]
在本实施例的一些可选的实现方式中,上述音频判别模型是通过以下方式训练得到的:获取样本集,其中,上述样本集的样本包括正样本和负样本,正样本包括新冠肺炎对应的咳嗽音频的特征向量和概率值1,负样本包括非新冠肺炎对应的咳嗽音频的特征向量和概率值0;将样本的特征向量作为输入,将与输入的特征向量对应的概率值作为期望输出,训练得到音频判别模型。
[0068]
在本实施例的一些可选的实现方式中,上述获取模块401进一步配置为:对音频采集设备采集的音频进行预处理,得到处理后音频;使用预先训练的咳嗽声判别模型,确定上述处理后音频中是否包括咳嗽声音频;响应于确定上述处理后音频中包括咳嗽声音频,提取咳嗽声音频作为待判别咳嗽音频。
[0069]
在本实施例的一些可选的实现方式中,上述提取模块402进一步配置为:从待判别
咳嗽音频中提取梅尔频率倒谱系数,作为特征向量。
[0070]
本领域普通技术人员应该还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执轨道,取决于技术方案的特定应用和设计约束条件。本领域普通技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
[0071]
结合本文中所公开的实施例描述的方法或算法的步骤可以用硬件、处理器执轨道的软件模块,或者二者的结合来实施。软件模块可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、cd
‑
rom、或技术领域内所公知的任意其它形式的存储介质中。
[0072]
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。