1.本技术涉及信号处理装置、信号处理方法和程序,并且更具体地,涉及允许更容易的声源分离的信号处理装置、信号处理方法和程序。
背景技术:
2.例如,存在期望分别处理多个说话者的同时话语的许多情况,诸如多个说话者的语音识别(例如,参见专利文献1)、字幕和语音澄清。
3.作为用于将包括多个说话者的话语的混合语音的声学信号分离成每个说话者的声学信号的声源分离技术,常规已经提出了使用方向信息的技术(例如,参见专利文献2)和假设声源的独立性的技术。
4.然而,这些技术在用单个麦克风实现以及应对来自多个声源的声音从同一方向到达的情况方面存在困难。
5.因此,作为用于分离在这种情况下同时发出的语音的技术,已知深度聚类(例如,参见非专利文献1)和置换不变训练(例如,参见非专利文献2)。
6.引用列表
7.专利文献
8.专利文献1:日本未审查专利申请公开(pct申请的翻译)第2017
‑
515140号。
9.专利文献2:日本专利申请公开第2010
‑
112995号。
10.非专利文献
11.非专利文献1:j.r.hershey,z.chen,and j.le roux,“deep clustering:discriminative embeddings for segmentation and separation”。
12.非专利文献2:m.kolbaek,d.yu,z.
‑
h.tan,and j.jensen,“multitalker speech separation with utterance
‑
level permutation invariant training of deep recurrent neural networks,”ieee/acm transactions on audio,speech,and language processing,vol.25,no.10,pp.1901
‑
1913,2017。
技术实现要素:
13.本发明要解决的问题
14.然而,在上述技术中,不容易从说话者的数量未知的混合语音中分离每个说话者的话语。
15.例如,在深度聚类和置换不变训练中,假设同时说话的说话者的数量是已知的。
16.然而,通常,存在说话者的数量未知的许多情况。在这种情况下,这些技术另外需要用于估计说话者的数量的模型,并且有必要通过例如准备用于分离说话者的每个说话者的话语的声源分离模型(分离算法)来在算法之间切换。
17.因此,当这些技术用于将说话者的数量未知的混合语音分离成每个说话者的话语时,开发时间增加,并且用于保留声源分离模型的存储量增加。此外,在没有正确执行说话
者的数量的估计的情况下,性能显著恶化。
18.本技术是鉴于这种情况而提出的,并且允许更容易的声源分离。
19.问题的解决方案
20.本技术的一个方面提供信号处理装置,包括:声源分离单元,通过使用预先学习的预定声源分离模型对输入声学信号递归地执行声源分离以从包括预定声源的用于学习的声学信号中分离预定声源。
21.本技术的一个方面提供信号处理方法或程序,包括以下步骤:通过使用预先学习的预定声源分离模型对输入声学信号递归地执行声源分离以从包括预定声源的用于学习的声学信号中分离预定声源。
22.在本技术的一个方面,通过使用预先学习的预定声源分离模型对输入声学信号递归地执行声源分离以从包括预定声源的用于学习的声学信号中分离预定声源。
附图说明
23.图1是示出递归声源分离的示图。
24.图2是示出信号处理装置的配置示例的示图。
25.图3是示出声源分离处理的流程图。
26.图4是示出递归声源分离的示图。
27.图5是示出信号处理装置的配置示例的示图。
28.图6是示出声源分离处理的流程图。
29.图7是示出计算机的配置示例的示图。
具体实施方式
30.下面将参考附图描述应用本技术的实施例。
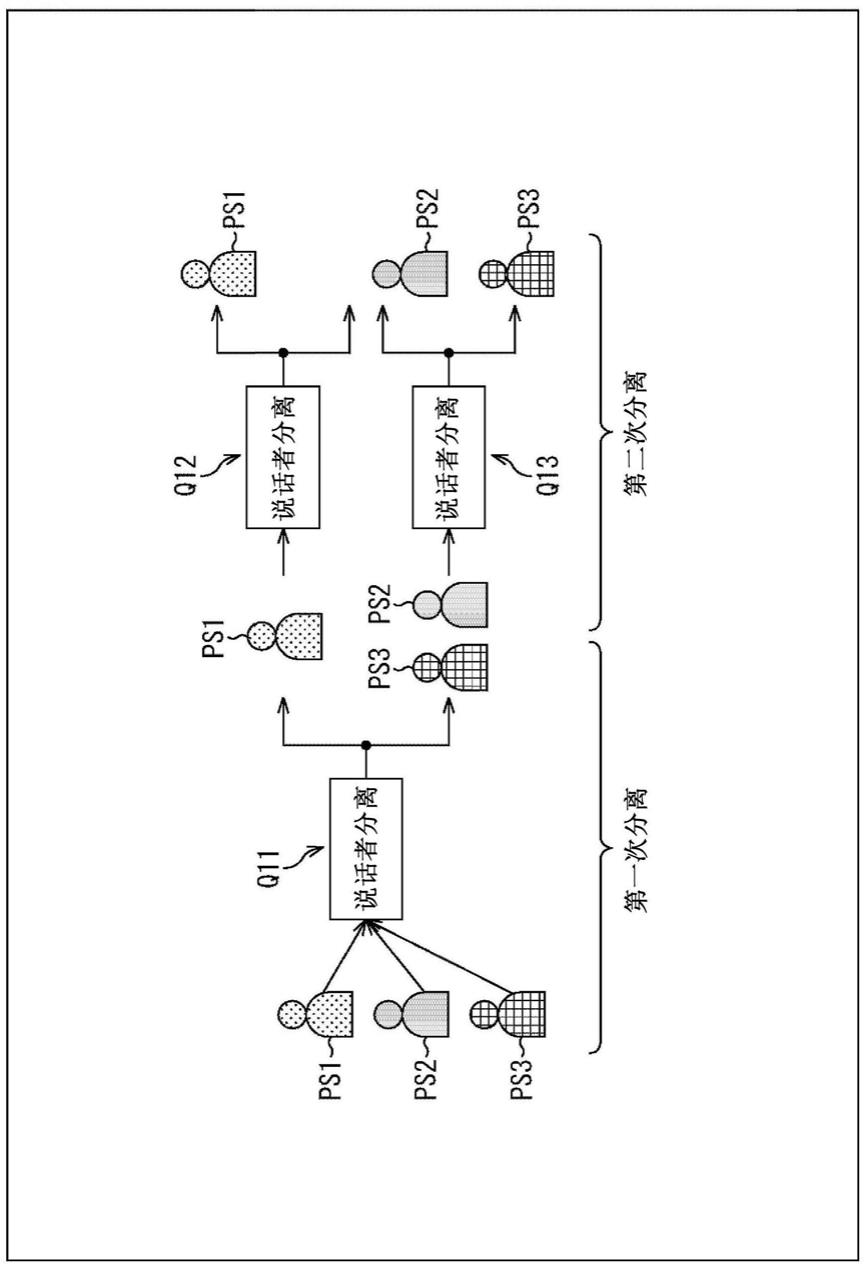
31.<第一实施例>
32.<本技术>
33.首先,将描述本技术的概要。在此处,将描述通过使用单个声源分离模型从通过用一个或多个麦克风收集由多个说话者在同时或在不同定时发出的混合语音而获得的输入声学信号分离每个说话者的话语(语音)的示例。
34.具体地,在此处,包括在基于输入声学信号的混合语音中的说话者的数量是未知的。本技术通过使用单个声源分离模型对输入声学信号递归地执行声源分离,使得可以更容易地从输入声学信号中分离未指定的未知数量的说话者中的每个说话者的话语(语音)。
35.注意,在此处描述的示例中,声源的声音是说话者的话语,但是声音不限于此,并且可以是任何声音,诸如动物叫声或乐器声音。
36.在本技术中使用的声源分离模型是被学习在说话者到说话者的基础上分离输入语音的诸如神经网络的模型。即,已经预先学习声源分离模型以从包括作为声源的说话者的话语的混合语音的用于学习的声学信号中分离说话者的话语的声学信号。
37.声源分离模型根据预定声源分离算法使用算术系数来执行计算以将输入声学信号分离成每个声源(说话者)的声学信号(在下文中,也称为分离信号),并且由声源分离算法和算术系数实现。
38.在本技术中,使用声源分离模型对说话者的数量未知或已知的混合语音的输入声学信号执行声源分离。
39.然后,基于所获得的分离信号,确定是否满足预定结束条件。使用同一声源分离模型对分离信号递归地执行声源分离,直到确定满足结束条件,并且最终获得每个声源(说话者)的分离信号。
40.在此处,作为具体示例,将描述两个说话者分离模型用作声源分离模型的情况,该两个说话者分离模型被学习以将包括作为声源的两个说话者的话语的用于学习的声学信号分离成包括一个说话者的话语的分离信号和包括另一说话者的话语的分离信号。
41.可以通过使用诸如深度聚类或置换不变训练的学习技术进行学习来获得这种声源分离模型。
42.在两个说话者分离模型中,当输入两个说话者的混合语音的输入声学信号时,期望输出每个说话者的话语(语音)的分离信号作为声源分离结果。
43.此外,在两个说话者分离模型中,当输入一个说话者的语音的输入声学信号时,期望输出一个说话者的话语的分离信号和无声分离信号作为声源分离结果。
44.另一方面,在输入两个说话者分离模型的情况下,即,在输入声学信号是三个或更多个说话者的混合语音的信号的情况下,这种混合语音是在学习两个说话者分离模型时没有出现的输入。
45.在这种情况下,响应于三个说话者的混合语音的输入,执行声源分离,使得两个说话者的话语(语音)包括在一个分离信号中,例如,如图1所示。
46.在图1所示的示例中,基于输入声学信号的混合语音包括说话者ps1到说话者ps3的三个说话者的话语。
47.作为声源分离的结果,即,如箭头q11所示,使用两个说话者分离模型对这种输入声学信号进行说话者分离,混合语音分离,使得一个分离信号仅包括说话者ps1的话语,而另一分离信号仅包括说话者ps2和说话者ps3的话语。
48.此外,例如,如箭头q12所示,作为使用两个说话者分离模型对仅包括说话者ps1的话语的分离信号进行进一步声源分离的结果,语音分离,使得一个分离信号仅包括说话者ps1的话语,而另一分离信号是无声信号。
49.以类似的方式,例如,如箭头q13所示,作为使用两个说话者分离模型对仅包括说话者ps2和说话者ps3的话语的分离信号进行进一步声源分离的结果,混合语音分离,使得一个分离信号仅包括说话者ps2的话语,而另一分离信号仅包括说话者ps3的话语。
50.以这种方式,当通过使用相同的两个说话者分离模型对输入声学信号递归地执行声源分离时,获得分离信号,每个分离信号仅包括说话者ps1到说话者ps3中的对应一个说话者。
51.在该示例中,当执行由箭头q11指示的第一次声源分离时,所获得的分离信号最多仅包括两个说话者的话语。在大多数情况下,输入声学信号没有被分离成三个说话者的话语的分离信号和无声分离信号。
52.因此,当已经执行第一次声源分离时,所有分离信号是可以通过使用两个说话者分离模型求解的语音,即,可以从两个说话者分离模型获得每个说话者的分离信号的信号。然后,如箭头q12和箭头q13所示,对这样的分离信号执行递归声源分离,从而可以获得每个
说话者的分离信号。
53.注意,即使在输入声学信号是四个或更多个说话者的话语的混合语音的情况下,也可以增加递归地执行的声源分离的次数,使得可以最终获得每个说话者的分离信号。
54.此外,在递归地执行声源分离以将输入声学信号分离成每个说话者的分离信号(以提取分离信号)的情况下,当输入声学信号的混合语音的说话者的数量未知(不知道)时,需要用于结束递归声源分离的结束条件。
55.该结束条件是当通过声源分离获得的分离信号仅包括一个说话者的话语时满足的条件,换句话说,当分离信号不包括两个或更多个说话者的话语时满足的条件。
56.在此处,作为示例,在通过声源分离获得的一个分离信号是无声信号的情况下,更详细地,在一个分离信号的平均电平(能量)等于或小于预定阈值的情况下,假设满足结束条件,即,获得每个说话者的分离信号。
57.根据如上所述的本技术,即使在输入声学信号的说话者的数量未知的情况下,也可以容易地执行声源分离,而不需要用于估计说话者的数量的模型、用于每个说话者的数量的声源分离模型、指示声源方向的方向信息等,并且可以获得每个声源(说话者)的分离信号。
58.因此,本技术显著抑制了用于开发声源分离模型等的时间的增加以及用于保持声源分离模型的存储量的增加。
59.即,在本技术中,无论输入声学信号的说话者的数量如何,可以通过一个声源分离模型获得每个说话者的分离信号,并且可以简化系统、减少必要的存储量、集成声源分离模型的开发等。
60.此外,在本技术中,递归地执行声源分离,使得可以简化由每次声源分离要解决的问题(任务),并且因此可以提高分离性能。
61.注意,此处已经描述了使用两个说话者分离模型作为声源分离模型的示例。然而,这不是限制性的,并且可以通过将输入声学信号分离成三个或更多个说话者中的每个说话者的分离信号的多个说话者的说话者分离模型(诸如,三个说话者分离模型)来执行递归声源分离。
62.例如,三个说话者分离模型是被学习以将包括作为声源的三个说话者的话语的用于学习的声学信号分离成三个分离信号的说话者分离模型,三个分离信号中的每一个分离信号包括三个说话者的话语中的对应一个说话者的话语,即,三个说话者中的每一个说话者的分离信号。
63.<信号处理装置的配置示例>
64.接下来,将描述应用本技术的信号处理装置。
65.例如,应用本技术的信号处理装置被配置为如图2所示。
66.图2所示的信号处理装置11具有声源分离单元21和结束确定单元22。
67.声源分离单元21从外部接收输入声学信号。此外,声源分离单元21保留通过学习预先获得的声源分离模型。
68.注意,在该实施例中,将在假设输入声学信号是说话者的数量(尤其是同时发出话语的说话者的数量)未知的混合语音的声学信号的情况下给出描述。此外,在此处,由声源分离单元21保留的声源分离模型是两个说话者分离模型。
69.根据从结束确定单元22提供的结束确定的结果,声源分离单元21基于保留的声源分离模型对所提供的输入声学信号递归地执行声源分离以获得分离信号,并且将所得分离信号提供给结束确定单元22。
70.结束确定单元22基于从声源分离单元21提供的分离信号执行结束确定以确定是否结束递归声源分离,即是否满足结束条件,并且将确定结果提供给声源分离单元21。
71.此外,如果确定满足结束条件,则结束确定单元22将通过声源分离获得的分离信号作为每个说话者的话语的声学信号输出到后级。
72.<声源分离处理的描述>
73.接下来,将参考图3中的流程图描述由信号处理装置11执行的声源分离处理。
74.在步骤s11中,声源分离单元21基于保留的声源分离模型对所提供的输入声学信号执行声源分离以获得分离信号,并且将所得分离信号提供给结束确定单元22。
75.具体地,声源分离单元21基于构成声源分离模型的算术系数和输入声学信号,根据对应于声源分离模型的声源分离算法执行算术处理,并且获得作为声源分离模型的输出的两个分离信号。
76.在步骤s12中,基于从声源分离单元21提供的分离信号,结束确定单元22对通过一次声源分离获得的两个分离信号的每一对(组)执行结束确定,并且确定所有对是否都满足结束条件。
77.具体地,例如,对于一对,如果构成该对的两个分离信号中的一个分离信号的平均电平等于或小于预定阈值,则结束确定单元22确定该对满足结束条件。
78.如果在步骤s12中确定没有一对满足结束条件,则结束确定单元22将指示不满足结束条件的对的信息作为结束确定的结果提供给声源分离单元21,并且然后处理进行到步骤s13。
79.在步骤s13中,基于从结束确定单元22提供的结束确定的结果,声源分离单元21使用声源分离模型对构成不满足结束条件的对的每个分离信号执行声源分离以获得分离信号,并且将所得分离信号提供给结束确定单元22。
80.例如,在步骤s13中,与步骤s11中使用的声源分离模型相同的声源分离模型用于声源分离。
81.注意,可以使用彼此不同的多个声源分离模型递归地执行声源分离。例如,三个说话者分离模型可以用于步骤s11中的声源分离,并且两个说话者分离模型可以用于步骤s13中的声源分离。
82.在步骤s13的处理中执行递归声源分离之后,处理返回到步骤s12,并且重复上述处理,直到确定所有对都满足结束条件。
83.例如,在图1所示的示例中,由于在箭头q12所示的声源分离中一个分离信号是无声信号,因此作为箭头q12所示的声源分离的结果获得的一对分离信号满足结束条件。
84.另一方面,由于不能通过图1中箭头q13所示的声源分离获得无声分离信号,因此不确定满足结束条件,并且在步骤s13中对通过箭头q13所示的声源分离获得的两个分离信号中的每一个分离信号执行递归声源分离。
85.此外,如果在图3的步骤s12中确定所有对都满足结束条件,则输入声学信号已经被分离成每个说话者的分离信号,并且因此处理进行到步骤s14。
86.在步骤s14中,结束确定单元22将通过已经执行的声源分离获得的每个说话者的分离信号输出到后级,并且声源分离处理结束。
87.如上所述,信号处理装置11对输入声学信号递归地执行声源分离,直到满足结束条件,并且获得每个说话者的分离信号。以这种方式,可以更容易地且以足够的分离性能执行声源分离。
88.<第二实施例>
89.<根据分离结果的合成>
90.同时,在通过使用说话者分离模型作为声源分离模型对输入声学信号递归地执行声源分离的情况下,某个说话者的话语可以被分散成不同的分离结果,即不同的分离信号。
91.具体地,例如,如图1所示,假设通过使用两个说话者分离模型对包括说话者ps1到说话者ps3的话语的混合语音的输入声学信号执行声源分离的情况。
92.在这种情况下,例如,如图1的箭头q11所示的声源分离的结果,某个说话者的话语可以不仅出现在一个分离信号中,而是如图4所示,可以以分散的方式出现在两个分离信号中。注意,在图4中,相同的参考数字被赋予对应于图1的情况的部分,并且将适当地省略其描述。
93.在图4所示的示例中,通过使用两个说话者分离模型对包括说话者ps1到说话者ps3的话语的混合语音的输入声学信号递归地执行声源分离(说话者分离)。
94.在此处,首先,如箭头q21所示,对输入声学信号执行声源分离。
95.因此,获得包括说话者ps1的话语和说话者ps2的话语的一部分的分离信号以及包括说话者ps3的话语和说话者ps2的话语的一部分的分离信号。
96.即,尽管说话者ps1和说话者ps3的话语仅出现在一个分离信号中,但是说话者ps2的话语被分散成两个分离信号。
97.在此处,使用如箭头q22所示的两个说话者分离模型对作为箭头q21所示的声源分离的结果而获得的包括说话者ps1的话语和说话者ps2的话语的一部分的分离信号执行递归声源分离,从而获得每个说话者的分离信号。
98.即,在该示例中,作为箭头q22所示的声源分离的结果,获得仅包括说话者ps1的话语的分离信号和仅包括说话者ps2的话语的一部分的分离信号。
99.以类似的方式,使用如箭头q23所示的两个说话者分离模型对作为箭头q21所示的声源分离的结果而获得的包括说话者ps3的话语和说话者ps2的话语的一部分的分离信号执行递归声源分离,从而获得每个说话者的分离信号。
100.即,在该示例中,作为箭头q23所示的声源分离的结果,获得仅包括说话者ps3的话语的分离信号和仅包括说话者ps2的话语的一部分的分离信号。
101.即使在这样的示例中,所得分离信号中的每一个仅包括一个说话者的话语。然而,在此处,说话者ps2的话语被分散成两个分离信号。
102.因此,两个或多个分离语音(即分散成多个分离信号的同一说话者的分离语音(话语))可以组合成说话者的一个合成话语。
103.在这种情况下,可以使用输入分离信号并且输出说话者识别结果的说话者识别模型。
104.具体地,例如,预先学习识别任意多个说话者的神经网络等作为说话者识别模型。
在此处,在学习说话者识别模型时说话者的数量较大的情况下,说话者不必包括作为声源分离的实际目标的说话者。
105.以这种方式准备说话者识别模型,并且然后说话者识别模型用于对通过声源分离获得的分离信号(即对应于分离信号的说话者)进行聚类。
106.在聚类时,每个分离信号被输入到说话者识别模型,并且执行说话者识别。
107.此时,获得说话者识别模型的输出(即说话者识别的结果)或者说话者识别模型的中间层的激活(输出)(即用于获得说话者识别结果的算术处理的中间的计算结果)作为表示对应于输入分离信号的说话者的特征值(说话者嵌入)。
108.注意,在计算表示说话者的特征值时,在计算中可以忽略分离信号的无声部分。
109.当已经获得每个分离信号(分离语音)的特征值时,获得特征值彼此之间的距离,即特征值之间的距离。特征值之间的距离等于或小于阈值的分离信号被确定为同一说话者的分离信号。
110.此外,作为聚类的结果,从被确定为同一说话者的多个分离信号中合成并获得一个分离信号作为说话者的最终分离信号。
111.因此,例如,在图4的示例中,假设仅包括由箭头q22所示的声源分离获得的说话者ps2的话语的一部分的分离信号和仅包括由箭头q23所示的声源分离获得的说话者ps2的话语的一部分的分离信号属于同一说话者。
112.然后,将分离信号相加,使得合成一个分离信号,并且输出所得信号作为包括说话者ps2的话语的最终分离信号。
113.<信号处理装置的配置示例>
114.在如上所述执行通过声源分离获得的分离信号的聚类的情况下,信号处理装置例如被配置为如图5所示。注意,在图5中,相同的参考数字被赋予对应于图2的情况的部分,并且将适当地省略其描述。
115.图5所示的信号处理装置51具有声源分离单元21、结束确定单元22和同一说话者确定单元61。
116.信号处理装置51的配置与信号处理装置11的配置的不同之处在于,新设置了同一说话者确定单元61,但是在其他方面与信号处理装置11的配置相同。
117.同一说话者确定单元61执行确定通过递归声源分离获得的多个分离信号是否是同一说话者的信号的同一说话者确定,并且然后根据确定的结果从同一说话者的多个分离信号中合成并生成说话者的最终分离信号。
118.更具体地,同一说话者确定单元61保留通过学习预先获得的说话者识别模型,并且基于保留的说话者识别模型和从结束确定单元22提供的每个说话者的分离信号来执行聚类。即,同一说话者确定单元61通过执行聚类来执行同一说话者确定。
119.此外,同一说话者确定单元61执行聚类以从被确定为属于同一说话者的分离信号中合成说话者的最终分离信号,并且将最终获得的每个说话者的分离信号输出到后级。
120.<声源分离处理的描述>
121.接下来,将参考图6中的流程图描述由信号处理装置51执行的声源分离处理。
122.注意,步骤s41至步骤s43的处理类似于图3中的步骤s11至步骤s13的处理,并且将省略其描述。
123.当在步骤s41到步骤s43中执行递归声源分离并且获得每个说话者的分离信号时,分离信号从结束确定单元22被提供给同一说话者确定单元61,并且然后处理进行到步骤s44。即,如果在步骤s42中确定所有对都满足结束条件,则处理进行到步骤s44。
124.在步骤s44中,同一说话者确定单元61基于保留的说话者识别模型和从结束确定单元22提供的分离信号,针对每个分离信号计算表示说话者的特征值。
125.即,同一说话者确定单元61通过以分离信号作为输入执行使用说话者识别模型的计算,针对每个分离信号计算表示说话者的特征值。
126.在步骤s45中,同一说话者确定单元61基于在步骤s44中获得的特征值来确定是否存在同一说话者的分离信号。即,执行同一说话者确定。
127.例如,针对所有分离信号中的任何两个分离信号,同一说话者确定单元61获得两个分离信号的特征值之间的距离。如果该距离等于或小于预定阈值,则确定两个分离信号是同一说话者的信号(信号)。
128.针对所有分离信号,同一说话者确定单元61针对两个分离信号的所有可能的组合确定这两个分离信号是否属于同一说话者。
129.然后,如果针对所有组合获得指示不属于同一说话者的确定结果,则同一说话者确定单元61在步骤s45中确定不存在同一说话者的分离信号。
130.同一说话者确定单元61执行上述步骤s44和步骤s45的处理作为聚类处理。
131.如果在步骤s45中确定存在同一说话者的分离信号,则在步骤s46中,同一说话者确定单元61从被确定为属于同一说话者的多个分离信号中合成说话者的最终分离信号。
132.在从同一说话者的分离信号中合成并获得每个说话者的最终分离信号之后,处理进行到步骤s47。
133.另一方面,如果在步骤s45中确定不存在同一说话者的分离信号,则已经获得了每个说话者的分离信号,因此跳过步骤s46的处理,并且处理进行到步骤s47。
134.如果在步骤s45中确定不存在同一说话者的分离信号,或者如果执行步骤s46的处理,则在步骤s47中,同一说话者确定单元61将最终获得的每个说话者的分离信号输出到后级,并且声源分离处理结束。
135.如上所述,信号处理装置51对输入声学信号递归地执行声源分离,直到满足结束条件,并且执行分离信号的聚类以从同一说话者的分离信号执行合成,并且获得每个说话者的最终分离信号。
136.以这种方式,可以更容易地且以足够的分离性能执行声源分离。具体地,信号处理装置51从同一说话者的分离信号执行合成,并且与信号处理装置11的情况相比,这进一步提高分离性能。
137.<第三实施例>
138.<一对多说话者分离模式>
139.同时,在上面,已经描述了通过使用被学习以将包括m(其中,m≥2)个说话者的话语的混合语音的声学信号分离成每个说话者的m个分离信号的m个说话者分离模型来执行声源分离的示例。
140.具体地,在声源分离时,预定说话者的话语可能以分散的方式出现在多个分离信号中。因此,在第二实施例中,已经描述了执行聚类并且适当地合成分离信号的示例。
141.然而,不仅这样的说话者分离模型,而且其他说话者分离模型(诸如通过对不确定数量的说话者执行学习而获得的说话者分离模型(在下文中,也称为一对多说话者分离模型))也可以用于声源分离。
142.一对多说话者分离模型是被学习以将用于学习任何未知(不确定)数量的说话者的混合语音的声学信号分离成仅包括预定一个说话者的话语(语音)的分离信号和包括混合语音中包括的多个说话者中除了预定一个说话者之外的剩余说话者的话语的分离信号的说话者分离模型(诸如神经网络)。
143.在此处,使用一对多说话者分离模型的声源分离的分离结果(即一对多说话者分离模型的输出)也被称为头部。
144.具体地,在此处,输出包括一个说话者的话语的分离信号的一侧也被称为头部1,并且输出包括其他剩余说话者的话语的分离信号的一侧也被称为头部2。此外,在没有特别必要区分头部1与头部2的情况下,头部1和头部2被简单地称为头部。
145.在学习一对多说话者分离模型时,执行学习,使得在随机改变用于学习的声学信号的说话者的数量m的同时,通过使用用于学习说话者的数量m的声学信号来使损失函数l最小化。
146.此时,说话者的数量m被设置为等于或小于说话者的最大数量m。此外,学习一对多说话者分离模型,使得仅包括用于学习的声学信号的混合语音中包括的m个说话者中损失最小的一个说话者的话语的分离信号是头部1的输出,并且包括剩余(m
‑
1)个说话者的话语的分离信号始终是头部2的输出。
147.此外,学习一对多说话者分离模型时的损失函数l例如由以下公式(1)表示。
148.[数学1]
[0149][0150]
注意,在公式(1)中,j是指示用于学习的声学信号(即,用于学习的混合语音)的索引,并且i是指示包括在第j个混合语音中的话语的说话者的索引。
[0151]
此外,在公式(1)中,l
i1j
表示当对第j个混合语音的用于学习的声学信号x
j
执行声源分离时头部1的输出s
’1(x
j
)与第i个说话者的话语的声学信号s
ij
进行比较时的损失函数。损失函数l
i1j
可以例如由以下公式(2)所示的平方误差来定义。
[0152]
[数学2]
[0153][0154]
此外,公式(1)中的l
i2j
表示当对第j个混合语音的用于学习的声学信号x
j
执行声源分离时头部2的输出s
’2(x
j
)与除了第i个说话者之外的剩余说话者k的声学信号s
kj
的和进行比较时的损失函数。损失函数l
i2j
可以例如由以下公式(3)所示的平方误差来定义。
[0155]
[数学3]
[0156][0157]
在通过如上所述学习获得的一对多说话者分离模型中,期望始终获得仅一个说话者的话语的分离信号作为头部1的输出,并且获得剩余说话者的话语的分离信号作为头部2
的输出。
[0158]
因此,例如,以与图1所示的示例类似的方式,可以期望仅通过使用一对多说话者分离模型对输入声学信号递归地执行声源分离来顺序分离仅包括每个说话者的话语的分离信号。
[0159]
在以这种方式使用一对多说话者分离模型的情况下,例如,信号处理装置11的声源分离单元21保留通过学习预先获得的一对多说话者分离模型作为声源分离模型。然后,信号处理装置11执行参考图3描述的声源分离处理以获得每个说话者的分离信号。
[0160]
然而,在这种情况下,在步骤s11或步骤s13中,声源分离单元21基于一对多说话者分离模型执行声源分离。此时,由于头部1的输出是一个说话者的话语的分离信号,因此使用一对多说话者分离模型对头部2的输出(分离信号)递归地执行声源分离。
[0161]
此外,在步骤s12中,在最近执行的声源分离的头部2的输出(分离信号)的平均电平等于或小于预定阈值的情况下,确定满足结束条件,并且处理进行到步骤s14。
[0162]
注意,此处已经描述了使用一对多说话者分离模型的示例,在该一对多说话者分离模型中,通过使用一个输入声学信号作为输入获得两个头部,即头部1和头部2的两个输出。
[0163]
然而,这不是限制性的。例如,可以通过使用可以获得三个头部的输出的一对多说话者分离模型来执行声源分离。
[0164]
在这种情况下,例如,执行学习,使得在头部1至头部3中,头部1和头部2的输出是分离信号,每个分离信号仅包括一个说话者的话语,并且头部3的输出是包括其他剩余说话者的话语的分离信号。
[0165]
<第四实施例>
[0166]
<一对多说话者分离模型和聚类的组合>
[0167]
此外,即使在一对多说话者分离模型用作声源分离模型的情况下,也不一定完全分离声源,即每个说话者的话语。即,例如,应该输出到头部1的说话者的话语可能稍微泄漏到头部2的输出中。
[0168]
因此,在这种情况下,如参考图4所述,同一说话者的话语被分散在通过递归声源分离获得的多个分离信号中。然而,在这种情况下,包括在一个分离信号中的说话者的话语是稍微泄漏的分量,并且具有比包括在另一分离信号中的说话者的话语的音量低得多的音量。
[0169]
因此,即使在一对多说话者分离模型用作声源分离模型的情况下,也可以以与第二实施例类似的方式执行聚类。
[0170]
在这种情况下,例如,信号处理装置51的声源分离单元21保留通过学习预先获得的一对多说话者分离模型作为声源分离模型。
[0171]
然后,信号处理装置51执行参考图6描述的声源分离处理以获得每个说话者的分离信号。
[0172]
然而,在这种情况下,与在第三实施例的情况一样,在步骤s41和步骤s43中,声源分离单元21基于一对多说话者分离模型执行声源分离。
[0173]
此外,在步骤s44中,计算上述说话者识别模型等的输出作为表示说话者的特征值,并且如果两个分离信号的特征值之间的距离等于或小于阈值,则确定两个分离信号属
于同一说话者。
[0174]
另外,例如,在获得分离信号的时间能量变化作为表示说话者的特征值,并且两个分离信号的特征值之间的相关性(即分离信号的能量变化之间的相关性)等于或大于阈值的情况下,这两个分离信号可以被确定为属于同一说话者。
[0175]
<其他修改示例1>
[0176]
<单个说话者确定模式的使用>
[0177]
同时,在上述每个实施例中,已经描述了如果通过声源分离获得的分离信号的平均电平(能量)变得足够小,即,如果平均电平变得等于或小于阈值,则确定满足递归声源分离的结束条件的示例。
[0178]
在这种情况下,当对仅包括单个说话者的话语的分离信号执行声源分离时,获得无声分离信号,并且确定满足结束条件。
[0179]
因此,尽管在获得仅包括单个说话者的话语的分离信号时首先获得每个说话者的分离信号,但是声源分离需要再次执行,并且因此声源分离处理的次数相应地增加。例如,这种情况对于处理时间有限的应用等不是优选的。
[0180]
因此,可以通过使用单个说话者确定模型来执行结束确定,该单个说话者确定模型是接收分离信号作为输入并确定分离信号是仅包括单个说话者的话语的声学信号还是包括多个说话者的话语的混合语音的声学信号的声学模型。
[0181]
换句话说,单个说话者确定模型是用于确定包括在输入分离信号中的话语的说话者的数量是否为1的声学模型。
[0182]
在这样的示例中,例如,通过学习预先获得的单个说话者确定模型保留在信号处理装置11或信号处理装置51的结束确定单元22中。
[0183]
然后,例如,在图3的步骤s12或图6的步骤s42中,结束确定单元22基于保留的单个说话者确定模型和通过声源分离获得的分离信号来执行计算,并且确定包括在分离信号中的话语的说话者的数量是否为1。换句话说,确定分离信号是否仅包括单个说话者的话语。
[0184]
然后,如果所获得的确定结果指示包括在所有分离信号中的话语的说话者的数量是1,即,分离信号仅包括单个说话者的话语,则结束确定单元22确定满足结束条件。
[0185]
在使用这样的单个说话者确定模型的确定中,与使用用于估计包括在分离信号中的话语的说话者的数量的说话者数量估计模型相比,任务被简化。因此,具有可以以较小的模型规模获得更高性能的声学模型(单个说话者确定模型)的优点。即,与使用说话者数量估计模型的情况相比,可以更容易地执行声源分离。
[0186]
如上所述,通过使用单个说话者确定模型来确定是否满足结束条件,可以减少参考图3和图6描述的声源分离处理的整体处理量(处理次数)和处理时间。
[0187]
此外,例如,在使用单个说话者确定模型等来执行结束确定的情况下,在参考图3和图6描述的声源分离处理中,也可以首先执行结束确定,即,是否满足结束条件,并且然后根据确定的结果执行递归声源分离。
[0188]
在这种情况下,例如,当单个说话者确定模型用于结束确定时,通过使用单个说话者确定模型对被确定为不是仅包括单个说话者的话语的分离信号的分离信号执行递归声源分离。
[0189]
另外,声源分离单元21可以使用用于确定说话者的粗略数量的说话者数量确定模
型来选择用于递归声源分离的声源分离模型。
[0190]
具体地,例如,假设声源分离单元21保留用于确定输入声学信号是包括两个或更少个说话者的话语的信号还是包括三个或更多个说话者的话语的信号的说话者数量确定模型、两个说话者分离模型和三个说话者分离模型的情况。
[0191]
在这种情况下,声源分离单元21通过输入声学信号或通过声源分离获得的分离信号使用说话者数量确定模型来确定说话者的数量,并且选择两个说话者分离模型或三个说话者分离模型作为用于声源分离的声源分离模型。
[0192]
即,例如,针对被确定为包括三个或更多个说话者的话语的信号的输入声学信号或分离信号,声源分离单元21使用三个说话者分离模型来执行声源分离。
[0193]
另一方面,针对被确定为包括两个或更少个说话者的话语的信号的输入声学信号或分离信号,声源分离单元21使用两个说话者分离模型来执行声源分离。
[0194]
以这种方式,可以选择性地将适当的声源分离模型用于声源分离。
[0195]
<其他修改示例2>
[0196]
<语言信息的使用>
[0197]
此外,在第二实施例或第四实施例中,可以基于多个分离信号的语言信息来执行同一说话者确定。具体地,在此处,将描述指示基于分离信号的语音(话语)的内容的文本信息用作语言信息的示例。
[0198]
在这种情况下,例如,信号处理装置51的同一说话者确定单元61对从结束确定单元22提供的每个说话者的分离信号执行语音识别处理,并且将每个说话者的分离信号的语音转换成文本。即,通过语音识别处理生成指示基于分离信号的话语的内容的文本信息。
[0199]
然后,在由任意两个或更多个分离信号的文本信息指示的文本(即话语的内容)被合并(集成)并且合并的文本形成句子的情况下,同一说话者确定单元61确定分离信号属于同一说话者。
[0200]
具体地,例如,在由文本信息指示的两个分离信号中的每一个分离信号的话语在时间和内容上相同的情况下,这两个分离信号被假设为属于同一说话者。
[0201]
此外,例如,在由两个分离信号的文本信息指示的话语在时间上不同,但是这些话语在被集成到一个话语中时形成有意义的句子的情况下,这两个分离信号被假设为属于同一说话者。
[0202]
以这种方式,使用诸如文本信息的语言信息提高了确定同一说话者的精度,并且因此可以提高分离性能。
[0203]
<其他修改示例3>
[0204]
<同一说话者确定模型的使用>
[0205]
此外,在第二实施例或第四实施例中,可以基于同一说话者确定模型来执行同一说话者确定,该同一说话者确定模型用于确定任何两个分离信号中的每一个分离信号是否包括同一说话者的话语,即,两个分离信号是否是同一说话者的信号。
[0206]
在此处,同一说话者确定模型是输入两个分离信号并且输出关于包括在每个分离信号中的话语的说话者是相同还是不同的确定结果的声学模型。
[0207]
在这种情况下,例如,信号处理装置51的同一说话者确定单元61保留通过学习预先获得的同一说话者确定模型。
[0208]
基于保留的同一说话者确定模型和从结束确定单元22提供的每个说话者的分离信号,同一说话者确定单元61针对所有可能的组合确定包括在两个分离信号的每一个分离信号中的话语的说话者是否相同。
[0209]
在使用这样的同一说话者确定模型的同一说话者确定中,与上述说话者识别模型的情况相比,任务被简化。因此,具有可以以较小的模型规模获得更高性能的声学模型(同一说话者确定模型)的优点。
[0210]
注意,在确定同一说话者时,可以通过组合多个可选方法(诸如上述使用特征值之间的距离的方法、使用语言信息的方法和使用同一说话者确定模型的方法)来指定同一说话者的分离信号。
[0211]
<计算机的配置示例>
[0212]
同时,上述一系列处理不仅可以由硬件执行,还可以由软件执行。在一系列处理由软件执行的情况下,构成软件的程序安装在计算机上。在此处,例如,计算机包括并入专用硬件中的计算机或者能够用安装有各种程序来执行各种功能的通用个人计算机。
[0213]
图7是示出根据程序执行上述一系列处理的计算机的硬件的配置示例的框图。
[0214]
在计算机中,中央处理单元(cpu)501、只读存储器(rom)502和随机存取存储器(ram)503通过总线504相互连接。
[0215]
总线504进一步与输入/输出接口505连接。输入/输出接口505与输入单元506、输出单元507、记录单元508、通信单元509和驱动器510连接。
[0216]
输入单元506包括键盘、鼠标、麦克风、成像元件等。输出单元507包括显示器、扬声器等。记录单元508包括硬盘、非易失性存储器等。通信单元509包括网络接口等。驱动器510驱动诸如磁盘、光盘、磁光盘或半导体存储器的可移动记录介质511。
[0217]
为了执行上述一系列处理,具有上述配置的计算机使cpu 501例如经由输入/输出接口505和总线504将记录在记录单元508中的程序加载到ram 503中,并且然后执行该程序。
[0218]
可以通过例如记录在作为封装介质等的可移动记录介质511上来提供要由计算机(cpu 501)执行的程序。此外,可以经由诸如局域网、因特网或数字卫星广播的有线或无线传输介质来提供程序。
[0219]
将可移动记录介质511插入驱动器510允许计算机经由输入/输出接口505将程序安装到记录单元508中。此外,程序可以经由有线或无线传输介质由通信单元509接收,并且安装在记录单元508中。另外,程序可以预先安装在rom 502或记录单元508中。
[0220]
注意,要由计算机执行的程序可以是如本说明书中描述的按时间顺序执行处理的程序,或者可以是并行或者当需要时(例如,当调用处理时)执行处理的程序。
[0221]
此外,本技术的实施例不限于上述实施例,而是可以在本技术的范围内以各种方式进行修改。
[0222]
例如,本技术可以具有云计算配置,其中,多个装置共享一个功能并且经由网络协作处理。
[0223]
此外,上述流程图中描述的每个步骤可以由一个装置执行或者可以由多个装置共享。
[0224]
此外,在一个步骤中包括多个处理的情况下,该步骤中包括的多个处理可以由一
个装置执行或者可以由多个装置共享。
[0225]
此外,本技术还可以具有以下配置。
[0226]
(1)一种信号处理装置,包括:
[0227]
声源分离单元,通过使用预先学习的预定声源分离模型对输入声学信号递归地执行声源分离以从包括预定声源的用于学习的声学信号中分离预定声源。
[0228]
(2)根据(1)的信号处理装置,其中,
[0229]
声源分离单元执行声源分离以从声学信号中分离说话者的话语的分离信号。
[0230]
(3)根据(2)的信号处理装置,其中,
[0231]
声源分离单元对说话者的数量未知的声学信号执行声源分离。
[0232]
(4)根据(2)或(3)的信号处理装置,其中,
[0233]
声源分离模型是被学习以将包括两个说话者的话语的用于学习的声学信号分离成包括一个说话者的话语的分离信号和包括另一说话者的话语的分离信号的说话者分离模型。
[0234]
(5)根据(2)或(3)的信号处理装置,其中,
[0235]
声源分离模型是被学习以将包括三个说话者的话语的用于学习的声学信号分离成三个分离信号的说话者分离模型,该三个分离信号中的每一个分离信号包括三个说话者的话语中的对应一个说话者的话语。
[0236]
(6)根据(2)或(3)的信号处理装置,其中,
[0237]
声源分离模型是被学习以将包括任意多个说话者的话语的用于学习的声学信号分离成包括一个说话者的话语的分离信号和包括多个说话者中除了一个说话者之外的剩余说话者的话语的分离信号的说话者分离模型。
[0238]
(7)根据(2)至(6)中任一项的信号处理装置,其中,
[0239]
声源分离单元通过使用彼此不同的多个声源分离模型作为预定声源分离模型来递归地执行声源分离。
[0240]
(8)根据(2)至(7)中任一项的信号处理装置,进一步包括:
[0241]
结束确定单元,基于通过声源分离获得的分离信号来确定是否结束递归声源分离。
[0242]
(9)根据(8)的信号处理装置,其中,
[0243]
在通过声源分离获得的一个分离信号是无声信号的情况下,结束确定单元确定结束递归声源分离。
[0244]
(10)根据(8)的信号处理装置,其中,
[0245]
在基于用于确定包括在分离信号中的话语的说话者的数量是否为1的单个说话者确定模型和分离信号确定包括在通过声源分离获得的分离信号中的话语的说话者的数量为1的情况下,结束确定单元确定递归声源分离将被结束。
[0246]
(11)根据(2)至(10)中任一项的信号处理装置,进一步包括:
[0247]
同一说话者确定单元,执行关于通过递归声源分离获得的多个分离信号是否是同一说话者的信号的同一说话者确定,并且从同一说话者的多个分离信号合成分离信号。
[0248]
(12)根据(11)的信号处理装置,其中,
[0249]
同一说话者确定单元通过对分离信号进行聚类来执行同一说话者确定。
[0250]
(13)根据(12)的信号处理装置,其中,
[0251]
同一说话者确定单元计算分离信号的特征值,并且确定在两个分离信号的特征值之间的距离等于或小于阈值的情况下,两个分离信号是同一说话者的信号。
[0252]
(14)根据(12)的信号处理装置,其中,
[0253]
同一说话者确定单元基于两个分离信号的时间能量变化之间的相关性来执行同一说话者确定。
[0254]
(15)根据(11)的信号处理装置,其中,
[0255]
同一说话者确定单元基于多个分离信号的语言信息来执行同一说话者确定。
[0256]
(16)根据(11)的信号处理装置,其中,
[0257]
同一说话者确定单元基于用于确定两个分离信号是否是同一说话者的信号的同一说话者确定模型执行同一说话者确定。
[0258]
(17)一种信号处理方法,包括:
[0259]
由信号处理装置通过使用预先学习的预定声源分离模型对输入声学信号递归地执行声源分离以从包括预定声源的用于学习的声学信号中分离预定声源。
[0260]
(18)一种程序,用于使计算机执行包括以下步骤的处理:
[0261]
通过使用预先学习的预定声源分离模型对输入声学信号递归地执行声源分离以从包括预定声源的用于学习的声学信号中分离预定声源。
[0262]
参考标记列表
[0263]
11 信号处理装置
[0264]
21 声源分离单元
[0265]
22 结束确定单元
[0266]
51 信号处理装置
[0267]
61 同一说话者确定单元。