1.本发明涉及背景音消除,具体为一种自适应背景音消除方法。
背景技术:
2.长久以来,心血管疾病一直是危害人类生命健康的主要疾病之一。随着 我国人口老龄化趋势的加重,对心血管疾病的防治形势也变得越来越严峻。 心音听诊是对心血管疾病进行诊断的便捷手段之一,它以一种无侵入的方式 获取伴随心血管活动所产生的生理以及病理音,从而给出快捷的诊断结果。 传统听诊器的使用需要医师具备丰富的临床经验,且给出的结果也比较主观。 随着近年来计算机以及物联网技术的发展,实现一种可自动给出客观听诊结 果的电子听诊器成为可能。电子听诊器在实际心音听诊过程中面临三方面问 题:心音信号的采集场所复杂,有用信号易受各种背景噪音的污染。
3.目前背景音消除的研究已经取得一定的成果,但是背景音干扰实质上在 时域和频域上都是稀疏的,即并非每时每刻都存在、也并非在所有频段上都 存在,因此没有必要所有时间帧和频段都进行背景音消除,否则会导致结果 的过度消除,使得一些与疾病相关联的特异性成分消失,另外,传统心音去 噪方法未引入控制抵消后信号失真的机制,导致输出信号可能出现失真过大 的问题。
技术实现要素:
4.针对上述情况,为克服现有技术的缺陷,本发明提供一种自适应背景音 消除方法,有效的解决了目前背景音消除的研究已经取得一定的成果,但是 背景音干扰实质上在时域和频域上都是稀疏的,即并非每时每刻都存在、也 并非在所有频段上都存在,因此没有必要所有时间帧和频段都进行背景音消 除,否则会导致结果的过度消除,使得一些与疾病相关联的特异性成分消失, 另外,传统心音去噪方法未引入控制抵消后信号失真的机制,导致输出信号 可能出现失真过大的问题。
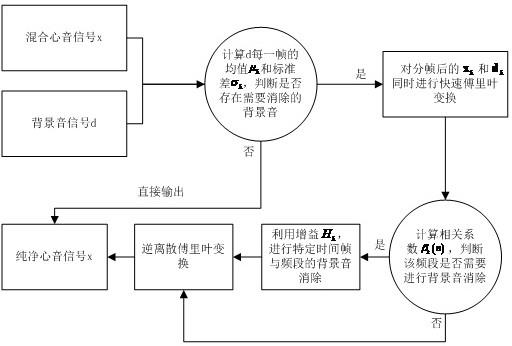
5.为实现上述目的,本发明提供如下技术方案:本发明包括如下步骤,时 间帧上的判断、频域上的判断、背景音消除和转变为时序信号,所述时间帧 上的判断:首先对输入数据分帧得到混合心音信号的第k帧数据向量x
k
和背景 音干扰信号的第k帧向量d
k
,每帧为256个采样点,且相邻两帧之间交叠50%, 然后进行每一帧的判断,为了满足背景音消除算法在电子听诊器中的实时性 要求,选择使用拉依达准则来进行背景音的检测,即计算出背景音数据每帧 上的均值μ
k
和标准差σ
k
,设定一个背景音检测门限th
bg
,若μ
k
+3σ
k
>th
bg
,则 判断此帧上存在背景音,需要进一步在频段上进行背景音消除,否则直接输 出;
6.所述频域上的判断:首先对混合心音信号和背景音信号加窗,分别通过 快速傅里叶变换求得其n点fft向量为xf
k
和df
k
,令p
k
为由xf
k
的第n
l
~n
h
个频 点上的数值构成的n
h
‑
n
l
+1维向量,q
k
为由df
k
的第n
l
~n
h
个频点上的数值构成 的n
h
‑
n
l
+1维向量,并且加入失真控制因子α,将p
k
、q
k
改写为|p
k
|
α
、|q
k
|
α
, 然后通过秩1修正方式分别计算混合信号自相关向量c
x,k
与混合信号和背景音 信号的自相关向量c
xd,k
,公式如下:
7.c
x,k
=λc
x,k
‑1+(1
‑
λ)|p
k
|
2α
,
ꢀꢀ
(3
‑
21)
8.c
xd,k
=λc
xd,k
‑1+(1
‑
λ)|p
k
|
a
⊙
|q
k
|
a
,
ꢀꢀ
(3
‑
22)
9.其中
⊙
表示hadamard积,λ为遗忘因子,a为信号失真控制因子,设定相 关系数的所用帧数m为20,可以得到相邻m个p
k
组合成的混合心音信号自相 关矩阵x
r,k
与相邻m个q
k
组合成的背景音信号自相关矩阵d
r,k
,然后利用x
r,k
与d
r,k
计算从第n
i
个频点到第n
h
个频点的各个频点上混合心音信号和背景音 信号的互相关系数:
[0010][0011]
接下来进行判断,设定相关系数门限th
corr
,若β
k
(n+n
l
‑
1)>th
corr
则认为此 频段需要进行背景音消除,否则进行逆短时傅里叶变换转换到时域信号;
[0012]
所述背景音消除:频域上干净心音信号的估计值可以通过下式获得:
[0013][0014]
其中表示干净心音信号第k帧第n个频点的fft值,p
k
[n]表示混合心 音信号第k帧第n个频点的fft值,表示回声消除之后背景音信号第k帧 第n个频点的fft值,回声消除之后的可由下式获得:
[0015][0016]
所以(3
‑
24)可以改写为:
[0017][0018]
由于q
k
[n]可以写为:
[0019][0020]
于是(3
‑
26)进一步写为:
[0021][0022]
其中
[0023]
定义噪声信号的误差信号为:
[0024]
e
k
=|q
k
[n]|
α
‑
h
′
k
|p
k
[n]|
α
,n=1,2,...,n
h
‑
n
l
+1,
ꢀꢀ
(3
‑
29)
[0025]
然后基于均方误差准则可得:
[0026][0027]
通过最小化j[h
k
]得到最优的h
′
k
:
[0028][0029]
将其带入可得最终的频域维纳滤波增益:
[0030][0031]
最后对需要进行背景音消除的频段p
k
利用式(3
‑
33)更新其频谱:
[0032]
p
′
k
[n]=max{0,h
k
p
k
[n]},n=1,2,...,n
h
‑
n
l
+1,
ꢀꢀ
(3
‑
33)
[0033]
将xf
k
中第n
l
~n
h
个频点上的元素由p
′
k
中的对应元素替换,形成当前帧背 景音干扰自动抵消后的频域向量xf
′
k
;
[0034]
所述转变为时序信号:从式(3
‑
33)可以看出,最后更新的结果有可能 为0,若p
′
k
中包含值为0的元素,通过三次样条插值来更新这些元素,然后将 频域向量xf
′
k
加窗,通过快速傅里叶反变换将其转换为时域向量x
′
k
。
[0035]
有益效果:本发明相较于传统心音去噪方法,引入了控制抵消后信号失 真的机制,导致输出信号不会出现失真过大的问题,分别在时域和频域上进 行是否存在背景音的判断,对存在背景音的时间帧和频段运用频域维纳滤波 进行背景音的消除,在计算增益时加入了信号失真控制因子α,用来平衡背 景音消除与心音信号保真,最后的对比实验证明了本发明的背景音消除方法 可以在保真心音信号的同时有效进行背景音干扰的消除。
附图说明
[0036]
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本 发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
[0037]
图1是本发明流程图;
[0038]
图2是本发明图2中(a)为干净心音波形图;(b)为干净心音时频图; (c)为背景音波形图;(d)为背景音时频图;(e)为10db信噪比叠加信 号波形图;(f)为10db信噪比叠加信号时频图;
[0039]
图3是本发明图3中(a)为心音信号定位波形图;(b)为心音信号时 频图;
[0040]
图4是本发明结构示意图;
[0041]
图中标号:1、包装盒本体;2、第一侧板;3、第二侧板;4、底板;5、 第一通孔;6、第二通孔;7、支撑柱;8、凹槽;9、第一密封板;10、第二 密封板。
具体实施方式
[0042]
下面结合附图1
‑
3对本发明的具体实施方式做进一步详细说明。
[0043]
实施例一,由图1
‑
3给出,本发明提供一种自适应背景音消除方法,包 括如下步
骤,时间帧上的判断、频域上的判断、背景音消除和转变为时序信 号,所述时间帧上的判断:首先对输入数据分帧得到混合心音信号的第k帧数 据向量x
k
和背景音干扰信号的第k帧向量d
k
,每帧为256个采样点,且相邻两 帧之间交叠50%,然后进行每一帧的判断,为了满足背景音消除算法在电子听 诊器中的实时性要求,选择使用拉依达准则来进行背景音的检测,即计算出 背景音数据每帧上的均值μ
k
和标准差σ
k
,设定一个背景音检测门限th
bg
,若 μ
k
+3σ
k
>th
bg
,则判断此帧上存在背景音,需要进一步在频段上进行背景音消 除,否则直接输出;
[0044]
所述频域上的判断:首先对混合心音信号和背景音信号加窗,分别通过 快速傅里叶变换求得其n点fft向量为xf
k
和df
k
,令p
k
为由xf
k
的第n
l
~n
h
个频 点上的数值构成的n
h
‑
n
l
+1维向量,q
k
为由df
k
的第n
l
~n
h
个频点上的数值构成 的n
h
‑
n
l
+1维向量,并且加入失真控制因子α,将p
k
、q
k
改写为|p
k
|
α
、|q
k
|
α
, 然后通过秩1修正方式分别计算混合信号自相关向量c
x,k
与混合信号和背景音 信号的自相关向量c
xd,k
,公式如下:
[0045]
c
x,k
=λc
x,k
‑1+(1
‑
λ)|p
k
|
2α
,
ꢀꢀ
(3
‑
21)
[0046]
c
xd,k
=λc
xd,k
‑1+(1
‑
λ)|p
k
|
a
⊙
|q
k
|
a
,
ꢀꢀ
(3
‑
22)
[0047]
其中
⊙
表示hadamard积,λ为遗忘因子,a为信号失真控制因子,设定相 关系数的所用帧数m为20,可以得到相邻m个p
k
组合成的混合心音信号自相 关矩阵x
r,k
与相邻m个q
k
组合成的背景音信号自相关矩阵d
r,k
,然后利用x
r,k
与d
r,k
计算从第n
i
个频点到第n
h
个频点的各个频点上混合心音信号和背景音 信号的互相关系数:
[0048][0049]
接下来进行判断,设定相关系数门限th
corr
,若β
k
(n+n
l
‑
1)>th
corr
则认为此 频段需要进行背景音消除,否则进行逆短时傅里叶变换转换到时域信号;
[0050]
所述背景音消除:频域上干净心音信号的估计值可以通过下式获得:
[0051][0052]
其中表示干净心音信号第k帧第n个频点的fft值,p
k
[n]表示混合心 音信号第k帧第n个频点的fft值,表示回声消除之后背景音信号第k帧 第n个频点的fft值,回声消除之后的可由下式获得:
[0053][0054]
所以(3
‑
24)可以改写为:
[0055][0056]
由于q
k
[n]可以写为:
[0057]
[0058]
于是(3
‑
26)进一步写为:
[0059][0060]
其中
[0061]
定义噪声信号的误差信号为:
[0062]
e
k
=|q
k
[n]|
α
‑
h
k
|p
k
[n]|
α
,n=1,2,...,n
h
‑
n
l
+1,
ꢀꢀ
(3
‑
29)
[0063]
然后基于均方误差准则可得:
[0064][0065]
通过最小化j[h
′
k
]得到最优的h
′
k
:
[0066][0067]
将其带入可得最终的频域维纳滤波增益:
[0068][0069]
最后对需要进行背景音消除的频段p
k
利用式(3
‑
33)更新其频谱:
[0070]
p
′
k
[n]=max{0,h
k
p
k
[n]},n=1,2,...,n
h
‑
n
l
+1,
ꢀꢀ
(3
‑
33)
[0071]
将xf
k
中第n
l
~n
h
个频点上的元素由p
′
k
中的对应元素替换,形成当前帧背 景音干扰自动抵消后的频域向量xf
′
k
;
[0072]
所述转变为时序信号:从式(3
‑
33)可以看出,最后更新的结果有可能 为0,若p
′
k
中包含值为0的元素,通过三次样条插值来更新这些元素,然后将 频域向量xf
′
k
加窗,通过快速傅里叶反变换将其转换为时域向量x
′
k
。
[0073]
实验例
[0074]
本实验例的评价指标主要有如下三个:
[0075]
(1)输出信噪比,osnr定义为干净心音信号功率p
s
与背景音信号功率p
d
的比值,值越大表明信号中存留的背景音越少:
[0076][0077]
(2)均方误差,mse表示去噪信号中存在不需要的信息,对于背景音消 除后的干净心音信号,其值必须低于背景音信号且值越小表明去噪效果越好, 定义如下:
[0078]
[0079]
其中x(j)和s(j)分别表示原始心音信号和背景音消除后的干净心音信号, l表示信号的长度。
[0080]
(3)相关系数,ccf是一个衡量去噪效果的常用指标,它通过测量干净 的心音信号和背景音消除之后心音信号之间的相似度来计算,值越大表示相 关性越高,当值为1时说明两个信号完全相同,但是在实际背景音消除结果 中,ccf的值都会小于1:
[0081][0082]
通过预实验,发现λ在0.35到0.65之间的去噪效果较好,所以选择0.35、 0.5、0.65三个待试验的λ值,并在不同的α下进行实验,以10db信噪比将 背景音加到干净心音上进行实验,并对所有实验结果求平均。
[0083]
osnr和ccf在λ=0.5和α=0.4的条件下最大,同时mse最小,代表背景音 去噪效果最好,因此选择此时的λ=0.5和α=0.4作为后续实验的最佳参数。
[0084]
选定λ与α之后可以得到图3所示的实验结果,(a)是含噪心音信号以 及背景音定位的结果,其中蓝色曲线为含噪心音信号,黑色曲线为背景音成 分,红色虚线框是定位到的背景音位置,可以看到黑色背景音成分都可以成 功被找到;(b)是含噪心音信号的时频图,整体来说,背景音在时域和频域 上都是稀疏的,本发明所提算法可以成功定位出稀疏存在的背景音,图4是 以10db信噪比叠加了噪声之后得到的各方法对比实验结果示意图。
[0085]
从图中可以看出本发明可以有效去除背景音,并且心音成分都被完整保 留下来,而传统谱减法虽然也可以将大多数背景音消除,但是部分心音成分 也被消除,这会造成重要信息的丢失,另外,传统nlms算法得到的结果中背 景音只有少部分被去除,大量的背景音依旧存在。
[0086]
有益效果:本发明相较于传统心音去噪方法,引入了控制抵消后信号失 真的机制,导致输出信号不会出现失真过大的问题,分别在时域和频域上进 行是否存在背景音的判断,对存在背景音的时间帧和频段运用频域维纳滤波 进行背景音的消除,在计算增益时加入了信号失真控制因子α,用来平衡背 景音消除与心音信号保真,最后的对比实验证明了本发明的背景音消除方法 可以在保真心音信号的同时有效进行背景音干扰的消除。
[0087]
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限 制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的 技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或 者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作 的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。