1.本公开涉及音频处理技术领域,尤其涉及一种音频检测方法、装置、电子设备及存储介质。
背景技术:
2.为了达到美化声音的目的,需要消除歌曲音频中的换气声,因此,如何能够检测出歌曲音频中的换气声,成为了一个亟待解决的问题。
3.相关技术中,通常可以在输入原始音频之后,采用换气相似度的计算,确定出每一帧是否为换气声,然而,通过相关技术中的这种方式,仅基于换气相似度的计算来确定换气声区域,因此,确定出的换气声的边界不准确,从而导致检测出的换气声不准确。
技术实现要素:
4.本公开实施例提供一种音频检测方法、装置、电子设备及存储介质,以提高检测换气声的准确性。
5.本公开实施例提供的具体技术方案如下:
6.一种音频检测方法,包括:
7.从原始音频中确定出待处理音频,以及所述待处理音频的各音频帧对应的能量值和时域分布的时间点信息,并从所述待处理音频中确定出初始目标音频,其中,所述待处理音频为包含有换气声的非人声音频,所述初始目标音频表征初步检测出的换气声;
8.从所述初始目标音频的各换气帧中确定出能量值满足最高能量值条件的最高换气帧,其中,所述初始目标音频由至少一帧换气帧组成;
9.分别对所述待处理音频的各音频帧对应的能量值进行平滑处理,并从所述待处理音频的起始帧与所述最高换气帧之间的各音频帧中,确定出满足最低能量值条件的第一最低换气帧,并从所述最高换气帧与所述待处理音频的终止帧之间的各音频帧中,确定出满足最低能量值条件的第二最低换气帧;
10.将所述第一最低换气帧和所述第二最低换气帧之间的各音频帧,作为所述原始音频的目标音频,其中,所述目标音频表征边界修正后的换气声。
11.可选的,分别对所述待处理音频的各音频帧对应的能量值进行平滑处理,具体包括:
12.分别针对所述待处理音频的各音频帧,根据预设的平滑阶数和各音频帧的时间点信息,确定任意一音频帧对应的预设数个音频帧,根据所述预设数个音频帧的能量值之和,与所述平滑阶数之间的比值,确定该音频帧的处理后的能量值。
13.可选的,从所述待处理音频的起始帧与所述最高换气帧之间的各音频帧中,确定出满足最低能量值条件的第一最低换气帧,并从所述最高换气帧与所述待处理音频的终止帧之间的各音频帧中,确定出满足最低能量值条件的第二最低换气帧,具体包括:
14.将所述待处理音频的起始帧与所述最高换气帧之间的各音频帧,作为第一候选音
频,并将所述最高换气帧与所述待处理音频的结束帧之间的各音频帧作为第二候选音频;
15.从所述第一候选音频的各音频帧中,确定出所述能量值小于前一音频帧且小于后一音频帧的音频帧,并将确定出的各音频帧中时间点信息最大的音频帧作为第一最低换气帧;以及,
16.从所述第二候选音频的各音频帧中,确定出能量值小于前一音频帧且小于后一音频帧的音频帧,并将确定出的各音频帧中时间点信息最小的音频帧作为第二最低换气帧。
17.可选的,将所述第一最低换气帧和所述第二最低换气帧之间的各音频帧,作为所述原始音频的目标音频之后,还包括:
18.确定所述目标音频的各换气帧对应的锐度值,其中,所述锐度值表征音频帧的声音信号的尖锐程度;
19.根据各锐度值,确定所述目标音频是否为正确检测出的换气声。
20.可选的,根据各锐度值,确定所述目标音频是否为正确检测出的换气声,具体包括:
21.从所述目标音频的各换气帧中筛选出锐度值高于锐度值阈值的换气帧;
22.若确定所述目标音频中不存在预设连续数个高于所述锐度值阈值的换气帧,则确定所述目标音频为正确检测出的换气声。
23.可选的,从所述初始目标音频的各换气帧中确定出能量值满足最高能量值条件的最高换气帧,具体包括:
24.从所述初始目标音频的各换气帧中,确定出能量值最高的换气帧;
25.将确定出的换气帧作为所述初始目标音频中的最高换气帧。
26.可选的,从原始音频中确定出待处理音频,具体包括:
27.对原始音频进行时域分帧,获得各音频帧;
28.基于已训练的第一音频检测模型,以所述各音频帧为输入参数,通过所述第一音频检测模型中的人声检测网络,从所述原始音频中确定出待处理音频,并通过所述第一音频检测模型中的静音检测网络,筛选掉所述待处理音频中的静音音频,获得处理后的待处理音频,其中,所述第一音频检测模型用于检测出所述原始音频中包含有换气声的待处理音频。
29.可选的,通过所述第一音频检测模型中的静音检测网络,筛选掉所述待处理音频中的静音音频,获得处理后的待处理音频,具体包括:
30.确定所述待处理音频中的各音频帧对应的能量值和时域分布的时间点信息;
31.从所述待处理音频中的各音频帧中确定出大于等于预设能量值阈值的音频帧;
32.将所述小于所述能量值阈值的音频帧组成静音音频;
33.从所述待处理音频中去除所述静音音频,获得处理后的待处理音频。
34.可选的,获得处理后的待处理音频之后,进一步包括:
35.分别对所述待处理音频的各音频帧进行特征提取,确定各音频特征;
36.分别针对所述待处理音频的各音频帧,基于已训练的第二音频检测模型,以任意一帧音频帧的音频特征为输入参数,确定该音频帧是否为换气帧,其中,所述第二音频检测模型用于检测所述待处理音频中的音频帧是否为换气帧;
37.将高于数量阈值的连续数个换气帧组成初始目标音频。
38.一种音频检测装置,包括:
39.第一确定模块,用于从原始音频中确定出待处理音频,以及所述待处理音频的各音频帧对应的能量值和时域分布的时间点信息,并从所述待处理音频中确定出初始目标音频,其中,所述待处理音频为包含有换气声的非人声音频,所述初始目标音频表征初步检测出的换气声;
40.第二确定模块,用于从所述初始目标音频的各换气帧中确定出能量值满足最高能量值条件的最高换气帧,其中,所述初始目标音频由至少一帧换气帧组成;
41.第一处理模块,用于分别对所述待处理音频的各音频帧对应的能量值进行平滑处理,并从所述待处理音频的起始帧与所述最高换气帧之间的各音频帧中,确定出满足最低能量值条件的第一最低换气帧,并从所述最高换气帧与所述待处理音频的终止帧之间的各音频帧中,确定出满足最低能量值条件的第二最低换气帧;
42.第三确定模块,用于将所述第一最低换气帧和所述第二最低换气帧之间的各音频帧,作为所述原始音频的目标音频,其中,所述目标音频表征边界修正后的换气声。
43.可选的,分别对所述待处理音频的各音频帧对应的能量值进行平滑处理时,第一处理模块具体用于:
44.分别针对所述待处理音频的各音频帧,根据预设的平滑阶数和各音频帧的时间点信息,确定任意一音频帧对应的预设数个音频帧,根据所述预设数个音频帧的能量值之和,与所述平滑阶数之间的比值,确定该音频帧的处理后的能量值。
45.可选的,从所述待处理音频的起始帧与所述最高换气帧之间的各音频帧中,确定出满足最低能量值条件的第一最低换气帧,并从所述最高换气帧与所述待处理音频的终止帧之间的各音频帧中,确定出满足最低能量值条件的第二最低换气帧时,第一处理模块具体用于:
46.将所述待处理音频的起始帧与所述最高换气帧之间的各音频帧,作为第一候选音频,并将所述最高换气帧与所述待处理音频的结束帧之间的各音频帧作为第二候选音频;
47.从所述第一候选音频的各音频帧中,确定出所述能量值小于前一音频帧且小于后一音频帧的音频帧,并将确定出的各音频帧中时间点信息最大的音频帧作为第一最低换气帧;以及,
48.从所述第二候选音频的各音频帧中,确定出能量值小于前一音频帧且小于后一音频帧的音频帧,并将确定出的各音频帧中时间点信息最小的音频帧作为第二最低换气帧。
49.可选的,将所述第一最低换气帧和所述第二最低换气帧之间的各音频帧,作为所述原始音频的目标音频之后,还包括:
50.第四确定模块,用于确定所述目标音频的各换气帧对应的锐度值,其中,所述锐度值表征音频帧的声音信号的尖锐程度;
51.判断模块,用于根据各锐度值,确定所述目标音频是否为正确检测出的换气声。
52.可选的,判断模块具体用于:
53.从所述目标音频的各换气帧中筛选出锐度值高于锐度值阈值的换气帧;
54.若确定所述目标音频中不存在预设连续数个高于所述锐度值阈值的换气帧,则确定所述目标音频为正确检测出的换气声。
55.可选的,第二确定模块具体用于:
56.从所述初始目标音频的各换气帧中,确定出能量值最高的换气帧;
57.将确定出的换气帧作为所述初始目标音频中的最高换气帧。
58.可选的,从原始音频中确定出待处理音频时,第一确定模块具体用于:
59.对原始音频进行时域分帧,获得各音频帧;
60.基于已训练的第一音频检测模型,以所述各音频帧为输入参数,通过所述第一音频检测模型中的人声检测网络,从所述原始音频中确定出待处理音频,并通过所述第一音频检测模型中的静音检测网络,筛选掉所述待处理音频中的静音音频,获得处理后的待处理音频,其中,所述第一音频检测模型用于检测出所述原始音频中包含有换气声的待处理音频。
61.可选的,通过所述第一音频检测模型中的静音检测网络,筛选掉所述待处理音频中的静音音频,获得处理后的待处理音频时,第一确定模块具体用于:
62.确定所述待处理音频中的各音频帧对应的能量值和时域分布的时间点信息;
63.从所述待处理音频中的各音频帧中确定出大于等于预设能量值阈值的音频帧;
64.将所述小于所述能量值阈值的音频帧组成静音音频;
65.从所述待处理音频中去除所述静音音频,获得处理后的待处理音频。
66.可选的,获得处理后的待处理音频之后,进一步包括:
67.特征提取模块,用于分别对所述待处理音频的各音频帧进行特征提取,确定各音频特征;
68.第二处理模块,用于分别针对所述待处理音频的各音频帧,基于已训练的第二音频检测模型,以任意一帧音频帧的音频特征为输入参数,确定该音频帧是否为换气帧,其中,所述第二音频检测模型用于检测所述待处理音频中的音频帧是否为换气帧;
69.组合模块,用于将高于数量阈值的连续数个换气帧组成初始目标音频。
70.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述音频检测方法的步骤。
71.一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述音频检测方法的步骤。
72.本公开实施例中,从原始音频中确定出待处理音频,以及待处理音频的各音频帧对应的能量值和时域分布的时间点信息,并从待处理音频中确定出初始目标音频,从初始目标音频的各换气帧中确定出能量值满足最高能量值条件的最高换气帧,分别对待处理音频的各音频帧对应的能量值进行平滑处理,并从待处理音频的起始帧与最高换气帧之间的各音频帧中,确定出满足最低能量值条件的第一最低换气帧,并从最高换气帧与待处理音频的终止帧之间的各音频帧中,确定出满足最低能量值条件的第二最低换气帧,将第一最低换气帧和第二最低换气帧之间的各音频帧,作为原始音频的目标音频。这样,根据换气声的发声原理,吸气时能量上升,呼气时能量下降,对待处理音频的各音频帧的能量值进行平滑处理,能够使得待处理音频具有明显的最低能量值,并从平滑处理后的各能量值中确定出满足预设最低能量值条件的第一最低换气帧和第二最低换气帧,从而修正换气声边界,以达到边界和实际换气声吻合的目的,提高了换气声检测的准确性。
附图说明
73.图1为相关技术中换气声的波形示意图;
74.图2为本公开实施例中一种音频检测方法的流程图;
75.图3为本公开实施例中的能量值分布的第一示意图;
76.图4为本公开实施例中平滑处理后的能量值分布的第二示意图;
77.图5为本公开实施例中删除清齿音的方法的流程图;
78.图6为本公开实施例中锐度值分布示意图;
79.图7为本公开实施例中一种音频检测方法的另一流程图;
80.图8为本公开实施例中音频检测装置的结构示意图;
81.图9为本公开实施例中电子设备的结构示意图。
具体实施方式
82.下面将结合本公开实施例中的附图,对本公开实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本公开一部分实施例,并不是全部的实施例。基于本公开中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本公开保护的范围。
83.下面先对本公开实施例中的名词进行介绍:
84.原始音频:是指未经过人为处理的干声演唱数据,原始音频中包括人声音频、静音音频和换气声。
85.待处理音频:是指包含有换气声的非人声音频。
86.能量值:是指音频信号的均方根能量,表示音频信号波形短时间内的平均能量。
87.初始目标音频:是初步检测出的换气声。
88.换气帧:用于表示一帧数据是否为一处换气声的其中一帧。
89.换气声:一处换气声由多个换气帧组成,换气帧密集的部分可以整合为一处换气声。例如,一个完整换气声的换气持续时间为100ms~600ms。
90.锐度值:是指音频帧的声音信号的尖锐程度。
91.静音音频:是由能量值小于能量值阈值的多个音频帧组成的。
92.人声活动区域检测技术(voice activity detection,vad):通过vad技术可以区分出原始音频中的人声音频和非人声音频。
93.支持向量机(support vector machine,svm):用于对音频帧是否为换气帧进行二分类。
94.梅尔倒谱系数(mel
‑
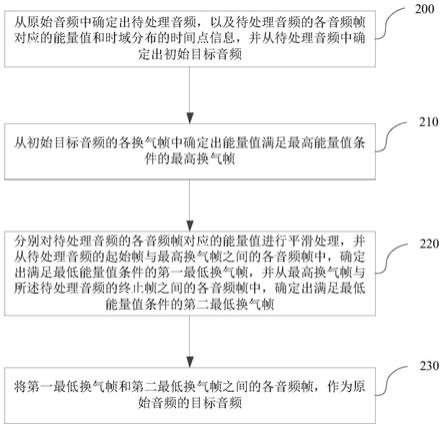
frequency cepstral coefficients,mfcc):是音频的一种频域特征,由频域信号提取得到。
95.清齿音:清齿音是包含一定齿音成分的清音,汉语中一般有“c”、“s”、“q”此类发音。
96.齿音:为人唱歌吐字时发出的咝擦声,一般出现在字词发音的起始位置,能量集中在2~10khz的频带范围。
97.为了消除唱歌过程中的换气声,从而达到声音美化的目的,换气声检测的准确性非常重要。因此,如何能够检测出歌曲音频中的换气声,成为了一个亟待解决的问题。参阅
图1所示,为相关技术中换气声的波形示意图。
98.相关技术中,首先过滤掉不可能是换气声的位置,然后,通过检测模型,计算原始音频的每一音频帧与标准换气帧之间的换气相似度,从而确定出每一帧是否为换气声,最后,整合所有的换气帧,从而确定出原始音频中的换气声。然而,相关技术中的这种方式,由于仅基于换气相似度来确定换气声,面对复杂的人声信号表现出较低性能,且对于换气声的边界修正仅依赖于经验,因此,确定出的换气声的边界不准确,从而导致检测出的换气声不准确。
99.为了解决上述问题,本公开实施例中,提供了一种音频检测方法,从原始音频中确定出待处理音频,以及待处理音频的各音频帧对应的能量值和时域分布的时间点信息,并从待处理音频中确定出初始目标音频,从初始目标音频的各换气帧中确定出能量值满足最高能量值条件的最高换气帧,分别对待处理音频的各音频帧对应的能量值进行平滑处理,并从待处理音频的起始帧与最高换气帧之间的各音频帧中,确定出满足最低能量值条件的第一最低换气帧,并从最高换气帧与待处理音频的终止帧之间的各音频帧中,确定出满足最低能量值条件的第二最低换气帧,将第一最低换气帧和第二最低换气帧之间的各音频帧,作为原始音频的目标音频。这样,通过对各音频帧的能量值进行平滑处理后,将平滑处理后获得的第一最低换气帧和第二最低换气帧之间的各音频帧作为边界修正后的换气声,从而能够提高换气声检测的准确性。
100.基于上述实施例,参阅图2所示,为本公开实施例中一种音频检测方法的流程图,具体包括:
101.步骤200:从原始音频中确定出待处理音频,以及待处理音频的各音频帧对应的能量值和时域分布的时间点信息,并从待处理音频中确定出初始目标音频。
102.其中,待处理音频为包含有换气声的非人声音频,初始目标音频表征初步检测出的换气声。
103.本公开实施例中,由于原始音频为未经过处理的干声演唱数据,因此,原始音频中包含有人声音频,需要对原始音频进行处理,从原始音频中确定出包含有换气声的非人声音频,并将确定出的非人声音频作为待处理音频。同时,获得待处理音频的每个音频帧对应的能量值和时域分布的时间点信息。
104.其中,待处理音频由多个音频帧组成,待处理音频中包含有换气声。
105.本公开实施例中为从原始音频中确定出待处理音频提供了一种可能的实施方式,下面对本公开实施例中,从原始音频中确定出待处理音频的过程进行详细阐述,具体包括:
106.s2001:对原始音频进行时域分帧,获得各音频帧。
107.本公开实施例中,根据预先设定的每帧音频帧的采样点的数量,获得每帧音频帧的长度,并根据预先设定的各音频帧之间的间隔采样点数量,获得采样间隔。然后,根据每帧音频帧的长度和采样间隔,对原始音频进行时域分帧,从而获得各音频帧。
108.例如,假设每帧音频帧的采样点的数量为2048个采样点,各音频帧之间的间隔采样点数量为1024个采样点,采样率为48hz,因此,在48khz的采样率下,每帧音频帧的长度约为23ms。
109.s2002:基于已训练的第一音频检测模型,以各音频帧为输入参数,通过第一音频检测模型中的人声检测网络,从原始音频中确定出待处理音频,并通过第一音频检测模型
中的静音检测网络,筛选掉待处理音频中的静音音频,获得处理后的待处理音频。
110.其中,第一音频检测模型用于检测出原始音频中包含有换气声的待处理音频。
111.本公开实施例中,将各音频帧输入至已训练的第一音频检测模型中,并输入至第一音频检测模型中的人声检测网络中,通过人声检测网络,将原始音频中的不可能存在换气声的人声区域筛选掉,得到可能存在换气声的待处理音频,然后,将待处理音频输入至第一音频检测模型中的静音网络,通过静音网络,筛选出待处理音频中的静音音频,从而获得处理后的待处理音频。
112.可选的,本公开实施例中的一种可能的实施方式为,第一音频检测模型由两个网络串行组成,第一个网络为人声检测网络,人声检测网络用于检测出原始音频中包含的不可能存在换气声的人声区域,并删除人声音频,从而得到可能存在换气声的非人声区域,也即待处理音频;第二个网络为静音网络,静音网络用于检测出待处理音频中包含的静音音频,并将待处理音频中的静音区域筛选掉,获得处理后的待处理音频。
113.其中,人声检测网络例如可以为vad模块,本公开实施例中对此并不进行限制。
114.可选的,本公开实施例中为获得处理后的待处理音频提供了一种可能的实施方式,下面对本公开实施例中,筛选掉待处理音频中的静音音频的过程进行详细阐述,具体包括:
115.s2010:确定待处理音频中的各音频帧对应的能量值和时域分布的时间点信息。
116.本公开实施例中,由于待处理音频由多个音频帧组成,因此,确定各待处理音频中的各音频帧对应的能量值和时域分布的时间点信息。
117.其中,每个音频帧对应一个能量值,以及该音频帧在时域分布的时间点信息。
118.s2011:从待处理音频中的各音频帧中确定出大于等于预设能量值阈值的音频帧。
119.本公开实施例中,在确定出的待处理音频中的各音频帧对应的能量值之后,首先,分别确定待处理音频中的各音频帧是否大于等于预先设定的能量值阈值,从而就能够获知每一个音频帧是否大于能量值阈值,然后,从待处理音频中的各音频帧中,确定出大于等于预设能量值阈值的音频帧,以及小于预设能量值阈值的音频帧。
120.s2012:将小于能量值阈值的音频帧组成静音音频。
121.本公开实施例中,预先设定音频帧数量阈值,将待处理音频的各音频帧中,超过预设音频帧数量阈值的连续数个小于能量值阈值的音频帧,作为静音音频。
122.例如,假设第1个音频帧对应的能量值大于能量值阈值,第2
‑
10个音频帧对应的能量值小于能量值阈值,第11
‑
25个音频帧对应的能量值大于能量值阈值,第26
‑
27个音频帧对应的能量值小于能量值阈值,第28
‑
35个音频帧对应的能量值大于能量值阈值,预先设定的音频帧数量阈值为5。由于第2
‑
10个音频帧对应的能量值小于能量值阈值,且该连续9个音频帧的数量大于预设音频帧数量阈值,则将第2
‑
10个音频帧组成的音频,作为静音音频;虽然第26
‑
27个音频帧对应的能量值小于能量值阈值,但该连续2个音频帧的数量小于预设音频帧数量阈值,因此,第26
‑
27个音频帧组成的音频无法作为静音音频。
123.需要说明的是,本公开实施例中从待处理音频中确定出的静音音频可能为一段静音音频,也可能为多段静音音频,对此并不进行限制。
124.需要说明的是,如图1所示,静音音频的各音频帧的能量值小于换气声的换气帧的能量值,并且,静音音频的各音频帧的能量值小于人声音频的音频帧的能量值,因此,预先
设定能量值阈值,从待处理音频的各音频帧中,确定出小于预设能量值阈值的音频帧,即可从待处理音频中确定出静音音频。
125.s2013:从待处理音频中去除静音音频,获得处理后的待处理音频。
126.本公开实施例中,由于静音音频中不存在换气,因此,需要从待处理音频中去除静音音频,获得处理后的待处理音频。进而就能够从处理后的待处理音频中确定出初始目标音频。
127.然后,就能够根据各音频帧对应的能量值和时域分布的时间点信息,从待处理音频中确定出初始目标音频。
128.可选的,本公开实施例中,为确定出初始目标音频提供了一种可能的实施方式,下面对本公开实施例中,从处理后的待处理音频中确定出初始目标音频的过程进行详细阐述,具体包括:
129.s2020:分别对待处理音频的各音频帧进行特征提取,确定各音频特征。
130.本公开实施例中,分别针对待处理音频的各音频帧,执行以下操作步骤:通过预设的特征提取方式,对任意一音频帧进行特征提取,从而获得该音频帧对应的音频特征。
131.其中,在对任意一音频帧进行特征提取时,提取每个音频帧的13维的mfcc特征,mfcc是音频的一种频域特征,对音频帧的频域信号,得到音频帧的13维的mfcc特征,当然,并不仅限于上述特征。
132.需要说明的是,在进行特征提取时,是对处理后的待处理音频包含的各音频帧进行特征提取的,也即,对不包含有人声音频和静音音频的待处理音频进行特征提取。
133.s2022:分别针对待处理音频的各音频帧,基于已训练的第二音频检测模型,以任意一帧音频帧的音频特征为输入参数,确定该音频帧是否为换气帧。
134.其中,第二音频检测模型用于检测待处理音频中的音频帧是否为换气帧。
135.本公开实施例中,分别针对处理后的待处理音频帧中包含的各音频帧,基于已训练的第二音频检测模型,以任意一帧音频帧对应的音频特征为输入参数,对该音频帧进行二分类处理,从而获得该音频帧是否为换气帧的检测结果。
136.其中,第二音频检测模型例如可以为已训练的svm模型,本公开实施例中对此并不进行限制。
137.另外需要说明的是,svm模型为二分类模型,用于输出音频帧是否为换气帧的检测结果,也即,将音频帧输入至已训练的svm模型中,输出音频帧为换气帧,或音频帧为非换气帧的检测结果。
138.s2023:将高于数量阈值的连续数个换气帧组成初始目标音频。
139.本公开实施例中,由于第二音频检测模型仅能够输出每个音频帧是否为换气帧,而无法直接检测出换气声,并且,由数量较少的连续个换气帧无法组成完整的一处换气声。因此,对于通过第二音频检测模型输出的检测结果为换气帧的音频帧,需要剔除时域上分布零散的换气帧,合并时域上密集分布的换气帧,并整合为一处完整的换气声,也即初始目标音频。
140.例如,假设确定出的第1个音频帧为非换气帧,第2
‑
10个音频帧为换气帧,第11
‑
25个音频帧为非换气帧,第26
‑
27个音频帧为换气帧,第28
‑
35个音频帧为非换气帧,预先设定的数量阈值为5(110ms以内)。由于第2
‑
10个音频帧为换气帧,且第2
‑
10个音频帧的数量大
于预设音频帧数量阈值5,则可以将第2
‑
10个音频帧整合为检测出的换气声;虽然第26
‑
27个音频帧为换气帧,但第26
‑
27个音频帧的数量小于预设数量阈值,因此,无法将第26
‑
27个音频帧组成的音频作为检测出的换气声。
141.另外,需要说明的是,通过步骤200确定出的初始目标音频为换气声,但初始目标音频为边界不准的换气声,也即,初始目标音频为真实换气声的一部分,并非完整的换气声,因此,需要对初步检测出的初始目标音频的边界进行修正,从而获得真实的换气声。
142.步骤210:从初始目标音频的各换气帧中确定出能量值满足最高能量值条件的最高换气帧。
143.其中,初始目标音频由至少一帧换气帧组成。
144.本公开实施例中,在获得初始目标音频之后,确定初始目标音频的每个换气帧对应的能量值是否满足最高能量值条件,并从初始目标音频的各换气帧中,确定出能量值满足最高能量值条件的最高换气帧。
145.其中,本公开实施例中的最高能量值条件例如可以为能量值最高,本公开实施例中对此并不进行限制。
146.下面最高能量值条件为能量值最高为例,对本公开实施例中确定出满足预设能量值条件的步骤进行详细阐述,具体包括:
147.s2101:从初始目标音频的各换气帧中,确定出能量值最高的换气帧。
148.本公开实施例中,在确定出初始目标音频之后,确定初始目标音频的各换气帧对应的能量值,然后,从初始目标音频的各换气帧中,确定出能量值取值最大对应的换气帧。
149.其中,初始目标音频为边界不准确的换气声。
150.s2102:将确定出的换气帧作为初始目标音频中的最高换气帧。
151.本公开实施例中,将确定出的能量值取值最大对应的换气帧作为初始目标音频中的最高换气帧。
152.需要说明的是,由于换气声的发声原理为,吸气时能量上升,呼气时能量下降,因此,本公开实施例中确定初始目标音频的目的是,从初始目标音频中确定出能量值最高的换气帧,该换气帧为吸气过程结束,呼气过程开始对应的换气帧,并根据能量值最高的换气帧找到吸气过程开始的音频帧,以及呼气过程结束的音频帧,从而获得真实的换气声。
153.例如,参阅图3所示,为本公开实施例中的能量值分布的第一示意图,如图3可知,由于每个音频帧对应的能量值分布会产生毛刺,因此,确定出的初始目标音频的边界不准确。
154.步骤220:分别对待处理音频的各音频帧对应的能量值进行平滑处理,并从待处理音频的起始帧与最高换气帧之间的各音频帧中,确定出满足最低能量值条件的第一最低换气帧,并从最高换气帧与待处理音频的终止帧之间的各音频帧中,确定出满足最低能量值条件的第二最低换气帧。
155.本公开实施例中,由于每个音频帧对应的能量值分布会产生毛刺,因此,为了提高查找到第一最低换气帧和第二最低换气帧的准确度,需要对每个音频帧对应的能量值进行平滑处理,去除各音频帧对应的能量值分布的毛刺,从而使得各音频帧对应的能量值形成的波形中,产生明显的波谷。
156.其中,本公开实施例中为对各音频帧对应的能量值进行平滑处理提供了一种可能
的实施方式。下面对本公开实施例中,对待处理音频的各音频帧对应的能量值进行平滑处理的过程进行详细阐述,具体包括:
157.分别针对待处理音频的各音频帧,根据预设的平滑阶数和各音频帧的时间点信息,确定任意一音频帧对应的预设数个音频帧,根据预设数个音频帧之和,与平滑阶数之间的比值,确定该音频帧的处理后的能量值。
158.本公开实施例中,分别针对待处理音频的各音频帧,执行以下操作步骤:
159.s2201:根据预设的平滑阶数和各音频帧的时间点信息,确定任意一音频帧对应的预设数个音频帧。
160.本公开实施例中,获取预先设定的平滑阶数,并根据获取到的平滑阶数,确定采样数量。然后,根据确定出的采样数量,以及各音频帧的时间点信息,确定任意一音频帧对应的各音频帧,进而就能够根据确定出的各音频帧,对任意一音频帧进行平滑处理。
161.其中,采样数量表征基于任意一音频帧之前的音频帧和之后的音频帧进行平滑处理的音频帧数量。例如,当平滑阶数为3时,则需要根据任意一音频帧之前的一个音频帧的能量值,以及该音频帧之后的音频帧的能量值,对该音频帧进行平滑处理。
162.s2202:根据预设数个音频帧的能量值之和,与平滑阶数之间的比值,确定该音频帧的处理后的能量值。
163.本公开实施例中,对确定出的各音频帧的能量值进行累加,获得累加结果,然后,通过计算累加结果与平滑阶数之间的比值,确定该音频帧的处理后的能量值。
164.其中,本公开实施例中,对各音频帧的能量值进行平滑处理时,采用了基于均值滤波的方法,每个音频帧的平滑处理公式为:
[0165][0166]
其中,rms(k)为第k个音频帧处理后的能量值,n为平滑阶数,i为第i个音频帧。
[0167]
例如,当n为3时,第k个音频帧的处理后的能量值等于第k个音频帧的能量值与左右相邻音频帧的能量值的均值,也即,rms(k
‑
1),rms(k),rms(k+1)的均值为第k个音频帧的处理后的能量值。
[0168]
当然,本公开实施例中对平滑阶数并不进行限制。
[0169]
例如,参阅图4所示,为本公开实施例中平滑处理后的能量值分布的第二示意图,如图4可知,对每个音频帧对应的能量值进行平滑处理后,使得由每个音频帧处理后的能量值的分布具有明显的波峰和波谷。波峰即为本公开实施例中的最高换气帧,波谷分别为本公开实施例中的第一最低换气帧和第二最低换气帧。
[0170]
这样,根据发声原理,吸气呼气存在一个上升下降的过程,这个过程可以用平滑后的能量值来模拟,本公开实施例中,平滑处理的作用是为了去除掉能量值分布的毛刺,让能量值分布的走势更清晰地反映换气声的发声原理,也即吸气时能量上升,呼气时能量下降。
[0171]
在对待处理音频的各音频帧对应的能量值进行平滑处理之后,获得处理后的待处理音频帧对应的能量值,由于待处理音频的起始帧和终止帧之间包含有多个音频帧,因此,以最高换气帧为中心点,从待处理音频的起始帧和最高换气帧之间的各音频帧中,确定出
满足最低能量值条件的第一最低换气帧,以及,从最高换气帧与待处理音频的终止帧之间的各音频帧中,确定出满足该最低能量值条件的第二最低换气帧。下面对本公开实施例中确定第一最低换气帧和第二最低换气帧的步骤进行详细阐述,具体包括:
[0172]
a1:将待处理音频的起始帧与最高换气帧之间的各音频帧,作为第一候选音频,并将最高换气帧与待处理音频的结束帧之间的各音频帧作为第二候选音频。
[0173]
本公开实施例中,将待处理音频包含的各音频帧中,时间点信息最小的音频帧作为该待处理音频的起始帧,并将待处理音频包含的各音频帧中,时间点信息最大的音频帧作为该待处理音频的终止帧。然后,将待处理音频的起始帧与最高换气帧之间的各音频帧,作为待处理音频的第一候选音频,并将最高换气帧与待处理音频的终止帧之间的各音频帧,作为待处理音频的第二候选音频。
[0174]
需要说明的是,本公开实施例中,是从第一候选音频中确定出第一最低换气帧的,并且,是从第二候选音频中确定出第二最低换气帧的。
[0175]
a2:从第一候选音频的各音频帧中,确定出能量值小于前一音频帧且小于后一音频帧的音频帧,并将确定出的各音频帧中时间点信息最大的音频帧作为第一最低换气帧;以及,从第二候选音频的各音频帧中,确定出能量值小于前一音频帧且小于后一音频帧的音频帧,并将确定出的各音频帧中时间点信息最小的音频帧作为第二最低换气帧。
[0176]
本公开实施例中,确定第一候选音频的各音频帧,并从各音频中,确定出能量值小于前一音频帧,且该能量值小于后一音频帧对应的音频帧,并将确定出的各音频帧中,时间点信息最大的音频帧作为第一最低换气帧。同时,确定第二候选音频的各音频帧,并从各音频帧中,确定出能量值小于前一音频帧,且该能量值小于后一音频帧对应的音频帧,并将确定出的各音频帧中,时间点信息最小的音频帧作为第二最低换气帧。
[0177]
例如,如图4所示,波峰为最高换气帧,从波峰对应的音频帧往左,为第一候选音频,开始往左对逐个音频帧进行遍历,从而确定出左波谷的位置,也即在第一候选音频中能量值最小对应的音频帧,并将该音频帧作为第一最低换气帧。同时,从波峰对应的音频帧往右,为第二候选音频,开始往右对逐个音频帧进行遍历,从而确定出右波谷的位置,也即在第二候选音频中能量值最小对应的音频帧,并将该音频帧作为第二最低换气帧。
[0178]
其中,第一最低换气帧为准确的换气声左边界,第二最低换气帧为准确的换气声右边界。
[0179]
这样,本公开实施例中,通过对各音频帧对应的能量值进行平滑处理,并根据平滑处理后的能量值修正换气声边界,能够提高换气声检测的准确性。
[0180]
步骤230:将第一最低换气帧和第二最低换气帧之间的各音频帧,作为原始音频的目标音频。
[0181]
其中,目标音频表征边界修正后的换气声。
[0182]
本公开实施例中,在获得第一最低换气帧和第二最低换气帧之后,将第一换气帧和第二换气帧之间的各音频帧,作为原始音频的目标音频,也即确定出的边界修正后的换气声。
[0183]
例如,如图4所示,黑色线条为检测出的真实换气声的区域。
[0184]
本公开实施例中,用对待处理音频的各音频帧对应的能量值进行平滑处理,从而修正换气声边界,以达到边界和实际换气声吻的目的,因此,通过本公开实施例中的这种方
法,能够提高换气声检测的准确性。
[0185]
基于上述实施例,在获得目标音频之后,目标音频中有可能还会存在被误检为换气声的清齿音,因此,需要将被误检为换气声的清齿音剔除,下面对本公开实施例中筛选掉清齿音的步骤进行详细阐述,参阅图5所示,为本公开实施例中删除清齿音的方法的流程图,具体包括:
[0186]
步骤500:确定目标音频的各换气帧对应的锐度值。
[0187]
其中,锐度值表征音频帧的声音信号的尖锐程度。
[0188]
本公开实施例中,根据实验可知,误检的换气声几乎均为包含齿音的清齿音,因此,可以通过计算目标音频的各换气帧对应的锐度值,从而确定出被误检为换气声的清齿音。因此,确定目标音频的各换气帧对应的锐度值。
[0189]
可选的,本公开实施例中对确定锐度值的方法提供了一种可能的实施方式,具体可以表示为:
[0190][0191]
其中,s
a
为锐度值,n'(z)为特征响度值,g
a
(z)为加权函数,z为临界频带,accum为锐度值的单位。
[0192]
步骤510:根据各锐度值,确定目标音频是否为正确检测出的换气声。
[0193]
本公开实施例中,由于清齿音的锐度值较高,因此,可以根据目标音频的各音频帧对应的锐度值,确定目标音频是否为正确检测出的换气声。
[0194]
可选的,本公开实施例中,为确定目标音频是否为正确检测出的换气声提供了一种可能的实施方式,下面对各锐度值,确定目标音频是否为正确检测出的换气声的过程进行详细阐述,具体包括:
[0195]
s5101:从目标音频的各换气帧中筛选出锐度值高于锐度值阈值的换气帧。
[0196]
本公开实施例中,由于误检的换气声几乎都是包含齿音的清齿音,因此,根据换气帧的锐度值,确定出齿音位置,并判断齿音位置与换气声是否有交集,有交集的部分被认为是齿音,而并非换气声。因此,分别确定目标音频的各换气帧的锐度值是否高于锐度值阈值,以获得锐度值检测结果,并从锐度值检测结果中,筛选出锐度值高于锐度值阈值的换气帧。
[0197]
例如,假设锐度值阈值为950,将锐度值高于950的换气帧作为出现了齿音的换气帧。
[0198]
s5102:若确定目标音频中不存在预设连续数个高于锐度值阈值的换气帧,则确定目标音频为正确检测出的换气声。
[0199]
本公开实施例中,在获得高于锐度值阈值的换气帧之后,由于数量较少的连续个高于锐度值阈值的换气帧无法组成清齿音,因此,判断目标音频中是否存在预设连续数个高于锐度值阈值的换气帧,若确定目标音频中存在预设连续数个高于锐度值阈值的换气帧,则确定目标音频为误检为换气声的清齿音,若确定目标音频中不存在预设连续数个高于锐度值阈值的换气帧,则确定目标音频为正确检测出的换气声。
[0200]
例如,参阅图6所示,为本公开实施例中锐度值分布示意图,图中生成的曲线为锐
度值分布,假设共检测到两处真实的换气声,分别为换气声1和换气声2,假设确定出的换气声1中并未存在连续5个高于锐度值阈值的换气帧,确定出的换气声2中的连续5个换气帧的锐度值高于预设锐度值阈值,则可以确定换气声1为正确检测出的真实换气声,第二处为误检为换气声的清齿音字母“c”。
[0201]
本公开实施例中,由于误检的换气声几乎都是包含齿音的清齿音。因此,根据目标音频所包含的换气帧对应的锐度值,确定目标音频是否为正确检测出的换气帧,能够判断换气声是否误检,从而提高换气声检测的准确性。
[0202]
基于上述实施例,参阅图7所示,为本公开实施例中一种音频检测方法的另一流程图,具体包括:
[0203]
步骤700:对原始音频进行时域分帧,获得各音频帧。
[0204]
本公开实施例中,原始音频为包含有人声区域和非人声区域的音频。
[0205]
步骤701:基于已训练的第一音频检测模型,以各音频帧为输入参数,通过第一音频检测模型中的人声检测网络,从原始音频中确定出待处理音频,并通过第一音频检测模型中的静音检测网络,筛选掉待处理音频中的静音音频,获得处理后的待处理音频。
[0206]
其中,第一音频检测模型用于检测出原始音频中包含有换气声的待处理音频。
[0207]
本公开实施例中,将各音频帧输入至已训练的第一音频检测模型的人声检测网络中,通过人声检测网络,从原始音频中确定出待处理音频,并通过静音检测网络,筛选掉待处理音频中的静音音频,从而获得处理后的待处理音频。
[0208]
其中,在筛选待处理音频中的静音音频时,可以先确定待处理音频中的各音频帧对应的能量值和时域分布的时间点信息,并从各音频帧中确定出不小于预设能量值阈值的音频帧,并将小于预设能量值阈值的音频帧所组成的静音音频删除,从而获得处理后的待处理音频。
[0209]
步骤702:分别对待处理音频的各音频帧进行特征提取,确定各音频特征。
[0210]
本公开实施例中,各音频帧对应的音频特征例如可以为mfcc特征。
[0211]
步骤703:分别针对待处理音频的各音频帧,基于已训练的第二音频检测模型,以任意一帧音频帧的音频特征为输入参数,确定该音频帧是否为换气帧。
[0212]
步骤704:将高于数量阈值的连续数个换气帧组成初始目标音频。
[0213]
本公开实施例中,初始目标音频为初步检测出的换气声,但该换气声的边界不准确。
[0214]
步骤705:从初始目标音频的各换气帧中确定出能量值取值最大的最高换气帧。
[0215]
本公开实施例中,将能量值取值最大的换气帧,作为初始目标音频中确定出的最高换气帧。
[0216]
步骤706:分别对待处理音频的各音频帧对应的能量值进行平滑处理。
[0217]
本公开实施例中,分别对待处理音频的各音频帧对应的能量值进行平滑处理。
[0218]
步骤707:从待处理音频的起始帧与最高换气帧之间的各音频帧中,确定出满足最低能量值条件的第一最低换气帧,以及,从最高换气帧与待处理音频的终止帧之间的各音频帧中,确定出满足最低能量值条件的第二最低换气帧。
[0219]
本公开实施例中,从待处理音频的起始帧至最高换气帧之间,确定出能量值取值最小的音频帧,作为第一最低换气帧,并从最高换气帧至待处理音频的终止帧之间,确定出
能量值取值最小的音频帧,作为第二最低换气帧。
[0220]
步骤708:将第一最低换气帧和第二最低换气帧之间的各音频帧,作为原始音频的目标音频。
[0221]
步骤709:确定目标音频的各换气帧对应的锐度值。
[0222]
其中,锐度值表征音频帧的声音信号的尖锐程度。
[0223]
本公开实施例中,由于清齿音包含的齿音对应的锐度值较高,因此,可以确定目标音频的各换气帧对应的锐度值,并筛选出高于锐度值阈值的音频帧。
[0224]
步骤710:从目标音频的各换气帧中筛选出锐度值高于锐度值阈值的换气帧。
[0225]
本公开实施例中,从目标音频的各换气帧中筛选出高于锐度值阈值的换气帧,这些换气帧可以认定为齿音。
[0226]
步骤711:若确定目标音频中不存在预设连续数个高于锐度值阈值的换气帧,则确定目标音频为正确检测出的换气声。
[0227]
本公开实施例中,通过对音频帧的能量值进行平滑处理,修正换气声的边界,以达到边界与实际换气声吻合的目的,并且,通过换气帧的锐度值,从而判断换气声是否误检,结合修正换气声边界和判断换气声是否误检,对换气声进行检测,能够进一步提高换气声检测的准确性,从而能够应用到对歌唱人声的换气声消除美化的场景中,准确的换气声检测可以确保换消除美化不会误伤人声;还可应用于确定演唱过程中气口开始和闭合位置的场景中,结合原唱的歌词时间信息,可以确定哪些位置该不该换气,进而评价演唱者的气息控制能力在k歌气息打分和演唱教学方面均可应用,可应用到多种场景中,具有广泛的应用价值。
[0228]
基于同一发明构思,本公开实施例中还提供了一种音频检测装置,该音频检测装置可以是硬件结构、软件模块、或硬件结构加软件模块,该音频检测装置实施例可以继承前述方法实施例描述的内容。基于上述实施例,参阅图8所示为本公开实施例中音频检测装置的结构示意图,具体包括:
[0229]
第一确定模块800,用于从原始音频中确定出待处理音频,以及所述待处理音频的各音频帧对应的能量值和时域分布的时间点信息,并从所述待处理音频中确定出初始目标音频,其中,所述待处理音频为包含有换气声的非人声音频,所述初始目标音频表征初步检测出的换气声;
[0230]
第二确定模块810,用于从所述初始目标音频的各换气帧中确定出能量值满足最高能量值条件的最高换气帧,其中,所述初始目标音频由至少一帧换气帧组成;
[0231]
第一处理模块820,用于分别对所述待处理音频的各音频帧对应的能量值进行平滑处理,并从所述待处理音频的起始帧与所述最高换气帧之间的各音频帧中,确定出满足最低能量值条件的第一最低换气帧,并从所述最高换气帧与所述待处理音频的终止帧之间的各音频帧中,确定出满足最低能量值条件的第二最低换气帧;
[0232]
第三确定模块830,用于将所述第一最低换气帧和所述第二最低换气帧之间的各音频帧,作为所述原始音频的目标音频,其中,所述目标音频表征边界修正后的换气声。
[0233]
可选的,分别对所述待处理音频的各音频帧对应的能量值进行平滑处理时,第一处理模块820具体用于:
[0234]
分别针对所述待处理音频的各音频帧,根据预设的平滑阶数和各音频帧的时间点
信息,确定任意一音频帧对应的预设数个音频帧,根据所述预设数个音频帧的能量值之和,与所述平滑阶数之间的比值,确定该音频帧的处理后的能量值。
[0235]
可选的,从所述待处理音频的起始帧与所述最高换气帧之间的各音频帧中,确定出满足最低能量值条件的第一最低换气帧,并从所述最高换气帧与所述待处理音频的终止帧之间的各音频帧中,确定出满足最低能量值条件的第二最低换气帧时,第一处理模块820具体用于:
[0236]
将所述待处理音频的起始帧与所述最高换气帧之间的各音频帧,作为第一候选音频,并将所述最高换气帧与所述待处理音频的结束帧之间的各音频帧作为第二候选音频;
[0237]
从所述第一候选音频的各音频帧中,确定出所述能量值小于前一音频帧且小于后一音频帧的音频帧,并将确定出的各音频帧中时间点信息最大的音频帧作为第一最低换气帧;以及,
[0238]
从所述第二候选音频的各音频帧中,确定出能量值小于前一音频帧且小于后一音频帧的音频帧,并将确定出的各音频帧中时间点信息最小的音频帧作为第二最低换气帧。
[0239]
可选的,将所述第一最低换气帧和所述第二最低换气帧之间的各音频帧,作为所述原始音频的目标音频之后,还包括:
[0240]
第四确定模块840,用于确定所述目标音频的各换气帧对应的锐度值,其中,所述锐度值表征音频帧的声音信号的尖锐程度;
[0241]
判断模块850,用于根据各锐度值,确定所述目标音频是否为正确检测出的换气声。
[0242]
可选的,判断模块850具体用于:
[0243]
从所述目标音频的各换气帧中筛选出锐度值高于锐度值阈值的换气帧;
[0244]
若确定所述目标音频中不存在预设连续数个高于所述锐度值阈值的换气帧,则确定所述目标音频为正确检测出的换气声。
[0245]
可选的,第二确定模块810具体用于:
[0246]
从所述初始目标音频的各换气帧中,确定出能量值最高的换气帧;
[0247]
将确定出的换气帧作为所述初始目标音频中的最高换气帧。
[0248]
可选的,从原始音频中确定出待处理音频时,第一确定模块800具体用于:
[0249]
对原始音频进行时域分帧,获得各音频帧;
[0250]
对原始音频进行时域分帧,获得各音频帧;
[0251]
基于已训练的第一音频检测模型,以所述各音频帧为输入参数,通过所述第一音频检测模型中的人声检测网络,从所述原始音频中确定出待处理音频,并通过所述第一音频检测模型中的静音检测网络,筛选掉所述待处理音频中的静音音频,获得处理后的待处理音频,其中,所述第一音频检测模型用于检测出所述原始音频中包含有换气声的待处理音频。
[0252]
可选的,通过所述第一音频检测模型中的静音检测网络,筛选掉所述待处理音频中的静音音频,获得处理后的待处理音频时,第一确定模块800具体用于:
[0253]
确定所述待处理音频中的各音频帧对应的能量值和时域分布的时间点信息;
[0254]
从所述待处理音频中的各音频帧中确定出大于等于预设能量值阈值的音频帧;
[0255]
将所述小于所述能量值阈值的音频帧组成静音音频;
[0256]
从所述待处理音频中去除所述静音音频,获得处理后的待处理音频。
[0257]
可选的,获得处理后的待处理音频之后,进一步包括:
[0258]
特征提取模块860,用于分别对所述待处理音频的各音频帧进行特征提取,确定各音频特征;
[0259]
第二处理模块870,用于分别针对所述待处理音频的各音频帧,基于已训练的第二音频检测模型,以任意一帧音频帧的音频特征为输入参数,确定该音频帧是否为换气帧,其中,所述第二音频检测模型用于检测所述待处理音频中的音频帧是否为换气帧;
[0260]
组合模块880,用于将高于数量阈值的连续数个换气帧组成初始目标音频。
[0261]
基于上述实施例,参阅图9所示为本公开实施例中电子设备的结构示意图。
[0262]
本公开实施例提供了一种电子设备,该电子设备可以包括处理器910(center processing unit,cpu)、存储器920、输入设备930和输出设备940等,输入设备930可以包括键盘、鼠标、触摸屏等,输出设备940可以包括显示设备,如液晶显示器(liquid crystal display,lcd)、阴极射线管(cathode ray tube,crt)等。
[0263]
存储器920可以包括只读存储器(rom)和随机存取存储器(ram),并向处理器910提供存储器920中存储的程序指令和数据。在本公开实施例中,存储器920可以用于存储本公开实施例中任一种音频检测方法的程序。
[0264]
处理器910通过调用存储器920存储的程序指令,处理器910用于按照获得的程序指令执行本公开实施例中任一种音频检测方法。
[0265]
基于上述实施例,本公开实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任意方法实施例中的音频检测方法。
[0266]
本领域内的技术人员应明白,本公开的实施例可提供为方法、系统、或计算机程序产品。因此,本公开可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本公开可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd
‑
rom、光学存储器等)上实施的计算机程序产品的形式。
[0267]
本公开是参照根据本公开的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0268]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0269]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一
个方框或多个方框中指定的功能的步骤。
[0270]
显然,本领域的技术人员可以对本公开进行各种改动和变型而不脱离本公开的精神和范围。这样,倘若本公开的这些修改和变型属于本公开权利要求及其等同技术的范围之内,则本公开也意图包含这些改动和变型在内。