1.本发明涉及声纹识别领域,具体的说,涉及一种说话人识别方法及系统。
背景技术:
2.声纹识别作为一种重要的生物特征识别方式广泛的应用于安全领域、医疗领域、金融领域以及智能家居中。在声纹识别中,输入到网络中的特征谱图的质量好坏在提高声纹识别的准确率上起着重要的作用,目前主流的mfcc、gfcc、lpcc等谱图通常是将在时域上的语音信息使用傅里叶变换得到线性特征谱图然后再经过不同的滤波器而得到的。
3.由傅里叶变换得到的特征谱图的时间分辨率与频率分辨率受到傅里叶变换窗长的长度影响较大,傅里叶变换窗长越长,生成的谱图的时间分辨率越差,频率分辨率越好,反之亦然。传统的特征谱图生成方法都是在单一恒定的傅里叶变换窗长下得到的,其时间分辨率和频率分辨率一定,因此其无法很好的表达在不同时间分辨率,频率分辨率下的信息,可能会导致时域、频域信息的流失。因此目前的声纹识别算法无法很好的满足说话人识别的需求,其识别准确率有待提高。
技术实现要素:
4.本发明针对现有技术存在的不足,提供了一种说话人识别方法及系统,基于多分辨谱图特征注意力融合网络,有效的解决了在使用单一傅里叶变换窗长的情况下所造成的时间分辨率和频率分辨率精度不足的问题,提高了声纹识别的准确率。
5.本发明的具体技术方案如下:
6.本发明的其中一个技术方案是一种说话人识别方法及系统,包括以下步骤:
7.步骤1:对原始音频进行采样处理;
8.步骤2:对步骤1经采样处理后的数据进行预处理,
9.所述预处理包括:
10.端点检测,去除语音信号静音和噪声片段;
11.预加重,补偿语音信号高频分量;
12.分帧,从非稳态的长段语音中截取小段稳态的短语音;
13.步骤3:基于多个不同窗长的短时傅里叶变换对所述步骤2预处理后的数据进行处理得到多个线性谱图;对所述步骤2处理后的数据分别使用不同窗长的短时傅里叶变换处理得到多个线性谱图;
14.步骤4:将所述多个线性谱图分别通过梅尔滤波器组滤波得到多个梅尔谱图;
15.步骤5:通过训练网络对所述多个梅尔谱图分别进行训练,得到多个特征向量;
16.步骤6:同时在所述训练网络后添加通道注意力模块,然后对所述多个梅尔谱图分别进行训练,得到多个最优的特征通道权重;
17.步骤7:加权融合所述多个特征向量和所述特征通道权重,得到融合特征向量
18.步骤8:将所述融合特征向量与数据库中的特征向量进行余弦相似度计算后与预设阈值相比较,判定出说话人。
19.作为优选,所述步骤3对所述步骤2处理后的数据分别使用不同窗长的短时傅里叶变换处理得到多个线性谱图中,根据以下方式获得线性谱图:
[0020][0021]
其中x(m)为m时刻的信号,ω(n
‑
m)为窗函数,n代表当前位置。
[0022]
作为优选,所述步骤4中的梅尔滤波器组中的梅尔刻度和频率的关系如下所示:
[0023][0024]
其中,f
mel
是以mel为单位的感知频率,f是以hz为单位的实际频率。
[0025]
4.如权利要求1所述的一种说话人识别方法及系统,其特征在于:所述步骤6中的通道注意力模块按照以下方式训练:
[0026][0027]
其中m
c
(f)为通道注意力权重,σ为sigmoid函数,mlp为多层感知机,f为输入的feature map,w1和w0为权值,和分别是feature map在通道上的平均池化和最大池化。
[0028]
作为优选,多个特征向量包括特征向量特征向量特征向量特征向量多个特征通道权重包括特征通道权重特征通道权重特征通道权重特征通道权重所述步骤7中,将特征向量和所述步骤6中的得到的特征通道权重进行加权融合,得到融合特征向量
[0029]
作为优选,所述步骤8中融合特征向量与数据库中已有的特征向量根据以下方式进行余弦相似度计算:
[0030][0031]
其中,d为余弦距离。
[0032]
根据d与阈值的大小来判定出说话人。
[0033]
本发明的另一技术方案是一种基于多分辨谱图特征注意力融合网络的说话人识别系统,包括:
[0034]
采样模块:用于采样处理原始音频;
[0035]
预处理模块:用于对采样模块处理后的数据进行预处理,
[0036]
所述预处理模块包括:
[0037]
端点检测单元,用于去除语音信号静音和噪声片段;
[0038]
预加重单元,用于补偿语音信号高频分量;
[0039]
分帧单元,用于从非稳态的长段语音中截取小段稳态的短语音;
[0040]
傅里叶变换模块:用于对所述预处理模块处理后的数据分别使用不同窗长的短时傅里叶变换处理得到多个线性谱图;
[0041]
梅尔滤波器组:用于将多个线性谱图分别通过梅尔滤波器组滤波得到多个梅尔谱图;
[0042]
第一训练模块:用于对每个梅尔谱图进行训练,得到多个特征向量;
[0043]
第二训练模块:用于训练出多个最优的特征通道权重;
[0044]
加权融合模块:用于加权融合所述第一训练模块训练得到的特征向量和所述第二训练模块训练得到的特征通道权重,得到融合特征向量
[0045]
判别模块:用于将融合特征向量与数据库中的特征向量进行余弦相似度计算后与阈值相比较,判定出说话人。
[0046]
作为优选,所述梅尔滤波器组中的梅尔刻度和频率的关系如下所示:
[0047][0048]
其中,f
mel
是以mel为单位的感知频率,f是以hz为单位的实际频率。
[0049]
作为优选,所述判别模块根据以下方式进行余弦相似度计算:
[0050][0051]
其中,d为余弦距离。
[0052]
作为优选,所述第二训练模块包括第一训练模块和通道注意力模块。
[0053]
有益效果在于:
[0054]
本发明使用不同傅里叶窗长尺度上提取了不同时间分辨率和频率分辨率精度的梅尔谱图并进行融合,弥补了单一傅里叶窗长尺度下所照成的时间分辨率和频率分辨率精度不足的问题,从而提高了声纹识别的准确率。
附图说明
[0055]
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍。在所有附图中,类似的元件或部分一般由类似的附图标记标识。附图中,各元件或部分并不一定按照实际的比例绘制。
[0056]
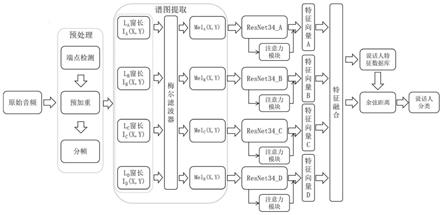
图1为本发明方法的总体结构图;
[0057]
图2为梅尔滤波器组示意图;
[0058]
图3为梅尔谱图特征提取流程图;
[0059]
图4为通道注意力模块的网络结构图;
[0060]
图5为多分辨谱图特征与单一分辨谱图特征的准确率变换曲线图。
具体实施方式
[0061]
下面将对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0062]
需要说明的是,本发明实施例中所有方向性指示(诸如上、下、左、右、前、后
……
)仅用于解释在某一特定姿态(如附图所示)下各部件之间的相对位置关系、运动情况等,如果该特定姿态发生改变时,则该方向性指示也相应地随之改变。
[0063]
另外,在本发明中如涉及“第一”、“第二”等的描述仅用于描述目的,而不能理解为指示或暗示其相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
[0064]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定发明。
[0065]
现在结合说明书附图对本发明做进一步的说明。
[0066]
本发明实施例,如图1所示,本发明提供一种说话人识别方法及系统,包括以下步骤:
[0067]
1、加载原始音频,对原始音频数据进行预处理,预处理过程为:
[0068]
a1:对原始语音数据采样量化,本方法的采样频率为16000hz;
[0069]
a2:端点检测,通过判断短时能量的大小来去除静音点,短时能量计算公式如公式1所示:
[0070][0071]
其中x(n)为语音信号,w(n)为窗函数,当e
n
小于10db时判定为静音片段。
[0072]
a3:预加重,为了弥补声音信号在空气中辐射传播导致的高频分量的损失,本方法通过预加重的方式对声音的高频信号进行补偿,补偿公式如公式2所示:
[0073]
y(n)=x(n)
‑
a*x(n
‑
1)
ꢀꢀꢀꢀꢀꢀ
(2)
[0074]
其中,a为预加重系数,通常可以取0.9<a<1.0。
[0075]
a4:分帧,长语音信号是不稳定的,故使用分帧的方式来截取一小段稳态语音,帧长取20ms,并且为了使特征参数平滑地变化,设置在相邻的两帧之间有重叠部分为1/2。
[0076]
2、抽取预处理后的语音数据在不同短时傅里叶变换(stft)时窗下的梅尔谱图特征,具体步骤如下:
[0077]
a1:抽取语音信号在不同短时傅里叶变换(stft)时窗下的线性频谱特征。其公式可表示为:
[0078][0079]
式中t为采样周期,x(k)为k时刻的信号,γ(kt
‑
mt)为窗函数,分别取长度为l
a
、l
b
、l
c
、l
c
的窗函数长度对语音信号进行处理得到语音信号的线性谱图i
a
(x,y)、i
b
(x,y)、i
c
(x,y)、i
d
(x,y);
[0080]
a2:将a1中得到的线性频谱i
a
(x,y)、i
b
(x,y)、i
c
(x,y)、i
d
(x,y)分别通过梅尔滤波器组过滤得到不同窗长的梅尔谱图mel
a
(x,y)、mel
b
(x,y)、mel
c
(x,y)、mel
d
(x,y)。梅尔刻度和频率的关系如下所示:
[0081][0082]
f
mel
是以mel为单位的感知频率,f是以hz为单位的实际频率。梅尔滤波器组如图2所示;
[0083]
3、将梅尔谱图mel
a
(x,y)、mel
b
(x,y)、mel
c
(x,y)、mel
d
(x,y)分别放入resnet34网络训练出resnet34_a,resnet34_b,resnet34_c,resnet34_d得到特征向量其中resnet34网络的结构如表1所示:
[0084][0085]
表1
[0086]
在resnet34网络结构中的fc(fully connected layer)之前加入通道注意力模块,使网络能够训练出最优的特征通道权重通道注意力模块训练的表达式为:
[0087][0088]
其中m
c
(f)为通道注意力权重,σ为sigmoid函数,mlp为多层感知机,f为输入的feature map,w1和w0为权值,和分别是feature map在通道上的平均池化和最大池化。
[0089]
通道注意力模块的网络结构为图4所示。
[0090]
4、将特征向量使用通道权重进行加权融合得到融合特征向量
[0091]
5、将融合特征向量与数据库中已有的特征向量进行余弦相似度计算如公式6所示:
[0092][0093]
其中d为余弦距离。
[0094]
根据d与阈值的大小来判定出说话人。
[0095]
本方法使用的数据集为free st chinesemandarin corpus中文数据集,数据集中共包含855人,每人120条语音,使用855人中的90%作为训练集,10%作为测试集,使用本方法后的测试结果相对于使用单一傅里叶变换窗长生成的单一分辨率谱图的准确率提高了2%~3%,其准确率变换曲线如图5所示。
[0096]
以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。