1.本技术涉及音频数据处理技术领域,特别是涉及一种用于智能客服的语音处理方法、装置、计算机设备和存储介质。
背景技术:
2.智能客服中的语音导航是综合利用自动语音识别(automatic speech recognition,asr)、文字转语音(text to speech,tts)和自然语言理解(natural language understanding,nlu)技术,并面向用户提供的一款电话机器人产品。语音导航在传统的热线电话中加入了语音业务自助办理/语音问答功能,可有效的处理常规业务场景,大幅减少人工热线电话客服压力。
3.传统的语音导航中,会采用gmm-hmm作为语音识别模型,该gmm-hmm模型通常包括声学模型、发音词典和语言模型。每一部分都需要单独的学习训练。
4.但是,采用传统的gmm-hmm模型,无法很好地建模不同语言之间声学属性的联系,导致语音识别的准确性较低。
技术实现要素:
5.基于此,有必要针对上述技术问题,提供一种能够提高客服过程中语音识别的准确性的用于智能客服的语音处理方法、装置、计算机设备和存储介质。
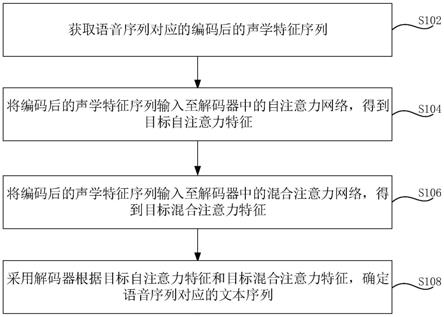
6.一种用于智能客服的语音处理方法,所述方法包括:
7.获取语音序列对应的编码后的声学特征序列;
8.将所述编码后的声学特征序列输入至解码器中的自注意力网络,得到目标自注意力特征;
9.将所述编码后的声学特征序列输入至所述解码器中的混合注意力网络,得到目标混合注意力特征;
10.采用所述解码器根据所述目标自注意力特征和所述目标混合注意力特征,确定所述语音序列对应的文本序列。
11.在其中一个实施例中,所述解码器的数量为多个,所述多个解码器串行连接;
12.所述将所述编码后的声学特征序列输入至解码器中的自注意力网络,得到目标自注意力特征,包括:
13.将所述编码后的声学特征序列输入至第一个解码器中的自注意力网络,得到第一个自注意力特征;
14.将所述第一个自注意力特征输入至下一个解码器中的自注意力网络,以此类推,直至最后一个解码器中的自注意力网络输出最后一个自注意力特征;
15.将所述最后一个自注意力特征确定为目标自注意力特征;
16.所述将所述编码后的声学特征序列输入至所述解码器中的混合注意力网络,得到目标混合注意力特征,包括:
17.将所述编码后的声学特征序列输入至所述第一个解码器中的混合注意力网络,得到第一个混合注意力特征;
18.将所述第一个混合注意力特征和所述第一个自注意力特征输入至所述下一个解码器中的混合注意力网络,以此类推,直至所述最后一个解码器中的混合注意力网络输出最后一个混合注意力特征;
19.将所述最后一个混合注意力特征确定为目标混合注意力特征。
20.在其中一个实施例中,所述采用所述解码器根据所述目标自注意力特征和所述目标混合注意力特征,确定所述语音序列对应的文本序列,包括:
21.采用所述解码器对所述目标自注意力特征和所述目标混合注意力特征进行拼接,得到拼接后的特征;
22.采用所述解码器根据所述拼接后的特征,确定所述语音序列对应的文本序列。
23.在其中一个实施例中,所述采用所述解码器根据所述拼接后的特征,确定所述语音序列对应的文本序列,包括:
24.采用所述解码器将所述拼接后的特征与所述编码后的声学特征序列进行相加,得到相加后的特征;
25.采用所述解码器根据所述相加后的特征,确定所述语音序列对应的文本序列。
26.在其中一个实施例中,所述方法还包括:
27.响应于用户的客服请求,播报需求引导语,并采集包含业务需求信息的所述语音序列。
28.在其中一个实施例中,所述方法还包括:
29.根据所述文本序列,确定是否开启对应语种类型的人工客服模式;
30.若是,则开启对应语种类型的人工客服模式;
31.若否,则开启对应语种类型的智能客服模式,并播报与所述文本序列相匹配的业务信息。
32.在其中一个实施例中,所述解码器的训练过程包括:
33.获取语音序列样本对应的编码后的声学特征序列样本和所述语音序列样本对应的文本序列样本;
34.将所述声学特征序列样本作为输入数据,对初始化的解码器中自注意力网络和混合注意力网络进行训练,其中,所述初始化的解码器的输出数据为预测文本序列,所述初始化的解码器的损失函数是基于所述预测文本序列和所述文本序列样本构建的。
35.一种用于智能客服的语音处理装置,所述装置包括:
36.声学特征获取模块,用于获取语音序列对应的编码后的声学特征序列;
37.自注意力模块,用于将所述编码后的声学特征序列输入至解码器中的自注意力网络,得到目标自注意力特征;
38.混合注意力模块,用于将所述编码后的声学特征序列输入至所述解码器中的混合注意力网络,得到目标混合注意力特征;
39.文本序列确定模块,用于采用所述解码器根据所述目标自注意力特征和所述目标混合注意力特征,确定所述语音序列对应的文本序列。
40.一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理
器执行所述计算机程序时实现以下步骤:
41.获取语音序列对应的编码后的声学特征序列;
42.将所述编码后的声学特征序列输入至解码器中的自注意力网络,得到目标自注意力特征;
43.将所述编码后的声学特征序列输入至所述解码器中的混合注意力网络,得到目标混合注意力特征;
44.采用所述解码器根据所述目标自注意力特征和所述目标混合注意力特征,确定所述语音序列对应的文本序列。
45.一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
46.获取语音序列对应的编码后的声学特征序列;
47.将所述编码后的声学特征序列输入至解码器中的自注意力网络,得到目标自注意力特征;
48.将所述编码后的声学特征序列输入至所述解码器中的混合注意力网络,得到目标混合注意力特征;
49.采用所述解码器根据所述目标自注意力特征和所述目标混合注意力特征,确定所述语音序列对应的文本序列。
50.上述用于智能客服的语音处理方法、装置、计算机设备和存储介质,首先获取语音序列对应的编码后的声学特征序列,然后将编码后的声学特征序列输入至解码器中的自注意力网络,得到目标自注意力特征,以及将编码后的声学特征序列输入至解码器中的混合注意力网络,得到目标混合注意力特征,最后采用解码器根据目标自注意力特征和目标混合注意力特征,确定语音序列对应的文本序列。采用基于编码-解码框架的语音识别模型,无需对声学单元进行建模,而是采用自注意力特征和混合注意力特征进行建模,模糊了建模单元与声学属性之间的联系,并且由于编码-解码框架能够考虑上下帧之间的信息,可以有效地建模语言转换点的声学属性,有利于大幅提升语音识别的准确性。
附图说明
51.图1为一个实施例中用于智能客服的语音处理方法的流程示意图;
52.图2为一个实施例中中英文混合语音识别模型的示意图;
53.图3为一个实施例中单头(head)self-and-mixed mha的示意图;
54.图4为一个实施例中用于智能客服的语音处理装置的结构框图;
55.图5为一个实施例中计算机设备的内部结构图。
具体实施方式
56.为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
57.在一个实施例中,如图1所示,提供了一种用于智能客服的语音处理方法,本实施例以该方法应用于终端进行举例说明,可以理解的是,该方法也可以应用于服务器,还可以
应用于包括终端和服务器的系统,并通过终端和服务器的交互实现。本实施例中,该方法包括以下步骤:
58.步骤s202,获取语音序列对应的编码后的声学特征序列。
59.具体地,首先,获取初始的语音序列。然后,提取该语音序列的梅尔频率倒谱系数(mel frequency cepstral coefficients,mfcc),得到语音序列对应的声学特征(acoustic features)序列。之后,将该声学特征序列输入至编码器中,得到语音序列对应的编码后的声学特征序列。
60.可选地,为了节约计算资源,先对语音序列对应的声学特征序列进行下采样(down sampling),得到下采样后的声学特征序列,然后将该下采样后的声学特征序列输入至编码器中,得到语音序列对应的编码后的声学特征序列。在一个实施例中,下采样采用了3
×
3步长为2的卷积神经网络(cnn),以此减少输入语音序列的长度,并降低图形处理器(gpu)的显存占用。
61.可选地,为了加入声学特征序列的时序信息,通过位置编码(postional encoding)在语音序列对应的声学特征序列中添加时序信息,然后将该声学特征序列和时序信息输入至编码器中,得到语音序列对应的编码后的声学特征序列。另外,也可以通过位置编码(postional encoding)在下采样后的声学特征序列中添加时序信息,然后将该下采样后的声学特征序列和时序信息输入至编码器中,得到语音序列对应的编码后的声学特征序列。
62.步骤s204,将编码后的声学特征序列输入至解码器中的自注意力网络,得到目标自注意力特征。
63.其中,自注意力网络中采用了自注意力(self-attention)机制。自注意力机制可以用于处理声学表征。
64.具体地,将编码后的声学特征序列输入至解码器中的自注意力网络,自注意力网络输出目标自注意力特征。其中,自注意力网络为预先训练好的神经网络。
65.步骤s206,将编码后的声学特征序列输入至解码器中的混合注意力网络,得到目标混合注意力特征。
66.其中,混合注意力网络中采用了混合注意力(mixed-attention)机制。混合注意力机制用于学习声学特征序列与文本序列(即语言学表征)之间联系,例如可以用于计算声学特征序列与输出的文本序列间的对齐。
67.具体地,将编码后的声学特征序列输入至解码器中的混合注意力网络,混合注意力网络输出目标混合注意力特征。其中,混合注意力网络为预先训练好的神经网络。
68.步骤s208,采用解码器根据目标自注意力特征和目标混合注意力特征,确定语音序列对应的文本序列。
69.具体地,在解码器中,首先对目标自注意力特征和目标混合注意力特征进行拼接,得到拼接后的特征,然后根据拼接后的特征,确定语音序列对应的文本序列。其中,解码器可以根据拼接后的特征,循环生成字符,得到语音序列对应的文本序列。
70.可选地,采用解码器将拼接后的特征与编码后的声学特征序列进行相加,得到相加后的特征,然后采用解码器根据相加后的特征,确定语音序列对应的文本序列。其中,解码器可以根据相加后的特征,循环生成字符,得到语音序列对应的文本序列。
71.上述用于智能客服的语音处理方法中,首先获取语音序列对应的编码后的声学特征序列,然后将编码后的声学特征序列输入至解码器中的自注意力网络,得到目标自注意力特征,以及将编码后的声学特征序列输入至解码器中的混合注意力网络,得到目标混合注意力特征,最后采用解码器根据目标自注意力特征和目标混合注意力特征,确定语音序列对应的文本序列。采用基于编码-解码框架的语音识别模型,无需对声学单元进行建模,而是采用自注意力特征和混合注意力特征进行建模,模糊了建模单元与声学属性之间的联系,并且由于编码-解码框架能够考虑上下帧之间的信息,可以有效地建模语言转换点的声学属性,有利于大幅提升语音识别的准确性。
72.在一个实施例中,解码器的数量为多个,多个解码器串行连接。基于此,在一个实施例中,涉及上述步骤s204“将编码后的声学特征序列输入至解码器中的自注意力网络,得到目标自注意力特征”的一种可能的实现方式。在上述实施例的基础上,步骤s204具体可以通过以下步骤实现:
73.步骤s2042,将编码后的声学特征序列输入至第一个解码器中的自注意力网络,得到第一个自注意力特征;
74.步骤s2044,将第一个自注意力特征输入至下一个解码器中的自注意力网络,以此类推,直至最后一个解码器中的自注意力网络输出最后一个自注意力特征;
75.步骤s2046,将最后一个自注意力特征确定为目标自注意力特征。
76.具体地,假设解码器的数量为3个,3个解码器串行连接。首先,将编码后的声学特征序列输入至第一个解码器中的自注意力网络,第一个解码器中的自注意力网络输出第一个自注意力特征。然后,将该第一个自注意力特征作为第二个解码器(即下一个解码器)中的自注意力网络的输入数据,第二个解码器中的自注意力网络输出第二个自注意力特征。最后,将该第二个自注意力特征作为第三个解码器(即最后一个解码器)中的自注意力网络的输入数据,第三个解码器中的自注意力网络输出第三个自注意力特征(即最后一个自注意力特征),并将最后一个自注意力特征确定为目标自注意力特征。
77.可选地,自注意力网络为多头自注意力网络。
78.进一步地,在一个实施例中,涉及上述步骤s206“将编码后的声学特征序列输入至解码器中的混合注意力网络,得到目标混合注意力特征”的一种可能的实现方式。在上述实施例的基础上,步骤s206具体可以通过以下步骤实现:
79.步骤s2062,将编码后的声学特征序列输入至第一个解码器中的混合注意力网络,得到第一个混合注意力特征;
80.步骤s2064,将第一个混合注意力特征和第一个自注意力特征输入至下一个解码器中的混合注意力网络,以此类推,直至最后一个解码器中的混合注意力网络输出最后一个混合注意力特征;
81.步骤s2066,将最后一个混合注意力特征确定为目标混合注意力特征。
82.具体地,假设解码器的数量为3个,3个解码器串行连接。首先,将编码后的声学特征序列输入至第一个解码器中的混合注意力网络,第一个解码器中的混合注意力网络输出第一个混合注意力特征。然后,将该第一个混合注意力特征和第一个自注意力特征作为第二个解码器(即下一个解码器)中的混合注意力网络的输入数据,第二个解码器中的混合注意力网络输出第二个混合注意力特征。最后,将该第二个混合注意力特征和第二个自注意
力特征作为第三个解码器(即最后一个解码器)中的混合注意力网络的输入数据,第三个解码器中的混合注意力网络输出第三个混合注意力特征(即最后一个混合注意力特征),并将最后一个混合注意力特征确定为目标混合注意力特征。
83.可选地,混合注意力网络为多头混合注意力网络。
84.在一个实施例中,将语音序列识别为文本序列,采用的是中英文混合语音识别模型。可以理解,中英文混合语音识别模型包括编码器、解码器等。
85.在一个实施例中,该方法还包括以下步骤:
86.步骤s212,响应于用户的客服请求,播报需求引导语,并采集包含业务需求信息的语音序列。
87.本实施例中,通过对ivr app侧的改进,将语音导航流程前置,直接播报欢迎语来引导用户说出自己的需求。当用户说出需求时,利用中英文混合语音识别模型实现语种识别判断进入对应的流程。这样用户拨打电话会直接进入语音交互流程,根据欢迎语提示,如果需要英语服务可直接说出english service,如果需要中文服务直接中文说出需要办理的业务即可,无需用户在首层导航按键菜单中做按键选择,因此可去除传统的导航按键菜单。
88.在一个实施例中,为了保证能正确进入对应的服务流程,该方法还包括以下步骤:
89.步骤s222,根据文本序列,确定是否开启对应语种类型的人工客服模式;
90.步骤s224,若是,则开启对应语种类型的人工客服模式;
91.步骤s226,若否,则开启对应语种类型的智能客服模式,并播报与文本序列相匹配的业务信息。
92.具体地,从文本序列中抽取出语种特征,将抽取出的语种特征作为预先生成的文本语种分类器的输入,通过文本语种分类器计算获取文本序列所属的语种类型。然后,通过自然语言理解技术对文本序列进行处理,确定是否开启人工客服模式。
93.在一个实施例中,在对客体验上,为了提升智能客服导航的人性化,降低用户学习成本,通过更改智能导航欢迎语,可给予用户友好提示。为此将欢迎语更改为:欢迎致电xxx客户服务中心,您可以直接说出你的需求,if you want english service,please say english service。这样针对中文客户依据提示就可以直接说出自己的需求,进入到对应的业务流程中业务办理;针对英文客户依据提示可以请求英文服务,进入到英文导航中进而实现业务咨询办理,有利于实现导航电话全语音交互的目标。
94.在一个实施例中,涉及解码器的训练过程。
95.步骤s232,获取语音序列样本对应的编码后的声学特征序列样本和语音序列样本对应的文本序列样本;
96.步骤s234,将声学特征序列样本作为输入数据,对初始化的解码器中自注意力网络和混合注意力网络进行训练,其中,初始化的解码器的输出数据为预测文本序列,初始化的解码器的损失函数是基于预测文本序列和文本序列样本构建的。
97.在一个实施例中,请参见图2,编码器(图2中左侧部分)由n层独立的编码器层组成,每个编码器层中第一个子层是一个多头注意力(multi-head attention,mha)机制,第二个子层是一个位置相关的全连接前馈网络(position-wise fully connected feed-forward network)。对于这两个子层,每层都配有残差连接(residual connection,rc)以
及层归一化(layer normalization,ln))。
98.在一个实施例中,请参见图2,解码器(图2中右侧部分)由m层独立的解码器层组成,称为自注意力与混合注意力解码器(self-and-mixed attention decoder,smad。为了对输入序列进行计算,解码器输入前先利用词向量层计算序列中每个标签的词向量,并且通过位置编码(postional encoding)生成特征序列,同编码器的输出序列共同输入到解码器中。其中,编码器中self-and-mixed mha组件中的自注意力网络,主要负责处理声学表征。编码器中self-and-mixed mha组件中的混合注意力网络计算声学与输出间的对齐。
99.本实施例中,采用smad解码器,相比标准的transformer每层解码器使用同一h,smad解码器使用m层的解码器层捕捉多个级别的声学表征,有利于提高语音识别的准确性。
100.在一个实施例中,请参见图3,为简单描述起见,在图3中使用单头(head)self-and-mixed mha,来解释图2中解码器层中的self-and-mixed mha组件。s(source)代表输入相关向量,即虚线左边的声学特征序列向量;t(target)代表标注序列通过位置编码后的输出向量,即虚线右边的语言学表征向量。
101.对于sma中的自注意力,s通过ws投影得到长度为n的声学特征序列向量,当前层的声学特征序列向量是由前一层中累积的声学信息通过自注意力生成的。
102.对于sma中的混合注意力,当前层预测的token是由上一层的声学特征序列向量和之前的token,通过混合注意力机制计算得到。为了将声学与语言学表征向量投影至同一子空间,s与t拼接后使用同一投影矩阵wm,将向量投影至同一个子空间。
103.具体地,将编码后的声学特征序列与语言学部分的输入拼接为联合表征向量,作为解码器的输入,经过self-and-mixed mha之后,带有声音和语言信息的联合表征被传递到全连接前馈网络(feed-forward network,ffn)和下一个self-and-mixed mha。由于该解码器中的信息流包含两种形式,因此该解码器还采用特定于模态的残差连接和位置相关的前馈网络来分离语言和声学信息,以计算最后一层输出文本序列的后验概率。
104.在一个实施例中,解码器输出通过ctc(connectionist temporal classification)损失函数,建模输入语音序列与目标标签序列之间的关系,进而最大化后验概率,从而完成中英文混合语音识别模型的训练。
105.本实施例中,采用基于encoder-decoder(ed)框架的语音识别模型,无需对声学单元进行建模,而是采用字符进行建模,模糊了建模单元与声学属性之间的联系,并且由于encoder-decoder模型架构能够考虑上下帧之间的信息,可以有效地建模语言转换点的声学属性,使得识别效果大幅提升,通过通用测试集验证,ed中英文混合语音识别模型,中文识别率为96.2%,相比于基于dnn-hmm模型提升了3%,英文识别率96.3%,相比提升了22%,中英文混合识别效果准确率达到92%。
106.在一个实施例中,涉及训练集和测试集的选择与标注。其中,中英文混合语音识别模型主要使用的训练集为seame数据集和对客语音数据集(2万小时)。
107.seame数据集是一个基于麦克风自发性会话双语语音语料库,其中含有154个说话人,均来自于马来西亚及新加坡华人。seame数据集中不仅包含中英混合的句子,还包含少量的单语言语音。为了充分评估中英文混合的语音识别性能,seame数据集中设计了两个独立的测试集:(1)eval
man
,其中语音内容以中文为主。(2)eval
sge
,其中主要语音内容以新加坡英文为主。
108.对客语音数据集中主要包括金融业务场景语音数据。其中主要包括中外籍客户的客服电话录音、理财专员对客录音、外呼电话录音。涉及的业务场景主要有:个人业务、公司业务、营销活动三大类,共计2万多小时。
109.语音标注过程中主要按照以下标注规范:
110.1、保证语音转写出来的内容不具二义性(语音上的二义性),根据文本内容确切知道用户说的语音是什么。假设标成数字“123”,是不知道用户发的音,究竟是“一二三”,还是“幺二三”,还是“一百二十三”。
111.2、语气词使用“噢,啊,嗯,呃,吗,唉”不可使用其他同音词代替。超出规定六个语气词之外的其他音,例如“好嘞呐”,则可随意使用。
112.3、录音出现什么词汇就转写什么词汇,不可概括录音内容。注意区分:你
‑‑
您;那
‑‑
哪;在
‑‑
再。
113.4、字母要小写空格,字母与文字无需空格。英文语句小写,单词与单词之间空一格。例如:“查询atm机”、“what is the time”、“开通gprs流量”、“iphone四s”,如果字母和字母能组成一个词的话,就不需要加空格,比如说gprs、atm等。如果字母和字母之间没有联系,就要加空格,比如说皖b m,b和m中间加空格,比如说a b c d e f g,那么这些字母之间要加空格。同样,对于字母要加空格,也是如此。标成“me”,怎么确定用户说的是英文单词“me you”的“me”还是字母“m和e的连读”。
114.5、出现特殊符号的音,应输汉字谐音,不能出现特殊符号例如%、@,应使用中文谐音“百分比、艾特”。标注规范里,要求不要写阿拉伯数字,要写汉字。基于同样的原则,要求不要写“#”或“%”,而标“井”或“百分”之类的。
115.6、主说话人必须判断准确,如果出现系统音和人声同时出现,则只需要转写出人声。
116.7、一句话不论多长都不可以加标点符号或者空格。
117.8、车牌号:易混字母发音要分清:g(读ji)、j(读jie)、哥(读ge)、e(读yi第四声)、一(读yi)、z和c区分;
118.9、所有订购和退订都用:“订”。
119.在一个实施例中,对客语音数据集详情可见下列表格:
120.[0121][0122]
表1
[0123]
按照上述标注规范,标注测试集共计6.7w+,其中主要有5w多条业务场景(客服电话录音、理财专员对客录音、外呼电话录音等)数据、1万条热词,可参见表2。
[0124]
[0125]
[0126][0127]
表2
[0128]
本实施例中,基于2w多小时训练集和6.5w+测试集,完成中英文混合语音识别模型的优化,保证了中文和英文的识别率,有利于实现全语音智能客服导航。
[0129]
应该理解的是,虽然图1的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,图1中的至少一部分步骤可以包括多个步骤或者多个阶段,这些步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤中的步骤或者阶段的至少一部分轮流或者交替地执行。
[0130]
在一个实施例中,如图4所示,提供了一种用于智能客服的语音处理装置,包括:
[0131]
声学特征获取模块202,用于获取语音序列对应的编码后的声学特征序列;
[0132]
自注意力模块204,用于将编码后的声学特征序列输入至解码器中的自注意力网络,得到目标自注意力特征;
[0133]
混合注意力模块206,用于将编码后的声学特征序列输入至解码器中的混合注意力网络,得到目标混合注意力特征;
[0134]
文本序列确定模块208,用于采用解码器根据目标自注意力特征和目标混合注意力特征,确定语音序列对应的文本序列。
[0135]
上述用于智能客服的语音处理装置中,首先获取语音序列对应的编码后的声学特征序列,然后将编码后的声学特征序列输入至解码器中的自注意力网络,得到目标自注意力特征,以及将编码后的声学特征序列输入至解码器中的混合注意力网络,得到目标混合注意力特征,最后采用解码器根据目标自注意力特征和目标混合注意力特征,确定语音序列对应的文本序列。采用基于编码-解码框架的语音识别模型,无需对声学单元进行建模,而是采用自注意力特征和混合注意力特征进行建模,模糊了建模单元与声学属性之间的联系,并且由于编码-解码框架能够考虑上下帧之间的信息,可以有效地建模语言转换点的声学属性,有利于大幅提升语音识别的准确性。
[0136]
在一个实施例中,自注意力模块204具体用于将编码后的声学特征序列输入至第一个解码器中的自注意力网络,得到第一个自注意力特征;将第一个自注意力特征输入至下一个解码器中的自注意力网络,以此类推,直至最后一个解码器中的自注意力网络输出最后一个自注意力特征;将最后一个自注意力特征确定为目标自注意力特征。混合注意力模块206具体用于将编码后的声学特征序列输入至第一个解码器中的混合注意力网络,得到第一个混合注意力特征;将第一个混合注意力特征和第一个自注意力特征输入至下一个解码器中的混合注意力网络,以此类推,直至最后一个解码器中的混合注意力网络输出最后一个混合注意力特征;将最后一个混合注意力特征确定为目标混合注意力特征。
[0137]
在一个实施例中,文本序列确定模块208具体用于采用解码器对目标自注意力特征和目标混合注意力特征进行拼接,得到拼接后的特征;采用解码器根据拼接后的特征,确定语音序列对应的文本序列。
[0138]
在一个实施例中,文本序列确定模块208具体用于采用解码器将拼接后的特征与编码后的声学特征序列进行相加,得到相加后的特征;采用解码器根据相加后的特征,确定语音序列对应的文本序列。
[0139]
关于用于智能客服的语音处理装置的具体限定可以参见上文中对于用于智能客服的语音处理方法的限定,在此不再赘述。上述用于智能客服的语音处理装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
[0140]
在一个实施例中,提供了一种计算机设备,该计算机设备可以是终端,其内部结构图可以如图5所示。该计算机设备包括通过系统总线连接的处理器、存储器、通信接口、显示屏和输入装置。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统和计算机程序。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的通信接口用于与外部的终端进行有线或无线方式的通信,无线方式可通过wifi、运营商网络、nfc(近场通信)或其他技术实现。该计算机程序被处理器执行时以实现一种用于智能客服的语音处理方法。该计算机设备的显示屏可以是液晶显示屏或者电子墨水显示屏,该计算机设备的输入装置可以是显示屏上覆盖的触摸层,也可以是计算机设备外壳上设置的按键、轨迹球或触控板,还可以是外接的键盘、触控板或鼠标等。
[0141]
本领域技术人员可以理解,图5中示出的结构,仅仅是与本技术方案相关的部分结构的框图,并不构成对本技术方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
[0142]
在一个实施例中,提供了一种计算机设备,包括存储器和处理器,存储器中存储有计算机程序,该处理器执行计算机程序时实现以下步骤:
[0143]
获取语音序列对应的编码后的声学特征序列;
[0144]
将编码后的声学特征序列输入至解码器中的自注意力网络,得到目标自注意力特征;
[0145]
将编码后的声学特征序列输入至解码器中的混合注意力网络,得到目标混合注意力特征;
[0146]
采用解码器根据目标自注意力特征和目标混合注意力特征,确定语音序列对应的文本序列。
[0147]
在一个实施例中,处理器执行计算机程序时还实现以下步骤:
[0148]
将编码后的声学特征序列输入至第一个解码器中的自注意力网络,得到第一个自注意力特征;将第一个自注意力特征输入至下一个解码器中的自注意力网络,以此类推,直至最后一个解码器中的自注意力网络输出最后一个自注意力特征;将最后一个自注意力特征确定为目标自注意力特征;以及将编码后的声学特征序列输入至第一个解码器中的混合注意力网络,得到第一个混合注意力特征;将第一个混合注意力特征和第一个自注意力特征输入至下一个解码器中的混合注意力网络,以此类推,直至最后一个解码器中的混合注意力网络输出最后一个混合注意力特征;将最后一个混合注意力特征确定为目标混合注意力特征。
[0149]
在一个实施例中,处理器执行计算机程序时还实现以下步骤:
[0150]
采用解码器对目标自注意力特征和目标混合注意力特征进行拼接,得到拼接后的特征;采用解码器根据拼接后的特征,确定语音序列对应的文本序列。
[0151]
在一个实施例中,处理器执行计算机程序时还实现以下步骤:
[0152]
采用解码器将拼接后的特征与编码后的声学特征序列进行相加,得到相加后的特征;采用解码器根据相加后的特征,确定语音序列对应的文本序列。
[0153]
在一个实施例中,处理器执行计算机程序时还实现以下步骤:
[0154]
响应于客服请求,播报需求引导语,并采集包含业务需求信息的语音序列。
[0155]
在一个实施例中,处理器执行计算机程序时还实现以下步骤:
[0156]
根据文本序列,确定是否开启对应语种类型的人工客服模式;若是,则开启对应语种类型的人工客服模式;若否,则开启对应语种类型的智能客服模式,并播报与文本序列相匹配的业务信息。
[0157]
在一个实施例中,处理器执行计算机程序时还实现以下步骤:
[0158]
获取语音序列样本对应的编码后的声学特征序列样本和语音序列样本对应的文本序列样本;将声学特征序列样本作为输入数据,对初始化的解码器中自注意力网络和混合注意力网络进行训练,其中,初始化的解码器的输出数据为预测文本序列,初始化的解码器的损失函数是基于预测文本序列和文本序列样本构建的。
[0159]
在一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现以下步骤:
[0160]
获取语音序列对应的编码后的声学特征序列;
[0161]
将编码后的声学特征序列输入至解码器中的自注意力网络,得到目标自注意力特征;
[0162]
将编码后的声学特征序列输入至解码器中的混合注意力网络,得到目标混合注意力特征;
[0163]
采用解码器根据目标自注意力特征和目标混合注意力特征,确定语音序列对应的文本序列。
[0164]
在一个实施例中,计算机程序被处理器执行时还实现以下步骤:
[0165]
将编码后的声学特征序列输入至第一个解码器中的自注意力网络,得到第一个自注意力特征;将第一个自注意力特征输入至下一个解码器中的自注意力网络,以此类推,直至最后一个解码器中的自注意力网络输出最后一个自注意力特征;将最后一个自注意力特征确定为目标自注意力特征;以及将编码后的声学特征序列输入至第一个解码器中的混合注意力网络,得到第一个混合注意力特征;将第一个混合注意力特征和第一个自注意力特征输入至下一个解码器中的混合注意力网络,以此类推,直至最后一个解码器中的混合注意力网络输出最后一个混合注意力特征;将最后一个混合注意力特征确定为目标混合注意力特征。
[0166]
在一个实施例中,计算机程序被处理器执行时还实现以下步骤:
[0167]
采用解码器对目标自注意力特征和目标混合注意力特征进行拼接,得到拼接后的特征;采用解码器根据拼接后的特征,确定语音序列对应的文本序列。
[0168]
在一个实施例中,计算机程序被处理器执行时还实现以下步骤:
[0169]
采用解码器将拼接后的特征与编码后的声学特征序列进行相加,得到相加后的特征;采用解码器根据相加后的特征,确定语音序列对应的文本序列。
[0170]
在一个实施例中,计算机程序被处理器执行时还实现以下步骤:
[0171]
响应于客服请求,播报需求引导语,并采集包含业务需求信息的语音序列。
[0172]
在一个实施例中,计算机程序被处理器执行时还实现以下步骤:
[0173]
根据文本序列,确定是否开启对应语种类型的人工客服模式;若是,则开启对应语种类型的人工客服模式;若否,则开启对应语种类型的智能客服模式,并播报与文本序列相匹配的业务信息。
[0174]
在一个实施例中,计算机程序被处理器执行时还实现以下步骤:
[0175]
获取语音序列样本对应的编码后的声学特征序列样本和语音序列样本对应的文本序列样本;将声学特征序列样本作为输入数据,对初始化的解码器中自注意力网络和混合注意力网络进行训练,其中,初始化的解码器的输出数据为预测文本序列,初始化的解码器的损失函数是基于预测文本序列和文本序列样本构建的。
[0176]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本技术所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和易失性存储器中的至少一种。非易失性存储器可包括只读存储器(read-only memory,rom)、磁带、软盘、闪存或光存储器等。易失性存储器可包括随机存取存储器(random access memory,ram)或外部高速缓冲存储器。作为说明而非局限,ram可以是多种形式,比如静态随机存取存储器(static random access memory,sram)或动态随机存取存储器(dynamic random access memory,dram)等。
[0177]
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0178]
以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。