1.本技术涉及生物识别技术领域,尤其涉及一种语音增强方法、设备、系统以及计算机可读存储介质。
背景技术:
2.目前,基于生物特征识别的生物认证技术逐渐在家庭生活、公共安全等领域中得到了推广应用。可应用于生物认证的生物特征包括指纹、面部(人脸)、虹膜、dna、声纹等,其中,以声纹作为识别特征的声纹识别技术(又称,说话人识别技术),以不接触的方式实现声音样本的采集,采集方式更加隐蔽,因而更容易被用户接受。
3.现有技术中,当声音样本的采集环境中存在噪声时,声纹的识别率会受到影响。
技术实现要素:
4.本技术的一些实施方式提供了一种语音增强方法、终端设备、语音增强系统以及计算机可读存储介质,以下从多个方面介绍本技术,以下多个方面的实施方式和有益效果可互相参考。
5.第一方面,本技术实施方式提供了一种语音增强方法,应用于电子设备,包括:采集待验证语音;确定待验证语音中包含的环境噪声和/或环境特征参数;基于环境噪声和/或环境特征参数对注册语音进行增强;比较待验证语音与增强的注册语音进行比较,确定待验证语音与注册语音来自相同用户。
6.根据本技术的实施方式,根据待验证语音中的噪声成分对注册语音进行增强,以使得增强的注册语音和待验证语音具有相接近的噪声成分,这样,待验证语音和增强的注册语音的主要区别就在于两者有效语音成分之间的区别,通过声纹识别算法对两者进行比较后,可以得到更准确的识别结果。另外,本技术实施方式中,用户只需在安静环境下录入注册语音即可,无需在多个场景分别录制注册语音,因而用户体验较好。
7.在一些实施方式中,注册语音为在安静环境下采集的来自注册说话人的语音。这样,注册语音中没有明显的噪声分量,可以提高识别的准确率。
8.在一些实施方式中,基于环境噪声对注册语音进行增强,包括:在注册语音上叠加环境噪声。本技术实施方法通过在注册语音上叠加环境噪声得到增强的注册语音,算法简单。
9.在一些实施方式中,环境噪声为电子设备的副麦克风拾取到的声音。本技术实施方式可以方便地确定待验证语音中所包含的噪声。
10.在一些实施方式中,待验证语音的时长小于注册语音的时长。这样,用户可以录入较短的待验证语音,有利于提高用户体验。
11.在一些实施方式中,环境特征参数包括待验证语音所对应的场景类型;基于环境特征参数对注册语音进行增强,包括:基于待验证语音所对应的场景类型,确定场景类型所对应的模板噪声,并在注册语音上叠加模板噪声。
12.根据本技术的实施方式,通过在注册语音上叠加模板噪声对注册语音进行增强,使得增强的注册语音和待验证语音具有尽量接近的噪声成分,有利于提高识别的准确率。
13.在一些实施方式中,待验证语音所对应的场景类型是根据场景识别算法对待验证语音进行识别而确定的。在一些实施方式中,场景识别算法为下述任意一种:gmm算法;dnn算法。
14.在一些实施方式中,待验证语音的场景类型为下述任意一种:居家场景;车载场景;室外嘈杂场景;会场场景;影院场景。本技术实施方式的场景类型涵盖了用户日常活动的场所,有利于提高用户体验。
15.在一些实施方式中,待验证语音的环境参数特征包括产生待验证语音的用户与电子设备之间的距离;基于环境特征参数对注册语音进行增强,包括:根据产生待验证语音的用户与电子设备之间的距离,对注册语音进行远场仿真。其中,对注册语音进行远场仿真用于将注册语音的采集距离(注册语音的语音采集装置与产生注册语音的用户之间的距离)模拟至待验证语音的采集距离(待验证语音的语音采集装置与产生待验证语音的用户之间的距离)。
16.根据本技术的实施方式,通过对注册语音进行远场仿真,可以考虑待验证语音在传播过程中的衰减成分,使得增强的注册语音和待验证语音具有尽量接近的噪声成分,有利于提高识别的准确率。
17.在一些实施方式中,根据产生待验证语音的用户与电子设备之间的距离,对注册语音进行远场仿真,包括:根据产生待验证语音的用户与电子设备之间的距离,基于镜像源模型方法建立待验证语音的采集场所的脉冲响应函数;将脉冲响应函数与注册语音的音频信号进行卷积,以对注册语音进行远场仿真。
18.在一些实施方式中,待验证语音和增强的注册语音为经过相同的前端处理算法处理过的语音。通过前端处理可以去除语音中的干扰因素,有利于提高声纹识别的准确率。
19.在一些实施方式中,前端处理算法包括以下至少一种处理算法:回声抵消;去混响;主动降噪;动态增益;定向拾音。
20.在一些实施方式中,注册语音的数量为多条;并且,基于环境噪声和/或环境特征参数,对多条注册语音分别进行增强,以得到多条增强的注册语音。
21.根据本技术的实施方式,得到多条增强的注册语音,可以将待验证语音与多条增强的注册语音进行分别进行匹配,以得到多个相似度匹配结果,进而可根据多个相似度匹配结果综合判断待验证说话人语音与注册说话人语音的相似度,从而可以对单个匹配结果的误差进行平均,有利于提高声纹识别的准确率和声纹识别算法的鲁棒性。
22.在一些实施方式中,比较待验证语音与增强的注册语音,确定待验证语音与注册语音来自相同用户,包括:通过特征参数提取算法提取待验证语音的特征参数,和增强的注册语音的特征参数;通过参数识别模型对待验证语音的特征参数和增强的注册语音的特征参数进行参数识别,以分别得到待验证说话人的语音模板和注册说话人的语音模板;通过模板匹配算法对待验证说话人的语音模板和注册说话人的语音模板进行匹配,根据匹配结果确定待验证语音与注册语音来自相同用户。
23.在一些实施方式中,特征参数提取算法为mfcc算法,log mel算法或者lpcc算法;和/或,参数识别模型为身份向量模型、时延神经网络模型或者resnet模型;和/或,模板匹
配算法为余弦距离法、线性判别法或者概率线性判别分析法。
24.第二方面,本技术实施方式提供了一种语音增强方法,包括:终端设备采集待验证语音,并将待验证语音发送至与终端设备通信相连的服务器;服务器,确定待验证语音中包含的环境噪声和/或环境特征参数;服务器,基于环境噪声和/或环境特征参数对注册语音进行增强;服务器,比较待验证语音与增强的注册语音,确定待验证语音与注册语音来自相同用户;服务器,将确定待验证语音与注册语音来自相同用户的确定结果发送至终端设备。
25.根据本技术的实施方式,根据待验证语音中的噪声成分对注册语音进行增强,以使得增强的注册语音和待验证语音具有相接近的噪声成分,这样,待验证语音和增强的注册语音的主要区别就在于两者有效语音成分之间的区别,通过声纹识别算法对两者进行比较后,可以得到更准确的识别结果。另外,本技术实施方式中,用户只需在安静环境下录入注册语音即可,无需在多个场景分别录制注册语音,因而用户体验较好。本技术实施方式中,说话人识别算法在服务器上实现,可以节省终端设备本地的计算资源。
26.在一些实施方式中,注册语音为在安静环境下采集的来自注册说话人的语音。这样,注册语音中没有明显的噪声分量,可以提高识别的准确率。
27.在一些实施方式中,基于环境噪声对注册语音进行增强,包括:在注册语音上叠加环境噪声。本技术实施方法通过在注册语音上叠加环境噪声得到增强的注册语音,算法简单。
28.在一些实施方式中,环境噪声为终端设备的副麦克风拾取到的声音。本技术实施方式可以方便地确定待验证语音中所包含的噪声。
29.在一些实施方式中,待验证语音的时长小于注册语音的时长。这样,用户可以录入较短的待验证语音,有利于提高用户体验。
30.在一些实施方式中,环境特征参数包括待验证语音所对应的场景类型;基于环境特征参数对注册语音进行增强,包括:基于待验证语音所对应的场景类型,确定场景类型所对应的模板噪声,并在注册语音上叠加模板噪声。
31.根据本技术的实施方式,通过在注册语音上叠加模板噪声对注册语音进行增强,使得增强的注册语音和待验证语音具有尽量接近的噪声成分,有利于提高识别的准确率。
32.在一些实施方式中,待验证语音所对应的场景类型是根据场景识别算法对待验证语音进行识别而确定的。在一些实施方式中,场景识别算法为下述任意一种:gmm算法;dnn算法。
33.在一些实施方式中,待验证语音的场景类型为下述任意一种:居家场景;车载场景;室外嘈杂场景;会场场景;影院场景。本技术实施方式的场景类型涵盖了用户日常活动的场所,有利于提高用户体验。
34.在一些实施方式中,待验证语音的环境参数特征包括产生待验证语音的用户与终端设备之间的距离;基于环境特征参数对注册语音进行增强,包括:根据产生待验证语音的用户与终端设备之间的距离,对注册语音进行远场仿真。其中,对注册语音进行远场仿真用于将注册语音的采集距离(注册语音的语音采集装置与产生注册语音的用户之间的距离)模拟至待验证语音的采集距离(待验证语音的语音采集装置与产生待验证语音的用户之间的距离)。
35.根据本技术的实施方式,通过对注册语音进行远场仿真,可以考虑待验证语音在
传播过程中的衰减成分,使得增强的注册语音和待验证语音具有尽量接近的噪声成分,有利于提高识别的准确率。
36.在一些实施方式中,根据产生待验证语音的用户与终端设备之间的距离,对注册语音进行远场仿真,包括:根据产生待验证语音的用户与终端设备之间的距离,基于镜像源模型方法建立待验证语音的采集场所的脉冲响应函数;将脉冲响应函数与注册语音的音频信号进行卷积,以对注册语音进行远场仿真。
37.在一些实施方式中,待验证语音和增强的注册语音为经过相同的前端处理算法处理过的语音。通过前端处理可以去除语音中的干扰因素,有利于提高声纹识别的准确率。
38.在一些实施方式中,前端处理算法包括以下至少一种处理算法:回声抵消;去混响;主动降噪;动态增益;定向拾音。
39.在一些实施方式中,注册语音的数量为多条;并且,服务器基于环境噪声和/或环境特征参数,对多条注册语音分别进行增强,以得到多条增强的注册语音。
40.根据本技术的实施方式,得到多条增强的注册语音,可以将待验证语音与多条增强的注册语音进行分别进行匹配,以得到多个相似度匹配结果,进而可根据多个相似度匹配结果综合判断待验证说话人语音与注册说话人语音的相似度,从而可以对单个匹配结果的误差进行平均,有利于提高声纹识别的准确率和声纹识别算法的鲁棒性。
41.在一些实施方式中,比较待验证语音与增强的注册语音,确定待验证语音与注册语音来自相同用户,包括:通过特征参数提取算法提取待验证语音的特征参数,和增强的注册语音的特征参数;通过参数识别模型对待验证语音的特征参数和增强的注册语音的特征参数进行参数识别,以分别得到待验证说话人的语音模板和注册说话人的语音模板;通过模板匹配算法对待验证说话人的语音模板和注册说话人的语音模板进行匹配,根据匹配结果确定所述待验证语音与所述注册语音来自相同用户。
42.在一些实施方式中,特征参数提取算法为mfcc算法,log mel算法或者lpcc算法;和/或,参数识别模型为身份向量模型、时延神经网络模型或者resnet模型;和/或,模板匹配算法为余弦距离法、线性判别法或者概率线性判别分析法。
43.第三方面,本技术实施方式提供了一种电子设备,包括:存储器,用于存储由电子设备的一个或多个处理器执行的指令;处理器,当处理器执行存储器中的指令时,可使得电子设备执行本技术第一方面任一实施方式提供的说话人识别方法。第三方面能达到的有益效果可参考第一方面任一实施方式所提供的方法的有益效果,此处不再赘述。
44.第四方面,本技术实施方式提供了一种语音增强系统,包括终端设备以及与终端设备通信连接的服务器,其中,
45.终端设备采集待验证语音,并将待验证语音发送至服务器;服务器,用于确定待验证语音中包含的环境噪声和/或环境特征参数,基于环境噪声和/或环境特征参数对注册语音进行增强;并比较待验证语音与增强的注册语音,确定待验证语音与注册语音来自相同用户;服务器,还用于将确定待验证语音与注册语音来自相同用户的确定结果发送至终端设备。
46.根据本技术的实施方式,根据待验证语音中的噪声成分对注册语音进行增强,以使得增强的注册语音和待验证语音具有相接近的噪声成分,这样,待验证语音和增强的注册语音的主要区别就在于两者有效语音成分之间的区别,通过声纹识别算法对两者进行比
较后,可以得到更准确的识别结果。另外,本技术实施方式中,用户只需在安静环境下录入注册语音即可,无需在多个场景分别录制注册语音,因而用户体验较好。本技术实施方式中,说话人识别算法在服务器上实现,可以节省终端设备本地的计算资源。
47.在一些实施方式中,注册语音为在安静环境下采集的来自注册说话人的语音。这样,注册语音中没有明显的噪声分量,可以提高识别的准确率。
48.在一些实施方式中,基于环境噪声对注册语音进行增强,包括:在注册语音上叠加环境噪声。本技术实施方法通过在注册语音上叠加环境噪声得到增强的注册语音,算法简单。
49.在一些实施方式中,环境噪声为终端设备的副麦克风拾取到的声音。本技术实施方式可以方便地确定待验证语音中所包含的噪声。
50.在一些实施方式中,待验证语音的时长小于注册语音的时长。这样,用户可以录入较短的待验证语音,有利于提高用户体验。
51.在一些实施方式中,环境特征参数包括待验证语音所对应的场景类型;基于环境特征参数对注册语音进行增强,包括:基于待验证语音所对应的场景类型,确定场景类型所对应的模板噪声,并在注册语音上叠加模板噪声。
52.根据本技术的实施方式,通过在注册语音上叠加模板噪声对注册语音进行增强,使得增强的注册语音和待验证语音具有尽量接近的噪声成分,有利于提高识别的准确率。
53.在一些实施方式中,待验证语音所对应的场景类型是根据场景识别算法对待验证语音进行识别而确定的。在一些实施方式中,场景识别算法为下述任意一种:gmm算法;dnn算法。
54.在一些实施方式中,待验证语音的场景类型为下述任意一种:居家场景;车载场景;室外嘈杂场景;会场场景;影院场景。本技术实施方式的场景类型涵盖了用户日常活动的场所,有利于提高用户体验。
55.在一些实施方式中,待验证语音的环境参数特征包括产生待验证语音的用户与终端设备之间的距离;基于环境特征参数对注册语音进行增强,包括:根据产生待验证语音的用户与终端设备之间的距离,对注册语音进行远场仿真。其中,对注册语音进行远场仿真用于将注册语音的采集距离(注册语音的语音采集装置与产生注册语音的用户之间的距离)模拟至待验证语音的采集距离(待验证语音的语音采集装置与产生待验证语音的用户之间的距离)。
56.根据本技术的实施方式,通过对注册语音进行远场仿真,可以考虑待验证语音在传播过程中的衰减成分,使得增强的注册语音和待验证语音具有尽量接近的噪声成分,有利于提高识别的准确率。
57.在一些实施方式中,根据产生待验证语音的用户与终端设备之间的距离,对注册语音进行远场仿真,包括:根据产生待验证语音的用户与终端设备之间的距离,基于镜像源模型方法建立待验证语音的采集场所的脉冲响应函数;将脉冲响应函数与注册语音的音频信号进行卷积,以对注册语音进行远场仿真。
58.在一些实施方式中,待验证语音和增强的注册语音为经过相同的前端处理算法处理过的语音。通过前端处理可以去除语音中的干扰因素,有利于提高声纹识别的准确率。
59.在一些实施方式中,前端处理算法包括以下至少一种处理算法:回声抵消;去混
响;主动降噪;动态增益;定向拾音。
60.在一些实施方式中,注册语音的数量为多条;并且,服务器基于环境噪声和/或环境特征参数,对多条注册语音分别进行增强,以得到多条增强的注册语音。
61.根据本技术的实施方式,得到多条增强的注册语音,可以将待验证语音与多条增强的注册语音进行分别进行匹配,以得到多个相似度匹配结果,进而可根据多个相似度匹配结果综合判断待验证说话人语音与注册说话人语音的相似度,从而可以对单个匹配结果的误差进行平均,有利于提高声纹识别的准确率和声纹识别算法的鲁棒性。
62.在一些实施方式中,比较待验证语音与增强的注册语音,确定待验证语音与注册语音来自相同用户,包括:通过特征参数提取算法提取待验证语音的特征参数,和增强的注册语音的特征参数;通过参数识别模型对待验证语音的特征参数和增强的注册语音的特征参数进行参数识别,以分别得到待验证说话人的语音模板和注册说话人的语音模板;通过模板匹配算法对待验证说话人的语音模板和注册说话人的语音模板进行匹配,根据匹配结果确定所述待验证语音与所述注册语音来自相同用户。
63.在一些实施方式中,特征参数提取算法为mfcc算法,log mel算法或者lpcc算法;和/或,参数识别模型为身份向量模型、时延神经网络模型或者resnet模型;和/或,模板匹配算法为余弦距离法、线性判别法或者概率线性判别分析法。
64.第五方面,本技术实施方式提供一种计算机可读存储介质,计算机可读存储介质中存储有指令,该指令在计算机上执行时,可使计算机执行本技术第一方面任一实施方式提供的方法,或者使计算机执行本技术第二方面任一实施方式提供的方法。第五方面能达到的有益效果可参考第一方面任一实施方式或第二方面任一实施方式所提供的方法的有益效果,此处不再赘述。
附图说明
65.图1a示出了本技术实施方式提供的语音增强方法的示例性应用场景;
66.图1b示出了本技术实施方式提供的语音增强方法的另一个示例性应用场景;
67.图2示出了本技术实施方式提供的语音增强设备的构造示意图;
68.图3示出了本技术一个实施例提供的语音增强方法的流程图;
69.图4示出了本技术另一个实施例提供的语音增强方法的流程图;
70.图5示出了本技术实施例提供的语音增强方法的一个应用场景;
71.图6示出了本技术实施方式提供的电子设备的结构图;
72.图7示出了本技术实施方式提供的片上系统(soc)的框图。
具体实施方式
73.下面将结合附图对本技术实施方式进行详细描述。
74.说话人识别技术(又称,声纹识别技术)是利用说话人声纹的独特性来对说话人的身份进行识别的技术。因为每个人的发声器官(例如,舌、牙齿、喉头、肺、鼻腔、发声通道等)具有先天区别,且发声习惯等具有后天差异,因此,每个人的声纹特征是独一无二的,通过对声纹特征进行分析,可对说话人的身份进行识别。
75.说话人识别的具体过程为,采集待确认身份的说话人的语音,将之与特定说话人
的语音进行比较,以确认待确认身份的说话人是否为该特定说话人。本文中,将待确认身份的说话人的语音称为“待验证语音”,该待确认身份的说话人称为“待验证说话人”;将特定说话人的语音称为“注册语音”,该特定说话人称为“注册说话人”。
76.参考图1a,以手机的声纹解锁功能(即,通过声纹识别的手段对手机屏幕进行解锁)为例,对上述过程进行介绍。在利用手机声纹解锁功能之前,手机机主通过手机上麦克风在手机中录入本人的语音(该语音为注册语音)。
77.当需要通过声纹识别的手段对手机屏幕进行解锁时,手机的当前用户通过手机麦克风录入实时语音(该语音为待验证语音),手机通过内置的声纹识别程序对待验证语音和注册语音进行比较,以判断手机的当前用户是否为手机的机主。如果待验证语音与注册语音的相匹配,则判断手机的当前用户为机主本人,手机的当前用户通过身份认证,手机完成后续的屏幕解锁动作;如果待验证语音与注册语音不匹配,则判断手机的当前用户并非机主本人,手机的当前用户未通过身份认证,手机可以拒绝后续的屏幕解锁动作。
78.以上以手机的声纹解锁功能为例对声纹识别技术的应用进行了说明,但本技术不限于此,声纹识别技术可应用于需要对说话人的身份进行识别的其他场景。例如,声纹识别技术可以应用于家庭生活领域,对智能手机、智能汽车、智能家居(例如,智能音视频设备、智能照明系统、智能门锁)等进行语音控制;声纹识别技术还可以应用于支付领域,将声纹认证与其他认证手段(例如,密码、动态验证码等)相结合对用户的身份进行双重或多重认证,以提高支付的安全性;声纹识别技术还可以应用于信息安全领域,将声纹认证作为登录账号的方式;声纹识别技术还可以应用于司法领域,将声纹作为判断身份的辅助证据等。
79.并且,声纹识别的主体设备可以是除手机之外的其他电子设备,例如,移动式设备,包括可穿戴设备(例如,手环、耳机等)、车载终端等;或者固定式设备,包括智能家居、网络服务器等。另外,声纹识别的算法除了可以在终端实现外,还可以在云端实现。例如,手机采集到待验证语音后,可以将采集到的待验证语音发送到云端,通过云端的声纹识别算法对待验证语音进行识别,云端在完成识别之后,将识别结果返回至手机。通过云端识别模式,用户可以共享云端的计算资源,以节约手机本地的计算资源。
80.如图1b所示的场景,在对待验证说话人的语音进行采集的时候,如果周围环境中存在嘈杂的人声噪声,这些噪声会被麦克风一起采集进去,成为待验证语音的一部分。这样,待验证语音中除了包括待验证说话人的声音外,还掺杂进了噪声的成分,这样会降低声纹的识别率。
81.本实施例对声纹识别的场景不作限定,例如,还可以是居家场景、车载场景、会场场景、影院场景等。
82.手机的机主需要通过声纹识别解锁手机时,如果周围的环境中存在噪声,手机麦克风采集到的声音除了机主语音外,还有环境中的噪声,这样,手机在将采集到的机主实时语音与机主预置在手机中的注册语音进行比较后,可能会得出两者不匹配结果。即便手机的当前用户为机主本人,手机仍可能给出用户身份认证未通过的结果,从而影响用户体验。
83.现有技术中,有的技术方案通过对待验证语音进行消噪处理来去除待验证语音中的噪声成分,以提高声纹的识别率。但是,经消噪处理后的待验证语音中仍包含部分噪音成分,并且部分有效语音成分(待验证说话人的语音成分)也一并被去除,这样,可能出现消噪处理后的待验证语音仍不能被正确识别,声纹的识别率提升不明显。
84.现有技术中,还有的技术方案是通过在不同的场景中分别录制注册语音来提高声纹的识别率。具体地,用户在多个不同场景(例如,居家场景、影院场景、室外嘈杂场景等)下分别录制注册语音,在进行声纹识别时,将待验证语音与对应场景下录制的注册语音进行比较,以提高声纹的识别率。该现有技术中,用户需要在多个不同的场景分别录制注册语音,用户体验较低。
85.为此,本技术实施方式提供了一种语音增强方法,用于提高声纹的识别率和声纹识别方法的鲁棒性,并且使得用户体验获得提升。本技术中,在采集到待验证语音后,会在注册语音上叠加上与待验证语音中的噪声成分相对应的噪声成分,然后将叠加过噪声成分之后的注册语音与待验证语音进行比较,以得到识别结果。换句话说,本技术中,会根据待验证语音中的噪声成分对注册语音进行增强,以使得增强的注册语音和待验证语音具有相接近的噪声成分,这样,待验证语音和增强的注册语音的主要区别就在于两者有效语音成分之间的区别,通过声纹识别算法对两者进行比较后,可以得到更准确的识别结果。另外,本技术实施方式中,用户只需在安静环境下录入注册语音即可,无需在多个场景分别录制注册语音,因而用户体验较好。
86.这里,“有效语音成分”为来自说话人的语音成分,例如,待验证语音中的有效语音成分为待验证说话人的语音成分,增强的注册语音中的有效语音成分为注册说话人的语音成分。
87.以下仍结合图1b中手机的声纹解锁功能对本技术的技术方案进行介绍,但可以理解,本技术不限于此。
88.图2示出了手机100的结构。手机100可以包括处理器110,外部存储器接口120,内部存储器121,天线,通信模块150,音频模块170,扬声器170a,受话器170b,麦克风170c,耳机接口170d,摄像头193,显示屏194等。
89.可以理解的是,本发明实施例示意的结构并不构成对手机100的具体限定。在本技术另一些实施例中,手机100可以包括比图示更多或更少的部件,或者组合某些部件,或者拆分某些部件,或者不同的部件布置。图示的部件可以以硬件,软件或软件和硬件的组合实现。
90.处理器110可以包括一个或多个处理单元,例如:处理器110可以包括应用处理器(application processor,ap),调制解调处理器,控制器,数字信号处理器(digital signal processor,dsp),基带处理器等。其中,不同的处理单元可以是独立的器件,也可以集成在一个或多个处理器中。
91.处理器可以根据指令操作码和时序信号,产生操作控制信号,完成取指令和执行指令的控制。
92.处理器110中还可以设置存储器,用于存储指令和数据。在一些实施例中,处理器110中的存储器为高速缓冲存储器。该存储器可以保存处理器110刚用过或循环使用的指令或数据。如果处理器110需要再次使用该指令或数据,可从所述存储器中直接调用。避免了重复存取,减少了处理器110的等待时间,因而提高了系统的效率。
93.在一些实施例中,处理器110可以包括一个或多个接口。接口可以包括集成电路内置音频(inter-integrated circuit sound,i2s)接口,脉冲编码调制(pulse code modulation,pcm)接口,和/或通用输入输出(general-purpose input/output,gpio)接口
storage,ufs)等。处理器110通过运行存储在内部存储器121的指令,和/或存储在设置于处理器中的存储器的指令,执行手机100的各种功能应用以及数据处理。
103.手机100可以通过音频模块170,扬声器170a,受话器170b,麦克风170c,耳机接口170d,以及应用处理器等实现音频功能。例如音乐播放,录音等。
104.音频模块170用于将数字音频信息转换成模拟音频信号输出,也用于将模拟音频输入转换为数字音频信号。音频模块170还可以用于对音频信号编码和解码。在一些实施例中,音频模块170可以设置于处理器110中,或将音频模块170的部分功能模块设置于处理器110中。
105.扬声器170a,也称“喇叭”,用于将音频电信号转换为声音信号。手机100可以通过扬声器170a收听音乐,或收听免提通话。
106.受话器170b,也称“听筒”,用于将音频电信号转换成声音信号。当手机100接听电话或语音信息时,可以通过将受话器170b靠近人耳接听语音。
107.麦克风170c,也称“mic”,“话筒”,“传声器”,用于将声音信号转换为电信号。在录入注册语音或待验证语音时,用户可以通过人嘴靠近麦克风170c发声,将声音信号输入到麦克风170c。手机100可以设置至少一个麦克风170c。
108.在另一些实施例中,手机100可以设置两个麦克风170c,除了采集声音信号,还可以实现降噪功能。具体地,手机100上下各有一个麦克风,一个麦克风170c设于手机100的底部侧边,另一个麦克风170c设于手机100的顶部侧边。用户在拨打电话或发送语音消息时,嘴巴通常靠近底部侧边的麦克风170c,因此,用户语音会在该麦克风中产生较大的音频信号va,本文称之为“主mic”。与此同时,用户语音也会在顶部侧边的麦克风170c也上产生一定量的音频信号vb,但由于该麦克风离用户嘴巴较远,因而该麦克风上的音频信号vb要显著小于主mic上的音频信号va,本文称之为“副mic”。
109.对于环境中的噪声来说,由于噪声的声源通常是远离手机100的,因此可认为噪声声源与主mic和副mic的距离基本是一致的,即,可认为主mic和副mic采集到的噪声的强度是基本相同的。
110.利用两个mic位置差异造成的信号强度差异可以分离噪声信号和用户语音信号。例如,将主mic拾取到的音频信号与副mic拾取到的音频信号进行差分后(即在主mic中的信号减去副mic中的信号),可得到用户的语音信号(这便是双mic主动降噪的原理)。进而,在主mic的信号中去除用户的语音信号后,即可以分离出噪声信号。或者,由于副mic上的音频信号vb显著小于主mic上的音频信号va,因此可认为副mic拾取到的信号即为噪声信号。
111.以上给出了手机100双mic的一种设置方式,但这仅是示例性说明,麦克风可采用其他的设置方式,例如,主mic设于手机100的正面,副mic设于手机的背面等。
112.在另一些实施例中,手机100还可以设置三个,四个或更多麦克风170c,实现采集声音信号,降噪,还可以识别声音来源,实现定向录音功能等。
113.耳机接口170d用于连接有线耳机。耳机接口170d可以是通用串行总线(universal serial bus,usb)接口,也可以是3.5mm的开放移动电子设备平台(open mobile terminal platform,omtp)标准接口,美国蜂窝电信工业协会(cellular telecommunications industry association of the usa,ctia)标准接口。
114.【实施例一】
115.以下结合图1b中的手机声纹解锁场景,对本实施例的技术方案进行说明。可以理解的是,本技术不限于此,本技术的语音增强方法还可以应用与图1b所示场景之外的其他场景。
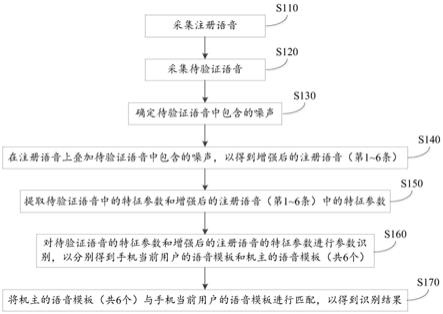
116.参考图3,本实施例用于提供一种语音增强方法,在采集到待验证语音后,从待验证语音中分离出待验证语音中包含的噪声,然后将分离出来的噪声叠加到注册语音上,这样,待验证语音与叠加过噪声后的注册语音具有相似的噪声成分,两者的主要区别在于两者有效语音成分之间的区别,从而可以提高声纹的识别率以及声纹识别方法的鲁棒性。具体地,本实施例提供的语音增强方法包括以下步骤:
117.s110:采集注册语音。为提供声纹解锁功能,手机100上具有声纹解锁应用(可以为系统应用,也可为第三方应用)。为利用手机100的声纹解锁的功能,手机100机主在注册该声纹解锁应用的用户账号时,通过手机100采集本人语音,声纹解锁应用将该语音作为后续声纹识别的基准语音,该语音即为注册语音。但本技术不限于此,例如,在其他实施例中,手机100首次开机时,机主通过手机100的设置向导录入注册语音,手机100的声纹解锁应用将该语音作为声纹识别的基准语音。
118.这里,注册语音为手机100机主在安静环境下录制的语音,这样,注册语音中没有明显的噪声分量。
119.当注册语音录制环境中的信噪比(即,机主语音信号强度与噪声信号强度的比值)进行表征,当录制环境中的信噪比高于设定值(例如,30db)时,认为录制环境为安静环境。或者,当注册语音录制环境中噪声信号的强度低于设定值(例如,20db)时,认为录制环境为安静环境。
120.本实施例中,通过手机100的麦克风采集来自于机主的注册语音。该注册语音为近场语音。在录制注册语音时,机主嘴巴与手机100主mic的距离保持在30cm~1m以内,例如,机主手持手机100正对主mic讲话,机主嘴巴与手机100主mic的距离保持在30cm以内,这样可以避免机主语音由于传播距离较远而出现的衰减。
121.机主在录制注册语音时录入6条语音,以形成6条注册语音。录入多段语言,有助于提升语音识别的灵活性以及声纹信息的丰富性。
122.为兼顾用户的操作体验,以及确保每段注册语音中包含足够的声纹信息,每条注册语音的长度为10~30s。进一步地,每条注册语音对应于不同的文本内容,以丰富注册语音中包含的声纹信息。在采集到注册语音后,手机100将注册语音的音频信号存储在内部存储器中。但本技术不限于此,手机100还可以将注册语音的音频信号上传至云端,以通过云端识别模式对声纹进行识别。
123.以上注册语音的录制方式、录制长度和数量等仅是示例性说明,本技术不限于此。例如,在其他示例中,注册语音可以通过其他录音设备(例如,录音笔、专用话筒等)进行录制,注册语音的数量可以为1条,注册语音的长度可以大于30s。
124.为了叙述的连贯性,步骤s110首先被提及,可以理解的是,步骤s110作为语音增强方法的数据准备过程,其相对于单次的语音增强过程来说是相对独立的,不需要每次都与语音增强方法的其他步骤一起发生。
125.s120:采集待验证语音,待验证语音为手机的当前用户在嘈杂人声场景下录制的语音。换句话说,手机用户可以在该场景中通过声纹识别的手段对手机屏幕进行解锁。另
外,手机的当前用户是当前操作手机100的人,可能是机主本人,也可能机主本人之外的其他人。
126.本实施例中,通过手机100的麦克风采集待验证语音。当手机100的屏幕处于锁屏状态时,手机100的麦克风开启,此时,手机100的当前用户可通过手机100的麦克风录入待验证语音,以通过声纹识别的方式解锁手机。例如,当用户需要远距离操作手机100(例如,开启手机中的某个应用(例如,音乐应用、电话应用)),或者用户需要在双手被占用的情况下(例如,家务劳动时)操作手机100时,通过手机100的麦克风输入待验证语音,以通过声纹识别方式解锁手机。
127.待验证语音是具有特定内容的语音。在其他的实施方式中,待验证语音也可以是任意文本内容的语音。
128.本实施例中,对待验证语音的长度为10~30s,这样,待验证语音中可以包含较为丰富的声纹信息,有利于提高声纹的识别率。但本技术对此不作限定,例如,在另一些实施例中,待验证语音的长度小于10s,这样,待验证语音的长度小于注册语音的长度,这种情况下,用户可以录入较短的待验证语音,有利于提高用户体验。当待验证语音的长度小于注册语音的长度时,可以从待验证语音中截取部分语音片段,并与原始采集到的待验证语音进行拼接,以使得拼接后的语音具有与注册语音基本相同的长度,这样,在本实施例的后续步骤中(下文将进行详细说明),从注册语音中提取到的特征参数和从待验证语音中提取到的特征参数具有相同的维度,便于对两者的相似度进行比较。在本文的描述中,不区分原始采集的待验证语音还是拼接后的待验证语音,本文都称为待验证语音。
129.本文中,a语音与b进行拼接的含义为将a语音与b语音首尾相接,以使得拼接后的语音的长度为a语音和b语音的长度之和。在此基础上,本技术不限定a语音和b语音的连接次序,例如,可以将a语音连接在b语音的后面,也可以将a语音连接在b语音的前面。
130.s130:确定待验证语音中包含的噪声。本实施例中,待验证语音中包含的噪声是识别场景下中除手机100的当前用户以外的其他声源产生的声音。例如,居家场景中家用设备(例如,吸尘器)的声音、洗碗时水流的声音;车载场景中车载广播的声音、发动机的声音;影院环境中放映音响的声音、影院其他观众的语音等。
131.本实施例中,将手机100副mic拾取到声音确定为待验证语音中包含的噪声,从而可以方便地确定待验证语音中所包含的噪声。但本技术不限于此,例如,在一些实施例中,认为待验证语音的起始片段中仅包含噪声成分,从而,将待验证语音的起始片段进行多段复制后,将之确定为待验证语音中包含的噪声;再如,在另一些实施例中,将待验证语音分为多个语音帧,并计算各语音帧的中能量。由于噪声中的能量通常小于有效语音中的能量,因此,当语音帧中的能量小于预定值时,可以将该语音帧确定为噪声帧,从而简化噪声的提取过程。另外,还可以采用现有技术中的其他方法来确定待验证语音中的噪声,不再一一赘述。
132.其中,语音帧的能量表示该语音帧中包括的各语音信号的信号数值的平方之和。示例性地,设语音帧中第i个语音信号的信号数值为xi,该语音帧中语音信号的个数为n,则该语音帧中的能量为
133.s140:在注册语音上叠加待验证语音中包含的噪声,以得到增强的注册语音。本实
施例中,在时域内,将噪声信号的信号数值与注册语音信号的信号数值相加,以得到增强的注册语音。但本技术不限于此,在其他实施例中,也可以在频域内完成注册语音信号和噪声信号的叠加。本技术实施例通过对声音信号信号数值进行简单叠加,实现注册语音信号的增强,算法简单。
134.本实施例中,噪声的长度与注册语音的长度相等,在其他实施例中,噪声的长度可以小于注册语音的长度。
135.本实施例中,注册语音的数量为6条,因此,在6条注册语音上分别叠加待验证语音中包含的噪声,以得到6条增强的注册语音。
136.s150:提取待验证语音的特征参数和增强的注册语音的特征参数。由于mfcc方法能够较好地符合人耳的听觉感知特性,因此,本实施例通过梅尔频率倒谱系数(mel-frequency cepstrum coefficient,mfcc)方法提取语音信号中的特征参数。
137.首先以待验证语音为例,对特征参数的提取过程进行介绍。为便于描述,用s
t
表示待验证语音的音频信号。在进行特征提取之前,首先将待验证语音的音频信号s
t
划分为一系列的语音帧x(n),其中,n为语音帧的数量。考虑到发声器官的运动模型在10~30ms内基本保持稳定,因此,每个语音帧的长度为10~30ms。具体地,本实施例将长度为10s的音频信号s
t
划分为500个语音帧。
138.对音频信号s
t
进行分帧处理之后,通过mfcc方法提取各语音帧x(n)中的特征参数。mfcc特征提取方法包括对语音帧x(n)进行傅里叶变换,梅尔滤波、离散余弦变换等步骤,语音帧x(n)的特征参数即为离散余弦变换后各阶余弦函数的系数。本实施例中,离散余弦变换的阶数为20阶,因此,各语音帧x(n)的mfcc特征参数为20维。
139.将各语音帧x(n)的特征参数进行拼接后,得到待验证语音的音频信号s
t
的mfcc特征参数,可以理解,其维数为20
×
500=10000维。
140.增强的注册语音的特征参数的提取过程可参照上述过程,不再赘述。可以理解,对于每一条增强的注册语音,分别得到一组mfcc特征参数。
141.需要说明的是,以上是对mfcc方法的原理性说明,实际实施过程中,可以根据需要对提取过程进行调整。例如,可对上述提取到的mfcc特征参数进行差分计算。例如,对上述提取到的mfcc特征参数取一阶差分和二阶差分后,对于每个语音帧,得到一组60维的mfcc特征参数。另外,提取过程的其他参数,例如,语音帧的长度、数量、离散余弦变换的阶数等,也可以根据设备计算能力和识别精度需求等进行相应调整。
142.另外,除mfcc方法外,还可以通过其他方法提取语音信号中的特征参数,例如,log mel方法,线性预测倒谱系数(linear predictive cepstrum coefficient,lpcc)方法等。
143.s160:对待验证语音的特征参数和增强的注册语音的特征参数进行参数识别,以分别得到手机100当前用户的语音模板和手机100机主的语音模板。本技术对参数识别的识别模型不作限定,可以是概率模型,例如,身份向量(i-vector)模型;也可以是深度神经网络模型,例如,时延神经网络(time-delay neural network,tdnn)模型,resnet模型等。
144.将待验证语音的10000维特征参数输入识别模型,通过识别模型的降维和抽象之后,得到手机100当前用户的语音模板。本实施例中,手机100当前用户的语音模板为一个512维的特征向量,记为a。
145.相应地,将6条增强的注册语音的特征参数输入识别模型,得到6个手机100机主的
语音模板,各语音模板均为一个512为的特征向量,6个机主语音模板分别记为b1,b2,
……
,b6。
146.可以理解,上述特征向量的维数仅是示例性说明,实际可以根据设备的计算能力和识别精度要求进行调整。
147.s170:将手机100机主的语音模板与手机100当前用户的语音模板进行匹配,以得到识别结果。本技术中,模板匹配方法可以为余弦距离法、线性判别法或概率线性判别分析法等。以下以余弦距离法为例进行说明。
148.余弦距离法通过计算两个特征向量之间的夹角的余弦来评估它们的相似度。以特征向量a(手机100当前用户的语音模板对应的特征向量)和特征向量b1(手机100机主语音模板对应的特征向量)为例,其余弦相似度可表示为:
[0149][0150]
其中,ai为特征向量a中的第i个坐标,bi为特征向量b1中的第i个坐标,θ1为特征特征向量a和特征向量b1的夹角。其中,cosθ1的值越大,表示特征特征向量a和特征向量b1的方向越趋近于一致,两个特征向量的相似度越高。反之,cosθ1的值越小,两个特征向量的相似度越低。
[0151]
对于6条增强的注册语音,得到6个机主语音模板b1,b2,
……
,b6,其与手机100当前用户语音模板的余弦相似度分别为cosθ1、cosθ2,
……
,cosθ6。对6个余弦相似度取均值,得到当前用户语音与机主语音的相似度p=(cosθ1+cosθ2+
……
+cosθ6)/6。
[0152]
如果当前用户语音与机主语音的相似度p大于设定值(例如,0.8),则判断手机100的当前用户为机主本人,此时,手机100解锁屏幕;否则,判断手机100的当前用户并非机主本人,手机100不会解锁屏幕。
[0153]
本实施例中,将待验证语音与6条增强的注册语音分别进行比较,得到6个余弦相似度计算结果,再将6个余弦相似度结果进行平均以得到当前用户语音与机主语音的最终相似度p。本实施例可以对待验证语音和单条增强的注册语音的匹配误差进行平均,有利于提高声纹识别的准确率和声纹识别算法的鲁棒性。
[0154]
需要说明的是,本实施例中,声纹识别的算法(步骤s130~s170所对应的算法)可以在手机100上实现,以实现声纹的离线识别;也可以在云端实现,以节省手机100本地的计算资源。当声纹识别算法在云端实现时,手机100将步骤s120采集到的待验证语音上传到云端服务器中,云端服务器利用声纹识别算法对手机100的当前用户的身份进行认证后,将认证结果返回至手机,手机100根据认证结果决定是否解锁屏幕。
[0155]
以上介绍了本实施例中语音增强方法的实现过程,但可以理解的是,以上仅是示例性说明,在符合本技术发明构思的前提下,本领域技术人员可以在上述实施例的基础上进行其他变形。
[0156]
例如,在一些实施例中,除了根据待验证语音中的噪声对注册语音进行增强之外,还在注册语音中加入混响成分,以得到增强的注册语音。
[0157]
声波在室内传播时,会经过房间墙壁、室内障碍物的多次反射,这样,当声源停止
发生后,还会有若干个声波叠加混合在一起,使得人们感觉到声音在声源停止发声后还会持续一段时间,这种由于声波的多次反射而使声音延续的现象即为混响。
[0158]
当声纹识别的识别场景为室内场景时,待验证说话人的语音会在房间内产生混响,混响作为干扰因素的一部分,会对声纹的识别率造成一定影响。为此,在一些实施例中,基于识别场景对注册语音进行混响预估,即,对注册语音在识别场景下的混响进行模拟,基于混响模拟在注册语音中加入注册语音在识别场景中产生的混响成分,以使得待验证语音的非语音成分与增强的注册语音中的非语音成分尽可能接近,从而提高声纹的识别率以及声纹识别方法的鲁棒性。
[0159]
可选地,基于镜像源模型(image source model,ism)方法,来预估注册语音在识别场景下产生的混响。镜像源模型方法可以模拟声波在房间内的反射路径,根据声波的延迟和衰减参数计算房间声场的冲击响应函数(room impulse response,rir)。在得到房间声场的冲击响应函数后,将注册语音的音频信号与脉冲响应函数进行卷积即得到注册语音在房间内产生的混响。
[0160]
另外,在一些情况下,例如,对智能机器人、智能家居进行语音控制时,待验证说话人与麦克风的距离可能较远(例如,超过1m时),这样,待验证说话人的语音到达麦克风时会产生一定的衰减。因此,在一些实施例中,为考虑待验证语音与麦克风之间的距离因素,通过镜像源模型方法对注册语音进行混响预估时,还对注册语音进行远场仿真。即,在根据镜像源模型方法计算房间的冲击响应函数时,根据待验证说话人与麦克风之间的距离,设定模拟声场中注册语音与语音接收装置之间的距离,这样,可以将注册语音的采集距离模拟与待验证语音相同的采集距离,从而可以进一步减小待验证语音和增强的注册语音之间除有效语音成分之外的其他区别,提高声纹的识别率以及声纹识别方法的鲁棒性。
[0161]
再如,在一些实施例中,在对待验证语音和增强后的语音进行比较之前(即,步骤s50之前),还会对待验证语音进行前端处理,例如,对待验证语音进行回声抵消、去混响、主动降噪、动态增益、定向拾音等。为减小待验证语音和增强的注册语音之间除有效语音成分之外的其他区别,对增强的注册语音进行与待验证语音相同的前端处理(即,使待验证语音与增强的注册语音通过相同的前端处理算法模块),以进一步提高声纹的识别率以及声纹识别方法的鲁棒性。
[0162]
又如,在一些实施例中,可以省去语音信号的特征参数提取步骤(即,步骤s150),直接通过深度神经网络模型对语音信号进行识别等。
[0163]
【实施例二】
[0164]
参考图4,本实施例用于提供另一种语音增强方法,与实施例一不同的是,本实施例中,在采集到待验证语音后,还对待验证语音的采集场景进行识别,以获取待验证语音所对应的场景类型。之后,除了根据待验证语音中包含的噪声确定增强的注册语音之外,还根据上述场景类型确定增强的注册语音。具体地,根据本实施例的由手机100执行的语音增强方法包括下述步骤:
[0165]
s210:采集注册语音,这里,注册语音为手机100机主在安静环境下录制的语音,这样,注册语音中没有明显的噪声分量。
[0166]
s220:采集待验证语音,这里,待验证语音为手机的当前用户在嘈杂人声场景下录制的语音。换句话说,手机用户可以在该场景中通过声纹识别的手段对手机屏幕进行解锁。
另外,手机的前用户是当前操作手机100的人,可能是机主本人,也可能机主本人之外的其他人。
[0167]
s230:确定待验证语音中包含的噪声。本实施例中,待验证语音中包含的噪声是识别场景下中除手机100的当前用户以外的其他声源产生的声音。
[0168]
s240:在注册语音上叠加待验证语音中包含的噪声,以得到增强的注册语音。本实施例中,在时域内,将噪声信号的信号数值与注册语音信号的信号数值相加,以得到增强的注册语音。
[0169]
本实施中,步骤s210~s240与实施例一中的步骤s110~s140实质上相同,对于步骤中的细节过程不再赘述。本实施例中,注册语音的数量与实施例一相同,即,注册语音的数量为6条,因此,在步骤s240中,在6条注册语音上分别叠加待验证语音中包含的噪声,得到6条增强的注册语音。
[0170]
s250:确定待验证语音所对应的场景类型。具体地,在采集到待验证语音后,通过语音识别算法对待验证语音所对应的场景类型进行识别,语音识别算法例如为gmm方法、dnn方法等。在语音识别算法中,场景类型的标签值可以为居家场景;车载场景;室外嘈杂场景;会场场景;影院场景等。
[0171]
s260:在注册语音上叠加模板噪声。模板噪声是与步骤s250所确定的场景类型相对应的噪声,例如,模板噪声是在步骤s250所确定的场景下录制的噪声。其中,对于每个场景类型,可对应多组模板噪声。本实施例中,假设步骤s250中确定待验证语音所对应的场景类型为居家场景,且居家场景下录制有3组模板噪声(例如,家用音视频设备产生的声音、家庭成员对话时产生的背景语音、和/或家用电器产生的噪声等)。
[0172]
然后,将3组模板噪声,分别叠加到6条注册语音上,形成3
×
6=18条增强的注册语音。连同步骤s240中形成的6条增强的注册语音,本实施例中,共形成24条增强的注册语音。
[0173]
s270:提取待验证语音的特征参数和增强的注册语音的特征参数,可参考实施例一中的步骤s150。但可以理解,本实施例中,分别提取24条增强的注册语音中的特征参数。
[0174]
s280:对待验证语音的特征参数和增强的注册语音的特征参数进行参数识别,以分别得到手机100当前用户的语音模板和手机100机主的语音模板,可参考实施例一中的s160。但可以理解,本实施例中,得到24个机主语音模板分别记为b1,b2,
……
,b24。
[0175]
s290:将手机100机主的语音模板与手机100当前用户的语音模板进行匹配,以得到识别结果,可参考实施例一中的步骤s170。但可以理解,本实施例中,24个机主语音模板与手机100当前用户语音模板的余弦相似度分别为cosθ1、cosθ2,
……
,cosθ
24
。对24个余弦相似度取均值,得到当前用户语音与机主语音的相似度p=(cosθ1+cosθ2+
……
+cosθ
24
)/24。
[0176]
如果当前用户语音与机主语音的相似度p大于设定值(例如,0.8),则判断手机100的当前用户为机主本人,此时,手机100解锁屏幕;否则,判断手机100的当前用户并非机主本人,手机100不会解锁屏幕。
[0177]
可以理解的是,以上仅是对本技术的技术方案的示例性说明,在上述基础上,本领域技术人员可以进行其他变形。例如,省去步骤s230和步骤s240,即省去根据待验证语音中包含的噪声对注册语音进行增强的步骤,仅根据与识别场景所对应的模板噪声对注册语音进行增强。这样,增强的注册语音为18条,其对应的机主语音模板为b7,b2,
……
,b24,相应
地,手机100当前用户语音与机主语音的相似度p=(cosθ7+cosθ2+
……
+cosθ
24
)/18。
[0178]
另外,本实施例未提及的技术细节,例如,声纹识别算法的实现主体(在手机100本地实现还是在云端实现),对语音的其他处理(例如,混响预估、远场仿真、前端处理等)等,可以参考实施例一中的介绍,不再赘述。
[0179]
本文中,待验证语音所对应的场景类型、待验证说话人与麦克风之间的距离等均为待验证语音中的环境特征参数。
[0180]
【实施例三】
[0181]
本实施例在实施例一的基础上,将语音增强方法的应用场景进行了变更,具体地,本实施例中语音增强方法应用于图5示出对智能音箱200进行控制的场景。智能音箱200具有语音识别功能,用户可通过语音与智能音箱200进行交互,以通过智能音箱200进行歌曲点播、天气查询、日程管理、智能家居控制等功能。
[0182]
本实施例中,当用户向智能音箱200发出语音指令以使智能音箱200执行某种操作(例如,播放当日日程,播放特定目录的歌曲,对智能家居进行控制等)时,智能基于声纹识别方法对用户的身份进行认证,以判断当前用户是否为智能音箱200的机主,进而判断当前用户是否有控制智能音箱200执行该操作的权限。
[0183]
具体地,本实施例的语音增强方法包括:
[0184]
s310:采集注册语音。本实施例中,通过智能音箱200的麦克风采集来自于智能音箱200的机主的注册语音,但本技术不限于此,在其他实施例中,也可以通过手机、专用麦克风等采集注册语音。在采集到注册语音后,可以将注册语音保存在智能音箱200本地,以通过智能音箱200对用户的声纹进行识别,以实现声纹的离线识别;也可以将注册语音上传到云端,以利用云端的计算资源对用户的声纹进行识别,以节省智能音箱200本地的计算资源。
[0185]
s320:采集待验证语音。本实施例中,通过智能音箱200的麦克风采集待验证语音。待验证语音的采集参数(例如,待验证语音的时长、文本内容)等可以参考实施例一中的描述,不再赘述。
[0186]
s330:确定待验证语音中包含的噪声。本实施例中,将待验证语音分为多个语音帧,并计算各语音帧的中能量。由于噪声中的能量通常小于有效语音中的能量,因此,当语音帧中的能量小于预定值时,可以将该语音帧确定为噪声帧,从而简化噪声的提取过程。
[0187]
s340:在注册语音上叠加待验证语音中包含的噪声,以得到增强的注册语音。本实施例中,在时域内,将噪声信号的信号数值与注册语音信号的信号数值相加,以得到增强的注册语音。
[0188]
s350:提取待验证语音的特征参数和增强的注册语音的特征参数。例如,通过mfcc方法提取待验证语音的特征参数和增强的注册语音的特征参数。
[0189]
s360:对待验证语音的特征参数和增强的注册语音的特征参数进行参数识别,以分别得到智能音箱200的当前用户的语音模板和智能音箱200机主的语音模板。本实施例对参数识别的识别模型不作限定,可以是概率模型,例如,身份向量(i-vector)模型;也可以是深度神经网络模型,例如,时延神经网络(time-delay neural network,tdnn)模型,resnet模型等。
[0190]
s370:将智能音箱200机主的语音模板与智能音箱200当前用户的语音模板进行匹
配,以得到识别结果。本实施例中,模板匹配方法可以为余弦距离法、线性判别法或概率线性判别分析法等。如果当前用户语音与机主语音的相似度大于设定值时,则判断智能音箱200的当前用户为机主本人,此时,智能音箱200响应于用户的语音指令执行相应操作;否则,判断智能音箱200的当前用户并非机主本人,智能音箱200忽略用户的语音指令。
[0191]
需要说明的是,除应用场景外,本实施例的语音增强方法与实施例一的语音增强方法实质相同,因此,本实施例中未描述的技术细节可以参考实施例一中的描述。
[0192]
与实施例一类似,声纹识别的算法(步骤s330~s370所对应的算法)可以在智能音箱200上实现,以实现声纹的离线识别;也可以在云端实现,以节省智能音箱200本地的计算资源。当声纹识别算法在云端实现时,智能音箱200将步骤s120采集到的待验证语音上传到云端服务器中,云端服务器利用声纹识别算法对智能音箱200的当前用户的身份进行认证后,将认证结果返回至智能音箱200,智能音箱200根据认证结果决定是否执行用户的语音指令。
[0193]
另外,本领域技术人员也可将实施例二中的语音增强方法应用于图5示出的对智能音箱控制的场景,不再赘述。
[0194]
现在参考图6,所示为根据本技术的一个实施例的电子设备400的框图。电子设备400可以包括耦合到控制器中枢403的一个或多个处理器401。对于至少一个实施例,控制器中枢403经由诸如前端总线(fsb,front side bus)之类的多分支总线、诸如快速通道连(qpi,quickpath interconnect)之类的点对点接口、或者类似的连接406与处理器401进行通信。处理器401执行控制一般类型的数据处理操作的指令。在一实施例中,控制器中枢403包括,但不局限于,图形存储器控制器中枢(gmch,graphics&memory controller hub)(未示出)和输入/输出中枢(ioh,input output hub)(其可以在分开的芯片上)(未示出),其中gmch包括存储器和图形控制器并与ioh耦合。
[0195]
电子设备400还可包括耦合到控制器中枢403的协处理器402和存储器404。或者,存储器和gmch中的一个或两者可以被集成在处理器内(如本技术中所描述的),存储器404和协处理器402直接耦合到处理器401以及控制器中枢403,控制器中枢403与ioh处于单个芯片中。
[0196]
存储器404可以是例如动态随机存取存储器(dram,dynamic random access memory)、相变存储器(pcm,phase change memory)或这两者的组合。存储器404中可以包括用于存储数据和/或指令的一个或多个有形的、非暂时性计算机可读介质。计算机可读存储介质中存储有指令,具体而言,存储有该指令的暂时和永久副本。该指令可以包括:由处理器中的至少一个执行时导致电子设备400实施如图3、图4所述语音增强方法的指令。当指令在计算机上运行时,使得计算机执行上述实施例一和/或实施例二中公开的方法。
[0197]
在一个实施例中,协处理器402是专用处理器,诸如例如高吞吐量mic(many integrated core,集成众核)处理器、网络或通信处理器、压缩引擎、图形处理器、gpgpu(general-purpose computing on graphics processing units,图形处理单元上的通用计算)、或嵌入式处理器等等。协处理器402的任选性质用虚线表示在图6中。
[0198]
在一个实施例中,电子设备400可以进一步包括网络接口(nic,network interface controller)406。网络接口406可以包括收发器,用于为电子设备400提供无线电接口,进而与任何其他合适的设备(如前端模块,天线等)进行通信。在各种实施例中,网
络接口406可以与电子设备400的其他组件集成。网络接口406可以实现上述实施例中的通信单元的功能。
[0199]
电子设备400可以进一步包括输入/输出(i/o,input/output)设备405。i/o405可以包括:用户界面,该设计使得用户能够与电子设备400进行交互;外围组件接口的设计使得外围组件也能够与电子设备400交互;和/或传感器设计用于确定与电子设备400相关的环境条件和/或位置信息。
[0200]
值得注意的是,图6仅是示例性的。即虽然图6中示出了电子设备400包括处理器401、控制器中枢403、存储器404等多个器件,但是,在实际的应用中,使用本技术各方法的设备,可以仅包括电子设备400各器件中的一部分器件,例如,可以仅包含处理器401和网络接口406。图6中可选器件的性质用虚线示出。
[0201]
现在参考图7,所示为根据本技术的一实施例的soc(system on chip,片上系统)500的框图。在图7中,相似的部件具有同样的附图标记。另外,虚线框是更先进的soc的可选特征。在图7中,soc500包括:互连单元550,其被耦合至处理器510;系统代理单元580;总线控制器单元590;集成存储器控制器单元540;一组或一个或多个协处理器520,其可包括集成图形逻辑、图像处理器、音频处理器和视频处理器;静态随机存取存储器(sram,static random-access memory)单元530;直接存储器存取(dma,direct memory access)单元560。在一个实施例中,协处理器520包括专用处理器,诸如例如网络或通信处理器、压缩引擎、gpgpu(general-purpose computing on graphics processing units,图形处理单元上的通用计算)、高吞吐量mic处理器、或嵌入式处理器等。
[0202]
静态随机存取存储器(sram)单元530可以包括用于存储数据和/或指令的一个或多个有形的、非暂时性计算机可读介质。计算机可读存储介质中存储有指令,具体而言,存储有该指令的暂时和永久副本。该指令可以包括:由处理器中的至少一个执行时导致soc实施如图3、图4所述语音增强方法的指令。当指令在计算机上运行时,使得计算机执行上述实施例一和/或实施例二中公开的方法。
[0203]
本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。
[0204]
本技术的各方法实施方式均可以以软件、磁件、固件等方式实现。
[0205]
可将程序代码应用于输入指令,以执行本文描述的各功能并生成输出信息。可以按已知方式将输出信息应用于一个或多个输出设备。为了本技术的目的,处理系统包括具有诸如例如数字信号处理器(dsp,digital signal processor)、微控制器、专用集成电路(asic)或微处理器之类的处理器的任何系统。
[0206]
程序代码可以用高级程序化语言或面向对象的编程语言来实现,以便与处理系统通信。在需要时,也可用汇编语言或机器语言来实现程序代码。事实上,本文中描述的机制不限于任何特定编程语言的范围。在任一情形下,该语言可以是编译语言或解释语言。
[0207]
至少一个实施例的一个或多个方面可以由存储在计算机可读存储介质上的表示性指令来实现,指令表示处理器中的各种逻辑,指令在被机器读取时使得该机器制作用于执行本文所述的技术的逻辑。被称为“ip(intellectual property,知识产权)核”的这些表示可以被存储在有形的计算机可读存储介质上,并被提供给多个客户或生产设施以加载到实际制造该逻辑或处理器的制造机器中。
[0208]
在一些情况下,指令转换器可用来将指令从源指令集转换至目标指令集。例如,指令转换器可以变换(例如使用静态二进制变换、包括动态编译的动态二进制变换)、变形、仿真或以其它方式将指令转换成将由核来处理的一个或多个其它指令。指令转换器可以用软件、硬件、固件、或其组合实现。指令转换器可以在处理器上、在处理器外、或者部分在处理器上且部分在处理器外。