1.本发明涉及声音识别技术领域,具体为一种水禽声音识别监测系统。
背景技术:
2.声音识别和定位是研究水禽行为、反应水禽健康状况的重要手段之一,对水禽声音信号进行特征辨识和定位,能够提高异常行为辨识的准确率,帮助养殖企业及时掌握其健康状况。
3.传统的语言识别系统的流程繁琐,首先需要提取一些特征,并对采集的数据进行标注;然后对音频数据进行预处理操作以减少其他信息的干扰,预处理主要包括预加重、分帧、加窗和减噪;接下来,利用端点检测技术截取出有效的单个声音数据;最后,将所有带有类别标签的单个声音数据保存在水禽叫声音频数据库,费时费力,效率低,所以急需一种水禽声音识别监测系统来解决上述问题。
技术实现要素:
4.本发明提供一种可直接采集原始数据,并输出健康状况,简化设计工作流程,减少设计成本和时间的水禽声音识别监测系统,来解决上述现有技术中存在的问题。
5.为实现上述目的,本发明提供如下技术方案:一种水禽声音识别监测系统,包括拾音器、音频编解码芯片和嵌入式处理器,所述嵌入式处理器内置有声学识别与分类模型,所述声学识别与分类模型中包括多种水禽声音特征参数,并将时域特征与频域特征进行融合,其中,利用声音训练集的数据对声学识别与分类模型进行训练与调控;
6.所述拾音器采集原始语音数据作为输入,导入音频编解码芯片内,音频编解码芯片对语音数据进行编码后输入至嵌入式处理器中,通过嵌入式处理器中的声学识别与分类模型对语音数据进行处理识别,并将识别与分类结果输出。
7.优选的,构建声学识别与分类模型包括:采集水禽声音数据,并对声音数据特征进行分类标记,形成分类信息数据库;对分类信息数据库进行预处理,获得多种水禽声音特征参数,其中,水禽声音特征参数包括持续时长、短时能量、短时过零率、功率谱密度和mel频率倒谱系数。
8.优选的,所述预处理包括加窗分帧和端点检测,以及对水禽声音的信息利用matlab进行参数计算与提取。
9.优选的,将声音训练集中的音频数据通过python程序生成相应的语谱图作为训练数据的输入,将对应音频信号的标签信息作为另一个输入信息,其中,水禽状态标签将训练集中所有状态生成列表词典,并将一条音频对应的状态序列对于词典的id提出,将填充后生成列表作为标签输入声学识别与分类模型进行训练。
10.优选的,填充后生成列表作为标签即水禽状态序列以最大的输入数据的大小作为标准进行填充,其中,比最长状态序列短的序列以0进行填充,填充后长度与最长状态序列等长,以0补齐。
11.与现有技术相比,本发明的有益效果:本发明中,通过嵌入式处理器内置有声学识别与分类模型,利用拾音器可直接对对原始数据进行重新采样,作为声学识别与分类模型的输入,可直接输出健康状况,无需人工进行特征提取工程,简化设计工作流程,减少设计成本和时间,更加时候复杂的环境的声音识别场景,其中,利用声音训练集的数据对声学识别与分类模型进行训练与调控,优化该模型的参数,增加声音识别精度,提高识别和分类的效率。
附图说明
12.附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。
13.在附图中:
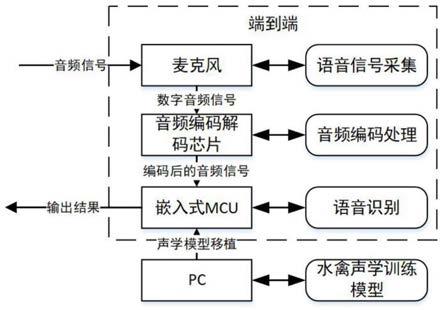
14.图1是本发明水禽声音识别监测系统框图;
15.图2是本发明构建声学识别与分类模型流程框图;
16.图3是本发明声学模型训练流程框图;
17.图4是本发明esc-50中的一条音频信号所生成的波形图。
具体实施方式
18.以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
19.实施例:如图1所示,一种水禽声音识别监测系统,包括拾音器,本实施例中为麦克风、音频编解码芯片和嵌入式处理器,嵌入式处理器内置有声学识别与分类模型(即图中的水禽声学训练模型),声学识别与分类模型中包括多种水禽声音特征参数,并将时域特征与频域特征进行融合,其中,利用声音训练集的数据对声学识别与分类模型进行训练与调控;
20.拾音器直接采集原始语音数据作为输入,导入音频编解码芯片内,音频编解码芯片对语音数据进行编码后输入至嵌入式处理器中,通过嵌入式处理器中的声学识别与分类模型对语音数据进行处理识别,并将识别与分类结果输出。
21.参考图2,为构建声学识别与分类模型流程框图,其中,采集水禽声音数据,,通过对不同疾病的呼吸音和咳嗽声音特征进行分类标记,通过和发病模型的比对,将相关水禽行为活动声、健康咳嗽声和各种患病咳嗽声进行分类甄别,得到水禽各种呼吸音和咳嗽声音的数据集,形成分类信息数据库;然后对采集到的水禽呼吸声音和咳嗽声音进行预处理,预处理步骤包括加窗分帧和端点检测;后对水禽声音的信息利用matlab进行参数计算与提取,获取的特征参数包括:持续时长、短时能量、短时过零率、功率谱密度和mel频率倒谱系数;此时,分别得到不同患病与健康水禽的声音特征参数;
22.在分析得到水禽咳嗽声音信息的数据信息区别后,将具有区分特征的时域特征与频域特征进行融合;然后针对声音参数特征,利用支持向量机建立水禽咳嗽声音识别模型;然后利用声音训练集的数据,将其输入到建立好的声音识别模型中,对识别模型进行训练与调控,优化模型的参数,增加声音识别精度,最终获得高精度的基于声音识别技术的水禽呼吸道疾病智能识别与分类模型。
23.参考图3,为声学模型训练流程框图,将样本数据读入内存,将语言数据转化为梅
尔倒频系统,建立批次获取样本的函数,将mfcc转变成训练格式数据时间列表和频率特征系数的矩阵,将状态文本转换为向量,对齐改批次的音频数据,构件网络结构进行模型训练;其中,针对声音模型训练,本实施例中利用开源的音频数据集esc-50数据集进行训练操作,此数据集中的音频片段是从freesound.org项目收集的公共场合音频数据中手动提取的;数据集预先划分为5个文件夹,方便进行交叉验证比较,通过确保同一源文件的音频片段在相同的文件夹中;
24.首先,提取提取音频图谱,每一条语音都可以通过音频数据提取特征值,也可以通过相应预处理操作后提取出相应的语谱图,语音信号虽然是音频信号,却可以通过快速傅立叶变换取模、取对数后,绘制训练所需要的语谱图;在pycharm环境下,进行语言信号的预处理操作,为优化的dfcnn模型的训练做好相应的准备;将esc-50的音频信号作为输入,利用python进行处理,将其中一条语音信号通过python程序读入后之后,只需要scipy、plt、os三个库即可实现此过程,并可以将音频数据以波形图的形式展现在电脑上,如图4所示为esc-50中的一条音频信号所生成的波形图,图为该语音信号的波形图进行预加重操作后的图像,预加重系数设置为0.98。将生成的语谱图和经过处理生成列表的id作为训练模型的输入数据,输入tensorflow所搭建好的模型中进行训练操作;作为tensorflow中最为重要的实现卷积的函数,首先tf.nn.conv2d(input,filter,strides,padding)为conv2d重要的四个参数:
25.input:代表需要进行卷积训练的图片信息,其格式需是张量(tensor),其所包含的结构一般是[batch,in
height
,in
width
,in
channels
],即训练一个系列的图片数量,图片高度,图片宽度,图片通道数这思维信息,语谱图只有单一颜色,通道数为1。
[0026]
filter:卷积核的张量,以卷积核的高度,卷积核的宽度,图像通道数,卷积核个数进行设置,其中第三维同input的第四维数据需保持一致,设置为1。
[0027]
strides:代表图像在卷积时的步长;padding代表只进行有效的卷积。
[0028]
为了更有效的对语谱图的特征进行提取,在dfcnn单元结构中第一个单元中两个层卷积和数量都设置为32,3x3的卷积核大小,步长为1;第二个单元层两个卷积核数量设置为64,3x3的卷积核大小,步长为1;第三个单元层与前两个结构类似,除了卷积核个数设置为128;第四个单元层结构除了池化层之外与其他三个单元层相同。卷积核个数也是如此设置,为了更好的提取前一层结构的特征值。padding设置为same,每个卷积层都需要通过激活函数来进行非线性操作,在此选择relu激活函数,在卷积层外部添加tf,nn,relu()函数即可。
[0029]
在每个单元结构的两层卷积层之间需要添加dropout层,防止或减轻过拟合,在tensorflow中常使用tf,nn,dropout函数,在训练舍弃一部分神经元,即让某个神经元的激活值以概率p停止工作,训练中不更新权值也不参加神经网络计算,仅保留其权重不更新,下次样本输入工作;tf,nn,dropout函数参数设置方式为:tf,nn,dropout(x,keep_prob),其中,第一个参数x:指输入,第二个参数keep_prob:设置神经元被选中的概率;keep_prob在初始化时是一个占位符,tensorflow在运行时设置keep_prob具体的值,设置每个卷积层之间的dropout函数时,以0.05递增的方式进行设置,第一个dropout设置为0.05而后设置为0.10直到最后的两层卷积层设置为0.2为止。
[0030]
之后需对结果再进行池化操作,即降采样,利用最大池化,保留最显著特征,并进
一步使模型的畸变容忍能力得到提升;在tensorflow中采用tf.nn.max_pool(value,ksize,strides,padding)函数进行最大池化操作,其中,value代表池化的输入,在池化层在卷积之后出现,具体结构是[batch,in_height,in_width,in_channels];ksize为池化窗口的大小,四维向量作为其参数,结构为[1,height,width,1];
[0031]
strides为步长,[1,stride,stride,1]同为四维向量;padding为和卷积类似,取valid或者same,选择valid,返回一个张量,其结构为[batch,in_height,in_width,in_channels]。
[0032]
fc全连接层,函数tf.layers.dense主要参数包含:input该层的输入、units输出的大小(维度)本项目设置为256,activation选相应的激活函数即神经网络去线性操作;全连层后得到高度提纯后的特征。
[0033]
最后通过tf.nn.softmax函数主要进行分类操作,此函数输入为上一层输出。
[0034]
对声学识别与分类模型的输入输出的处理:将声音训练集中的音频数据通过python程序生成相应的语谱图作为训练数据的输入,将对应音频信号的标签信息作为另一个输入信息,其中,水禽状态标签将训练集中所有状态生成列表词典,并将一条音频对应的状态序列对于词典的id提出,将填充后生成列表作为标签输入声学识别与分类模型进行训练,填充后生成列表作为标签即水禽状态序列以最大的输入数据的大小作为标准进行填充,其中,比最长状态序列短的序列以0进行填充,填充后长度与最长状态序列等长,以0补齐;填充数据是便于并行训练操作,将语谱图和填充后的标签作为dfcnn模型的输入。
[0035]
最后应说明的是:以上所述仅为本发明的优选实例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。