1.本发明涉及语音增强与语音降噪技术。
背景技术:
2.语音增强旨在通过分离语音和噪声成分来提高语音信号的可懂度和清晰度,对自动语音识别技术、助听器、移动设备等产业产生巨大影响,从而受到了极大的关注;近些年得益于深度学习的进步,业界内有关语音增强的研究显著增加,大量基于深度学习的方法实现了干净语音与噪声有效分离。
3.多层的深度神经网络dnn被用于从带噪对数功率谱到干净语音的非线性映射来对语音进行增强,证明了深度神经网络在语音增强任务上的有效性;与基于dnn的模型相比,卷积神经网络cnn由于其参数共享机制在参数更少的情况下获得了很好的性能。cnn在语音增强中有多种用处,包括使用冗余卷积编解码器模型来映射干净语音信号及使用基于cnn的模型来估算干净语音的复数谱图;cnn和递归神经网络rnn的联合使用可以充分利用cnn的特征提取能力和rnn的时间建模能力;另外,有关学者还提出了带有门控和残差机制的扩张卷积模型以提高泛化能力。
4.受unet结构在医学图像处理领域的影响,越来越多的工作尝试于将unet架构引入语音增强领域。而其中的跳跃连接(skip connections)也被广泛用于直接传递低粒度特征,以更好地重建语音语谱图。尽管跳跃连接被证明可以很好地补充低级特征,其仍然存在以下两个问题。其一,模型底层的降噪能力有限,低信噪比条件下直接将底层的信息补充到高层级在引入细粒度信息的同时也引入了大量的噪声。其二,跳跃连接忽略了低层与高层之间可能存在的语义差异,导致信息融合效率与准确性低。
技术实现要素:
5.本发明所要解决的技术问题是,针对现有引入unet架构的语音增强模型由于跳跃连接直接传递低粒度特征到高层级时引入噪声和存在语义差异的问题,提供一种准确性更高的语音增强方法。
6.本发明为解决上述技术问题所采用的技术方案是,一种基于信息蒸馏与聚合的低信噪比语音增强方法,包括以下步骤:
7.1)对原始语音信号进行短时傅立叶变换得到原始语谱图;
8.2)将原始语谱图进行语音特征提取得到语音信息表示;
9.3)对语音信息表示进行多阶段信息蒸馏处理得到过滤噪声成分之后的语音信息蒸馏结果;蒸馏处理通过n个串行自注意力信息处理子模块与n个串行的信息蒸馏子模块实现,第n个自注意力信息处理子模块的输出信号即为语音信息蒸馏结果:
10.第t个信息蒸馏子模块的输出信号y
t
为:第t个自注意力信息处理子模块输出的信号x
t
为:
11.其中,t为序号变量,1≤t≤n,x0和y0均为步骤2)输出的语音信息表示;y
t-1
为第t-1
个信息蒸馏子模块的输出信号y
t
;x
t-1
为第t-1个自注意力信息处理子模块的输出信号;为自注意力信息处理函数,为信息蒸馏处理函数;
[0012][0013]
其中,
⊙
代表点乘操作,a
t-1
为第t-1个权重矩阵:
[0014][0015]
其中,σ是sigmoid激活函数,conv2和conv3分别是两个不同卷积核的步长相同的二维卷积层;
[0016]
4)将语音信息蒸馏结果进行语谱图重建;
[0017]
5)对重建的语谱图进行反短时傅里叶变换得到时域增强语音信号。
[0018]
本发明根据注意力机制和信息蒸馏机制形成的多阶段信息蒸馏处理过程中,串行的信息蒸馏子模块组成一条信息蒸馏线,n个自注意力信息处理子模块共享该信息蒸馏线。自注意力信息处理子模块通过信息蒸馏线不断地汇聚各个信息蒸馏子模块的输出并自适应地进行信息校准,每一时刻的信息蒸馏线上的校准后信息将作为下一时刻自注意力信息处理子模块的输入,通过n个注意力信息处理子模块与n个信息蒸馏子模块顺序的信息蒸馏与重新校准,最终实现噪声成分过滤的效果。
[0019]
进一步的,语谱图重建的通过m个基于动态选择机制的自适应性信息集合模块串联完成,每个自适应性信息集合模块对输入的语音信息分别进行多尺度卷积处理和形变卷积处理,再基于动态选择机制聚合对多尺度卷积处理和形变卷积处理的信息。
[0020]
本发明根据动态选择机制融合多尺度卷积子模块和形变卷机子模块的输出,以提供更好的特征处理能力和较高稳定性,并基于所述基于动态选择机制的自适应性信息集合模块构建得到语音特征解码器,进而构建语音增强模型;同时,本发明仅仅使用darcn一半的参数(0.68m),便取得了最优的性能,在模型训练时间上也有明显优势。所提出的基于信息蒸馏和聚合的单声道语音增强方法在stoi和pesq指标上均好于所有对比例,其中stoi平均得分上比最优对比例高出0.40,pesq平均得分上比最优对比例高出0.02。
[0021]
本发明的有益效果是,能够适应不同环境下的语音特征提取,使模型能够适应不同噪声的声学特征,显著提升语音增强的效果。
附图说明
[0022]
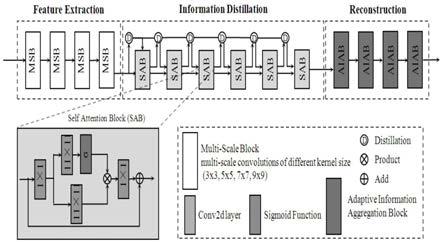
图1为实施例中基于信息蒸馏和聚合的单声道语音增强模型的网络结构示意图;
[0023]
图2为实施例中基于动态选择机制的自适应性信息集合模块的网络结构示意图。
具体实施方式
[0024]
在时域上,一段喊噪声信号x(n)可以被表示为:
[0025]
x(n)=s(n)+d(n)
[0026]
其中,n是时间帧的索引,s(n)表示原信号,d(n)表示噪声信号。值得注意的是,由于输入语音时长不同,因此各个样本中时间帧的维度是不固定的。在时域中给定一个大小为n的实值向量x,通过短时傅里叶变换stft将x(n)转换为时频域:
[0027][0028]
其中其中是z的复共轭,α是时移步长,g是一个分析窗(通常使用汉宁窗或者汉明窗),l是原始波的长度,n是频点的数量。在stft的定义里,时间帧的数量为t=l/α。因此,stft的输出是一个大小为t
×
f的二维矩阵。输入为带噪的幅度谱,经过处理后,得到增强的幅度谱。最后,通过对增强的幅度谱和带噪的相位谱进行逆短时傅里叶变换istft重建时域上的语音波形。
[0029]
本发明提供的基于信息蒸馏和聚合的单声道语音增强方法主要用于噪声环境下的语音增强问题。
[0030]
如图1所示的单声道语音增强模型的网络结构包括语音特征提取器feature extraction、信息蒸馏单元information distillation和语谱图重建模块reconstuction串联构成;根据该网络结构实现语音增强的方法如下:
[0031]
步骤1:对原始语音信号进行短时傅立叶变换得到原始语谱图;
[0032]
步骤2:将原始语谱图输入语音特征提取器feature extraction得到语音信息表示;
[0033]
步骤3:由信息蒸馏单元information distillation对上一步骤所得到的语音信息表示进行多阶段信息蒸馏,保留语音信息的同时丢弃噪声成分;
[0034]
步骤4:由语谱图重建模块reconstuction将信息蒸馏的结果利用基于动态选择的信息聚合机制形成重建的语谱图;
[0035]
步骤5:最后对重建的语谱图进行反短时傅里叶变换得到时域增强语音信号。
[0036]
具体的,步骤2中语音特征提取器feature extraction由4个基于多尺度卷积模块msb(multi-scale block)串联构成,依次为第一至第四多尺度卷积模块;其中,第一自适应卷积模块的输入通道数为1,第一至第四自适应卷积模块的输出通道数依次为4、8、16、32。更具体的,每个多尺度卷积模块由4个卷积核大小不同的二维卷积层组成,卷积核大小分别为(3,3),(5,5),(7,7),(9,9),最后通过一个(1,1)的标准卷积整合信息。
[0037]
传统的跳跃连接直接传递低粒度特征到高层级时会引入噪声并且低粒度特征与高层级特征之间可能存在语义差异;为了减少这种语义差异,因此本发明提出了一种多阶段信息蒸馏,其灵感来自于图像超分辨率领域。步骤3的具体过程为:信息蒸馏单元information distillation包括n个基于自注意力机制的信息蒸馏单元,以顺序进过的方式凝练语音特征。其中,每个信息蒸馏单元包含一个自注意力信息处理子模块sab并互相共享一条信息蒸馏线,信息蒸馏线由串联的n的信息蒸馏子模块d实现。自注意力信息处理子模块通过信息蒸馏线不断地汇聚各个信息蒸馏子模块的输出并自适应地进行信息校准,每一时刻的信息蒸馏线上的校准后信息将作为下一时刻自注意力信息处理子模块的输入,通过n个注意力信息处理子模块与n个信息蒸馏子模块顺序的信息蒸馏与重新校准,最终实现噪声成分过滤的效果。
[0038]
图1中的n=6。即,信息蒸馏单元包括6个串联的自注意力信息处理子模块sab,6个sab共享一条信息蒸馏线。信息蒸馏线又6个串联的信息蒸馏子模块d构成。信息蒸馏线上有一个注意力机制以自适应地校准信息;
[0039]
自注意力信息处理子模块的结构为:最初输入信息经过(1,1)的二维卷积层分别经过两条路(一条路为(11,11)的二维卷积层,另一条路为顺序通过(11,11)的二维卷积层和sigmoid激活函数),两条路的输出相乘,再通过一层(1,1)的二维卷积层,结果与最初输入信息相加作为最后输出;
[0040]
每个信息蒸馏子模块会进行两个操作;首先通过对上一时刻蒸馏线上的信息y
t-1
(第t-1个信息蒸馏子模块d的输出信号的输出信号)做全局平均池化和全局最大池化,并将结果进行拼接、激活得到权重矩阵a
t-1
:
[0041][0042]
其中,ca是拼接操作,conv1代表了一个用来压缩通道的(1,1)二维卷积层,σ是sigmoid激活函数,和分别代表全局平均池化和全局最大池化操作;然后再通过通道维度的压缩与激励机制(squeeze and excitation)校准信息蒸馏线上的信息y
t-1
:
[0043][0044]
其中,a是通道级的注意力权重,
⊙
代表点乘操作;随后,通过初始化一个自注意的门控机制来从当前输入x
t
(第t个自注意力信息处理子模块sab输出的信号)挖掘深层潜在关联:
[0045][0046][0047]
其中,conv2和conv3是两个不同的(11,11)二维卷积层;最后保存在信息蒸馏线(t-1)时刻的信息将被更新为:
[0048][0049]
进一步的,完成步骤4)的语谱图重建模块reconstuction由4个基于动态选择机制的自适应性信息集合模块aiab(adaptive information aggregation block)串联构成,依次为第一至第四自适应卷积模块;其中,第一自适应卷积模块的输入通道数为32、第一至第四自适应卷积模块的输出通道数依次为16、8、4、1;
[0050]
如图2所示,基于动态选择机制的自适应性信息集合模块aiab包括多尺度卷积子模块m-module和形变卷积子模块d-module;并通过动态选择机制聚合两个子模块的输出,重建图谱;
[0051]
首先采用多尺度的卷积层作为信息提取部分,包含4种不同大小的卷积核(3
×
3,5
×
5,7
×
7,9
×
9);之后,使用形变卷积去拟合光谱图像的几何变换;在形变卷积中,使用一个额外的二维卷积层来估计常规网格采样位置的二维偏移;计算在样本偏移δpn修正位置pn的加权以得到x(p0)的输出特征y(p0):
[0052][0053]
其中,w为内核中可学习权重,pn为第n个位置,δpn为位置pn预先指定的偏移量,包含了所有采样点到中心点的相对位置;在δpn的帮助下,常规网格可以自适应地调整接受野;值得注意的是,偏移量δpn常常是分数,所以在实施的时候需要线性插值;
[0054]
最终,通过双重注意力聚合单元来融合这两个分支(多尺度卷积模块和形变卷积模块),然后通过通道级和空间级注意力机制动态地聚合两条支路的输出特征;假设多尺度卷积的输出为m,形变卷积的输出为d,首先,通过加法直接融合两个输出特征:
[0055]
u=d+m
[0056]
然后,通过全局平均池化生成通道维度和空间维度的权重c和s;具体地说,分别通过收缩特征u的空间维度t
×
f和通道维度c来计算的第k个元素uk和的第(m,n)个元素u(m,n):
[0057][0058][0059]
然后,通过维度不变的一层二维卷积操作得到通道级和空间级的特征表示。本实施例中,将上述得到的两个表示经过四层卷积(通道级表示经过两个并行的卷积层,空间级表示经过两个并行的卷积层),得到四个相关的权重c_a,经过softmax进行权重归一化,继而作用于不同的支路,然后动态聚合两条支路的信息。
[0060]
最后,基于上述语音增强模型重建干净语谱图。
[0061]
针对跳跃连接存在的普遍问题:直接传递低层级特征到高层级,虽然补充了大量细节信息,但也引入了大量的噪声信息,该特性在低信噪比场景下尤其明显;本发明采用信息蒸馏与信息聚合机制,不断地蒸馏和重新校准历史信息,逐层汇聚以更好地恢复干净语音;本发明等效于使用信息蒸馏方式的特征提取模型,利用双重注意力机制动态汇聚不同支路的并行多路学习模型。
[0062]
本实施例中,渐进式学习模型的训练集选择timit数据集中3696个语句,干净语音采样率均为16khz、噪声来自noisex92数据集和demand数据集(包括五种不同工业环境噪声以及一种生活噪声“餐厅噪声”、信噪比为(-5db,0db和5db));模型一共训练了60轮,设置学习率为0.0002,采用平均绝对误差函数(mae)作为损失函数,使用adam优化器对所述模型进行训练。
[0063]
采用timit数据集中192个语句(干净语音采样率均为16khz)作为测试集,在可见噪声的基础上增加了三种训练时未见过的工业噪声以及一种生活噪声(“咖啡厅噪声”)。此外,还使用两种未曾见过的信噪比(-10db和10db)对所述模型进行测试;通过将192条语句分别与不同的噪声(9种)和不同的信噪比(5种),共构建测试数据6720条;对语音使用短时傅立叶变换(stft),使用窗长度为20ms、帧重叠为10ms的汉宁窗将语音信号转换为语谱图,评估指标选用短时客观清晰度(stoi)和语音质量感知评估(pesq)。
[0064]
以文献“s.r.park and j.lee,“a fully convolutional neural network for speech enhancement,”in interspeech 2017,18th annual conference of the international speech communication association,stockholm,sweden,august 20-24,2017,2017,pp.1993
–
1997.”中提到的模型rced、“k.tan and d.wang,“a convolutional recurrent neural network for real-time speech enhancement.”in interspeech,
2018,pp.3229
–
3233.”中提到的模型crn,文献“ke tan,jitong chen,and deliang wang,“gated residual networks with dilated convolutions for monaural speech enhancement,”ieee/acm transactions on audio,speech,and language processing,vol.27,no.1,pp.189
–
198,2018.”中提到的模型grn、文献“a.li,c.zheng,c.fan,r.peng,and x.li,“a recursive network with dynamic attention for monaural speech enhancement,”in interspeech 2020,21st annual conference of the international speech communication association,virtual event,shanghai,china,25-29october 2020.isca,2020,pp.2422
–
2426.”中提到的模型darcn为对比例,将本发明提出的基于自适应注意力机制和渐进式学习的单声道语音增强方法idanet与对比例的stoi和pesq指标在不同信噪比条件下进行对比,如下表所示:
[0065]
表1不同模型在可见噪声场景下的stoi和pesq对比
[0066][0067]
表2不同模型在未见噪声场景下的stoi和pesq对比
[0068][0069]
本发明仅仅使用darcn一半的参数(0.68m),便取得了最优的性能,在模型训练时间上也有明显优势。所提出的基于信息蒸馏和聚合的单声道语音增强方法在stoi和pesq指标上均好于所有对比例,其中stoi平均得分上比最优对比例高出0.40,pesq平均得分上比最优对比例高出0.02。
[0070]
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。