1.本发明涉及一种用于电力调度业务领域的基于人工智能的配网调度语音交互方法。
背景技术:
2.随着电网规模扩大及信息化建设进程的不断推进,电网运行数据复杂多变,发输变配调各环节信息和数据量也在不断增长,对电力调度业务的数据处理及响应能力形成了新的挑战,现有的配网调度系统人机交互模式仍主要依靠键鼠完成,同时业务系统存在诸多缺陷,难以适应现阶段的配网调度运行管理需求,有必要通过技术创新,解决现有业务系统存在的操作繁琐、响应慢等问题。
3.当前人工智能技术在人机交互模式方面极具先进性,在电力系统中的应用也做过不少尝试,通过关键技术的创新和延伸应用,实现传统业务的智能化改造。目前,人工智能技术在电力系统中的应用主要集中在理论研究方面,在交互方面的落地应用较少。
技术实现要素:
4.本发明的目的是为了克服现有技术的不足,提供一种基于人工智能的配网调度语音交互方法,开发适用于配网电力调度的人机交互技术,并利用智能语音交互技术,实现语音调图、设备语音定位、供电路径查询、潮流信息查询等语音交互场景,实现了语音交互技术在电力系统的应用实践。
5.实现上述目的的一种技术方案是:一种基于人工智能的配网调度语音交互方法,包括语音训练步骤和语音识别:
6.语音训练如下步骤:
7.步骤1.1,数据采集和预处理,通过采集文本数据和音频数据进行关键字数据收集以构建训练样本库,然后针对文本和音频数据进行数据筛选和关联匹配,将文本数据和音频数据一一对应,并且依据数据类型打上相应的序列标签,得到准确的拼音序列和音素序列;
8.步骤1.2,语言模型和声学模型训练,对于音频数据,根据每帧音频将语音文件解读成为各小段,通过对每一小段的语音中存在的音素进行识别,结合音调分析,自动辨识归类多音素组成的音素集;经过声学模型的构建,在文字给定后,将单词组合转换成音素集,计算发生对应音频的概率,并在不断的识别训练中,经过统计规律计算,将常见、应用广泛的单词、短语等存储至数据库中,提升识别效率;
9.语音识别包括如下步骤:
10.步骤2.1,通过解析语音指令,通过设计多轮对话流程,通过对电压等级、目标地区的精确识别定位目标d5000系统厂站图,自动调取目标svg图形并进行展示,实现语音调图;
11.步骤2.2,基于d5000系统厂站图接口,通过解析语音指令快速识别目标设备,自动跳转到目标设备厂站图位置,进而实现设备语音定位;
12.步骤2.3,多轮对话查询模块通过语音问答的形式采集调控人员的语音数据并数据解析,根据意图识别结果生成相应的查询模型,调取目标系统功能接口执行相应的业务功能。
13.本发明的一种基于人工智能的配网调度语音交互方法,通过构建电力领域的专业语料库,训练适用调度的语音识别、意图识别模型,通过多轮对话技术搭建人机交互引擎,支撑调度业务语音交互的实现,对语音指令进行识别与解析,基于交互接口对现有相关业务系统执行交互控制。基于语音交互技术能够实现调控中心现有交互模式的智能化升级,通过构建调控专业语料库和语音识别、意图识别模型,基于多轮对话技术的运用,实现智能人机交互。通过与其他系统建立交互接口的方式,形成联合控制通道,最终实现语音调图、设备语音定位、供电路径查询、潮流信息查询等功能,大幅减轻人工工作压力,提高调控相关工作的执行效率。
附图说明
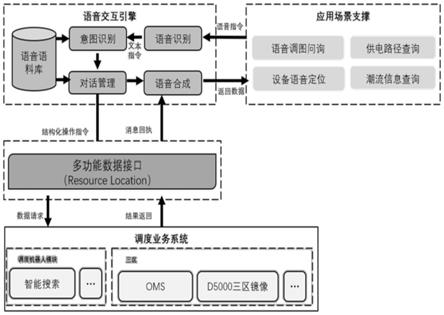
14.图1为本发明的一种基于人工智能的配网调度语音交互方法的架构示意图。
具体实施方式
15.为了能更好地对本发明的技术方案进行理解,下面通过具体地实施例进行详细地说明:
16.请参阅图1,本发明的一种基于人工智能的配网调度语音交互方法,包括语音训练步骤和语音识别:
17.语音训练如下步骤:
18.步骤1.1,数据采集和预处理。通过采集文本数据和音频数据进行关键字数据收集以构建训练样本库,然后针对文本和音频数据进行数据筛选和关联匹配,将文本数据和音频数据一一对应,并且依据数据类型打上相应的序列标签,得到准确的拼音序列和音素序列。
19.步骤1.2,语言模型和声学模型训练。语音模型的构建需要满足大词汇量、独立于说话人的识别要求,可以支持海量语法规模的词汇量,并能适应不同人群、不同地域、不同部门、不同信道、不同终端和不同噪声环境的应用环境。对于音频数据,通过分析说话人的声音,根据每帧音频将语音文件解读成为各小段,通过对每一小段的语音中存在的音素进行识别,并结合声调分析,自动辨识归类多音素组成的音素集;经过声学模型的构建,在文字给定后,结合词典的标准音,将单词组合转换成音素集,计算发生这段音频的概率,并在不断的识别训练中,经过相应的语言统计规律计算后,将常见、应用广泛的单词、短语等存储至数据库中,提升识别效率。
20.语音识别包括如下步骤:
21.步骤2.1,通过解析语音指令,通过设计多轮对话流程,通过对电压等级、目标地区的精确识别定位目标d5000系统厂站图,自动调取目标svg图形并进行展示,实现语音调图;
22.步骤2.2,基于d5000系统厂站图接口,通过解析语音指令快速识别目标设备,自动跳转到目标设备厂站图位置,进而实现设备语音定位;
23.步骤2.3,多轮对话查询模块通过语音问答的形式采集调控人员的语音数据并数
据解析,根据意图识别结果生成相应的查询模型,调取目标系统功能接口执行相应的业务功能。如,实现供电路径查询、潮流信息查询等功能。
24.本发明基于语音识别与交互技术对配网调控中心现有的业务系统及交互模式进行升级。数据采集和预处理步骤中,数据采集主要是保障采集数据的安全性和数据访问安全性,保障数据存储的高可用性,数据预处理主要是针对文本和音频数据进行数据筛选及关联匹配。语言模型和声学模型训练步骤中,语音识别中需要分析声音特征,进行语言训练,声学模型训练是给语音识别提供帧和状态所对应的概率。
25.本发明进行端点检测。在进行在对说话人语音进行识别前,首先要将语音中未包含任何音频的部分进行删减,并识别出噪音频段进行删除,构建有效及无效两类音频信号,在删除无效音频信号之后,得到精确、完善的可用语音。
26.本发明进行语音识别。通过已经构建的声学模型,识别语音的未知内容,通过对语音时序的拆解、分析,基于语言模型和声学模型的构建,通过端点监测后,生成相应的语音转换文件。文本语料制作。对文本语料分类和去重,统计文本中声母和韵母的覆盖率。
27.本发明进行语音录制。根据所需录音者的分类将文本语料精准分,并在其录制完毕后收集各人的音频,打上相应标签。
28.本发明进行意图识别。通过文本编辑距离计算、textcnn模型算法,实现电力领域的交互用户真正意图获取。
29.本发明进行多轮对话自定义配置,主要包括多轮对话配置模块、意图识别模块、实体识别模块以及多轮对话存储模块,供在一次对话过程中支持多意图切换的能力,保障人机交互的顺畅性。
30.本技术领域中的普通技术人员应当认识到,以上的实施例仅是用来说明本发明,而并非用作为对本发明的限定,只要在本发明的实质精神范围内,对以上所述实施例的变化、变型都将落在本发明的权利要求书范围内。