1.本发明属于语音转换技术领域,具体涉及一种基于自动编码器框架的语音转换方法。
背景技术:
2.随着智能语音技术的迅猛发展,音频变声技术已经成为目前新兴的一项热门技术,其旨在将某一源语音转换成具有特征语音风格且语音内容不发生变化的目标语音;例如,某一变声应用将用户录制的某一段音频采用某一特点目标的变声特效进行变声播放。
3.目前,语音转换系统中,针对非配对数据的方法非常少,仅有autovc、one-shot vc、prosody transfer和speechflow四种实现了非配对数据下的语音转换,且其中仅有prosody transfer和speechflow能够实现对韵律的转换。但是以上两种方法仍然包含两大缺点:一是对于内容不同音频的韵律转换效果较差;二是模型的训练时间较长。
4.经过检索发现,公开号为cn111312267a的发明专利申请,公开了一种语音风格的转换方法、装置、设备和储存介质;其对语音分离的流程为:获取源风格语音、目标风格语音和初始转换语音;根据初始转换语音和源风格语音之间的语音内容损失以及初始转换语音和目标风格语音之间的语音风格损失,对初始转换语音进行损失优化,得到新的初始转换语音继续进行损失优化,直至新的初始转换语音满足预设的损失优化条件,则将新的初始转换语音作为源风格语音在目标风格下的风格转换语音。上述专利申请中的技术方案的优点在于,实现了源风格语音在目标风格下的准确转换,无需针对目标风格进行语音风格转换的预先训练,保证未经过预先训练的目标语音下的语音风格转换,提高语音风格转换的全面性和准确性。
5.而上述技术方案,是针对说话人音色进行语音转换,并不能针对语音风格进行转换,其次是不能保证完全实现所有语音特征的分离。
技术实现要素:
6.本发明公开了一种基于自动编码器框架的语音转换方法,拟解决背景技术中提到的不能针对语音风格进行转换,且不能保证完全实现所有语音特征分离的技术问题。
7.为解决上述技术问题,本发明采用的技术方案如下:
8.一种基于自动编码器框架的语音转换方法,包括以下步骤:
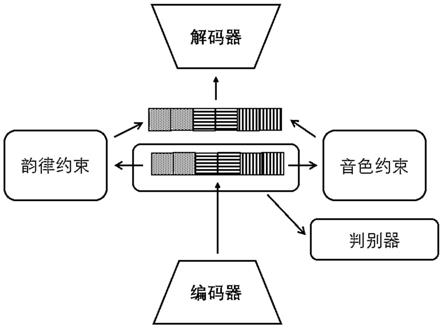
9.步骤1:基于开源的音频处理库,提取音频的mel频谱特征作为数据集;
10.步骤2:搭建由编码器、解码器、鉴别器和分别针对音色和韵律的两个约束模型组成的系统框架;
11.步骤3:将步骤1中的数据集输入步骤2搭建的系统中,进行约束模型的训练,直至损失函数收敛,提取源说话人和目标说话人对应的语音特征;
12.步骤4:基于步骤3中提取的语音特征,并替换源韵律编码为目标编码,完成语音转换任务。
13.本发明所搭建的系统框架仅包括一个编码器,使得训练过程中没有丢失原始输入的mel频谱信息,实现完美重构;通过两个约束模型通编码器和解码器结合训练,确保了内容、音色和韵律三个语音特征的可提取性;并且采用鉴别器进一步的确保了内容、音色和韵律三个语音特征的可提取性,实现了语音特征的完全分离;本发明针对不同内容的音频进行语音转换时,不涉及配对数据的训练,模型训练过程仅仅重构自身,故实现了高效的语音转换。
14.优选的,所述编码器、解码器、约束模型和鉴别器均是基于informer:aaai2021 best paper的标准搭建而成。informer为固定模型名称,aaai2021 best paper为2021年美国人工智能协会会议(aaai)最佳论文。
15.优选的,步骤2中系统框架的网络结构有2层或3层prosparse attention模块堆叠组成。prosparse attention为稀疏化概率的注意力机制。
16.通过利用prosparse attention模块,使得模型训练时间大大降低;进一步的提高了语音转换的效率。
17.优选的,所述步骤3包括以下步骤:
18.步骤3.1:编码器输出一个长度为160*1的向量;
19.步骤3.2:按照90、35、35的长度将步骤3.1中的向量切分为三段,分别代表内容、音色和韵律的编码;
20.步骤3.3:将音色的编码和韵律的编码输入到对应的约束模型中,基于真实的音色向量和韵律向量进行监督训练;
21.步骤3.4:将步骤3.2确定的内容、音色和韵律的编码均输入到鉴别器中进行训练,直到三个编码的分布被鉴别器判定为三个不同的类别。
22.本发明将mel频谱输入到系统中进行训练。在训练过程中,编码器的中间输出是一个长度为160*1的向量,会被切分为三段(90、35、35),分别代表内容、音色和韵律的编码,然后分别将音色的编码和韵律的编码输入到对应的约束模型中,基于真实的音色向量和韵律向量进行监督训练,使得从大向量中切分出的该部分分量和真实的语音特征足够接近。
23.具体的,步骤3中所述的损失函数分别为:第一个是编码器和解码器的重构损失,编码器接受真实的mel频谱作为输入,编码器和解码器的训练目标是重构相应的mel频谱;第二个是音色约束的损失函数;第三个是韵律约束的损失函数;第四个是针对分类任务的鉴别器的损失函数。
24.优选的,所述步骤4包括以下步骤:
25.步骤4.1:记一条源音频为a0,通过librosa库处理后,该音频对应的mel频谱为记x0;
26.步骤4.2:记一条目标音频为a1,通过librosa库处理后,该音频对应的mel频谱记为x1;
27.步骤4.3:将x0输入到系统的编码器部分,输出长度为160*1的向量v0;将x1输入到模型的编码器部分,输出长度为160*1的向量v1;
28.步骤4.4:按照90、35和35的长度将v0和v1分别切分为v
0c
,v
0t
,v
0p
和v
1c
,v
1t
,v
1p
,分别代表源音频和目标音频的内容、音色和韵律的编码;
29.步骤4.5:组合目标韵律编码、源内容编码和源音色编码,将其输入到系统的解码
器部分,输出转换后的mel频谱。
30.优选的,步骤1中每条所述的音频对应的mel频谱为480*80维的矩阵。
31.综上所述,由于采用了上述技术方案,本发明的有益效果是:
32.1.本发明所搭建的系统框架仅包括一个编码器,使得训练过程中没有丢失原始输入的mel频谱信息,实现完美重构;通过两个约束模型通编码器和解码器结合训练,确保了内容、音色和韵律三个语音特征的可提取性;并且采用鉴别器进一步的确保了内容、音色和韵律三个语音特征的可提取性;本发明针对不同内容的音频进行语音转换时,不涉及配对数据的训练,模型训练过程仅仅重构自身,故实现了高效的语音转换;并实现所有语音特征的分离,以及针对语音风格进行转换。
33.2.本发明不需要预先设定任何条件,即可实现对语音转换系统的训练,在实际应用中可以直接调用训练好的模型进行语音转换。
34.3.通过利用prosparse attention模块,使得模型训练时间大大降低;进一步的提高了语音转换的效率。
附图说明
35.本发明将通过例子并参照附图的方式说明,其中:
36.图1为本发明的系统框图。
具体实施方式
37.为使本技术实施例的目的、技术方案和优点更加清楚,下面将结合本技术实施例中附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本技术实施例的组件可以各种不同的配置来布置和设计。因此,以下对在附图中提供的本技术的实施例的详细描述并非旨在限制要求保护的本技术的范围,而是仅仅表示本技术的选定实施例。基于本技术的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本技术保护的范围。
38.下面结合附图1对本发明的实施例作详细描述;
39.一种基于自动编码器框架的语音转换方法,包括以下步骤:
40.步骤1:基于开源的音频处理库,提取音频的mel频谱特征作为数据集;每条所述的音频对应的mel频谱为480*80维的矩阵。
41.步骤2:搭建由编码器、解码器、鉴别器和分别针对音色和韵律的两个约束模型组成的系统框架;所述编码器、解码器、约束模型和鉴别器均是基于informer:aaai2021 best paper的标准搭建而成。系统框架的网络结构有2层或3层prosparse attention模块堆叠组成。
42.通过利用prosparse attention模块,使得模型训练时间大大降低;进一步的提高了语音转换的效率。
43.步骤3:将步骤1中的数据集输入步骤2搭建的系统中,进行约束模型的训练,直至损失函数收敛,提取源说话人和目标说话人对应的语音特征;
44.所述步骤3包括以下步骤:
45.步骤3.1:编码器输出一个长度为160*1的向量;
46.步骤3.2:按照90、35、35的长度将步骤3.1中的向量切分为三段,分别代表内容、音色和韵律的编码;
47.步骤3.3:将音色的编码和韵律的编码输入到对应的约束模型中,基于真实的音色向量和韵律向量进行监督训练;
48.步骤3.4:将步骤3.2确定的内容、音色和韵律的编码同时输入到鉴别器中进行训练,直到三个编码的分布被鉴别器判定为三个不同的类别。
49.步骤3中所述的损失函数分别为:第一个是编码器和解码器的重构损失,编码器接受真实的mel频谱作为输入,编码器和解码器的训练目标是重构相应的mel频谱;第二个是音色约束的损失函数;第三个是韵律约束的损失函数;第四个是针对分类任务的鉴别器的损失函数。
50.步骤4:基于步骤3中训练好的模型提取语音特征,并替换源韵律编码为目标编码,完成语音转换任务。
51.所述步骤4包括以下步骤:
52.步骤4.1:记一条源音频为a0,通过librosa库处理后,该音频对应的mel频谱记为x0;
53.步骤4.2:记一条目标音频为a1,通过librosa库处理后,该音频对应的mel频谱记为x1;
54.步骤4.3:将x0输入到系统的编码器部分,输出长度为160*1的向量v0;将x1输入到模型的编码器部分,输出长度为160*1的向量v1;
55.步骤4.4:按照90、35和35的长度将v0和v1分别切分为v
0c
,v
0t
,v
0p
和v
1c
,v
1t
,v
1p
,分别代表源音频和目标音频的内容、音色和韵律的编码;
56.步骤4.5:组合目标韵律编码、源内容编码和源音色编码,将其输入到系统的解码器部分,输出转换后的mel频谱。
57.本发明所搭建的系统框架仅包括一个编码器,使得训练过程中没有丢失原始输入的mel频谱信息,实现完美重构;通过两个约束模型通编码器和解码器结合训练,确保了内容、音色和韵律三个语音特征的可提取性;并且采用鉴别器进一步的确保了内容、音色和韵律三个语音特征的可提取性;本发明针对不同内容的音频进行语音转换时,不涉及配对数据的训练,模型训练过程仅仅重构自身,故实现了高效的语音转换。
58.本发明将mel频谱输入到系统中进行训练。在训练过程中,编码器输出的是一个长度为160*1的向量,会被切分为三段(90、35、35),分别代表内容、音色和韵律的编码,然后分别将音色的编码和韵律的编码输入到对应的约束模型中,基于真实的音色向量和韵律向量进行监督训练,使得从大向量中切分出的该部分分量和真实的语音特征足够接近。
59.以上所述实施例仅表达了本技术的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本技术保护范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术技术方案构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。