1.本发明涉及一种指向助听的技术,尤其涉及一种指向选取特定目标的音频的指向助听装置及其方法。
背景技术:
2.在一嘈杂环境中,由于周围的高分贝环境音或其他人声容易盖过特定对象的声音,使得用户在该环境下难以听取特定对象的声音。例如上课时同学过于嘈杂,而无法听到老师上课的声音,或是在大自然中的风速太大,进而带动河流或树叶发出声响,使得使用者无法听到自然环境中的鸟叫声。
3.在此情况下,现有技术通常会利用一收音罩设置在一收音装置上,使得收音装置通过物理限缩的方式,专注于接收收音方向上的声音。
4.然而,此种方法并无法有效判别特定对象的声音,除此以外,在收音方向上接收到多个高分贝声响时,也无法有效的判别且听取特定对象的声音。另外,通过物理限缩的方式,容易因外部环境的风速过大,使得收音罩接收到风导流在收音罩上时发出的声响,进而影响收音的判别。
5.因此,现有技术上亟需一种屏除物理限缩收音范围的方式,且可有效地听取特定对象声音的方法,用来改善现有技术所存在的问题。
技术实现要素:
6.本发明的目的在于提供一种指向助听装置及其方法,其主要是利用声波探取波束范围上的声音,且依据相关处理选取特定对象的声音(探取音源),进而降低或屏蔽其他声响后,使得使用者可有效听取特定对象的声音,从而有效改善现有技术的问题。
7.为了达成上述目的,本发明提供一种指向助听装置,其包括:一壳体;一收音模块,设置在壳体内,用于在一波束所指向的范围内接收一声音信号;一处理模块,设置在壳体内且与收音模块连接,用来接收声音信号,并分离声音信号内的多个音源,处理模块根据多个声纹数据比对出多个所述音源中的一声音特征点,且处理模块接收一探取目标,并运用一深度学习算法选取多个所述声音特征点中对应探取目标的音源的一声音特征点音频,且放大或放大及移频对应探取目标的音源内的声音特征点音频以产生一探取音源,并降低或屏蔽其他多个所述音源内的声音特征点音频以产生多个调整音源,其中处理模块针对探取音源以及多个所述调整音源执行一合成程序,使得探取音源与多个所述调整音源合并产生一输出声音信号;一选择模块,设置在壳体内且与处理模块连接,用来接收多个所述声音特征点,且选择至少一声音特征点为探取目标;以及一扬声器,设置在壳体内与处理模块连接,用来接收并输出该输出声音信号。
8.优选地,收音模块内设有一近端过滤模块,当收音模块在一默认距离接收到声音信号时,近端过滤模块将声音信号设定为一近端声音信号,且将近端声音信号发送给该处理模块,其中,处理模块根据一用户声纹数据比对近端声音信号内的一近端音源中的一近
端声音特征点,当用户声纹数据与近端声音特征点相符时,处理模块则运用深度学习算法选取近端声音特征点的一近端声音特征点音频,以降低近端声音特征点音频后产生一自身音源,且根据自身音源产生输出声音信号,或是根据自身音源与探取音源、多个所述调整音源或二者以上组合,执行所述合成程序,用来合并产生所述输出声音信号。
9.优选地,当用户声纹数据与近端声音特征点不相符时,处理模块则降低或屏蔽近端声音特征点音频以产生调整音源。
10.优选地,所述的指向助听装置还包含:一探取模块,设置在壳体上,用于在一探取范围内提供一声波;以及一发送模块,设置在壳体上,用于在探取范围内施加一分离声波至所述声波上,使得所述声波分离成两个方向性的一第一声波及一第二声波;其中,收音模块接收第一声波及第二声波,且在第一声波与第二声波的重叠区域上形成波束。
11.优选地,所述的指向助听装置还包含:一第一探取模块,设置在壳体上,用于在一第一探取范围内提供一第一声波;以及一第二探取模块,设置在壳体上,用于在一第二探取范围内提供一第二声波;其中,收音模块接收第一声波及第二声波,且在第一声波与第二声波的重叠区域上形成波束。
12.优选地,处理模块设定有一频率数据,当对应探取目标的音源的声音特征点音频的声音频率与频率数据相符合时,处理模块放大及移频探取目标的音源内的声音特征点音频以产生探取音源,当对应探取目标的音源的声音特征点音频的声音频率与频率数据不相符合时,处理模块放大探取目标的音源内的声音特征点音频以产生探取音源。
13.优选地,所述的指向助听装置还包含:一激活模块,设置在壳体内,且与处理模块及收音模块链接,激活模块从收音模块接收声音信号,且依据一负分贝门限值与声音信号的一声源数据相比对,以判断是否启动处理模块,当声源数据低于该负分贝门限值时,激活模块启动处理模块,使处理模块分离声音信号内的多个所述音源,当声源资料高于负分贝门限值时,激活模块则继续接收另一个声音信号。
14.优选地,所述声源数据报括一分贝值或一频率值。
15.优选地,收音模块在一判断时间内接收多个声音信号,且在判断时间内选定至少一负分贝时间点上所接收到的声音信号且发送至处理模块,其中负分贝时间点包括声音信号的声音分贝低于一负分贝门限值的时间点。
16.本发明的另一目的在于提供一种指向助听方法,主要是利用声波探取波束范围上的声音,且依据相关处理选取特定对象的声音(探取音源),进而降低或屏蔽其他声响后,使得使用者可有效听取特定对象的声音,用于有效改善现有技术的问题。
17.为了达到上述目的,本发明提供一种应用于如上所述的指向助听装置上的指向助听方法,其包含下列步骤:收音模块在波束所指向的范围内接收声音信号;处理模块分离所述声音信号内的多个音源;所述处理模块根据声纹数据比对出所述多个音源中的声音特征点;选择模块接收所述多个声音特征点,且选择至少一所述声音特征点为探取目标;所述处理模块接收所述探取目标,并运用深度学习算法选取所述多个声音特征点中对应所述探取目标的所述音源的声音特征点音频;所述处理模块放大或放大及移频对应所述探取目标的所述音源内的所述声音特征点音频以产生探取音源,并降低或屏蔽其他所述多个音源内的所述声音特征点音频以产生多个调整音源;所述处理模块针对所述探取音源以及所述多个调整音源执行合成程序,使得所述探取音源与所述多个调整音源合并产生输出声音信号;
以及扬声器接收并输出所述输出声音信号。
18.为使本发明的上述目的、特征和优点能更明显易懂,下文配合各图示所列举的具体实施例详加说明。
附图说明
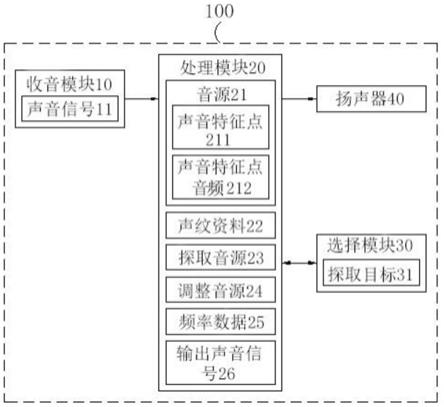
19.图1为本发明的组件配置关系示意图;
20.图2为本发明的近端过滤模块配置示意图;
21.图3为本发明中一实施例的探取模块及发送模块配置示意图;
22.图4为本发明中另一实施例的第一探取模块及第二探取模块配置示意图;
23.图5为本发明的第一声波及第二生波形成波束的示意图;
24.图6为本发明的激活模块配置示意图;
25.图7为本发明的步骤流程图;
26.100:壳体;
27.10:收音模块;
28.11:声音信号;
29.111:声源资料;
30.12:近端过滤模块;
31.121:近端声音信号;
32.1211:近端音源;
33.1212:近端声音特征点;
34.1213:近端声音特征点音频;
35.122:自身音源;
36.13:波束;
37.14:第一声波;
38.15:第二声波;
39.20:处理模块;
40.21:音源;
41.211:声音特征点;
42.212:声音特征点音频;
43.22:声纹资料;
44.221:用户声纹数据;
45.23:探取音源;
46.24:调整音源;
47.25:频率数据;
48.26:输出声音信号;
49.30:选择模块;
50.31:探取目标;
51.40:扬声器;
52.50:探取模块;
53.60:发送模块;
54.71:第一探取模块;
55.72:第二探取模块;
56.80:激活模块;
57.81:负分贝门限值;
58.oa:重叠区域;
59.步骤流程:s01-s08。
具体实施方式
60.本发明的优点、特征以及达到的技术方法将参照例示性实施例及所附图示进行更详细地描述,使其更容易被理解,且本发明可以不同形式来实现,故不应被理解为其本发明仅限于此处所陈述的实施例,相反地,对本领域的技术人员而言,所提供的实施例将使本揭露更加透彻与全面且完整地传达本发明的范畴,且本发明将仅为所附加的权利要求书所为定义。
61.另外,术语「包括」及/或「包含」指所述特征、区域、整体、步骤、操作、组件及/或部件的存在,但不排除一个或多个其他特征、区域、整体、步骤、操作、组件、部件及/或其组合的存在或添加。
62.为方便了解本发明的内容,以及所能达成的功效,现配合图示列举的各项具体实施例以详细说明如下:
63.图1为本发明得组件配置关系示意图。如图1所示,本发明主要是由设置在一壳体100内的一收音模块10、一处理模块20、一选择模块30及一扬声器40所构成。其中收音模块10具体可为一麦克风或其他相关可接收到外部声音的装置,而为了有效的接收到特定对象的声音,在本发明中将收音模块10的收音范围限制在一波束所指向的范围内,进而从波束的范围内接收到一声音信号11,又,当波束范围内的声音过于嘈杂而无法有效选取到特定对象的声音时,收音模块10进一步会在一判断时间中接收多个声音信号,且在判断时间内选定至少一负分贝时间点上所接收到的声音信号11以发送至处理模块20,其中负分贝时间点包括声音信号11的声音分贝低于一负分贝门限值(例如60分贝或其他不会让特定对象的声音被盖过的分贝值上)的时间点。负分贝时间点的设置目的在于,例如在上课的环境中,同学分的声音虽然嘈杂,但是人讲话的声量并无法随时保持在高分贝声量上,因此,当收音模块10选取到该负分贝时间点上(即同学们的讲话分贝较低的时间点上)的声音信号11时,收音模块10即可利用所述声音信号进行后续的处理判别。
64.处理模块20具体可为一种中央处理器或是其他可进行数据处理的装置,处理模块20与收音模块10连接时,可接收到收音模块10所接收到的声音信号11,此时,处理模块20会先分离声音信号11内的多个音源21(例如特定对象的声音及其他人声),当各音源21被分离出来后,为了有效的分辨多个所述音源21的差异,凭借其差异进行特定对象的选取,因此处理模块还会利用多个声纹数据22比对出多个所述音源21中的一声音特征点211,其中多个所述声纹数据22可通过一段时间的声音学习或是原先缓存器所储存的数据而来。此时,选择模块30凭借与处理模块20连接而接收到多个所述声音特征点211,在具体的实施利中,选择模块30可借由显示一选择接口给用户选择,或是利用自动选择的方式(例如已设定需选
取的对象时)选择至少一该声音特征点211为一探取目标31,在发送给处理模块20。
65.当处理模块20接收到探取目标31时,则会运用一深度学习算法选取多个所述声音特征点211中对应探取目标31得音源21的一声音特征点音频212,且放大对应探取目标31得音源21内的声音特征点音频212以产生一探取音源23,然而,所接收到的多个所述音源21中可能还可被区分为配戴本发明的指向助听装置的用户无法听到或会造成用户不适的声音频率,以及用户可听到且不会造成不适的声音频率,为了有效分辨探取音源所归属的声音频率的类别,可在处理模块20中设定有一频率数据25,以当对应探取目标的音源21的声音特征点音频212的声音频率与频率数据25相符合时,即可判定探取音源23为使用者无法听到或是会造成不适的声音频率,故处理模块20放大及移频(利用移频的方式将探取音源23移频到不符合该频率数据25的声音频率上)探取目标31的音源21内的声音特征点音频212,当对应探取目标31的音源21的声音特征点音频212的声音频率与频率数据25不相符合时,即可判定探取音源23为使用者可听到且不会造成不适的声音频率,故处理模块20仅需通过放大的方式,放大探取标的31的音源21内的声音特征点音频212。
66.除了上述突显该探取音源23的动作,处理模块20进一步还会降低或屏蔽掉其他多个所述音源21内的声音特征点音频212以产生多个调整音源24,且针对探取音源23以及多个所述调整音源24执行一合成程序,使得探取音源23与多个所述调整音源24合并产生一输出声音讯号26,如此,输出声音信号26中则会包括有被突显的探取音源23及被削弱或静音的多个所述调整音源24。
67.之后,扬声器40即可凭借与处理模块20连接的方式接收输出声音信号26,且将输出声音信号26输出给用户听取。进而有效达成选择性地选取探取音源23,且降低或屏蔽其他杂音,有利于用户听取特定对象的音频等功效。
68.另外,由于数字信号或模拟信号之间的转换,或是处理为现有技术,故在上述信号接收或输出的动作中,不再赘述现有技术中已知的动作。
69.如图2所示,为本发明得近端过滤模块配置示意图。如图2所示,使用者配戴本发明的指向助听装置时,虽可通过上述动作,有效的听取探取音源23的声音,但当使用者自己本身说话时,由于自己本身离指向助听装置的距离最近,故可能会有使用者说话的声量过大,而盖过探取音源23的声量的情形发生,因此,为了避免上述的情形发生,本发明的收音模块10内进一步还设有一近端过滤模块12,用于当收音模块10在一默认距离(例如0~10公分之间)内接收到声音信号11时,近端过滤模块12则会先将声音信号11设定为一近端声音信号121,且将近端声音信号121发送给处理模块20,其中处理模块20根据一用户声纹数据221比对近端声音信号121内的一近端音源1211中的一近端声音特征点1212,当用户声纹数据221与近端声音特征点1212相符时,处理模块20则运用深度学习算法选取近端声音特征点1212的一近端声音特征点音频1213,以降低近端声音特征点音频1213后产生一自身音源122,且依据自身音源122产生输出声音信号26,或是根据自身音源122与探取音源23、多个所述调整音源24或是所述二者都是执行合成程序,以合并产生输出声音信号26。在此的目的是在于避免使用者的声音盖过探取音源23,故并不会屏蔽掉近端声音特征点音频1213,以让用户可在一定的声量上听到自己说话的声音。
70.又,若当用户声纹数据221与近端声音特征点1212不相符时,该处理模块20则是降低或屏蔽近端声音特征点音频1213以产生该调整音源24(即如上述的多个所述调整音源
24)。
71.如图3~图5所示,为本发明的一实施例的探取模块及发送模块配置示意图、另一实施例的第一探取模块及第二探取模块配置示意图、以及第一声波及第二声波形成波束的示意图。如图3~图5所示,为了有效提供收音模块10可在波束13指向的范围上获取声音信号11,本发明举例提供两种实现的方式,其一实施例为指向助听装置还包含设置在壳体100上的一探取模块50及一发送模块60,探取模块50可在一探取范围内提供一声波,而探取范围可例如为指向助听装置所面向的广角范围,发送模块60则是在探取范围上提供一分离声波至声波上,使得声波分离成在探取范围上的两个方向性的一第一声波14及一第二声波15,且第一声波14及第二声波15之间形成有一重叠区域oa,此时,由于收音模块10可配备有波束13形成的功能,因此,当收音模块10接收到第一声波14及第二声波15时,即可在重叠区域oa上形成该波束13,进而在波束13范围上选取声音信号11。
72.而另一实施例中,指向助听装置则是可包括设置在壳体上的一第一探取模块71及一第二探取模块72,用于直接利用第一探取模块71在一第一探取范围内提供一第一声波14,以及第二探取模块72在第二探取范围内提供一第二声波15,值得注意的是,为了提供收音模块10形成波束,因此第一探取范围及第二探取范围理当具有一重叠区域,使得收音模块10接收到第一声波14及第二声波15时,即可在重叠区域oa上形成波束13,进而在波束13范围上选取声音信号11。
73.如此,本发明至少可利用上述各实施例所提供的方式,以达成指向性选取声音信号的功效。
74.如图6所示,为本发明的激活模块配置示意图。如图6所示,为了有效节省电源,故本发明的指向助听装置还包含一激活模块80,设置在壳体100内,且与处理模块20及收音模块10连接,激活模块80从收音模块10接收到声音信号11,且依据负分贝门限值81与声音信号11的一声源数据111(例如一分贝值)相比对,以判断是否启动处理模块20,举例来说,当声源资料111低于负分贝门限值81(例如上述的60分贝)时,激活模块80启动处理模块10,使处理模块10分离声音信号11内的多个所述音源21,当声源资料111高于负分贝门限值81时,激活模块80则继续接收另一个声音信号11,以进行相关激活程序的判断。由此有效地提供本发明的指向助听装置省电的功能。
75.如图7所示,为本发明的步骤流程图。如图7所示,本发明主要可根据下列步骤流程,以达成如上述的有效听取探取音源的功能,包括:
76.s01:收音模块在一波束所指向的范围内接收声音信号;
77.s02:处理模块分离声音信号内的多个音源;
78.s03:处理模块根据声纹数据比对出多个所述音源中的声音特征点;
79.s04:选择模块接收多个所述声音特征点,且选择至少一声音特征点为探取目标;
80.s05:处理模块接收探取目标,并运用深度学习算法选取多个所述声音特征点中对应探取目标的音源的一声音特征点音频;
81.s06:处理模块放大或放大及移频对应探取目标的音源内的声音特征点音频以产生一探取音源,并降低或屏蔽其他多个所述音源内的声音特征点音频以产生多个调整音源;
82.s07:处理模块针对探取音源以及多个所述调整音源执行合成程序,使得探取音源
与多个所述调整音源合并产生一输出声音信号;
83.s08:扬声器接收并输出输出声音信号。
84.借此,本发明即可有效提供助听器具有选择性地选取探取音源,且降低或屏蔽其他杂音的功能,有利于用户听取特定对象的音频。
85.尽管本发明的内容已经通过上述优选实施例作了详细介绍,但应当认识到上述的描述不应被认为是对本发明的限制。在本领域技术人员阅读了上述内容后,对于本发明的多种修改和替代都将是显而易见的。因此,本发明的保护范围应由所附的权利要求来限定。。