1.本发明涉及一种异常声音检测方法。
背景技术:
2.随着科学和计算机技术的发展,人机互动形式多种多样,语音识别技术取代传统的通过鼠标、键盘实现人机信息交流的模式,这是计算机、信号处理和人工智能等领域的重要课题。自动语音识别的任务是研究如何利用计算机模拟人类的听觉功能,从人的语音信号中提取出有用的声学特征和语言信息,进而确定语音信号的语言含义,实现人和机器之间的自然语言通信。语音识别技术开始渐渐走出实验室,在国防监听、远程会议、音频设备、移动通讯、身份鉴别、智能玩具、机器人等领域展现了广阔的应用前景,一些应用已非常贴近人们的生活。由于语音信号的不确定性,以及周围环境的不可控性,还鲜有十分可靠的语音识别系统大面积商用或民用的实例。从语音识别理论的发展来看,非特定人的大词汇量和连续语音识别仍然是语音识别领域的技术难点。相对而言,非特定人中小词汇量的关键词语音识别的理论和实践发展相对较成熟和完善,完全有可能应用于一些声环境相对稳定,噪声相对较小的场合,如室内的语音报警、声控家电及智能玩具等。
3.环境声监控和识别是语音识别中的分支方向,处于发展初期,还没有可应用于非特定人的监控和识别系统得到实际应用,而随着智能楼宇、大型社交活动场所的安防及重要场所的监控等方面的需求与日俱增,急需发展这方面的技术。特别地,监控系统所感兴趣的多是人在紧急状况下发出的呼叫声,咳嗽声,巨大的撞击声等能起到警告作用的异音,其识别本质上属于关键词识别的范畴。此类的大声音、讲话内容的关键词属于异常声音的检测范围。
技术实现要素:
4.本发明的目的在于提供一种异常声音检测方法,以解决上述背景技术中提出的问题。
5.为实现上述目的,本发明提供如下技术方案:
6.一种异常声音检测方法,包括以下步骤:
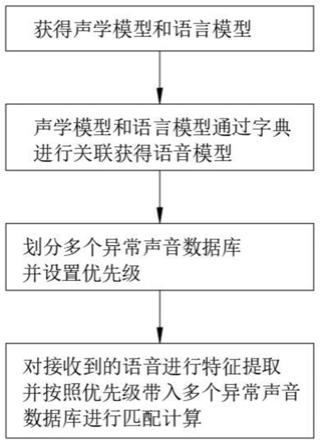
7.通过语音数据训练获得声学模型并通过文本数据训练获得语言模型;
8.将声学模型和语言模型通过字典进行关联获得语音模型;
9.根据异常声音的类型对语音模型内的异常声音进行分类划分为多个异常声音数据库并设置多个异常声音数据库的初始优先级;
10.对接收到的语音进行特征提取,通过语音解码和搜索算法按照优先级依次带入多个异常声音数据库进行匹配计算,匹配成功后停止继续计算;
11.其中,间隔预设时间对多个异常声音数据库的优先级自动进行调整。
12.作为本发明进一步的方案:间隔预设时间对多个异常声音数据库的优先级自动进行调整的方法,包括以下步骤:
13.统计一段时间间隔内多个异常声音数据库匹配成功的次数;
14.根据多个异常声音数据库匹配成功的次数进行优先级的调整。
15.作为本发明进一步的方案:在当次进行优先级别的调整时若优先级别未发生变动则对预设时间进行增加,预设时间设有上限,在达到上限时不再增加。
16.作为本发明进一步的方案:在当次进行优先级别的调整时若优先级别发生变动则对预设时间进行缩短,预设时间设有下限,在达到下限时不再缩短。
17.作为本发明进一步的方案:带入多个异常声音数据库后仍未匹配成功则将语音信息存储至未识别语音数据库。
18.作为本发明进一步的方案:定期将未识别语音数据库内的数据进行上传。
19.作为本发明进一步的方案:通过语音数据训练获得声学模型包括以下步骤:
20.创建语音数据库;
21.进行特征提取;
22.进行声学模型训练;
23.获得声学模型。
24.作为本发明进一步的方案:通过文本数据训练获得语言模型包括以下步骤:
25.创建文本数据库;
26.进行语言模型训练获得语言模型。
27.作为本发明进一步的方案:异常声音数据库的个数为三个到五个。
28.作为本发明进一步的方案:在匹配成功后,输出异常字和异常音量。
29.与现有技术相比,本发明的有益效果是:可以实现对异常声音的识别。
30.通过设置多个异常声音数据库提升对不同环境的适配性,在不同环境下均可以实现较高的识别效率。
31.本发明的异常声音检测方法可以检测大声音、讲话内容的关键词等异常音。
附图说明
32.图1是本发明的异常声音检测方法的流程图;
33.图2是本发明的异常声音检测方法的创建语音模型的流程框图。
具体实施方式
34.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
35.如图1和图2所示,一种异常声音检测方法,包括以下步骤:
36.通过语音数据训练获得声学模型并通过文本数据训练获得语言模型;
37.将声学模型和语言模型通过字典进行关联获得语音模型;
38.根据异常声音的类型对语音模型内的异常声音进行分类划分为多个异常声音数据库并设置多个异常声音数据库的初始优先级;
39.对接收到的语音进行特征提取,通过语音解码和搜索算法按照优先级依次带入多
个异常声音数据库进行匹配计算,匹配成功后停止继续计算;
40.其中,间隔预设时间对多个异常声音数据库的优先级自动进行调整。
41.作为一种具体的实施方式,在匹配成功后,输出异常字和异常音量。
42.作为一种优选的实施方式:间隔预设时间对多个异常声音数据库的优先级自动进行调整的方法,包括以下步骤:
43.统计一段时间间隔内多个异常声音数据库匹配成功的次数;
44.根据多个异常声音数据库匹配成功的次数进行优先级的调整。
45.作为一种具体的实施方式,在当次进行优先级别的调整时若优先级别未发生变动则对预设时间进行增加,预设时间设有上限,在达到上限时不再增加。在当次进行优先级别的调整时若优先级别发生变动则对预设时间进行缩短,预设时间设有下限,在达到下限时不再缩短。
46.作为一种具体的实施方式,带入多个异常声音数据库后仍未匹配成功则将语音信息存储至未识别语音数据库。定期将未识别语音数据库内的数据进行上传。定期将未识别语音数据库中的数据上传至服务器,人工识别后加入到语音模型中。
47.作为一种具体的实施方式,通过语音数据训练获得声学模型包括以下步骤:
48.创建语音数据库;
49.进行特征提取;
50.进行声学模型训练;
51.获得声学模型。
52.作为一种具体的实施方式,通过文本数据训练获得语言模型包括以下步骤:
53.创建文本数据库;
54.进行语言模型训练获得语言模型。
55.作为一种具体的实施方式,异常声音数据库的个数为三个到五个。
56.对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
57.此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。