1.本发明涉及人工智能领域,尤其涉及一种会议记录生成方法、装置、设备及存储介质。
背景技术:
2.目前随着人工智能的发展,语音识别技术逐渐成熟,通过语音识别把声音转化为文字,一定程度上可以辅助或代替重复利用人力进行会议记录及总结工作。此外,随着声纹识别技术的发展,可通过声纹识别来判断声音的来源人,将语音识别和声纹识别结合,对不同发言人讲述的文本进行区分标注,会使得会议记录更为准确和高效。
3.在现有的技术中,只能根据识别到的声纹对识别到的文本内容进行标注,以区分不同发言人的发言内容,无法根据会议所属的工作项目及确定具体的发言人,导致识别得到的会议记录不够准确,与音频存在较大的误差。
技术实现要素:
4.本发明的主要目的在于解决现有技术中自动生成的会议记录中信息内容误差较大的技术问题。
5.本发明第一方面提供了一种会议记录生成方法,包括:获取待进行记录识别的会议音频文件;调用预置的语音识别模型对所述会议音频文件进行语音识别,得到所述会议音频文件中的文本内容;调用预置的声纹提取模型对所述会议音频文件进行声纹特征提取,得到所述会议音频文件中的声纹特征,其中,所述声纹特征为至少一个;根据所述声纹特征,在预置的声纹信息库中查找所述声纹特征对应的参会人信息;根据所述参会人信息对所述文本内容进行发言人标注,得到发言人信息;根据所述参会人信息确定所述会议所属的工作项目,并根据所述工作项目、文本内容和对应的发言人信息生成会议记录。
6.可选的,在本发明第一方面的第一种实现方式中,在所述根据所述工作项目、文本内容和对应的发言人信息生成会议记录之后,还包括:对所述会议记录内容进行文本语义识别,提取所述会议记录的核心观点和任务内容;基于所述核心观点生成会议摘要,基于所述任务内容生成待办事项;根据所述会议摘要和待办事项对所述会议记录的内容进行更新。
7.可选的,在本发明第一方面的第二种实现方式中,所述语音识别模型包括特征提取层,音调识别层和文本序列匹配层,所述调用预置的语音识别模型对所述会议音频文件进行语音识别,得到所述会议音频文件中的文本内容包括:调用所述特征提取层对所述会议音频文件进行频谱特征提取,得到音频特征频谱;调用所述音调识别层将所述音频特征频谱进行切分,得到多个特征频谱片,对所述多个特征频谱片进行发音声调的识别,得到拼音序列;调用所述文本序列匹配层基于所述拼音序列进行文本序列的匹配,得到会议音频文件的文本内容。
8.可选的,在本发明第一方面的第三种实现方式中,所述调用预置的声纹提取模型
对所述会议音频文件进行声纹特征提取,得到所述会议音频文件中的声纹特征包括:将所述会议音频文件输入声纹提取模型中进行声纹特征的提取,得到所述会议音频文件中的声学频谱特征参数、词法特征参数、韵律特征参数以及口音特征参数,其中,所述声纹提取模型是预先基于径向基函数神经网络构建的;基于所述声学频谱特征参数、所述词法特征参数、所述韵律特征参数以及所述口音特征参数生成声纹参数,得到所述会议音频文件中的声纹特征。
9.可选的,在本发明第一方面的第四种实现方式中,所述根据所述工作项目、文本内容和对应的发言人信息生成会议记录包括:根据所述工作项目信息确定当前会议相关领域;根据所述会议相关领域查找预置的相关领域词典;根据所述相关领域词典对所述文本内容进行调整,将识别不准确的词语进行修正,得到修正文本内容;根据所述修正文本内容和对应的发言人信息生成会议记录。
10.可选的,在本发明第一方面的第五种实现方式中,其特征在于,在所述获取待进行记录识别的会议音频文件之前还包括:采集员工的语音样本,对所述语音样本进行去噪处理,得到去噪语音样本;对所述去噪语音样本进行质量检测,判断所述语音质量是否满足预设的样本阈值;若是,则对所述去噪语音样本进行特征提取,得到注册声纹特征;获取预置的员工信息,将所述注册声纹特征与所述员工信息进行关联,并基于所述员工信息和注册声纹特征得到声纹信息库。
11.可选的,在本发明第一方面的第六种实现方式中,在所述根据所述参会人信息对所述文本内容进行发言人标注,得到发言人信息之后,还包括:调用预置的音频情绪识别模型对所述会议音频文件进行语音情绪识别,得到情绪特征参数;基于所述情绪特征参数对所述文本内容进行情绪状态标注,得到情绪状态标识;基于所述情绪状态标识输出会议达成预计会议目标的概率,并根据所述预计会议目标和所述概率对所述文本内容进行标注。
12.本发明第二方面提供了一种会议记录生成装置,包括:获取模块,用于获取待进行记录识别的会议音频文件;识别模块,用于调用预置的语音识别模型对所述会议音频文件进行语音识别,得到所述会议音频文件中的文本内容;提取模块,用于调用预置的声纹提取模型对所述会议音频文件进行声纹特征提取,得到所述会议音频文件中的声纹特征,其中,所述声纹特征为至少一个;查找模块,用于根据所述声纹特征,在预置的声纹信息库中查找所述声纹特征对应的参会人信息;标注模块,用于根据所述参会人信息对所述文本内容进行发言人标注,得到发言人信息;生成模块,用于根据所述参会人信息确定所述会议所属的工作项目,并根据所述工作项目、文本内容和对应的发言人信息生成会议记录。可选的,在本发明第二方面的第一种实现方式中,所述会议记录生成装置还包括内容更新模块,所述内容更新模块包括:提取单元,用于对所述会议记录内容进行文本语义识别,提取所述会议记录的核心观点和任务内容;内容生成单元,用于基于所述核心观点生成会议摘要,基于所述任务内容生成待办事项;更新单元,用于根据所述会议摘要和待办事项对所述会议记录的内容进行更新。
13.可选的,在本发明第二方面的第二种实现方式中,所述语音识别模型包括特征提取层,音调识别层和文本序列匹配层,所述识别模块包括:频谱提取单元,用于调用所述特征提取层对所述会议音频文件进行频谱特征提取,得到音频特征频谱;音调识别单元,用于调用所述音调识别层将所述音频特征频谱进行切分,得到多个特征频谱片,对所述多个特
征频谱片进行发音声调的识别,得到拼音序列;文本匹配单元,用于调用所述文本序列匹配层基于所述拼音序列进行文本序列的匹配,得到会议音频文件的文本内容。
14.可选的,在本发明第二方面的第三种实现方式中,所述提取模块包括:参数提取单元,用于将所述会议音频文件输入声纹提取模型中进行声纹特征的提取,得到所述会议音频文件中的声学频谱特征参数、词法特征参数、韵律特征参数以及口音特征参数,其中,所述声纹提取模型是预先基于径向基函数神经网络构建的;参数计算单元,用于基于所述声学频谱特征参数、所述词法特征参数、所述韵律特征参数以及所述口音特征参数生成声纹参数,得到所述会议音频文件中的声纹特征。
15.可选的,在本发明第二方面的第四种实现方式中,所述生成模块包括:领域确定单元,用于根据所述工作项目信息确定当前会议相关领域;词典查找单元,用于根据所述会议相关领域查找预置的相关领域词典;文本修正单元,用于根据所述相关领域词典对所述文本内容进行调整,将识别不准确的词语进行修正,得到修正文本内容;记录生成单元,用于根据所述修正文本内容和对应的发言人信息生成会议记录。
16.可选的,在本发明第二方面的第五种实现方式中,所述会议记录生成装置还包括声纹库构建模块,所述声纹库构建模块包括:采集员工的语音样本,对所述语音样本进行去噪处理,得到去噪语音样本;对所述去噪语音样本进行质量检测,判断所述语音质量是否满足预设的样本阈值;若是,则对所述去噪语音样本进行特征提取,得到注册声纹特征;获取预置的员工信息,将所述注册声纹特征与所述员工信息进行关联,并基于所述员工信息和注册声纹特征得到声纹信息库。
17.可选的,在本发明第二方面的第六种实现方式中,所述会议记录生成装置还包括目标标注模块,所述目标标注模块包括:情绪识别单元,用于调用预置的音频情绪识别模型对所述会议音频文件进行语音情绪识别,得到情绪特征参数;情绪标注单元,用于基于所述情绪特征参数对所述文本内容进行情绪状态标注,得到情绪状态标识;目标标注单元,用于基于所述情绪状态标识输出会议达成预计会议目标的概率,并根据所述预计会议目标和所述概率对所述文本内容进行标注。
18.本发明第三方面提供了一种会议记录生成设备,包括:存储器和至少一个处理器,所述存储器中存储有指令;所述至少一个处理器调用所述存储器中的所述指令,以使得所述会议记录生成设备执行上述的会议记录生成方法的步骤。
19.本发明的第四方面提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机执行上述的会议记录生成方法的步骤。
20.本发明提供的技术方案中,获取待进行记录识别的会议音频文件;调用预置的语音识别模型对会议音频文件进行语音识别,得到会议音频文件中的文本内容;调用预置的声纹提取模型对会议音频文件进行声纹特征提取,得到会议音频文件中的声纹特征,其中,声纹特征为至少一个;根据声纹特征,在预置的声纹信息库中查找声纹特征对应的参会人信息;根据参会人信息对文本内容进行发言人标注,得到发言人信息;根据参会人信息确定会议所属的工作项目,并根据工作项目、文本内容和对应的发言人信息生成会议记录。本发明实施例的技术方案,提高了自动生成的会议记录的信息内容的准确度和详细度。
附图说明
21.图1为本发明实施例中会议记录生成方法的第一实施例的示意图;
22.图2为本发明实施例中会议记录生成方法的第二实施例的示意图;
23.图3为本发明实施例中会议记录生成方法的第三实施例的示意图;
24.图4为本发明实施例中会议记录生成方法的第四实施例的示意图;
25.图5为本发明实施例中会议记录生成方法中cbhg模型的示意图;
26.图6为本发明实施例中会议记录生成装置的一个实施例示意图;
27.图7为本发明实施例中会议记录生成装置的另一个实施例示意图;
28.图8为本发明实施例中会议记录生成设备的一个实施例示意图。
具体实施方式
29.本发明实施例提供了一种会议记录生成方法、装置、设备及存储介质,获取待进行记录识别的会议音频文件;调用语音识别模型对会议音频文件进行语音识别,得到会议音频文件中的文本内容;调用声纹提取模型对会议音频文件进行声纹特征提取,得到会议音频文件中的声纹特征,其中,声纹特征为至少一个;根据声纹特征,在预置的声纹信息库中查找出对应的参会人信息;根据参会人信息对文本内容进行发言人标注,得到发言人信息;根据参会人信息确定会议所属的工作项目,并根据工作项目、文本内容和对应的发言人信息生成会议记录。本发明实施例中的技术方案,提高了自动生成的会议记录的信息内容的准确度和详细度。
30.本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”、“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的实施例能够以除了在这里图示或描述的内容以外的顺序实施。此外,术语“包括”或“具有”及其任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
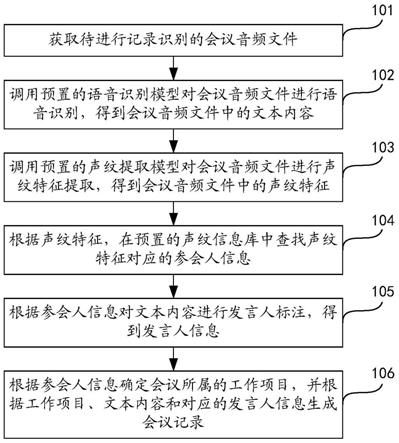
31.为便于理解,下面对本发明实施例的具体流程进行描述,请参阅图1,本发明实施例中会议记录生成方法的一个实施例包括:
32.101、获取待进行记录识别的会议音频文件;
33.可以理解的是,本发明的执行主体可以为会议记录生成装置,还可以是终端或者服务器,具体此处不做限定。本发明实施例以服务器为执行主体为例进行说明。
34.本实施例中的服务器可以接收会议记录生成请求,提取所述会议记录生成请求中包含的对应的会议音频文件;还可以响应于接收到的会议记录生成请求,实时获取需要进行会议记录生成的会议场景中的发言语音,得到会议音频文件。
35.具体地,本实施例中在进行会议音频记录时可以通过使用麦克风阵列对会议音频进行记录以提高会议音频文件的音频质量,使得后续进行识别,对得到的会议音频针对声场的空间特性进行处理,去除会议音频文件中的混响、回声以及噪音等,得到去除背景噪声的会议音频文件。
36.102、调用预置的语音识别模型对会议音频文件进行语音识别,得到会议音频文件
中的文本内容;
37.通过预置的vad(voice activity detection,语音活动检测)模型对会议音频文件中的静音时间段进行识别,其中,该静音时间段指的是会议中的休息或停顿的间隙、以及发言中的停顿间隙;通过静音时间段的音频波形获取到当前会议音频的底噪以及语音端点。根据当前会议音频的底噪对会议音频文件进行去噪处理,根据语音端点对去噪后的会议音频文件进行分段处理,得到分段后的会议音频文件。
38.随后,将分段后的会议音频文件输入预置的语音识别模型中,语音识别模型首先对分段会议音频文件进行声音特征的提取,得到各分段会议音频文件的声学特征,根据本步骤中得到的语音端点及具体的声学特征对所述声学特征进行特征匹配,得到所述分段会议音频文件中每个文字对应的发音;最后通过深度神经网络构建的语言模型,基于每个字对应的发音生成所述发音内容对应的文本内容。
39.103、调用预置的声纹提取模型对会议音频文件进行声纹特征提取,得到会议音频文件中的声纹特征;
40.获取前述步骤中进行去噪及分段处理后的会议音频文件,将得到的分段会议音频文件输入预置的声纹提取模型中,进行语音效果增强处理,得到增强分段会议语音,随后,对语音质量进行检测,提取有效语音片段,并对有效语音中的声纹特征进行提取,得到每个分段会议音频文件中的声纹特征。其中,在本步骤中,声纹特征为至少一个,其中,每个分段会议语音中可以包含有多人的语音,当每个分段会议语音中可以包含有多人的语音时,该分段会议语音中会识别得到多个声纹特征。
41.104、根据声纹特征,在预置的声纹信息库中查找声纹特征对应的参会人信息;
42.根据前述识别到的声纹特征,在预置的声纹信息库查找出与所述声纹特征一致的声纹特征数据,根据所述声纹特征数据的标注,得到所述声纹特征对应的参会人编码,随后根据参会人编码在预置的员工信息库中进行匹配,得到当前会议音频文件中包含的进行发言的具体参会人信息。其中,所述参会人信息预先保存在员工信息库中包括参会人名称、职位、所属组织架构、所属项目组等信息。
43.105、根据参会人信息对文本内容进行发言人标注,得到发言人信息;
44.106、根据参会人信息确定会议所属的工作项目,并根据工作项目、文本内容和对应的发言人信息生成会议记录。
45.根据前述识别到的每段会议音频的声纹特征,对每段会议音频的参会人信息进行标注,同时,根据参会人信息对该段会议音频识别出的文本内容进行对应标注,得到每段文本内容的具体发言人信息。
46.得到当前会议音频文件中的全部参会人信息后,基于当前会议中的全部发言人信息中确定当前会议所属的工作项目,获取工作项目的具体内容。
47.根据得到每段文本内容的具体发言人信息以及工作项目的具体内容对识别得到的文本内容进行调整和标注,生成会议记录。
48.本发明实施例的技术方案,提高了自动生成的会议记录的信息内容的准确度和详细度。
49.请参阅图2,本发明实施例中会议记录生成方法的第二实施例包括:
50.201、获取待进行记录识别的会议音频文件;
51.接收会议记录生成请求,提取所述会议记录生成请求中包含的对应的会议音频文件;或响应于接收到的会议记录生成请求,实时获取需要进行会议记录生成的会议场景中的发言语音,得到会议音频文件。
52.202、调用特征提取层对会议音频文件进行频谱特征提取,得到音频特征频谱;
53.203、调用音调识别层将音频特征频谱进行切分,得到多个特征频谱片,对多个特征频谱片进行发音声调的识别,得到拼音序列;
54.204、调用文本序列匹配层基于拼音序列进行文本序列的匹配,得到会议音频文件的文本内容;
55.由于有些会议的时间较长导致音频文件中录音时长很长、文件较大,为了保证识别的准确度,提高识别的成功率,首先要对上步骤中得到的会议音频文件进行分段处理。
56.具体地,在进行音频文件转换时,通过调用预置的vad(voice activity detection,语音活动检测)模型对所述会议音频文件中的语音端点进行检测,其中,所述vad模型又称为语音端点检测模型或语音边界检测模型;通过vad模型对会议音频文件中的静音时间段进行识别,其中,所述静音时间段的来源可能为会议中的休息或停顿的间隙,将静音时间段的具体位置进行标注,得到语音端点。
57.随后,获取预先配置好的分段规则,所述预先配置好的分段规则中可以预先设定的分段文件大小阈值和/或文件时长阈值,以满足分段文件大小阈值和/或文件时长阈值为条件,根据语音端点的位置对会议音频文件进行分段处理,得到分段的会议音频文件。
58.将得到的分段会议音频文件输入语音识别模型中进行文本内容的识别,其中语音识别模型包括特征提取层,音调识别层和文本序列匹配层。首先,调用特征提取层对会议音频文件进行频谱特征提取,具体地,首先对分段处理后的会议音频文件进行傅里叶变换,得到会议音频文件的频谱;将得到的频谱输入特征提取层中提取所述频谱的特征信息,将得到的频谱的特征信息输入用音调识别层中,其中,所述音调识别层中包含有预先训练好的频谱识别工具,其中,该频谱识别工具是根据神经网络算法构建的;音调识别层根据频谱的特征识别出所述频谱对应的发音,根据发音输出对应的拼音序列。
59.随后,将得到的拼音序列输入文本匹配工具中,根据每个拼音在汉字注音数据库中筛选出所述拼音对应的候选汉字标签,并根据上下文信息候选汉字标签进行筛选,得到对应的汉字标签,根据所述汉字标签提取对应的汉字,得到会议音频对应的文本。
60.205、将会议音频文件输入声纹提取模型中进行声纹特征的提取,得到会议音频文件中的声学频谱特征参数、词法特征参数、韵律特征参数以及口音特征参数;
61.获取前述步骤中进行去噪及分段处理后的会议音频文件,将得到的分段会议音频文件输入预置的声纹提取模型中进行声纹特征的提取,其中,声纹提取模型是预先基于rbfnn(radial basis function neyral network,径向基函数神经网络)构建的;所述径向基函数神经网络是以径向基函数(radial basis function,rbf)作为隐单元的“基”构成隐含层空间构建的神经网络,所述径向基函数,在神经网络结构中,可以作为全连接层和relu(rectified linear unit,线性整流函数)层的主要函数。
62.将会议音频文件输入基于rbfnn构建的声纹提取模型中,对音频文件中的特征参数进行提取,本实施例中,提取到的声纹特征参数包括声学频谱特征参数、词法特征参数、韵律特征参数以及口音特征参数。
63.其中,声学频谱特征参数是通过提取音频文件的功率谱后对功率谱取倒数处理,将得到的倒数值执行傅里叶逆变换得到的;词法特征参数和韵律特征参数是基于n-gram算法对会议音频文件中的每个说话段落的语句进行评估,得到当前说话段落的说话人相关的词音素n-gram生成的;口音特征参是根据识别到的语种、方言和口音信息进行归类生成的。
64.206、基于声学频谱特征参数、词法特征参数、韵律特征参数以及口音特征参数生成声纹参数,得到会议音频文件中的声纹特征;
65.基于上述得到的声纹特征参数生成声纹参数,得到所述会议音频文件中的声纹特征;具体地,所述声纹特征可以为上述声纹参数组合而成的声纹序列,将所述声纹序列作为当前说话段落的声纹特征。其中,所述会议音频文件中包含的声纹特征为至少一个。
66.207、根据声纹特征,在预置的声纹信息库中查找声纹特征对应的参会人信息;
67.208、根据参会人信息对文本内容进行发言人标注,得到发言人信息;
68.209、根据参会人信息确定会议所属的工作项目,并根据工作项目、文本内容和对应的发言人信息生成会议记录。
69.本实施例中步骤207-步骤209中内容与前述实施例中步骤104-106中内容基本相同,故在此不再赘述。
70.本发明实施例的技术方案,提高了自动生成的会议记录的准确度,同时提高了所述会议记录中包含的信息内容的详细程度。
71.请参阅图3,本发明实施例中会议记录生成方法的第三实施例包括:
72.301、获取待进行记录识别的会议音频文件;
73.接收会议记录生成请求,提取所述会议记录生成请求中包含的会议音频文件,对会议音频文件进行分段处理,得到分段会议音频文件。
74.302、调用预置的声纹提取模型对会议音频文件进行声纹特征提取,得到会议音频文件中的声纹特征;
75.将得到的分段会议音频文件输入预置的声纹提取模型中,对有效语音中的声纹特征进行提取,得到每个分段会议音频文件中的声纹特征。
76.303、根据声纹特征,在预置的声纹信息库中查找声纹特征对应的参会人信息;
77.根据前述识别到的声纹特征,在预置的声纹信息库查找出与所述声纹特征一致的声纹特征数据,查询对应的参会人编码,随后根据参会人编码匹配得到当前会议音频文件中包含的进行发言的具体参会人信息。
78.304、根据参会人信息确定会议所属的工作项目,根据工作项目信息确定当前会议相关领域;
79.305、根据会议相关领域在预置的领域词典集中查找出相关领域词典;
80.得到前述步骤中获取到的参会人信息后,根据参会人信息中包含的参会人名称、职位、所属组织架构、所属项目组等信息,获取当前会议的相关领域标签,根据当前会议的相关领域标签在预置的词典集中查找出根据会议相关领域对应的相关领域词典。
81.306、调用预置的语音识别模型对会议音频文件进行语音识别,得到会议音频文件中的文本内容;
82.在本实施例中,根据所述相关领域词典对预置的语音识别模型的识别参数进行调整,提高所述相关领域词典包含的词语的匹配概率;将会议音频文件输入调整后的语音识
别模型中,识别所述会议音频文件中包含的语音端点,根据音频文件具体的声学特征对所述声学特征进行特征匹配,得到会议音频文件中每个文字对应的发音,基于每个字对应的发音生成所述发音内容对应的文本内容。
83.307、根据参会人信息对文本内容进行发言人标注,得到发言人信息;
84.根据前述识别到的每段会议音频的声纹特征,对每段文本内容进行对应标注,得到每段文本内容的具体发言人信息。
85.308、调用预置的音频情绪识别模型对会议音频文件进行语音情绪识别,得到情绪特征参数;
86.309、基于情绪特征参数对文本内容进行情绪状态标注,得到情绪状态标识;
87.310、基于情绪状态标识输出会议达成预计会议目标的概率,并根据预计会议目标和概率对文本内容进行标注;
88.本实施例中,调用预置的音频情绪识别模型对会议音频文件进行语音情绪识别,其中,所述音频情绪识别模型是预先基于深度神经网络算法构建的,具体可以通过语音的韵律或者基频特征等信息判断会议音频文件中每段文本的情绪特征,并得到情绪特征参数。
89.基于情绪特征参数的具体数值对得到的文本内容中的每段文本进行情绪状态标注,得到情绪状态标识;统计全部会议文本内容中的情绪状态标识,计算本次会议达成预计会议目标概率,并根据预计会议目标和概率对文本内容进行标注。
90.311、根据文本内容和对应的发言人信息生成会议记录。
91.根据得到每段文本内容的具体发言人信息以及工作项目的具体内容对识别得到的文本内容进行调整和标注,生成会议记录。
92.本发明实施例的技术方案,提高了自动生成的会议记录的准确程度以及信息内容的详细程度,还可以根据会议记录自动生成待办事项及会议摘要,以便后续对会议内容进行具体跟进操作。
93.请参阅图4以及图5,本发明实施例中会议记录生成方法的第四实施例包括:
94.本技术中,需要预先获取公司的职员信息数据库,其中,所述职员信息数据库中包含有员工信息,员工信息包含员工编号、姓名、职位、所属组织组织架构等信息。采集各员工的语音样本音频,得到语音样本音频后对所述语音样本音频进行去噪处理,得到去噪语音样本;随后对所述去噪语音样本进行质量检测,判断所述语音质量是否满足预设的样本阈值,若否则重新进行语音样本音频的采集,若是则对所述去噪语音样本进行特征提取,得到每位员工的注册声纹特征,并将所述注册声纹特征与职员信息数据库中的员工信息进行关联,得到声纹信息库,以便后续在匹配到与所述注册声纹特征一致的声纹特征时可以通过该声纹数据库查找出对应的员工信息。
95.401、获取待进行记录识别的会议音频文件;
96.本步骤中,接收会议记录生成请求,提取所述会议记录生成请求中包含的对应的会议音频文件;或响应于接收到的会议记录生成请求,实时获取需要进行会议记录生成的会议场景中的发言语音,得到会议音频文件。
97.402、调用特征提取层对会议音频文件进行频谱特征提取,得到音频特征频谱;
98.403、调用音调识别层将音频特征频谱进行切分,得到多个特征频谱片,对多个特
征频谱片进行发音声调的识别,得到拼音序列;
99.404、调用文本序列匹配层基于拼音序列进行文本序列的匹配,得到会议音频文件的文本内容;
100.通过调用预置的vad(voice activity detection,语音活动检测)模型对所述会议音频文件中的语音端点进行检测,得到语音端点。根据语音端点的位置对会议音频文件进行分段处理,得到分段的会议音频文件。
101.将得到的分段会议音频文件输入语音识别模型中进行文本内容的识别,其中语音识别模型包括特征提取层,音调识别层和文本序列匹配层。首先,调用特征提取层对会议音频文件进行频谱特征提取,具体地,首先对分段处理后的会议音频文件进行傅里叶变换,得到会议音频文件的频谱;将得到的频谱输入特征提取层中提取所述频谱的特征信息,将得到的频谱的特征信息输入用音调识别层中,其中,所述音调识别层中包含有预先训练好的频谱识别工具,其中,该频谱识别工具是根据神经网络算法构建的;音调识别层根据频谱的特征识别出所述频谱对应的发音,根据发音输出对应的拼音序列。
102.随后,将得到的拼音序列输入文本匹配工具中,根据每个拼音在汉字注音数据库中筛选出所述拼音对应的候选汉字标签,并根据上下文信息候选汉字标签进行筛选,得到对应的汉字标签,根据所述汉字标签提取对应的汉字,得到会议音频对应的文本。
103.其中,本实施例中所述文本匹配工具是基于cbhg模型构建的,请参阅图5,,所述cbhg指1-d convolution bank+highway network+bidirectional gru,是由1-d卷积(1-d convolution bank/1-d convolution bank,一维卷积神经网络)、highway layers(多层的高速网络)以及双向gru网络(gate recurrent unit,门控循环单元)构建的模型架构,其中,所述gru网络是一种双向循环神经网络(bidirectional rnn,bidirectional recurrent neural network)。
104.具体地,得到的拼音序列首先经过k个1-d卷积(conv1d bank)中对拼音序列的信息进行建模,其中,这些卷积核还可以对上下文信息进行有效建模。随后获取卷积网络的输出。其中,卷积输出被堆叠(stacking)在一起后,沿着时间轴最大池化(max-pool along time)以增加当前信息不变性,stride取为1维持时间分辨率;然后输入到几个固定宽度的1-d卷积层(conv1d layers)中,并通过残差连接(residual connection)将输出增加到起始的输入序列;随后将得到的结果输入多层的高速网络(highway layers)中,用以提取更高级别的特征;最后在顶部加入双向gru,用于提取序列的上下文特征;最后根据提取出的序列特征进行分类,输出拼音序列最可能对应的汉字。
105.405、将会议音频文件输入声纹提取模型中进行声纹特征的提取,得到会议音频文件中的声学频谱特征参数、词法特征参数、韵律特征参数以及口音特征参数;
106.406、基于声学频谱特征参数、词法特征参数、韵律特征参数以及口音特征参数生成声纹参数,得到会议音频文件中的声纹特征;
107.407、根据声纹特征,在预置的声纹信息库中查找声纹特征对应的参会人信息;
108.本实施例中步骤405-步骤407中内容与前述实施例中步骤205-步骤207中内容基本相同,故在此不再赘述。
109.408、根据参会人信息对文本内容进行发言人标注,得到发言人信息;
110.根据前述识别到的每段会议音频的声纹特征,对每段文本内容进行对应标注,得
到每段文本内容的具体发言人信息。
111.409、调用预置的音频情绪识别模型对会议音频文件进行语音情绪识别,得到情绪特征参数;
112.410、基于情绪特征参数对文本内容进行情绪状态标注,得到情绪状态标识;
113.411、基于情绪状态标识输出会议达成预计会议目标的概率,并根据预计会议目标和概率对文本内容进行标注;
114.本实施例中,调用预置的音频情绪识别模型对会议音频文件进行语音情绪识别,其中,所述音频情绪识别模型是预先基于深度神经网络算法构建的,具体可以通过语音的韵律或者基频特征等信息判断会议音频文件中每段文本的情绪特征,并得到情绪特征参数。
115.基于情绪特征参数的具体数值对得到的文本内容中的每段文本进行情绪状态标注,得到情绪状态标识;统计全部会议文本内容中的情绪状态标识,计算本次会议达成预计会议目标概率,并根据预计会议目标和概率对文本内容进行标注。
116.412、根据参会人信息确定会议所属的工作项目,根据工作项目信息确定当前会议相关领域;
117.413、根据会议相关领域查找预置的相关领域词典;
118.414、根据相关领域词典对文本内容进行调整,将识别不准确的词语进行修正,得到修正文本内容;
119.415、根据修正文本内容和对应的发言人信息生成会议记录。
120.得到前述步骤中获取到的参会人信息后,根据参会人信息中包含的参会人名称、职位、所属组织架构、所属项目组等信息,获取当前会议的相关领域标签,根据当前会议的相关领域标签在预置的词典集中查找出根据会议相关领域对应的相关领域词典。根据相关领域词典中的内容对生成的文本内容进行调整将识别不准确的词语进行修正,得到修正文本内容;并根据修正文本内容和对应的发言人信息生成会议记录。
121.得到标记完毕的会议记录内容后,针对会议记录内容进行文本语义识别,提取会议记录的核心观点和任务内容;基于核心观点生成会议摘要,从而提炼会议中的重要内容;基于任务内容自动生成待办事项;根据会议摘要和待办事项对会议记录的内容进行更新。
122.本发明实施例的技术方案,提高了自动生成的会议记录的准确程度以及信息内容的详细程度,还可以根据会议记录自动生成待办事项及会议摘要,以便后续对会议内容进行具体跟进操作。
123.上面对本发明实施例中会议记录生成方法进行了描述,下面对本发明实施例中会议记录生成装置进行描述,请参阅图6,本发明实施例中会议记录生成装置一个实施例包括:
124.获取模块601,用于获取待进行记录识别的会议音频文件;
125.识别模块602,用于调用预置的语音识别模型对所述会议音频文件进行语音识别,得到所述会议音频文件中的文本内容;
126.提取模块603,用于调用预置的声纹提取模型对所述会议音频文件进行声纹特征提取,得到所述会议音频文件中的声纹特征,其中,所述声纹特征为至少一个;
127.查找模块604,用于根据所述声纹特征,在预置的声纹信息库中查找所述声纹特征
对应的参会人信息;
128.标注模块605,用于根据所述参会人信息对所述文本内容进行发言人标注,得到发言人信息;
129.生成模块606,用于根据所述参会人信息确定所述会议所属的工作项目,并根据所述工作项目、文本内容和对应的发言人信息生成会议记录。
130.本发明实施例的技术方案,提高了自动生成的会议记录的信息内容的准确度和详细度。
131.请参阅图7,本发明实施例中会议记录生成装置的另一个实施例包括:
132.获取模块601,用于获取待进行记录识别的会议音频文件;
133.识别模块602,用于调用预置的语音识别模型对所述会议音频文件进行语音识别,得到所述会议音频文件中的文本内容;
134.提取模块603,用于调用预置的声纹提取模型对所述会议音频文件进行声纹特征提取,得到所述会议音频文件中的声纹特征,其中,所述声纹特征为至少一个;
135.查找模块604,用于根据所述声纹特征,在预置的声纹信息库中查找所述声纹特征对应的参会人信息;
136.标注模块605,用于根据所述参会人信息对所述文本内容进行发言人标注,得到发言人信息;
137.生成模块606,用于根据所述参会人信息确定所述会议所属的工作项目,并根据所述工作项目、文本内容和对应的发言人信息生成会议记录。
138.在本技术的另一实施例中,会议记录生成装置还包括内容更新模块607,所述内容更新模块607包括:
139.提取单元6071,用于对所述会议记录内容进行文本语义识别,提取所述会议记录的核心观点和任务内容;
140.内容生成单元6072,用于基于所述核心观点生成会议摘要,基于所述任务内容生成待办事项;
141.更新单元6073,用于根据所述会议摘要和待办事项对所述会议记录的内容进行更新。
142.在本技术的另一实施例中,所述语音识别模型包括特征提取层,音调识别层和文本序列匹配层,所述识别模块602包括:
143.频谱提取单元6021,用于调用所述特征提取层对所述会议音频文件进行频谱特征提取,得到音频特征频谱;
144.音调识别单元6022,用于调用所述音调识别层将所述音频特征频谱进行切分,得到多个特征频谱片,对所述多个特征频谱片进行发音声调的识别,得到拼音序列;
145.文本匹配单元6023,用于调用所述文本序列匹配层基于所述拼音序列进行文本序列的匹配,得到会议音频文件的文本内容。
146.在本技术的另一实施例中,所述提取模块603包括:
147.参数提取单元6031,用于将所述会议音频文件输入声纹提取模型中进行声纹特征的提取,得到所述会议音频文件中的声学频谱特征参数、词法特征参数、韵律特征参数以及口音特征参数,其中,所述声纹提取模型是预先基于径向基函数神经网络构建的;
148.参数计算单元6032,用于基于所述声学频谱特征参数、所述词法特征参数、所述韵律特征参数以及所述口音特征参数生成声纹参数,得到所述会议音频文件中的声纹特征。
149.在本技术的另一实施例中,所述生成模块606包括:
150.领域确定单元6061,用于根据所述工作项目信息确定当前会议相关领域;
151.词典查找单元6062,用于根据所述会议相关领域查找预置的相关领域词典;
152.文本修正单元6063,用于根据所述相关领域词典对所述文本内容进行调整,将识别不准确的词语进行修正,得到修正文本内容;
153.记录生成单元6064,用于根据所述修正文本内容和对应的发言人信息生成会议记录。
154.在本技术的另一实施例中,所述会议记录生成装置还包括声纹库构建模块,所述声纹库构建模块包括:
155.采集员工的语音样本,对所述语音样本进行去噪处理,得到去噪语音样本;
156.对所述去噪语音样本进行质量检测,判断所述语音质量是否满足预设的样本阈值;
157.若是,则对所述去噪语音样本进行特征提取,得到注册声纹特征;
158.获取预置的员工信息,将所述注册声纹特征与所述员工信息进行关联,并基于所述员工信息和注册声纹特征得到声纹信息库。
159.在本技术的另一实施例中,所述会议记录生成装置还包括目标标注模块,所述目标标注模块包括:
160.情绪识别单元,用于调用预置的音频情绪识别模型对所述会议音频文件进行语音情绪识别,得到情绪特征参数;
161.情绪标注单元,用于基于所述情绪特征参数对所述文本内容进行情绪状态标注,得到情绪状态标识;
162.目标标注单元,用于基于所述情绪状态标识输出会议达成预计会议目标的概率,并根据所述预计会议目标和所述概率对所述文本内容进行标注。
163.本发明实施例的技术方案,提高了自动生成的会议记录的准确程度以及信息内容的详细程度,还可以根据会议记录自动生成待办事项及会议摘要,以便后续对会议内容进行具体跟进操作。
164.上面图6和图7从模块化功能实体的角度对本发明实施例中的会议记录生成装置进行详细描述,下面从硬件处理的角度对本发明实施例中会议记录生成设备进行详细描述。
165.图8是本发明实施例提供的一种会议记录生成设备的结构示意图,该会议记录生成设备800可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上处理器(central processing units,cpu)810(例如,一个或一个以上处理器)和存储器820,一个或一个以上存储应用程序833或数据832的存储介质830(例如一个或一个以上海量存储设备)。其中,存储器820和存储介质830可以是短暂存储或持久存储。存储在存储介质830的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对会议记录生成设备800中的一系列指令操作。更进一步地,处理器810可以设置为与存储介质830通信,在会议记录生成设备800上执行存储介质830中的一系列指令操作。
166.会议记录生成设备800还可以包括一个或一个以上电源840,一个或一个以上有线或无线网络接口850,一个或一个以上输入输出接口860,和/或,一个或一个以上操作系统831,例如windows serve,mac os x,unix,linux,freebsd等等。本领域技术人员可以理解,图8示出的会议记录生成设备结构并不构成对会议记录生成设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
167.本发明还提供一种计算机设备,该计算机设备可以是能够执行上述实施例中所述的会议记录生成方法的任何一种设备,所述计算机设备包括存储器和处理器,存储器中存储有计算机可读指令,计算机可读指令被处理器执行时,使得处理器执行上述各实施例中的所述会议记录生成方法的步骤。
168.本发明还提供一种计算机可读存储介质,该计算机可读存储介质可以为非易失性计算机可读存储介质,该计算机可读存储介质也可以为易失性计算机可读存储介质,所述计算机可读存储介质中存储有指令,当所述指令在计算机上运行时,使得计算机执行所述会议记录生成方法的步骤。
169.所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统,装置和单元的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。
170.所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(read-only memory,rom)、随机存取存储器(random access memory,ram)、磁碟或者光盘等各种可以存储程序代码的介质。
171.以上所述,以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。