1.本发明涉及的是一种语音处理领域的技术,具体是一种用于移动端的基于多模态知识图谱的语音自适应补全系统。
背景技术:
2.实时音视频技术多用于实时视频聊天、视频会议、远程教育、智能家居等,但在实际使用中由于网络传输时数据包可能乱序或丢包,导致的通话抖动会造成通话质量大幅下降,通常接收端通过包丢失修复系统创建音视频数据,用以填充丢包或网络延迟产生的音频空隙。音频数据补全在移动端音视频通信过程中还面临以下几个方面的难题:首先,音频生成以深度学习的方法为主导,推理过程的不透明导致该类方法的可解释性低,因而难以针对场景进行设计或调优;其次,目前的技术主要采用单一模态的数据作为模型推理的依据,忽略了移动端可感知多种模态信息的能力,导致系统对数据和信息的感知不完整,形成认知上的限制。
技术实现要素:
3.本发明针对现有技术存在的上述不足,提出一种基于多模态知识图谱的语音自适应补全系统,通过音素推理模型,在语音模态缺失时进行音素识别的同时,根据多模态知识图谱中实体间的语义关系对已有语音所产生的历史文本进行领域会话建模,从而推理并生成具有语义的文本,结合用户语音的波形特征对语音进行合成,形成补全后的音频。
4.本发明是通过以下技术方案实现的:
5.本发明涉及一种基于多模态知识图谱的语音自适应补全系统,包括:数据接收器、数据分析器和数据推理器,其中:数据接收器根据接收的音视频数据,进行预处理并输出至数据分析器;数据分析器对语音和图像的分析提取出波形时序特征和唇部轨迹特征,经多模态联合表征得到音素序列;数据推理器根据历史文本,进行领域会话建模和候选文本预测,结合音素序列进行文本推理,得到具有语义的语句,并根据波形特征合成补全的语音。
6.所述的系统中进一步设有多模态数据汇聚模块,该多模态数据汇聚模块存储并关联数据接收器和数据分析器的结果,并为数据分析器和数据推理器提供数据支撑。
7.所述的系统中进一步设有模型管理模块,该模型管理模块为数据接收器、数据分析器和数据推理器提供模型的调用和更新。
8.所述的数据接收器包括:数据接收模块、语音预处理模块和视频预处理模块,其中:数据接收模块接收并解析应用的音视频数据包,并分别将其中的语音包输出至语音预处理模块、将视频包输出至视频预处理模块;语音预处理模块对语音包进行收集和预处理,以数据包丢失的低质量实时音频为输入,经由语音数据包检测、语音分帧、音频加窗和端点检测对语音模态数据进行初步处理,得到预处理后波形并输出至语音分析模块;视频预处理模块对视频包进行收集和预处理,以连续视频图像为输入,依次通过视频分帧、面部唇形控制点检测、唇部区域尺度归一化和时间对齐对视频模态数据进行初步处理,得到预处理
后图像并输出至图像分析模块。
9.所述的数据分析器包括:语音分析模块、基于时空的图像分析模块和多模态信息融合模块,其中:语音分析模块从预处理后波形中提取历史文本、波形特征和波形时序特征,作为语音模态数据输出至多模态数据汇聚模块;基于时空的图像分析模块对预处理后的每一帧唇部控制点集合构建时空图,搭建时空图卷积神经网络,根据时空图中每一帧的前后信息提取出每一帧的唇部运动特征,合并形成唇部轨迹特征,作为视频模态数据输入到多模态数据汇聚模块;多模态融合模块对波形时序特征和唇部轨迹特征以跨模交互的方式实现特征对齐,训练得到跨模态转换模型,再将唇部轨迹特征和波形时序特征相互转换过程中的隐藏状态特征作为两个模态间联合表征,通过训练音素预测模型将联合表征信息转换为音素信息,增强唇部特征模态对音素信息的表征能力,对于语音数据包丢失区域,基于唇部轨迹特征进行音素识别,并拼接为音素序列,作为语义文本推理模块的输入。
10.所述的数据推理器包括:语义文本推理模块和语音补全模块,其中:语义文本推理模块针对语音包丢失区域,根据当前会话的历史文本对涉及的知识领域进行识别,同时基于时空知识图谱对候选文本进行预测,用以剪枝优化文本推理的解空间大小,将识别出的音素与解空间中的文本进行匹配,从而推理并生成补全后的文本并输出至语音补全模块;语音补全模块根据补全后文本和收集的用户语音波形特征对缺失的语音进行合成,通过语音拼接将补全语音填入到原本语音中,形成完整且自然的语音片段。
11.所述的语音数据包检测,得到的语音数据的活动状态包括:语音出现区域、语音静默区域和语音数据包丢失区域,其中:区分语音是否静默有利于减少不必要的语音识别和补全,标识语音数据包区域则是为了在后续对这部分区域进行语音补全。语音数据包检测对语音活动进行第一次分类,根据是否接收到当前时刻的语音数据包将此时语音区域标签为true或none,标签为none的区域将通过语义文本推理模块和语音补全模块进行补全,标签为true的区域将进一步通过端点检测的方式对语音出现和语音消失的区域进行区分。
12.所述的语音分帧,由于语音信号的时变特性导致整体信号是不平稳的,而在语音分析模块中的mfcc特征提取会使用傅立叶变换,需要平稳的输入信号,因此利用语音信号的短时平稳性,对语音信号进行分帧处理。语音分帧的过程采用交叠分段的策略,按照预设的帧长和交叠比(帧移)对每一帧进行采样,从而使前一帧向后一帧平滑过渡,保持样本的连续性。
13.所述的音频加窗采用汉明窗,对每一帧中的语音数据乘以窗函数,突显中间的数据,弱化两边的数据信息,有效解决了频谱泄露的问题,从而支持傅里叶变换。
14.所述的端点检测对每一帧数据计算出短时能量、短时平均过零率,通过双门限比较法实时对语音出现区域和语音静默区域进行分类,标签为true或false,从而从整个语音活动中定位出有效语音区域的开始点和结束点,避免静音部分和噪音部分的影响。
15.所述的视频分帧采用与语音分帧相同的采样频率将视频转换为图像序列。
16.所述的面部唇形控制点检测通过外部人脸识别引擎逐一检测每帧图像中人物唇部的控制点,包括唇部中心坐标、上唇唇中上边界坐标、嘴左角点坐标等。
17.所述的唇部区域尺度归一化,由于后续图像分析模块只关注唇部各个控制点的相对运动,需要降低图像中唇部大小、面部偏转角度、倾斜角度的影响,因此根据嘴左右角点、唇部中心坐标、唇部上下边界坐标及唇部中心坐标拟合出四边形唇部检测框,通过透视变
换将唇部控制点旋转、放缩到统一尺寸,实现唇部区域的尺度归一化,并保留了控制点移动轨迹的连续性。
18.所述的时间对齐,为了便于语音模态和视频模态的跨模交互,需要让每一帧音频都能和一帧图像相对应,又由于短时唇部控制点的轨迹可以通过简单曲线近似地代替,通过采用拉格朗日插值法拟合出每一帧音频所对应的唇部控制点集合,从而实现图像向音频的时间对齐。
19.所述的唇部控制点时空图,通过以下方式构建得到:利用控制点之间天然的连接关系,对所有输入帧的唇部控制点集合,在每一帧内按照人体唇部控制点的关系进行连接,且每个控制点与自身形成自环,构造出每一帧的空间图,再将相邻两帧的相同控制点连接构成时序边,表示两个时刻间唇部运动轨迹信息,从而同时对唇部控制点的空间信息和时序信息进行建模。
20.所述的唇部运动特征,通过以下方式提取得到:通过构建时空图卷积神经网络,对于当前帧,空间图卷积神经网络的输入用一个3维矩阵(c,t,v)表示,其中c代表唇部控制点的特征维度,采用控制点的坐标作为特征,t代表与当前帧及前t-1帧,v代表唇部控制点的数量。从空间上,采用图划分的策略,将每一帧的图g分解成g1,g2,g3三个子图,分别表示控制点向心运动、离心运动和静止的动作特征,g1中每个控制点连接比该控制点更靠近唇部中心的邻居控制点,g2中每个控制点连接比该控制点更远离唇部中心的邻居控制点,g3中每个控制点连接该控制点本身,因此图卷积所使用的大小为(1,v,v)卷积核个数为3个,通过加权平均得到相邻控制点的局部特征。在时间上,为了在当前帧的空间特征上叠加时序特征,采用时间卷积神经网络,使用(t,1)大小的卷积核对每个唇部控制点当前帧和前t-1帧的特征进行融合,获取每个控制点在时间中变化的局部特征。通过使用空间和时间卷积,提取出唇部运动特征,每一帧的输出为(1,v,n2),其中n2为每个控制点提取得的特征个数,将每一帧的唇部运动特征进行拼接,输出为(t,v,c2)唇部轨迹特征。
21.所述的数据汇聚是指:定义领域、文本词语、音素、波形特征、波形时序特征和唇部轨迹特征等本体类型、属性及其关系,以语音模态的历史文本、波形特征、波形时序特征和视频模态的唇部轨迹特征的输入为不同实体,基于多模态知识图谱汇聚、存储和关联这些实体,在系统运行的过程中不断扩张知识,为后续模块中文本推理的增强和验证提供支持。此外,数据经过整编后,波形时序特征和唇部轨迹特征作为多模态融合模块的输入,历史文本作为语义文本推理模块的输入,波形特征作为语音补全模块的输入。
22.所述的联合表征,即基于seq2seq的多模态联合表征,具体是指:跨模交互基于seq2seq模型,其中跨模态转换模型用bilstm作为编码器和解码器,通过从唇部轨迹特征到波形时序特征的翻译和从波形时序特征到唇部轨迹特征的反向翻译进行训练,得到两个模态的联合表征。
23.所述的增强唇部特征模态是指:采用与跨模态转换模型相同结构的音素推理模型,接收联合表征并输出大小为(t,|a|)的时序音素后验概率矩阵y=(y1,y2,...,yt,...,yt),其中:|a|为需要识别的音素集合a的大小,y的每一列为(yt1,yt2,...,yta,...,yta),表示第t帧为某一音素a概率。
24.所述的需要识别的音素包括:所有已知音素和blank,对blank的表示为
“‑”
,在lstm的输出转换为音素序列时,对相邻的发音相同音素作出区分。
25.所述的音素推理模型,通过以下方式进行训练:在音素预测模型解码器的bilstm后接入ctc作为转录层,目的是提高bilstm在给定输入x的情况下,输出正确结果的概率p(l|x)。由于l中的一个音素由y中多个时间片的预测结果组成,因此可能有多种组成l的路径π,即b(π)=l,b为映射函数,则转录层ctc通过梯度调整lstm的参数ω,使得对于输入样本为π∈b-1
(l)时使得p(l|x)取得最大。
26.所述的音素识别是指:对语音数据包丢失区域,将从视频中提取出的唇部轨迹特征输入到音素推理模型中,每一帧获得对应大小为|a|的音素推理向量,向量中每个值p(a),a∈a表示该帧为每个音素的概率。
27.所述的领域会话建模是指:根据历史文本推断出语义上下文所处的知识领域,如金融行业、旅行活动、生活闲谈等,主要是通过定义领域关键词的辨别性度量key推断历史文本涉及的知识领域,再结合文本实体间的时序关联性度量emi(e,w)表示一定文本步长内实体w在实体e后出现的可能性,将可能性大于一定阈值的emi(e,w)拼接成领域文本向量作为输出,从而实现对领域会话的建模。首先,领域会话模型在训练时,根据不同领域的会话样本生成每个领域的初始文本集合,在多模态知识图谱中将领域实体与文本实体进行多对多的关联。然后,为了产生具有辨识度的领域关键词,对每个文本词语j计算其在领域文本集合i中出现的频度f
ij
,统计最大频率max_f,并计算每个文本词语在n个领域中出现的次数nj,通过公式,通过公式计算得到文本词语j对领域i的辨别程度,这个计算公式相较tf-idf公式,既考虑了领域文本集合的长度,将文本频度转换成了频率,又通过归一化变换的方式保证原本计算tf的部分恒为非负数,实现了对领域关键词的辨别性度量,从而通过搜索历史文本中的关键词识别涉及的知识领域。其次,在每个知识领域中,通过计算一定文本步长内两个文本实体先后出现的频率得到实体间互信息通过计算一定文本步长内两个文本实体先后出现的频率得到实体间互信息用于表示entity2在文本顺序上与entity1的相关性,emi大于零时,值越大则出现的概率越大,emi小于零时,两个实体互斥,从而在每个领域内界定了文本实体间的关联性度量。最后,在系统使用过程中,根据会话的真实数据,向领域实体扩充关联新的文本实体,若多次会话反复跳跃在多个领域之间,则基于无监督聚类的方法对领域进行分裂和生成。
28.所述的候选文本预测,即基于时空知识图谱的候选文本预测,具体是指:利用历史文本的时序特性构成时空知识图谱网络,推理得当前候选文本的联合概率表示p(w),将概率高于一定阈值的p(w)拼接成候选文本向量,从而实现解空间的剪枝,具体包括:已经形成的历史文本可以看作是在知识图谱实体间游走的一条路径,由若干个文本实体二元组向量(from,to)组合表示。又由于音视频通话的实时性,系统当前时刻无法完全准确地预测未来,在音素识别正确的情况下,未必能预测出具有真正适当语义的文本实体,因此在路径末端实体节点前的其他实体节点上会保留多条权重较小的备选路径以供推理错误时的语义回溯,从而组成当前时刻t的路径游走图g
t
,在多模态知识图谱基础上,与之前每一时刻的路径游走图在时间维度上叠加,形成时空知识图谱g,其中空间指的是解空间。为了提高推理效率,基于一个假设:t时刻的路径游走图只取决于之前的s个时间步的路径游走图,训练
时空知识图谱网络,目的在于优化和推理g的联合概率分布其中p(g
t
|g
t-s:t-1
)可以拆分得进一步地,进一步地,进一步地,表示from_t的所有邻居实体节点,有两点好处:涵盖了候选文本空间,且具有频繁模式挖掘的能力。针对以上公式,基于循环神经网络rnn建立面向文本的时空图神经网络,需要经过以下公式参数化步骤:e
from_t
是与from_t相关的可学习向量,h
t-1
(from_t)是关于from_t的历史语义向量,ω
to_t
是分类器参数,同理,p(from_t|g
t-s:t-1
)
→
exp(h
t-1t
·
ω
from_t
),h
t-1t
为全游走路径的历史语义向量。在此基础上有为全游走路径的历史语义向量。在此基础上有和h
t
=rnn2(g(g
t
),h
t-1
),即通过rnn对历史语义向量递归更新,g为具有注意力机制的聚合函数,通过注意力矩阵学习到邻居实体节点对from实体节点的重要性权重。
29.所述的将识别出的音素与解空间中的文本进行匹配是指:根据文本对应的音素,将音素推理向量与领域文本向量、候选文本向量作笛卡尔积,得到相交音素的文本解空间,再通过公式p(a)p(w)emi(e,w)计算解空间中每个文本的概率,取值最大的文本作为补全后的文本用作语音补全,将相同音素排名前三的文本作为备选文本,一同补充历史文本,形成权重较小的备选路径,用作下一次文本推理时可能产生的语义回溯。
30.所述的基于语义的语句生成,具体为:设置阈值t和置信度α,将每条备选路径末端t个文本实体的概率相加,取其中概率最大的路径拼接生成语句,同时,将结果小于αt的路径收缩,使得图中只包含结果大于αt的路径,实现对当前时刻路径游走图的进一步剪枝,优化系统持续推理的效率。
31.所述的对缺失的语音进行合成是指:将带时间戳的文本序列转换成带时间戳的音素序列,通过tts模型根据用户语音波形特征学习到音素到波形特征的映射,并通过声码器将特征反向转换为波形。
32.所述的语音拼接是指:将已有语音波形和补全语音波形在连接点附近进行伸缩拟合后进行拼接,使语音过渡更为平滑自然。技术效果
33.相较常用于唇部特征提取中的技术手段,即对唇部运动视频提取图像特征并输入到循环神经网络,本发明以图像中的唇部控制点作为特征提取的侧重点,很大程度上减少了特征提取过程中无关变量,然后对唇部控制点间的时空关系进行时空图建模和特征提取,使得特征提取过程具有更高的可解释性。
34.相较于语音补全中常用的技术手段,即基于历史语音的语音预测,本发明通过多模态特征的交互和互补,很大程度上补充了推理所依赖的信息。
35.本发明基于知识图谱中预设和演化的参考信息进行领域会话建模和候选文本预测相结合的文本剪枝推理方式,提炼上下文的历史语义和文本路径的游走概率,结合领域知识,使结果的语义更适当,具有更高的准确性。
附图说明
36.图1为本发明的方法框架图;
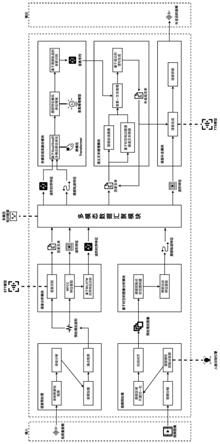
37.图2为本发明的实施例系统结构图;
38.图中:三个虚线框分别表示系统输入,系统内部功能模块和系统输出,实线连线和箭头表示各个模块交互过程中数据流动的方向,无箭头的实线连线表示功能所依赖的内部模型,虚线连线表示功能模块所依赖的外部模型。
具体实施方式
39.如图1所示,为本实施例涉及一种基于多模态知识图谱的语音自适应补全系统,包括:语音预处理模块、语音分析模块、视频预处理模块、基于时空的图像分析模块、多模态数据汇聚模块、多模态信息融合模块、语义文本推理模块以及语音补全模块,其中:语音预处理模块在接收端对语音包进行收集和预处理,以数据包丢失的低质量实时音频为输入,经由语音数据包检测、语音分帧、音频加窗和端点检测对语音模态数据进行初步处理,得到预处理后波形并输出至语音分析模块;视频预处理模块在接收端对视频包进行收集和预处理,以连续视频图像为输入,依次通过视频分帧、面部唇形控制点检测、唇部区域尺度归一化和时间对齐对视频模态数据进行初步处理,得到预处理后图像并输出至图像分析模块;语音分析模块从预处理后波形中提取历史文本、波形特征和波形时序特征,作为语音模态数据输出至多模态数据汇聚模块;基于时空的图像分析模块对预处理后的每一帧唇部控制点集合构建时空图,搭建时空图卷积神经网络,根据时空图中每一帧的前后信息提取出每一帧的唇部运动特征,合并形成唇部轨迹特征,作为视频模态数据输入到多模态数据汇聚模块;多模态数据汇聚模块汇聚、存储和关联语音模态的历史文本、波形特征、波形时序特征和视频模态的唇部轨迹特征,为后续模块的融合和推理提供支持;多模态融合模块对波形时序特征和唇部轨迹特征以跨模交互的方式实现特征对齐,训练得到跨模态转换模型,再将唇部轨迹特征和波形时序特征相互转换过程中的隐藏状态特征作为两个模态间联合表征,通过训练音素预测模型将联合表征信息转换为音素信息,增强唇部特征模态对音素信息的表征能力,对于语音数据包丢失区域,基于唇部轨迹特征进行音素识别,并拼接为音素序列,作为语义文本推理模块的输入;语义文本推理模块针对语音包丢失区域,根据当前会话的历史文本对涉及的知识领域进行识别,同时基于时空知识图谱对候选文本进行预测,用以剪枝优化文本推理的解空间大小,将识别出的音素与解空间中的文本进行匹配,从而推理并生成补全后的文本并输出至语音补全模块;语音补全模块根据补全后文本和收集的用户语音波形特征对缺失的语音进行合成,通过语音拼接将补全语音填入到原本语音中,形成完整且自然的语音片段。
40.如图2所示,实施例分为移动端应用、语音自适应补全系统和基础设施层,其中,语音自适应补全系统是整个框架的核心内容,包含语音预处理模块、视频预处理模块、语音分析模块、基于时空的视频分析模块、多模态数据汇聚模块、多模态信息融合模块、语义文本推理模块、语音补全模块,通过各模块间的交互和协作来支持音视频数据的接收、分析、推理和补全。
41.所述的语音预处理模块包括:语音数据包检测单元、语音分帧单元、音频加窗单元以及端点检测单元,其中:语音数据包检测单元根据是否收到当前时刻的语音数据包,标记
语音数据包丢失区域,语音分帧单元利用语音信号的短时平稳性,对语音信号进行分帧处理。语音分帧的过程采用交叠分段的策略,按照预设的帧长和交叠比(帧移)对每一帧进行采样,从而使前一帧向后一帧平滑过渡,保持样本的连续性,音频加窗单元采用汉明窗,对每一帧中的语音数据乘以窗函数,突显中间的数据,弱化两边的数据信息,端点检测单元对每一帧数据计算出短时能量、短时平均过零率,通过双门限比较法实时对语音出现区域和语音静默区域进行分类,从而从整个语音活动中定位出有效语音区域的开始点和结束点。
42.所述的语音分析模块包括:语音识别单元、mfcc特征提取单元和基于bilstm时序特征识别单元,其中:语音识别单元采用外部stt模型从语音中获取文本,作为文本推理的上下文;基于mfcc的特征提取单元对输入的每一帧预处理后语音数据在mel标度频率域提取出m维的倒谱特征参数,达到特征提取和降低运算维度的目的,对当前帧及其前t-1帧的倒谱特征参数拼接得到大小为(1,t,m)的波形特征图;然而,一个发音通常由很多帧语音数据组合而成,单对某一帧的特征向量进行分析会产生很大的误差,因此需要结合该帧在时间上的上下文特征;基于bilstm时序特征识别单元利用深层双向lstm网络,在mfcc波形特征图的基础上继续提取每一帧上下文的时序特征,输出大小为(t,n1)的波形时序特征矩阵,n1为每一帧的特征数。
43.所述的视频预处理模块包括:视频分帧单元、面部唇形控制点检测单元、唇部区域尺度归一化单元和时间对齐单元,其中:视频分帧单元根据输入的视频数据包,采用与语音分帧相同的采样频率将视频转换为图像序列,面部唇形控制点检测单元通过外部人脸识别引擎逐一检测每帧图像中人物唇部的控制点,包括唇部中心坐标、上唇唇中上边界坐标、嘴左角点坐标等,唇部区域尺度归一化单元根据嘴左右角点、唇部中心坐标、唇部上下边界坐标及唇部中心坐标拟合出四边形唇部检测框,通过透视变换将唇部控制点旋转、放缩到统一尺寸,实现唇部区域的尺度归一化,并保留了控制点移动轨迹的连续性,时间对齐单元通过采用拉格朗日插值法拟合出每一帧音频所对应的唇部控制点集合,从而实现图像向音频的时间对齐。
44.所述的基于时空的图像分析模块包括:唇部控制点时空图构建单元和唇部运动特征提取单元,其中:唇部控制点时空图构建单元利用控制点之间天然的连接关系,对所有输入帧的唇部控制点集合,在每一帧内按照人体唇部控制点的关系进行连接,且每个控制点与自身形成自环,构造出每一帧的空间图,再将相邻两帧的相同控制点连接构成时序边,表示两个时刻间唇部运动轨迹信息,从而同时对唇部控制点的空间信息和时序信息进行建模,唇部运动特征提取单元通过构建时空图卷积神经网络,对于当前帧,空间图卷积神经网络的输入用一个3维矩阵(c,t,v)表示,其中c代表唇部控制点的特征维度,采用控制点的坐标作为特征,t代表与当前帧及前t-1帧,v代表唇部控制点的数量。从空间上,采用图划分的策略,将每一帧的图g分解成g1,g2,g3三个子图,分别表示控制点向心运动、离心运动和静止的动作特征,g1中每个控制点连接比该控制点更靠近唇部中心的邻居控制点,g2中每个控制点连接比该控制点更远离唇部中心的邻居控制点,g3中每个控制点连接该控制点本身,因此图卷积所使用的大小为(1,v,v)卷积核个数为3个,通过加权平均得到相邻控制点的局部特征。在时间上,为了在当前帧的空间特征上叠加时序特征,采用时间卷积神经网络,使用(t,1)大小的卷积核对每个唇部控制点当前帧和前t-1帧的特征进行融合,获取每个控制点在时间中变化的局部特征。通过使用空间和时间卷积,提取出唇部运动特征,每一
帧的输出为(1,v,),其中为每个控制点提取得的特征个数,将每一帧的唇部运动特征进行拼接,输出为(t,v,c2)唇部轨迹特征。
45.所述的多模态数据汇聚模块中定义了领域、文本词语、音素、波形特征、波形时序特征和唇部轨迹特征等本体类型、属性及其关系,以语音模态的历史文本、波形特征、波形时序特征和视频模态的唇部轨迹特征的输入为不同实体,基于多模态知识图谱汇聚、存储和关联这些实体,在系统运行的过程中不断扩张知识,为后续模块中文本推理的增强和验证提供支持。此外,数据经过整编后,波形时序特征和唇部轨迹特征作为多模态融合模块的输入,历史文本作为语义文本推理模块的输入,波形特征作为语音补全模块的输入。
46.所述的多模态信息融合模块包括:基于seq2seq的多模态联合表征单元,唇部特征模态表征增强单元和基于唇部轨迹的音素识别单元,其中:基于seq2seq的多模态联合表征单元利用bilstm作为跨模态转换的编码器和解码器,通过从唇部轨迹特征到波形时序特征的翻译和从波形时序特征到唇部轨迹特征的反向翻译进行训练,得到两个模态的联合表征,唇部特征模态表征增强单元的音素推理模型采用与跨模态转换模型相同的结构,输入为联合表征,输出大小为(t,|a|)的时序音素后验概率矩阵y=(y1,y2,...,yt,...,yt),其中|a|为需要识别的音素集合a的大小,y的每一列为(yt1,yt2,...,yta,...,yta),表示第t帧为某一音素a概率。其中,需要识别的音素包括所有已知音素和blank,对blank的表示为
“‑”
,在lstm的输出转换为音素序列时,对相邻的发音相同音素作出区分。训练过程中,在音素预测模型解码器的bilstm后接入ctc作为转录层,目的是提高bilstm在给定输入x的情况下,输出正确结果的概率p(l|x)。由于l中的一个音素由y中多个时间片的预测结果组成,因此可能有多种组成l的路径π,即b(π)=l,b为映射函数,则转录层ctc通过梯度调整lstm的参数ω,使得对于输入样本为π∈b-1
(l)时使得p(l|x)取得最大,基于唇部轨迹的音素识别单元对语音数据包丢失的语音区域,将从视频中提取出的唇部轨迹特征输入到音素推理模型中,每一帧获得对应大小为|a|的音素推理向量,向量中每个值表示该帧为每个音素的概率。
47.所述的语义文本推理模块包括:领域会话建模单元,基于时空知识图谱的候选文本预测单元,文本推理单元和基于语义的语句生成单元,其中:领域会话建模单元根据当前会话的历史文本对涉及的知识领域进行识别,同时基于时空知识图谱的候选文本预测单元对候选文本进行预测,用以剪枝优化文本推理的解空间大小。文本推理单元将识别出的音素与解空间中的文本进行匹配,基于语义的语句生成单元推理并生成补全后的文本,作为语音补全模块的输入。
48.所述的领域会话建模单元是指:根据历史文本推断出语义上下文所处的知识领域,如金融行业、旅行活动、生活闲谈等,主要是通过定义领域关键词的辨别性度量key推断历史文本涉及的知识领域,再结合文本实体间的时序关联性度量emi(e,w)表示一定文本步长内实体w在实体e后出现的可能性,将可能性大于一定阈值的emi(e,w)拼接成领域文本向量作为输出,从而实现对领域会话的建模。首先,领域会话模型在训练时,根据不同领域的会话样本生成每个领域的初始文本集合,在多模态知识图谱中将领域实体与文本实体进行多对多的关联。然后,为了产生具有辨识度的领域关键词,对每个文本词语j计算其在领域文本集合i中出现的频度f
ij
,统计最大频率max_f,并计算每个文本词语在n个领域中出现的
次数nj,通过公式,通过公式计算得到文本词语j对领域i的辨别程度,这个计算公式相较tf-idf公式,既考虑了领域文本集合的长度,将文本频度转换成了频率,又通过归一化变换的方式保证原本计算tf的部分恒为非负数,实现了对领域关键词的辨别性度量,从而通过搜索历史文本中的关键词识别涉及的知识领域。其次,在每个知识领域中,通过计算一定文本步长内两个文本实体先后出现的频率得到实体间互信息域中,通过计算一定文本步长内两个文本实体先后出现的频率得到实体间互信息用于表示entity2在文本顺序上与entity1的相关性,emi大于零时,值越大则出现的概率越大,emi小于零时,两个实体互斥,从而在每个领域内界定了文本实体间的关联性度量。最后,在系统使用过程中,根据会话的真实数据,向领域实体扩充关联新的文本实体,若多次会话反复跳跃在多个领域之间,则基于无监督聚类的方法对领域进行分裂和生成。
49.所述的基于时空知识图谱的候选文本预测单元,具体是指:利用历史文本的时序特性构成时空知识图谱网络,推理得当前候选文本的联合概率表示p(w),将概率高于一定阈值的p(w)拼接成候选文本向量,从而实现解空间的剪枝,具体包括:已经形成的历史文本可以看作是在知识图谱实体间游走的一条路径,由若干个文本实体二元组向量(from,to)组合表示。又由于音视频通话的实时性,系统当前时刻无法完全准确地预测未来,在音素识别正确的情况下,未必能预测出具有真正适当语义的文本实体,因此在路径末端实体节点前的其他实体节点上会保留多条权重较小的备选路径以供推理错误时的语义回溯,从而组成当前时刻t的路径游走图g
t
,在多模态知识图谱基础上,与之前每一时刻的路径游走图在时间维度上叠加,形成时空知识图谱g,其中空间指的是解空间。为了提高推理效率,基于一个假设:t时刻的路径游走图只取决于之前的s个时间步的路径游走图,训练时空知识图谱网络,目的在于优化和推理g的联合概率分布其中p(g
t
|g
t-s:t-1
)可以拆分得以拆分得进一步地,进一步地,进一步地,表示from_t的所有邻居实体节点,有两点好处:涵盖了候选文本空间,且具有频繁模式挖掘的能力。针对以上公式,基于循环神经网络rnn建立面向文本的时空图神经网络,需要经过以下公式参数化步骤:e
from_t
是与from_t相关的可学习向量,h
t-1
(from_t)是关于from_t的历史语义向量,ω
to_t
是分类器参数,同理,p(from_t|g
t-s:t-1
)
→
exp(h
t-1t
·
ω
from_t
),h
t-1t
为全游走路径的历史语义向量。在此基础上有为全游走路径的历史语义向量。在此基础上有和h
t
=rnn2(g(g
t
),h
t-1
),即通过rnn对历史语义向量递归更新,g为具有注意力机制的聚合函数,通过注意力矩阵学习到邻居实体节点对from实体节点的重要性权重。
50.所述的文本推理单元:根据文本对应的音素,将音素推理向量与领域文本向量、候选文本向量作笛卡尔积,得到相交音素的文本解空间,再通过公式p(a)p(w)emi(e,w)计算解空间中每个文本的概率,取值最大的文本作为补全后的文本用作语音补全,将相同音素排名前三的文本作为备选文本,一同补充历史文本,形成权重较小的备选路径,用作下一次
文本推理时可能产生的语义回溯。
51.所述的基于语义的语句生成单元,具体为:设置阈值t和置信度α,将每条备选路径末端t个文本实体的概率相加,取其中概率最大的路径拼接生成语句,同时,将结果小于αt的路径收缩,使得图中只包含结果大于αt的路径,实现对当前时刻路径游走图的进一步剪枝,优化系统持续推理的效率。
52.所述的语音补全模块包括:语音合成单元和语音拼接单元,其中:语音合成单元将带时间戳的文本序列转换成带时间戳的音素序列,通过tts模型根据用户语音波形特征学习到音素到波形特征的映射,并通过声码器将特征反向转换为波形,语音拼接单元将已有语音波形和补全语音波形在连接点附近进行伸缩拟合后进行拼接,使语音过渡更为平滑自然。
53.表1技术特性对比
54.本系统基于知识图谱,在图像特征提取上构建具有结构意义的时空图,在文本推理上构建具有语义关联的时空知识图谱,推理的过程更具有可解释性;采用跨模态推理的方式,以多模态知识图谱作为数据支撑,对多模态信息形成汇集、关联和互补,具有更高的完整性;对领域会话和时序文本进行建模,基于知识图谱中预设和演化的信息,实现具有上下文语境的文本推理,提高了结果的准确性。
55.与现有技术相比较,本发明解决了在移动端音视频通信场景下,语音补全的准确率、方法的可解释性、信息和数据的完整性较低的问题,并且充分应用接收端的各模态数据进行文本的推理和语音的补全,提升了系统的智能化水平,为语音数据包的修复提供了有力的技术支撑。
56.上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。