1.本发明涉及动作合成及角色动画,特别是一种训练虚拟动物基于控制参数运动的方法。
背景技术:
2.在过去的几十年中,动画、电玩游戏和数字特效中的角色动画(character animation)的质量由于本领域研究人员开发的新工具和技术得到了极大的提高。在各种类型的角色中,四足动物的风格、节奏和步态模式的差异特别明显,因此不容易设置其动画角色。对于电玩游戏之类的实时应用,需要角色对环境做出动态反应,因此进一步使问题复杂化。
3.运动图是从运动捕捉(motion capture)资料中合成新的动画,其中节点表示从运动捕捉数据中定义好的动作,边缘代表动作之间的过渡。然而,标注节点及其过渡的过程漫长而繁琐,且为了支持不同的步态模式,需要获取大量的的运动捕捉数据。考虑到角色主体(agent)与其周围环境之间的交互作用,运动图在动态环境中将变得庞大而复杂。即使如此,运动图仍然无法适用于未曾出现过的场景。
4.运动学控制器(kinematic controllers)允许用户控制主体产生所需的运动。运动学控制器被设计为模仿运动数据集,当主体在动态环境中需要与环境进行无法看到的互动时,例如考虑四足动物在光滑且有起伏的船上行走的场景,通过运动学控制器产生的主体无法自然地响应。收集或手动设计足够的参考运动数据集来训练运动控制器显然不切实际。虽然基于物理的控制器可以有效地对复杂现象进行建模,因为物理模拟使主体能够对外部干扰产生有意义的反应,而无需收集或动画化这些反应。然而,例如重力,摩擦和碰撞之类的物理限制条件在设计基于物理的控制器时仍具有许多困难。
技术实现要素:
5.有鉴于此,本发明提出一种训练虚拟动物基于控制参数运动的方法,由此解决上述传统作法的问题。
6.依据本发明一实施例的一种训练虚拟动物基于控制参数运动的方法,包括模仿学习阶段及控制适应阶段。模仿学习阶段包含:取得一第一动量、一第二动量、一当前状态及一目标状态;以一基元网络分析该第一动量及该第二动量以产生多个基元分布;及训练一第一门控网络依据该当前状态及该些基元分布产生一第一基元权重,以从该当前状态转换为该目标状态;其中该第一动量系一参考动物进行一第一类型动作,该第二动量系该参考动物进行一第二类型动作,该参考动物关联于该虚拟动物,该当前状态及该目标状态为该参考动物在时间上连续的二取样动作。控制适应阶段,包含:取得一控制参数组;训练一第二门控网络依据该当前状态及该些基元分布产生一第二基元权重,以从该当前状态转换为该当前状态与该控制参数组的组合;及以一判别器依据该第一基元权重及该第二基元权重产生一判别结果;及依据该判别结果更新该第二门控网络;其中该判别结果用以保留该第
二基元权重或以该第二门控网络依据该当前状态及该些基元分布产生另一第二基元权重,以从该当前状态转换为该当前状态与该控制参数组的组合。
7.综上所述,依据本发明提出的训练虚拟动物基于控制参数运动的方法建立的虚拟四足动物,可在动态物理环境中自然地响应高阶控制指令。本发明在模仿学习阶段中,撷取在动画剪辑中感知到的自然运动;在控制适应阶段中,利用生成对抗网络将高阶指令映像到与动画相对应的动作分布;在微调阶段中,通过深度强化学习对控制器进行进一步的微调,使其能够从外部干扰中恢复,同时产生平稳自然的动作。依据本发明所建立的虚拟动物的控制器上可附加导航模块,使虚拟动物能够自主运行例如走出迷宫的任务。整体而言,本发明提出的方法涉及动态环境的运动合成任务,且具有运动影像自然以及高阶指令控制的两大优势。
8.以上的关于本公开内容的说明及以下的实施方式的说明系用以示范与解释本发明的精神与原理,并且提供本发明的专利申请范围更进一步的解释。
附图说明
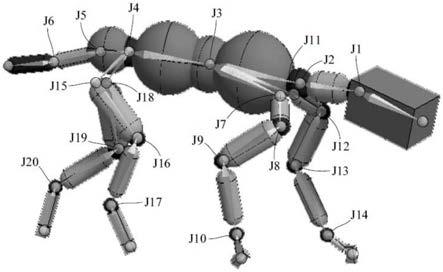
9.图1是虚拟动物的示意图;
10.图2是本发明一实施例的流程图;
11.图3是模仿学习阶段s1的细部流程图;
12.图4是控制适应阶段s2的细部流程图;以及
13.图5是微调阶段s3的细部流程图。
14.附图标记如下:
15.j1~j20
…
关节
16.s1~s3
…
阶段
17.s11~s14、s21~s24、s31~s34
…
步骤
具体实施方式
18.以下在实施方式中详细叙述本发明的详细特征以及特点,其内容足以使任何本领域普通技术人员了解本发明的技术内容并据以实施,且根据本说明书所公开的内容、申请专利范围及图式,任何本领域普通技术人员可轻易地理解本发明相关的构想及特点。以下的实施例系进一步详细说明本发明的观点,但非以任何观点限制本发明的范畴。
19.本发明提出一种训练虚拟动物基于控制参数运动的方法,所述的虚拟动物包括多个关节,如图1所示。图1示出一只具有20个关节j1~j20的四足虚拟动物,每个关节可配置虚拟马达。本发明用于产生一个控制虚拟动物运动的控制器,此控制器在每个虚拟马达提供一旋转动量,使该处的虚拟马达产生扭力,进而驱动虚拟动物基于控制参数运动。
20.图2示出本发明一实施例的流程图,包括三个主要阶段:模仿学习(imitation learning)阶段s1,控制适应阶段s2及微调阶段s3。图3是模仿学习阶段s1的细部流程图。
21.步骤s11是“取得第一动量、第二动量、当前状态及目标状态”。在一实施例中,第一动量及第二动量的每一者包含下列量测资料:位置、速度、旋转量及角速度,除了旋转量以4维的四元数(quaternions)表示,其余三者以三维向量表示。步骤s11用于取得一参考动物运动时的动量数据及状态数据。所述参考动物是虚拟动物的真实版本,例如为狗。步骤s11
的一种实施方式为在真实世界的动物身体上设置多个传感器,由此收集量测资料。步骤s11的另一种实施方式如下:通过物理引擎仿真得到动量数据及状态数据。对于步骤s11取得动量数据及状态数据的方式,本发明并不特别限制。
22.关于第一及第二动量,详言之,针对参考动物的每一个关节,在参考动物进行第一类型动作时收集第一动量的数据,且在参考动物进行第二类型动作时收集第二动量的数据。第一类型动作及第二类型动作持续一间隔时间,例如为10秒。简言之,第一及第二动量分别对应至参考动物的同一个关节的两种类型动作。第一及第二类型动作的一个范例为:走路及跑步。另一个范例为:速度每秒1.5公尺的小跑(trot)及速度每秒3公尺的慢跑(canter)。步骤s11取得的动量至少包含第一动量及第二动量等两种类型动作,但本发明并不限类型动作的上限数量。换言之,可根据需求取得参考动物的第三、第四
…
动量。
23.关于当前状态及目标状态,详言之,当前状态及目标状态代表参考动物在时间上连续的二个取样姿态。就数据结构而言,当前状态及目标状态的每一者与第一动量或第二动量相同。换言之,当前状态及目标状态的每一者亦包含位置、速度、旋转量及角速度等数据;而差别在于:当前状态及目标状态只包含两个连续的时间点取样的量测数据,而第一动量及第二动量则分别包含一段时间的量测数据。在一实施例中,当前状态及目标状态可从第一或第二动量选取。例如:第一动量包含10秒钟长度的小跑动作,则当前状态及目标状态可以是第3秒及第4秒时的量测资料。
24.步骤s12是“基元网络分析第一动量及第二动量以产生多个基元分布”,步骤s13是“训练第一门控网络依据当前状态及基元分布产生第一基元权重”,由此从当前状态转换为目标状态。基元网络(primitive network)及门控网络(gating network)为一策略网络(policy network)的两个模块,此策略网络的实施方式请参考此文件:“xue bin peng,michael chang,grace zhang,pieter abbeel,and sergey levine.2019.mcp:learning composable hierarchical control with multiplicative compositional policies.in neurips”本发明在此并不叙述“基元网络产生基元分布”及“第一门控网络产生第一基元权重”的实施方式。
25.基元分布(primitive distribution),或称为基元影响力(primitive influence),其为动作的基本单位。在一实施例中,基元网络p产生的基元分布为φ1...φk。每个基元分布φi包含一高斯分布(gaussian distribution)的模型,其具有一个状态相关的动作均值(state-depedent action mean)μi(s
t
)以及一个对角共变异数矩阵(diagonal covariance matrix)σi,如下方式1所示。本发明特别采用固定的(fixed)对角共变异数矩阵,由此避免在基元网络训练过程中因为修改σ导致过早收敛(prematrue convenrgence)。
26.φi=n(μi(s
t
),σi),i=1,2...k
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(式1)
27.一或多个基元分布的组合可使虚拟动物呈现指定的动作。步骤s13系以第一门控网络产生用于组合该一或多个基元分布的一或多个基元权重,所述的权重如下方式2所示。
28.w=g
low
(s
t
,c
low
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(式2)
29.其中w为第一基元权重,w∈rk,k为基元分布的数量。g
low
为第一门控网络,s
t
为当前状态,c
low
为目标状态,包含关节层级的信息,如位置、速度、旋转量
及角速度。s
t
代表第t秒的状态,c
low
代表第t+1秒及第t+2秒的状态。
30.步骤s14是“依据基元分布及第一基元权重产生动作分布”。第一基元权重及基元分布可采用乘法形式组合成一复合分布,如式3所示,式3所示的复合分布也是一种高斯分布。此动作分布已可用作控制虚拟动物的关节的控制指令。
[0031][0032]
其中z(s
t
,c
t
)是标准化(normailization)函数,c
t
为控制目标(control objective),c
t
=c
low
。依据式3可取样得到虚拟动物的下一个动作分布a
t+1
。
[0033]
本发明一实施例中,在模仿学习阶段s1更包含姿态、速度及质心(center of mass)三种奖励函数(reward function),如式4、式5及式6所示。
[0034][0035][0036][0037]
式4的姿态奖励函数r
p
通过计算虚拟动物的第j个关节的实际定向(orientation)qj和目标定向两者的四元数差θ以鼓励控制器匹配目标状态。
[0038]
式5的速度奖励函数rv计算关节速度的差值,及分别代表虚拟动物的第j个关节的当前角速度与目标角速度。
[0039]
式6的质心奖励函数r
com
用于避免虚拟动物的当前质心pc偏离目标质心提供反激励(discourage)。
[0040]
在本发明一实施例中,其特征在于以接触点(contact point)的奖励函数rc取代末端执行器(end effector)的奖励函数,如式7所示。
[0041][0042]
其中,表示逻辑互斥或(exclusive-or,xor)运算,pe为虚拟动物的末端执行器的布尔接触状态,e属于“左前、右前、左后、右后”中的一者。式7的奖励函数rc用于避免虚拟动物的步态样式(gait pattern)偏离目标状态,且有助于解决脚部滑动的现象。例如,只有左前方的末端执行器接触地面时可标示为p=[1,0,0,0]。式7中的λc表示控制指数函数斜率的超参数(hypeparameter),在本发明一实施例中,λc=5可产生最佳结果。奖励函数的最终形式如式8所示。
[0043]
r=0.65r
p
+0.1rv+0.1r
com
+0.15rcꢀꢀꢀꢀꢀ
(式8)
[0044]
为了减少训练时的复杂度,本发明将每个控制目标的目标状态分别计算。因此,本发明在模仿学习阶段得到的基于物理的控制器可通过学习对应的基元分布及基元权重来
模仿给定的目标状态,并且产生自然的运动,执行目标状态所描述的步态样式。
[0045]
在一实施例中,可省略步骤s14不执行而直接进入控制适应阶段s2。
[0046]
图4是控制适应阶段s2的细部流程图,控制适应阶段s2包含步骤s21~s24。步骤s21是“取得控制参数组”。控制参数组可由目标状态c
low
推导得出,控制参数组包含虚拟动物的速度及方向(heading)。在一实施例中,控制参数组c
high
=(σ,δθ),其中σ代表虚拟动物的目标速度,δθ代表当前方向与目标方向的角度差。例如,指定虚拟动物以每秒1公尺,逆时钟90度的方向前进,此时控制参数组为c
high
=(1,0.5π)。
[0047]
步骤s22是“训练第二门控网络依据当前状态及基元分布产生第二基元权重”。详言之,将目标状态以控制参数组取代时,第二门控网络需学习高阶指令与基元权重之间的映射关系,由此从当前状态转换为当前状态与控制参数组的组合。须注意的是,传统的误差函数如l1距离或l2距离只会保留低阶(low-order)的分布,而无法保证从正确的动作分布取得样本。因此,本发明在本步骤s22采用生成对抗网络(generative adversarial network)中的生成器(generator)作为第二门控网络。给定从真实世界的动作分布w
real
~g
low
(s
t
,c
low
)提取的第一基元权重w
real
,步骤s22的第二门控网络g
high
产生从w
fake
~g
high
(s
t
,c
high
)提取的第二基元权重w
fake
。
[0048]
步骤s23是“判别器依据第一基元权重及第二基元权重产生一判别结果”。在本发明一实施例中,第二门控网络及判别器(discriminator)皆为生成对抗网络架构中的模块。判别器d通过最大化如下方式9定义的对抗损失(adversarial loss)函数l
adv
以产生判别结果。
[0049][0050]
l
rec
=||w
fake-w
real
||1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(式10)
[0051]
lg=λ
adv
*l
adv
+λ
rec
*l
rec
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(式11)
[0052]
式10的重建误差(reconstruction loss)l
rec
计算第一基元权重及第二基元权重之间的绝对值距离。本发明一实施例中,通过最小化式11定义的目标函数以训练第二门控网络g
high
。通过损失函数l
adv
,判别器d可判别所产生的第二基元权重属于可保留(real)或不可保留(fake),如此使得第二门控网络学习到真实的数据分布。式11中的λ
rec
的值为100,且λ
adv
的值为1。共同最小化l
rec
和l
adv
的两个损失函数可以使第二门控网络产生第二基元权重更近似于模仿学习阶段s1产生的真实的第一基元权重。
[0053]
步骤s24是“依据判别结果更新第二门控网络”。若判别器判断第二基元权重可用,则保留第二基元权重。否则,第二门控网络依据当前状态及基元分布产生另一第二基元权重,再交由判别器判断此另一第二基元权重是否可使虚拟动物从当前状态转换为当前状态与控制参数组的组合。产生另一第二基元权重的方式例如以随机方式产生,本发明对此不予限制。
[0054]
在步骤s24完成之后,可依据一或多个基元分布以及更新后的第二门控网络产生的第二基元权重组合出另一动作分布,由此控制虚拟动物的每个关节。此另一动作分布相似于步骤s14产生的动作分布,其差别在于此另一动作分布更具有依据生成对抗网络所得到的规范(criteria)。另一动作分布的组成方式则与步骤s14所述相同。
[0055]
在本发明一实施例中,仅完成模仿学习阶段s1及控制适应阶段s2便可实现一个可基于高阶指令运动的虚拟动物的控制适配器(control adapter)。在本发明另一实施中,在控制适应阶段s2之后更包括一微调阶段s3。图5是微调阶段s3的细部流程图。微调阶段s3包含图5的步骤s31~s34。
[0056]
步骤s31是“取得环境参数组”。类似于前述的控制参数组,环境参数组同样包含虚拟动物的速度及方向,其差别在于环境参数组反映了大量的场景的信息。详言之,在控制适应阶段s2中,控制参数组只反映了一小部分的环境场景。为了使虚拟动物在未见过的场景中仍可恢复正常状态,因此需要进一步微调控制适应阶段s2中建立的第二门控网络。
[0057]
步骤s32是“训练第二门控网络依据当前状态、基元分布及奖励函数组产生第三基元权重”,由此从当前状态转换为适应状态。适应状态系当前状态与环境参数组的组合,虚拟动物响应于环境参数组而具有适应状态。步骤s32所述的奖励函数组速度奖励函数及方向奖励函数,分别如下方式12及式13所示。
[0058]rspd
=exp[-λ
spd
(σ-||v||)2]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(式12)
[0059][0060]
速度奖励函数r
spd
计算目标速度σ与当前速度||v||之间的l2距离。λ
spd
的值设置为0.8可得到最好的效果。
[0061]
方向奖励函数r
head
计算目标方向与虚拟动物的当前方向投影到动作平面上的向量v两者之间的余弦相似度,其中代表目标方向的弪度量。余弦相似度被标准化到0与1之间。
[0062]
步骤s33是“判别器依据第三基元权重及第一基元权重产生另一判别结果”。步骤s33与控制适应阶段s2的步骤s23基本上相同,在此不重复叙述。步骤s34是“至少依据另一判别结果更新第二门控网络”。在本发明一实施例中,可以只依据另一判别结果更新第二门控网络。在本发明另一实施例中,至少依据另一判别结果更新第二门控网络包括:依据另一判别结果及正规化函数更新第二门控网络。步骤s34的重点之一在于:在更新第二门控网络时,禁止修改每一基元分布的参数。步骤s34的重点之二在于:为了确保控制器不会偏离在控制适应阶段s2中学习到的动作分布,而采用加入下方式14所示的正则化函数l
reg
。
[0063][0064]
其中代表以生成对抗网络训练的门控网络的第l个全连接层的参数,α
l
代表目前训练的门控网络的第l个全连接层的参数,l代表每一个门控网络的总层数。本发明将此正则化函数应用于参数空间而非层的输出,因为将正则化函数应用在层的输出导致对于真实未知场景的额外惩罚。在控制适应阶段s2及微调阶段s3分别对第二门控网络进行更新时,通过此正则化函数l
reg
,可达到两者之间的平衡,而不会在较晚执行的微调阶段s3中过度修改在适应阶段s2中训练过的第二门控网络。
[0065]
在步骤s34完成之后,可依据一或多个基元分布以及更新后的第二门控网络产生的第二基元权重组合出又一动作分布,由此控制虚拟动物的每个关节。此又一动作分布相似于步骤s14及步骤s24产生的动作分布,其差别在于此又一动作分布更具有依据生成对抗网络及深度强化学习所得到的规范(criteria)。又一动作分布的组成方式则与步骤s14所述相同。
[0066]
综上所述,依据本发明提出的训练虚拟动物基于控制参数运动的方法建立的虚拟四足动物,可在动态物理环境中自然地响应高阶控制指令。本发明在模仿学习阶段中,撷取在动画剪辑中感知到的自然运动;在控制适应阶段中,利用生成对抗网络将高阶指令映像到与动画相对应的动作分布;在微调阶段中,通过深度强化学习对控制器进行进一步的微调,使其能够从外部干扰中恢复,同时产生平稳自然的动作。依据本发明所建立的虚拟动物的控制器上可附加导航模块,使虚拟动物能够自主运行例如走出迷宫的任务。整体而言,本发明提出的方法涉及动态环境的运动合成任务,且具有运动影像自然以及高阶指令控制的两大优势。