1.本发明属于自动驾驶控制技术领域。
背景技术:
2.一般情况下,自动驾驶的驾驶策略都是模块化的组成。大致分为4个层次:(1)战略规划层:一般负责从起点到终点的全局路径层面的规划。这一部分涉及到最短路径、加权最短路径、gis等一些相关知识,目前的研究和实现方法均已经比较成熟;(2)战术层决策:一般负责在实际驾驶过程中,局部范围内的行为决策,例如跟驶、换道、超车、加速、减速等;(3)局部规划层:依据战术决策层的动作意图,该层负责生成一条安全、且符合交通法规的轨迹(trajectory);(4)车辆控制层:这一层主要是根据生成的轨迹,一般采用最优控制的方法,通过对车辆油门、刹车、方向盘的控制,实现对生成轨迹的最小偏差跟踪。
3.换道决策和换道轨迹生成分别是自动驾驶战术决策层和局部规划层中的关键内容,是很多驾驶场景下的基本决策行为,其性能水平的高低很大程度上决定了自动驾驶决策、规划与控制的安全、效率与好坏。传统的做法主要包括:(1)换道决策采用基于规则(例如有限状态机)的方式来实现,换道轨迹生成采用最优控制理论来生成;(2)换道决策与执行绑定在一起,采用端到端(end-to-end)的方式进行学习,直接从状态输入,输出换道车辆控制动作。第(1)种方式,由于本质上是基于规则的做法,因此很难泛化到未定义驾驶场景下,而且定义复杂场景下的规则集十分困难,甚至无法实现;第(2)种方式尽管在决策上非常高效,同时也能够很好泛化到未定义场景下,但是这种纯粹基于学习的方式,无法完全保证换道的安全性。此外,自动驾驶策略本质上是“分层的”,也就是先产生驾驶意图,然后根据意图生成轨迹和控制车辆,如果直接将决策与控制绑定在一起,很难建立高效的决策与控制方法。
技术实现要素:
4.本发明目的是为了解决现有自动驾驶过程中存在安全性差/效率低的问题,提供了一种基于分层强化学习的自动驾驶车辆换道决策控制方法。
5.本发明所述的一种基于分层强化学习的自动驾驶车辆换道决策控制方法,该方法包括:
6.步骤一、利用自动驾驶车辆实际驾驶场景中的速度及与周边环境内车辆的相对位置、相对速度信息建立带有3个隐含层的决策神经网络,并利用换道安全奖励函数对所述决策神经网络进行训练拟合q估值函数,获取q估值最大的动作;
7.步骤二、当q估值最大的动作为换道动作时,执行步骤三,当q估值最大的动作为继续跟驰时,利用自动驾驶车辆的实际驾驶场景中的速度和周边环境车辆的相对位置信息与跟驰动作对应的奖励函数,建立深度q学习的加速度决策模型,获得跟驰加速度,完成一次自动驾驶决策及控制;
8.步骤三、利用自动驾驶车辆的实际驾驶场景中的速度和周边环境车辆的相对位置
信息与换道动作对应的奖励函数,建立深度q学习的加速度决策模型;获得换道动作的加速度信息;
9.步骤四、利用换道动作的加速度信息,采用5次多项式曲线生成一条参考换道轨迹;
10.步骤五、采用纯跟踪控制方法,控制自动驾驶车辆执行换道动作,完成一次自动驾驶换道决策及控制。
11.进一步地,本发明中,步骤一、步骤二和步骤三中所述的自动驾驶车辆实际驾驶场景中的速度及与周边环境内车辆的相对位置和相对速度信息为:
12.目标自动驾驶车辆与当前车道前车相对位置:δx
leader
=|x
ego-x
leader
|;其中,x
ego
为目标自动驾驶车辆沿车道方向的位置坐标,x
leader
为当前车道目标自动驾驶车辆前车沿车道方向的位置坐标;
13.目标自动驾驶车辆与目标车道前车相对位置:δx
target
=|x
ego-x
target
|;其中,x
target
为目标车道前车沿车道方向的位置坐标;
14.目标自动驾驶车辆与目标车道后车相对位置:δx
follow
=|x
ego-x
follow
|;其中,x
follow
为目标车道后车沿车道方向的位置坐标;
15.目标自动驾驶车辆与目标车道前车相对速度:δv
ego
=|v
ego-v
leader
|;其中,v
ego
为目标自动驾驶车辆的速度,v
leader
为当前车道目标自动驾驶车辆前车的速度;
16.目标自动驾驶车辆与目标车道前车相对速度:δv
target
=|v
ego-v
target
|;其中,v
target
为目标车道前车沿车道方向的速度;
17.目标自动驾驶车辆速度:v
ego
;
18.目标自动驾驶车辆加速度:a
ego
。
19.进一步地,本发明中,步骤一中,换道安全奖励函数为:
[0020][0021]
其中,w1,w2,w3,w4分别为目标自动驾驶车辆与当前车道前车相对位置的权重系数、目标自动驾驶车辆与目标车道前车相对速度的权重系数,目标自动驾驶车辆与目标车道前车相对位置和目标自动驾驶车辆与目标车道前车相对速度的权重系数。
[0022]
进一步地,本发明中,步骤一中,带有3个隐含层的决策神经网络中,每个隐含层包括100个神经元。
[0023]
进一步地,本发明中,步骤二中,建立深度q学习的加速度决策模型的具体方法为:
[0024]
以环境状态作为输入,分别通过3个子全连接神经网络a、b、c,获取加速度决策模型的最终q估值:
[0025]
环境状态:s=(δx
leader
,δx
target
,δx
follow
,δv
ego
,δv
target
,v
ego
,a
ego
)
[0026]
其中,a代表需要决策的纵向加速度;
[0027]
跟驰奖励函数:
[0028]rdis
=-w
dis
.|x
leader-x
ego
|
ꢀꢀ
公式二
[0029]rv
=wv.|v
leader-v
ego
|
ꢀꢀ
公式三
[0030]
rc=r
dis
+rvꢀꢀ
公式四
[0031]
其中,r
dis
,rv分别代表跟驰状态与距离相关的奖励函数和速度相关的奖励函数;w
dis
和wv分别为跟驰状态距离奖励和速度奖励对应的权重;rc代表跟驰状态与距离和速度相关的综合奖励;
[0032]
加速度决策模型最终的q估值:
[0033]
q(s,a)=a(s).(b(s)-rc|a)2+c(s)
ꢀꢀ
公式五
[0034]
其中,rc|a表示在加速度取a的条件下,跟驰状态获得的综合奖励;a(s),b(s),c(s)分别为当前状态s下,3个子全连接神经网络的输出。
[0035]
进一步地,本发明中,步骤三中,利用自动驾驶车辆的实际驾驶场景信息、速度和周边环境车辆的相对位置信息与换道动作对应的奖励函数,建立深度q学习的加速度决策模型的具体方法:
[0036]
以环境状态作为输入,分别通过3个子全连接神经网络a、b、c,获取加速度决策模型的最终q估值:
[0037]
环境状态:s=(δx
leader
,δx
target
,δx
follw
δv
ego
,δv
target
,v
ego
,a
ego
)
[0038]
其中,a代表需要决策的纵向加速度;
[0039]
换道奖励函数:
[0040]rdis
=-w
dis
.|min(δx
leader
,δx
target
)-δx
follow
|
ꢀꢀ
公式六
[0041]rv
=-wv.|min(v
leader
,v
target
)-v
ego
|
ꢀꢀ
公式七
[0042]
ra=r
dis
+rvꢀꢀ
公式八
[0043]
其中,r
dis
,rv分别代表换道状态时与距离和速度相关的奖励;w
dis
和wv分别为换道状态时距离奖励和速度奖励对应的权重;ra代表换道状态时与距离和速度相关的综合奖励;
[0044]
加速度决策模型最终的q值:
[0045]
q(s,a)=a(s).(b(s)-ra|a)2+c(s)
ꢀꢀ
公式九
[0046]
其中,ra|a表示在加速度取a的条件下,换道状态所获得的即时奖励,a(s),b(s),c(s)分别为当前状态s下,3个子全连接神经网络的输出。
[0047]
进一步地,本发明中,步骤四中,利用换道动作的加速度信息,采用5次多项式曲线生成一条参考换道轨迹为:
[0048]
x(t)=a5t5+a4t4+a3t3+a2t2+a1t+a0ꢀꢀ
公式十
[0049]
y(t)=b5t5+b4t4+b3t3+b2t2+b1t+b0ꢀꢀ
公式十一
[0050]
其中,x(t)为t时刻的轨迹点沿道路横向的位置坐标,y(t)为t时刻的轨迹点沿道路纵向的位置坐标,t为时间,参数a1,...,a5,b1,...,b5通过期望函数:
[0051][0052]
确定,通过改变a1,...,a5,b1,...,b5的值优化期望函数,使期望函数在轨迹规划边界约束和交通限速约束条件下在t时刻的加速度a对应参考轨迹的距离和风险最小化,舒适性最大化,其中,t为参考换道轨迹规划的时间窗,表示参考换道轨迹的出行距离项,wdp(dangerous|a,t)表示参考换道轨迹的安全风险项,wcp(comfort|a,t)表示参考换道轨迹的舒适项,wd,wc分别为参考轨迹的风险项的权重和舒适性的权重,wc<0,p
(dangerous|a,t)为目标函数中安全风险概率,p(comfort|a,t)为目标函数中的舒适性程度。
[0053]
进一步地,本发明中,轨迹规划边界约束条件具体为:使参考轨迹在车道线以内:
[0054][0055]
其中,x
min
、y
min
、x
max
和y
max
分别表示当前车辆对应的车道线边界坐标。
[0056]
进一步地,本发明中,交通限速约束条件具体为:使参考轨迹的任意一个点上的地点速度不超过交通限速值:
[0057][0058]
其中,υ
x,min
υ
x,max
,υ
y,min
,υ
y,max
分别表示自动驾驶车辆沿着x,y两个方向的速度允许值范围。
[0059]
进一步地,本发明中,步骤五中,采用纯跟踪控制方法,控制自动驾驶车辆执行换道动作的具体方法:
[0060]
根据生成的参考换道轨迹,采用纯跟踪控制算法,控制自动驾驶车辆的换道动作过程中方向盘转角:
[0061][0062][0063]
其中,δ(t)为纯跟踪控制算法在t时刻计算得到的方向盘转角;α(t)为实际的方向盘转角;ld是向前观看的距离,l为车辆的轴距。
[0064]
本发明所述方法非常好的结合了基于学习方式的可泛化以及最优控制的安全性两方面优势,同时由于将换道决策和加速度决策行为采用两个模型进行了分层处理,本发明采用换道决策模型和加速度决策模型利用q估值神经网络,使处理更加高效,准确性更高,本质上更贴近“换道意图产生
→
换道轨迹生成
→
换道动作执行”的人类驾驶换道行为,因此能够产生更加安全、鲁棒、高效的决策及控制输出。
附图说明
[0065]
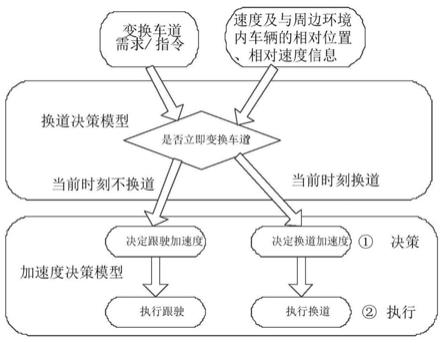
图1是本发明所述基于自动驾驶换道决策及控制方法的原理图;
[0066]
图2是换道场景参数示意图;图中,ego为目标自动驾驶车辆,leader为目标自动驾驶车辆当前车道前车,target为目标自动驾驶车辆目标车道的前车,follow为目标自动驾驶车辆目标车道的后车;
[0067]
图3是加速度决策模型的网络架构图。
具体实施方式
[0068]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完
整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0069]
需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
[0070]
具体实施方式一:下面结合图1说明本实施方式,本实施方式所述一种基于分层强化学习的自动驾驶车辆换道决策控制方法,该方法包括:
[0071]
步骤一、利用自动驾驶车辆实际驾驶场景中的速度及与周边环境内车辆的相对位置、相对速度信息,建立带有3个隐含层的决策神经网络,并利用换道安全奖励函数对所述决策神经网络进行训练拟合q估值函数,获取q估值最大的动作;
[0072]
步骤二、当q估值最大的动作为换道动作时,执行步骤三,当q估值最大的动作为继续跟驰时,利用自动驾驶车辆的实际驾驶场景中的速度和周边环境车辆的相对位置信息与跟驰动作对应的奖励函数,建立深度q学习的加速度决策模型,获得跟驰加速度,完成一次自动驾驶决策及控制;
[0073]
步骤三、利用自动驾驶车辆的实际驾驶场景中的速度和周边环境车辆的相对位置信息与换道动作对应的奖励函数,建立深度q学习的加速度决策模型;获得换道动作的加速度信息;
[0074]
步骤四、利用换道动作的加速度信息,采用5次多项式曲线生成一条参考换道轨迹;
[0075]
步骤五、采用纯跟踪控制方法,控制自动驾驶车辆执行换道动作,完成一次自动驾驶换道决策及控制。
[0076]
本实施方式中,输入是变换车道的需求/指令以及环境状态信息。变换车道的需求可能来自更高级别的行为决策,例如在超车情境下,由于自动驾驶目标车辆所在车道的前方车辆行驶速度过慢,而自动驾驶车辆为了获取更高的驾驶效率收益,因此尝试做出超车行为,而超车行为必然触发换道需求或指令。同时,目标自动驾驶车辆周边的环境信息(主要为周边环境车辆的相对位置、速度等信息)也必须同步输入,它们是自动驾驶车辆换车道决策的基础。
[0077]
本发明所述方法采用了两个决策模型的架构,包括了换道决策模型和加速度决策模型。换道决策模型收到变道需求和环境状态信息后,决定是否变换车道,调整自动驾驶车辆纵向的加速度(决策),进一步执行跟驶和换道行为。
[0078]
进一步地,结合图2说明本实施方式,本实施方式中,步骤一、步骤二和步骤三中所述的自动驾驶车辆实际驾驶场景中的速度及与周边环境内车辆的相对位置和相对速度信息为:
[0079]
目标自动驾驶车辆与当前车道前车相对位置:δx
leader
=|x
ego-x
leader
|;其中,x
ego
为目标自动驾驶车辆沿车道方向的位置坐标,x
leader
为当前车道目标自动驾驶车辆前车沿车道方向的位置坐标;
[0080]
目标自动驾驶车辆与目标车道前车相对位置:δx
target
=|x
ego-x
target
|;其中,x
target
为目标车道前车沿车道方向的位置坐标;
[0081]
目标自动驾驶车辆与目标车道后车相对位置:δx
follow
=|x
ego-x
follow
|;其中,
x
follow
为目标车道后车沿车道方向的位置坐标;
[0082]
目标自动驾驶车辆与目标车道前车相对速度:δv
ego
=|v
ego-v
leader
|;其中,v
ego
为目标自动驾驶车辆的速度,v
leader
为当前车道目标自动驾驶车辆前车的速度;
[0083]
目标自动驾驶车辆与目标车道前车相对速度:δv
target
=|v
ego-v
target
|;其中,v
target
为目标车道前车沿车道方向的速度;
[0084]
目标自动驾驶车辆速度:v
ego
;
[0085]
目标自动驾驶车辆加速度:a
ego
。
[0086]
本实施方式中,换道环境状态定义示意图如图2所示,ego为自动驾驶车辆,其余车辆为背景车辆。每一辆车都具有自身的状态,包括了位置横坐标、位置纵坐标、速度和加速度4个信息。环境状态s=(δx
leader
,δx
target
,δx
follow
,δv
ego
,δv
target
,v
ego
,a
ego
)。
[0087]
进一步地,本实施方式中,步骤一中,换道安全奖励函数为:
[0088][0089]
其中,w1,w2,w3,w4分别为目标自动驾驶车辆与当前车道前车相对位置的权重系数、目标自动驾驶车辆与目标车道前车相对速度的权重系数,目标自动驾驶车辆与目标车道前车相对位置和目标自动驾驶车辆与目标车道前车相对速度的权重系数;
[0090]
本实施方式中,w1=0.4,w2=0.6,w3=0.4,w4=0.6。
[0091]
进一步地,结合图2进行说明,本实施方式中,步骤一中,带有3个隐含层的决策神经网络中,每个隐含层包括100个神经元。
[0092]
进一步地,本实施方式中,步骤二中,建立深度q学习的加速度决策模型的具体方法为:
[0093]
以环境状态作为输入,分别通过3个子全连接神经网络a、b、c,获取加速度决策模型的最终q估值:
[0094]
环境状态:s=(δx
leader
,δx
target
,δx
follow
,δv
ego
,δv
target
,v
ego
,a
ego
)
[0095]
其中,a代表需要决策的纵向加速度;
[0096]
跟驰奖励函数:
[0097]rdis
=-w
dis
.|x
leader-x
ego
|
ꢀꢀ
公式二
[0098]rv
=-wv.|v
leader-v
ego
|
ꢀꢀ
公式三
[0099]
rc=r
dis
+rvꢀꢀ
公式四
[0100]
其中,r
dis
,rv分别代表跟驰状态与距离相关的奖励函数和速度相关的奖励函数;w
dis
和wv分别为跟驰状态距离奖励和速度奖励对应的权重;rc代表跟驰状态与距离和速度相关的综合奖励;
[0101]
加速度决策模型最终的q估值:
[0102]
q(s,a)=a(s).(b(s)-rc|a)2+c(s)
ꢀꢀ
公式五
[0103]
其中,rc|a表示在加速度取a的条件下,跟驰状态获得的综合奖励;a(s),b(s),c(s)分别为当前状态s下,3个子全连接神经网络的输出。
[0104]
进一步地,本实施方式中,步骤三中,利用自动驾驶车辆的实际驾驶场景信息、速度和周边环境车辆的相对位置信息与换道动作对应的奖励函数,建立深度q学习的加速度
决策模型的具体方法:
[0105]
以环境状态作为输入,分别通过3个子全连接神经网络a、b、c,获取加速度决策模型的最终q估值:
[0106]
环境状态:s=(δx
leader
,δx
target
,δx
follow
,δv
ego
,δv
target
,v
ego
,a
ego
)
[0107]
其中,a代表需要决策的纵向加速度;
[0108]
换道奖励函数:
[0109]rdis
=-w
dis
.|min(δx
leader
,δx
target
)-δx
follow
|
ꢀꢀ
公式六
[0110]rv
=-wv.|min(v
leader
,v
target
)-v
ego
|
ꢀꢀ
公式七
[0111]
ra=r
dis
+rvꢀꢀ
公式八
[0112]
其中,r
dis
,rv分别代表换道状态时与距离和速度相关的奖励;w
dis
和wv分别为换道状态时距离奖励和速度奖励对应的权重;ra代表换道状态时与距离和速度相关的综合奖励。
[0113]
加速度决策模型最终的q值:
[0114]
q(s,a)=a(s).(b(s)-ra|a)2+c(s)
ꢀꢀ
公式九
[0115]
其中,ra|a表示在加速度取a的条件下,换道状态所获得的即时奖励,a(s),b(s),c(s)分别为当前状态s下,3个子全连接神经网络的输出。
[0116]
本实施方式中,加速度决策模型接收来自换道决策模型的决策输出,即是否换道。如果不换道,则触发跟驶行为,如果换道,则触发换道行为。如图1所示,加速度决策模型负责决策出一个纵向的加速度(沿道路方向的连续值),加速度决策模型负责生成一条安全的轨迹,然后控制车辆跟踪这条生成的轨迹。本实施方式中,自动驾驶车辆的实际驾驶场景信息、速度和周边环境车辆的相对位置信息为环境状态,三个子全连接神经网络包括三个子全连接神经网络,每个子全连接神经网络都包括200个神经元。
[0117]
进一步地,本实施方式中,步骤四中,利用换道动作的加速度信息,采用5次多项式曲线生成一条参考换道轨迹为:
[0118]
x(t)=a5t5+a4t4+a3t3+a2t2+a1t+a0ꢀꢀ
公式十
[0119]
y(t)=b5t5+b4t4+b3t3+b2t2+b1t+b0ꢀꢀ
公式十一
[0120]
其中,x(t)为t时刻的轨迹点沿道路纵向的位置坐标,y(t)为t时刻的轨迹点沿道路横向的位置坐标,t为时间,参数a1,...,a5,b1,...,b5通过期望函数:
[0121][0122]
确定,通过改变a1,...,a5,b1,...,b5的值优化期望函数,使期望函数在轨迹规划边界约束和交通限速约束条件下在t时刻的加速度a对应参考轨迹的距离和风险最小化,舒适性最大化,其中,t为参考换道轨迹规划的时间窗,表示参考换道轨迹的出行距离项,wdp(dangerous|a,t)表示参考换道轨迹的安全风险项,wcp(comfort|a,t)表示参考换道轨迹的舒适项,wd,wc分别为参考轨迹的风险项的权重和舒适性的权重,wc<0,p(dangerous|a,t)为目标函数中安全风险概率,p(comfort|a,t)为目标函数中的舒适性程度。
[0123]
本实施方式中,根据加速度决策模型输出的加速度a,接下来规划自动驾驶车辆跟
驶或换道的轨迹。轨迹的规划依据两项指标,分别是:安全性和舒适性。首先,采用5次多项式曲线生成一条参考换道轨迹,所述安全性通过参考轨迹的距离和风险体现。
[0124]
进一步地,本实施方式中,轨迹规划边界约束条件具体为:使参考轨迹在车道线以内:
[0125][0126]
其中,x
min
、y
min
、x
max
和y
max
分别表示当前车辆对应的车道线边界坐标。
[0127]
进一步地,本实施方式中,交通限速约束条件具体为:使参考轨迹的任意一个点上的地点速度不超过交通限速值:
[0128][0129]
其中,v
x,min
、v
x,max
、v
y,min
和v
y,max
分别表示自动驾驶车辆沿着道路横向y和纵向x两个方向的速度允许值范围。
[0130]
进一步地,本实施方式中,步骤五中,采用纯跟踪控制方法,控制自动驾驶车辆执行换道动作的具体方法:
[0131]
根据生成的参考换道轨迹,采用纯跟踪控制算法,控制自动驾驶车辆的换道动作过程中方向盘转角:
[0132][0133][0134]
其中,δ(t)为纯跟踪控制算法在t时刻计算得到的方向盘转角;α(t)为实际的方向盘转角;ld是向前观看的距离,l为车辆的轴距。
[0135]
虽然在本文中参照了特定的实施方式来描述本发明,但是应该理解的是,这些实施例仅仅是本发明的原理和应用的示例。因此应该理解的是,可以对示例性的实施例进行许多修改,并且可以设计出其他的布置,只要不偏离所附权利要求所限定的本发明的精神和范围。应该理解的是,可以通过不同于原始权利要求所描述的方式来结合不同的从属权利要求和本文中所述的特征。还可以理解的是,结合单独实施例所描述的特征可以使用在其他所述实施例中。