1.本公开涉及用于在包括讲话者(発話者)的声音的声响数据中,检测讲话者发出声音的讲话(発話,utterance)区间的装置、方法以及程序。
背景技术:
2.例如,在专利文献1中,公开了基于由相机获取到的图像(图像数据)中拍摄到的讲话者的嘴唇形状的变化来检测由麦克风采集的声音(声响数据)中的讲话者的声音的讲话区间(讲话区间)的装置以及方法。
3.在先技术文献
4.专利文献
5.专利文献1:日本特开2008-152125号公报
技术实现要素:
6.发明要解决的课题
7.然而,在专利文献1所记载的装置以及方法的情况下,在相机的摄影范围内讲话者正在步行、正在移动头部等正在运动的情况下,提取该相机的摄影图像数据中的讲话者的嘴唇区域的精度下降。其结果,将讲话者未发出声音的声响数据的区间误检测为讲话区间等、讲话区间的检测精度有可能下降。
8.因此,本公开以在包括讲话者的声音在内的声响数据中高精度地检测讲话者发出声音的讲话区间为课题。
9.用于解决课题的手段
10.根据本公开的一个方式,提供讲话区间检测装置,该讲话区间检测装置包括:第1嘴唇形状估计部,基于包括讲话者的声音的声响数据估计所述讲话者的第1嘴唇形状;第2嘴唇形状估计部,基于至少拍摄到所述讲话者的面部的图像数据估计所述讲话者的第2嘴唇形状;和讲话区间检测部,基于所述第1嘴唇形状的变化和所述第2嘴唇形状的变化,在所述声响数据中检测所述讲话者发出声音的讲话区间。
11.此外,根据本公开的另外的方式,提供在包括讲话者的声音的声响数据中检测所述讲话者发出声音的讲话区间的讲话区间检测方法,该讲话区间检测方法包括:获取所述声响数据;获取至少拍摄到所述讲话者的面部的图像数据;基于所述声响数据估计所述讲话者的第1嘴唇形状的变化;基于所述图像数据估计所述讲话者的第2嘴唇形状的变化;和基于所述第1嘴唇形状的变化和所述第2嘴唇形状的变化检测所述声响数据中的所述讲话区间。
12.进一步地,根据本公开的又一的方式,提供讲话区间检测程序,被安装在具备处理器的装置的存储设备,用于使所述处理器在包括讲话者的声音的声响数据中检测所述讲话者发出声音的讲话区间,所述讲话区间检测程序用于使所述处理器:基于所述声响数据估计所述讲话者的第1嘴唇形状;基于至少拍摄到所述讲话者的面部的图像数据估计所述讲
话者的第2嘴唇形状;以及基于所述第1嘴唇形状的变化和所述第2嘴唇形状的变化,在所述声响数据中检测所述讲话区间。
13.此外,根据本公开的不同的方式,提供讲话区间检测装置,包括:第1嘴唇形状估计部,基于包括讲话者的声音的声响数据计算所述讲话者的第1张嘴程度;第2嘴唇形状估计部,基于至少拍摄到所述讲话者的面部的图像数据计算所述讲话者的第2张嘴程度;和讲话区间检测部,基于所述第1张嘴程度的变化和所述第2张嘴程度的变化,在所述声响数据中检测所述讲话者发出声音的讲话区间。
14.另外,根据本公开的又一不同的方式,提供讲话区间检测装置,包括:第1嘴唇形状估计部,基于包括讲话者的声音的声响数据计算所述讲话者的第1嘴唇运动量;第2嘴唇形状估计部,基于至少拍摄到所述讲话者的面部的图像数据计算所述讲话者的第2嘴唇运动量;和讲话区间检测部,基于所述第1嘴唇运动量和第2嘴唇运动量的变化,在所述声响数据中检测所述讲话者发出声音的讲话区间。
15.发明效果
16.根据本公开,能够在包括讲话者的声音的声响数据中,高精度地检测讲话者发出声音的讲话区间。
附图说明
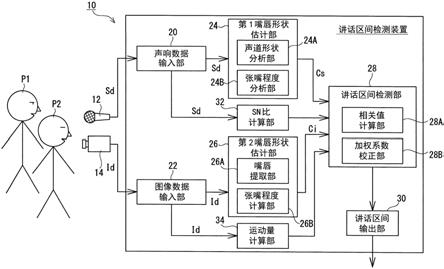
17.图1是概略性地示出本公开的一个实施方式涉及的讲话区间检测装置的结构的图。
18.图2是示出声响数据的一个例子的图。
19.图3是示出发声期间的声道的多个区域中的声道剖面积的一个例子的图。
20.图4是示出基于声响数据而计算出的嘴唇的张嘴程度的变化的图。
21.图5是示出拍摄到讲话者的嘴唇的图像数据的一个例子的图。
22.图6是示出嘴唇图像数据ld的一个例子的图。
23.图7是示出基于图像数据而计算出的嘴唇的张嘴程度的变化的图。
24.图8是示出在声响数据中检测讲话区间的一个例子的流程的流程图。
具体实施方式
25.以下,适当参照附图并详细地对实施方式进行说明。不过,有时省略超出必要地详细的说明。例如,有时省略已经公知的事项的详细说明、针对实质上相同的结构的重复说明。这是为了避免以下的说明不必要地变得冗长,使本领域技术人员的理解容易。
26.另外,发明人为了使本领域技术人员充分地理解本公开而提供附图以及以下的说明,意图并不在于由它们来限定专利保护范围所记载的主题。
27.以下,参照附图对本公开的一个实施方式涉及的讲话区间检测装置进行说明。
28.图1概略性地示出了本公开的一个实施方式涉及的讲话区间检测装置的结构。
29.图1所示的本实施方式涉及的讲话区间检测装置10构成为在由麦克风设备12获取到的包括多个讲话者p1、p2的声音在内的声响数据sd中,检测作为讲话者p1、p2分别发出声音的区间的讲话区间。为此,讲话区间检测装置10构成为使用由相机设备14获取且至少拍摄到多个讲话者p1、p2的面部的图像数据id。
30.如图1所示,在本实施方式涉及的讲话区间检测装置10连接有麦克风设备12和相机设备14。讲话区间检测装置10具有输入来自该麦克风设备12的声响数据sd的声响数据输入部20和输入来自相机设备14的图像数据id的图像数据输入部22。
31.此外,讲话区间检测装置10具有:第1嘴唇形状估计部24,基于输入到声响数据输入部20的声响数据sd,来估计讲话者p1、p2的嘴唇形状(第1嘴唇形状);第2嘴唇形状估计部26,基于输入到图像数据输入部22的图像数据id,来估计讲话者p1、p2的嘴唇形状(第2嘴唇形状)。进一步地,讲话区间检测装置10具有讲话区间检测部28,讲话区间检测部28基于由第1嘴唇形状估计部24估计出的嘴唇形状的变化和由第2嘴唇形状估计部26估计出的嘴唇形状的变化,来检测声响数据sd中的讲话区间。
32.在本实施方式的情况下,讲话区间检测装置10还具有:讲话区间输出部30,针对用户而输出检测出的讲话区间;sn比计算部32,计算声响数据sd的sn比;和运动量计算部34,基于图像数据id来计算讲话者p1、p2的运动量。
33.这样的讲话区间检测装置10例如通过具备cpu等处理器和硬盘等存储设备的个人计算机来实现。在该情况下,讲话区间检测装置10具备用于将麦克风设备12与相机设备14连接的外部连接端子,或具备麦克风设备12和相机设备14。在该存储设备保存有用于使处理器作为第1嘴唇形状估计部24、第2嘴唇形状估计部26、讲话区间检测部28、sn比计算部32以及运动量计算部34而发挥功能的讲话区间检测程序。此外,在存储设备存储为了检测声响数据sd、图像数据id以及讲话区间而制作的中间数据等。
34.此外,例如讲话区间检测装置10也可以是一体地具备麦克风设备12和相机设备14,并且具备处理器和存储器等存储设备的智能手机等便携式终端。例如,用于使便携式终端作为讲话区间检测装置10而发挥功能的讲话区间检测程序被设置在便携式终端的存储设备。
35.麦克风设备12采集讲话者p1、p2所在的空间(例如会议室)内的声音,将该采集到的声音作为声响数据sd而输出到讲话区间检测装置10。如图2所示,麦克风设备12作为声响数据sd而输出波形数据。另外,在图2中作为一个例子而示出的声响数据包括讲话者依次发出“a”、“i”、“u”、“e”、“o”的讲话区间。此外,噪声与波形数据整体重叠。
36.相机设备14是对讲话者p1、p2进行拍摄的设备,设置为至少讲话者p1、p2的面部进入到摄影范围内。此外,相机设备14制作至少拍摄到讲话者p1、p2的面部的多个图像数据id,并将该制作的图像数据id输出到讲话区间检测装置10。
37.从此处起,对图1所示的本实施方式涉及的讲话区间检测装置10的各构成要素的详细情况进行说明。
38.讲话区间检测装置10的声响数据输入部20从麦克风设备12接受声响数据sd,并将该声响数据sd输出到第1嘴唇形状估计部24和sn比计算部32。
39.讲话区间检测装置10的第1嘴唇形状估计部24基于声响数据sd,来估计讲话者的嘴唇形状。在本实施方式的情况下,作为将嘴唇形状数值化了的参数,计算嘴唇的张嘴程度。为此,第1嘴唇形状估计部24包括基于声响数据sd来分析讲话者的声道形状的声道形状分析部24a和基于分析出的声道形状来分析嘴唇的张嘴程度的张嘴程度分析部24b。
40.声道形状分析部24a使用声响数据sd和下述的数学式1来分析(计算)声道形状。
41.[数1]
[0042][0043]
在数学式1中,对从采集声音开始起经过了经过时间t的定时处的振幅s(t)进行z变换,从而计算s(z)。
[0044]
在作为声道声源模型而使用了线形预测模型(lpc模型)的情况下,声音波形(声音信号)的某个样本值s(n)根据在其之前的p个样本值来预测。样本值s(n)能够表示为下述的数学式2。
[0045]
[数2]
[0046]
s(n)=α1s(n-1)+α2s(n-2)+
…
+α
p
s(n-p)
ꢀꢀ
(数学式2)
[0047]
针对p个样本值的系数αi(i=1~p),能够通过使用相关法、协方差法等来计算。数学式1中的a(z)能够使用该αi而表示为下述的数学式3。
[0048]
[数3]
[0049][0050]
u(z)是同一定时处的声源信号u(t)的z变换,能够通过s(z)a(z)来计算。
[0051]
通过以上的处理,可计算从采集声音开始起经过了经过时间t的定时处的声道形状1/a(z)。另外,在本实施方式的情况下,对于声道形状1/a(z),使用parcor系数。
[0052]
张嘴程度分析部24b使用由声道形状分析部24a分析出的(计算出的)声道形状1/a(z)即parcor系数和下述的数学式4来分析(计算)声道剖面积。
[0053]
[数4]
[0054][0055]
在数学式4中,ki是i次的parcor系数,ai是第i个声道剖面积。另外,a
n+1
=1。
[0056]
图3是示出发声期间的声道的多个区域中的声道剖面积的一个例子的图。
[0057]
如图3所示,张嘴程度分析部24b首先将从声门至嘴唇的声道分割成11个区域,计算从嘴唇开始数第i个声道剖面积ai。a1表示嘴唇处的声道剖面积,a
11
表示声门处的声道剖面积。
[0058]
如果计算出声道的各区域的声道剖面积a1~a
11
,则张嘴程度分析部24b使用下述的数学式5来计算张嘴程度cs。
[0059]
[数5]
[0060][0061]
如数学式5所示,张嘴程度cs是针对从第1个(嘴唇)到第t个区域各自的声道剖面积之和。t在1~5的范围内设定,在本实施方式的情况下,t=3。
[0062]
图4是示出由第1嘴唇形状估计部24计算出的、即基于声响数据sd而计算出的嘴唇的张嘴程度的变化的图。另外,图4所示的张嘴程度的变化基于图2所示的声响数据来计算。
[0063]
比较图2以及图4,在将嘴张开得相对大而发出的“a”以及“e”的定时中,张嘴程度cs被计算为较大,在将嘴张开得相对小而发出的“i”、“u”以及“o”的定时中张嘴程度cs被计算为较小。此外,在未发声的定时中,张嘴程度cs实质上为零。因此,得知基于声响数据sd而适当地计算出了嘴唇的张嘴程度cs。不过,在如本实施方式这样多个讲话者p1、p2的声音包括于声响数据sd的情况下,不知道计算出的张嘴程度cs是哪个讲话者的张嘴程度。
[0064]
回到图1,关于由第1嘴唇形状估计部24计算出的张嘴程度cs(该数据)被输出到在后面详细描述的讲话区间检测部28。
[0065]
讲话区间检测装置10的图像数据输入部22从相机设备14接受图像数据id,并将该图像数据id输出到第2嘴唇形状估计部26和运动量计算部34。
[0066]
讲话区间检测装置10的第2嘴唇形状估计部26基于图像数据id,来估计讲话者的嘴唇形状。在本实施方式的情况下,作为将嘴唇形状数值化了的参数来计算嘴唇的张嘴程度。为此,第2嘴唇形状估计部26包括提取图像数据id中的讲话者的嘴唇区域的嘴唇提取部26a和基于提取出的嘴唇区域来计算嘴唇的张嘴程度的张嘴程度计算部26b。
[0067]
嘴唇提取部26a确定并提取在图像数据id内拍摄到讲话者p1、p2的嘴唇的区域(嘴唇区域)。
[0068]
图5是示出拍摄到讲话者的嘴唇的图像数据的一个例子。
[0069]
如图5所示,嘴唇提取部26a确定并提取在图像数据id中拍摄到讲话者p1、p2的嘴唇l的嘴唇区域lr,制作如图6所示那样的拍摄到嘴唇整体的嘴唇图像数据ld。
[0070]
另外,根据相机设备14与讲话者p1、p2各自之间的距离,图像数据id中的嘴唇的大小不同,因而也可以对制作的嘴唇图像数据ld的大小进行标准化。为了该标准化,嘴唇图像数据ld例如也可以确定并提取图像数据id中的拍摄到讲话者p1、p2的面部的面部区域fr,计算该面部区域fr的大小与基准的面部区域的大小的比率,基于该比率来调整尺寸(resize)。
[0071]
张嘴程度计算部26b基于由嘴唇提取部26a制作出的嘴唇图像数据ld,来计算嘴唇的张嘴程度ci。在本实施方式的情况下,如图6所示,张嘴程度ci是嘴唇图像数据ld中的上唇lt与下唇lb之间的距离d1和嘴角间距离d2之积。或者,也可以简单地根据上唇lt与下唇lb之间的距离d1来设为张嘴程度ci。
[0072]
另外,如上述那样,在嘴唇图像数据ld的大小被标准化了的情况下,在嘴唇图像数据ld中,也可以计算被上唇lt和下唇lb包围的区域内的像素数,以作为张嘴程度ci。
[0073]
图7是示出由嘴唇形状计算部26计算出的、即基于图像数据id而计算出的嘴唇的张嘴程度的变化的图。另外,图7所示的张嘴程度的变化基于与图2所示的声响数据sd同步的相机设备14的图像数据(运动图像数据)来计算。
[0074]
比较图2以及图7,在将嘴张开得相对大而发出的“a”以及“e”的定时中,张嘴程度ci被计算为较大,在将嘴张开得相对小而发出的“i”、“u”以及“o”的定时中,张嘴程度ci被计算为较小。因此,得知适当地计算出了张嘴程度ci。
[0075]
回到图1,由第2嘴唇形状估计部26计算出的张嘴程度ci(该数据)被输出到讲话区间检测部28。
[0076]
另外,在如本实施方式这样多个讲话者p1、p2被相机设备14拍摄的情况下,计算讲话者p1、p2各自的嘴唇的张嘴程度ci。
[0077]
讲话区间检测部28基于由第1嘴唇形状估计部24计算出的嘴唇的张嘴程度cs和由第2嘴唇形状估计部26计算出的嘴唇的张嘴程度ci,来检测声响数据sd中的讲话区间。为此,讲话区间检测部28包括相关值计算部28a和加权系数校正部28b。
[0078]
在本实施方式的情况下,首先,讲话区间检测部28的相关值计算部28a使用下述的数学式6来计算表示张嘴程度cs和张嘴程度ci的相关的程度的相关值r。
[0079]
[数6]
[0080]
r(t)=cs(t)
β
×
ci(t)
γ
ꢀꢀ
(数学式6)
[0081]
在数学式6中,cs(t)、ci(t)以及r(t)表示从采集声音开始起经过了经过时间t的定时处的张嘴程度cs、ci以及r。此外,β以及γ是加权系数(乘数)。
[0082]
讲话区间检测部28在声响数据sd中,检测包括相关值r(t)比给定阈值大的定时在内的区间,来作为讲话者p1、p2动嘴唇而发出声音的讲话区间。例如,在图2所示的数据中,将采集声音开始设为零秒时,约1.2~3.8秒的区间被作为讲话区间而检测出。
[0083]
在相关值r(t)的值比给定阈值大的情况下,即在张嘴程度cs、ci这两者较大的情况下,讲话者p1、p2动嘴唇而发出声音的准确度高。
[0084]
另一方面,在相关值r(t)比给定阈值小的情况下,即在张嘴程度cs以及张嘴程度ci中的至少一者小的情况下,讲话者p1、p2动嘴唇而发出声音的准确度低。
[0085]
例如,在张嘴程度cs大且张嘴程度ci小的情况下,麦克风设备12可能采集到了不处于相机设备14的摄影范围内的人物的声音,例如从讲话者所在的房间外听到的第三者的声音、从电视、广播等中听到的第三者的声音等。
[0086]
此外,例如,在张嘴程度cs小且张嘴程度ci大的情况下,讲话者p1、p2可能动了嘴唇而未发出声音。
[0087]
因此,通过使用相关值r(t),讲话区间检测部28能够在声响数据sd中高准确度地检测讲话者p1、p2发出了声音的讲话区间。
[0088]
另外,如图1所示,在多个讲话者p1、p2被相机设备14摄影的情况下,通过使用各自的张嘴程度ci来计算相关值r,能够高准确度地检测讲话者p1、p2各自的讲话区间。
[0089]
此外,在本实施方式的情况下,讲话区间检测部28构成为考虑张嘴程度cs、ci各自的可靠度而计算相关值r。为此,如图1所示,sn比计算部32和运动量计算部34包括于讲话区间检测装置10。
[0090]
sn比计算部32计算声响数据sd的sn比,并将该计算出的sn比输出到讲话区间检测部28。
[0091]
讲话区间检测部28的加权系数校正部28b在sn比低于给定门限sn比的情况下,在用于计算相关值r(t)的上述的数学式6中,与张嘴程度cs相比对张嘴程度ci进行加权。即,由于基于sn比低的声响数据sd而计算出的张嘴程度cs可靠度低,因而对基于图像数据id而计算出的张嘴程度ci进行加权。例如,进行将作为上述的数学式6中的张嘴程度cs的乘数的加权系数β减小的校正,并且进行将作为张嘴程度ci的乘数的加权系数γ增大的校正。由此,讲话区间检测部28能够计算出具备高可靠度的相关值r(t)。
[0092]
运动量计算部34基于在图像数据id中拍摄到的讲话者p1、p2的身体的至少一部分,来计算讲话者p1、p2的运动量。例如,运动量计算部34计算图像数据id中的头部的位移量,作为讲话者p1、p2的运动量。计算出的运动量被输出到讲话区间检测部28。
[0093]
讲话区间检测部28的加权系数校正部28b在运动量比给定门限运动量大的情况下,在用于计算相关值r(t)的上述的数学式6中,与张嘴程度ci相比对张嘴程度cs进行加权。即,在运动量大的情况下,图像数据id中的嘴唇区域的提取精度下降,基于这样的嘴唇区域而计算出的张嘴程度ci的可靠度低。因此,对基于声响数据sd而计算出的张嘴程度cs进行加权。例如,进行将作为上述的数学式6中的张嘴程度cs的乘数的加权系数β增大的校正,并且进行将作为张嘴程度ci的乘数的加权系数γ减小的校正。由此,讲话区间检测部28能够计算出具备高可靠度的相关值r(t)。
[0094]
由讲话区间检测部28检测出的讲话区间经由讲话区间输出部30,针对用户而被输出。讲话区间输出部30例如在与讲话区间检测装置10连接的显示器等显示设备,显示图2所示的声响数据sd(波形数据),并且显示由讲话区间检测部28检测出的讲话区间。此外,例如,讲话区间输出部30根据声响数据sd对由讲话区间检测部28检测出的讲话区间的部分进行修整,制作声响数据,并输出该制作得到的声响数据。
[0095]
从此处起,参照图8对在声响数据中检测讲话区间的流程进行说明。
[0096]
图8是示出在声响数据中检测讲话区间的一个例子的流程的流程图。
[0097]
如图8所示,讲话区间检测装置10(其声响数据输入部20)在步骤s100中,获取包括讲话者p1、p2的声音的声响数据sd。
[0098]
在步骤s110中,讲话区间检测装置10(其第1嘴唇形状估计部24的声道形状分析部24a)基于在步骤s100中获取到的声响数据sd,来分析讲话者p1、p2的声道形状。
[0099]
在步骤s120中,讲话区间检测装置10(其第1嘴唇形状估计部24的张嘴程度分析部24b)基于在步骤s110中分析出的声道形状,来分析讲话者p1、p2的嘴唇的张嘴程度cs。
[0100]
在接下来的步骤s130中,讲话区间检测装置10(其图像数据输入部22)获取拍摄到讲话者p1、p2的嘴唇的图像数据id。
[0101]
在步骤s140中,讲话区间检测装置10(其第2嘴唇形状估计部26的嘴唇提取部26a)在步骤s130中获取到的图像数据id中,确定并提取嘴唇区域。
[0102]
在步骤s150中,讲话区间检测装置10(其第2嘴唇形状估计部26的张嘴程度计算部26b)基于步骤s140中提取出的嘴唇区域,来计算讲话者p1、p2的嘴唇的张嘴程度ci。
[0103]
在步骤s160中,讲话区间检测装置10判定由sn比计算部32计算出的声响数据sd的sn比是否比给定门限sn比低。此外,讲话区间检测装置10判定由运动量计算部34计算出的讲话者p1、p2的运动量是否比给定门限运动量大。在sn比低或运动量大的情况下,前进到步骤s170。在不是如此的情况下,跳过步骤s170而前进行到步骤s180。
[0104]
在步骤s170中,由于sn比低或运动量大,因而讲话区间检测装置10(其讲话区间检测部28的加权系数校正部28b)对相关值r(t)的计算式(数学式6)的加权系数进行校正。
[0105]
在步骤s180中,讲话区间检测装置10(其讲话区间检测部28的相关值计算部28a)计算相关值r(t)。
[0106]
在步骤s190中,讲话区间检测装置10(其讲话区间检测部28)基于步骤s180中计算出的相关值r(t),来检测声响数据sd中的讲话区间。
[0107]
在步骤s200中,讲话区间检测装置10(其讲话区间输出部30)针对用户而输出步骤s190中检测出的讲话区间。
[0108]
另外,也可以在基于声响数据sd来计算张嘴程度cs的步骤(步骤s100~s120)之前
或与之同时,执行基于图像数据id来计算张嘴程度ci的步骤(步骤s130~s150)。
[0109]
根据以上那样的本实施方式,能够在包括讲话者的声音的声响数据中,高精度地检测讲话者发出声音的讲话区间。
[0110]
如果具体地说明,在判断声响数据中的讲话区间时,使用基于声响数据而估计出的讲话者的嘴唇形状(具体地,计算出的张嘴程度cs)的变化和基于图像数据而估计出的讲话者的嘴唇形状(具体地,计算出的张嘴程度ci)的变化,即使用2个判断材料。因此,与仅使用基于图像数据而估计出的讲话者的嘴唇形状的变化来检测声响数据中的讲话区间的情况相比,能够高精度地检测讲话区间。
[0111]
虽然以上举出上述的实施方式而对本公开进行了说明,但本公开的实施方式不限定于此。
[0112]
例如,在上述的实施方式的情况下,使用数学式6所示的计算式,计算了表示基于声响数据sd而计算出的张嘴程度cs与基于图像数据id而计算出的张嘴程度ci的相关性的相关值r。然而,相关值的计算式不限于此。
[0113]
例如,如下述的数学式7所示,相关值r(t)也可以是张嘴程度cs(t)、ci(t)之和。
[0114]
[数7]
[0115]
r(t)=β
×
cs(t)+γ
×
ci(t)
ꢀꢀ
(数学式7)
[0116]
此外,如下述的数学式8所示,相关值r也可以是以张嘴程度cs、ci为变量的correl函数。
[0117]
[数8]
[0118]
r=corr(cs,ci)
ꢀꢀ
(数学式8)
[0119]
在使用数学式8的计算式的情况下,首先,声响数据sd被分割成多个区间。针对分割出的各区间分别计算相关值r。然后,将相关值r比给定阈值高的至少1个区间检测为讲话区间。
[0120]
另外,在张嘴程度cs、ci的可靠度高的情况下,例如在讲话者所在的空间安静的情况、在图像数据中提取嘴唇区域的精度高的情况(图像处理能力高的情况)等情况下,也可以省略加权系数β、γ中的至少一者。
[0121]
此外,在上述的实施方式的情况下,使用表示基于声响数据sd而计算出的张嘴程度cs与基于图像数据id而计算出的张嘴程度ci的相关的程度的相关值r,来检测声响数据sd中的讲话区间。然而,本公开的实施方式不限于此。
[0122]
例如,也可以对图4所示的那样的基于声响数据sd而计算出的张嘴程度cs的波形和图7所示的那样的基于图像数据而计算出的张嘴程度ci的波形进行比较,基于它们的一致的程度来检测讲话区间。
[0123]
进一步地,在上述的实施方式的情况下,基于包括噪声的状态的声响数据sd来估计讲话者的嘴唇形状(具体地计算张嘴程度cs)。也可以取代于此,使用通过噪声滤波器等将噪声除去了的声响数据来估计讲话者的嘴唇形状。在该情况下,能够高精度地估计嘴唇形状。此外,能够省略图1所示的sn比计算部32以及加权系数校正部30b。
[0124]
进一步地,此外,在上述的实施方式的情况下,遍及声响数据sd整体而估计讲话者的嘴唇形状(具体地,计算张嘴程度cs)。即,即便不在讲话区间的范围中也估计嘴唇形状。也可以取代于此,在估计嘴唇形状之前,对在声响数据sd中可能存在讲话区间的范围进行
推测。例如,也可以推测在声响数据中振幅比给定阈值大的范围内可能存在讲话区间,并在该范围内估计嘴唇形状。此外,例如,也可以将在声响数据中具有周期性的范围推测为可能存在讲话区间的范围。例如,也可以将自相关函数为给定值以上的范围设为具有周期性的范围。
[0125]
进一步地,在上述的实施方式的情况下,用1个麦克风设备12来采集多个讲话者p1、p2的声音。因此,有可能多个讲话者的声音重叠地被麦克风设备12采集。作为其对策,麦克风设备也可以是包括指向性不同的多个指向性麦克风的麦克风阵列。指向性麦克风分别面向一个讲话者而进行声音采集,多个指向性麦克风分别获取声响数据。并且根据多个声响数据分别来估计讲话者的嘴唇形状。
[0126]
进一步地,此外,在上述的实施方式的情况下,声响数据sd中的讲话区间使用基于声响数据sd而计算出的嘴唇的张嘴程度cs和基于图像数据id而计算出的嘴唇的张嘴程度ci来检测。然而,本公开的实施方式不限于此。
[0127]
例如,也可以提取图像数据中的讲话者的嘴唇区域,基于提取出的嘴唇区域,来计算该讲话者的嘴唇的活动量。如图2所示,在讲话者发出多个音的情况下,在该音与音之间嘴唇形状变化。此外,在由多个音构成的短语的情况下,嘴唇形状在短语的开始(最初的音开始定时)和结束后(最后的音结束定时)也变化。因此,也可以基于图像数据,例如计算下唇相对于上唇的每单位时间的活动量作为将嘴唇形状数值化了的参数,并使用基于该计算出的活动量的变化和声响数据而计算出的张嘴程度,来检测讲话区间。
[0128]
此外,例如,也可以根据声响数据来计算讲话者的嘴唇的活动量。使用图2来进行说明,如果讲话者发音,则在该音的开始定时和结束定时处,振幅大幅变化。该振幅的每单位时间的变化量能够被视为嘴唇的每单位时间的活动量。因此,也可以基于声响数据的振幅,计算嘴唇的每单位时间的活动量作为将嘴唇形状数值化了的参数,使用该计算出的活动量的变化和基于图像数据而计算出的张嘴程度,来检测讲话区间。
[0129]
进一步地,例如,如上述那样,也可以使用基于声响数据而计算出的嘴唇的活动量和基于图像数据而计算出的嘴唇的活动量,来检测声响数据中的讲话区间。
[0130]
即,本公开的某个实施方式在广义上,基于包括讲话者的声音在内的声响数据来估计讲话者的第1嘴唇形状,此外,基于至少拍摄到讲话者的面部的图像数据来估计讲话者的第2嘴唇形状,基于第1嘴唇形状的变化和第2嘴唇形状的变化,在声响数据中检测讲话者发出声音的讲话区间。
[0131]
另外,在本实施方式中,通过基于线形预测分析的声道形状来计算出张嘴程度,但不限于此,只要是根据声音信息来计算嘴唇的张嘴程度的方法即可。例如,也可以利用通过arx声音分析法而分析出的传递特性来计算张嘴程度。或者,也可以设为通过神经网络等机器学习来预先学习产生的声音与嘴唇形状的关系,由此根据声音来直接估计嘴唇形状。
[0132]
此外,张嘴程度分析部24b也可以根据声响数据将张嘴程度的变化量作为运动量计算,以作为讲话者的张嘴程度的特征量。具体地,运动量能够通过张嘴程度的时间差分来计算。同样,张嘴程度计算部26b也可以根据图像数据将讲话者的嘴唇的活动量作为运动量计算。具体地,通过由嘴唇提取部26a提取出的嘴唇形状的时间差分来计算运动量。讲话区间检测部28也可以基于声响数据的振幅,将嘴唇的每单位时间的活动量作为运动量计算,以作为将嘴唇形状数值化了的参数,使用作为计算出的运动量的时间变化和作为基于图像
数据而计算出的嘴唇的活动量的运动量的时间变化,来检测讲话区间。具体地,也可以设为相关值计算部28a在给定时间宽度内计算基于由张嘴程度分析部24b计算出的声响数据的嘴唇的运动量的时间变化与基于由张嘴程度计算部26b计算出的图像数据的嘴唇的运动量的时间变化的相关性,从而计算时间变化的联动性。
[0133]
如以上那样,作为本公开中的技术的例示而说明了上述的实施方式。为此,提供了附图以及详细的说明。
[0134]
因此,在附图以及详细的说明所记载的构成要素之中,不仅例示了为了课题解决而必须的构成要素,为了例示所述技术,还可能包括为了课题解决而非必要的构成要素。因此,不应因这些非必要的构成要素记载于附图、详细的说明中,而直接将这些非必要的构成要素认定为是必要的。
[0135]
此外,上述的实施方式用于例示本公开中的技术,所以能够在权利要求书或在其等同的范围内进行各种变更、置换、附加、省略等。
[0136]
产业上的可利用性
[0137]
本公开能够应用于需要在包括讲话者的声音在内的声响数据中确定该讲话者发出声音的区间的情况,例如需要获得会议的会议记录等情况。