1.本发明属于人工智能技术领域,涉及语音提取技术,具体涉及一种基于双麦克风阵列的目标语音提取方法。
背景技术:
2.在人工智能技术领域,语音增强、语音识别一直都是专家学者及语音交互产品市场关注的热点话题。其中,双麦克风阵列以其显而易见的优势成为技术人员研究的主要对象。原因在于相比于单麦克风,双麦克风阵列在非稳态噪声处理及远距离拾音等方面具有较大优势;而与多麦克风阵列相比,双麦克风阵列又极大简化了语音交互产品的硬件设计方案及语音前端算法处理的复杂度。因此,双麦克风阵列以其小巧灵活的构型以及电路、算力、成本要求都比较低而广泛应用于智能家居、智能玩具等领域。
3.在语音增强技术上,基于双麦克风阵列的语音信号处理算法主要有基于波束形成的算法,如延时累加波束形成(delay
‑
sum beamforming,dsb)方法、最小方差无失真响应(minimum variance distortionless response,mvdr)波束形成方法等,基于盲源分离的算法以及基于深度学习的方法等。其中,基于盲源分离的算法相比于传统波束形成方法降噪效果好、相比于深度学习方法算力小,易集成在嵌入式系统上。因此,盲源分离算法在双麦克风阵列降噪处理上具有很好的应用前景。
4.虽然盲源分离算法在双麦降噪处理上可以取得较好的效果,但由于盲源分离算法只是将语音与噪声或者语音与干扰分离开,对于如何在盲源分离处理后提取目标语音仍是需要解决的难题。目前,对于目标语音的提取,主要的方法有基于目标声源的波达方向(direction of arrival,doa)、基于深度学习的训练、基于音视频融合等方法。但是对于双麦克风而言,由于其麦克风数量较少,空间指向性较弱,doa估计误差较大,使得利用doa的方法会使目标语音提取时信号频谱失真甚至无法提取到目标语音。而深度学习的方法存在对嵌入式系统的性能和资源要求较高,且需要大量数据训练模型,应用时泛化性能也会受限等缺点。
技术实现要素:
5.为克服现有方案技术存在的缺陷,本发明公开了一种基于双麦克风阵列的目标语音提取方法。
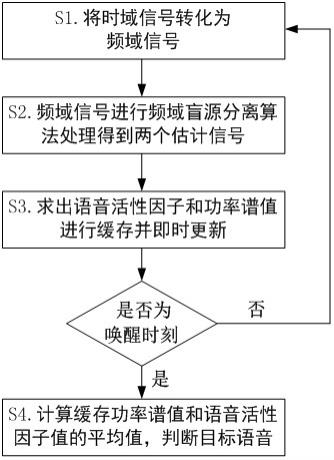
6.本发明所述基于双麦克风阵列的目标语音提取方法,包括如下步骤:s1.将两个麦克风接收的时域信号转化为频域信号;s2.然后对频域信号进行频域盲源分离算法处理;处理后得到两个不同估计信号y1(k,l)、y2(k,l);k为频点,l为帧数;s3.利用两个估计信号求出各自的帧语音活性因子和帧功率谱值,设置存储长度,在数据缓存区中即时逐帧缓存更新帧语音活性因子和帧功率谱值;s4.即时检验是否处于唤醒时刻,在唤醒时刻,计算数据缓存区中当前缓存的各帧
功率谱值和帧语音活性因子的均值,并以两个估计信号的平均功率谱值的比值和平均语音活性因子的差值综合比较,从估计信号中选择出目标语音;不在唤醒时刻则重复步骤s1至s3。
7.优选的,所述s3中帧语音活性因子的计算过程如下:s31.计算估计信号y
i
每个频点的频点功率谱,k为频点,l为帧数:频点功率谱 psd
i
=| y
i
(k,l)|
2 ,i表示不同的估计信号,s32.设置语音活性因子检测窗长度为l,设置窗内信号功率谱阈值最小值ε;然后根据每l帧长的检测窗不断更新ε,即psd
i,tmp
=min{ psd
i,1
,
…
,psd
i,l
}ε= min{ε, psd
i,tmp
}psd
i,1
,
…
,psd
i,l
表示窗内第1...l帧的频点功率谱,psd
i,tmp
为窗内信号功率谱最小值;s33.计算语音活性标志c(k,l),当符合以下任意一种情况时,c(k,l)=1,否则为零;在低频带,psd
i
>ε* m1,m1为低频带经验倍数,在高频带,psd
i
>ε* m2,m2为高频带经验倍数; s34.计算频点语音活性因子vaf
i
(k,l)为:vaf
i
(k,l)= α
p
*vaf
i
(k,l
‑
1)+(1
‑
α
p
)* c(k,l)其中α
p
为遗忘因子,i表示不同的估计信号。
8.s35.计算帧语音活性因子值 选取语音能量集中的频带计算累加语音活性因子,两个估计信号的帧语音活性因子为vaf_sum1和vaf_sum2;;其中:ks为累加计算点,1<ks <ka, ka为麦克风频域信号的采样点总数。
9.优选的,所述帧功率谱值计算过程如下:两个估计信号的帧功率谱值pow1和pow2通过下列公式计算:通过下列公式计算:其中:ks为累加计算点,1<ks <ka, ka为麦克风频域信号的采样点总数。
10.优选的:所述s1步骤具体为:s11.对时域信号做分帧加窗处理,设置每帧长度为k个采样点,采样率为fs;s12.进行分帧加窗处理后的时域信号进行端点识别处理,检测输入信号是否为语音信号,是则进入下一步骤s13,否则终止进程;
s13.对时域信号进行短时傅里叶变换,得到频域信号。
11.优选的,所述s4步骤中的综合比较具体为:定义: 功率谱值比值δ1=pow
2_mean
/pow
1_mean 语音活性因子差值δ2=vaf
2_mean
‑
vaf
1_mean
其中:其中:其中:其中:pow
1_mean
、pow
2_mean
分别表示数据缓存区存储的两个估计信号的帧功率谱值的平均值,vaf
1_mean
、vaf
2_mean
分别表示数据缓存区存储的两个估计信号的帧语音活性因子的平均值, vaf_sum
1,n
、vaf_sum 2,n
为两个估计信号的第n帧帧语音活性因子, pow
1,n
、pow 2,n
为两个估计信号的第n帧功率谱值,下标1、2表示不同的估计信号,n为数据缓存区中的不同帧数,n为数据缓存区的长度;对功率谱值比值δ1设置从高到低的第一比值阈值、第二比值阈值、第三比值阈值、第四比值阈值;对语音活性因子差值δ2设置从低到高的第一差值阈值、第二差值阈值,第三差值阈值;则如果属于下列五种情况之一时,认为目标语音信号y= y2(k,l),否则y= y1(k,l);y1(k,l)、y2(k,l)为s2步骤中的两个不同估计信号;
①
功率谱值比值δ1大于第一比值阈值;
②
语音活性因子差值δ2大于第三差值阈值;
③
功率谱值比值δ1小于第一比值阈值且大于第二比值阈值;且语音活性因子差值δ2大于零;
④
功率谱值比值δ1小于第二比值阈值且大于第三比值阈值;且语音活性因子差值δ2大于第一差值阈值;
⑤
功率谱值比值δ1小于第三比值阈值且大于第四比值阈值;且语音活性因子差值δ2大于第二差值阈值。
12.本发明所述目标语音提取方法,利用盲源分离算法能有效将目标人声和噪声分离开的优点,对盲源分离算法分离后的目标语音信号和噪声信号通过计算唤醒词语音段的语音活性因子值和功率谱值,并对语音活性因子值和功率谱值进行比较,提取出目标语音信号。该方法相对传统方法,不需要利用doa提供目标声源先验信息,且不需要采用深度学习训练大量数据提取,对系统资源要求降低。
附图说明
13.图1是本发明所述目标语音提取方法的一个具体实施方式示意图。
具体实施方式
14.下面对本发明的具体实施方式作进一步的详细说明。
15.本发明所述基于双麦克风阵列的目标语音提取方法,如图1所示,包括如下步骤:s1.将两个麦克风接收的时域信号转化为频域信号;s2.然后对频域信号进行频域盲源分离算法处理;处理后得到两个不同估计信号y1(k,l)、y2(k,l);s3.利用两个估计信号求出各自的帧语音活性因子和帧功率谱值,设置存储长度,在数据缓存区中即时逐帧缓存更新帧语音活性因子和帧功率谱值;s4.即时检验是否处于唤醒时刻,在唤醒时刻,计算数据缓存区中当前缓存的各帧功率谱值和帧语音活性因子的均值,并以两个估计信号的平均功率谱值的比值和平均语音活性因子的差值综合比较,从估计信号中选择出目标语音;不在唤醒时刻则重复步骤s1至s3。
16.以下进行更详细的说明。
17.将两个麦克风接收的时域信号转化为频域信号,假设双麦克风阵列中两个麦克风接收的时域信号分别为z1、z2;首先对两个时域信号z1、z2做分帧加窗处理,设置每帧长度为k个采样点。
18.进行分帧加窗处理后的时域信号进行端点识别(vad)处理,检测输入信号是否为语音信号,去除静音和不包含语音的噪声信号。端点识别方法可以是短时功率谱、短时幅度、短时平均过零率等判定方法中任意一种或几种方法的结合。
19.检测到语音信号起始端点后,对时域信号z1、z2进行短时傅里叶变换,得到频域信号x1(k,l) 、x2(k,l)。其中,k表示第k个时频点,l表示第l帧语音信号。
20.然后对频域信号x1(k,l) 、x2(k,l)进行频域盲源分离算法处理,得到分离后的两个不同估计信号分别为可能的目标语音估计信号和噪声估计信号,y1(k,l)、y2(k,l)。但此时无法确定y1(k,l)、y2(k,l)哪个是目标语音信号,哪个是噪声信号。常见的盲源分离算法有频域独立分量分析、频域独立向量分析以及基于辅助函数的独立向量分析算法等。
21.然后分别求两个估计信号y1(k,l)、y2(k,l)的帧语音活性因子和帧功率谱值。
22.估计信号的帧语音活性因子的计算过程为:s31.计算估计信号y
i
每个频点的频点功率谱,k为频点,l为帧数:频点功率谱 psd
i
=| y
i
(k,l)|
2 ,i表示不同的估计信号,s32.设置语音活性因子检测窗长度为l,设置窗内信号功率谱阈值最小值ε;然后根据每l帧长的检测窗不断更新ε,即psd
i,tmp
=min{ psd
i,1
,
…
,psd
i,l
}ε= min{ε, psd
i,tmp
}即时选择ε和psd
i,tmp
二者之间的较小值对ε进行更新, psd
i,tmp
ε初始值一般设置为零,l表示帧数;psd
i,1
,
…
,psd
i,l
表示第i个估计信号的窗内第1...l个频点功率谱,psd
i,tmp
为第i
个估计信号的窗内信号功率谱最小值;s33.计算语音活性标志c(k,l),当符合以下任意一种情况时,c(k,l)=1,否则为零;在低频带,psd
i
>ε* m1,m1为低频带经验倍数,在高频带,psd
i
>ε* m2,m2为高频带经验倍数;本实施例中,对语音信号,可以第50个频点为界线划分频带。
23.例如,设置低频带为第1
‑
50个频点,对应的低频带经验倍数m1=5,高频带为50
‑
256个频点,对应的高频带经验倍数m2=3.5。
24.s34.计算频点语音活性因子vaf
i
(k,l)为:vaf
i
(k,l)= α
p
*vaf
i
(k,l
‑
1)+(1
‑
α
p
)* c(k,l)其中α
p
为遗忘因子, 可设置α
p
=0.96, i表示不同的估计信号,在双麦克风阵列中,i=1或2。
25.s35.计算帧语音活性因子值 选取语音能量集中的频带计算累加语音活性因子,两个估计信号的帧语音活性因子为vaf_sum1和vaf_sum2;;其中:ks为累加计算点,1<ks <ka, ka为麦克风频域信号的采样点总数。语音信号能量集中的频带,学术上认为是在300
‑
3400hz。具体在本实施例中,可设置ks=100,考虑到男声低频较重,本实施例选取31.25hz到3150hz频带范围作为语音活性因子和功率谱值计算范围。
26.另外,两个估计信号的帧功率谱值pow1和pow2可通过下列公式计算:可通过下列公式计算:并将每帧信号得到的帧语音活性因子值vaf_sum1、vaf_sum2、帧功率谱值pow1、pow2分别存储在长度为n的数据缓存区中。n的长度设置可根据唤醒词的时间长度设置。如一个唤醒词有4个汉字,正常语速读完1秒,可以设置n=60。随着时间帧的增加,数据缓存区循环更新。
27.然后在循环更新过程中,即时根据语音识别系统的识别反馈,获取唤醒时刻。此时数据缓存区中存储的功率谱值和语音活性因子值为分离出的两个估计信号的连续多个帧功率谱值和帧语音活性因子值。
28.最后分别计算各个数据缓存区中存储的帧功率谱值和帧语音活性因子值的平均值,并以两个分离信号的平均功率谱值的比值和平均语音活性因子的差值综合比较,设置不同的阈值范围,根据功率谱值大和语音活性因子高的基本原则选择目标语音。
29.具体地,根据语音活性因子差值和功率谱值比值提取目标语音可按如下设置:定义: 功率谱值比值δ1=pow
2_mean
/pow
1_mean
语音活性因子差值δ2=vaf
2_mean
‑
vaf
1_mean
其中:其中:其中:其中:pow
1_mean
、pow
2_mean
分别表示数据缓存区存储的两个估计信号的帧功率谱值的平均值,vaf
1_mean
、vaf
2_mean
分别表示数据缓存区存储的两个估计信号的帧语音活性因子的平均值, vaf_sum
1,n
、vaf_sum 2,n
为两个估计信号的第n帧帧语音活性因子, pow
1,n
、pow 2,n
为两个估计信号的第n帧功率谱值,下标1、2表示不同的估计信号,n为数据缓存区中的不同帧数,n为数据缓存区的长度;对功率谱值比值δ1设置从高到低的第一比值阈值、第二比值阈值、第三比值阈值、第四比值阈值;对语音活性因子差值δ2设置从低到高的第一差值阈值、第二差值阈值,第三差值阈值;则属于下列五种情况之一时,认为目标语音信号y= y2(k,l):
①
功率谱值比值δ1大于第一比值阈值;
②
语音活性因子差值δ2大于第三差值阈值;
③
功率谱值比值δ1小于第一比值阈值且大于第二比值阈值;且语音活性因子差值δ2大于零;
④
功率谱值比值δ1小于第二比值阈值且大于第三比值阈值;且语音活性因子差值δ2大于第一差值阈值;
⑤
功率谱值比值δ1小于第三比值阈值且大于第四比值阈值;且语音活性因子差值δ2大于第二差值阈值;一个具体设置方式为:第一比值阈值、第二比值阈值、第三比值阈值、第四比值阈值分别为3、1.5、1.05,0.95;第一差值阈值、第二差值阈值、第三差值阈值分别为0.1、0.15、0.3。则目标语音信号y表达式为:同理,对上述设置的功率谱比值阈值取倒数及活性因子差值阈值取负数,同样满足以下五种情况之一时,认为目标语音信号y=y1(k,l):
上述阈值通常满足绝大部分应用场景,也可对阈值范围做相应改变。
30.上述目标语音提取的原理在于:由于语音信号在频谱上呈稀疏特性且又有能量较集中的频带,当原始带噪语音经盲源分离算法处理后,得到目标语音信号和噪声信号的估计信号。且这两个信号呈现出不同的信号特征,所以在语音信号能量较集中的频带范围内计算该频带范围内的累加能量,能表征一个信号是否为语音信号。
31.当两个估计信号中,一个估计信号的功率谱远远大于另一个估计信号功率谱时,此时无需考虑语音活性因子值的大小,可直接根据功率谱比值选取目标语音,如具体实施中设置δ1的第一比值阈值为3。
32.语音活性因子表征了各个频点能量分布差异程度,由于语音信号在频谱上呈稀疏特性,即语音信号在某些频点上能量较大,占主导地位,活性较强,在某些频点上能量较小,活性较弱。在语音信号能量较集中的频带范围内,大部分频点的能量都较强,活性因子值高。因此当两个估计信号中,一个估计信号的活性因子值远远大于另一个估计信号活性因子时,此时无需考虑功率谱值的大小,可直接根据活性因子值选取目标语音。如具体实施中设置δ2的第三差值阈值为0.3。
33.但在实际应用环境中,产品所处的信噪比范围变化较大。而不同的信噪比环境下,盲源分离算法的分离效果不同。总体来说,信噪比越高,分离效果越好。所以在高信噪比环境下,盲源分离算法几乎能将目标语音和噪声完全分离开,此时语音信号特征明显,只需一个语音信号特征即可选取出目标语音。但随着信噪比降低,盲源分离算法性能也随之降低,此时分离出两个估计信号,目标语音信号中会残留噪声信号,噪声信号中也会残留部分语音信号。在这样的情况下,若只用一个信号特征选取语音信号很可能错误选取,所以需要综合考虑功率谱比值和语音活性因子差值。即本发明采取分段函数形式,对功率谱比值和语音活性因子差值进一步设置阈值,以满足不同信噪比条件下的目标语音选取。
34.当功率谱比值不能满足情况
①
的显著优势,但值还较大时,如上述第二和第三比值阈值范围内,此时可考虑语音活性因子的差值范围,只需满足功率谱值大的信号,语音活性因子高即可。可归纳为情况
③
:功率谱值比值δ1小于第一比值阈值且大于第二比值阈值;且语音活性因子差值δ2大于零。
35.但当功率谱值比值进一步减小,甚至是相差不大,如第
④
、第
⑤
种情况小于第三比值阈值甚至小于第四比值阈值,此时就要考虑语音活性因子的大小,对其设置更严苛的阈值范围。
36.采用前述的具体实施方式和参数设置,进行语音提取,其中目标人声位于阵列90
°
方向,距离双麦克风阵列2米,说话声65
‑
70db。噪声位于阵列180
°
方向,距离双麦克风阵列1米,音响播放噪声。噪声类型为新闻噪声和音乐噪声55
‑
60db;按照本发明所述步骤s1至s4,根据唤醒词选取出目标语音后,对识别率的统计采用命令词识别方法,即统计99个命令词中能正确识别的词的个数、错误识别的个数及未能识别的个数,最终以正确识别率作为评估标准:
ꢀ
doa为先验信息的方法本发明提出的方法原始语音识别方法新闻噪声91.41%91.13%83.47%音乐噪声89.91%91.94%81.05%表1 正确识别率比较从上表可见,本发明提出的方法与以doa为先验信息的目标语音提取方法相比,正确识别率相差不大,且识别率远远高于不做降噪处理的原始语音识别率,说明本发明所述目标语音提取方法可正确选取目标语音。
37.通过本发明所述目标语音提取方法,利用盲源分离算法降噪性好的特点,对盲源分离算法分离后的两个信号通过语音活性因子和功率谱值综合比较,提取出目标语音信号。该方法相对传统方法,不需要利用doa提供目标声源先验信息,且不需要采用深度学习提取,对系统资源要求降低,并在信噪比(snr)较高情况如snr≥0db下能准确提取出目标语音。
38.前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书内容所作的等同结构变化,同理均应包含在本发明的保护范围内。