1.本发明属于语音合成技术领域,具体涉及一种基于可控最大熵自编码器的零样本语音风格迁移方法;
背景技术:
2.语音风格迁移(voice style transfer),其目标为给定源人物和目标人物的不同说话语音,使得源人物的说话内容以目标人物的语音风格说出;语音风格迁移是实现客制化人机交互的核心系统之一;其日益成为语音处理技术中的一个重要研究方向,有着极其重要的研究价值和现实应用基础;特别是任意人少样本情况下的语音风格迁移,在隐私和身份保护、创意产业、游戏、导航、读书以及悼念活动中有着可预估的良好应用;
3.当给定的目标人物的语音材料比较丰富时,语音风格迁移可以当作时传统语音合成的特例(语音合成的输入为文本,输出为语音;而语音风格迁移的输入和输出都为语音);传统的语音合成包括统计参数法和拼接法;其中,统计参数法根据统计模型建立文本到声学特征的映射,再利用这些声学特征还原其语音波形,通常此类方法合成的语音质量较低;拼接法事先录制好目标人物大量语音并对这些语音的内容进行标注,在合成时,通过文本内容选取对应语音,进对选取到的语音进行拼接,通常此类方法需要构建一个较为庞大的数据集,在具体使用时会有一定限制;
4.近年来,随着计算机硬件和深度学习的发展,很多人在语音合成领域做出了不错的工作;tacotron2和fastspeech是其中两个较为杰出的工作;然而它们解决的依旧是传统的语音合成问题;这就导致基于他们的方法不能很好的解决只有少量样本甚至零样本的语音风格迁移任务;最近,随着风格迁移(style transfer),生成对抗网络(generative adversarial nets)以及条件变分自编码器(conditional vibrational autoencoder)的提出及应用,越来越多的人将此类技术应用于语音风格迁移问题,然而这些在图片风格迁移问题上应用比较成功的方法在语音风格迁移问题上面临生成语音不够真实、需要成对数据(paired data)、训练复杂不可控、不能解决小样本(few
‑
shot)或零样本(zero
‑
shot)问题;
技术实现要素:
5.本发明的目的是为了解决上述背景技术中存在的不足;因此,提出了一种基于可控最大熵自编码器的零样本语音风格迁移方法用于合成风格语音;
6.为了实现上述目的,本发明所采用的技术方案为:
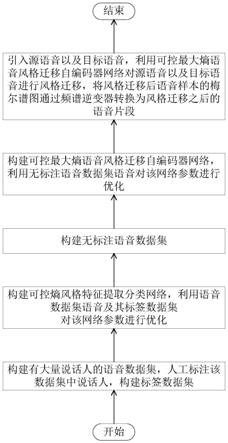
7.一种基于可控最大熵自编码器的零样本语音风格迁移方法,其特征在于,包括如下步骤:
8.步骤1:通过多个说话人的语音构建语音数据集,人工标注语音数据集中每段语音对应的说话人,将每段语音对应的说话人采用one
‑
hot的编码方式进行编码得到每段语音对应的标注标签,通过每段语音对应的标注标签构建标签数据集;
9.步骤2,构建可控熵风格特征提取分类网络,将语音数据集中每段语音通过语音信号梅尔谱图计算方法得到语音数据集中段语音对应的梅尔谱图,将每段语音对应的梅尔谱图依次输入至可控熵风格特征提取分类网络预测分类得到每段语音预测的说话人,结合标签数据集每段语音的说话人构建可控熵风格特征提取分类网络损失函数模型,进一步通过梯度反向传播法进行优化得到优化后可控熵风格特征提取分类网络;
10.步骤3:构建无标注语音数据集;
11.步骤4:构建可控最大熵语音风格迁移自编码器网络,将无标注语音数据集中每段语音通过语音信号梅尔谱图计算方法得到无标注语音中段语音对应的梅尔谱图,将每段无标注语音对应的梅尔谱图依次输入至可控最大熵语音风格迁移自编码器网络生成重构的语音梅尔谱图,结合相应的输入无标注语音中段语音对应的梅尔谱图构建可控最大熵语音风格迁移自编码器模型损失函数模型,进一步通过梯度反向传播法进行优化得到优化后可控最大熵语音风格迁移自编码器模型;
12.步骤5:引入源语音以及目标语音,将源语音以及目标语音分别通过梅尔谱图计算得到源语音对应的梅尔谱图、目标语音对应的梅尔谱图,将目标语音对应的梅尔谱图依次通过步骤2所述优化后的可控最大熵语音风格迁移自编码器网络的可控熵风格特征提取器、过步骤2所述可控最大熵语音风格迁移自编码器网络的语音风格采样器进行风格特征提取,得到目标语音对应的风格特征;将源语音通过步骤4所述优化后的可控最大熵语音风格迁移自编码器网络的可控熵内容特征提取器、步骤4所述优化后的可控最大熵语音风格迁移自编码器网络语音内容采样器,进行内容特征提取,得到源语音对应的内容特征;将目标语音对应的风格特征、源语音对应的内容特征通过步骤4所述优化后的可控最大熵语音风格迁移自编码器网络的解码器进行融合得到生成风格迁移后语音样本的梅尔谱图,将风格迁移后语音样本的梅尔谱图通过频谱逆变器转换为风格迁移之后的语音片段;
13.作为优选,步骤1所述语音数据集为:
14.s={x1,x2,...,x
n
}
[0015][0016]
其中,x
i
表示语音数据集中第i段语音,n表示语音数据集中语音段的数量,t
i
表示语音数据集中第i段语音中帧的数量,x
i,t
表示语音数据集中第i段语音中第t帧语音片段;
[0017]
步骤1所述标签数据集为:
[0018]
ys={y1,y2,...,y
n
}
[0019]
其中,y
i
标签数据集中第i段语音的说话人,n表示语音数据集中语音段的数量;
[0020]
作为优选,步骤2所述的语音数据集中每段语音对应的梅尔谱图为:
[0021][0022]
其中,表示语音数据集中第i段语音对应的梅尔谱图,n表示语音数据集中语音段的数量,i∈[1,n];
[0023]
步骤2所述的可控熵风格特征提取分类网络由可控熵风格特征提取器、语音风格特征采样器、说话人分类器串联级联构成;
[0024]
所述的可控熵风格特征提取器e
s
由第一长短期记忆网络、第二长短期记忆网络、
第一残差块、第二残差块、第二残差块依次串联级联构成;
[0025]
所述的第一残差块、第二残差块、第二残差块均由残差连接层、批归一化层、激活函数层依次串联级联构成;
[0026]
所述的语音风格特征采样模块由并联高斯分布采样器与并联狄拉克函数分布采样模块连接构成;
[0027]
所述并联高斯分布采样模块由第一高斯分布采样器、第二高斯分布采样器、...、第k高斯分布采样器依次并联构成;
[0028]
所述并联狄拉克函数分布采样模块由第一中心为零的狄拉克函数分布采样器、第二中心为零的狄拉克函数分布采样器、...、第k中心为零的狄拉克函数分布采样器依次并联构成;
[0029]
所述的说话人分类器由全连接层、softmax分类层串联级联构成;
[0030]
步骤2.1,所述可控熵风格特征提取器对语音数据集中第i段语音对应的梅尔谱图进行提取,得到语音数据集中第i段语音的k维风格特征均值向量、语音数据集中第i段语音的k维风格特征方差向量、语音数据集中第i段语音的k维风格特征的最大熵控调节参数向量;
[0031]
所述的可控熵风格特征提取器,具体计算过程为:
[0032][0033]
其中,e
s
表示可控熵风格特征提取器,为语音数据集中第i个语音片段对应的梅尔谱图,μ
s_i
表示语音数据集中第i个语音片段对应的k维风格特征均值向量,表示语音数据集中第i段语音的k维风格特征方差向量,γ
s_i
表示语音数据集中第i段语音的k维风格特征的最大熵控调节参数向量;
[0034]
步骤2.2,将步骤2.1中可控熵风格特征提取器输出的语音数据集中第i段语音的k维风格特征均值向量μ
s_i
、语音数据集中第i段语音的k维风格特征方差向量语音数据集中第i段语音的k维风格特征的最大熵控调节参数向量γ
s_i
,输入语音风格特征采样器进行多次采样,得到语音数据集中第i段语音的风格特征;
[0035]
所述多次采样描述为:
[0036][0037]
其中,j表示进行的采样次数,j表示第j次采样,k表示风格特征的维度,k表示风格特征的维度索引值,i表示语音数据集中的第i段语音,μ
s_ik
表示语音数据集中第i段语音的k维风格特征均值向量μ
s_i
的第k维,表示语音数据集中第i段语音的k维风格特征方差向量的第k维,γ
s_ik
表示语音数据集中第i段语音的k维风格特征的最大熵控调节参数向量γ
s_i
的第k维,表示针对数据集中的第i段语音,第j次对其风格特征的第k维,从一个均值为μ
s_ik
,方差为的高斯分布中采样得到s
ik_j
,δ(s
ik_j
)表示一个
中心为零的狄拉克函数(dirac delta function),f
s_i
表示语音数据集中第i段语音的风格特征;
[0038]
步骤2.3,将步骤2.2采样得到的语音数据集中第i段语音的风格特征输入说话人分类器中,预测语音数据集中第i段语音的说话人;
[0039]
所述的说话人分类器,具体计算过程为:
[0040][0041]
其中,c表示说话人分类器,f
s_i
表示语音数据集中第i段语音的风格特征,为预测的语音数据集中第i段语音对应说话人说话人标签的概率分布;
[0042]
步骤2所述构建可控熵风格特征提取分类网络损失函数模型为:
[0043]
l
cls
=λ
ce
*l
ce
+λ
cmhs
*l
cmhs
[0044][0045][0046][0047]
其中,l
ce
表示交叉熵损失函数,l
cmhs
表示可控最大熵风格约束损失,λ
ce
和λ
cmhs
表示交叉熵损失函数和可控最大熵风格约束损失的权重值,n表示语音数据集中语音段的数量,i表示语音数据集中语音段的序号,k表示语音风格特征的维度,k表示语音风格特征的维度索引值,y
i
表示语音数据集中第i段语音对应的说话人编码,为步骤2.3中提及的预测的说话人标签的概率分布,表示第i个语音片段风格特征的最大熵控调节参数的均值,γ
s_ik
表示步骤2.2提及的第i个语音片段风格特征的最大熵控调节参数的第k维,α表示人为设定的最大熵控调节参数;
[0048]
作为优选,步骤3所述无标注语音数据集为:
[0049]
as={a1,a2,...,a
n'
}
[0050]
a
i’=(a
i’,1
,a
i’,2
,...,a
i’,t’i
,)
[0051]
i
′
∈[1,n’]
[0052]
其中,a
i
’1表示语音数据集中第i
′
段语音,n’表示语音数据集中语音段的数量,t’i
表示语音数据集中第i
′
段语音中帧的数量,a
i’,t’表示语音数据集中第i
′
段语音中第t’帧语音片段;
[0053]
作为优选,步骤4中所述无标注语音数据集中每段语音对应的梅尔谱图为:
[0054][0055]
其中,表示无标注语音数据集中第i
′
段语音对应的梅尔谱图,n’表示语音数据集中语音段的数量,i
′
∈[1,n’];
[0056]
步骤4所述可控最大熵语音风格迁移自编码器网络由步骤2所述优化后可控熵风格特征提取分类网络的可控熵风格特征提取器、步骤2所述优化后可控熵风格特征提取分类网络的语音风格特征采样器、可控熵内容特征提取器、语音内容特征采样器、语音特征解码器构成;
[0057]
步骤2所述优化后可控熵风格特征提取分类网络的可控熵风格特征提取器与语音风格特征采样器串联后,进一步与所述可控熵内容特征提取器和所述语音内容特征采样器串联后并联,再与语音特征解码器依次串联级联构成;
[0058]
所述的可控熵内容特征提取器由第一内容残差块、第二内容残差块、第三内容残差块、第四内容残差块、第五内容残差块、第一内容双向长短期记忆网络、第二内容双向长短期记忆网络、第三内容双向长短期记忆网络依次串联级联构成;
[0059]
所述的第一内容残差块、第二内容残差块、第三内容残差块、第四内容残差块、第五内容残差块均由残差连接层、批归一化层、激活函数层依次串联级联构成;
[0060]
所述的语音内容特征采样器由并联内容高斯分布采样模块与并联内容狄拉克函数分布采样模块连接构成;
[0061]
所述并联内容高斯分布采样器由第一内容高斯分布采样器、第二内容高斯分布采样器、...、第d内容高斯分布采样器依次并联构成;
[0062]
所述并联内容狄拉克函数分布采样模块由第一中心为零的内容狄拉克函数分布采样器、第二中心为零的内容狄拉克函数分布采样器、...、第d中心为零的内容狄拉克函数分布采样器依次并联构成;
[0063]
所述的语音特征解码器由第一级联层,第一解码残差块、第二解码残差块、第三解码残差块,第一解码双向长短期记忆网络、第二解码双向长短期记忆网络、第三解码双向长短期记忆网络,第一卷积块、第二卷积块依次串联级联构成;
[0064]
第一解码残差块、第二解码残差块、第三解码残差块均由残差连接层、批归一化层、激活函数层依次串联级联构成;
[0065]
所述的第一卷积块、第二卷积块均由卷积层、批归一化、激活函数依次串联级联构成;
[0066]
步骤4.1,固定步骤2所述的可控熵风格特征提取分类网络的参数,步骤2所述优化后可控熵风格特征提取分类网络的可控熵风格特征提取器按照步骤2.1所述方法对无标注语音数据集中第i
′
段语音对应的梅尔谱图进行提取,得到无标注语音数据集中第i
′
段语音的k维内容特征均值向量、无标注语音数据集中第i
′
段语音的k维内容特征方差向量、无标注语音数据集中第i
′
段语音的k维内容特征的最大熵控调节参数向量;进一步将上述得到无标注语音数据集中第i
′
段语音的k维内容特征均值向量、无标注语音数据集中第i
′
段语音的k维内容特征方差向量、无标注语音数据集中第i
′
段语音的k维内容特征的最大熵控调节参数向量通过步骤2所述优化后可控熵风格特征提取分类网络的语音风格特征采样器采样得到无标注语音数据集中第i
′
段语音对应的风格特征:f
s_i
′
,其中i
′
∈[1,n’],n’表示无标注语音数据集中语音段的数量;
[0067]
步骤4.2,所述可控熵内容特征提取器对无标注语音数据集中第i
′
段语音对应的梅尔谱图进行提取,得到无标注语音数据集中第i
′
段语音的d维内容特征均值向量、无标注语音数据集中第i
′
段语音的d维内容特征方差向量、无标注语音数据集中第i
′
段语音的d维
内容特征的最大熵控调节参数向量;
[0068]
所述可控熵内容特征提取器,具体计算过程为:
[0069][0070]
其中,ec表示可控熵内容特征提取器,为无标注语音数据集中第i
′
段语音片段对应的梅尔谱图,μ
c_i
′
表示无标注语音数据集中第i
′
段语音片段对应的d维内容特征均值向量,表示无标注语音数据集中第i
′
段语音的d维内容特征方差向量,γ
c_i
′
表示无标注语音数据集中第i
′
段语音的d维内容特征的最大熵控调节参数向量;
[0071]
步骤4.3,将步骤4.2中可控熵内容特征提取器输出的无标注语音数据集中第i
′
段语音的d维内容特征均值向量μ
c_i
′
、无标注语音数据集中第i
′
段语音的d维内容特征方差向量无标注语音数据集中第i
′
段语音的d维内容特征的最大熵控调节参数向量γ
c_i
′
,输入语音内容特征采样器进行多次采样,得到无标注语音数据集中第i
′
段语音的内容特征;
[0072]
其采样过程可形式化描述为:
[0073][0074]
其中,j表示进行的采样次数,j表示第j次采样,d表示内容特征的维度,d表示内容特征的维度索引值,i
′
表示无标注语音数据集中的第i
′
段语音,μ
c_i
′
d
表示无标注语音数据集中第i
′
段语音的d维内容特征均值向量μ
c_i
′
的第d维,表示无标注语音数据集中第i
′
段语音的d维内容特征方差向量的第d维,γ
c_i
′
d
表示无标注语音数据集中第i
′
段语音的d维内容特征的最大熵控调节参数向量γ
c_i
′
的第d维,表示针对无标注数据集中的第i
′
段语音,第j次对其内容特征的第d维,从一个均值为μ
c_i
′
d
,方差为的高斯分布中采样得到c
i
′
d_j
,δ(c
i
′
d_j
)表示一个中心为零的狄拉克函数(dirac delta function),f
c_i
′
表示无标注语音数据集中第i
′
段语音的内容特征;
[0075]
步骤4.4,所述语音特征解码器将步骤4.1所得的无标注语音数据集中第i
′
段语音对应的风格特征f
s_i
′
和步骤4.3所得的无标注语音数据集中第i
′
段语音对应的内容特征f
c_i
′
解码重构为无标注语音数据集中第i
′
段语音对应的梅尔谱图;
[0076]
所述语音特征解码器,具体计算过程为:
[0077][0078]
其中,d表示语音特征解码器,表示无标注语音数据集中第i
′
段语音对应的风格特征,表示无标注语音数据集中第i
′
段语音对应的内容特征,表示重构出来的无标注语音数据集中第i
′
段语音对应的梅尔谱图;
[0079]
步骤4所构建的可控最大熵语音风格迁移自编码器模型损失函数模型为:
[0080]
l
res
=λ2*l2+λλ
cmhc
*l
cmhc
[0081][0082][0083][0084]
其中,l2表示l2范数损失,l
cmhc
表示可控最大熵内容约束损失,λ2和λ
cmhc
表示l2范数损失函数和可控最大熵内容约束损失的权重值,n’表示无标注语音数据集中语音样本的个数,i
′
表示无标注语音数据集中第i
′
段语音,d表示内容特征的维度,d表示内容特征的维度索引值,表示无标注语音数据集中第i
′
段语音对应的梅尔谱图,为步骤4.4中提及的重构出的无标注语音数据集中第i
′
段语音对应的梅尔谱图,表示第i
′
个语音片段内容特征的最大熵控调节参数的均值,γ
c_i
′
d
表示步骤4.2提及的无标注语音数据集中第i
′
段语音对应内容特征的最大熵控调节参数的第d维,β表示人为设定的最大熵控调节参数;
[0085]
本发明的有益效果在于:本发明利用了可控最大熵自编码器,训练过程不涉及对抗过程,仅有一个自监督重构和一个可控最大熵调节的约束,训练简单,易于收敛;由于使用了两个目的不同的可控最大熵自编码器,实现了风格特征和内容特征的解耦,可以解决目标人物历史数据缺失等零样本、少样本语音风格迁移任务;本方案仅使用自监督的过程便可以实现风格迁移,故不需要构造成对数据集,可以节约成本;模型本身不涉及音素提取,说话内容识别等,故不仅可以用来生成英语、汉语,还能够生成其他各种语言,其中风格包括但不限于说话人音色、语调、重音、节奏、语速、口音、表达情感方式等;在给定目标人物数据的情况下,模型可以进行微调,以提高风格迁移的性能;实验证明,生成的语音效果无论是定性的评价还是定量的评价都表现的之前的方法更好;
附图说明
[0086]
图1:为本发明的实施例流程图;
[0087]
图2:为本发明模型的网络结构示意图;
具体实施方式
[0088]
为了更清楚地说明本发明和/或现有技术中的技术方案,下面将对照附图说明本发明的具体实施方式;显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式;
[0089]
如图1所示,一种基于可控最大熵自编码器的零样本语音风格迁移方法,该方法主要包括如下步骤:
[0090]
步骤1:通过多个说话人的语音构建语音数据集,人工标注语音数据集中每段语音
对应的说话人,将每段语音对应的说话人采用one
‑
hot的编码方式进行编码得到每段语音对应的标注标签,通过每段语音对应的标注标签构建标签数据集;
[0091]
步骤1所述语音数据集为:
[0092]
s={x1,x2,...,x
n
}
[0093][0094]
其中,x
i
表示语音数据集中第i段语音,n=10000表示语音数据集中语音段的数量,t
i
=25表示语音数据集中第i段语音中帧的数量,x
i,t
表示语音数据集中第i段语音中第t帧语音片段;
[0095]
步骤1所述标签数据集为:
[0096]
ys={y1,y2,...,y
n
}
[0097]
其中,y
i
标签数据集中第i段语音的说话人,n=10000表示语音数据集中语音段的数量;
[0098]
步骤2,构建可控熵风格特征提取分类网络,将语音数据集中每段语音通过语音信号梅尔谱图计算方法得到语音数据集中段语音对应的梅尔谱图,将每段语音对应的梅尔谱图依次输入至可控熵风格特征提取分类网络预测分类得到每段语音预测的说话人,结合标签数据集每段语音的说话人构建可控熵风格特征提取分类网络损失函数模型,进一步通过梯度反向传播法进行优化得到优化后可控熵风格特征提取分类网络;
[0099]
步骤2所述的语音数据集中每段语音对应的梅尔谱图为:
[0100][0101]
其中,表示语音数据集中第i段语音对应的梅尔谱图,n=10000表示语音数据集中语音段的数量,i∈[1,n];
[0102]
步骤2所述的可控熵风格特征提取分类网络由可控熵风格特征提取器、语音风格特征采样器、说话人分类器串联级联构成;
[0103]
所述的可控熵风格特征提取器e
s
由第一长短期记忆网络、第二长短期记忆网络、第一残差块、第二残差块、第二残差块依次串联级联构成;
[0104]
所述的第一残差块、第二残差块、第二残差块均由残差连接层、批归一化层、激活函数层依次串联级联构成;
[0105]
所述的语音风格特征采样模块由并联高斯分布采样器与并联狄拉克函数分布采样模块连接构成;
[0106]
所述并联高斯分布采样模块由第一高斯分布采样器、第二高斯分布采样器、...、第100(k=100)高斯分布采样器依次并联构成;
[0107]
所述并联狄拉克函数分布采样模块由第一中心为零的狄拉克函数分布采样器、第二中心为零的狄拉克函数分布采样器、...、第100(k=100)中心为零的狄拉克函数分布采样器依次并联构成;
[0108]
所述的说话人分类器由全连接层、softmax分类层串联级联构成;
[0109]
步骤2.1,所述可控熵风格特征提取器对语音数据集中第i段语音对应的梅尔谱图进行提取,得到语音数据集中第i段语音的k=100维风格特征均值向量、语音数据集中第i
段语音的k=100维风格特征方差向量、语音数据集中第i段语音的k=100维风格特征的最大熵控调节参数向量;
[0110]
所述的可控熵风格特征提取器,具体计算过程为:
[0111][0112]
其中,e
s
表示可控熵风格特征提取器,为语音数据集中第i个语音片段对应的梅尔谱图,μ
s_i
表示语音数据集中第i个语音片段对应的k=100维风格特征均值向量,表示语音数据集中第i段语音的k=100维风格特征方差向量,γ
s_i
表示语音数据集中第i段语音的k=100维风格特征的最大熵控调节参数向量;
[0113]
步骤2.2,将步骤2.1中可控熵风格特征提取器输出的语音数据集中第i段语音的k=100维风格特征均值向量μ
s_i
、语音数据集中第i段语音的k=100维风格特征方差向量语音数据集中第i段语音的k=100维风格特征的最大熵控调节参数向量γ
s_i
,输入语音风格特征采样器进行多次采样,得到语音数据集中第i段语音的风格特征;
[0114]
所述多次采样描述为:
[0115][0116]
其中,j=10表示进行的采样次数,j表示第j次采样,k=100表示风格特征的维度,k表示风格特征的维度索引值,i表示语音数据集中的第i段语音,μ
s_ik
表示语音数据集中第i段语音的k=100维风格特征均值向量μ
s_i
的第k维,表示语音数据集中第i段语音的k=100维风格特征方差向量的第k维,γ
s_ik
表示语音数据集中第i段语音的k=100维风格特征的最大熵控调节参数向量γ
s_i
的第k维,定示针对数据集中的第i段语音,第j次对其风格特征的第k维,从一个均值为μ
s_ik
,方差为的高斯分布中采样得到s
ik_j
,δ(s
ik_j
)表示一个中心为零的狄拉克函数(dirac delta function),f
s_i
表示语音数据集中第i段语音的风格特征;
[0117]
步骤2.3,将步骤2.2采样得到的语音数据集中第i段语音的风格特征输入说话人分类器中,预测语音数据集中第i段语音的说话人;
[0118]
所述的说话人分类器,具体计算过程为:
[0119][0120]
其中,c表示说话人分类器,f
s_i
表示语音数据集中第i段语音的风格特征,为预测的语音数据集中第i段语音对应说话人说话人标签的概率分布;
[0121]
步骤2所述构建可控熵风格特征提取分类网络损失函数模型为:
[0122]
l
cls
=λ
ce
*l
ce
+λ
cmhs
*l
cmhs
[0123][0124][0125][0126]
其中,l
ce
表示交叉熵损失函数,l
cmhs
表示可控最大熵风格约束损失,λ
ce
=0.5和λ
cmhs
=0.5表示交叉熵损失函数和可控最大熵风格约束损失的权重值,n=10000表示语音数据集中语音段的数量,i表示语音数据集中语音段的序号,k=100表示语音风格特征的维度,k表示语音风格特征的维度索引值,y
i
表示语音数据集中第i段语音对应的说话人编码,为步骤2.3中提及的预测的说话人标签的概率分布,表示第i个语音片段风格特征的最大熵控调节参数的均值,γ
s_ik
表示步骤2.2提及的第i个语音片段风格特征的最大熵控调节参数的第k维,α=0.2表示人为设定的最大熵控调节参数;
[0127]
步骤3:构建无标注语音数据集;
[0128]
步骤3所述无标注语音数据集为:
[0129]
as={a1,a2,...,a
n'
}
[0130]
a
i’=(a
i',1
,a
i',2
,...,a
i’,t’i
,)
[0131]
i
′
∈[1,n’]
[0132]
其中,a
i'1
表示语音数据集中第i
′
段语音,n'=20000表示语音数据集中语音段的数量,t'
i
=25表示语音数据集中第i
′
段语音中帧的数量,a
i’,t’表示语音数据集中第i
′
段语音中第t’帧语音片段;
[0133]
步骤4:构建可控最大熵语音风格迁移自编码器网络,将无标注语音数据集中每段语音通过语音信号梅尔谱图计算方法得到无标注语音中段语音对应的梅尔谱图,将每段无标注语音对应的梅尔谱图依次输入至可控最大熵语音风格迁移自编码器网络生成重构的语音梅尔谱图,结合相应的输入无标注语音中段语音对应的梅尔谱图构建可控最大熵语音风格迁移自编码器模型损失函数模型,进一步通过梯度反向传播法进行优化得到优化后可控最大熵语音风格迁移自编码器模型,如图2所示。
[0134]
步骤4中所述无标注语音数据集中每段语音对应的梅尔谱图为:
[0135][0136]
其中,表示无标注语音数据集中第i
′
段语音对应的梅尔谱图,n'=20000表示语音数据集中语音段的数量,i
′
∈[1,n’];
[0137]
步骤4所述可控最大熵语音风格迁移自编码器网络由步骤2所述优化后可控熵风格特征提取分类网络的可控熵风格特征提取器、步骤2所述优化后可控熵风格特征提取分类网络的语音风格特征采样器、可控熵内容特征提取器、语音内容特征采样器、语音特征解码器构成;
[0138]
步骤2所述优化后可控熵风格特征提取分类网络的可控熵风格特征提取器与语音风格特征采样器串联后,进一步与所述可控熵内容特征提取器和所述语音内容特征采样器串联后并联,再与语音特征解码器依次串联级联构成;
[0139]
所述的可控熵内容特征提取器由第一内容残差块、第二内容残差块、第三内容残差块、第四内容残差块、第五内容残差块、第一内容双向长短期记忆网络、第二内容双向长短期记忆网络、第三内容双向长短期记忆网络依次串联级联构成;
[0140]
所述的第一内容残差块、第二内容残差块、第三内容残差块、第四内容残差块、第五内容残差块均由残差连接层、批归一化层、激活函数层依次串联级联构成;
[0141]
所述的语音内容特征采样器由并联内容高斯分布采样模块与并联内容狄拉克函数分布采样模块连接构成;
[0142]
所述并联内容高斯分布采样器由第一内容高斯分布采样器、第二内容高斯分布采样器、...、第200(d=200)内容高斯分布采样器依次并联构成;
[0143]
所述并联内容狄拉克函数分布采样模块由第一中心为零的内容狄拉克函数分布采样器、第二中心为零的内容狄拉克函数分布采样器、...、第200(d=200)中心为零的内容狄拉克函数分布采样器依次并联构成;
[0144]
所述的语音特征解码器由第一级联层,第一解码残差块、第二解码残差块、第三解码残差块,第一解码双向长短期记忆网络、第二解码双向长短期记忆网络、第三解码双向长短期记忆网络,第一卷积块、第二卷积块依次串联级联构成;
[0145]
第一解码残差块、第二解码残差块、第三解码残差块均由残差连接层、批归一化层、激活函数层依次串联级联构成;
[0146]
所述的第一卷积块、第二卷积块均由卷积层、批归一化、激活函数依次串联级联构成;
[0147]
步骤4.1,固定步骤2所述的可控熵风格特征提取分类网络的参数,步骤2所述优化后可控熵风格特征提取分类网络的可控熵风格特征提取器按照步骤2.1所述方法对无标注语音数据集中第i
′
段语音对应的梅尔谱图进行提取,得到无标注语音数据集中第i
′
段语音的k=100维内容特征均值向量、无标注语音数据集中第i
′
段语音的k=100维内容特征方差向量、无标注语音数据集中第i
′
段语音的k=100维内容特征的最大熵控调节参数向量;进一步将上述得到无标注语音数据集中第i
′
段语音的k=100维内容特征均值向量、无标注语音数据集中第i
′
段语音的k=100维内容特征方差向量、无标注语音数据集中第i
′
段语音的k=100维内容特征的最大熵控调节参数向量通过步骤2所述优化后可控熵风格特征提取分类网络的语音风格特征采样器采样得到无标注语音数据集中第i
′
段语音对应的风格特征:f
s_i
′
,其中i
′
∈[1,n’],n=20000表示无标注语音数据集中语音段的数量;
[0148]
步骤4.2,所述可控熵内容特征提取器对无标注语音数据集中第i
′
段语音对应的梅尔谱图进行提取,得到无标注语音数据集中第i
′
段语音的d=200维内容特征均值向量、无标注语音数据集中第i
′
段语音的d=200维内容特征方差向量、无标注语音数据集中第i
′
段语音的d=200维内容特征的最大熵控调节参数向量;
[0149]
所述可控熵内容特征提取器,具体计算过程为:
[0150]
[0151]
其中,e
c
表示可控熵内容特征提取器,为无标注语音数据集中第i
′
段语音片段对应的梅尔谱图,μ
c_i
′
表示无标注语音数据集中第i
′
段语音片段对应的d=200维内容特征均值向量,表示无标注语音数据集中第i
′
段语音的d=200维内容特征方差向量,γ
c_i
′
表示无标注语音数据集中第i
′
段语音的d=200维内容特征的最大熵控调节参数向量;
[0152]
步骤4.3,将步骤4.2中可控熵内容特征提取器输出的无标注语音数据集中第i
′
段语音的d=200维内容特征均值向量μ
c_i
′
、无标注语音数据集中第i
′
段语音的d=200维内容特征方差向量无标注语音数据集中第i
′
段语音的d=200维内容特征的最大熵控调节参数向量γ
c_i
′
,输入语音内容特征采样器进行多次采样,得到无标注语音数据集中第i
′
段语音的内容特征;
[0153]
其采样过程可形式化描述为:
[0154][0155]
其中,j=10表示进行的采样次数,j表示第j次采样,d=200表示内容特征的维度,d表示内容特征的维度索引值,i
′
表示无标注语音数据集中的第i
′
段语音,μ
c_i
′
d
表示无标注语音数据集中第i
′
段语音的d=200维内容特征均值向量μ
c_i
′
的第d维,表示无标注语音数据集中第i
′
段语音的d=200维内容特征方差向量的第d维,γ
c_i
′
d
表示无标注语音数据集中第i
′
段语音的d=200维内容特征的最大熵控调节参数向量γ
c_i
′
的第d维,表示针对无标注数据集中的第i
′
段语音,第j次对其内容特征的第d维,从一个均值为μ
c_i
′
d
,方差为的高斯分布中采样得到c
i
′
d_j
,δ(c
i
′
d_j
)表示一个中心为零的狄拉克函数(dirac delta function),f
c_i
′
表示无标注语音数据集中第i
′
段语音的内容特征;
[0156]
步骤4.4,所述语音特征解码器将步骤4.1所得的无标注语音数据集中第i
′
段语音对应的风格特征f
s_i
′
和步骤4.3所得的无标注语音数据集中第i
′
段语音对应的内容特征f
c_i
′
解码重构为无标注语音数据集中第i
′
段语音对应的梅尔谱图;
[0157]
所述语音特征解码器,具体计算过程为:
[0158][0159]
其中,d表示语音特征解码器,表示无标注语音数据集中第i
′
段语音对应的风格特征,表示无标注语音数据集中第i
′
段语音对应的内容特征,表示重构出来的无标注语音数据集中第i
′
段语音对应的梅尔谱图;
[0160]
步骤4所构建的可控最大熵语音风格迁移自编码器模型损失函数模型为:
[0161]
l
res
=λ2*l2+λ
cmhc
*l
cmhc
[0162][0163][0164][0165]
其中,l2表示l2范数损失,l
cmhc
表示可控最大熵内容约束损失,λ2=0.5和λ
cmhc
=0.5表示l2范数损失函数和可控最大熵内容约束损失的权重值,n'=20000表示无标注语音数据集中语音样本的个数,i
′
表示无标注语音数据集中第i
′
段语音,d=200表示内容特征的维度,d表示内容特征的维度索引值,表示无标注语音数据集中第i
′
段语音对应的梅尔谱图,为步骤4.4中提及的重构出的无标注语音数据集中第i
′
段语音对应的梅尔谱图,表示第i
′
个语音片段内容特征的最大熵控调节参数的均值,γ
c_i
′
d
表示步骤4.2提及的无标注语音数据集中第i
′
段语音对应内容特征的最大熵控调节参数的第d维,β=0.5表示人为设定的最大熵控调节参数;
[0166]
步骤5:引入源语音以及目标语音,将源语音以及目标语音分别通过梅尔谱图计算得到源语音对应的梅尔谱图、目标语音对应的梅尔谱图,将目标语音对应的梅尔谱图依次通过步骤2所述优化后的可控最大熵语音风格迁移自编码器网络的可控熵风格特征提取器、过步骤2所述可控最大熵语音风格迁移自编码器网络的语音风格采样器进行风格特征提取,得到目标语音对应的风格特征;将源语音通过步骤4所述优化后的可控最大熵语音风格迁移自编码器网络的可控熵内容特征提取器、步骤4所述优化后的可控最大熵语音风格迁移自编码器网络语音内容采样器,进行内容特征提取,得到源语音对应的内容特征;将目标语音对应的风格特征、源语音对应的内容特征通过步骤4所述优化后的可控最大熵语音风格迁移自编码器网络的解码器进行融合得到生成风格迁移后语音样本的梅尔谱图,将风格迁移后语音样本的梅尔谱图通过频谱逆变器转换为风格迁移之后的语音片段;
[0167]
应当理解的是,本说明书未详细阐述的部分均属于现有技术;
[0168]
应当理解的是,上述针对较佳实施例的描述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。