1.本发明属于麦克风阵列拾音领域,涉及一种基于麦克风阵列的拾音方法、拾音装置及存储介质。
背景技术:
2.在复杂的声学环境中,背景噪声、干扰以及混响等因素都会恶化麦克风的拾音性能,降低语音的清晰度和可懂度,导致单麦克风拾音无法满足日常需求。相比于单麦克风拾音效果,结合波束形成算法的麦克风阵列可以通过融合空时信息,增强来自目标方向的信号,抑制非目标方向信号增益,提高输出语音的信噪比,提升语音质量,因此被广泛应用于语音增强和语音识别等领域。
3.差分波束形成设计算法具有孔径小、指向性指数高等优点,且可以实现宽带恒定波束宽度,有效降低语音失真度,因此在众多固定波束形成设计算法获得了广泛关注。但是其滤波器响应存在白噪声放大的问题,从而导致系统对麦克风的自噪声、不匹配等不可避免的误差较为敏感,在实际中性能会极度恶化。
技术实现要素:
4.本发明的目的是提供一种麦克风阵列的拾音方法,具有较好的抗干扰性,尤其是在低频处仍有较好的指向性,失真度低。
5.本发明的另一个目的是提供一种拾音装置,其尺寸较小,具有较好的抗干扰性,失真度低。
6.本发明的又一个目的是提供一种计算机可读存储介质,其存储有上述的麦克风阵列的拾音方法。
7.根据本发明的第一个方面,一种基于麦克风阵列的拾音方法,包括如下步骤:
8.a、确定麦克风阵列,所述麦克风阵列具有多个麦克风通道,每个所述麦克风通道包括至少一个麦克风单元;
9.b、建立误差概率模型如下,
[0010][0011]
其中,
[0012]
表示实际导向矢量;
[0013]
理想导向矢量其中,θ为平面波传播方向,δ为相邻麦克风阵列单元的间距,τ0=δ/c为0度方向平面波到达相邻两个麦克风单元的延时,c为声传播速度,j为虚指数,ω为角频率;
⊙
表示元素点乘;
[0014]
a
mul
(ω)表示随机乘性误差,其大小为m
×
1,m表示麦克风通道的数量,其中第m个元素为表示乘性误差幅度,表示乘性误差相位;
[0015]
a
add
(ω)表示随机加性误差,其大小为m
×
1,其中第m个元素为
表示加性误差幅度,表示加性误差相位;
[0016]
c、构建基于所述误差概率模型的差分波束设计算法的最优问题;
[0017]
d、求解上述最优问题的最优解,得到所述麦克风阵列的多个麦克风通道的权重向量;
[0018]
e、根据所述权重向量对所述麦克风阵列采集的语音信号进行调整,输出优化后的语音信号。
[0019]
根据一优选的实施例,步骤c中,所述最优问题表达如下:
[0020][0021]
其中,e{}为求期望平均值,h(ω)=[h1(ω),h2(ω),
…
,h
m
(ω)]
t
为所述权重向量,第m个麦克风通道的权重上标*和h分别表示共轭和共轭转置,α=[θ
n,1
,
…
,θ
n,n
]
t
为n个零点位置向量,定义如下:
[0022][0023]
其中,元素表示依据式(i)获得的零点位置θ
n,1
的实际导向矢量,n满足m≥n+1;其他元素以此类推。
[0024]
更优选地,步骤d中,所述最优解为:
[0025]
h
opt
(ω)=r
‑1(ω)c
h
(ω)[c(ω)r
‑1(ω)c
h
(ω)]
‑1[0026]
r(ω)和c(ω)的定义分别为
[0027]
r(ω)=(d
h
(ω,α)d(ω,α))
⊙
r1+n*r2+r3;
[0028]
其中,
[0029][0030][0031]
[0032][0033]
re{}为取元素实部操作,
[0034]
为乘性误差幅度平方的期望值为乘性误差幅度的期望值
[0035][0036][0037]
为加性误差幅度平方的期望值为加性误差幅度的期望值
[0038][0039][0040]
和分别表示乘性误差幅度和相位的概率密度分布函数,和分别表示加性误差幅度和相位的概率密度分布函数,d(a
mul
(ω))表示a
mul
(ω)的微分,d(φ
mul
(ω))表示φ
mul
(ω)的微分,d(a
add
(ω))表示a
add
(ω)的微分,d(φ
add
(ω))表示φ
add
(ω)的微分,
[0041]
d
n,m
(ω,α)表示为矩阵d(ω,α)下标为(n,m)处的元素,n=1,
…
,n,m=1,
…
,m。
[0042]
根据一优选的实施例,所述乘性误差的幅度和相位的内部概率密度分布函数一致,和/或,所述加性误差的幅度和相位的内部概率密度分布函数一致。
[0043]
根据一优选的实施例,所述乘性误差的幅度和相位的内部概率密度分布函数一致及所述加性误差的幅度和相位的内部概率密度分布函数一致通过建模或实际测量获取。
[0044]
根据一优选的实施例,步骤a中,所述麦克风单元均匀线性排布构成线性麦克风阵列。
[0045]
更优选地,确定n个零点位置向量α=[θ
n,1
,
…
,θ
n,n
]
t
,上标t为转置,且零点位置需满足0<θ
n,1
<θ
n,2
<
…
<θ
n,n
<180,而个数需满足条件m≥n+1,期望目标方向为0度方向。
[0046]
根据一优选的实施例,步骤e中,将所述麦克风阵列采集的信号转换至频域,与所述权重向量相乘后叠加,然后通过逆傅里叶变换转换为时域输出优化后的语音信号。
[0047]
根据本发明的第二个方面,一种拾音装置,包括麦克风阵列、数模转换机构及信号处理机构,所述信号处理机构包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上所述的拾音方法。
[0048]
根据本发明的第三个方面,一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储有计算机程序,该程序被处理器执行时实现如上所述的拾音方法。
[0049]
本发明采用以上方案,相比现有技术具有如下优点:
[0050]
本发明的基于麦克风阵列的拾音方法,采用基于误差概率模型的零点能量约束的差分设计算法,通过对麦克风的自噪声、不匹配等误差进行概率建模,对期望值进行最优化,可以进一步提升算法的抗干扰性能,尤其是在低频处仍有较好的指向性效果,抗干扰性能较强,频响较平坦,失真度低,还具有较好的鲁棒性;同时,采用此方法的拾音装置尺寸较小,保持较好的指向性,便于安装。
附图说明
[0051]
为了更清楚地说明本发明的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
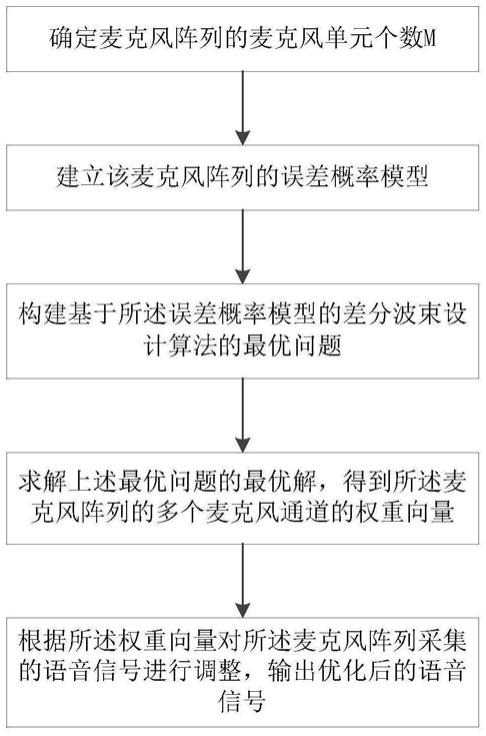
[0052]
图1为根据本发明实施例的一种拾音方法的流程图;
[0053]
图2为根据本发明实施例的麦克风阵列的示意图;
[0054]
图3a和图3b分别为本发明实施例的拾音方法的白噪声增益曲线图和0度方向的平均期望频响曲线图;
[0055]
图4a和图4b分别示出了两种算法的500hz和3000hz的平均期望波束图案;
[0056]
图5为根据本发明实施例的拾音装置的结构框图。
具体实施方式
[0057]
下面结合附图对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域的技术人员理解。在此需要说明的是,对于这些实施方式的说明用于帮助理解本发明,但并不构成对本发明的限定。
[0058]
本实施例提出一种麦克风阵列的拾音方法,其采用基于误差概率模型零点能量约束的差分设计算法,此算法通过对麦克风的自噪声、不匹配等误差进行概率建模,对期望值进行最优化,可以进一步提升算法的抗干扰性能。如图1所示,该拾音方法包括:步骤a、确定麦克风阵列,所述麦克风阵列具有多个麦克风通道,每个所述麦克风通道包括至少一个麦克风单元;b、建立该麦克风阵列的误差概率模型;c、构建基于所述误差概率模型的差分波束设计算法的最优问题;d、求解上述最优问题的最优解,得到所述麦克风阵列的多个麦克风通道的权重向量;e、根据所述权重向量对所述麦克风阵列采集的语音信号进行调整,输出优化后的语音信号。具体阐述如下。
[0059]
一、参照图2所示,麦克风阵列为线性阵列,其包括均匀分布的m个麦克风单元,从而具有m个麦克风通道,x(ω)为说话人的语音信号,y1(ω)、y2(ω)、y3(ω)分别为麦克风单元1、2、m拾取的语音信号。根据实际需求,确定均匀分布线性阵列的麦克风单元个数m,同时确定n个零点位置向量α=[θ
n,1
,
…
,θ
n,n
]
t
,上标t为转置,且零点位置需满足0<θ
n,1
<θ
n,2
<
…
<θ
n,n
<180,而个数需满足条件m≥n+1,期望目标方向为0度方向。
[0060]
二、建立实际导向矢量模型为:
[0061][0062]
为理想导向矢量,其中θ为平面波传播方向,δ为
麦克风阵列单元相邻间距,τ0=δ/c为0度方向平面波到达相邻两个麦克风的延时,c为声传播速度,j为虚指数,ω为角频率。
[0063]
⊙
表示元素点乘,a
mul
(ω)为随机乘性误差,大小为mx1,其中第m个元素为(ω)为随机乘性误差,大小为mx1,其中第m个元素为为乘性误差幅度,内部概率分布函数相同,为乘性误差相位,内部概率分布函数相同,a
add
(ω)为随机加性误差,大小为mx1,其中第m个元素为为加性误差幅度,内部概率分布函数相同,为加性误差相位,内部概率分布函数相同,上述所有随机变量相互独立。
[0064]
这些概率分布可以通过建模获取,或者通过实际测量获取。
[0065]
三、基于误差概率分布模型的改进型零点能量约束差分波束设计算法的最优问题表达如下:
[0066][0067]
s.t.
[0068]
e{
·
}为求期望平均值,h(ω)=[h1(ω),h2(ω),
…
,h
m
(ω)]
t
为权重向量,为第m个麦克风通道的权重,上标*和h分别为共轭和共轭转置,定义为:
[0069][0070]
四、上述优化问题的最优解h
opt
(ω)为:
[0071]
h
opt
(ω)=r
‑1(ω)c
h
(ω)[c(ω)r
‑1(ω)c
h
(ω)]
‑1[0072]
r(ω)的定义为:
[0073]
r(ω)=(d
h
(ω,α)d(ω,α))
⊙
r1+n*r2+r3[0074]
c(ω)的定义为:
[0075][0076]
其中
[0077][0078]
d
n,m
(ω,α)表示为矩阵d(ω,α)下标为(n,m)处的元素,n=1,
…
,n,m=1,
…
,m
[0079]
[0080][0081][0082]
re{
·
}为取元素实部操作,
[0083]
为乘性误差幅度平方的期望值为乘性误差幅度的期望值
[0084][0085][0086]
为加性误差幅度平方的期望值为加性误差幅度的期望值
[0087][0088][0089]
和分别为乘性误差幅度和相位的概率密度分布函数,因为乘性随机误差向量中的每个元素的分布都一样,所以误差的幅度或相位下标给省略,和分别表示加性误差幅度和相位的概率密度分布函数,d(a
mul
(ω))表示a
mul
(ω)的微分,d(φ
mul
(ω))表示φ
mul
(ω)的微分,d(a
add
(ω))表示a
add
(ω)的微分,d(φ
add
(ω))表示φ
add
(ω)的微分,同理可定义微分,同理可定义d
n,m
(ω,α)表示为矩阵d(ω,α)下标为(n,m)处的元素,n=1,
…
,n,m=1,
…
,m。
[0090]
五、将麦克风阵列采集的信号转换至频域,与权重向量相乘后叠加,然后通过逆傅里叶变换转换为时域输出优化后的语音信号。
[0091]
仿真例
[0092]
采用四元线性麦克风阵列,相邻麦克风单元的间距为1cm,考虑的频段范围为[100,3700]hz,覆盖了语言声频段,且间距远小于声波波长,满足差分阵列要求。假定导向矢量同时存在乘此误差和加性误差,乘性误差幅度范围在[0.85,1.15]之间均匀分布,相位误差在[
‑
5,5]度之间均匀分布,加性误差幅度范围在[0,0.01]之间均匀分布,相位在[
‑
180,180]度之间均匀分布。选择二阶超心形图案作为目标波束图案,零点位置为106和153度,目标方向为0度。分别采用基于最小范数和本文提出的基于误差概率分布的鲁棒性设计
方法进行波束成形,其中二阶超心形图案和最小范数方法见“chen,jingdong.benesty,jacob.pan,chao.on the design and implementation of linear differential microphone arrays.j.acoust.soc.am.,vol.136,no.6,dec.2014.”[0093]
评价指标为白噪声增益(white noise gain,wng)、平均期望波束图案和目标方向的平均期望频响,其中wng用于描述系统抗麦克风自噪声、不匹配等系统误差的能力,其值越大,表示抗误差性能越强,其定义为:
[0094][0095]
平均期望波束图案定义为即频率ω不变,θ取值区间为[
‑
180,180]度,而目标方向的平均期望频响表达式也为但这时θ为0度不变,频率ω区间为[100,3700]hz。平均值通过monte carlo方法仿真,误差随机产生1000次以后取平均值。
[0096]
结合图3a和图3b所示,本实施例的算法在wng性能方面有明显提升,且平均期望频响非常平坦;而基于最小范数的方法在低频处频响明显拉升,相比于高频处最大拉升35db,极易引起语音失真。
[0097]
图4a和图4b分别给出了两种算法分别在500hz和3000hz时的平均期望波束图案,从图中可以看出,最小范数方法在500hz时基本失效,无指向性;而基于概率误差的方法在180度方向仍有10db衰减效果。在3000hz时,相比于最小范数方法,基于概率误差的方法主瓣略宽一点,旁瓣略低一点。
[0098]
本实施例还提供一种拾音装置。参照图5所示,该拾音装置包括麦克风阵列、数模转换机构及信号处理机构;麦克风阵列用于采集说话者的语音,数模转换机构用于将麦克风阵列采集的语音信号转换为数字信号,信号处理机构采用上文述及的算法对数模转换机构输出的数字信号进行优化处理,输出优化后的语音信号。
[0099]
麦克风阵列包括多个麦克风单元,这些麦克风单元线性排列且间距相等;具体到本实施例中,相邻麦克风单元的间距为1cm。数模转换机构为多通道adc数模转换芯片,其输入端和麦克风阵列电性连接。信号处理机构采用dsp处理芯片或fpga处理芯片,其和数模转换机构的输出端电性连接。具体地,信号处理机构包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上所述的拾音方法。
[0100]
本实施例还提供一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该程序被处理器执行时实现如上所述的拾音方法。
[0101]
本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本技术的说明书中使用的措辞“包括”是指存在特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。
[0102]
上述实施例只为说明本发明的技术构思及特点,是一种优选的实施例,其目的在于熟悉此项技术的人士能够了解本发明的内容并据以实施,并不能以此限定本发明的保护范围。凡根据本发明的精神实质所作的等效变换或修饰,都应涵盖在本发明的保护范围之内。