1.本技术涉及语音识别技术领域,具体涉及多媒体节目点播系统、方法和装置,点餐系统、方法和装置,通讯连接建立系统、方法和装置,语音交互系统、方法和装置,语音实体识别模型构建方法和装置,实体知识库构建方法和装置,电视节目点播方法和装置,会议记录方法和装置,智能音箱,智能电视,点餐机,用户设备,以及电子设备。
背景技术:
2.随着自动语音识别(automatic speech recognition,asr)技术的不断发展,智能语音助手得到了广泛引用,如智能手机向用户提供的智能语音助手服务、智能音箱等等。
3.人工智能的核心功能是语音助手的发力点,使语音助手更好地理解用户指令,特别是用户指令中具有特定意义的实体,主要包括人名、地名、机构名、歌曲名、电影名、电话号码、专有名词等。以智能音箱为例,用户可使用音箱提供的点歌服务,如用户对音箱说:我想听雷雨心的记念”,其中“雷雨心”和“记念”是具有特定意义的实体,是点歌指令的处理对象,如果不能正确识别这两个实体,就会导致无法正确播放用户所点的歌曲。目前,一种典型的语音实体识别系统的处理过程为:首先,通过语音识别技术asr,将输入的语音信号转换成为文字;然后,通过对文字的语义理解,识别用户指令中的实体名称。
4.然而,在实现本发明过程中,发明人发现该技术方案至少存在如下问题:该方案严重依赖上游asr输出的文本内容,如果遇到用户发音不准(如有口音或者部分读音错误)或者发音不清楚的情况,asr将语音信号转换成为错误的文本内容的概率很大,这样就会导致无法正确的识别语音信号中实体名称。综上所述,如何提升语音实体识别的准确率,从而提升语音交互准确率,成为本领域技术人员急需解决的问题。
技术实现要素:
5.本技术提供多媒体节目点播系统,以解决现有技术存在的由用户发音不准、发音不清或者同音不同词导致的语音实体识别准确率较低的问题。本技术另外提供多媒体节目点播方法和装置,点餐系统、方法和装置,通讯连接建立系统、方法和装置,语音交互系统、方法和装置,语音实体识别模型构建方法和装置,实体知识库构建方法和装置,电视节目点播方法和装置,会议记录方法和装置,智能音箱,智能电视,点餐机,用户设备,以及电子设备。
6.本技术提供一种多媒体节目点播系统,包括:
7.智能音箱,用于采集多媒体节目点播语音数据,将所述语音数据发送至服务端;根据服务端的多媒体节目播放处理结果,播放多媒体节目;
8.服务端,用于构建多媒体节目知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的多媒体节目信息;根据所述多媒体节目信息,执行多媒体节目播放处理。
9.本技术还提供一种点餐系统,包括:
10.点餐设备,用于采集点餐语音数据,将所述语音数据发送至服务端;
11.服务端,用于构建餐品知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的餐品信息;根据所述餐品信息,执行备餐处理。
12.本技术还提供一种通讯连接建立系统,包括:
13.用户设备,用于采集通讯指令语音数据,将所述语音数据发送至服务端;
14.服务端,用于构建通讯用户知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的通讯用户信息;根据所述通讯用户信息,执行通讯连接建立处理。
15.本技术还提供一种语音交互系统,包括:
16.终端设备,用于采集语音数据,将所述语音数据发送至服务端;
17.服务端,用于构建实体知识库;通过语音实体识别模型和所述实体知识库,确定所述语音数据中的实体信息;根据所述实体信息,执行语音交互处理。
18.本技术还提供一种语音交互方法,包括:
19.构建实体知识库;
20.通过语音实体识别模型和所述实体知识库,确定目标语音数据中的实体信息;
21.根据所述实体信息,执行语音交互处理。
22.可选的,所述通过语音实体识别模型和所述实体知识库,确定目标语音数据中的实体信息,包括:
23.通过所述语音实体识别模型包括的音频编码模型,确定所述语音数据的音频特征数据;
24.通过所述语音实体识别模型包括的实体解码模型和所述实体知识库,根据所述音频特征数据,确定所述实体信息。
25.可选的,所述通过所述语音实体识别模型包括的实体解码模型和所述实体知识库,根据所述音频特征数据,确定所述实体信息,包括:
26.通过所述实体解码模型包括的实体候选发音确定模块,根据所述音频特征数据,确定所述实体信息的至少一个候选发音;
27.通过所述实体解码模型包括的实体发音确定模块,根据所述实体知识库,从所述至少一个候选发音中,确定所述实体信息的发音;
28.根据所述实体信息的发音,确定所述实体信息。
29.可选的,所述根据所述实体知识库,从所述至少一个候选发音中,确定所述实体信息的发音,包括:
30.确定所述实体知识库中的实体的发音与所述候选发音的相似度;
31.根据所述相似度,确定所述实体信息的发音。
32.可选的,所述实体知识库包括:多媒体节目点播领域的节目实体知识库;
33.所述节目实体知识库包括:同音不同字的节目相关实体,用户实体,节目相关实体与用户实体间的实体关系;
34.所述构建实体知识库,包括:
35.根据用户历史播放信息,确定所述用户实体,并构建所述实体关系;
36.所述根据所述实体信息的发音,确定所述实体信息,包括:
37.根据所述实体信息的发音,确定候选实体;
38.根据用户信息和所述实体关系,从所述候选实体中确定所述实体信息。
39.可选的,还包括:
40.从训练数据中学习得到所述语音实体识别模型;
41.其中,所述训练数据包括:音频数据和实体标注信息。
42.可选的,所述通过语音实体识别模型和所述实体知识库,确定目标语音数据中的实体信息,包括:
43.通过所述语音实体识别模型包括的音频编码模型,确定所述语音数据的音频特征数据;
44.通过所述语音实体识别模型包括的实体编码模型,确定所述实体知识库中实体的发音特征数据;
45.通过所述语音实体识别模型包括的实体解码模型,根据所述音频特征数据和实体发音特征数据,确定所述实体信息。
46.可选的,所述通过所述语音实体识别模型包括的实体解码模型,根据所述音频特征数据和实体发音特征数据,确定所述实体信息,包括:
47.根据所述音频特征数据和实体发音特征数据,确定所述语音数据中的实体与所述实体知识库中的实体的发音相似度;
48.根据所述发音相似度,确定所述实体信息。
49.可选的,所述实体知识库包括:多媒体节目点播领域的节目实体知识库;
50.所述节目实体知识库包括:同音不同字的节目相关实体,用户实体,节目相关实体与用户实体间的实体关系;
51.所述构建实体知识库,包括:
52.根据用户历史播放信息,确定所述用户实体,并构建所述实体关系;
53.所述根据所述发音相似度,确定所述实体信息,包括:
54.根据所述发音相似度,确定候选实体;
55.根据用户信息和所述实体关系,从所述候选实体中确定所述实体信息。
56.可选的,还包括:
57.从训练数据中学习得到所述语音实体识别模型;
58.其中,所述训练数据包括:音频数据、实体知识库和实体标注信息。
59.可选的,所述实体知识库包括:多媒体节目点播领域的节目实体知识库;
60.所述构建实体知识库,包括:
61.确定多媒体节目相关实体,形成所述实体知识库。
62.本技术还提供一种语音交互方法,包括:
63.采集语音数据,将所述语音数据发送至服务端,以使得服务端构建实体知识库;通过语音实体识别模型和所述实体知识库,确定所述语音数据中的实体信息;根据所述实体信息,执行语音交互处理。
64.本技术还提供一种多媒体节目点播方法,包括:
65.构建多媒体节目知识库;
66.通过语音实体识别模型和所述知识库,确定多媒体节目点播语音数据中的多媒体节目信息;
67.根据所述多媒体节目信息,执行多媒体节目播放处理。
68.本技术还提供一种多媒体节目点播方法,包括:
69.采集多媒体节目点播语音数据,将所述语音数据发送至服务端,以使得服务端构建多媒体节目知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的多媒体节目信息;根据所述多媒体节目信息,执行多媒体节目播放处理。
70.本技术还提供一种点餐方法,包括:
71.构建餐品知识库;
72.通过语音实体识别模型和所述实体知识库,确定点餐语音数据中的餐品信息;
73.根据所述餐品信息,执行备餐处理。
74.本技术还提供一种点餐方法,包括:
75.采集点餐语音数据,将所述语音数据发送至服务端,以使得服务端构建餐品知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的餐品信息;根据所述餐品信息,执行备餐处理。
76.本技术还提供一种通讯连接建立方法,包括:
77.构建通讯用户知识库;
78.通过语音实体识别模型和所述知识库,确定通讯指令语音数据中的通讯用户信息;
79.根据所述通讯用户信息,执行通讯连接建立处理。
80.本技术还提供一种通讯连接建立方法,包括:
81.采集通讯指令语音数据,将所述语音数据发送至服务端,以使得服务端构建通讯用户知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的通讯用户信息;根据所述通讯用户信息,执行通讯连接建立处理。
82.本技术还提供一种语音实体识别模型构建方法,包括:
83.确定训练数据集,所述训练数据包括:语音数据、实体标注信息和实体知识库;
84.构建所述模型的网络结构;
85.从训练数据集中学习得到所述模型。
86.可选的,所述模型包括音频编码模型,用于确定所述语音数据的音频特征数据;
87.所述模型包括实体解码模型,根据所述音频特征数据和所述实体知识库,确定所述语音数据中的实体信息。
88.可选的,所述模型包括音频编码模型,用于确定所述语音数据的音频特征数据;
89.所述模型包括实体编码模型,用于确定所述实体知识库中实体的发音特征数据;
90.所述模型包括实体解码模型,用于根据所述音频特征数据和实体发音特征数据,确定所述语音数据中的实体信息。
91.本技术还提供一种实体知识库构建方法,包括:
92.获取目标领域的实体名;
93.根据所述实体名,生成目标领域的实体知识库,所述实体知识库用于通过语音实体识别模型和所述实体知识库,确定目标领域的语音数据中的实体信息。
94.本技术还提供一种语音实体识别方法,包括:
95.构建实体知识库和语音实体识别模型;
96.确定目标语音数据;
97.通过所述语音实体识别模型和实体知识库,确定目标语音数据中的实体信息。
98.本技术还提供一种语音交互装置,包括:
99.知识库构建单元,用于构建实体知识库;
100.实体确定单元,用于通过语音实体识别模型和所述实体知识库,确定目标语音数据中的实体信息;
101.交互处理单元,用于根据所述实体信息,执行语音交互处理。
102.本技术还提供一种电子设备,包括:
103.处理器;以及
104.存储器,用于存储实现语音交互方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:构建实体知识库;通过语音实体识别模型和所述实体知识库,确定目标语音数据中的实体信息;根据所述实体信息,执行语音交互处理。
105.本技术还提供一种语音交互装置,包括:
106.语音数据采集单元,用于采集语音数据;
107.语音数据发送单元,用于将所述语音数据发送至服务端,以使得服务端构建实体知识库;通过语音实体识别模型和所述实体知识库,确定所述语音数据中的实体信息;根据所述实体信息,执行语音交互处理。
108.本技术还提供一种电子设备,包括:
109.处理器;以及
110.存储器,用于存储实现语音交互方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:采集语音数据,将所述语音数据发送至服务端,以使得服务端构建实体知识库;通过语音实体识别模型和所述实体知识库,确定所述语音数据中的实体信息;根据所述实体信息,执行语音交互处理。
111.本技术还提供一种多媒体节目点播装置,包括:
112.语音数据采集单元,用于采集多媒体节目点播语音数据;
113.语音数据发送单元,用于将所述语音数据发送至服务端,以使得服务端构建多媒体节目知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的多媒体节目信息;根据所述多媒体节目信息,执行多媒体节目播放处理。
114.本技术还提供一种智能音箱,包括:
115.处理器;以及
116.存储器,用于存储实现多媒体节目点播方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:采集多媒体节目点播语音数据,将所述语音数据发送至服务端,以使得服务端构建多媒体节目知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的多媒体节目信息;根据所述多媒体节目信息,执行多媒体节目播放处理。
117.本技术还提供一种多媒体节目点播装置,包括:
118.知识库构建单元,用于构建多媒体节目知识库;
119.实体识别单元,用于通过语音实体识别模型和所述知识库,确定多媒体节目点播语音数据中的多媒体节目信息;
120.节目播放处理单元,用于根据所述多媒体节目信息,执行多媒体节目播放处理。
121.本技术还提供一种电子设备,包括:
122.处理器;以及
123.存储器,用于存储实现多媒体节目点播方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:构建多媒体节目知识库;通过语音实体识别模型和所述知识库,确定多媒体节目点播语音数据中的多媒体节目信息;根据所述多媒体节目信息,执行多媒体节目播放处理。
124.本技术还提供一种点餐装置,包括:
125.知识库构建单元,用于构建餐品知识库;
126.实体识别单元,用于通过语音实体识别模型和所述实体知识库,确定点餐语音数据中的餐品信息;
127.备餐处理单元,用于根据所述餐品信息,执行备餐处理。
128.本技术还提供一种电子设备,包括:
129.处理器;以及
130.存储器,用于存储实现点餐方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:构建餐品知识库;通过语音实体识别模型和所述实体知识库,确定点餐语音数据中的餐品信息;根据所述餐品信息,执行备餐处理。
131.本技术还提供一种点餐装置,包括:
132.语音数据采集单元,用于采集点餐语音数据;
133.语音数据发送单元,用于将所述语音数据发送至服务端,以使得服务端构建餐品知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的餐品信息;根据所述餐品信息,执行备餐处理。
134.本技术还提供一种点餐机,包括:
135.处理器;以及
136.存储器,用于存储实现点餐方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:采集点餐语音数据,将所述语音数据发送至服务端,以使得服务端构建餐品知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的餐品信息;根据所述餐品信息,执行备餐处理。
137.本技术还提供一种通讯连接建立装置,包括:
138.语音数据采集单元,用于采集通讯指令语音数据;
139.语音数据发送单元,用于将所述语音数据发送至服务端,以使得服务端构建通讯用户知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的通讯用户信息;根据所述通讯用户信息,执行通讯连接建立处理。
140.本技术还提供一种用户设备,包括:
141.处理器;以及
142.存储器,用于存储实现通讯连接建立方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:采集通讯指令语音数据,将所述语音数据发送至服务端,以使得服务端构建通讯用户知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的通讯用户信息;根据所述通讯用户信息,执行通讯连接建立处理。
143.本技术还提供一种通讯连接建立装置,包括:
144.知识库构建单元,用于构建通讯用户知识库;
145.实体识别单元,用于通过语音实体识别模型和所述知识库,确定通讯指令语音数据中的通讯用户信息;
146.通讯连接处理单元,用于根据所述通讯用户信息,执行通讯连接建立处理。
147.本技术还提供一种电子设备,包括:
148.处理器;以及
149.存储器,用于存储实现点餐方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:构建通讯用户知识库;通过语音实体识别模型和所述知识库,确定通讯指令语音数据中的通讯用户信息;根据所述通讯用户信息,执行通讯连接建立处理。
150.本技术还提供一种语音实体识别模型构建装置,包括:
151.训练数据确定单元,用于确定训练数据集,所述训练数据包括:语音数据、实体标注信息和实体知识库;
152.网络构建单元,用于构建所述模型的网络结构;
153.模型训练单元,用于从训练数据集中学习得到所述模型。
154.本技术还提供一种电子设备,包括:
155.处理器;以及
156.存储器,用于存储实现语音实体识别模型构建方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:确定训练数据集,所述训练数据包括:语音数据、实体标注信息和实体知识库;构建所述模型的网络结构;从训练数据集中学习得到所述模型。
157.本技术还提供一种实体知识库构建装置,包括:
158.实体确定单元,用于获取目标领域的实体名;
159.知识库生成单元,用于生成目标领域的实体知识库,所述实体知识库用于通过语音实体识别模型和所述实体知识库,确定目标领域的语音数据中的实体信息。
160.本技术还提供一种电子设备,包括:
161.处理器;以及
162.存储器,用于存储实现实体知识库构建方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:获取目标领域的实体名;根据所述实体名,生成目标领域的实体知识库,所述实体知识库用于通过语音实体识别模型和所述实体知识库,确定目标领域的语音数据中的实体信息。
163.本技术还提供一种语音实体识别装置,包括:
164.模型构建单元,用于语音实体识别模型;
165.知识库构建单元,用于构建实体知识库;
166.语音数据确定单元,用于确定目标语音数据;
167.实体确定单元,用于通过所述语音实体识别模型和实体知识库,确定目标语音数据中的实体信息。
168.本技术还提供一种电子设备,包括:
169.处理器;以及
170.存储器,用于存储实现语音实体识别方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:构建实体知识库和语音实体识别模型;确定目标语音数据;通过所述语音实体识别模型和实体知识库,确定目标语音数据中的实体信息。
171.本技术还提供一种电视节目播放方法,包括:
172.构建电视节目知识库;
173.通过语音实体识别模型和所述知识库,确定与目标节目播放语音指令数据对应的目标节目名;
174.根据所述目标节目名,执行目标节目对象播放处理。
175.可选的,所述知识库包括:同音不同字的节目相关实体,用户实体,节目相关实体与用户实体间的实体关系;
176.所述构建电视节目知识库,包括:
177.根据用户历史播放信息,确定所述用户实体,并构建所述实体关系。
178.可选的,所述根据所述目标节目名,执行目标节目对象播放处理,包括:
179.根据节目表,确定与所述目标节目名对应的电视频道和播放时间;
180.根据所述播放时间和所述电视频道,确定目标节目对象;
181.执行播放所述目标节目对象的处理。
182.可选的,所述根据所述播放时间和所述电视频道,确定目标节目对象,包括:
183.显示与所述目标节目名对应的至少一个电视频道在多个时间播放的多个节目对象;
184.将用户指定的节目对象作为目标节目对象。
185.可选的,还包括:
186.若所述节目表不包括所述目标节目名,则确定与所述目标节目名相关的节目名;
187.显示相关节目名;
188.若用户指定播放相关节目对象,则执行播放相关节目对象的处理。
189.本技术还提供一种电视节目播放方法,包括:
190.智能电视采集用户的节目播放语音指令数据;
191.将所述语音指令数据发送至服务端,以便于服务端构建电视节目知识库;通过语音实体识别模型和所述知识库,确定与所述语音指令数据对应的目标节目名;根据所述目标节目名,执行目标节目对象播放处理;
192.播放目标节目对象。
193.本技术还提供一种会议记录方法,包括:
194.构建会议领域的语言知识库;
195.通过语音实体识别模型和所述会议领域的语言知识库,确定目标会议语音数据中的实体信息;
196.通过语音识别模型和所述实体信息,确定与所述会议语音数据对应的文本序列,形成会议记录。
197.可选的,还包括:
198.确定与会议语音数据对应的会议领域。
199.本技术还提供一种会议记录方法,包括:
200.采集目标会议的语音数据;
201.将所述语音数据发送至服务端,以便于服务端构建会议领域的语言知识库;通过语音实体识别模型和所述会议领域的语言知识库,确定目标会议语音数据中的实体信息;通过语音识别模型和所述实体信息,确定与所述会议语音数据对应的文本序列,形成会议记录。
202.本技术还提供一种电视节目播放装置,包括:
203.语音数据采集单元,用于采集用户的节目播放语音指令数据;
204.语音数据发送单元,用于将所述语音指令数据发送至服务端,以便于服务端构建电视节目知识库;通过语音实体识别模型和所述知识库,确定与所述语音指令数据对应的目标节目名;根据所述目标节目名,执行目标节目对象播放处理;
205.节目播放单元,用于播放目标节目对象。
206.本技术还提供一种智能电视,包括:
207.处理器;以及
208.存储器,用于存储实现电视节目播放方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:采集用户的节目播放语音指令数据;将所述语音指令数据发送至服务端,以便于服务端构建电视节目知识库;通过语音实体识别模型和所述知识库,确定与所述语音指令数据对应的目标节目名;根据所述目标节目名,执行目标节目对象播放处理;播放目标节目对象。
209.本技术还提供一种电视节目播放装置,包括:
210.知识库构建单元,用于构建电视节目知识库;
211.实体识别单元,用于通过语音实体识别模型和所述知识库,确定与目标节目播放语音指令数据对应的目标节目名;
212.播放处理单元,用于根据所述目标节目名,执行目标节目对象播放处理。
213.本技术还提供一种电子设备,包括:
214.处理器;以及
215.存储器,用于存储实现电视节目播放方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:构建电视节目知识库;通过语音实体识别模型和所述知识库,确定与目标节目播放语音指令数据对应的目标节目名;根据所述目标节目名,执行目标节目对象播放处理。
216.本技术还提供一种会议记录装置,包括:
217.语音数据采集单元,用于采集目标会议的语音数据;
218.语音数据发送单元,用于将所述语音数据发送至服务端,以便于服务端构建会议领域的语言知识库;通过语音实体识别模型和所述会议领域的语言知识库,确定目标会议语音数据中的实体信息;通过语音识别模型和所述实体信息,确定与所述会议语音数据对应的文本序列,形成会议记录。
219.本技术还提供一种电子设备,包括:
220.处理器;以及
221.存储器,用于存储实现会议记录方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:采集目标会议的语音数据;将所述语音数据发送至服务
端,以便于服务端构建会议领域的语言知识库;通过语音实体识别模型和所述会议领域的语言知识库,确定目标会议语音数据中的实体信息;通过语音识别模型和所述实体信息,确定与所述会议语音数据对应的文本序列,形成会议记录。
222.本技术还提供一种会议记录装置,包括:
223.知识库构建单元,用于构建会议领域的语言知识库;
224.实体识别单元,用于通过语音实体识别模型和所述会议领域的语言知识库,确定目标会议语音数据中的实体信息;
225.会议记录确定单元,用于通过语音识别模型和所述实体信息,确定与所述会议语音数据对应的文本序列,形成会议记录。
226.本技术还提供一种电子设备,包括:
227.处理器;以及
228.存储器,用于存储实现会议记录方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:构建会议领域的语言知识库;通过语音实体识别模型和所述会议领域的语言知识库,确定目标会议语音数据中的实体信息;通过语音识别模型和所述实体信息,确定与所述会议语音数据对应的文本序列,形成会议记录。
229.本技术还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机执行上述各种方法。
230.本技术还提供一种包括指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述各种方法。
231.与现有技术相比,本技术具有以下优点:
232.本技术实施例提供的多媒体节目点播系统,通过智能音箱多媒体节目点播语音数据,将所述语音数据发送至服务端;根据服务端的多媒体节目播放处理结果,播放多媒体节目;服务端用于构建多媒体节目知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的多媒体节目信息;根据所述多媒体节目信息,执行多媒体节目播放处理;这种处理方式,使得引入多媒体节目知识图谱信息,直接比对多媒体节目点播语音中是否有知识图谱中的多媒体节目实体发音,实现从语音信号中进行语义理解和实体识别,不再依赖asr将语音转换成为文字,再通过对文字的语义理解识别其中的多媒体节目实体名称,这样更接近于人类理解语音的过程;因此,可以有效提升多媒体节目名识别的准确率,从而提升多媒体节目点播的成功率和准确率。
233.本技术实施例提供的点餐系统,通过点餐设备采集点餐语音数据,将所述语音数据发送至服务端;服务端构建餐品知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的餐品信息;根据所述餐品信息,执行备餐处理;这种处理方式,使得引入餐品知识图谱信息,直接比对点餐语音中是否有知识图谱中的餐品名发音,实现从点餐语音信号中进行语义理解和餐品名识别,不再依赖asr将语音转换成为文字,再通过对文字的语义理解识别其中的餐品名称,这样更接近于人类理解语音的过程;因此,可以有效提升餐品名识别的准确率,从而提升点餐成功率和准确率。
234.本技术实施例提供的通讯连接建立系统,通过用户设备采集通讯指令语音数据,将所述语音数据发送至服务端;服务端构建通讯用户知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的通讯用户信息;根据所述通讯用户信息,执行通讯连接建
立处理;这种处理方式,使得引入联系人图谱信息,直接比对打电话指令语音中是否有知识图谱中的人名发音,实现从打电话指令语音信号中进行语义理解和餐品名识别,不再依赖asr将语音转换成为文字,再通过对文字的语义理解识别其中的人名,这样更接近于人类理解语音的过程;因此,可以有效提升人名识别的准确率,从而提升通讯成功率和准确率。
235.本技术实施例提供的语音交互系统,通过终端设备采集语音数据,将语音数据发送至服务端;服务端构建实体知识库,通过语音实体识别模型和实体知识库,确定语音数据中的实体信息;根据实体信息,执行语音交互处理;这种处理方式,使得引入实体知识图谱信息,直接比对语音中是否有知识图谱中的实体发音,实现从语音信号中进行语义理解和实体识别,不再依赖asr将语音转换成为文字,再通过对文字的语义理解识别其中的实体名称,这样更接近于人类理解语音的过程;因此,可以有效提升语音实体识别的准确率,从而提升语音交互准确率。
236.本技术实施例提供的电视节目播放系统,通过智能电视用于采集用户的节目播放语音指令数据,将所述语音指令数据发送至服务端,播放目标节目对象;服务端用于构建电视节目知识库;通过语音实体识别模型和所述知识库,确定与所述语音指令数据对应的目标节目名;根据所述目标节目名,执行目标节目对象播放处理;这种处理方式,使得引入节目相关实体图谱信息,直接比对节目播放语音指令中是否有知识图谱中的节目相关实体发音,实现从节目播放语音指令信号中进行语义理解和节目名等实体的识别,不再依赖asr将语音转换成为文字,再通过对文字的语义理解识别其中的节目名,这样更接近于人类理解语音的过程;因此,可以有效提升节目实体识别的准确率,从而提升电视节目点播的成功率和准确率。
237.本技术实施例提供的会议记录系统,通过终端设备采集目标会议的语音数据,将所述语音数据发送至服务端;服务端构建会议领域的语言知识库;通过语音实体识别模型和所述会议领域的语言知识库,确定目标会议语音数据中的实体信息;通过语音识别模型和所述实体信息,确定与所述会议语音数据对应的文本序列,形成会议记录;这种处理方式,使得引入会议领域相关术语等实体图谱信息,直接比对会议语音数据中是否有知识图谱中的会议领域相关术语等实体的发音,实现从会议语音数据信号中进行语义理解和会议领域相关术语等实体的识别,不再依赖asr将语音转换成为文字,再通过对文字的语义理解识别其中的会议领域相关术语,这样更接近于人类理解语音的过程;因此,可以有效提升会议领域相关术语识别的准确率,从而提升会议记录了的成功率和准确率。
附图说明
238.图1本技术提供的一种多媒体节目点播系统的实施例的结构示意图;
239.图2本技术提供的一种多媒体节目点播系统的实施例的场景示意图;
240.图3本技术提供的一种多媒体节目点播系统的实施例的设备交互示意图;
241.图4本技术提供的一种多媒体节目点播系统的实施例的系统架构示意图;
242.图5本技术提供的一种多媒体节目点播系统的实施例的语音实体识别模型示意图;
243.图6本技术提供的一种多媒体节目点播系统的实施例的知识图谱示意图;
244.图7本技术提供的一种多媒体节目点播系统的实施例的又一语音实体识别模型示
意图。
具体实施方式
245.在下面的描述中阐述了很多具体细节以便于充分理解本技术。但是本技术能够以很多不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本技术内涵的情况下做类似推广,因此本技术不受下面公开的具体实施的限制。
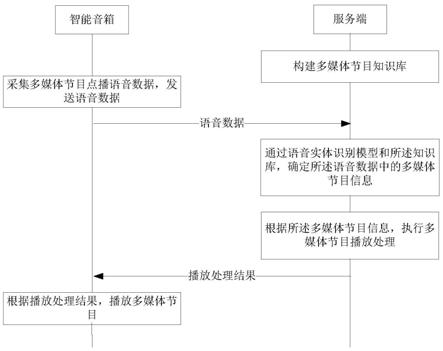
246.在本技术中,提供了多媒体节目点播系统、方法和装置,点餐系统、方法和装置,通讯连接建立系统、方法和装置,语音交互系统、方法和装置,语音实体识别模型构建方法和装置,实体知识库构建方法和装置,电视节目点播方法和装置,会议记录方法和装置,智能音箱,智能电视,点餐机,用户设备,以及电子设备。在下面的实施例中逐一对各种方案进行详细说明。
247.第一实施例
248.请参考图1,其为本技术的多媒体节目点播系统的实施例的示意图。本实施例提供的多媒体节目点播系统包括:服务器1和智能音箱2。
249.服务器1,可以是部署在云端服务器上的服务端,也可以是专用于实现多媒体节目点播系统的服务器,可部署在数据中心。
250.智能音箱2,可以是家庭消费者用语音进行上网的一个工具,比如点播歌曲、上网购物,或是了解天气预报,它也可以对智能家居设备进行控制,比如打开窗帘、设置冰箱温度、提前让热水器升温等。
251.请参考图2,其为本技术的多媒体节目点播系统的场景示意图。服务端1和智能音箱2间可通过网络连接,如智能音箱2可通过wifi等方式联网,等等。用户与智能音箱之间通过语音方式进行交互。在本实施例中,用户向智能音箱2下达点歌语音指令,服务端通过语音实体识别模型和预先构建的多媒体节目知识库,确定点歌语音指令中的歌曲名信息;执行播放该歌曲的处理。
252.请参考图3,其为本技术的多媒体节目点播系统的设备示意图。在本实施例中,智能音箱用于采集多媒体节目点播语音数据,将所述语音数据发送至服务端;服务端用于构建多媒体节目知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的多媒体节目信息;根据所述多媒体节目信息,执行多媒体节目播放处理。
253.所述多媒体节目,可以是歌曲、电影、电视节目、演讲视频等等。所述多媒体节目知识库,包括节目相关实体信息。所述节目相关实体信息,包括但不限于以下实体的至少一者:节目名(如歌曲名、电影名、电视节目名、演讲者姓名等),节目相关人名(如歌手姓名、电影导演姓名等),等等。
254.所述服务端,要构建多媒体节目知识库,可采用如下方式:确定多媒体节目相关实体,形成多媒体节目知识库。表1示出了本实施例中多媒体节目知识库的内容。
[0255][0256][0257]
表1、实体数据
[0258]
由图4可见,在智能音箱侧,模拟语音信号通过智能音箱的接收传感器和相应的数字信号处理单元后,被转换成为数字语音信号;该部分也可以包括一部分声学处理,产生相应的语音中间结果,可以包括但不限于声音频谱信号、音素、字、字片段、拼音等。智能音箱可将数字语音信号上传至服务端,服务端通过所述语音实体识别模型对数字语音信号进行建模,同时结合知识图谱(即知识库)中的实体信息,识别在语音中提及的实体名称(如歌曲名等)。
[0259]
具体实施时,所述语音实体识别模型,可以是机器学习模型(如深度神经网络模型、贝叶斯模型等),也可以是非机器学习模型(如启发式模型等)。
[0260]
所述语音实体识别模型,可直接从语音信号中进行语义理解和实体识别,不再依赖语音识别asr将语音转换成为文字,再通过对文字的语义理解识别其中的实体名称。通过引入知识图谱,可以直接比对语音中是否有知识图谱中的实体发音,更接近于人类理解语音的过程,获得更准确的实体识别结果,有效的解决用户发音不准、发音不清以及一音多字的问题。
[0261]
下面通过几个应用场景示例,说明本技术实施例提供的所述系统可解决的具体问题:
[0262]
场景1:
[0263]
用户小赵开车时经常使用智能音箱进行点歌,由于地方口音问题,前鼻音/后鼻音无法区分,卷舌音/翘舌音无法区分,尝尝导致传统语音实体识别系统中的智能音箱执行错误的指令,比如小赵语音指令对应的汉语拼音是“wo xiang ting bie zi ji”,智能音箱通过asr识别成文本“我想听别自己”,最后会把“别自己”识别成一首歌名,然而并没有“别自己”这首歌,小赵真实想听的歌曲是“别知己”。采用本技术实施例提供的所述系统,由于所述知识库中包括歌曲名“别知己”,因此可准确识别出该歌曲,正确播放该歌曲。
[0264]
场景2:
[0265]
用户豆豆是一位5岁儿童,经常使用家里的带屏智能音箱观看动画片,由于豆豆年龄太小不会打字,只能通过语音进行搜索。然而豆豆发音不是很清楚,经常点播失败,需要家长帮助点播,比如豆豆发出语音点播指令后,智能音箱通过asr识别成文本“我要看那个站”,其实豆豆想表达的是“我要看哪吒”。采用本技术实施例提供的所述系统,由于所述知识库中包括电影名“哪吒”,因此可准确识别出该电影,正确播放该电影。
[0266]
场景3:
[0267]
用户小王正在打扫家务的时候,想要听点音乐缓解疲劳,双手正在劳作的他便通过语音向家中的智能音箱点了一首歌,语音指令对应的拼音为“wo yao ting lei yu xin de ji nian”,智能音箱设备通过asr识别成文本“我要听雷雨心的纪念”,其实小王希望播放的是雷雨心演唱的“记念”而非“纪念”。采用本技术实施例提供的所述系统,由于所述知识库中包括歌曲名“记念”,因此可准确识别出该歌曲,正确播放该歌曲。
[0268]
请参考图5,其为本技术的多媒体节目点播系统的语音实体识别模型示意图。在一个示例中,服务端要通过语音实体识别模型和所述知识库,确定目标语音数据中的实体信息,可采用如下处理过程:首先,通过所述语音实体识别模型包括的音频编码模型,确定所述语音数据的音频特征数据;然后,通过所述语音实体识别模型包括的实体解码模型和所述知识库,根据所述音频特征数据,确定所述多媒体节目信息。
[0269]
其中,所述音频编码模型的输入数据可包括音频帧序列,每个音频帧可包括音频信号的声学特征数据等。实体解码模型的输出数据可包括拼音,但在实际应用中,也可以是任何实体的表现形式,如文字、音素等。
[0270]
具体实施时,可先通过音频信号处理模块(梅尔滤波器等),对原始音频信号进行处理,形成音频帧序列。所述音频编码模型,可采用常用的编码模型,模型结构包括但不限于lstm、transformer等;所述实体解码模型的网络结构包括但不限于lstm、transformer等。
[0271]
在一个示例中,通过所述实体解码模型包括的实体候选发音确定模块,根据所述
音频特征数据,确定所述多媒体节目信息的至少一个候选发音;通过所述实体解码模型包括的实体发音确定模块,根据所述知识库,从所述至少一个候选发音中,确定所述多媒体节目信息的发音;根据所述多媒体节目信息的发音,确定所述多媒体节目信息。该模型的输入是音频信号(音频帧序列),输出是音频中包含的实体名称(如拼音序列)。在该模型中,会产生混淆的发音会在解码模型里面产生所有可能发音的候选,然后通过实体知识库来确定更有可能的发音。具体实施时,解码部分可自动找到编码网络的合适位置来生成候选发音。
[0272]
具体实施时,所述根据所述知识库,从所述至少一个候选发音中,确定所述多媒体节目信息的发音,可包括如下子步骤:1)确定所述知识库中的实体的发音与所述候选发音的相似度;2)根据所述相似度,确定所述多媒体节目信息的发音,如将相似度大于相似度阈值的相似度排在高位的候选发音作为所述多媒体节目信息的发音。其中,所述相似度计算部分可以是神经网络自动学习。
[0273]
具体实施时,服务端还可用于从训练数据中学习得到所述语音实体识别模型;其中,所述训练数据包括:音频数据和多媒体节目标注信息。
[0274]
具体实施时,服务端还可用于确定实体知识库和训练数据集,构建所述模型的网络结构;将所述语音数据作为所述模型的输入数据,将所述多媒体节目标注信息作为所述模型的输出数据,根据所述知识库,训练所述模型的网络参数。
[0275]
在一个示例中,若所述知识库中包括同音不同字的节目相关实体,如包括“纪念”和“记念”两首歌曲的歌曲名,则所述知识库还可包括:用户实体、及节目相关实体与用户实体间的实体关系。表2示出了本实施例中的节目相关实体与用户实体间的实体关系。
[0276][0277][0278]
表2、实体关系数据
[0279]
由表2可见,实体关系不仅可以是用户实体与节目实体间的对应关系,还可以是用户实体与节目相关人名间的对应关系。表3示出了本实施例中的用户实体信息。
[0280]
用户实体标识用户账号(淘宝账号)1abdgdf0012hanhao55
…ꢀ
[0281]
表3、用户实体数据
[0282]
在一个示例中,所述节目相关实体与用户实体间的实体关系可采用如下方式确
定:根据用户历史播放信息,确定所述用户实体,并构建所述实体关系。表4示出了本实施例中的用户历史播放信息。
[0283]
播放记录标识用户实体节目相关实体时间1张三记念202005262张三再回首20200315
ꢀ…ꢀꢀ
23李四周杰伦2019023024李四半壶纱20200511
ꢀ…ꢀꢀ
[0284]
表4、用户历史播放数据
[0285]
请参考图6,其为本技术的多媒体节目点播系统的知识图谱示意图。在一个示例中,所述知识库还包括用户类型的实体,用户实体与部分节目相关实体间可具有实体关系,而与其它节目相关实体间并不具有实体关系。例如,用户a点播过歌曲“记念”,则与“记念”有关联关系,与“纪念”没有关联关系。由图6可见,知识图谱描述了实体(点)和实体之间的关系(边),发出音频命令的用户是知识图谱中的实体,同时歌曲也是图谱中的实体,利用用户的历史听歌记录,来确定相同发音的歌曲。此外,还可利用歌曲在播放列表中的共现关系,来确定相同发音的歌曲。
[0286]
相应的,服务端要根据所述多媒体节目信息的发音,确定所述多媒体节目信息,可包括如下子步骤:1)根据所述多媒体节目信息的发音,确定候选实体,如“ji nian”对应“记念”和“纪念”两个候选实体;2)根据用户信息和所述实体关系,从所述候选实体中确定所述多媒体节目信息。例如,最终确定用户a点播歌曲“记念”,而非“记念”。
[0287]
请参考图7,其为本技术的多媒体节目点播系统的又一语音实体识别模型示意图。在一个示例中,服务端具体用于确定所述知识库中实体的发音特征数据;通过所述语音实体识别模型包括的实体解码模型,根据所述音频特征数据和实体发音特征数据,确定所述多媒体节目信息。
[0288]
由图7可见,可通过所述语音实体识别模型包括的音频编码模型,对输入的音频信号(音频帧序列)计算音频特征向量;通过所述语音实体识别模型包括的实体编码模型,对实体名称(如拼音序列)计算特征向量;所述语音实体识别模型可使得音频特征向量和它所包含的实体名称的特征向量距离更近。在图7所示的模型中,特征向量对混淆音不敏感,也就是说虽然有一些音发错了,但是音频计算出来的特征向量仍然比较接近。
[0289]
具体实施时,服务端要通过所述语音实体识别模型包括的实体解码模型,根据所述音频特征数据和实体发音特征数据,确定所述多媒体节目信息,可包括如下子步骤:1)根据所述音频特征数据和实体发音特征数据,确定所述语音数据中的实体与所述知识库中的实体的发音相似度;2)根据所述发音相似度,确定所述多媒体节目信息,如将相似度大于相似度阈值的相似度排在高位的知识库实体作为所述多媒体节目信息。
[0290]
其中,所述音频编码模型和实体解码模型,可采用常用的编码模型,模型结构包括但不限于lstm、transformer等。所述实体解码模型可包括距离函数,通过距离函数可确定所述语音数据中的实体与所述知识库中的实体的发音相似度,该距离函数可以是点乘、欧式距离、余弦距离等。
[0291]
具体实施时,服务端还可用于从训练数据中学习得到所述语音实体识别模型和所述实体发音特征数据;其中,所述训练数据包括:音频数据、实体标注信息和知识库。通过图7所示的模型,可离线计算出来实体的发音特征向量并储存,然后在线和音频特征向量做匹配。
[0292]
在一个示例中,所述知识库包括:同音不同字的节目相关实体,用户实体,节目相关实体与用户实体间的实体关系;所述服务端要构建实体知识库,可包括如下步骤:根据用户历史播放信息,确定所述用户实体,并构建所述实体关系;并具体用于根据所述发音相似度,确定候选实体;根据用户信息和所述实体关系,从所述候选实体中确定所述实体信息。
[0293]
从上述实施例可见,本技术实施例提供的多媒体节目点播系统,通过智能音箱多媒体节目点播语音数据,将所述语音数据发送至服务端;根据服务端的多媒体节目播放处理结果,播放多媒体节目;服务端用于构建多媒体节目知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的多媒体节目信息;根据所述多媒体节目信息,执行多媒体节目播放处理;这种处理方式,使得引入多媒体节目知识图谱信息,直接比对多媒体节目点播语音中是否有知识图谱中的多媒体节目实体发音,实现从语音信号中进行语义理解和实体识别,不再依赖asr将语音转换成为文字,再通过对文字的语义理解识别其中的多媒体节目实体名称,这样更接近于人类理解语音的过程;因此,可以有效提升多媒体节目名识别的准确率,从而提升多媒体节目点播的成功率和准确率。
[0294]
第二实施例
[0295]
在上述的实施例中,提供了一种多媒体节目点播系统,与之相对应的,本技术还提供一种语音交互方法,该方法的执行主体可以是服务端,也可以是智能音箱,智能电视,售卖机,售票机,聊天机器人,等等。该方法是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0296]
本技术实施例提供的所述语音交互方法,可包括如下步骤:
[0297]
步骤1:构建实体知识库;
[0298]
步骤2:通过语音实体识别模型和所述实体知识库,确定目标语音数据中的实体信息;
[0299]
步骤3:根据所述实体信息,执行语音交互处理。
[0300]
在一个示例中,步骤2可包括如下子步骤:
[0301]
步骤2-1:通过所述语音实体识别模型包括的音频编码模型,确定所述语音数据的音频特征数据;
[0302]
步骤2-2:通过所述语音实体识别模型包括的实体解码模型和所述实体知识库,根据所述音频特征数据,确定所述实体信息。
[0303]
在一个示例中,步骤2-2可包括如下子步骤:
[0304]
步骤2-2-1:通过所述实体解码模型包括的实体候选发音确定模块,根据所述音频特征数据,确定所述实体信息的至少一个候选发音;
[0305]
步骤2-2-2:通过所述实体解码模型包括的实体发音确定模块,根据所述实体知识库,从所述至少一个候选发音中,确定所述实体信息的发音;
[0306]
步骤2-2-3:根据所述实体信息的发音,确定所述实体信息。
[0307]
在一个示例中,步骤2-2-2可包括如下子步骤:
[0308]
步骤2-2-2-1:确定所述实体知识库中的实体的发音与所述候选发音的相似度;
[0309]
步骤2-2-2-2:根据所述相似度,确定所述实体信息的发音。
[0310]
在一个示例中,所述实体知识库包括:多媒体节目点播领域的节目实体知识库;所述节目实体知识库包括:同音不同字的节目相关实体,用户实体,节目相关实体与用户实体间的实体关系;步骤1可包括如下子步骤:根据用户历史播放信息,确定所述用户实体,并构建所述实体关系;相应的,步骤2-2-3可包括如下子步骤:
[0311]
步骤2-2-3-1:根据所述实体信息的发音,确定候选实体;
[0312]
步骤2-2-3-2:根据用户信息和所述实体关系,从所述候选实体中确定所述实体信息。
[0313]
在一个示例中,所述方法还可包括如下步骤:从训练数据中学习得到所述语音实体识别模型;其中,所述训练数据包括:音频数据和实体标注信息。
[0314]
在另一个示例中,步骤2-2可包括如下子步骤:
[0315]
步骤2-2-1’:通过所述语音实体识别模型包括的音频编码模型,确定所述语音数据的音频特征数据;
[0316]
步骤2-2-2’:通过所述语音实体识别模型包括的实体编码模型,确定所述实体知识库中实体的发音特征数据;
[0317]
步骤2-2-3’:通过所述语音实体识别模型包括的实体解码模型,根据所述音频特征数据和实体发音特征数据,确定所述实体信息。
[0318]
在一个示例中,步骤2-2-3’可包括如下子步骤:
[0319]
步骤2-2-3
’-
1:根据所述音频特征数据和实体发音特征数据,确定所述语音数据中的实体与所述实体知识库中的实体的发音相似度;
[0320]
步骤2-2-3
’-
2:根据所述发音相似度,确定所述实体信息。
[0321]
在一个示例中,所述实体知识库包括:多媒体节目点播领域的节目实体知识库;所述节目实体知识库包括:同音不同字的节目相关实体,用户实体,节目相关实体与用户实体间的实体关系;步骤1可包括如下子步骤:根据用户历史播放信息,确定所述用户实体,并构建所述实体关系;相应的,步骤2-2-3
’-
2:可包括如下子步骤:
[0322]
步骤2-2-3
’-
2-1:根据所述发音相似度,确定候选实体;
[0323]
步骤2-2-3
’-
2-2:根据用户信息和所述实体关系,从所述候选实体中确定所述实体信息。
[0324]
在一个示例中,所述方法还可包括如下步骤:从训练数据中学习得到所述语音实体识别模型;其中,所述训练数据包括:音频数据、实体知识库和实体标注信息。
[0325]
在一个示例中,所述实体知识库包括:多媒体节目点播领域的节目实体知识库;步骤1可包括如下子步骤:确定多媒体节目相关实体,形成所述实体知识库。
[0326]
第三实施例
[0327]
在上述的实施例中,提供了一种语音交互方法,与之相对应的,本技术还提供一种语音交互装置。该装置是与上述方法的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0328]
本技术提供的一种语音交互装置包括:
[0329]
知识库构建单元,用于构建实体知识库;
[0330]
实体确定单元,用于通过语音实体识别模型和所述实体知识库,确定目标语音数据中的实体信息;
[0331]
交互处理单元,用于根据所述实体信息,执行语音交互处理。
[0332]
第四实施例
[0333]
本技术还提供一种电子设备。由于设备实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的设备实施例仅仅是示意性的。
[0334]
本实施例的一种电子设备,该电子设备包括:处理器和存储器;存储器,用于存储实现语音交互方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:构建实体知识库;通过语音实体识别模型和所述实体知识库,确定目标语音数据中的实体信息;根据所述实体信息,执行语音交互处理。
[0335]
所述电子设备,可以是智能音箱,智能电视,点餐机,售卖机,售票机,聊天机器人,等等。
[0336]
第五实施例
[0337]
在上述的实施例中,提供了一种语音交互系统,与之相对应的,本技术还提供一种语音交互方法,该方法的执行主体可以是智能音箱,智能电视,售卖机,售票机,聊天机器人,等等。该方法是与上述系统的实施例相对应。本实施例与第二实施例内容相同的部分不再赘述,请参见实施例二中的相应部分。
[0338]
本技术提供的一种语音交互方法,可包括如下步骤:采集语音数据,将所述语音数据发送至服务端,以使得服务端构建实体知识库;通过语音实体识别模型和所述实体知识库,确定所述语音数据中的实体信息;根据所述实体信息,执行语音交互处理。
[0339]
第六实施例
[0340]
在上述的实施例中,提供了一种语音交互方法,与之相对应的,本技术还提供一种语音交互装置。该装置是与上述方法的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0341]
本技术提供的一种语音交互装置包括:
[0342]
语音数据采集单元,用于采集语音数据;
[0343]
语音数据发送单元,用于将所述语音数据发送至服务端,以使得服务端构建实体知识库;通过语音实体识别模型和所述实体知识库,确定所述语音数据中的实体信息;根据所述实体信息,执行语音交互处理。
[0344]
第七实施例
[0345]
本技术还提供一种电子设备。由于设备实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的设备实施例仅仅是示意性的。
[0346]
本实施例的一种电子设备,该电子设备包括:处理器和存储器;存储器,用于存储实现语音交互方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:采集语音数据,将所述语音数据发送至服务端,以使得服务端构建实体知识库;通过语音实体识别模型和所述实体知识库,确定所述语音数据中的实体信息;根据所述实体信息,执行语音交互处理。
[0347]
第八实施例
[0348]
在上述的实施例中,提供了一种多媒体节目点播系统,与之相对应的,本技术还提供一种语音交互系统。该系统是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0349]
本技术提供的一种语音交互系统包括:终端设备和服务端。
[0350]
其中,终端设备用于采集语音数据,将所述语音数据发送至服务端;服务端用于构建实体知识库;通过语音实体识别模型和所述实体知识库,确定所述语音数据中的实体信息;根据所述实体信息,执行语音交互处理。
[0351]
第九实施例
[0352]
在上述的实施例中,提供了一种多媒体节目点播系统,与之相对应的,本技术还提供一种多媒体节目点播方法,该方法的执行主体可以是智能音箱等等。该方法是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0353]
本技术提供的一种多媒体节目点播方法,可包括如下步骤:采集多媒体节目点播语音数据,将所述语音数据发送至服务端,以使得服务端构建多媒体节目知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的多媒体节目信息;根据所述多媒体节目信息,执行多媒体节目播放处理。
[0354]
第十实施例
[0355]
在上述的实施例中,提供了一种多媒体节目点播方法,与之相对应的,本技术还提供一种多媒体节目点播装置。该装置是与上述方法的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0356]
本技术提供的一种多媒体节目点播装置包括:
[0357]
语音数据采集单元,用于采集多媒体节目点播语音数据;
[0358]
语音数据发送单元,用于将所述语音数据发送至服务端,以使得服务端构建多媒体节目知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的多媒体节目信息;根据所述多媒体节目信息,执行多媒体节目播放处理。
[0359]
第十一实施例
[0360]
本技术还提供一种智能音箱。由于设备实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的设备实施例仅仅是示意性的。
[0361]
本实施例的一种智能音箱,该智能音箱包括:处理器和存储器;存储器,用于存储实现多媒体节目点播方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:采集多媒体节目点播语音数据,将所述语音数据发送至服务端,以使得服务端构建多媒体节目知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的多媒体节目信息;根据所述多媒体节目信息,执行多媒体节目播放处理。
[0362]
第十二实施例
[0363]
在上述的实施例中,提供了一种多媒体节目点播系统,与之相对应的,本技术还提供一种多媒体节目点播方法,该方法的执行主体可以是服务端等等。该方法是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的
相应部分。
[0364]
本技术提供的一种多媒体节目点播方法,可包括如下步骤:
[0365]
步骤1:构建多媒体节目知识库;
[0366]
步骤2:通过语音实体识别模型和所述知识库,确定多媒体节目点播语音数据中的多媒体节目信息;
[0367]
步骤3:根据所述多媒体节目信息,执行多媒体节目播放处理。
[0368]
第十三实施例
[0369]
在上述的实施例中,提供了一种多媒体节目点播方法,与之相对应的,本技术还提供一种多媒体节目点播装置。该装置是与上述方法的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0370]
本技术提供的一种多媒体节目点播装置包括:
[0371]
知识库构建单元,用于构建多媒体节目知识库;
[0372]
实体识别单元,用于通过语音实体识别模型和所述知识库,确定多媒体节目点播语音数据中的多媒体节目信息;
[0373]
节目播放处理单元,用于根据所述多媒体节目信息,执行多媒体节目播放处理。
[0374]
第十四实施例
[0375]
本技术还提供一种电子设备。由于设备实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的设备实施例仅仅是示意性的。
[0376]
本实施例的一种电子设备,该电子设备包括:处理器和存储器;存储器,用于存储实现多媒体节目点播方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:构建多媒体节目知识库;通过语音实体识别模型和所述知识库,确定多媒体节目点播语音数据中的多媒体节目信息;根据所述多媒体节目信息,执行多媒体节目播放处理。
[0377]
第十五实施例
[0378]
在上述的实施例中,提供了一种多媒体节目点播系统,与之相对应的,本技术还提供一种语音实体识别模型构建方法,该方法的执行主体可以是服务端等等。该方法是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0379]
本技术提供的一种语音实体识别模型构建方法,可包括如下步骤:
[0380]
步骤1:确定训练数据集,所述训练数据包括:语音数据、实体标注信息和实体知识库;
[0381]
步骤2:构建所述模型的网络结构;
[0382]
步骤3:从训练数据集中学习得到所述模型。
[0383]
在一个示例中,所述模型包括音频编码模型,用于确定所述语音数据的音频特征数据;所述模型包括实体解码模型,根据所述音频特征数据和所述实体知识库,确定所述语音数据中的实体信息。
[0384]
在另一个示例中,所述模型包括音频编码模型,用于确定所述语音数据的音频特征数据;所述模型包括实体编码模型,用于确定所述实体知识库中实体的发音特征数据;所
述模型包括实体解码模型,用于根据所述音频特征数据和实体发音特征数据,确定所述语音数据中的实体信息。
[0385]
从上述实施例可见,本技术实施例提供的语音实体识别模型构建方法,通过确定训练数据集,所述训练数据包括:语音数据、实体标注信息和实体知识库;构建所述模型的网络结构;从训练数据集中学习得到所述模型;这种处理方式,使得引入实体知识图谱信息,直接比对语音中是否有知识图谱中的实体发音,实现从语音信号中进行语义理解和实体识别,不再依赖asr将语音转换成为文字,再通过对文字的语义理解识别其中的实体名称,这样更接近于人类理解语音的过程;因此,可以有效提升语音实体识别模型的准确率。
[0386]
第十六实施例
[0387]
在上述的实施例中,提供了一种多媒体节目点播方法,与之相对应的,本技术还提供一种多媒体节目点播装置。该装置是与上述方法的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0388]
本技术提供的一种多媒体节目点播装置包括:
[0389]
训练数据确定单元,用于确定训练数据集,所述训练数据包括:语音数据、实体标注信息和实体知识库;
[0390]
网络构建单元,用于构建所述模型的网络结构;
[0391]
模型训练单元,用于从训练数据集中学习得到所述模型。
[0392]
第十七实施例
[0393]
本技术还提供一种电子设备。由于设备实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的设备实施例仅仅是示意性的。
[0394]
本实施例的一种电子设备,该电子设备包括:处理器和存储器;存储器,用于存储实现语音实体识别模型构建方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:确定训练数据集,所述训练数据包括:语音数据、实体标注信息和实体知识库;构建所述模型的网络结构;从训练数据集中学习得到所述模型。
[0395]
第十八实施例
[0396]
在上述的实施例中,提供了一种多媒体节目点播系统,与之相对应的,本技术还提供一种实体知识库构建方法,该方法的执行主体可以是服务端等等。该方法是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0397]
本技术提供的一种实体知识库构建方法,可包括如下步骤:
[0398]
步骤1:获取目标领域的实体名;
[0399]
步骤2:根据所述实体名,生成目标领域的实体知识库,所述实体知识库用于通过语音实体识别模型和所述实体知识库,确定目标领域的语音数据中的实体信息。
[0400]
所述目标领域包括但不限于:多媒体节目点播领域,点餐领域,通讯领域,等等。
[0401]
从上述实施例可见,本技术实施例提供的实体知识库构建方法,通过获取目标领域的实体名;根据所述实体名,生成目标领域的实体知识库,所述实体知识库用于通过语音实体识别模型和所述实体知识库,确定目标领域的语音数据中的实体信息;这种处理方式,使得可构建实体知识图谱信息,为构建语音实体识别模型打好数据基础,该模型可引入实
体知识图谱信息,直接比对语音中是否有知识图谱中的实体发音,实现从语音信号中进行语义理解和实体识别,不再依赖asr将语音转换成为文字,再通过对文字的语义理解识别其中的实体名称,这样更接近于人类理解语音的过程;因此,可以有效提升语音实体识别模型的准确率。
[0402]
第十九实施例
[0403]
在上述的实施例中,提供了一种实体知识库构建方法,与之相对应的,本技术还提供一种实体知识库构建装置。该装置是与上述方法的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0404]
本技术提供的一种实体知识库构建装置包括:
[0405]
实体确定单元,用于获取目标领域的实体名;
[0406]
知识库生成单元,用于生成目标领域的实体知识库,所述实体知识库用于通过语音实体识别模型和所述实体知识库,确定目标领域的语音数据中的实体信息。
[0407]
第二十实施例
[0408]
本技术还提供一种电子设备。由于设备实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的设备实施例仅仅是示意性的。
[0409]
本实施例的一种电子设备,该电子设备包括:处理器和存储器;存储器,用于存储实现实体知识库构建方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:获取目标领域的实体名;根据所述实体名,生成目标领域的实体知识库,所述实体知识库用于通过语音实体识别模型和所述实体知识库,确定目标领域的语音数据中的实体信息。
[0410]
第二十一实施例
[0411]
在上述的实施例中,提供了一种多媒体节目点播系统,与之相对应的,本技术还提供一种语音实体识别方法,该方法的执行主体可以是服务端等等。该方法是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0412]
本技术提供的一种语音实体识别方法,可包括如下步骤:
[0413]
步骤1:构建实体知识库和语音实体识别模型;
[0414]
步骤2:确定目标语音数据;
[0415]
步骤3:通过所述语音实体识别模型和实体知识库,确定目标语音数据中的实体信息。
[0416]
从上述实施例可见,本技术实施例提供的语音实体识别方法,通过构建实体知识库和语音实体识别模型;确定目标语音数据;通过所述语音实体识别模型和实体知识库,确定目标语音数据中的实体信息;这种处理方式,使得可构建实体知识图谱信息,为构建语音实体识别模型打好数据基础,该模型可引入实体知识图谱信息,直接比对语音中是否有知识图谱中的实体发音,实现从语音信号中进行语义理解和实体识别,不再依赖asr将语音转换成为文字,再通过对文字的语义理解识别其中的实体名称,这样更接近于人类理解语音的过程;因此,可以有效提升语音实体识别的准确率。
[0417]
第二十二实施例
[0418]
在上述的实施例中,提供了一种语音实体识别方法,与之相对应的,本技术还提供一种语音实体识别装置。该装置是与上述方法的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0419]
本技术提供的一种语音实体识别装置包括:
[0420]
模型构建单元,用于语音实体识别模型;
[0421]
知识库构建单元,用于构建实体知识库;
[0422]
语音数据确定单元,用于确定目标语音数据;
[0423]
实体确定单元,用于通过所述语音实体识别模型和实体知识库,确定目标语音数据中的实体信息。
[0424]
第二十三实施例
[0425]
本技术还提供一种电子设备。由于设备实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的设备实施例仅仅是示意性的。
[0426]
本实施例的一种电子设备,该电子设备包括:处理器和存储器;存储器,用于存储实现语音实体识别方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:构建实体知识库和语音实体识别模型;确定目标语音数据;通过所述语音实体识别模型和实体知识库,确定目标语音数据中的实体信息。
[0427]
第二十四实施例
[0428]
在上述的实施例中,提供了一种多媒体节目点播系统,与之相对应的,本技术还提供一种点餐系统。该系统是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0429]
本技术提供的一种点餐系统包括:点餐设备和服务端。
[0430]
其中,点餐设备用于采集点餐语音数据,将所述语音数据发送至服务端;服务端用于构建餐品知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的餐品信息;根据所述餐品信息,执行备餐处理。
[0431]
所述餐品知识库,可包括各种菜品名,如新奥尔良汉堡、薯条、拿铁咖啡等。
[0432]
所述执行备餐处理,可以是将点餐信息发送到后厨间,也可以是将点餐信息发送到前台售卖人员,等等。
[0433]
例如,用户通过点餐设备进行语音点餐,向点餐设备发出点餐语音指令“一个新奥尔良汉堡和一个拿铁咖啡”,但是由于该用户口齿不清,因此无法通过传统的语音识别算法识别出准确的文本,有可能识别成了其他餐品名,或者无法确定用户点的是哪种餐品;而采用本技术实施例提供的系统,可通过语音实体识别模型和餐品知识库,直接根据用户点餐语音指令,准确地确定出餐品信息。
[0434]
从上述实施例可见,本技术实施例提供的点餐系统,通过点餐设备采集点餐语音数据,将所述语音数据发送至服务端;服务端构建餐品知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的餐品信息;根据所述餐品信息,执行备餐处理;这种处理方式,使得引入餐品知识图谱信息,直接比对点餐语音中是否有知识图谱中的餐品名发音,实现从点餐语音信号中进行语义理解和餐品名识别,不再依赖asr将语音转换成为文字,再通过对文字的语义理解识别其中的餐品名称,这样更接近于人类理解语音的过程;因此,可
以有效提升餐品名识别的准确率,从而提升点餐成功率和准确率。
[0435]
第二十五实施例
[0436]
在上述的实施例中,提供了一种点餐系统,与之相对应的,本技术还提供一种点餐方法,该方法的执行主体可以是点餐设备等等。该方法是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0437]
本技术提供的一种点餐方法,可包括如下步骤:采集点餐语音数据,将所述语音数据发送至服务端,以使得服务端构建餐品知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的餐品信息;根据所述餐品信息,执行备餐处理。
[0438]
第二十六实施例
[0439]
在上述的实施例中,提供了一种点餐方法,与之相对应的,本技术还提供一种点餐装置。该装置是与上述方法的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0440]
本技术提供的一种点餐装置包括:
[0441]
语音数据采集单元,用于采集点餐语音数据;
[0442]
语音数据发送单元,用于将所述语音数据发送至服务端,以使得服务端构建餐品知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的餐品信息;根据所述餐品信息,执行备餐处理。
[0443]
第二十七实施例
[0444]
本技术还提供一种点餐设备。由于设备实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的设备实施例仅仅是示意性的。
[0445]
本实施例的一种点餐设备,该点餐设备包括:处理器和存储器;存储器,用于存储实现点餐方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:采集点餐语音数据,将所述语音数据发送至服务端,以使得服务端构建餐品知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的餐品信息;根据所述餐品信息,执行备餐处理。
[0446]
第二十八实施例
[0447]
在上述的实施例中,提供了一种点餐系统,与之相对应的,本技术还提供一种点餐方法,该方法的执行主体可以是服务端等等。该方法是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0448]
本技术提供的一种点餐方法,可包括如下步骤:
[0449]
步骤1:构建餐品知识库;
[0450]
步骤2:通过语音实体识别模型和所述实体知识库,确定点餐语音数据中的餐品信息;
[0451]
步骤3:根据所述餐品信息,执行备餐处理。
[0452]
第二十九实施例
[0453]
在上述的实施例中,提供了一种点餐方法,与之相对应的,本技术还提供一种点餐装置。该装置是与上述方法的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0454]
本技术提供的一种点餐装置包括:
[0455]
知识库构建单元,用于构建餐品知识库;
[0456]
实体识别单元,用于通过语音实体识别模型和所述实体知识库,确定点餐语音数据中的餐品信息;
[0457]
备餐处理单元,用于根据所述餐品信息,执行备餐处理。
[0458]
第三十实施例
[0459]
本技术还提供一种电子设备。由于设备实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的设备实施例仅仅是示意性的。
[0460]
本实施例的一种电子设备,该电子设备包括:处理器和存储器;存储器,用于存储实现点餐方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:构建餐品知识库;通过语音实体识别模型和所述实体知识库,确定点餐语音数据中的餐品信息;根据所述餐品信息,执行备餐处理。
[0461]
第三十一实施例
[0462]
在上述的实施例中,提供了一种多媒体节目点播系统,与之相对应的,本技术还提供一种通讯连接建立系统。该系统是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0463]
本技术提供的一种通讯连接建立系统包括:用户设备和服务端。
[0464]
其中,用户设备用于采集通讯指令语音数据,将所述语音数据发送至服务端;服务端用于构建通讯用户知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的通讯用户信息;根据所述通讯用户信息,执行通讯连接建立处理。
[0465]
所述通讯用户知识库,可包括联系人姓名等用户实体信息。
[0466]
所述用户设备,可以是手机、智能手机、智能音箱等移动通讯设备。
[0467]
所述通讯连接建立处理,可以是拨打通讯用户的电话号码等处理。
[0468]
例如,用户向智能手机发出打电话给某人的语音指令“给梓豪打电话”,但是由于该用户口齿不清,因此无法通过传统的语音识别算法识别出准确的人名,有可能识别成了其他人名;而采用本技术实施例提供的系统,可通过语音实体识别模型和通讯用户知识库,直接根据用户打电话语音指令,准确地确定出人名信息。
[0469]
在一个示例中,通讯用户知识库可包括“梓豪”和“子豪”,而用户a要打给“梓豪”,这是可在通讯用户知识库中存储用户a与“梓豪”间的对应关系,这样就不会识别成“子豪”,因此,可以有效提升通话准确率。
[0470]
从上述实施例可见,本技术实施例提供的通讯连接建立系统,通过用户设备采集通讯指令语音数据,将所述语音数据发送至服务端;服务端构建通讯用户知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的通讯用户信息;根据所述通讯用户信息,执行通讯连接建立处理;这种处理方式,使得引入联系人图谱信息,直接比对打电话指令语音中是否有知识图谱中的人名发音,实现从打电话指令语音信号中进行语义理解和餐品名识别,不再依赖asr将语音转换成为文字,再通过对文字的语义理解识别其中的人名,这样更接近于人类理解语音的过程;因此,可以有效提升人名识别的准确率,从而提升通讯成功率和准确率。
[0471]
第三十二实施例
[0472]
在上述的实施例中,提供了一种通讯连接建立系统,与之相对应的,本技术还提供一种通讯连接建立方法,该方法的执行主体可以是用户设备等等。该方法是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0473]
本技术提供的一种通讯连接建立方法,可包括如下步骤:采集通讯指令语音数据,将所述语音数据发送至服务端,以使得服务端构建通讯用户知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的通讯用户信息;根据所述通讯用户信息,执行通讯连接建立处理。
[0474]
第三十三实施例
[0475]
在上述的实施例中,提供了一种通讯连接建立方法,与之相对应的,本技术还提供一种通讯连接建立装置。该装置是与上述方法的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0476]
本技术提供的一种通讯连接建立装置包括:
[0477]
语音数据采集单元,用于采集通讯指令语音数据;
[0478]
语音数据发送单元,用于将所述语音数据发送至服务端,以使得服务端构建通讯用户知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的通讯用户信息;根据所述通讯用户信息,执行通讯连接建立处理。
[0479]
第三十四实施例
[0480]
本技术还提供一种用户设备。由于设备实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的设备实施例仅仅是示意性的。
[0481]
本实施例的一种用户设备,该用户设备包括:处理器和存储器;存储器,用于存储实现通讯连接建立方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:采集通讯指令语音数据,将所述语音数据发送至服务端,以使得服务端构建通讯用户知识库;通过语音实体识别模型和所述知识库,确定所述语音数据中的通讯用户信息;根据所述通讯用户信息,执行通讯连接建立处理。
[0482]
第三十五实施例
[0483]
在上述的实施例中,提供了一种通讯连接建立系统,与之相对应的,本技术还提供一种通讯连接建立方法,该方法的执行主体可以是服务端等等。该方法是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0484]
本技术提供的一种通讯连接建立方法,可包括如下步骤:
[0485]
步骤1:构建通讯用户知识库;
[0486]
步骤2:通过语音实体识别模型和所述知识库,确定通讯指令语音数据中的通讯用户信息;
[0487]
步骤3:根据所述通讯用户信息,执行通讯连接建立处理。
[0488]
第三十六实施例
[0489]
在上述的实施例中,提供了一种通讯连接建立方法,与之相对应的,本技术还提供
一种通讯连接建立装置。该装置是与上述方法的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0490]
本技术提供的一种通讯连接建立装置包括:
[0491]
知识库构建单元,用于构建通讯用户知识库;
[0492]
实体识别单元,用于通过语音实体识别模型和所述知识库,确定通讯指令语音数据中的通讯用户信息;
[0493]
通讯连接处理单元,用于根据所述通讯用户信息,执行通讯连接建立处理。
[0494]
第三十七实施例
[0495]
本技术还提供一种电子设备。由于设备实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的设备实施例仅仅是示意性的。
[0496]
本实施例的一种电子设备,该电子设备包括:处理器和存储器;存储器,用于存储实现点餐方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:构建通讯用户知识库;通过语音实体识别模型和所述知识库,确定通讯指令语音数据中的通讯用户信息;根据所述通讯用户信息,执行通讯连接建立处理。
[0497]
第三十八实施例
[0498]
在上述的实施例中,提供了一种多媒体节目点播系统,与之相对应的,本技术还提供一种电视节目播放系统。该系统是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0499]
本技术提供的一种电视节目播放系统包括:智能电视和服务端。
[0500]
其中,智能电视用于采集用户的节目播放语音指令数据,将所述语音指令数据发送至服务端,播放目标节目对象;服务端用于构建电视节目知识库;通过语音实体识别模型和所述知识库,确定与所述语音指令数据对应的目标节目名;根据所述目标节目名,执行目标节目对象播放处理。
[0501]
所述电视节目知识库,包括节目相关实体,如电视节目名、演员名、频道名等与电视节目播放有关的实体词汇。
[0502]
在本实施例中,智能电视可通过遥控器等装置采集用户的节目播放语音指令数据,如用户发出语音指令“我想看哪吒”,但用户口齿不清,实际发音为“我要看那个站”;服务端通过语音实体识别模型和所述知识库,可识别出节目名为“哪吒”。本步骤的语音实体识别的具体实施方式可参见实施例一的相关说明,此处不再赘述。服务端确定目标节目名后,就可以执行目标节目对象播放处理,如将该节目的视频流发送至请求方的设备,通过终端设备播放目标节目对象。
[0503]
在一个示例中,所述知识库可包括同音不同字的节目相关实体,如发音相同的电影名等;相应的,所述知识库还包括用户实体、及同音不同字的节目相关实体与用户实体间的实体关系,即知识库包括用户和其曾经看过的电视节目之间的关系;相应的,服务端可采用实施例一中的相关处理方式,根据该对应关系识别出用户真正要看的电影名,而非相同发音的其它电影名,这样就可以有效提升节目名准确率。本步骤的语音实体识别的具体实施方式可参见实施例一的相关说明,此处不再赘述。
[0504]
在一个示例中,服务端要根据所述目标节目名,执行目标节目对象播放处理,可采
用如下处理方式:首先,根据各个电视频道的节目表(如最近一周的节目表,可包括最近一周播放的节目信息和当前正在播放的节目信息),确定与所述目标节目名相关的电视频道和播放时间;然后,根据所述播放时间和所述电视频道,确定目标节目对象;最后,再播放所述目标节目对象。
[0505]
以某地区有线电视为例,用户对遥控器说“我要看那个站”,遥控器首先识别出用户想要点播或回看的节目名为“哪吒”,然后,可根据一周内可回看的电视节目表,从中查找哪个频道、何时播放了“哪吒”,如果找到了,就可播放这个可回看的节目对象或者相关频道当前正在播放的节目对象。下表示出了本实施例中的节目表。
[0506][0507][0508]
如上表所示,与识别出的目标节目名对应的节目对象可包括多个节目对象,如6月1日播放了电影版“哪吒”,3日播放了上海人民美术制片厂制作的动画片版“哪吒”,5日播放了52集版本的动画片“哪吒”。在这种情况下,服务端可向智能电视发送与所述目标节目名对应的至少一个电视频道在多个时间播放的多个节目对象,智能电视显示这些节目对象;用户可通过智能电视指定目标节目对象;服务端根据用户请求,再将用户指定的目标节目对象的视频流发送至智能电视播放。采用这种处理方式,使得可在电视屏幕上显示所有相关的节目对象,供用户选择,然后播放用户指定的目标节目对象。
[0509]
具体实施时,服务端如果检测到所述节目表不包括所述目标节目名,则了确定与所述目标节目名相关的节目名;显示相关节目名;若用户指定播放相关节目对象,则播放相关节目对象。采用这种处理方式,使得如果没找到用户先要观看的节目,则还可向用户推荐相关的电视节目,如用户想要看“印象西湖”纪录片,但近一周并没有播放该纪录片,则可以播放有关西湖的其他节目,如“解密灵隐寺”、“西湖十景”、“顾景舟”等节目。
[0510]
从上述实施例可见,本技术实施例提供的电视节目播放系统,通过智能电视用于采集用户的节目播放语音指令数据,将所述语音指令数据发送至服务端,播放目标节目对象;服务端用于构建电视节目知识库;通过语音实体识别模型和所述知识库,确定与所述语音指令数据对应的目标节目名;根据所述目标节目名,执行目标节目对象播放处理;这种处理方式,使得引入节目相关实体图谱信息,直接比对节目播放语音指令中是否有知识图谱中的节目相关实体发音,实现从节目播放语音指令信号中进行语义理解和节目名等实体的识别,不再依赖asr将语音转换成为文字,再通过对文字的语义理解识别其中的节目名,这样更接近于人类理解语音的过程;因此,可以有效提升节目实体识别的准确率,从而提升电视节目点播的成功率和准确率。
[0511]
第三十九实施例
[0512]
在上述的实施例中,提供了一种电视节目播放系统,与之相对应的,本技术还提供一种电视节目播放方法,该方法的执行主体可以是智能电视、电视遥控器等。该方法是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0513]
本技术提供的一种电视节目播放方法,可包括如下步骤:
[0514]
步骤1:采集用户的节目播放语音指令数据;
[0515]
步骤2:将所述语音指令数据发送至服务端,以便于服务端构建电视节目知识库;通过语音实体识别模型和所述知识库,确定与所述语音指令数据对应的目标节目名;根据所述目标节目名,执行目标节目对象播放处理;
[0516]
步骤3:播放目标节目对象。
[0517]
第四十实施例
[0518]
在上述的实施例中,提供了一种电视节目播放方法,与之相对应的,本技术还提供一种电视节目播放装置。该装置是与上述方法的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0519]
本技术提供的一种电视节目播放装置包括:
[0520]
语音数据采集单元,用于采集用户的节目播放语音指令数据;
[0521]
语音数据发送单元,用于将所述语音指令数据发送至服务端,以便于服务端构建电视节目知识库;通过语音实体识别模型和所述知识库,确定与所述语音指令数据对应的目标节目名;根据所述目标节目名,执行目标节目对象播放处理;
[0522]
节目播放单元,用于播放目标节目对象。
[0523]
第四十一实施例
[0524]
本技术还提供一种智能电视。由于设备实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的设备实施例仅仅是示意性的。
[0525]
本实施例的一种智能电视,该智能电视包括:处理器和存储器;存储器,用于存储实现电视节目播放方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:采集用户的节目播放语音指令数据;将所述语音指令数据发送至服务端,以便于服务端构建电视节目知识库;通过语音实体识别模型和所述知识库,确定与所述语音指令数据对应的目标节目名;根据所述目标节目名,执行目标节目对象播放处理;播放目标节目对象。
[0526]
第四十二实施例
[0527]
本技术还提供一种遥控器。由于设备实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的设备实施例仅仅是示意性的。
[0528]
本实施例的一种遥控器,该遥控器包括:处理器和存储器;存储器,用于存储实现电视节目播放方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:采集用户的节目播放语音指令数据;将所述语音指令数据发送至服务端,以便于服务端构建电视节目知识库;通过语音实体识别模型和所述知识库,确定与所述语音指令数据
对应的目标节目名;根据所述目标节目名,执行目标节目对象播放处理。
[0529]
第四十三实施例
[0530]
在上述的实施例中,提供了一种电视节目播放系统,与之相对应的,本技术还提供一种电视节目播放方法,该方法的执行主体可以是服务端、智能电视等。该方法是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0531]
本技术提供的一种电视节目播放方法,可包括如下步骤:
[0532]
步骤1:构建电视节目知识库;
[0533]
步骤2:通过语音实体识别模型和所述知识库,确定与目标节目播放语音指令数据对应的目标节目名;
[0534]
步骤3:根据所述目标节目名,执行目标节目对象播放处理。
[0535]
在一个示例中,所述知识库包括但不限于:同音不同字的节目相关实体,用户实体,节目相关实体与用户实体间的实体关系;步骤1可采用如下方式是实现:根据用户历史播放信息,确定所述用户实体,并构建所述实体关系。
[0536]
在一个示例中,步骤3可包括如下子步骤:3.1)根据节目表,确定与所述目标节目名对应的电视频道和播放时间;3.2)根据所述播放时间和所述电视频道,确定目标节目对象;3.3)执行播放所述目标节目对象的处理。
[0537]
具体实施时,如果所述方法的执行主体为服务端,则可将目标节目对象的视频流发送至智能电视播放;如果所述方法的执行主体为智能电视,则可播放目标节目对象。
[0538]
在一个示例中,步骤3.2可包括如下子步骤:3.2.1)显示与所述目标节目名对应的至少一个电视频道在多个时间播放的多个节目对象;3.2.2)将用户指定的节目对象作为目标节目对象。
[0539]
具体实施时,如果所述方法的执行主体为服务端,则可将与所述目标节目名对应的至少一个电视频道在多个时间播放的多个节目对象发送至智能电视显示;如果所述方法的执行主体为智能电视,则可直接显示与所述目标节目名对应的至少一个电视频道在多个时间播放的多个节目对象。
[0540]
在一个示例中,步骤3.2可包括如下子步骤:3.2.3)若所述节目表不包括所述目标节目名,则确定与所述目标节目名相关的节目名;3.2.4)显示相关节目名;3.2.5)若用户指定播放相关节目对象,则执行播放相关节目对象的处理。
[0541]
具体实施时,如果所述方法的执行主体为服务端,则可将相关节目名发送至智能电视显示;如果所述方法的执行主体为智能电视,则可直接显示相关节目名。
[0542]
第四十四实施例
[0543]
在上述的实施例中,提供了一种电视节目播放方法,与之相对应的,本技术还提供一种电视节目播放装置。该装置是与上述方法的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0544]
本技术提供的一种电视节目播放装置包括:
[0545]
知识库构建单元,用于构建电视节目知识库;
[0546]
实体识别单元,用于通过语音实体识别模型和所述知识库,确定与目标节目播放语音指令数据对应的目标节目名;
[0547]
播放处理单元,用于根据所述目标节目名,执行目标节目对象播放处理。
[0548]
第四十五实施例
[0549]
本技术还提供一种电子设备。由于设备实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的设备实施例仅仅是示意性的。
[0550]
本实施例的一种电子设备,该电子设备包括:处理器和存储器;存储器,用于存储实现电视节目播放方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:构建电视节目知识库;通过语音实体识别模型和所述知识库,确定与目标节目播放语音指令数据对应的目标节目名;根据所述目标节目名,执行目标节目对象播放处理。
[0551]
第四十六实施例
[0552]
在上述的实施例中,提供了一种多媒体节目点播系统,与之相对应的,本技术还提供一种会议记录系统。该系统是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0553]
本技术提供的一种会议记录系统包括:终端设备和服务端。
[0554]
其中,终端设备用于采集目标会议的语音数据,将所述语音数据发送至服务端;服务端用于构建会议领域的语言知识库;通过语音实体识别模型和所述会议领域的语言知识库,确定目标会议语音数据中的实体信息;通过语音识别模型和所述实体信息,确定与所述会议语音数据对应的文本序列,形成会议记录。
[0555]
所述会议领域的语言知识库,包括但不限于:相应领域的专业术语等实体词汇。也就是说,目标会议语音数据中的实体信息可以是相应领域的专业术语。
[0556]
所述会议领域,可以是各种应用领域,如计算机领域、医学领域、法律领域、专利领域等。具体实施时,可以构建多个会议领域的语言知识库,如计算机领域的语言知识库、医学领域的语言知识库、法律领域的语言知识库、专利领域的语言知识库等。
[0557]
具体实施时,针对一个会议领域,可以根据该领域的各种文字资料、多媒体资料,确定该领域的语言知识,形成相应的语言知识库。
[0558]
以某个计算机领域国际会议为例,会议语言为英文,参会者包括来自多国的技术人员,而有些人员的专业词汇英语发音并不清楚、准确。采用本技术实施例提供的系统,可通过会议现场的终端设备采集会议发言人的语音数据,并通过服务端通过语音实体识别模型和该会议领域的语言知识库(包括该领域的各种术语),确定现场采集的会议语音数据中的该领域术语词汇(实体信息),并通过语音识别模型和识别出的术语词汇,确定与所述会议语音数据对应的文本序列,形成会议记录。
[0559]
在一个示例中,服务端还用于确定与会议语音数据对应的会议领域。具体实施时,可以由用户指定会议领域,如在启动会议记录时指定会议领域;也可以是通过其它方式自动确定会议领域。
[0560]
从上述实施例可见,本技术实施例提供的会议记录系统,通过终端设备采集目标会议的语音数据,将所述语音数据发送至服务端;服务端构建会议领域的语言知识库;通过语音实体识别模型和所述会议领域的语言知识库,确定目标会议语音数据中的实体信息;通过语音识别模型和所述实体信息,确定与所述会议语音数据对应的文本序列,形成会议记录;这种处理方式,使得引入会议领域相关术语等实体图谱信息,直接比对会议语音数据
中是否有知识图谱中的会议领域相关术语等实体的发音,实现从会议语音数据信号中进行语义理解和会议领域相关术语等实体的识别,不再依赖asr将语音转换成为文字,再通过对文字的语义理解识别其中的会议领域相关术语,这样更接近于人类理解语音的过程;因此,可以有效提升会议领域相关术语识别的准确率,从而提升会议记录了的成功率和准确率。
[0561]
第四十七实施例
[0562]
在上述的实施例中,提供了一种会议记录系统,与之相对应的,本技术还提供一种会议记录方法,该方法的执行主体可以是庭审一体机等终端设备。该方法是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0563]
本技术提供的一种会议记录方法,可包括如下步骤:
[0564]
步骤1:采集目标会议的语音数据;
[0565]
步骤2:将所述语音数据发送至服务端,以便于服务端构建会议领域的语言知识库;通过语音实体识别模型和所述会议领域的语言知识库,确定目标会议语音数据中的实体信息;通过语音识别模型和所述实体信息,确定与所述会议语音数据对应的文本序列,形成会议记录。
[0566]
第四十八实施例
[0567]
在上述的实施例中,提供了一种会议记录方法,与之相对应的,本技术还提供一种会议记录装置。该装置是与上述方法的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0568]
本技术提供的一种会议记录装置包括:
[0569]
语音数据采集单元,用于采集目标会议的语音数据;
[0570]
语音数据发送单元,用于将所述语音数据发送至服务端,以便于服务端构建会议领域的语言知识库;通过语音实体识别模型和所述会议领域的语言知识库,确定目标会议语音数据中的实体信息;通过语音识别模型和所述实体信息,确定与所述会议语音数据对应的文本序列,形成会议记录。
[0571]
第四十九实施例
[0572]
本技术还提供一种电子设备。由于设备实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的设备实施例仅仅是示意性的。
[0573]
本实施例的一种电子设备,该电子设备包括:处理器和存储器;存储器,用于存储实现会议记录方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:采集目标会议的语音数据;将所述语音数据发送至服务端,以便于服务端构建会议领域的语言知识库;通过语音实体识别模型和所述会议领域的语言知识库,确定目标会议语音数据中的实体信息;通过语音识别模型和所述实体信息,确定与所述会议语音数据对应的文本序列,形成会议记录。
[0574]
第五十实施例
[0575]
在上述的实施例中,提供了一种会议记录系统,与之相对应的,本技术还提供一种会议记录方法,该方法的执行主体可以是服务端、庭审一体机等。该方法是与上述系统的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应
部分。
[0576]
本技术提供的一种会议记录方法,可包括如下步骤:
[0577]
步骤1:构建会议领域的语言知识库;
[0578]
步骤2:通过语音实体识别模型和所述会议领域的语言知识库,确定目标会议语音数据中的实体信息;
[0579]
步骤3:通过语音识别模型和所述实体信息,确定与所述会议语音数据对应的文本序列,形成会议记录。
[0580]
在一个示例中,所述方法还可包括如下步骤:确定与会议语音数据对应的会议领域。
[0581]
第五十一实施例
[0582]
在上述的实施例中,提供了一种会议记录方法,与之相对应的,本技术还提供一种会议记录装置。该装置是与上述方法的实施例相对应。本实施例与第一实施例内容相同的部分不再赘述,请参见实施例一中的相应部分。
[0583]
本技术提供的一种会议记录装置包括:
[0584]
知识库构建单元,用于构建会议领域的语言知识库;
[0585]
实体识别单元,用于通过语音实体识别模型和所述会议领域的语言知识库,确定目标会议语音数据中的实体信息;
[0586]
会议记录确定单元,用于通过语音识别模型和所述实体信息,确定与所述会议语音数据对应的文本序列,形成会议记录。
[0587]
第五十二实施例
[0588]
本技术还提供一种电子设备。由于设备实施例基本相似于方法实施例,所以描述得比较简单,相关之处参见方法实施例的部分说明即可。下述描述的设备实施例仅仅是示意性的。
[0589]
本实施例的一种电子设备,该电子设备包括:处理器和存储器;存储器,用于存储实现会议记录方法的程序,该设备通电并通过所述处理器运行该方法的程序后,执行下述步骤:构建会议领域的语言知识库;通过语音实体识别模型和所述会议领域的语言知识库,确定目标会议语音数据中的实体信息;通过语音识别模型和所述实体信息,确定与所述会议语音数据对应的文本序列,形成会议记录。
[0590]
本技术虽然以较佳实施例公开如上,但其并不是用来限定本技术,任何本领域技术人员在不脱离本技术的精神和范围内,都可以做出可能的变动和修改,因此本技术的保护范围应当以本技术权利要求所界定的范围为准。
[0591]
在一个典型的配置中,计算设备包括一个或多个处理器(cpu)、输入/输出接口、网络接口和内存。
[0592]
内存可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flash ram)。内存是计算机可读介质的示例。
[0593]
1、计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器
(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd-rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括非暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
[0594]
2、本领域技术人员应明白,本技术的实施例可提供为方法、系统或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。