1.本公开涉及用于提取属于每个类别的信号的信号提取系统、信号提取学习方法和信号提取学习程序。
背景技术:
2.用于从观察到的信号中提取属于每一类别的信号的各种技术是已知的。例如,说话人二值化是一种用于分析关于说话人的信息(说话人的数量等)是未知的音频信号并估计哪个说话人说话以及说话人何时说话的技术,并且是一种用于从音频信号中指定每个说话人的一组分段的技术。
3.作为说话人二值化的一般方法,有一种通过对音频信号进行分段并对分段后的音频信号进行聚类来指定每个说话人的分段集合的方法。
4.图10是图示用于从分段的音频信号中指定说话人的音频信号的方法的说明图。在图10所示的方法中,对单声道音频流201执行用于提取音频部分的分段。图10图示了提取四个分段202至205的示例。这里,分段202、分段203和分段205以及分段204被确定为相似信号并被聚类。因此,前一分段被指定为说话人a,后一分段被指定为说话人b。
5.另一方面,图10所示的分段的聚类受到噪声的影响,存在无法分离说话人的暂时重叠的音频信号的问题。为了应对这样的问题,还提出了通过使用目标说话人的音频信号(也称为锚)来指定音频信号的方法。
6.图11是图示用于通过使用锚来指定说话人的音频信号的方法的说明图。在图11所示的方法中,为单声道音频流201准备了作为被指定的目标说话人a的音频信号的锚206。通过将音频流201与锚206进行比较来指定说话人a的一组分段(分段207、分段208和分段209)。
7.非专利文献1描述了一种通过使用深度学习技术提取说话人的音频信号的方法。在非专利文献1中描述的方法中,基于作为目标说话人的音频信号和混合音频信号的锚来学习用于提取目标说话人的音频信号(分段)的掩码(重构掩码)。通过将学习到的重构掩码应用于混合音频信号来指定目标说话人的一组分段。
8.npl 2描述了一种用于从输入音频中提取特征值的方法。
9.引文列表
10.非专利文献
11.npl 1:jun wang等,“用于从单通道语音混合中恢复目标说话者的深度提取器网络(deep extractor network for target speaker recovery from single channel speech mixtures)”,interspeech 2018,2018年9月2日至6日。
12.npl 2:david snyder等,“x向量:用于说话人识别的鲁棒dnn嵌入(x
‑
vectors:robust dnn embeddings for speaker recognition)”,icassp 2018
‑
2018ieee声学、语音和信号处理国际会议(icassp),2018年4月。
技术实现要素:
13.技术问题
14.在非专利文献1中描述的方法中,基于以时频的二维表示的说话人的锚x
f,tas
和混合音频信号x
f,tms
来学习重构掩码m
f,t
。通过将学习到的重构掩码m
f,t
应用于混合音频信号x
f,tms
来估计说话人的频谱图s^
f,tms
(s^代表s的上标帽)。具体地,说话人的频谱图s^
f,tms
是基于下面要说明的表达式1来计算的。
15.[数学式1]
[0016][0017]
在学习时,通过优化下面说明的表达式2的损失函数以使其最小化来学习重构掩码。表达式2中的s
f,tms
是说话人的频谱图。具体地,npl 1中描述的神经网络学习了能够处理来自不相关噪声的重叠话语的重构掩码。
[0018]
[数学式2]
[0019][0020]
然而,包括在上述表达式2中的重构掩码m
f,t
的真值(地面真实)和要重构的说话人的频谱图s
f,tms
的真值通常是未知的。因此,在使用上述表达式2的优化中,存在对于提高重构掩码的精度存在限制的问题。
[0021]
还可以通过人工生成其中多个(例如,两个)音频信号叠加的学习数据来提高重构掩码的精度。然而,由于人工数据难以充分反映实际数据中存在的因素(例如,会话交流和混响等),即使使用人工数据进行学习,也难以生成能够从实际环境声音中提取目标说话人的音频信号的重构掩码。
[0022]
因此,本公开的目的是提供一种能够从观察到的信号中准确地提取属于每个类别的信号的信号提取系统、信号提取学习方法和信号提取学习程序。
[0023]
问题解决方案
[0024]
根据本公开的一种信号提取系统包括:神经网络输入单元,其输入其中组合了第一网络和第二网络的神经网络,所述第一网络具有用于输入属于预定类别的锚信号和包括属于所述类别的目标信号的混合信号的层以及用于输出作为估计结果的重构掩码的层,所述重构掩码指示所述目标信号存在于所述混合信号中的时频域,所述第二网络具有用于输入通过将所述混合信号应用于所述重构掩码而提取的所述目标信号的层以及用于输出通过将所述输入的目标信号分类为预定的类别而得到的结果的层;重构掩码估计单元,其将锚信号和所述混合信号应用于所述第一网络,以估计所述锚信号所属类别的重构掩码;信号分类单元,其将所述混合信号应用于所述估计的重构掩码以提取目标信号,并将所述提取的目标信号应用于所述第二网络以将所述目标信号分类到一个类别中;损失计算单元,其计算所述提取的目标信号被分类到的所述类别与真实类别之间的损失函数;参数更新单元,基于所述损失函数的所述计算结果来更新在所述神经网络中的所述第一网络的参数和所述第二网络的参数;以及,输出单元,其输出所述更新后的第一网络。
[0025]
根据本公开的一种信号提取学习方法包括:输入其中组合了第一网络和第二网络的神经网络,所述第一网络具有用于输入属于预定类别的锚信号和包括属于所述类别的目标信号的混合信号的层以及用于输出作为估计结果的重构掩码的层,所述重构掩码指示所
述目标信号存在于所述混合信号中的时频域,所述第二网络具有用于输入通过将所述混合信号应用于所述重构掩码而提取的所述目标信号的层以及用于输出通过将所述输入的目标信号分类为预定的类别而得到的结果的层;将锚信号和所述混合信号应用于所述第一网络,以估计所述锚信号所属类别的重构掩码;将所述混合信号应用于所述估计的重构掩码以提取目标信号,并将所述提取的目标信号应用于所述第二网络以将所述目标信号分类到一个类别中;计算所述提取的目标信号被分类到的所述类别与真实类别之间的损失函数;基于所述损失函数的所述计算结果来更新在所述神经网络中的所述第一网络的参数和所述第二网络的参数;以及,输出所述更新后的第一网络。
[0026]
根据本公开的一种信号提取学习程序使计算机执行:神经网络输入处理,其输入其中组合了第一网络和第二网络的神经网络,所述第一网络具有用于输入属于预定类别的锚信号和包括属于所述类别的目标信号的混合信号的层以及用于输出作为估计结果的重构掩码的层,所述重构掩码指示所述目标信号存在于所述混合信号中的时频域,所述第二网络具有用于输入通过将所述混合信号应用于所述重构掩码而提取的所述目标信号的层以及用于输出通过将所述输入的目标信号分类为预定的类别而得到的结果的层;重构掩码估计处理,其将锚信号和所述混合信号应用于所述第一网络,以估计所述锚信号所属类别的重构掩码;信号分类处理,其将所述混合信号应用于所述估计的重构掩码以提取目标信号,并将所述提取的目标信号应用于所述第二网络以将所述目标信号分类到一个类别中;损失计算处理,其计算所述提取的目标信号被分类到的所述类别与真实类别之间的损失函数;参数更新处理,其基于所述损失函数的所述计算结果来更新在所述神经网络中的所述第一网络的参数和所述第二网络的参数;以及,输出处理,其输出所述更新后的第一网络。
[0027]
有益效果
[0028]
根据本公开,可以从观察到的信号中准确地提取属于每一类别的信号。
附图说明
[0029]
图1描绘了图示根据本公开的信号提取系统的第一示例性实施例的配置示例的框图。
[0030]
图2描绘了图示输入神经网络的示例的说明图。
[0031]
图3描绘了图示根据第一示例性实施例的信号提取系统的操作示例的流程图。
[0032]
图4描绘了图示根据第一示例性实施例的信号提取系统的另一操作示例的流程图。
[0033]
图5描绘了图示作为会话中的提取目标的信号的示例的说明图。
[0034]
图6描绘了图示根据本公开的信号提取系统的第二示例性实施例的配置示例的框图。
[0035]
图7描绘了图示根据第二示例性实施例的信号提取系统的操作示例的流程图。
[0036]
图8描绘了示出根据本公开的信号提取系统的概要的框图。
[0037]
图9描绘了图示根据至少一个示例性实施例的计算机的配置的示意框图。
[0038]
图10描绘了图示用于从分段的音频信号中指定说话人的音频信号的方法的说明图。
[0039]
图11描绘了图示用于通过使用锚来指定说话人的音频信号的方法的说明图。
具体实施方式
[0040]
在下文中,将参照附图描述本公开的示例性实施例。在以下描述中,作为从观察到的信号中提取属于每个类别的信号的具体示例,将描述用于从音频流中提取每个说话人的音频信号(分段)的方法。然而,本公开作为提取目标的信号不限于音频信号。
[0041]
第一示例性实施例。
[0042]
图1是图示根据本公开的信号提取系统的第一示例性实施例的配置示例的框图。根据示例性实施例的信号提取系统100包括神经网络输入单元10、锚信号输入单元20、混合信号输入单元30、学习单元40、输出单元50和提取单元60。
[0043]
神经网络输入单元10输入用于提取属于特定类别的信号的神经网络。在示例性实施例中,类别是指具有特定指定属性的一组信号。在音频信号的情况下,类别具体为个体说话人、性别、年龄、语言或情感等。例如,当说话人a被确定为类别时,指示说话人a话语的信号是属于说话人a的类别的信号。
[0044]
示例性实施例中的神经网络输入是其中组合了两种类型的网络的神经网络。第一网络包括用于输入属于预定类别的锚信号和包括属于该类别的信号(以下称为目标信号)的混合信号的层,以及用于输出作为估计结果的指示目标信号存在于输入混合信号中的时频域的掩码(以下称为重构掩码)的层。时频域指示可以基于时间和频率从信号中指定的区域。例如,当说话人a被确定为类别时,目标信号是指示说话人a的话语的信号。
[0045]
第一网络的一个具体示例是卷积神经网络(cnn)。特别地,当音频流被假定为混合信号时,可以想到信号的长度变得可变。因此,对于第一网络,最好使用作为一维卷积神经网络模型(1d cnn)的时间延迟神经网络(tdnn)。第一网络可以是输入通过将混合信号除以预定长度(例如,四秒等)而获得的混合信号的网络。
[0046]
第二网络包括用于输入通过将混合信号应用于重构掩码而提取的目标信号的层,以及用于输出通过将输入的目标信号分类为预定类别而获得的结果的层。因此,可以说示例性实施例中的输入神经网络是将锚信号和混合信号作为输入并将提取的目标信号被分类为的类别作为输出的神经网络。
[0047]
具体地,第二网络具有这样的层,其中,设置了与假设为提取目标的类别的数量相对应的输出,即,与后述的包含在要在学习单元40中参考的学习数据中的全部或部分类别中的每一个类别对应的输出。作为异常处理,假设混合信号不包括任何假定类别的信号,第二网络可以具有其中设置通过将被假定为提取目标的类别的数量加1而获得的输出的层。该附加输出是用于检测异常处理的输出。
[0048]
图2是图示输入神经网络的示例的说明图。图2所示的第一网络n1是其中输入了作为锚信号的说话人的话语x
f,tas
和包含说话人的话语的混合音频x
f,tms
并输出重构掩码m
f,t
的网络。第二网络n2是其中输入了指示通过将混合音频x
f,tms
应用于重构掩码m
f,t
提取的说话人的话语的信号s^
f,tms
以及输出通过将输入信号分类为预定的类别而获得的结果的网络。这两种网络组合起来构成一个神经网络n3。
[0049]
锚信号输入单元20输入要输入到神经网络的锚信号。具体而言,锚信号输入单元20使用重构掩码输入属于作为提取对象的类别的锚信号。换言之,用于提取输入的锚信号所属的类别的重构掩码由稍后描述的学习单元40学习。在图2所示的示例中,话语x
f,tas
对应于锚信号。
[0050]
混合信号输入单元30输入包括要提取的目标信号的信号(即,混合信号)。在图2所示的示例中,混合音频x
f,tms
对应于混合信号。
[0051]
学习单元40学习包括两种类型网络的整个神经网络。由于作为目标的重构掩码是未知的,所以根据示例性实施例的学习单元40利用具有将被分类为目标的类别的标签的弱标签来执行学习。学习单元40包括重构掩码估计单元42、信号分类单元44、损失计算单元46和参数更新单元48。
[0052]
重构掩码估计单元42将输入的锚信号和混合信号应用于第一网络,并估计锚信号所属类别的重构掩码。具体地,重构掩码估计单元42估计神经网络中的第一网络的输出作为重构掩码。
[0053]
信号分类单元44将混合信号应用于估计的重构掩码以提取目标信号,并将提取的目标信号应用于第二网络以将目标信号分类到类别中。具体地,信号分类单元44获取神经网络中的第二网络的输出作为目标信号被分类到的类别。例如,当混合信号是指示说话人话语的音频流时,信号分类单元44提取说话人的频谱图作为目标信号,并将提取的频谱图应用到第二网络以对说话人进行分类。
[0054]
损失计算单元46计算提取的目标信号被分类到的类别与真实类别之间的损失函数。真实类别是输入的锚信号所属的类别。例如,损失计算单元46可以通过使用以下表达式3中所示的交叉熵来计算损失函数。
[0055]
[数学式3]
[0056][0057]
表达式3中,c
i
为锚信号的真实标签信息,并且当锚信号属于第i类别时取值为1,否则取值为0。c^
i
为已分类类别的标签信息,并且是第二网络输出层的每个元素的输出值。该输出值希望通过第二网络中的softmax激活函数等进行归一化。标签信息由信号分类单元44分配,并且被预先设置到锚信号。
[0058]
参数更新单元48基于损失函数的计算结果来更新神经网络中的第一网络的参数和第二网络的参数。具体地,参数更新单元48更新神经网络中的参数以最小化损失函数。参数更新单元48可以通过例如反向传播方法来更新参数。然而,更新参数的方法不限于反向传播方法,并且参数更新单元48可以使用公知的方法来更新参数。
[0059]
输出单元50输出更新后的第一网络。即,输出单元50输出通过从输入神经网络中去除用于将目标信号分类到类别中的网络(即,第二网络)而获得的神经网络。
[0060]
提取单元60将锚信号和混合信号应用于输出的第一网络,并且提取锚信号所属的类别的信号(目标信号)。例如,提取的信号可用于说话人识别。
[0061]
例如,在非专利文献1所述的方法中,执行优化上述表达式2中所示的损失函数的处理。然而,如上所述,由于重构掩码m
f,t
和待重构的说话人的频谱图s
f,tms
的真实值通常是未知的,因此提高重构掩码的准确性是有限度的。另一方面,在示例性实施例中,学习单元40学习神经网络以优化上述表达式3的损失函数(即,类别之间的损失函数)。因此,可以学习能够从观察到的信号中准确地提取属于每一类别的信号的重构掩码。
[0062]
神经网络输入单元10、锚信号输入单元20、混合信号输入单元30、学习单元40(更具体地,重构掩码估计单元42、信号分类单元44、损失计算单元46和参数更新单元48)、输出单元50和提取单元60由根据程序(信号提取学习程序)运行的计算机的处理器(例如,中央
处理单元(cpu)或图形处理单元(gpu))实现。
[0063]
例如,程序可以存储在信号提取系统100中包括的存储单元(未示出)中,处理器可以读取程序并作为神经网络输入单元10、锚信号输入单元20、混合信号输入单元30、学习单元40(更具体地,重构掩码估计单元42、信号分类单元44、损失计算单元46和参数更新单元48)、输出单元50和提取单元60根据程序进行操作。可以以软件作为服务(saas)格式提供信号提取系统100的功能。
[0064]
神经网络输入单元10、锚信号输入单元20、混合信号输入单元30、学习单元40(更具体地,重构掩码估计单元42、信号分类单元44、损失计算单元46、参数更新单元48)、输出单元50和提取单元60可以由专用硬件实现。每个设备的部分或全部组成部件可以由通用或专用电路、处理器或它们的组合来实现。这些组成部件可以由单个芯片实现,也可以由通过总线连接的多个芯片实现。每个设备的组成部件的一部分或全部可以通过上述电路和程序的组合来实现。
[0065]
当信号提取系统100的组成部件的一部分或全部由多个信息处理设备、电路等实现时,多个信息处理设备、电路等可以集中布置或可以是分布式排列。例如,信息处理设备、电路等可以实现为客户端和服务器系统、云计算系统等经由通信网络彼此连接的形式。
[0066]
接下来,将描述根据示例性实施例的信号提取系统100的操作。图3是图示根据示例性实施例的信号提取系统100的操作示例的流程图。神经网络输入单元10输入组合了第一网络和第二网络的神经网络(步骤s11)。
[0067]
锚信号输入单元20输入锚信号(步骤s12),并且混合信号输入单元30输入混合信号(步骤s13)。学习单元40(更具体地,重构掩码估计单元42)将输入的锚信号和混合信号应用于第一网络以估计锚信号所属的类别的重构掩码(步骤s14)。
[0068]
学习单元40(更具体地,信号分类单元44)将混合信号应用于估计的重构掩码以提取目标信号,并将提取的目标信号应用于第二网络以将提取的目标信号分类到类别中(步骤s15)。学习单元40(更具体地,损失计算单元46)计算提取的目标信号被分类到的类别与真实类别之间的损失函数(步骤s16)。
[0069]
学习单元40(更具体地,信号分类单元44)基于损失函数的计算结果来更新神经网络中的第一网络的参数和第二网络的参数(步骤s17)。输出单元50输出更新后的第一网络(步骤s18)。
[0070]
图4是示出根据示例性实施例的信号提取系统100的另一操作示例的流程图。提取单元60输入所输出的第一网络(步骤s21)。锚信号输入单元20输入锚信号(步骤s22),并且混合信号输入单元30输入混合信号(步骤s23)。提取单元60将输入的锚信号和混合信号应用于第一网络以估计重构掩码(步骤s24),并将估计的重构掩码应用于混合信号以提取目标信号(步骤s25)。
[0071]
如上所述,在示例性实施例中,神经网络输入单元10输入其中组合了第一网络和第二网络的神经网络,并且重构掩码估计单元42将锚信号和混合信号应用于第一网络以估计锚信号所属类别的重构掩码。信号分类单元44将混合信号应用于估计的重构掩码以提取目标信号,并将提取的目标信号应用于第二网络以将目标信号分类到类别中。损失计算单元46计算提取的目标信号被分类到的类别与真实类别之间的损失函数,参数更新单元48基于损失函数的计算结果来更新神经网络中第一网络的参数和第二网络的参数。此后,输出
单元50输出更新后的第一网络。
[0072]
通过这样的配置,可以提高第一网络估计的重构掩码的准确性。结果,可以从观察到的混合信号中准确地提取属于每一类别的信号。
[0073]
根据示例性实施例的信号提取系统可以被实现为例如提取任何类别的信号的系统,如下所示。
[0074]
·
从混合话语中提取特定说话人、性别、年龄、语言或情感类别的信号的系统
[0075]
·
从混合音乐中提取特定乐器类别信号的系统
[0076]
·
从混合音频中提取特定声学事件(例如,爆炸声或枪声)的类别信号的系统
[0077]
·
从混合电流中提取特定电气设备的类别信号的系统
[0078]
·
从混合无线电波中提取特定通信设备的类别信号的系统
[0079]
第二示例性实施例
[0080]
接下来,将描述根据本公开的信号提取系统的第二示例性实施例。通过使用由第一示例性实施例估计的重构掩码,可以从混合信号中准确地提取属于每一类别的信号。在示例性实施例中,将描述用于从音频信号中更准确地提取每个说话人的目标信号的方法。
[0081]
在从音频信号中提取目标信号的过程中,通常独立地估计各个说话人的话语(分段)。在正常的会话中,一般来说,说话人交替且排他性地说话。
[0082]
图5是图示作为会话中的提取目标的信号的示例的说明图。如图5(a)所示,通常,多个说话人(说话人a和说话人b)的信号被交替且排他地观察到,并且很少如图5(b)所示同时被观察到。在示例性实施例中,将着眼于会话中的特征来描述用于校正与另一信号相关的重构掩码的方法。
[0083]
图6是图示根据本公开的信号提取系统的第二示例性实施例的配置示例的框图。根据示例性实施例的信号提取系统200包括神经网络输入单元10、锚信号输入单元20、混合信号输入单元30、学习单元40、输出单元50、重构掩码转换单元52和提取单元60。
[0084]
即,根据该示例性实施例的信号提取系统200与根据第一示例性实施例的信号提取系统100的不同之处在于还提供了重构掩码转换单元52。其他配置与第一示例性实施例的配置相同。
[0085]
在示例性实施例中,信号提取系统200通过使用多个说话人的重构掩码来改变至少一个重构掩码。因此,锚信号输入单元20输入多个说话人的锚信号。在以下描述中,尽管将描述使用两个说话人的重构掩码的情况,但是同样适用于存在三个或更多说话人的情况。即,锚信号输入单元20输入两个说话人的锚信号。
[0086]
混合信号输入单元30输入混合信号。
[0087]
学习单元40基于每个输入的锚信号和输入混合信号来为每个说话人估计第一网络,并且输出单元50输出每个生成的第一网络。
[0088]
重构掩码转换单元52输入多个生成的第一网络,并将每个说话人的锚信号和混合信号应用于与每个说话人相对应的第一网络以估计重构掩码。重构掩码转换单元52基于与另一重构掩码的相似度来转换估计的重构掩码中的至少一个。具体地,重构掩码转换单元52转换重构掩码,使得随着与另一个重构掩码的频率的相似度变得越高,频率的可靠度变得越低。
[0089]
重构掩码转换单元52的这种转换意味着转换以不使用与其他重构掩码相似的目
标重构掩码。重构掩码与其他重构掩码相似的事实意味着要使用不同说话人的重构掩码来提取相似频率的信号。然而,由于在会话中很少生成这样的信号,因此意图通过降低这样的重构掩码的可靠度来提高准确度。
[0090]
重构掩码转换单元52计算相似度的方法是任意的。计算相似度的函数用sim表示,说话人a的一组重构掩码用m
f,ta
表示,并且说话人b的一组重构掩码用m
f,tb
表示。此时,频率之间的相似度s
f
由下面说明的表达式4表示。
[0091]
[数学式4]
[0092][0093]
例如,重构掩码转换单元52可以计算余弦相似度作为相似度。在这种情况下,相似度s
f
通过下面说明的表达式5来计算。
[0094]
[数学式5]
[0095][0096]
重构掩码转换单元52转换重构掩码,使得随着计算的相似度变得越高,可靠度变得越低。例如,当任何说话人的重构掩码是m
f,t*
时,重构掩码转换单元52可以通过使用下面说明的表达式6来转换重构掩码。
[0097]
[数学式6]
[0098][0099]
在上述表达式6中,α是归一化系数并且由下面说明的等式7计算。
[0100]
[数学式7]
[0101][0102]
(等式7)
[0103]
提取单元60通过使用转换后的重构掩码来提取目标信号。
[0104]
神经网络输入单元10、锚信号输入单元20、混合信号输入单元30、学习单元40(更具体地说,重构掩码估计单元42、信号分类单元44、损失计算单元46和参数更新单元48)、输出单元50、重构掩码转换单元52和提取单元60由根据程序(信号提取学习程序)操作的计算机的处理器实现。
[0105]
接下来,将描述根据示例性实施例的信号提取系统200的操作。图7是示出根据示例性实施例的信号提取系统200的操作示例的流程图。这里,假设执行图3所示的流程图的处理并且生成每个说话人的重构掩码。
[0106]
重构掩码转换单元52基于与另一重构掩码的相似度来转换估计重构掩码中的至少一个(步骤s31)。提取单元60通过使用转换后的重构掩码来提取目标信号(步骤s32)。
[0107]
如上所述,在示例性实施例中,重构掩码转换单元52基于与其他重构掩码的相似度来转换估计的重构掩码中的至少一个,并且提取单元60通过使用转换后的重构掩码来提取目标信号。因此,除了第一示例性实施例的效果之外,还可以考虑会话的性质来提取每个
说话人的话语。
[0108]
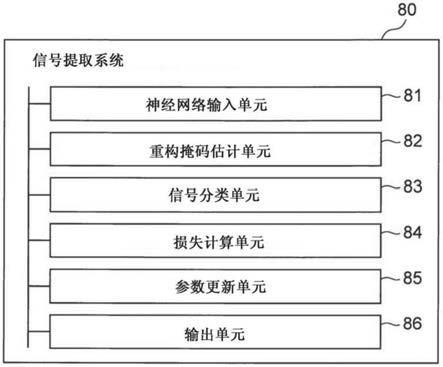
接下来,将描述本公开的概要。图8是图示根据本公开的信号提取系统的概要的框图。根据本发明的信号提取系统80(例如,信号提取系统100)包括:输入了神经网络(例如,图2中所示的神经网络n3)的神经网络输入单元81(例如,神经网络输入单元10),在神经网络中,组合了第一网络(例如,tdnn,图2中所示的第一网络n1)和第二网络(例如,图2中所示的第二网络n2),第一网络具有用于输入属于预定类别(例如,特定说话人)的锚信号和包括属于该类别(特定说话人的实际话语)的目标信号的混合信号(例如,音频流)的层以及用于输出作为估计结果的重构掩码的层,该重构掩码指示其中目标信号存在于混合信号中的时频域,并且第二网络具有用于输入通过将混合信号应用于重构掩码而提取的目标信号的层以及用于输出通过将输入目标信号分类为预定类别而获得的结果的层;重构掩码估计单元82(例如,重构掩码估计单元42),其将锚信号和混合信号应用于第一网络以估计锚信号所属类别的重构掩码;信号分类单元83(例如,信号分类单元44),其将混合信号应用于估计的重构掩码以提取目标信号,以及将提取的目标信号应用到第二网络以将目标信号分类到类别中;损失计算单元84(例如,损失计算单元46),其计算提取的目标信号被分类到的类别与真实类别(例如,输入的锚信号所属的类别)之间的损失函数;参数更新单元85(例如,参数更新单元48),其基于损失函数的计算结果来更新神经网络中第一网络的参数和第二网络的参数;以及输出单元86(例如,输出单元50),其输出更新的第一网络。
[0109]
通过这样的配置,可以从观察到的信号中准确地提取属于每一类别的信号。
[0110]
信号提取系统80(例如,信号提取系统200)可以包括重构掩码转换单元(例如,重构掩码转换单元52),该重构掩码转换单元基于与其他重构掩码的相似度来转换多个估计的重构掩码中的至少一个;以及,通过使用转换后的重构掩码来提取目标信号的提取单元(例如,提取单元60)。
[0111]
具体地,重构掩码转换单元可以转换重构掩码,使得随着与另一重构掩码的频率的相似度变得越高,频率的可靠度变得越低。
[0112]
参数更新单元85可以更新神经网络中的第一网络的参数和第二网络的参数,以减少由损失函数计算的损失。
[0113]
神经网络输入单元81可以输入其中组合了第二网络的神经网络,该第二网络具有其中设置了与假定为提取目标的类别的数量相对应的输出的层。
[0114]
例如,在提取说话人的音频的场景中,重构掩码估计单元82可以将锚信号和指示说话人话语的音频流应用到第一网络以估计说话人的重构掩码。信号分类单元83可以将混合信号应用于估计的重构掩码以提取说话人的频谱图,并且可以将提取的频谱图应用到第二网络以对说话人进行分类。
[0115]
图9是图示根据至少一个示例性实施例的计算机的配置的示意框图。计算机1000包括处理器1001、主存储设备1002、辅助存储设备1003和接口1004。
[0116]
上述信号提取系统在计算机1000中实现。上述各处理单元的操作以程序(信号提取学习程序)的形式存储在辅助存储设备1003中。处理器1001从辅助存储设备1003中读出程序,在主存储设备1002中扩展该程序,并根据该程序执行上述处理。
[0117]
在至少一个示例性实施例中,辅助存储设备1003是非暂时性有形介质的示例。作为非暂时性有形介质的另一个示例,存在经由接口1004连接的磁盘、磁光盘、压缩盘只读存
储器(cd
‑
rom)、数字通用盘只读存储器(dvd
‑
rom)和半导体存储器等。当该程序经由通信线路被分步到计算机1000时,被分步该程序的计算机1000可以扩展主存储设备1002中的程序并且可以执行上述处理。
[0118]
该程序可以用于实现上述部分功能。该程序可以是所谓的差异文件(差异程序),它与辅助存储设备1003中已经存储的其他程序结合来实现上述功能。
[0119]
参考标志列表
[0120]
10 神经网络输入单元
[0121]
20 锚信号输入单元
[0122]
30 混合信号输入单元
[0123]
40 学习单元
[0124]
42 重构掩码估计单元
[0125]
44 信号分类单元
[0126]
46 损失计算单元
[0127]
48 参数更新单元
[0128]
50 输出单元
[0129]
52 重构掩码转换单元
[0130]
60 提取单元
[0131]
100,200 信号提取系统