1.本发明涉及计算机技术领域,尤其涉及一种基于家庭角色的声学模型播报的方法、系统、设备及存储介质。
背景技术:
2.人机对话是计算机的一种工作方式,即计算机操作员或用户与计算机之间,通过控制台或终端显示屏幕,以对话方式进行工作。操作员可用命令或命令过程告诉计算机执行某一任务。现在人机对话已经广泛的应用于各个技术领域以及人们的生活中,其服务了社会,但其技术内容相当复杂。
3.如图1所示,左边最底部,是最基础的大数据、机器学习和语言学(linguistics);往上看,是知识图谱(knowledge graph),其中包含了实体图谱、注意力图谱和意图图谱。再往上,左侧是语言理解(language understanding),右侧是语言生成(language generation)——语言理解,包含了query理解、文本理解、情感分析(sentiment analysis)等,还有词法(lexical)、句法(syntax)和语义(semantic)等不同层次的分析。语言生成,包含了写作、阅读理解等等。最上方,是系统层面,包含了问答系统、机器翻译和对话系统。最右侧,是各种应用场景,包含搜索、feeds流、o2o、广告等等。
4.参见图2,tts(text to speec,从文本到语音)技术本质上解决的是“从文本转化为语音的问题”,通过这种方式让机器开口说话。但这个过程并不容易,为了降低机器理解的难度,科学家们将这个转化过程拆分成了两个部分——前端系统和后端系统。前端负责把输入的文本转化为一个中间结果,然后把这个中间结果送给后端,由后端生成声音。生成“语言学规格书”的前端系统,如小时候我们在认字之前需要先学习拼音,有了拼音,就可以用它去拼读我们不认识的字。对于tts来说,前端系统从文本转化出的中间结果就好像是拼音。
5.但是光有拼音还不行,因为要朗读的不是一个字,而是一句一句的话。如果一个人说话的时候不能正确的使用抑扬顿挫的语调来控制自己说话的节奏,就会让人听着不舒服,甚至误解说话人想要传达的意思。所以前端还需要加上这种抑扬顿挫的信息来告诉后端怎么正确的说话。将这种抑扬顿挫的信息称之为韵律(prosody)。韵律是一个非常综合的信息,为了简化问题,韵律又被分解成了如停顿,重读等信息。停顿就是告诉后端在句子的朗读中应该怎么停,重读就是在朗读的时候应该着重强调那一部分。这些所有的信息综合到一起,这称为“语言学规格书”。目前主流的后端系统有两种方法:一种是基于波形拼接的方法,一种是基于参数生成的方法。波形拼接的方法思路很简单:就是把事先录制好的音频存储在电脑上,当要合成声音的时候,可以根据前端开出的“语言学规格书”,从这些音频里去寻找那些最适合规格书的音频片段,然后把片段一个一个的拼接起来,最后就形成了最终的合成语音。比如:想要合成“你真好看”这句话,我们就会从数据库里去寻找“你、真、好、看”这四个字的音频片段,然后把这四个片段拼接起来。
6.参数生成法和波形拼接法的原理不相同,使用参数生成法的系统直接使用数学的
方法,先从音频里总结出音频最明显的特征,然后使用学习算法来学习一个如何把前端“语言学规格书”映射到这些音频特征的转换器。一但有了这个从语言学规格书到音频特征的转换器,在同样合成“你真好看”这四个字的时候,先使用这个转换器转换出音频特征,然后用另一个组件,把这些音频特征还原成人们可以听到的声音。在专业领域里,这个转换器叫“声学模型”,把声音特征转化为声音的组件叫“声码器”。
7.随着语音技术的发展,人们对tts合成的声音的要求也逐渐提高。现在batm(百度,阿里,腾讯,小米四大公司)对tts的技术也越来越完善。但是在终端设备的实际使用中,有时候家里多了一个与家人截然不同的声音会让人感觉不舒服,用户体验不佳。
8.综上可知,现有技术在实际使用上显然存在不便与缺陷,所以有必要加以改进。
技术实现要素:
9.针对上述的缺陷,本发明的目的在于提供一种基于家庭角色的声学模型播报的方法、系统、设备及存储介质,以实现在家庭中进行语音播报时,采用家庭成员喜欢的声音进行播报,提升了用户的人机对话的体验。
10.为了实现本发明的一个发明目的,提供了基于家庭角色的声学模型播报的方法,其特征在于,所述方法包括:
11.接收多个家庭成员的第一音频,并根据所述第一音频分析所述多个家庭成员分别对应的家庭角色以及喜欢的家庭成员和/或特定对象的声音;
12.根据所述喜欢的家庭成员和/或特定对象的声音,分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型;
13.在为所述家庭成员播报时,利用所述家庭成员喜欢的家庭成员和/或特定对象对应的所述声学模型播放第二音频。
14.根据所述的方法,所述接收多个家庭成员的第一音频,并根据所述第一音频分析所述多个家庭成员分别对应的家庭角色以及喜欢的家庭成员和/或特定对象的声音包括:
15.接收多个家庭成员的第一音频,并设置所述多个家庭成员的家庭角色;或者
16.接收多个家庭成员的第一音频,根据所述多个家庭成员的第一音频分析所述多个家庭成员的家庭角色;
17.根据所述家庭角色以及预设的喜好判定规则,分析每个所述家庭成员喜欢的家庭角色,并获取所述喜欢的家庭角色的声音;和/或
18.根据所述多个家庭成员的第一音频以及预存的大数据信息,分析每个所述家庭成员喜欢的特定对象的声音。
19.根据所述的方法,所述根据所述多个家庭成员的第一音频分析所述多个家庭成员的家庭角色包括:
20.根据所述多个家庭成员的第一音频及其内容分析每个家庭成员的年龄和性别,以及所述每个家庭成员之间的相互关系;
21.所述根据所述多个家庭成员的第一音频以及预存的大数据信息,分析每个所述家庭成员喜欢的特定对象的声音包括:
22.根据所述多个家庭成员的第一音频及其内容分析其年龄和性别;
23.根据所述第一音频的内容以及年龄和性别,在所述预存的大数据信息中获取与所
述第一音频的内容以及年龄和性别适配的声音作为所述家庭成员喜欢的特定对象的声音。
24.根据所述的方法,所述预设的喜好判定规则包括:若所述家庭角色为家庭女性,则判断其喜欢家庭男性的声音;
25.若所述家庭角色为家庭男性,则判断其喜欢家庭女性的声音;
26.若所述家庭角色为家庭长辈,则判断其喜欢家庭小辈的声音;
27.若所述家庭角色为家庭小辈,则判断其喜欢家庭长辈的声音;
28.若所述家庭角色为丈夫,则判断其喜欢妻子的声音;
29.若所述家庭角色为妻子,则判断其喜欢丈夫的声音;
30.若所述家庭成员包括至少一个儿童,则判断其他的所述家庭成员喜欢所述儿童的声音。
31.根据所述的方法,所述根据所述喜欢的家庭成员和/或特定对象的声音,分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型包括:
32.获取每个所述喜欢的家庭成员和/或特定对象的声音的音频特征;
33.采用预设的语言学规格书以及每个所述音频特征,分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型及声码器。
34.根据所述的方法,所述在为所述家庭成员播报时,利用所述家庭成员喜欢的家庭成员和/或特定对象对应的所述声学模型播放第二音频包括:
35.接收所述家庭成员的第三音频,并将所述第三音频转化为对应的文本;
36.根据所述文本和所述第三音频的特征,识别发出所述第三音频的家庭成员及其意图;
37.采用发出所述第三音频的家庭成员喜欢的家庭成员和/或特定对象对应的所述声学模型及声码器播放与所述意图相关的第二音频。
38.为了实现本发明的另一发明目的,本发明还提供了一种基于家庭角色的声学模型播报的系统,所述系统包括:
39.分析模块,用于接收多个家庭成员的第一音频,并根据所述第一音频分析所述多个家庭成员分别对应的家庭角色以及喜欢的家庭成员和/或特定对象的声音;
40.声学模型建立模块,用于根据所述喜欢的家庭成员和/或特定对象的声音,分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型;
41.播报模块,用于在为所述家庭成员播报时,利用所述家庭成员喜欢的家庭成员和/或特定对象对应的所述声学模型播放第二音频。
42.为了实现本发明的另一发明目的,本发明还提供了一种终端,包括上述任意一项所述的系统。
43.为了实现本发明的另一发明目的,本发明还提供了一种存储介质,用于存储一种用于执行上述任意一种方法的计算机程序。
44.为了实现本发明的另一发明目的,本发明还提供了一种计算机设备,包括存储介质、处理器以及存储在所述存储介质上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述任一项所述的方法。
45.本发明通过接收多个家庭成员的第一音频,并根据所述第一音频分析所述多个家庭成员分别对应的家庭角色以及喜欢的家庭成员和/或特定对象的声音;然后根据这些声
音,分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型;在为所述家庭成员播报时,利用所述家庭成员喜欢的家庭成员和/或特定对象对应的所述声学模型播放第二音频。由此实现了在家庭中进行tts语音播报时,采用家庭成员喜欢的声音进行播报,避免了在播报时家里多了一个与家人截然不同的声音会让人感觉不舒服的体验,提升了用户的人机对话的体验。
附图说明
46.图1是相关技术中人机对话管理系统的理论框图;
47.图2是相关技术中tts技术的理论框图;
48.图3是本发明实施例提供的基于家庭角色的声学模型播报的方法流程图;
49.图4是本发明实施例提供的基于家庭角色的声学模型播报的系统的结构框图;
50.图5是本发明实施例提供的基于家庭角色的声学模型播报的系统的结构框图;
51.图6是本发明实施例提供的存储介质的结构示意图;
52.图7是本发明实施例提供的计算机设备的结构示意图。
具体实施方式
53.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
54.需要说明的,本说明书中针对“一个实施例”、“实施例”、“示例实施例”等的引用,指的是描述的该实施例可包括特定的特征、结构或特性,但是不是每个实施例必须包含这些特定特征、结构或特性。此外,这样的表述并非指的是同一个实施例。进一步,在结合实施例描述特定的特征、结构或特性时,不管有没有明确的描述,已经表明将这样的特征、结构或特性结合到其它实施例中是在本领域技术人员的知识范围内的。
55.此外,在说明书及后续的权利要求当中使用了某些词汇来指称特定组件或部件,所属领域中具有通常知识者应可理解,制造商可以用不同的名词或术语来称呼同一个组件或部件。本说明书及后续的权利要求并不以名称的差异来作为区分组件或部件的方式,而是以组件或部件在功能上的差异来作为区分的准则。在通篇说明书及后续的权利要求书中所提及的“包括”和“包含”为一开放式的用语,故应解释成“包含但不限定于”。以外,“连接”一词在此系包含任何直接及间接的电性连接手段。间接的电性连接手段包括通过其它装置进行连接。
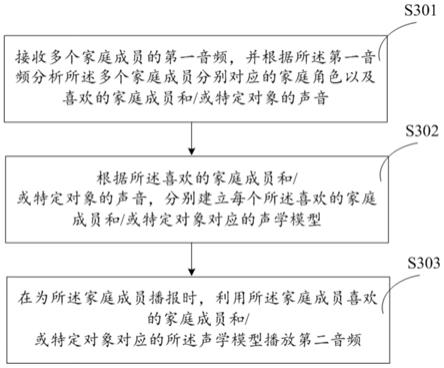
56.参见图3,在本发明的一个实施例中,提供了一种基于家庭角色的声学模型播报的方法,所述方法包括:
57.步骤s301中,接收多个家庭成员的第一音频,并根据所述第一音频分析所述多个家庭成员分别对应的家庭角色以及喜欢的家庭成员和/或特定对象的声音;
58.步骤s302中,根据所述喜欢的家庭成员和/或特定对象的声音,分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型;
59.步骤s303中,在为所述家庭成员播报时,利用所述家庭成员喜欢的家庭成员和/或特定对象对应的所述声学模型播放第二音频。
60.在该实施例中,在一个家庭中会包括多个家庭成员,通过接收多个家庭成员的说话的语音,即所述第一音频,可以分析多个家庭成员分别对应的家庭角色。这具体的可以通过第一音频的具体说话内容和分析第一音频的音频特性,获知包括说话者的年龄和性别等信息。此外,最简单的还可以是每个家庭成员可以自行发出如:“我是妈妈”的身份表示语音,由于获得每个家庭成员的家庭角色,此外还可以获得每个家庭成员所喜欢的家庭成员或者是特定对象的声音;如妈妈通常是喜欢孩子或者丈夫的声音,又或者是妈妈这个年纪喜欢的歌手的声音。在获得每个家庭成员喜欢的家庭成员和/或特定对象的声音后,则分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型;即为每个家庭成员建立其喜欢的声音的声学模型。在为所述家庭成员播报时,如该家庭成员与语音音箱进行对话时,则利用所述家庭成员喜欢的家庭成员和/或特定对象对应的所述声学模型播放第二音频。具体的,采用其喜欢的声音进行人机对话,提升了dm(dialog management,对话管理)效果。如为其播报天气等。由此实现了,在tts技术的终端设备的实际使用中,采用与用户熟悉的人的声音发出相应的语音,提升了用户体验。
61.在本发明的一个实施例中,所述步骤s301包括:
62.接收多个家庭成员的第一音频,并设置所述多个家庭成员的家庭角色;或者
63.接收多个家庭成员的第一音频,根据所述多个家庭成员的第一音频分析所述多个家庭成员的家庭角色;
64.根据所述家庭角色以及预设的喜好判定规则,分析每个所述家庭成员喜欢的家庭角色,并获取所述喜欢的家庭角色的声音;和/或
65.根据所述多个家庭成员的第一音频以及预存的大数据信息,分析每个所述家庭成员喜欢的特定对象的声音。
66.在该实施例中,每接收到一个家庭成员的第一音频,则相应设置所述该家庭成员的家庭角色,由此可以设置所述多个家庭成员的家庭角色。如对应家庭成员的角色可以从一开始设置语音音箱时,让对应的家庭成员录制对应的声音并明确出不同的家庭成员角色。或者是而如果缺少该步骤的话,则在接收多个家庭成员的第一音频,则根据所述多个家庭成员的第一音频分析所述多个家庭成员的家庭角色,即是可以从说话者的音频特征进一步分析出该音频对应的性别和年龄特征、及在经过一段时间后的音箱收到“多少个人”的音频,从而综合判断该音频对应的家庭角色大致类别。接着,根据所述家庭角色以及预设的喜好判定规则,分析每个所述家庭成员喜欢的家庭角色,并获取所述喜欢的家庭角色的声音;一般而言在无童音的情况下,则男性说话者对应女性说话者的声音,女性说话者对应男性说话者。在有童音的情况下,则默认以童音为大家都偏好的声音。在本发明的一个实施方式中,具体的,所述预设的喜好判定规则包括:若所述家庭角色为家庭女性,则判断其喜欢家庭男性的声音;若所述家庭角色为家庭男性,则判断其喜欢家庭女性的声音;若所述家庭角色为家庭长辈,则判断其喜欢家庭小辈的声音;若所述家庭角色为家庭小辈,则判断其喜欢家庭长辈的声音;若所述家庭角色为丈夫,则判断其喜欢妻子的声音;若所述家庭角色为妻子,则判断其喜欢丈夫的声音;若所述家庭成员包括至少一个儿童,则判断其他的所述家庭成员喜欢所述儿童的声音。此外,还可以根据所述多个家庭成员的第一音频以及预存的大数据信息进行分析每个所述家庭成员喜欢的特定对象的声音。预存的大数据信息可以存储在与语音音箱通信连接的云端服务器中,该大数据信息是云端服务器收集的如根据家庭成
员年纪、性别以及职业、爱好甚至籍贯相关的信息。如家庭中的爸爸,年纪在35岁左右,他是篮球运动员,则可以分析判断其喜欢科比,因此科比的声音应该是其喜欢的声音,而科比即是对家庭中的爸爸而言的特定对象。
67.此外,所述根据所述多个家庭成员的第一音频分析所述多个家庭成员的家庭角色包括:
68.根据所述多个家庭成员的第一音频及其内容分析每个家庭成员的年龄和性别,以及所述每个家庭成员之间的相互关系;在所述第一音频中,可能包括多种内容,如其身份、爱好、家庭角色等。而第一音频的音频特征,还可以分析家庭成员的龄和性别,如第一音频的音频特征指向其应该属于年纪大的男性,那发出该第一音频的家庭成员应该是这个家庭中长者,如爷爷。
69.所述根据所述多个家庭成员的第一音频以及预存的大数据信息,分析每个所述家庭成员喜欢的特定对象的声音包括:
70.根据所述多个家庭成员的第一音频及其内容分析其年龄和性别;
71.根据所述第一音频的内容以及年龄和性别,在所述预存的大数据信息中获取与所述第一音频的内容以及年龄和性别适配的声音作为所述家庭成员喜欢的特定对象的声音。在获得所述第一音频的内容后,根据第一音频的及其内容分析,可以获知该家庭成员的年纪和性别,如女性,年纪23岁,根据大数据信息进行匹配,其喜欢的声音大概率为鹿晗、吴亦凡等明星,因此,可以将这些明星的声音作为其喜欢的特定对象的声音。
72.在本发明的一个实施例中,所述步骤s302包括:
73.获取每个所述喜欢的家庭成员和/或特定对象的声音的音频特征;
74.采用预设的语言学规格书以及每个所述音频特征,分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型及声码器。
75.在该实施例中,获取每个所述喜欢的家庭成员和/或特定对象的声音的音频特征的音频特征包括但不限于所述声音的特征向量如男女性、高低音、韵律等信息。然后采用预设的语言学规格书以及每个所述音频特征,可以分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型。如妈妈喜欢的是儿子的声音,通过采用预设的语言学规格书以及儿子声音的音频特征,建立儿子的声学模型。
76.所述步骤s303包括:
77.接收所述家庭成员的第三音频,并将所述第三音频转化为对应的文本;
78.根据所述文本和所述第三音频的特征,识别发出所述第三音频的家庭成员及其意图;
79.采用发出所述第三音频的家庭成员喜欢的家庭成员和/或特定对象对应的所述声学模型及声码器播放与所述意图相关的第二音频。
80.在该实施例中,在接收所述家庭成员的第三音频,并将所述第三音频转化为对应的文本;该文本为机器能理解的语言文本,根据所述文本和所述第三音频的特征,能够识别出发出第三音频的家庭成员,这是由于在步骤s301中,已经收集了多个家庭成员的声音,因此只要其发生语音,即可以判断是谁说的,其发出的第三音频,作为语音指令进行识别,可以获取其意图,因此则将其喜欢的声音的声学模型发出与所述意图相关的第二音频。如在妈妈与语音音箱对话时,可以让语音音箱发出儿子的声音。当然,也不一定是即时的对话,
也可以是如闹钟,在闹钟时间到时,让儿子的声音,可以是预设的早安问候叫醒妈妈。
81.为了实现本发明的另一发明目的,参见图4,本发明还提供了一种基于家庭角色的声学模型播报的系统100,用于实现上述多个实施例中的方法,所述系统100包括:
82.分析模块10,用于接收多个家庭成员的第一音频,并根据所述第一音频分析所述多个家庭成员分别对应的家庭角色以及喜欢的家庭成员和/或特定对象的声音;
83.声学模型建立模块20,用于根据所述喜欢的家庭成员和/或特定对象的声音,分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型;
84.播报模块30,用于在为所述家庭成员播报时,利用所述家庭成员喜欢的家庭成员和/或特定对象对应的所述声学模型播放第二音频。
85.在该实施例中,分析模块10具有拾音功能,将接收多个家庭成员的发出的语音,根据根据接收到的语音分析多个家庭成员分别是什么样的家庭角色,如是奶奶还是妈妈等。此外,根据家庭成员的发出的语音,还能分析其喜欢的特定对象及其声音。声学模型建立模块20则根据所述喜欢的家庭成员和/或特定对象的声音,为每个喜欢的家庭成员和/或特定对象的声音建立对应的声学模型;由此,在播报模块30为所述家庭成员播报时,可以利用该家庭成员喜欢的家庭成员和/或特定对象的声学模型进行语音播报。由此实现了,在语音终端设备的实际使用中,采用与用户熟悉的人的声音发出相应的语音,提升了用户体验。
86.参见图5,在本发明的一个实施例中,所述分析模块10包括:
87.音频接收设置子模块11,用于接收多个家庭成员的第一音频,并设置所述多个家庭成员的家庭角色;或者
88.第一音频接收分析子模块12,用于接收多个家庭成员的第一音频,根据所述多个家庭成员的第一音频分析所述多个家庭成员的家庭角色;
89.分析获取子模块13,用于根据所述家庭角色以及预设的喜好判定规则,分析每个所述家庭成员喜欢的家庭角色,并获取所述喜欢的家庭角色的声音;和/或
90.第二音频接收分析子模块14,用于根据所述多个家庭成员的第一音频以及预存的大数据信息,分析每个所述家庭成员喜欢的特定对象的声音。
91.在该实施例中,音频接收设置子模块11是根据接收到的第一音频以及用户操作,将每个家庭成员对应于其发出的第一音频。而第一音频接收分析子模块12则是在用户没有设置采取上述音频接收设置子模块11的操作方式时,通过如多个家庭成员平时发出的语音或者与其他家庭成员的对话,以接收多个家庭成员的第一音频,并由此根据所述多个家庭成员的第一音频分析所述多个家庭成员的家庭角色。分析获取子模块13,用于根据所述家庭角色以及预设的喜好判定规则,分析每个所述家庭成员喜欢的家庭角色,并获取所述喜欢的家庭角色的声音。所述预设的喜好判定规则包括:若所述家庭角色为家庭女性,则判断其喜欢家庭男性的声音;若所述家庭角色为家庭男性,则判断其喜欢家庭女性的声音;若所述家庭角色为家庭长辈,则判断其喜欢家庭小辈的声音;若所述家庭角色为家庭小辈,则判断其喜欢家庭长辈的声音;若所述家庭角色为丈夫,则判断其喜欢妻子的声音;若所述家庭角色为妻子,则判断其喜欢丈夫的声音;若所述家庭成员包括至少一个儿童,则判断其他的所述家庭成员喜欢所述儿童的声音。具体的,如该家庭中有小孩,则默认所有的其他家庭成员都喜欢该小孩的声音。而该小孩则喜欢妈妈或者是奶奶的声音。除了上述的判断规则以外,还可以采用第二音频接收分析子模块14可以根据所述多个家庭成员的第一音频以及预
存的大数据信息,分析每个所述家庭成员喜欢的特定对象的声音。
92.优选的,所述第一音频接收分析子模块12根据所述多个家庭成员的第一音频及其内容分析每个家庭成员的年龄和性别,以及所述每个家庭成员之间的相互关系;即第一音频接收分析子模块12可以各家多个家庭成员的第一音频及其内容,分析家庭成员的年龄、性别以及职业等,以及每个家庭成员之间的相互关系;具体的,如声音苍老的家庭成员自然是声音年轻的家庭成员的长辈。
93.所述第二音频接收分析子模块14根据所述多个家庭成员的第一音频及其内容分析其年龄和性别;以及根据所述第一音频的内容以及年龄和性别,在所述预存的大数据信息中获取与所述第一音频的内容以及年龄和性别适配的声音作为所述家庭成员喜欢的特定对象的声音。如第二音频接收分析子模块14根据家庭成员的第一音频判定其是个儿童,大概5岁,根据大数据信息可以知道该年纪的儿童喜欢看的动画片,他们喜欢动画片里面的英雄人物或者是搞笑的漫画人物等,自然会喜欢这些特定人物的声音,像是“熊来了”里面的熊二的声音。
94.参见图5,在本发明的一个实施例中,所述声学模型建立模块20包括:
95.音频特征获取子模块21,用于获取每个所述喜欢的家庭成员和/或特定对象的声音的音频特征;在获知每个家庭成员喜欢的家庭成员或者特定对象的声音后,则可以由音频特征获取子模块21获取每个所述喜欢的家庭成员和/或特定对象的声音的音频特征;音的音频特征包括但不限于声音的特征向量如男女性、高低音、韵律等信息。
96.声学模型建立子模块22,用于采用预设的语言学规格书以及每个所述音频特征,分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型及声码器。声学模型建立子模块22采用预设的语言学规格书和所述音频特征建立声学模型,具体的声学模型建立子模块22采用的tts技术实现。
97.所述播报模块30包括:
98.音频接收及处理子模块31,用于接收所述家庭成员的第三音频,并将所述第三音频转化为对应的文本;
99.识别子模块32,用于根据所述文本和所述第三音频的特征,识别发出所述第三音频的家庭成员及其意图;
100.播报子模块33,用于采用发出所述第三音频的家庭成员喜欢的家庭成员和/或特定对象对应的所述声学模型及声码器播放与所述意图相关的第二音频。
101.在该实施例中,执行的是tts播报,音频接收及处理子模块31接收所述家庭成员发出的语音,该语音一般为语音指令,则将该语音指令转化为对应的文本,识别子模块32则根据所述文本和所述第三音频的特征,识别发出所述第三音频的家庭成员及其意图。音频接收及处理子模块31和识别子模块32采用asr和nlp(natural language processing,自然语言处理)技术进行上述处理。最后播报子模块33采用发出所述第三音频的家庭成员喜欢的声音的声学模型播放与所述意图相关的第二音频。该播报子模块33采用tts技术进行上诉处理。由此,实现了让tts播报的声音更容易让自己或者家人更好的接受,让tts播报的声音更像家里人的声音,如老公唤醒的语音音箱播报时,播报tts声音时采用老婆的声音;母亲唤醒语音音箱播报时,播放tts声音则是儿子的声音,提升了用户的体验。语音音箱与家庭成员的对话也是属于人机对话中的一种。
102.在本发明的一个实施例中,分析模块10同时具有拾音功能和asr(automatic speech recognition,自动语音识别技术)功能,如前端麦克风阵列拾取说话者第一音频并将其发送到云端服务器中。云端asr将其第一音频转为文字,同时云端服务器中的第一音频接收分析子模块12、分析获取子模块13、第二音频接收分析子模块14对其第一音频进行分析,同时进一步分析该音频特征及所对应的家庭角色及该家庭角色喜欢的声音对应的家庭成员。对应家庭成员的角色可以从一开始设置语音音箱时,采用音频接收设置子模块11对应的家庭成员录制对应的声音并明确出不同的家庭成员角色。而如果缺少该步骤的话,可以采用第一音频接收分析子模块12从说话者的音频特征进一步分析出该音频对应的性别和年龄特征、及在经过一段时间后的音箱收到“多少个人”的音频,从而综合判断该音频对应的家庭角色大致类别。而一般而言在无童音的情况下,则男性说话者对应女性说话者的声音,女性说话者对应男性说话者。在有童音的情况下,则默认以童音为大家都偏好的声音。另外也可以通过大数据信息去进一步发现用户选择的偏好的声音,从而更好地为用户做出选择。在进行tts播报时,音频接收及处理子模块31接收语音,其具有nlp和tts功能,经过nlp和tts处理后,找到对应该家庭成员喜欢的声音声学模型,并通过声码器将其转化为该家庭成员喜欢的声音。由此,在语音终端设备的tts播报使用中,采用与用户熟悉的人的声音发出相应的语音,提升了用户体验。
103.此外,为了实现本发明的另一发明目的,本发明还提供了一种终端,包括上述任意一项所述的系统100。所述系统包括相互通信连接的语音音箱和云端服务器。所述系统的多个模块及其子模块分别设置于所述语音音箱和云端服务器。
104.为了实现本发明的另一发明目的,本发明还提供了一种存储用于执行上述任意一种方法的计算机程序。
105.为了实现本发明的另一发明目的,本发明还提供了一种计算机设备400,包括存储介质200、处理器300以及存储在所述存储介质上并可在所述处理器300上运行的计算机程序,所述处理器300执行所述计算机程序时实现上述任一项所述的方法。
106.参见图6和图7,在本发明的一个实施例中,还提供了用于存储一种用于执行上述实施例中任意一种方法的计算机程序的存储介质200。以及一种计算机设备400,包括存储介质200、处理器300以及存储在所述存储介质200上并可在所述处理器300上运行的计算机程序,所述处理器300执行所述计算机程序时实现上述任一个实施例中的所述的方法。
107.本发明提供一种存储介质200,用于存储如图3所述任意一种方法的计算机程序。例如计算机程序指令,当其被计算机执行时,通过该计算机的操作,可以调用或提供根据本技术的方法和/或技术方案。而调用本技术的方法的程序指令,可能被存储在固定的或可移动的存储介质中,和/或通过广播或其他信号承载媒体中的数据流而被传输和/或被存储在根据程序指令运行的计算机设备的存储介质中。在此,根据本技术的一个实施例包括一个如图7所示的计算机设备400,所述计算机设备400优选包括用于存储计算机程序的存储介质200和用于执行计算机程序的处理器300,其中,当该计算机程序被该处理器300执行时,触发该计算机设备400执行基于前述多个实施例中的方法和/或技术方案。
108.需要注意的是,本技术可在软件和/或软件与硬件的组合体中被实施,例如,可采用专用集成电路(asic)、通用目的计算机或任何其他类似硬件设备来实现。在一个实施例中,本技术的软件程序可以通过处理器执行以实现上文步骤或功能。同样地,本技术的软件
程序(包括相关的数据结构)可以被存储到计算机可读记录介质中,例如,ram存储器,磁或光驱动器或软磁盘及类似设备。另外,本技术的一些步骤或功能可采用硬件来实现,例如,作为与处理器配合从而执行各个步骤或功能的电路。
109.根据本发明的方法可以作为计算机实现方法在计算机上实现、或者在专用硬件中实现、或以两者的组合的方式实现。用于根据本发明的方法的可执行代码或其部分可以存储在计算机程序产品上。计算机程序产品的示例包括存储器设备、光学存储设备、集成电路、服务器、在线软件等。优选地,计算机程序产品包括存储在计算机可读介质上以便当所述程序产品在计算机上执行时执行根据本发明的方法的非临时程序代码部件。
110.在优选实施例中,计算机程序包括适合于当计算机程序在计算机上运行时执行根据本发明的方法的所有步骤的计算机程序代码部件。优选地,在计算机可读介质上体现计算机程序。
111.综上所述,接收多个家庭成员的第一音频,并根据所述第一音频分析所述多个家庭成员分别对应的家庭角色以及喜欢的家庭成员和/或特定对象的声音;然后根据这些声音,分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型;在为所述家庭成员播报时,利用所述家庭成员喜欢的家庭成员和/或特定对象对应的所述声学模型播放第二音频。由此实现了在家庭中进行tts语音播报时,采用家庭成员喜欢的声音进行播报,避免了在播报时家里多了一个与家人截然不同的声音会让人感觉不舒服的体验,提升了用户的人机对话的体验。
112.本发明公开了a1、一种基于家庭角色的声学模型播报的方法,所述方法包括:
113.接收多个家庭成员的第一音频,并根据所述第一音频分析所述多个家庭成员分别对应的家庭角色以及喜欢的家庭成员和/或特定对象的声音;
114.根据所述喜欢的家庭成员和/或特定对象的声音,分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型;
115.在为所述家庭成员播报时,利用所述家庭成员喜欢的家庭成员和/或特定对象对应的所述声学模型播放第二音频。
116.a2、根据a1所述的方法,所述接收多个家庭成员的第一音频,并根据所述第一音频分析所述多个家庭成员分别对应的家庭角色以及喜欢的家庭成员和/或特定对象的声音包括:
117.接收多个家庭成员的第一音频,并设置所述多个家庭成员的家庭角色;或者
118.接收多个家庭成员的第一音频,根据所述多个家庭成员的第一音频分析所述多个家庭成员的家庭角色;
119.根据所述家庭角色以及预设的喜好判定规则,分析每个所述家庭成员喜欢的家庭角色,并获取所述喜欢的家庭角色的声音;和/或
120.根据所述多个家庭成员的第一音频以及预存的大数据信息,分析每个所述家庭成员喜欢的特定对象的声音。
121.a3、根据a2所述的方法,所述根据所述多个家庭成员的第一音频分析所述多个家庭成员的家庭角色包括:
122.根据所述多个家庭成员的第一音频及其内容分析每个家庭成员的年龄和性别,以及所述每个家庭成员之间的相互关系;
123.所述根据所述多个家庭成员的第一音频以及预存的大数据信息,分析每个所述家庭成员喜欢的特定对象的声音包括:
124.根据所述多个家庭成员的第一音频及其内容分析其年龄和性别;
125.根据所述第一音频的内容以及年龄和性别,在所述预存的大数据信息中获取与所述第一音频的内容以及年龄和性别适配的声音作为所述家庭成员喜欢的特定对象的声音。
126.a4、根据a2所述的方法,所述预设的喜好判定规则包括:若所述家庭角色为家庭女性,则判断其喜欢家庭男性的声音;
127.若所述家庭角色为家庭男性,则判断其喜欢家庭女性的声音;
128.若所述家庭角色为家庭长辈,则判断其喜欢家庭小辈的声音;
129.若所述家庭角色为家庭小辈,则判断其喜欢家庭长辈的声音;
130.若所述家庭角色为丈夫,则判断其喜欢妻子的声音;
131.若所述家庭角色为妻子,则判断其喜欢丈夫的声音;
132.若所述家庭成员包括至少一个儿童,则判断其他的所述家庭成员喜欢所述儿童的声音。
133.a5、根据a3所述的方法,所述根据所述喜欢的家庭成员和/或特定对象的声音,分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型包括:
134.获取每个所述喜欢的家庭成员和/或特定对象的声音的音频特征;
135.采用预设的语言学规格书以及每个所述音频特征,分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型及声码器。
136.a6、根据a5所述的方法,所述在为所述家庭成员播报时,利用所述家庭成员喜欢的家庭成员和/或特定对象对应的所述声学模型播放第二音频包括:
137.接收所述家庭成员的第三音频,并将所述第三音频转化为对应的文本;
138.根据所述文本和所述第三音频的特征,识别发出所述第三音频的家庭成员及其意图;
139.采用发出所述第三音频的家庭成员喜欢的家庭成员和/或特定对象对应的所述声学模型及声码器播放与所述意图相关的第二音频。
140.本发明还公开了b7、一种基于家庭角色的声学模型播报的系统,所述系统包括:
141.分析模块,用于接收多个家庭成员的第一音频,并根据所述第一音频分析所述多个家庭成员分别对应的家庭角色以及喜欢的家庭成员和/或特定对象的声音;
142.声学模型建立模块,用于根据所述喜欢的家庭成员和/或特定对象的声音,分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型;
143.播报模块,用于在为所述家庭成员播报时,利用所述家庭成员喜欢的家庭成员和/或特定对象对应的所述声学模型播放第二音频。
144.b8、根据b7所述的系统,所述分析模块包括:
145.音频接收设置子模块,用于接收多个家庭成员的第一音频,并设置所述多个家庭成员的家庭角色;或者
146.第一音频接收分析子模块,用于接收多个家庭成员的第一音频,根据所述多个家庭成员的第一音频分析所述多个家庭成员的家庭角色;
147.分析获取子模块,用于根据所述家庭角色以及预设的喜好判定规则,分析每个所
述家庭成员喜欢的家庭角色,并获取所述喜欢的家庭角色的声音;和/或
148.第二音频接收分析子模块,用于根据所述多个家庭成员的第一音频以及预存的大数据信息,分析每个所述家庭成员喜欢的特定对象的声音。
149.b9、根据b8所述的系统,所述第一音频接收分析子模块根据所述多个家庭成员的第一音频及其内容分析每个家庭成员的年龄和性别,以及所述每个家庭成员之间的相互关系;
150.所述第二音频接收分析子模块根据所述多个家庭成员的第一音频及其内容分析其年龄和性别;
151.以及根据所述第一音频的内容以及年龄和性别,在所述预存的大数据信息中获取与所述第一音频的内容以及年龄和性别适配的声音作为所述家庭成员喜欢的特定对象的声音。
152.b10、根据b8所述的系统,所述预设的喜好判定规则包括:若所述家庭角色为家庭女性,则判断其喜欢家庭男性的声音;
153.若所述家庭角色为家庭男性,则判断其喜欢家庭女性的声音;
154.若所述家庭角色为家庭长辈,则判断其喜欢家庭小辈的声音;
155.若所述家庭角色为家庭小辈,则判断其喜欢家庭长辈的声音;
156.若所述家庭角色为丈夫,则判断其喜欢妻子的声音;
157.若所述家庭角色为妻子,则判断其喜欢丈夫的声音;
158.若所述家庭成员包括至少一个儿童,则判断其他的所述家庭成员喜欢所述儿童的声音。
159.b11、根据b9所述的系统,所述声学模型建立模块包括:
160.音频特征获取子模块,用于获取每个所述喜欢的家庭成员和/或特定对象的声音的音频特征;
161.声学模型建立子模块,用于采用预设的语言学规格书以及每个所述音频特征,分别建立每个所述喜欢的家庭成员和/或特定对象对应的声学模型及声码器。
162.b12、根据b11所述的系统,所述播报模块包括:
163.音频接收及处理子模块,用于接收所述家庭成员的第三音频,并将所述第三音频转化为对应的文本;
164.识别子模块,用于根据所述文本和所述第三音频的特征,识别发出所述第三音频的家庭成员及其意图;
165.播报子模块,用于采用发出所述第三音频的家庭成员喜欢的家庭成员和/或特定对象对应的所述声学模型及声码器播放与所述意图相关的第二音频。
166.本发明还公开了c13、一种终端,包括b7~b12中任意一项所述的系统。
167.c14、根据c13所述的终端,所述系统包括相互通信连接的语音音箱和云端服务器。
168.本发明还公开了d15、一种存储介质,用于存储一种用于执行a1~a6中任意一种方法的计算机程序。
169.本发明还公开了e16、一种计算机设备,包括存储介质、处理器以及存储在所述存储介质上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现a1~a 6任一项所述的方法。