1.本发明属于语音信号处理技术领域,具体涉及到一种基于样本不均衡的半监督语音测谎方法。
背景技术:
2.说谎是一种常见的有意传递错误信息的交流方式,主要通过语音传达错误信息。谎言对于心理学、少儿教育、刑事侦查等领域的研究具有至关重要的作用,因此如何通过简单有效的方式进行谎言检测是研究的重点。早期针对测谎的研究主要是通过生理参数的变化判断,该方法虽然有一定的效果,但是相关信息的采集设备较为复杂,受试者容易产生抵触心理,导致测谎结果有误。后来,为降低这种影响,一些研究人员提出利用语音进行测谎。这种方法的优点是数据采集的过程不需要大型设备解除采集,通过录音设备就可完成,隐蔽性强,且样本容易获取,结果也相对客观。因此,基于语音谎言检测的研究受到了广泛的关注。
3.近些年,针对语音谎言检测的相关研究中,语音特征提取和数据库构建是最重要的两个研究方向。如何能够从语音中提取更能表征谎言信息的特征,是语音谎言检测系统具有高性能识别能力的关键。另外,谎言语料库是谎言检测系统设计的基本模块,即首先需要从语料库中提取语音特征用于模型训练。然而,目前谎言语料库数公开数据库少,据量小,标签获取困难以及谎言与真话样本不均衡的问题突出,这一问题给谎言检测研究带来了巨大的压力。因此,在样本不均衡和标签数据不充分的情况下,如何提取更具表征能力的谎言特征是研究的重点。
4.基于以上的分析,本发明开展针对谎言样本不均衡及半监督识别模型的研究,旨在降低样本不均衡对模型预测能力的影响,并降低模型对有标签谎言语料库的依赖,进而提升模型识别性能。本研究首先构建提取深度谎言特征的混合神经网络模型,以达到特征相互补充的目的;其次,对提取到的不同类型的特征经全连接层进行融合,并利用低程度增强的无标签数据的预测输出与概率阈值的关系,为为标记数据生成预测标签,并将该标签作为真实标签用于网络训练;最后,结合各部分损失,通过优化器对模型进行优化,以得到性能最佳的网络模型。
技术实现要素:
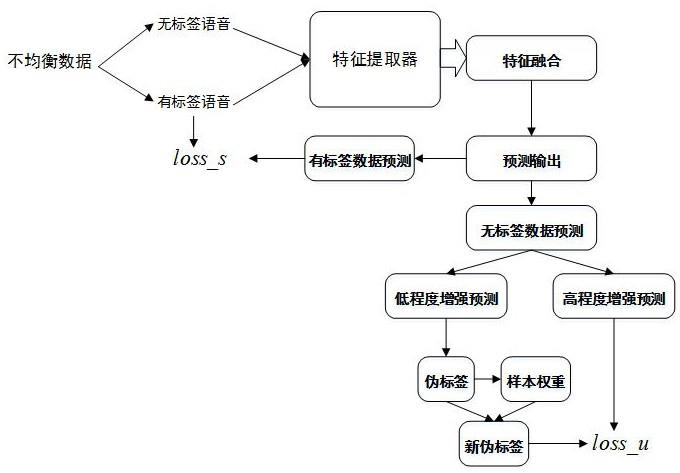
5.基于样本不均衡的研究在图像分类中有良好的性能,但是语音测谎与这些领域的分类任务不同,根据语音测谎的特点,将基础网络进行改进,使其可以实现对无标记输入数据的高置信度伪标签的预测,并根据样本权重给每个样本进行加权操作,然后提升网络模型的预测能力。于是,一种基于样本不均衡的半监督语音测谎方法,具体步骤如下:
6.(1)提取语音谎言特征:对语音数据进行分帧加窗等预处理操作,并提取其中的mel谱特征和人工统计特征;
7.(2)数据增强:采取对人工统计特征进行添加随机噪声方式实现数据增强的过程,
将该特征与mel特征组合为两种不同程度增强的无标签数据:低程度增强输入与高程度增强输入,有标签数据同样进行低程度的数据增强;
[0008][0009]
其中,为加噪后输入ae的人工统计特征,同理为加噪输入ae的人工统计特征,为随机噪声,α为添加噪声的系数;
[0010]
(3)构建网络模型:构建了用于提取mel谱特征以及人工统计特征的基础网络,并将步骤(2)中的特征x按批次输入网络,x如公式(2)所示:
[0011]
x={x
l
,x
u_w
,x
u_s
}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0012]
公式(2)中,x
l
、x
u_w
、x
u_s
分别有标签输入特征、无标签低程度数据增强特征、无标签高程度数据增强特征,x
u_w
、x
u_s
为同一批无标记数据的增强数据,每一部分的特征均由mel谱特征和人工统计特征组成;
[0013]
(4)语音特征深度融合:将步骤(3)中提取到的特征以拼接的方式进行融合,融合后的特征如公式(3)所示:
[0014]
f=[f1,f2,f3]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0015]
f1、f2、f3分别为步骤(3)中提取的特征,f为融合后的深层特征;
[0016]
(5)预测输出:步骤(4)中的融合特征,包含了更丰富的谎言信息,然后将该特征输入到softmax分类器,输出每个样本的类别概率,概率计算公式如公式(4);
[0017][0018]
(6)损失计算:对于步骤(5)中的预测输出,共分为四个部分:有标签的预测输出、无标签低程度增强数据的预测输出预测输出、无标签高程度增强数据的预测输出预测输出、所有数据的人工统计特征重构特征,损失函数计算过程如下:
[0019]
a.有标签的预测与标签之间进行交叉熵损失计算,如公式(5)所示:
[0020][0021]
b.无标签低程度增强数据的预测根据概率与本发明所设置的阈值比较,将概率高于该阈值的输出作为伪标签,该过程的约束条件使用公式(6)所示:
[0022]
max(p(y'|x;θ))>τ
ꢀꢀꢀꢀꢀꢀ
(6)
[0023]
p(y'|x;θ)为输出概率,τ为阈值;
[0024]
c.为解决样本的不均衡问题,本发明根据b中获取的伪标签求解每个样本在该批次的权重,然后利用该权重值,计算强增强数据的预测,该预测值可以由公式(7)表示,并采用交叉熵损失对模型训练,如公式(8)所示:
[0025]
p
′
u_s
=w
·
p
u_s
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0026][0027]
其中,公式(7)中p'
u_s
为样本权重与强增强概率的相乘结果;
[0028]
d.人工统计特征经经过自编码器进行冗余信息压缩后再完成重构,这一过程的损
失采用二值交叉熵计算,如公式(9)所示:
[0029][0030]
(7)网络模型优化:本发明最终的优化过程通过结合步骤(6)中的三部分损失实现,将三部分损失结合,如公式(10)所示,对网络实现反向微调,依次优化网络模型。
[0031]
附图说明
[0032]
图1为一种基于样本不均衡的半监督语音测谎方法结构图。
具体实施方式
[0033]
下面结合具体实施方式对本发明做更进一步的说明。
[0034]
本发明提出的是一种基于样本不均衡的半监督语音测谎方法,针对在语音测谎领域存在的难题提出了可行性的解决方法,步骤如下:
[0035]
(1)提取语音谎言特征:对语音数据进行分帧加窗等预处理操作,并提取其中的mel谱特征和人工统计特征;
[0036]
(2)数据增强:采取对人工统计特征进行添加随机噪声方式实现数据增强的过程,将该特征与mel特征组合为两种不同程度增强的无标签数据:低程度增强输入与高程度增强输入,有标签数据同样进行低程度的数据增强;
[0037][0038]
其中,为加噪后输入ae的人工统计特征,同理为加噪输入ae的人工统计特征,为随机噪声,α为添加噪声的系数;
[0039]
(3)构建网络模型:构建了用于提取mel谱特征以及人工统计特征的基础网络,并将步骤(2)中的特征x按批次输入网络,x如公式(2)所示:
[0040]
x={x
l
,x
u_w
,x
u_s
}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0041]
公式(2)中,x
l
、x
u_w
、x
u_s
分别有标签输入特征、无标签低程度数据增强特征、无标签高程度数据增强特征,x
u_w
、x
u_s
为同一批无标记数据的增强数据,每一部分的特征均由mel谱特征和人工统计特征组成;
[0042]
(4)语音特征深度融合:将步骤(3)中提取到的特征以拼接的方式进行融合,融合后的特征如公式(3)所示:
[0043]
f=[f1,f2,f3]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0044]
f1、f2、f3分别为步骤(3)中提取的特征,f为融合后的深层特征;
[0045]
(5)预测输出:步骤(4)中的融合特征,包含了更丰富的谎言信息,然后将该特征输入到softmax分类器,输出每个样本的类别概率,概率计算公式如公式(4);
[0046][0047]
(6)损失计算:对于步骤(5)中的预测输出,共分为四个部分:有标签的预测输出、
无标签低程度增强数据的预测输出预测输出、无标签高程度增强数据的预测输出预测输出、所有数据的人工统计特征重构特征,损失函数计算过程如下:
[0048]
a.有标签的预测与标签之间进行交叉熵损失计算,如公式(5)所示:
[0049][0050]
b.无标签低程度增强数据的预测根据概率与本发明所设置的阈值比较,将概率高于该阈值的输出作为伪标签,该过程的约束条件使用公式(6)所示:
[0051]
max(p(y'|x;θ))>τ
ꢀꢀꢀꢀꢀꢀꢀ
(6)
[0052]
p(y'|x;θ)为输出概率,τ为阈值;
[0053]
c.为解决样本的不均衡问题,本发明根据b中获取的伪标签求解每个样本在该批次的权重,然后利用该权重值,计算强增强数据的预测,该预测值可以由公式(7)表示,并采用交叉熵损失对模型训练,如公式(8)所示:
[0054]
p
′
u_s
=w
·
p
u_s
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0055][0056]
其中,公式(7)中p'
u_s
为样本权重与强增强概率的相乘结果;
[0057]
d.人工统计特征经经过自编码器进行冗余信息压缩后再完成重构,这一过程的损失采用二值交叉熵计算,如公式(9)所示:
[0058][0059]
(7)网络模型优化:本发明最终的优化过程通过结合步骤(6)中的三部分损失实现,将三部分损失结合,如公式(10)所示,对网络实现反向微调,依次优化网络模型。
[0060][0061]
为了验证所提出的一种基于样本不均衡的半监督语音测谎方法,本发明的验证在自建的interview库和公开库csc谎言语料库上进行实验。其中,interview库共包含1368条语音,真话477条,谎言891条,真话与谎言比例接近1:2。在本发明中,将训练集与测试集按照约9:1的比例划分,并且在测试集中仅选择150、300条有标签语音进行训练。csc谎言语料库包含有5411条语音,真话为3202条,谎言为2209条,真话与谎言的比例约为3:2。在本发明中,将训练集与测试集按照约9:1的比例划分,并且在测试集中仅选择500、1000条有标签语音进行训练。首先,采用混合神经网络提取不同类型的语音谎言特征。其次,在伪标签的选择上,本文将最大概率阈值选择为0.90,当低程度增强的为标记数据的预测概率高于阈值时,则保留该伪标签。最后,通过adam优化器最小化误差函数对模型进行优化,并对网络实现反向微调,以得到最佳网络。本发明提出的方法性能将用准确率进行评估,在每次的训练过程中,迭代次数为512,批次大小为32。为保证模型的有效性,模型进行10次的训练,并将10次训练的平均值作为最终的识别率。仿真实验结果表明:本发明所提方法能够有效降低样本不均衡带来导致模型预测能力降低的问题,并且充分利用了无标签数据,降低对有标签数据的依赖,在相同有标签数据的情况下,本发明达到了最先进的识别性能。
[0062]
本发明请求保护的范围并不仅仅局限于本具体实施方式的描述。