一种基于迁移学习和多损失动态调整的跨库语音情感识别方法
1.技术邻域
2.本发明属于语音信号处理技术领域,具体涉及到一种基于迁移学习和多损失动态调整的跨库语音情感识别方法。
背景技术:
3.语音情感识别是人机交互的重要技术基础。传统的语音情感识别研究往往是基于同一个语料库进行训练和测试,已经取得了非常好的识别效果。然而,由于不同语料库的录制环境、人员性别、年龄分布、语言等不同,造成不同语料库的语音特征分布存在极大的差异,这是一个典型的跨库语音情感识别问题。因此,如何有效地处理跨语料库训练带来的特征分布差异是语音情感识别研究中一个非常重要且极具挑战的问题。
4.受迁移学习在诸如文本分类与聚类、图像分类、传感器定位、协同过滤等成功应用的启发,在跨库语音情感识别研究中引入域自适应来减少不同领域之间特征分布的差异性。
5.因此本发明主要关注于不同语料库之间的跨库语音情感识别。首先,本发明基于深度去噪自编码器和深度神经网络搭建的深度网络模型来获取低维的语音情感特征。其中深度去噪自编码器是可以有效压缩特征冗余信息,并提升模型鲁棒性;深度神经网络具备强大的非线性拟合能力,可以有效的提升语音特征的情感表征能力。然后引入mmd和lmmd同时减小特征分布距离,同时缓解样本不平衡对模型识别性能的影响。最后在训练阶段,利用动态权重因子来动态调整不同损失函数对模型优化的贡献。
技术实现要素:
6.为了解决不同语料数据库之间特征分布差异的问题,更好地将带标记源域数据的知识迁移到无标记目标域,实现无标记数据的准确分类,提出了一种基于迁移学习和多损失动态调整的跨库语音情感识别方法。具体步骤如下:
7.(1)准备语料库:获取两个样本不平衡的语料库,分别作为源域数据库和目标域数据库,其中,源域数据库包括有若干语音信号和对应的情感类别标签,目标域数据库包括有若干语音信号;
8.(2)语音预处理:将源域数据库和目标域数据库中的语音信号进行预处理,为下一步提取特征做准备;
9.(3)语音特征提取:对步骤(2)预处理完毕后的语音信号,提取语音情感特征,该特征包括但不限于mfcc、短时平均过零率、基频、均值、标准差、最大最小值等;
10.(4)特征处理:首先,将步骤(3)得到的源域特征源域特征对应的标签和目标域特征随后在x
s
和x
t
中加入服从正太分布的噪音之后输入深度自编码器进行特征重构处理:
[0011][0012][0013]
其中和为经过深度自编码器解码重构之后的样本特征。然后,将深度自编码器的编码输出输入深度神经网络作进一步处理,从而分别源域和目标域的低维情感特征和最后使用源域的真实标签y
s
与经过softmax分类器预测的源域特征概率作交叉熵运算:
[0014][0015]
(5)特征迁移:首先,采用最大均值差异(maximum mean discrepancy,mmd)算法来减小x
′
s
和x
′
t
的全局域特征分布距离:
[0016][0017]
其中h为再生核希尔伯特空间(reproducing kernel hillbert space,rkhs),δ(
·
)为特征映射函数(高斯核函数)。然后,采用局部最大均值差异(local maximum mean discrepancy,lmmd)同时来来减小x
′
s
和x
′
t
的全局域特征分布距离:
[0018][0019]
其中为源域样本中每个样本属于情感类别c的权重,为目标域样本中每个样本属于情感类别c的权重;
[0020]
(6)模型训练:根据上述步骤(4)和(5)得到的五个损失函数,再利用动态权重因子w
i
来调整不同损失函数对模型优化的贡献,进而得到模型整体的优化目标为:
[0021][0022]
动态权重因子表示为:
[0023][0024]
其中i∈{s,t,y,mmd,lmmd},α
i
>0。
[0025]
(7)重复步骤(4)、(5),通过梯度下降法迭代训练网络模型,不断更新步骤(6)的动态权重因子,直至模型最优;
[0026]
(8)利用步骤(7)训练好的网络模型,使用sofmatx分类器预测步骤(3)中的目标域特征标签,最终实现语音情感在跨语料库条件下的情感识别。
附图说明
[0027]
如附图所示,图1为一种基于迁移学习和多损失动态调整的跨库语音情感识别方法的训练流程图,图2为一种基于迁移学习和多损失动态调整的跨库语音情感识别方法的测试流程图。
具体实施方式
[0028]
下面结合具体实施方式对本发明做更进一步的说明。
[0029]
(1)使用开源工具包opensmile从语音中提取2010年国际语音情感识别挑战赛的标准特征集,每条语音提取出的特征都为1582维。因此emo
‑
db数据库的5类情感语音共有368条语音,数据总量为368*1582;enterface数据库的5类情感语音共有1072条语音,数据总量为1072*1582;casia汉语语音情感数据库的6类情感语音共计1200条语音数据,数据总量为1200*1582。
[0030]
(2)将源域特征和目标域特征作归一化处理和添加服从正太分布的噪音。
[0031]
(3)建立基于深度自动编码器和深度神经网络的深度网络模型。对于dae的隐层数量为5,隐层神经元节点分别设置为1200、900、500、900、1200,其中编码阶段的激活函数使用elu函数,解码阶段的激活函数使用sigmoid函数。另外在dae的每层结构加入batchnorm层和dropout层。对于dnn的隐层数设置为2层,dnn的隐层神经元节点数分别为600、256,激活函数使用sigmoid函数。
[0032]
(4)将(2)得到的源域和目标域数据集特征分别输入基于深度自动编码器和深度神经网络的深度网络模型提取低维情感特征。
[0033]
(5)在低维情感空间中,同时使用mmd和lmmd来度量源于和目标域的低维情感特征的特征分布距离。其中计算mmd只需要源域和目标域的低维情感特征,而计算基于lmmd的子域自适应损失函数时,除了使用源域的低维特征及对应的真实标签和目标域低维特征外,还使用softmax计算的概率分布作为目标域的标签,即为伪标签。
[0034]
(6)所述模型的网络损失为:
[0035][0036]
其中
[0037]
和表示度量特征分布损失函数,表示源域重构损失,表示目标域重构损失,表示源域分类损失,α
i
为超参数,用于加强不同损失在在总体优化损失中的贡献。
[0038]
(7)模型的学习率和批处理大小都设置为0.00001和100,使用adam梯度下降法训练网络模型,模型迭代训练500次,分类器使用softmax。在mmd和lmmd中,特征映射函数使用多核高斯函数,高斯核数量设置为5。每一轮训练结束时,便会产生一组损失函数值,用于更新(6)中的权重w
i
,实现损失权重的动态调节。
[0039]
(8)将待识别的语音信号进行归一化处理,并输入训练好的深度网络模型,使用softmax分类器输出概率最大的类别即为识别的情感类别。
[0040]
下面以enterface数据库(缩写为e)、mo
‑
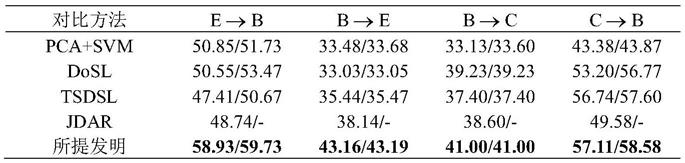
db数据库(缩写为b)和casia数据库(缩写为c)为例进行验证。所列4个跨库实验均为样本不平衡实验,验证结果如表1所示。
[0041]
表1与对比方法的实验结果(uar/war)
[0042][0043]
其中作为模型的精度测量方法分别为uar是非加权平均召回率(unweighted average recall)和war是加权平均召回率(weighted average recall)。pca+svm、dosl、tsdsl和jdar均为使用is10特征集以及跨库识别相同情感类别的跨库语音情感识别方法。所提发明是基于以上权利要求而搭建的跨库语音情感识别方法。
[0044]
实验结果表明,所提发明可以在样本不平衡的实验中取得最优的跨库语音识别率。本发明提出的模型结合深度网络模型以及两种迁移学习算法,同时还利用动态权重因子调整不同损失函数的贡献,实现模型训练的最优。
[0045]
本发明请求保护的范围并不仅仅局限于本具体实施方式的描述。