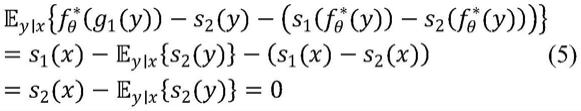
1.本发明涉及一种使用单个带噪语音样本进行语音去噪的方法,属于深度学习、语音去噪及语音增强领域。
背景技术:
2.目前电子技术应用非常广泛,语音作为典型的非平稳随机信号,是人们传递信息或相互通信最常用的媒介,随着语音业务逐渐涌现在智能终端上,人们对语音质量越来越重视。在信息化快速发展的今天,语音信号不可避免地会受到各种噪声的干扰,这些噪音种类众多,如电气设备声、汽笛声等,这些噪声的干扰会导致输出的语音质量差,不仅不易被人们理解,也会使得人机设备难以获得准确的信息。因此,各种语音去噪技术得到了迅速的发展和研究。传统的研究思路中,为了实现良好的语音降噪结果,需要大量的带噪语音样本和干净语音样本作为训练数据,这种训练数据需要昂贵的音频记录设备和环境严格的隔音记录工作室。
3.从去噪方法而言,由于现实世界有很多不便于收集或者干净数据较为昂贵的稀少语音资源,目前已经有使用一对带噪语音样本进行去噪的方法,这种方法要求每个场景中至少有两个独立的带噪语音样本,这在现实生活的场景中往往难以满足。
4.从去噪网络而言,为了缓解传统的基于卷积神经网络的方法中感受野受限的问题,目前已经有采用扩张卷积神经网络来提高语音增强性能的方法。后来有学者通过在unet的编码器和解码器之间加入时序卷积网络(temporal convolutional network,tcn)或长短期记忆(long short
‑
term memory,lstm)网络来学习长期依赖关系,但是语音的上下文信息仍然被忽略,这会大大限制去噪性能。
技术实现要素:
5.针对现有去噪方法的局限性,本发明在不使用干净语音数据的情况下,仅利用单个带噪语音样本训练去噪网络,这种方法打破了传统方法中需要构造两张独立带噪语音样本的局限性,通过设计采样器的方式从单个带噪语音样本中构造出相似语音训练对,将去噪技术推广到相似带噪语音样本和单个带噪语音样本这两个场景。
6.针对现有去噪网络的不足,本发明在复数编码器和解码器中融合了基于两级tansformer的复数模块以学习编码器输出的局部和全局上下文信息,来解决并行计算的长依赖问题,从而提高语音去噪网络的性能。
7.为了达到上述目的,本发明提供如下技术方案:
8.一种使用单个带噪语音样本进行语音去噪的方法,包括以下步骤:
9.步骤1,对于干净的语音信号,分别叠加合成噪声和真实世界的不同噪声类型生成带噪语音样本;
10.步骤2,对于单个带噪语音样本,使用一个语音下采样器生成一对语音训练样本,具体步骤如下:
[0011]2‑
1,设置参数i=0,k≥2,i的下一个取值为i+k,以此类推,直至遍历完原始语音信号;
[0012]2‑
2,对于带噪语音样本x的第i到第i+k
‑
1个的时域值,语音下采样器s从中随机选择两个相邻值分别作为下采样结果s1(x)和s2(x)的第i/k处的时域值;
[0013]2‑
3,通过步骤2
‑
2,可以得到一对训练样本s1(x)和s2(x),其长度为带噪语音样本x的1/k倍。由于下采样器s从原样本的相邻但不相同的位置采样得到语音对,因此该语音对满足相互之间的差异很小,但其对应的干净语音并不相同的条件。
[0014]
在语音训练对的生成过程中,我们使用语音下采样器直接处理原始语音的时域值,这是因为直接对训练输入进行子采样是不合理的。在我们的框架中通过短时傅里叶变换提取每个汉明窗内局部语音信息的频谱图形成训练输入,不同的窗口大小导致提取到的局部信息覆盖的语音特征不同,使得普通的采样方法很难获得非常相似的子采样对。因此,我们直接在语音的时域值上进行采样,然后再应用短时傅里叶变换生成有效的训练输入。除了短时傅里叶变换之外,我们的语音下采样器适合于其他去噪模型的任何语音变换操作,这意味着在任何有监督的语音去噪任务中表现良好的网络都可以应用我们的下采样方法。
[0015]
步骤3中,将训练对中的输入语音转化为频谱图输入去噪网络进行训练,训练对中另一个语音作为训练目标,去噪网络的特征如下:
[0016]3‑
1,普通unet的卷积层全部被取代为复数卷积层,除了网络最后一层之外,每个卷积层上均实现了复数批量归一化,在编码器阶段,使用复数下采样层替换最大池化层,以防止空间信息丢失,在解码器阶段,使用复数逆卷积上采样层以恢复输入图像的大小。
[0017]3‑
2,在去噪网络的编码器和解码器之间,叠加复数两级transformer模块来学习编码器输出的局部和全局上下文信息,从而在解码器处有效地重构增强语音。
[0018]
大多数去噪框架在处理频谱图时,侧重于关注幅度谱的特征,而忽略了相位谱的有用信息。因此,我们采用深度复数u
‑
net网络来解决这一问题。虽然这种u
‑
net结构可以更方便地处理复数频谱图,但往往会忽略语音的上下文信息,从而在一定程度上限制了去噪性能。所以,基于实值网络中两级transformer模块提取上下文信息的有效性,我们将复数形式的两级transformer模块引入到复数u
‑
net体系结构中,以更好地提取复数语音特征的上下文信息。
[0019]
步骤4中,训练使用的总损失函数由基础损失和正则化损失组成。其中,基础损失由时域损失频域损失和加权源失真比(weighted source
‑
to
‑
distortion ratio,wsdr)损失组成,正则化损失用于在单样本去噪方法中防止过度平滑现象。
[0020]
步骤5,将训练网络预测得到的掩码与原始带噪语音转换得到的频谱图相结合,得到去噪后的输出语音。
[0021]
与现有技术相比,本发明具有如下优点和有益效果:
[0022]
(1)针对现有语音去噪技术的不足,本发明设计了一种新的语音去噪框架,通过使用语音下采样器仅利用单个噪声语音样本进行去噪训练。本发明不仅不需要满足传统方法中对干净语音样本或者多个带噪样本的训练需求,而且缓解了现实场景中干净数据较为昂
贵的稀少语音资源的限制。
[0023]
(2)本发明设计了一种有效的复数语音去噪网络,该网络在深度复数unet的编码器和解码器之间引入了一个两级tansformer模块,并且类比复数卷积操作,实现复数形式的两级tansformer模块以代替传统的实数两级tansformer模块。该去噪网络通过对语音频谱的幅值和相位之间的相关性进行建模,学习编码器输出的局部和全局上下文信息,以提高语音去噪性能。
[0024]
(3)与传统的去噪策略相比,该方法不仅在人工合成的带噪语音数据集上表现良好,而且在真实世界噪声的数据集上也具有很好的适用性。对比实验表明,本发明在信噪比、语音质量感知评估、短时客观可懂度等多个评估指标上,不仅优于以干净语音作为训练目标的传统去噪方法,而且优于使用一对带噪语音样本进行去噪的方法,表明了本发明在训练数据需求以及去噪性能表现两方面的优势。
附图说明
[0025]
下面结合附图和具体实施方式对本发明做更进一步的具体说明。
[0026]
图1为本发明的总体网络架构示意图。
[0027]
图2为本发明的语音下采样器说明图。
[0028]
图3为本发明的语音去噪网络图。
[0029]
图4为本发明的两级transformer块结构图。
[0030]
具体施方式
[0031]
以下将结合附图和具体实施方式对本发明提供的技术方案进行详细说明。
[0032]
实施例1:参见图1
‑
图4,本发明提出的一种使用单个带噪语音样本进行语音去噪的方法流程及其架构如图1所示,具体步骤包括:
[0033]
步骤1,对于干净的语音信号,分别叠加合成噪声和真实世界的不同噪声类型生成带噪语音样本,
[0034]
步骤2,对于单个带噪语音样本,使用一个语音下采样器生成一对语音训练样本。下采样器的流程如图2所示,首先,设置参数i=0,k≥2,i的下一个取值为i+k,以此类推,直至遍历完原始语音信号;其次,对于带噪语音信号x的第i到第i+k
‑
1处的时域值,语音下采样器s从中随机选择两个相邻值分别作为下采样结果s1(x)和s2(x)的第i/k处的时域值。
[0035]
通过上述步骤,可以得到一对训练样本s1(x)和s2(x),其长度为带噪语音样本x的1/k倍。由于下采样器s从原样本的相邻但不相同的位置采样得到语音对,因此该语音对满足相互之间的差异很小,但其对应的干净语音并不相同的条件。
[0036]
由单个带噪样本生成一对语音训练样本进行训练的原理如下:
[0037]
首先,考虑相似场景的两个独立带噪语音样本的情况。假设有一个干净语音x,其对应的带噪语音是y,即e
y|x
(y)=x,当引入一个非常小的信号差ε≠0时,x+ε是另一张带噪语音z对应的干净语音,即e
z|x
(z)=x+ε。令f
θ
代表去噪网络,则有:
[0038][0039]
上式表明,当ε
→
0时,2εe
x,y
(f
θ
(y)
‑
x)
→
0,此时(y,z)配对可以作为(y,x)配对的一种近似。因此,一旦找到合适的满足“相似但不相同”条件的(y,z),就可以训练降噪网络。
[0040]
接着,考虑使用单个带噪语音样本的情况,构造出两个“相似但不相同”语音样本的一种可行方法是下采样。从时域信号的相邻但不相同的位置采样出来的子信号很显然满足了相互之间的差异很小,但是其对应的干净语音并不相同的条件(即ε
→
0)。
[0041]
因此,给定一个带噪语音y,本发明构造一对语音下采样器s1(*),s2(*),采样出两个子语音s1(y),s2(y),直接使用这两个子语音构造配对,则有:
[0042][0043]
由于两个采样噪声语音s1(y)和s2(y)采样的位置不同,即:
[0044][0045]
直接应用上式会导致语音去噪网络出现过度平滑现象,因此需要在总损失上增加正则项损失。假设有一个理想的语音去噪网络即:
[0046][0047]
该语音去噪网络满足:
[0048][0049]
因此,不再考虑直接优化等式(2),而是考虑以下带有约束的优化问题:
[0050][0051]
由于等式(6)可以被改写为如下正则化优化问题:
[0052][0053]
至此,我们完成了基于单个语音样本进行去噪训练方法的原理推导。
[0054]
步骤3,将训练对中的输入语音转化为频谱图,然后输入去噪网络进行训练,训练对中另一个语音作为训练目标,去噪网络的架构如图3所示,具体架构如下:
[0055]
1)普通unet的卷积层全部被取代为复数卷积层,除了网络最后一层之外,每个卷积层上均实现了复数批量归一化。在编码器阶段,使用复数下采样层替换最大池化层,以防止空间信息丢失。在解码器阶段,使用复数逆卷积上采样层以恢复输入图像的大小。
[0056]
2)在去噪网络的编码器和解码器之间,叠加一个复数tstm来学习编码器输出的局部和全局上下文信息,从而在解码器处有效地重构增强语音。
[0057]
3)一个复数两级transformer模块(two
‑
stage transformer module,tstm)由多个两级transformer块(two
‑
stage transformer block,tstb)叠加而成。tstb由一个局部transformer和一个全局transformer组成,分别提取局部和全局上下文信息,其架构如图4所示。局部transformer和全局transformer均基于改进的transformer实现,与一般的transformer结构有如下不同:首先,基于自注意机制的多头注意力块,输入特征被直接映射到不同位置的特征表示中;其次,在改进的transformer开始处并没有使用位置编码,而
是使用一个门控循环单元(gate recurrent unit,gru)层和一个中间有relu层的完全连接层作为前馈网络。
[0058]
3)给定复数输入的实部x
r
和虚部x
i
,复数tstm的输出f
out
可以定义为:
[0059]
f
rr
=tstm
r
(x
r
);f
ir
=tstm
r
(x
i
)
ꢀꢀ
(8)
[0060]
f
ri
=tstm
i
(x
r
);f
ii
=tstm
i
(x
i
)
ꢀꢀ
(9)
[0061]
f
out
=(f
rr
‑
f
ii
)+j(f
ri
+f
ii
)
ꢀꢀ
(10)
[0062]
其中,x
r
和x
i
分别表示复数频谱输入的实部和虚部;tstm
r
和tstm
i
分别表示tstm的实部和虚部;f
rr
和f
ir
表示原始输入的实部和虚部经过复数两级transformer架构的实部得到的结果;f
ri
和f
ii
表示原始输入的实部和虚部经过复数两级transformer架构的虚部得到的结果;f
out
表示复数两级transformer架构的运算结果。
[0063]
步骤4,训练使用的损失函数由基础损失和正则化损失组成,总损失函数的公式如下:
[0064][0065]
其中,表示基础损失,表示正则化损失,γ是控制正则化损失权重的超参数。
[0066]
1)基础损失由时域损失频域损失和加权源失真比(weighted source
‑
to
‑
distortion ratio,wsdr)损失组成,基础损失的公式如下:
[0067][0068]
其中,α是控制频域损失和时域损失权重的超参数,β是控制加权源失真比损失权重的超参数。
[0069]
①
时域损失使用去噪波形和干净波形之间的均方误差(mse)进行表示,定义为:
[0070][0071]
其中,s
i
和分别表示第i个干净语音样本和去噪后语音样本,n为语音样本的总数量。
[0072]
②
频域损失根据语音经过短时傅里叶变换后得到的频谱图计算,定义为:
[0073][0074]
其中,s和表示干净语音频谱图和去噪后语音频谱图,r和i代表复数频谱的实部和虚部,t代表帧数,f代表频率间隔。
[0075]
③
加权源失真比损失的定义如下:
[0076][0077]
其中,x表示带噪语音,y表示目标干净语音,表示去噪网络预测的语音结果,α表示目标语音和噪声之间的能量比。
[0078]
2)给定一对由带噪语音y下采样得到的语音对s1(y)和s2(y),正则化损失的公
式如下:
[0079][0080]
其中,f
θ
表示去噪网络,为了稳定学习,在训练过程中停止s1(f
θ
(y))和s2(f
θ
(y))的梯度更新,逐渐增加公式(11)中的超参数γ到达最好的训练效果。
[0081]
为了评估语音去噪的质量,使用以下客观措施:信噪比(signal
‑
to
‑
noise ratio,snr)、分段信噪比(segmental signal
‑
to
‑
noise ratio,ssnr)、窄带语音质量感知评估(perceptual evaluation of speech quality,using the narrow
‑
band version,pesq
‑
nb)、宽带语音质量感知评估(perceptual evaluation of speech quality,using the wide
‑
band version,pesq
‑
wb)、短时客观可懂度(short term objective intelligibility,stoi)。以上指标的值越大表示去噪后的语音质量越高。
[0082]
步骤5中,通过将预测的掩码与原始带噪语音的频谱图x
t,f
相结合,来计算预测的去噪后语音频谱图该计算过程如下:
[0083][0084][0085]
其中,表示频谱图的幅度谱信息,表示频谱图的幅度谱信息,表示频谱图的相位谱信息,
具体实施例:
[0086]
下面结合附图,对本发明实施例中的技术方案进行清楚、完整地描述。
[0087]
数据集:本发明使用voice bank数据集作为干净语音样本,其中共包含28个不同说话人集,26个用于训练,2个用于评估。在干净语音样本上分别叠加高斯白噪声和urbansound8k数据集生成带噪语音数据集,其中,高斯白噪声通过随机选择0到10范围内的信噪比得到,urbansound8k数据集选取自真实世界的噪声样本,使用其中所有的十个噪声类别进行实验。叠加过程中使用pydub在干净音频上重叠噪声,通过截断或重复噪声使其涵盖整个语音段以形成一段完整的带噪语音样本。
[0088]
实验环境:本实施例在ubuntu操作系统下开发,通过pytorch实现,机器配有四块nvidia geforce gtx1080 ti gpu。
[0089]
实验参数设置:
[0090]
1)本实施例中所有的信号采样率均为48khz,时域信号x长度被截取为65280,使用窗长为1022,帧移为256的汉明窗进行短时傅里叶变换,最终可以得到大小为512
×
256
×
2的复数频谱图x;
[0091]
2)将长度为65280时域信号x输入下采样器得到长度为16128的一对带噪语音样本s1(x)和s2(x),其中下采样的超参数k设置为2;
[0092]
3)接着,将s1(x)经过短时傅里叶变换得到大小为512
×
128
×
2的复数频谱图s1(x),将其作为编码器的输入。
[0093]
4)语音特征s1(x)经过编码器可以得到大小为15
×
13
×
2的特征,将其作为复数
tstm的输入,得到与编码器输入大小不变的特征作为解码器的输入,最终经过解码器得到与输入频谱图对应的时域信号大小一致的特征。
[0094]
5)对于训练过程的基础损失超参数α设置为0.8,β设置为1/200。对于总损失超参数γ设置为1。
[0095]
实验结果:为了体现本发明相对于现有方法的性能提升,本实施例和文献(kashyap m m,tambwekar a,manohara k,et al.speech denoising without clean training data:a noise2noise approach[j].)中的利用干净语音作为训练目标的方法以及使用一对带噪语音进行去噪训练的方法进行对比。
[0096]
对比实验结果如表1所示。其中,noise2clean表示利用干净语音作为训练目标的传统方法,noise2noise表示使用一对带噪语音进行去噪训练的方法,sns(single noisy speech)表示使用不包含复数tstm模块的十层复数unet进行单样本去噪的方法,sns
‑
tstm(single noisy speech
‑
tstm)表示在复数unet中融入复数tstm模块的单样本去噪方法。
[0097]
本实施例针对白噪声和urbansound8k数据集中十个噪声类型进行实验,表1每行对应所属噪声类别的对比实验结果。对于给定的噪声类别,分别计算所用度量标准的平均值和标准差。深色表格表示本发明提出的方法(即sns与sns
‑
tstm),加粗显示的值表示最好的结果(即更高的平均值)。
[0098]
为了探讨复数两级transformer模块对去噪网络性能的影响,实验设置了一个不包含复数tstm模块的十层复数unet模型作为对比实验,结果在表格中使用sns表示。该模型仅包含5个编码器和解码器层而不使用tstm,每个编码器和解码器层都具有与sns
‑
tstm的对应相同的配置。
[0099]
表1
[0100][0101][0102]
将两种基准方法noise2clean和noise2noise与本发明提出的sns和sns
‑
tstm的结果对比,可以得出如下结论:
[0103]
1)sns方法与基准方法noise2clean和noise2noise相比,可以发现本发明提出的单噪声样本去噪方法不仅优于使用干净语音进行训练的传统方法,同时超出了使用一对带噪样本进行训练的方法。即使对于noise2noise方法没有超过noise2clean方法的叠加白噪声的情况,本发明提出的sns架构也展现了去噪性能的有效性和优越性,各指标均超出了两种基准方法。
[0104]
2)将sns方法与sns
‑
tstm相比,可以发现:
[0105]
①
对于噪声种类2(小孩玩耍声)和噪声种类6(枪声),sns的方法超出了sns
‑
tstm方法,但是它们的差值是很小的。可以认为对于叠加了真实世界中小孩玩耍声和枪声的带噪语音,两级transformer模块提取到的局部和全局上下文信息对去噪网络影响是不大的,这种情况下,复数unet模块在去噪过程中负责提取主要信息。
[0106]
②
对于噪声种类0、4、8,除stoi指标外,其余指标均为sns
‑
tstm结果更好。stoi指标是基于纯净语音与带噪语音的时间包络相关系数计算得到,在实验中表现出与语音可懂度的高度相关性。可以认为对于叠加了噪声种类0、4、8的语音样本,两级transformer模块
对于提高去噪结果的语音可懂度作用较小,但是对于其他指标仍然表现良好。
[0107]
③
除上述两点分析外,对于叠加白噪声与其他剩余噪声种类的情况,tstm模块的添加对于解码器中语音的重建非常有效。复数两级transformer模块的引入使得去噪网络不仅能够更加精确地处理并重建来自频谱图的相位及幅度信息,又保证了语音的上下文信息不被忽略,总体来看,sns
‑
tstm模型不管在合成噪音还是现实世界噪音中普遍取得了更好的效果。
[0108]
以上实施例仅用以说明本发明的方案,而非限制该专利的范围,但凡是对该专利的说明书、附图或流程图进行等效修改或替换,却不脱离本专利所包括的范围,均在本专利的权利要求书的范围之内。