1.本发明属于音乐识别技术领域,具体涉及到一种音乐智能识别方法及装置。
背景技术:
2.音色又称为音品,是听觉感到的声音的特色。音色(timbre)是指不同声音表现在波形方面总是有与众不同的特性,不同的物体振动都有不同的特点。不同的发声体由于其材料、结构不同,则发出声音的音色也不同。例如钢琴、小提琴和人发出的声音不一样,每一个人发出的声音也不一样。
3.复音(complex tone)是发声体在形成复杂振动时,发出的声音中包含有许多频率,绘制频谱图,可以发现复音中频谱结构复杂,最低的频率称为基频(first partial),该声音成分为基音(fundamantal tone)。在频谱结构中高于基频的其它频率对应的声音成分称为泛音(over tones)。当泛音的频率恰好为基频的整数倍时,称为谐频。乐器发出的复音中振动能量通常分配给最低的频率,所以人类感知的乐音音高往往由基频决定。自然乐器产生的音都是复音,而每一个人每一种动物都有自己独特的音品,音品也是声音指纹的重要特征。对复音音色的识别可以帮我们准确判断是什么乐器,什么人所发出的声音。
4.在音乐教学中,通常会利用计算机进行辅助,通过设备进行音频采样,按照一定的频率记录声音的变化,完成从连续的模拟信号到离散的数字信号转化。对于音色而言,其是不同信号源信号本身的差异所产生的特性的音品。往往在音乐教学课堂上并不能通过音色来准确的判断出来该声源来自什么乐器什么人发出的声音,造成音乐教学过程中教学质量的下降。
技术实现要素:
5.本发明的目的在于提供一种基于高精度地图的交通载具的导航行驶方法,其目的为了解决上述技术问题:
6.为了解决上述技术问题,现在提供如下技术方案:
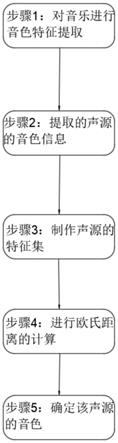
7.一种音乐智能识别方法,所述识别方法包括如下步骤:步骤1:对音乐进行音色特征提取,所述音色特征提取包括提取的声源的音色信息和声源的模板库;所述声源的模板库用tp表示,tp={tp1,tp2,tp3,
……
,tpk},k为模板的总数量;步骤2:提取的声源的音色信息,所述提取的声源的音色信息来源于当前音乐教学中出现的声源;步骤3:制作声源的特征集,把提取的声源的音色信息用所述声源的特征集表示;所述声源的特征集用tpj={tpji}表示;步骤4:进行欧氏距离计算,计算所述声源的特征集与所述声源的模板库中各不同音色的声源的特征集的欧氏距离;所述欧氏距离的计算方法步骤5:确定该声源的音色,选择最小欧氏距离的模板对应的音色作为该声源的音色,把所述提取的声源的音色信息被用来和所述声源的模板库进行计算比对识别以此来可以快速
判定音色出自哪一个声源。
8.作为本发明进一步的方案,所述的一种音乐智能识别方法,所述声源的模板库中包括多种不同音色的声源的特征集。
9.作为本发明进一步的方案,所述的一种音乐智能识别方法,所述模板库还包括多个子模板;所述子模板用来储存预先保存好的声源的特征集。
10.作为本发明进一步的方案,所述的一种音乐智能识别方法,所述声源的特征集是用来计算欧氏距离;所述欧氏距离是用来判定识别所述声源模板库中的模板对应的音色是否是该声源的音色。
11.作为本发明进一步的方案,所述的一种音乐智能识别方法,包括音色特征的提取方法,所述音色特征的提取方法包括提取该声源的音品特征值,所述音色特征值包括声源中的声音强度和声源中的声音强度的变化时长;所述声源中声音强度变化的时长是声源中声音强度变化中间需要的时间长度。
12.作为本发明进一步的方案所述的一种音乐智能识别方法,所述音色特征值的元素与所述的声源的特征集上的包含的元素数量相同。
13.作为本发明进一步的方案,所述的一种音乐智能识别方法,所述声源的声音强度分别为声源中最大的声音强度、声源中最中的声音强度以及声源中最小的声音强度。
14.作为本发明进一步的方案,所述的一种音乐智能识别方法,所述声源中声音强度的变化时长包括声源中最大的声音强度到声源中最中的声音强度的时长和声源中最中的声音强度到声源中最小的声音强度的时长。
15.一种音乐智能识别装置,包括:
16.提取模块,用于对音乐进行音色特征提取,音色特征提取包括提取的声源的音色信息和声源的模板库;声源的模板库用tp表示,tp={tp1,tp2,tp3,
……
,tpk},k为模板的总数量,提取的声源的音色信息,提取的声源的音色信息来源于当前音乐教学中出现的声源;
17.征集模块,用于制作声源的特征集,把提取的声源的音色信息用声源的特征集表示,声源的特征集用tpj={tpji}表示;
18.计算模块,用于进行欧氏距离计算,计算声源的特征集与声源的模板库中各不同音色的声源的特征集的欧氏距离;欧氏距离的计算方法
19.确定模块,用于确定该声源的音色,选择最小欧氏距离的模板对应的音色作为该声源的音色,把提取的声源的音色信息被用来和声源的模板库进行计算比对识别以此来快速判定音色出自哪一个声源。
20.与现有技术相比,本发明的有益效果为:
21.通过对音色的智能识别,可以帮助老师在教学课堂中,准确识别并判断出是什么乐器,发出的什么声音,大大提高了音乐课堂的教学质量和趣味性,也提高了学生们课堂上的学习兴趣。
附图说明
22.图1为一种音乐智能识别方法步骤示意图;
23.图2为一种音乐智能识别装置的接收器工作模块示意图;
24.图3为一种音乐智能识别装置的处理器工作模块示意图。
具体实施方式
25.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
26.本发明实施例提供了一种音乐智能识别方法,识别方法包括如下步骤:步骤1:对音乐进行音色特征提取,所述音色特征提取包括提取的声源的音色信息和声源的模板库;声源的模板库用tp表示,tp={tp1,tp2,tp3,
……
,tpk},k为模板的总数量,步骤2:提取的声源的音色信息,所述提取的声源的音色信息来源于当前音乐教学中出现的声源;步骤3:制作声源的特征集,把提取的声源的音色信息用所述声源的特征集表示;声源的特征集用tpj={tpji}表示,步骤4:进行欧氏距离计算,计算所述声源的特征集与所述声源的模板库中各不同音色的声源的特征集的欧氏距离;所述欧氏距离的计算方法步骤5:确定该声源的音色,选择最小欧氏距离的模板对应的音色作为该声源的音色,把所述提取的声源的音色信息被用来和所述声源的模板库进行计算比对识别以此来可以快速判定音色出自哪一个声源。具体的,对音乐进行音色特征提取时,主要提取出现的声源的音色信息,该声源的音色信息包含在含有不同声源的模板库中,优选的,模板库中不好大部分的声源的音色信息,可以清楚方便的得到该声源的音色信息,但是音乐教学中并不能第一时间识别出来该音色出自什么人或者其他发声物件,但是不同的声源它们的音色不同,可以提取它们的音色特征,所述该声源的音色特征通过计算比对识别,可以帮助判断出来该音色来自哪一个声源,从而达到对该声源的识别。通过对音色的智能识别,可以帮助老师在教学课堂中,准确识别并判断出是什么乐器,发出的什么声音,大大提高了音乐课堂的教学质量和趣味性,也提高了学生们课堂上的学习兴趣。
27.本发明实施例提供了另一种音乐智能识别方法,声源的模板库中包括多种不同音色的声源的特征集。优选的,模板库还包括多个子模板;子模板用来储存预先保存好的声源的特征集,具体的,模板库中包含多种不同音色声源,这样当出现不能快速判定的音色出自哪一个声源时,在通过计算分析,在回来跟模板库中各种声源进行比对,就可以找到与之对应的音色,从而知道该音色所对应的声源。在模板库中设置多个子模板,目的在于可以随意增减模板库中的声源的音色信息,例如tp表示模板库,tp={tp1,tp2,tp3,
……
,tpk},k为模板的总数量。每一个模板都有预先保存好的特征集,例如对于第j个模板tpj={tpji},i为自然数。本发明可以方便在得到充分计算后,快速从模板库中找到对应的声源的音色信息,从而可以快速帮助老师或者学生在音乐教学过程中,快速投入新的学习,大大提升了音乐教学的效率。
28.本发明实施例提供了另一种音乐智能识别方法,提取的音色信息被声源的特征集表示;声源的特征集是用来计算欧氏距离;欧氏距离是用来判定识别声源模板库中的模板对应的音色是否是该声源的音色。具体的,当对每一个声源进行音色特征提取,提取到的音色特征集可以用以下的来表示,例如分别用ta={ta1,ta2,
…
,tan},tb={tb1,tb2,
…
,tbm}表示;计算特征集ta和tb之间的欧氏距离
[0029][0030]
如果n<m,则tan+1值tam都补0,若n>m则tbm+1中tbn都补0。
[0031]
通过欧氏距离可以快捷判断出音色出自于哪一个声源,假设a为待识别音色的声源,只需要计算声源a的特征集ta与模板库中各不同音色的声源的特征集的欧氏距离,选择最小欧氏距离的模板对应的音色作为该声源的音色。
[0032]
tp表示模板库,tp={tp1,tp2,tp3,
……
,tpk},k为模板的总数量。每一个模板都有预先保存好的特征集,例如对于第j个模板tpj={tpji},i为自然数。声源a的音色为min(d(ta,{tp1,tp2,tp3,
……
,tpk})。
[0033]
本发明实施例提供了另一种音乐智能识别方法,包括音色特征的提取方法,音色特征的提取方法包括提取该声源的音品特征值,音色特征值包括声源中的声音强度和声源中的声音强度的变化时长;声源中声音强度变化的时长是声源中声音强度变化中间需要的时间长度。本领域的技术人员应当理解,声音在计算机中的存储形式一般为多个连续帧。因此对于声音而言,其存在时域和频域两个维度。在本发明中不考虑时域维度,因为对于待识别的声音而言其持续时长可能不完全一样,对于钢琴而言,其一个重击所带来的音符的持续时间可能会较长,而轻击则可能使音符持续时间较短。另一方面,音色的特征与声音持续时间的相关度不大,因此这里只考虑频域的因素。对于声源来说,其在计算机中存储为一系列的帧,这里用f(r)表示,r表示总帧数。即f(r)={f1,f2
……
fr},选择f(r)中声音强度最大的帧fr。
[0034]
首先对f(r)进行傅里叶变换其中n为窗宽。
[0035]
又因为fr为实信号,因此其虚部为0,此时
[0036]
f(ω)=fr*(cos2πω/n
‑
jsin2πω/n),也就是说可以将f(ω)变换为余弦和正弦两部分,分别用real和imag来表示。即
[0037]
real(fr)=fr*(cos2πω/n)
[0038]
imag(fr)=
‑
fr*(cos2πω/n)
[0039]
也就是说,可以用real(fr)和imag(fr)来表示fr的特征,即fr具有两个特征值,real(fr)和imag(fr),那么real(fr)和imag(fr)也可以作为声音源a的音色的特征值,但这种音色特征值的选择是存在一定的局限性的,因为音色与声音强度并不产生必然联系。但是注意到,每一个声音源在发生时的最大强度和最小强度以及中间强度都会有差异,因此这也是将声音强度与音色进行关联的一个合理的方式。例如对于钢琴和口琴而言,同样都是演奏音符c,那么虽然二者的频率一样,但是钢琴所发声的瞬时最大强度以及声音持续后衰减到最小强度的过程和口琴都不一样,因此,可以利用多个强度特征来辨别音色也就是
说,更为一般化地,可以从f(r)={f1,f2
……
fr}中选择多个帧来获得该声源的音色特征值。
[0040]
本发明实施例提供了另一种音乐智能识别方法,音色特征值的元素与声源的特征集上的包含的元素数量相同。具体的,声源模板库tp的音色特征集同样也包括相同的几个元素,这样就可以再利用即可计算出声源与模板库tp的欧氏距离,再取min(d(ta,tp))即可获得与声源最接近的音品。
[0041]
本发明实施例提供了另一种音乐智能识别方法,声源的声音强度分别为声源中最大的声音强度、声源中最中的声音强度以及声源中最小的声音强度。具体的,假如在本发明的最优的方案中,音色特征值为一个五元组fet()。
[0042]
声源a的音色特征为:
[0043]
fet(a)=(max{f1,f2
……
fr},mid{f1,f2
……
fr},min{f1,f2
……
fr},tmax_mid,tmid_min)
[0044]
其中,max{f1,f2
……
fr}表示声音强度最大的帧,mid{f1,f2
……
fr}表示声音强度最中的帧,min{f1,f2
……
fr}表示声音强度最小的帧。
[0045]
本发明实施例提供了另一种音乐智能识别方法,声源中声音强度的变化时长包括声源中最大的声音强度到声源中最中的声音强度的时长和声源中最中的声音强度到声源中最小的声音强度的时长。具体的,tmax_mid表示从声音强度最大的帧到声音强度最中的帧的时长,tmid_min表示声音强度最中的帧到声音强度最小的帧的时长。
[0046]
一种音乐智能识别装置,包括:
[0047]
提取模块,用于对音乐进行音色特征提取,音色特征提取包括提取的声源的音色信息和声源的模板库;声源的模板库用tp表示,tp={tp1,tp2,tp3,
……
,tpk},k为模板的总数量,提取的声源的音色信息,提取的声源的音色信息来源于当前音乐教学中出现的声源;
[0048]
征集模块,用于制作声源的特征集,把提取的声源的音色信息用声源的特征集表示,声源的特征集用tpj={tpji}表示;
[0049]
计算模块,用于进行欧氏距离计算,计算声源的特征集与声源的模板库中各不同音色的声源的特征集的欧氏距离;欧氏距离的计算方法
[0050]
确定模块,用于确定该声源的音色,选择最小欧氏距离的模板对应的音色作为该声源的音色,把提取的声源的音色信息被用来和声源的模板库进行计算比对识别以此来快速判定音色出自哪一个声源。
[0051]
具体的,当出现声源时,打开接收器,接收中的捕捉模块会快速捕捉到该声源的音色,波长,频率等关键的该声源的特征,然后接着由传送模块传送到后面的处理器。本发明可以快速捕捉到自己想要知道但是却第一时间不知道该音节属于哪一个声源,提高了智能化,提升了学习人们的对它的兴趣。
[0052]
本发明实施例提供了另一种智能识别装置,识别装置还包括处理接收器传送来的
处理器;处理器包括接收模块、存储模块、提取模块、计算模块、分析模块、输出模块,所接收模块用来接收接收器传送过来的捕捉到的声源信息;存储模块用来储存接收模块接收的声源信息;提取模块用来提取当前存储模块中存储的声源;计算模块用于计算当前从存储模块中提取的声源于模板库中的声源之间的欧氏距离;分析模块用来找出提取的声源与模板库中的声源之间的最小欧氏距离;输出模块用来输出分析模块得出对应声源的音色。具体的,接收模块主要接收来自接收器传送过来的声源的音色信息,储存在存储模块中,接着处理器中的提取模块会从存储模块中取出该声源的音色信息,接着处理器中的计算模块会处理计算音色特征集与模板库中储存好的声源特征集之间的欧氏距离,在经过与模板库中所有的声源之间的欧氏距离计算之后,在通过分析模块找到该声源的音色特征集与模板库中哪一个声源之间的欧氏距离最小,分析得出该声源的音色信息,并判断与模板库内欧氏距离最小的声源的音色即为该声源的音色,最后再由输出模块得到的结果。
[0053]
对于本领域技术人员而言,虽然说明了本发明的几个实施方式以及实施例,但这些实施方式以及实施例是作为例子而提出的,并不意图限定发明的范围。这些新的实施方式能够以其他各种方式实施,在不脱离发明的主旨的范围内能够进行各种省略、替换、变更。这些实施方式及其变形包含在发明的范围及主旨中,并且包含在权利要求所记载的发明和其等效的范围内。
[0054]
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域的技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域人员可以理解的其他实施方式。