1.本技术涉及音频解码技术领域,尤其涉及一种基于深度学习的关键词识别方法、系统、介质及设备。
背景技术:
2.现有技术中,无线音频有很多典型的应用场景,譬如说基于蓝牙的遥控器,其在智能家居产品中使用十分广泛,其大概流程如下:用户发出语音控制命令,如
‘
打开空调’,经麦克采集、模数转换、音频预处理和音频编码器生成音频压缩包,最后通过无线通信模块发送出去;接收端无线通信模块收到音频压缩包,调用音频解码器生成音频pcm,经关键词识别模块识别出关键词,如
‘
打开空调’,再将其转换成对应的控制信号来控制家电。其中在音频解码端,对用户语音命令中的关键词进行识别的过程中,在音频解码器的解码过程中涉及频域到时域的转换,而在关键词识别的模块中,又涉及到时域到频域的转换,因为这两个部分的运算量较大,互为逆操作,使得在用户语音中的关键词识别时速度较慢,同时不利于在低功耗语音识别设备中进行部署。
技术实现要素:
3.针对现有技术中,在音频接收端对语音信号中的关键词进行识别时,对部分运算量较大的处理过程进行反复运算,导致关键词的识别速度较慢,增加功耗的问题,本技术提出一种基于深度学习的关键词识别方法、系统、介质及设备。
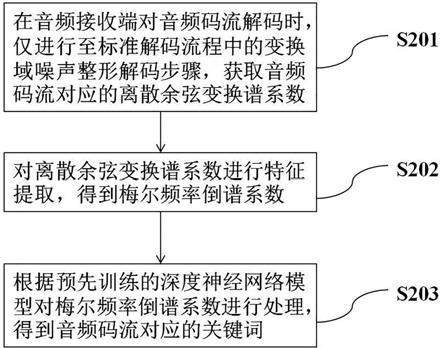
4.在本技术的一个技术方案中,提供一种基于深度学习的关键词识别方法,包括:在音频接收端对音频码流解码时,仅进行至标准解码流程中的变换域噪声整形解码步骤,获取音频码流对应的离散余弦变换谱系数;对离散余弦变换谱系数进行特征提取,得到梅尔频率倒谱系数;根据预先训练的深度神经网络模型对梅尔频率倒谱系数进行处理,得到音频码流对应的关键词概率。
5.可选的,仅进行至标准解码流程中的变换域噪声整形解码步骤,获取音频码流对应的离散余弦变换谱系数,包括:根据标准解码流程对音频码流进行解码,依次进行码流解析、算术与残差解码、噪声填充与噪声增益、时域噪声解码以及变换域噪声整形解码后,获得离散余弦变换谱系数,其中,该实际解码过程不包括频域与时域的转换过程以及长期后置滤波器的处理过程。
6.可选的,在频域内对离散余弦变换谱系数进行特征提取,得到梅尔频率倒谱系数,包括:对离散余弦变换谱系数进行预加重处理,并在预加重处理后,直接进行能量谱运算处理,省略掉预加重处理与能量谱运算处理之间的时域到频域的转换过程。
7.可选的,预加重处理包括:在预建立的预加重系数表中提取相应的预加重系数;根据预加重系数对离散余弦变换谱系数进行预加重处理,其中预加重系数与离散余弦变换谱系数一一对应。
8.可选的,在音频接收端对音频码流进行解码之前,还包括:获取多个音频文件分别
对应的梅尔频率倒谱系数;根据梅尔频率倒谱系数和音频文件对应的关键词,对深度网络模型进行训练,获得深度神经网络模型参数,使得当将梅尔频率倒谱系数输入到深度神经网络模型后,通过深度神经网络模型参数的设定,得到其对应的关键词的准确率大于或等于预设阈值。
9.在本技术的一个技术方案中,提供一种基于深度学习的关键词识别系统,包括:音频解码模块,其对音频码流进行解码时,进行至标准解码流程中的变换域噪声整形解码步骤,获取音频码流对应的离散余弦变换谱系数;特征提取模块,其对离散余弦变换谱系数进行特征提取,得到梅尔频率倒谱系数;神经网络模型处理模块,其根据预先训练的深度神经网络模型对梅尔频率倒谱系数进行处理,得到音频码流对应的关键词概率。
10.在本技术的一个技术方案中,提供一种计算机可读存储介质,其中,存储介质存储有计算机指令,计算机指令被操作以执行方案一中的基于深度学习的关键词识别方法。
11.在本技术的一个技术方案中,提供一种计算机设备,其包括处理器和存储器,存储器存储有计算机指令,其中:处理器操作计算机指令以执行方案一中的基于深度学习的关键词识别方法。
12.本技术的有益效果是:本技术通过对需要解码的音频码流只进行部分解码过程,获取中间参数;通过预训练的深度神经网络模型对中间参数进行处理,得到该音频码流对应的关键词,从而省去复杂、运算量大的解码步骤,节省功耗,提高关键词的识别速度。
附图说明
13.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
14.图1示出了在蓝牙接收端的音频码流处理流程图;图2示出了本技术基于深度学习的关键词识别方法的一个实施方式的流程示意图;图3示出了lc3音频解码器的标准解码流程;图4示出了关键词识别模块的标准识别流程;图5示出了本技术预加重处理的预加重频率相应曲线示意图;图6示出了本技术基于深度学习的关键词识别方法的一个实例的流程示意图;图7示出了本技术基于深度学习的关键词识别系统的一个实施方式的示意图。
15.通过上述附图,已示出本技术明确的实施例,后文中将有更详细的描述。这些附图和文字描述并不是为了通过任何方式限制本技术构思的范围,而是通过参考特定实施例为本领域技术人员说明本技术的概念。
具体实施方式
16.为使本技术实施例的目的、技术方案和优点更加清楚,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员
在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
17.本技术的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本技术的实施例例如能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的产品或设备不必限于清楚地列出的哪些单元,而是可包括没有清楚地列出的或对于这些产品或设备固有的其它单元。
18.目前主流的蓝牙音频编解码器如下:sbc:a2dp协议强制要求,使用最为广泛,是所有的蓝牙音频设备必须支持的,但音质一般;aac
‑
lc:音质较好且应用较为广泛,很多主流的手机都支持,但与sbc相比,内存占用较大,且运算复杂度高,很多蓝牙设备都基于嵌入式平台,电池容量有限,处理器运算能力较差且内存有限,而且,其专利费较高;aptx系列:音质较好,但码率很高,aptx需要码率384kbps,而aptx
‑
hd的码率为576kbps,且为高通独有的技术,较为封闭;ldac:音质较好,但码率也很高,分别是330kbps,660kbps和990kbps,由于蓝牙设备所处的无线环境特别复杂,稳定支持如此高的码率有一定的困难,且为索尼独有的技术,也很封闭;lhdc:音质较好,但码率也很高,典型的包括400kbps,600kbp和900kbps,如此高的码率,对于蓝牙的基带/射频设计提出了很高的要求。基于上述原因,蓝牙国际联盟bluetooth sig联合众多厂商推出了lc3,主要面向低功耗蓝牙,也可以用于经典蓝牙,其具有较低延迟、较高的音质和编码增益以及在蓝牙领域无专利费的优点,受到广大厂商的关注。其中lc3音频编解码器主要面向低功耗蓝牙,对功耗的要求较高。因此,在lc3音频编解码器的应用中,降低功耗成为一个关键。
19.目前无线音频的应用较广,尤其在智能家居的语音控制方面。现有技术中,例如,基于蓝牙技术的遥控器在对空调进行语音控制的流程大致如下:首先,用户发出语音控制指令,如“打开空调”,该语音命令经过麦克风的采集、模数转换、音频预处理以及音频编码器编码后生成音频压缩包,最后通过无线通信模块将该音频压缩包发送出去。然后在接收端,无线通信模块接收到该音频压缩包后,调用音频解码器进行解码,得到音频pcm,并通过关键词识别模块进行关键词识别,最终得到“打开空调”的指令,进而控制空调进行打开。
20.图1示出了在蓝牙接收端的音频码流处理流程图。其中,在蓝牙接收端的音频解码器和关键词识别模块是最关键的两个模块,其中,在音频解码器的处理过程包括:码流解析;算术与残差解码、噪声填充和全局增益;时域噪声解码;变换域噪声解码;频域到时域转换,即低延迟改进型离散余弦逆变换以及长期后置滤波器的滤波过程。在关键词识别模块的处理流程包括:特征提取:深度神经网络处理以及相应的后处理。其中,关键词特征提取部分包括:预加重处理;加窗处理;时域到频域转换,通常为离散傅里叶变换处理;能量谱;mel滤波器组;对数变换以及离散余弦变换,最终生成梅尔频率倒谱系数,简称mfcc。通过深度神经网络处理以及相应的后处理,根据梅尔频率倒谱系数得到音频码流对应的关键词。
21.通过上述说明可知,在音频解码器的解码过程和关键词识别模块的关键词特征提取过程中,存在频域到时域转换和时域到频域转换的逆操作,进行频域到时域的转换或者时域到频域的转换需要消耗较大的运算量,造成较大的功耗。
22.针对上述问题,本技术通过在音频接收端的音频解码器的解码过程中,对音频码流只进行一部分标准的解码流程,在获得音频码流对应的离散余弦变换谱系数后,不再进行后续的频域到时域的转换过程,同样在关键词识别模块中,也就不需要进行时域到频域的转换过程,进而将这两个运算量较高的步骤省略,降低运算量,加快关键词的识别过程。
23.针对上述问题,本技术提出一种基于深度学习的关键词识别方法,包括:在音频接收端对音频码流解码时,仅进行至标准解码流程中的变换域噪声整形解码步骤,获取音频码流对应的离散余弦变换谱系数;对离散余弦变换谱系数进行特征提取,得到梅尔频率倒谱系数;根据预先训练的深度神经网络模型对梅尔频率倒谱系数进行处理,得到音频码流对应的关键词概率。
24.本技术的关键词识别方法,通过将音频解码器中的频域到时域转换的步骤删除,进而省略掉关键词识别过程中的时域到频域的转换过程,降低运算量,加快关键词的识别速度。通过利用音频解码器得出的离散余弦变换谱系数利用深度神经网络模型进行处理,直接得到对应的关键词。其中,需要预先根据离散余弦变换谱系数和其对应的关键词对深度网络模型进行预训练,使得深度网络模型对离散余弦变换谱系数的处理结果的准确性提高,进而得到准确的关键词。
25.下面以具体地实施例对本技术的技术方案以及本技术的技术方案如何解决上述技术问题进行详细说明。下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例中不再赘述。下面将结合附图,对本技术的实施例进行描述。
26.图2示出了本技术基于深度学习的关键词识别方法的一个实施方式的流程示意图。
27.在图2所示的实施方式中,本技术的基于深度学习的关键词识别方法包括:过程s201,在音频接收端对音频码流解码时,仅进行至标准解码流程中的变换域噪声整形解码步骤,获取所述音频码流对应的离散余弦变换谱系数。
28.在该实施方式中,在对音频码流进行解码时,按照标准解码流程进行解码,但只进行一部分标准的解码流程,只要获得该音频码流对应的离散余弦变换谱系数即可。从而省略掉部分解码流程,节省解码器的算力和功耗。
29.可选的,仅进行至标准解码流程中的变换域噪声整形解码步骤,获取音频码流对应的离散余弦变换谱系数,包括:根据标准解码流程对音频码流进行解码,依次进行码流解析、算术与残差解码、噪声填充与噪声增益、时域噪声解码以及变换域噪声整形解码后,获得离散余弦变换谱系数,其中,该实际解码过程不包括频域与时域的转换过程以及长期后置滤波器的处理过程。
30.在该可选实施例中,图3示出了lc3音频解码器的标准解码流程。如图3所示,标准的音频解码器的解码流程包括:码流解析;算术与残差解码、噪声填充和全局增益;时域噪声解码、变换域噪声整形解码;频域到时域的转换以及长期后置滤波器滤波过程。其中,频域到时域的转换过程为低延迟改进型离散余弦逆变换,与关键词识别过程中的时域到频域的转换互为逆操作。因此,在本技术的方法中,本身请对音频码流的解码流程进行到变换域噪声整形解码后,在进行频域到时域转换的操作之前便结束,得到音频码流对应的离散余弦变换谱系数即可。
31.本技术的基于深度学习的关键词识别方法在音频解码的过程中,将运算量较大的
频域到时域转换以及长期后置滤波器的滤波过程省略,直接得到音频解码的离散余弦变换谱系数这一中间结果,通过对离散余弦变换谱系数进行后续的关键词识别流程,从而降低功耗,节省算力。
32.在图2所示的实施方式中,本技术的基于深度学习的关键词识别方法包括:过程s202,对离散余弦变换谱系数进行特征提取,得到梅尔频率倒谱系数。
33.在该实施方式中,对解码获得的离散余弦变换谱系数及进行特征提取处理,获得梅尔频率倒谱系数。
34.在该实施方式中,因为在音频解码器端没有进行频域到时域的转换以及长期后置滤波器的滤波过程,而直接得到离散余弦变换谱系数,因此,关键词识别模块中,也需要对原来的标准识别流程进行调整。
35.可选的,在频域内对离散余弦变换谱系数进行特征提取,得到梅尔频率倒谱系数,包括:对离散余弦变换谱系数进行预加重处理,并在预加重处理后,直接进行能量谱运算处理,省略掉预加重处理与能量谱运算处理之间的时域到频域的转换过程。
36.图4示出了关键词识别模块的标准识别流程。如图4所示,在关键词识别中的特征提取部分,包括:预加重;加窗;时域到频域转换,通常为离散傅里叶变换;能量谱;mel滤波器组;对数变换;离散余弦变换,生成梅尔频率倒谱系数,简称mfcc。根据音频解码端音频码流解码过程的更新,对应的,对识别流程进行调整。其中,因为在解码流程中不进行频域到时域的转换过程,相应的,在关键词的识别过程中,也就不进行时域到频域的转换过程,从而节省算力,降低功耗。其中,调整后,在关键词识别模块中,特征提取部分的流程为:预加重;能量谱;mel滤波器组;对数变换;离散余弦变换,生成梅尔频率倒谱系数,简称mfcc。
37.可选的,预加重处理包括:在预建立的预加重系数表中提取相应的预加重系数;根据预加重系数对离散余弦变换谱系数进行预加重处理,其中预加重系数与离散余弦变换谱系数一一对应。图5示出了本技术预加重处理的预加重频率相应曲线示意图。其中,如图5所示,横轴表示的是频率值,纵轴表示的是增益值。因为在一段音频中,主要能量集中的低频,而高频部分衰减较快,为了在关键词识别的过程中低频部分和高频部分的能量谱较为平坦,进行预加重处理,使得对低频能量进行衰减了,对高频能量进行加重。
38.在该可选实施例中,在接收端进行解码得到的离散余弦变换谱系数并没有经过频域到时域的转换,因此在关键词识别模块的识别过程中,对离散余弦变换谱系数的预加重处理也需要对应的进行调整。即在频域内对离散余弦谱系数预加重处理。首先在预建立的预加重系数表中提取相应的预加重系数,根据一一对应的关系,根据预加重系数对离散余弦变换谱系数进行预加重处理。
39.具体的,以16khz采样率为例,将预加重频率响应按照50hz间隔存为预加重系数表,p(0),p(1),p(2),
…
,p(159)。离散余弦变换谱系数mdct的谱系数共160个,是160。
40.根据预加重公式,进行预加重处理,具体如下:。
41.本技术的方法,在关键词识别模块的特征提取流程中,由于在发送端进行音频编
码时,已经进行过加窗步骤,同时因为时域到频域和频域到时域的转换过程互为逆操作,因此将标准流程中的加窗和时域到频域的转换过程进行省略,从而降低功耗。
42.在本技术的一个实例中,下面对关键词识别模块中特征提取过程的其他流程进行简单介绍,如下:在能量谱过程中,首先生成伪谱系数:其中,在当或时,。
43.接下来,接着生成能量谱:此步与上一步在具体实施例中可以合并,进一步节省运算,为了叙述方便分开。
44.。
45.需要说明的是,本发明并不限制是否使用伪谱系数,直接使用mdct离散余弦变换谱系数也能生成能量谱做关键词识别,但由于mdct伪谱系数的能量分布与傅里叶变换谱系数的能量分布有更好的对应关系,使用伪谱来计算能量谱可以提高训练与识别的性能。
46.在mel滤波器组的处理过程如下:将频谱能量经过梅尔滤波器组计算得到每个通道的能量梅尔滤波器组是由一系列的三角滤波器连接而成,是第m个梅尔滤波器,此属于成熟的技术,此处不再赘述。
47.对数变换过程如下:。
48.离散余弦变换过程:生成梅尔频率倒谱系数,简称mfcc,计算公式如下:,d是mfcc特征的维数。
49.在图2所示的实施方式中,本技术的基于深度学习的关键词识别方法包括:过程s203,根据预先训练的深度神经网络模型对梅尔频率倒谱系数进行识别,得到音频码流对应的关键词概率。
50.在该实施方式中,通过预先训练好的深度神经网络模型对梅尔频率倒谱系数进行处理,根据梅尔频率倒谱系数与关键词的对应关系,得到音频码流对应的关键词概率。之后的关键词处理过程中,在音频接收端的关键词处理模块根据关键词概率确定最终的关键词,进而控制相应的设备进行动作。例如,本技术的关键词识别方法对一段音频码流进行处理后,获得空调的“打开”的关键词概率为90%,获得“升温”的关键词概率为20%,因此,之后
的关键词处理模块根据关键词概率,确定关键词为打开,进而控制空调进行空调打开的操作。其中,关于后续的关键词处模块根据该关键词概率进行的后续处理,本技术不进行具体限制。
51.可选的,在音频接收端对音频码流进行解码之前,还包括:获取多个音频文件分别对应的梅尔频率倒谱系数;根据梅尔频率倒谱系数和音频文件对应的关键词,对深度网络模型进行训练,获得深度神经网络模型参数,使得当将梅尔频率倒谱系数输入到深度神经网络模型后,通过深度神经网络模型参数的设定,得到其对应的关键词的准确率大于或等于预设阈值。
52.在该可选实施例中,会预先对深度神经网络模型进行训练,其中在模型的训练过程中,对大量的语音素材的音频文件在离线的pc或服务器上进行处理,得到音频文件对应的梅尔频率倒谱系数,以梅尔频率倒谱系数及其对应的音频文件关键词为训练样本,建立梅尔频率倒谱系数与关键词的对应关系。其中,在pc或服务器中提取音频文件的梅尔频率倒谱系数获取原理,可参见上述描述的音频解码过程,具体情况,可进行适应调整。需要说明的是,对音频文件的处理设备,例如pc或者相关服务器可直接设置在深度神经网络模型中,进而在进行处理时,直接将音频文件输入到深度神经网络模型中进行训练,建立梅尔频率倒谱系数与关键词的对应关系,获得深度神经网络模型参数,供以后关键词的具体推理过程进行使用。
53.其中,在进行模型训练结果的检验时,在根据深度神经网络模型参数对模型设定后,将一定数量的音频文件输入到模型,统计音频文件与其对应关键词的对应关系,例如,当对应准确的音频文件测试样本数量占据总文本数量的比例不小于预设阈值时,则认为此时设定的深度神经网络模型参数设定正确,符合要求。具体的,预设阈值可选择95%。此时根据该深度神经网络模型参数进行模型设定后,在具体的关键词识别过程中,通过深度神经网络模型对梅尔频率倒谱系数进行处理,获得其对应的关键词的准确率也将大于或等于95%,以保证在根据深度神经网络模型获得对应的关键词的准确性。其中,深度神经网络模型可选择卷积神经网络,简称cnn;深度神经网络,简称dnn;循环神经网络,简称rnn;长短时记忆网络,简称lstm,其中以上只是部分深度神经网络的示例,关于具体的深度神经网络的选用,本技术不进行具体限制。
54.具体的,在对深度神经网络模型进行训练,获得深度神经网络模型参数后,在后续具体的关键词推理过程中,根据该神经网络模型参数对具体识别过程中的深度网络模型进行设置,进而对音频码流对应的关键词进行推理,进而提高关键词推理过程的处理速度和关键词识别的准确率。
55.本技术对深度神经网络模型的训练方法,基于对音频文件进行离散余弦变换,并在该基础上获得梅尔频率倒谱系数。而现有技术中提到的神经网络模型是基于快速傅里叶变换,并在此基础上获得梅尔频率倒谱系数。另外,本技术的关键词识别方法,在此训练方法的基础上,在进行实际的关键词的识别时,能够较大的节省音频解码和特征提取过程的运算量,避免现有技术中,频域到时域以及时域到频域的转换过程。降低功耗,节省算力。
56.图6示出了本技术基于深度学习的关键词识别方法的一个实例的流程示意图。如图6所示,在本技术的方法中,与现有技术相比,在解码流程中省略了频域到时域的转换过程,在特征识别的过程中,也相对应的省略了时域到频域的转换过程,通过将这两个需要较
大运算能力和功耗的步骤省略,进而节省算力,加快关键词的识别过程。
57.本技术既可以用于低功耗蓝牙音频,也可以用于经典蓝牙。既可以用于蓝牙领域,还可以用于其他无线通信领域,特别是关键词识别;充分利用音频解码器已有的信息与现有的算法模块,通过省略解码过程中的低延迟改进型离散余弦逆变换和长期后置滤波器的处理过程,进而降低了解码器的运算复杂度,通过省略加窗和时频转换的处理过程,又降低了关键词识别特征提取模块的运算复杂度;基于上,较大的节省了功耗,延长了设备的使用时间。节省了相关模块需要的程序空间和代码空间,降低了设备的成本。本技术的方法可应用在蓝牙遥控器与智能家居的组合中,通过蓝牙遥控器控制并编码后的音频码流进行关键词识别,实现对智能家居的控制。其中,以上及其应用情况,均在本技术的保护范围内。
58.本技术的基于深度学习的关键词识别方法将音频码流的标准解码流程中的运算量较大的频域到时域的转换过程进行省略,对应的将关键词识别过程中的时域向频域转换的省略,通过直接根据离散余弦变换谱系数进行识别,得到梅尔频率倒谱系数,通过预先训练好的深度神经网络模型对梅尔频率倒谱系数进行处理,得到该音频码流对应的关键词。本技术的方法将关键词识别过程中的运算量较大的过程省略,节省算力,降低功耗,提高关键词的识别速度。尤其对功耗有严格要求的低功耗蓝牙,具有较大的意义。另外,本技术通过深度神经网络模型进行关键词的识别,保证关键词识别的准确性。
59.图7示出了本技术基于深度学习的关键词识别系统的一个实施方式的示意图。
60.在图7所示的实施方式中,本技术的基于深度学习的关键词识别系统包括:音频解码模块701,其在音频接收端对音频码流解码时,仅进行至标准解码流程中的变换域噪声整形解码步骤,获取所述音频码流对应的离散余弦变换谱系数;特征提取模块702,其对离散余弦变换谱系数进行特征提取,得到梅尔频率倒谱系数;以及神经网络模型处理模块703,其根据预先训练的深度神经网络模型对梅尔频率倒谱系数处理,得到音频码流对应的关键词概率。
61.可选的,特征提取模块中,其对频域内的离散余弦变换谱系数进行预加重处理,并在预加重处理后,直接进行能量谱运算处理,省略掉预加重处理与能量谱运算处理之间的时域到频域的转换过程。
62.可选的,在特征提取模块中的预加重过程包括:在预建立的预加重系数表中提取相应的预加重系数;根据预加重系数对离散余弦变换谱系数进行预加重处理,其中预加重系数与离散余弦变换谱系数一一对应。其中具体的执行过程与上述关键词识别方法中的描述一致,在此不进行赘述。在该实施方式中,通过将音频解码器中的频域到时域转换的步骤删除,进而省略掉关键词识别过程中的时域到频域的转换过程,降低运算量,加快关键词的识别速度。通过利用音频解码器得出的离散余弦变换谱系数做特征提取,并基于mfcc特征利用深度神经网络模型进行处理,直接得到对应的关键词概率。其中,在深度神经网络模型对梅尔频率倒谱系数mfcc特征进行关键词的推理时,会根据预先确定好的深度神经网络模型参数进行模型设置,进而提高关键词推理过程的处理速度和准确性。其中,本技术的基于深度学习的关键词识别系统的运行原理与上述的基于深度学习的关键词识别方法的原理类似,不再进行赘述。
63.在本技术的一个具体实施方式中,一种计算机可读存储介质,其存储有计算机指令,其中计算机指令被操作以执行任一实施例描述的基于深度学习的关键词识别方法。其
中,该存储介质可直接在硬件中、在由处理器执行的软件模块中或在两者的组合中。
64.软件模块可驻留在ram存储器、快闪存储器、rom存储器、eprom存储器、eeprom存储器、寄存器、硬盘、可装卸盘、cd
‑
rom或此项技术中已知的任何其它形式的存储介质中。示范性存储介质耦合到处理器,使得处理器可从存储介质读取信息和向存储介质写入信息。
65.处理器可以是中央处理单元(英文:central processing unit,简称:cpu),还可以是其他通用处理器、数字信号处理器(英文:digital signal processor,简称:dsp)、专用集成电路(英文:application specific integrated circuit,简称:asic)、现场可编程门阵列(英文:field programmable gate array,简称:fpga)或其它可编程逻辑装置、离散门或晶体管逻辑、离散硬件组件或其任何组合等。通用处理器可以是微处理器,但在替代方案中,处理器可以是任何常规处理器、控制器、微控制器或状态机。处理器还可实施为计算装置的组合,例如dsp与微处理器的组合、多个微处理器、结合dsp核心的一个或一个以上微处理器或任何其它此类配置。在替代方案中,存储介质可与处理器成一体式。处理器和存储介质可驻留在asic中。asic可驻留在用户终端中。在替代方案中,处理器和存储介质可作为离散组件驻留在用户终端中。
66.在本技术的一个具体实施方式中,一种计算机设备,其包括处理器和存储器,存储器存储有计算机指令,其中:处理器操作计算机指令以执行任一实施例描述的基于深度学习的关键词识别方法。
67.在本技术所提供的实施方式中,应该理解到,所揭露的装置,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
68.作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
69.以上仅为本技术的实施例,并非因此限制本技术的专利范围,凡是利用本技术说明书及附图内容所作的等效结构变换,或直接或间接运用在其他相关的技术领域,均同理包括在本技术的专利保护范围内。