1.本发明涉及一种关键词检测方法,具体涉及一种基于语音识别的关键词检测方法。
背景技术:
2.传统关键词检测系统一般是由声学特征提取模块、声学模型、语言模型和解码器组成,利用声学特征提取模块对音频信号做预处理,再通过解码器、声学模型和语言模型中的数据进行对比来获得结果,比较常用的几种算法有动态时间规整、viterbi算法、hmm等。传统关键词检测系统需要分模块设计相对复杂,同时模型限制了不同人声的识别范围。在输入数据与目标词汇对比时,传统语音识别往往采用多遍搜索策略来保证准确率,这提高了传统关键词系统的识别率,但同时也增大了识别延迟。
3.随着近年来神经网络的兴起,神经网络被运用于关键词识别中。以tensorflow推出的关键词检测系统为例,整个系统由声学提取特征模块和识别网络构成,音频信号经过声学提取特征模块预处理成离散矩阵向量,经过识别网络后输出最终结果,相比于传统关键词检测系统,基于神经网络的关键词检测系统设计简单,识别准确率也相对更高。
4.现有的语音关键词检出技术通常需要较大的算力和内存做支撑,很难在家用pc以及嵌入式设备上使用。
5.即使部分智能家居设备,也只是实现了单个词的唤醒功能后续的识别还是需要连接互联网由后台大算力的服务器去做相应的计算,前段无法直接检出关键词。
技术实现要素:
6.本发明的目的在于提供一种关键词检测方法,以解决上述背景技术中提出的问题。
7.为实现上述目的,本发明提供如下技术方案:
8.一种关键词检测方法,包括以下步骤:
9.通过语音数据训练获得声学模型并通过文本数据训练获得语言模型;
10.将声学模型和语言模型通过字典进行关联获得语音模型,其中,语音模型的数据根据语言使用频率分别设置在常用语音数据库和备用语音数据库;
11.对接收到的语音进行特征提取,通过语音解码和搜索算法带入语音模型的常用语音数据库进行语音匹配计算,若匹配则输出接收到的语音所匹配的文字,若无匹配结果则带入语音模型的备用语音数据库进行语音匹配计算,若匹配则输出接收到的语音所匹配的文字,若无匹配结果则将接收到的语音信息存储至未识别语音数据库。
12.作为本发明进一步的方案:在输出接收到的语音所匹配的文字后同步对该文字进行计数;
13.基于计数对常用语音数据库和备用语音数据库进行优化,一定使用周期内,将备用语音数据库内的高频使用的词汇移动至常用语音数据库并将常用语音数据库内的低频
使用的词汇移动至备用语音数据库。
14.作为本发明进一步的方案:基于计数对常用语音数据库和备用语音数据库进行优化包括以下步骤:
15.对一定使用周期内的常用语音数据库内的数据的使用次数进行统计获取使用次数最少的n个数据;
16.对一定使用周期内的备用语音数据库内的数据的使用次数进行统计获取使用次数最多的m个数据;
17.将从常用语音数据库获取的n个数据和备用语音数据库获得的m个数据根据使用次数进行排序并将使用次数多的n个数据移动至常用语音数据库其余数据移动至备用语音数据库。
18.作为本发明进一步的方案:n个数据在常用语音数据库内的占比小于10%。
19.作为本发明进一步的方案:m个数据在备用语音数据库内的占比小于10%。
20.作为本发明进一步的方案:n大于等于1且小于100。
21.作为本发明进一步的方案:m大于等于1且小于100。
22.作为本发明进一步的方案:定期将未识别语音数据库内的数据进行上传。
23.作为本发明进一步的方案:通过语音数据训练获得声学模型包括以下步骤:
24.创建语音数据库;
25.进行特征提取;
26.进行声学模型训练;
27.获得声学模型。
28.作为本发明进一步的方案:通过文本数据训练获得语言模型包括以下步骤:
29.创建文本数据库;
30.进行语言模型训练并引入加权算法获得语言模型。
31.与现有技术相比,本发明的有益效果是:不需要服务器进行计算,可以由前段进行检测从而可以适配普通pc以及嵌入式设备。
32.通过优化语料的方式,采用较小的语料库训练出高准确率的关键词模型,并且支持普通pc的方式部署甚至嵌入式的方式部署。
33.采用常用语音数据库和备用语音数据库相比传统的单一大数据库的方式,进一步缩小常用数据库的大小,提升了关键词数据识别的效率,更好地适配普通pc和嵌入式设备。
附图说明
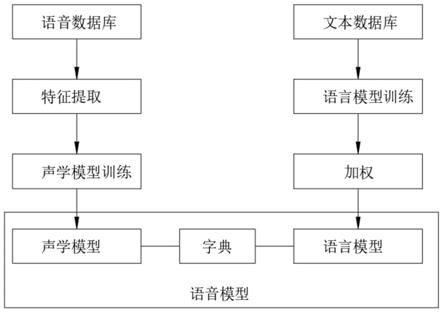
34.图1是本发明的关键词检测方法的创建语音模型的流程框图;
35.图2是本发明的关键词检测方法的语音识别的流程图。
具体实施方式
36.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
37.如图1和图2所示,一种关键词检测方法,包括以下步骤:
38.通过语音数据训练获得声学模型并通过文本数据训练获得语言模型;
39.将声学模型和语言模型通过字典进行关联获得语音模型,其中,语音模型的数据根据语言使用频率分别设置在常用语音数据库和备用语音数据库;
40.对接收到的语音进行特征提取,通过语音解码和搜索算法带入语音模型的常用语音数据库进行语音匹配计算,若匹配则输出接收到的语音所匹配的文字,若无匹配结果则带入语音模型的备用语音数据库进行语音匹配计算,若匹配则输出接收到的语音所匹配的文字,若无匹配结果则将接收到的语音信息存储至未识别语音数据库。
41.其中,在通过文本数据训练获得语言模型时引入加权算法。
42.作为一种优选的实施方式,在输出接收到的语音所匹配的文字后同步对该文字进行计数;
43.基于计数对常用语音数据库和备用语音数据库进行优化,一定使用周期内,将备用语音数据库内的高频使用的词汇移动至常用语音数据库并将常用语音数据库内的低频使用的词汇移动至备用语音数据库。
44.作为一种优选的实施方式,基于计数对常用语音数据库和备用语音数据库进行优化包括以下步骤:
45.对一定使用周期内的常用语音数据库内的数据的使用次数进行统计获取使用次数最少的n个数据;
46.对一定使用周期内的备用语音数据库内的数据的使用次数进行统计获取使用次数最多的m个数据;
47.将从常用语音数据库获取的n个数据和备用语音数据库获得的m个数据根据使用次数进行排序并将使用次数多的n个数据移动至常用语音数据库其余数据移动至备用语音数据库。其中,m可以与n相等或不等。
48.作为一种具体的实施方式,n个数据在常用语音数据库内的占比小于10%。m个数据在备用语音数据库内的占比小于10%。
49.作为一种具体的实施方式,n大于等于1且小于100。m大于等于1且小于100。
50.作为一种具体的实施方式,定期将未识别语音数据库内的数据进行上传。由服务器获取数据后,可以将新接收到的数据人工识别后引入语音模型后进行更新。
51.作为一种具体的实施方式,通过语音数据训练获得声学模型包括以下步骤:
52.创建语音数据库;
53.进行特征提取;
54.进行声学模型训练;
55.获得声学模型。
56.作为一种具体的实施方式,通过文本数据训练获得语言模型包括以下步骤:
57.创建文本数据库;
58.进行语言模型训练并引入加权算法获得语言模型。
59.对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权
利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
60.此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。