1.本发明涉及语音识别的技术领域,尤其涉及一种语音关键词的识别方法及系统。
背景技术:
2.随着物联网的快速发展,物联网设备的越发普及,为了提高用户使用物联网设备与用户的交互效率,通常会在设备中加入语音识别模型,通过语音识别模型识别用户的意图并执行相应的操作。
3.目前常用的语音识别模型的语音识别方法可以细分为大词汇量的asr识别、小词汇量识别以及关键词识别。具体是采用用户输入的训练数据集,对数据集信息上述识别方法进行神经网络训练,从而生成对应语音识别模型进行语音识别。
4.但目前常用的语音识别模型有如下技术问题:识别训练所需的数据集要求很高,若数据集的关键词数量小,数据集内会包含大量无关紧要的词汇,降低识别的准确率,若数据集包含大量特定关键词进行训练,则用户需要在前期花费大量时间进行词语采集,既增加训练难度,也降低训练效率;而且由于训练后的语音识别模型是采用单一数据集训练,使得语音识别模型难调整,进一步降低模型的灵活性和实用性。
技术实现要素:
5.本发明提出一种语音关键词的识别方法及系统,所述方法可以降低训练难度,增加训练效率,提高识别准确率。
6.本发明实施例的第一方面提供了一种语音关键词的识别方法,所述方法包括:
7.获取预设的语音数据集;
8.从所述预设的语音数据集中提取fbank特征,并对所述fbank特征进行归一化处理得到归一化特征;
9.采用预设的seq2seq+attention对所述归一化特征进行不定长序列的模型训练,得到语音识别模型;
10.获取预设的asr模型,并采用所述预设的asr模型对所述语音识别模型进行端对端的模型训练调整得到训练模型;
11.采用所述训练模型进行语音识别。
12.在第一方面的一种可能的实现方式中,所述从所述预设的语音数据集中提取fbank特征,包括:
13.获取所述语音数据集的语音波形;
14.对所述语音波形分别进行预操作得到预操作波形,其中所述预操作包括:预加重、分帧和加窗操作;
15.对所述预操作波形进行快速傅立叶变换得到波形绝对值;
16.采用预设的梅尔滤波器组过滤所述波形绝对值得到fbank特征。
17.在第一方面的一种可能的实现方式中,所述对所述fbank特征进行归一化处理得
到归一化特征,包括:
18.采用预设的iir低通滤波器对所述fbank特征进行低通滤波得到低通滤波特征;
19.对所述低通滤波特征进行自动增益控制和非线性压缩,得到归一化特征。
20.在第一方面的一种可能的实现方式中,所述采用预设的seq2seq+attention模型对所述fbank特征进行不定长序列的模型训练,得到语音识别模型,包括:
21.将所述归一化特征转换生成特征序列;
22.将所述特征序列输入至所述预设的seq2seq+attention模型进行不定长序列的模型训练,得到语音识别模型。
23.在第一方面的一种可能的实现方式中,所述预设的asr模型具体为用户预先训练且包含关于音素级别的声学特征的模型。
24.在第一方面的一种可能的实现方式中,所述预设的语音数据集为开源的数据集,具体包括:若干数量的asr语音数据集和若干数量的关键词数据集。
25.本发明实施例的第二方面提供了一种语音关键词的识别系统,所述系统包括:
26.获取模块,用于获取预设的语音数据集;
27.归一化模块,用于从所述预设的语音数据集中提取fbank特征,并对所述fbank特征进行归一化处理得到归一化特征;
28.训练模块,用于采用预设的seq2seq+attention对所述归一化特征进行不定长序列的模型训练,得到语音识别模型;
29.调整模块,用于获取预设的asr模型,并采用所述预设的asr模型对所述语音识别模型进行端对端的模型训练调整得到训练模型;
30.识别模块,用于采用所述训练模型进行语音识别。
31.在第二方面的一种可能的实现方式中,所述归一化模块还用于:
32.获取所述语音数据集的语音波形;
33.对所述语音波形分别进行预操作,预操作波形,其中所述预操作包括:预加重、分帧和加窗操作;
34.对所述预操作波形进行快速傅立叶变换得到波形绝对值;
35.采用预设的梅尔滤波器组过滤所述波形绝对值得到fbank特征。
36.在第二方面的一种可能的实现方式中,所述归一化模块还用于:
37.采用预设的iir低通滤波器对所述fbank特征进行低通滤波得到低通滤波特征;
38.对所述低通滤波特征进行自动增益控制和非线性压缩,得到归一化特征。
39.在第二方面的一种可能的实现方式中,所述训练模块还用于:
40.将所述归一化特征转换生成特征序列;
41.将所述特征序列输入至所述预设的seq2seq+attention模型进行不定长序列的模型训练,得到语音识别模型。
42.在第二方面的一种可能的实现方式中,所述预设的asr模型具体为用户预先训练且包含关于音素级别的声学特征的模型。
43.在第二方面的一种可能的实现方式中,所述预设的语音数据集为开源的数据集,具体包括:若干数量的asr语音数据集和若干数量的关键词数据集。
44.相比于现有技术,本发明实施例提供的语音关键词的识别方法及系统,其有益效
果在于:本发明可以充分利用开源的数据集进行网络预训练,并通过模型训练对识别的关键词进行微调,以确保了识别率同时也可以降低误识别,从而避免了因分类思想的训练方法要设计大量垃圾词汇而导致的误识别的问题,大大提高了识别的准确率,并且本技术使用端对端的训练方式,可以大大缩小训练模型的体积,减少模型的占用空间,进一步提高识别的灵活性和实用性。
附图说明
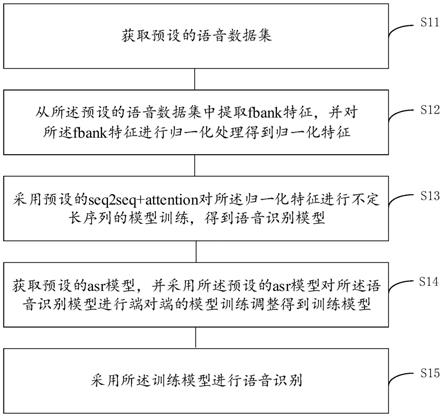
45.图1是本发明一实施例提供的一种语音关键词的识别方法的流程示意图;
46.图2是本发明一实施例提供的一种语音关键词的识别系统的结构示意图。
具体实施方式
47.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
48.目前常用的语音识别模型有如下技术问题:识别训练所需的数据集要求很高,若数据集的关键词数量小,数据集内会包含大量无关紧要的词汇,降低识别的准确率,若数据集包含大量特定关键词进行训练,则用户需要在前期花费大量时间进行词语采集,既增加训练难度,也降低训练效率;而且由于训练后的语音识别模型是采用单一数据集训练,使得语音识别模型难调整,进一步降低模型的灵活性和实用性。
49.为了解决上述问题,下面将通过以下具体的实施例对本技术实施例提供的一种语音关键词的识别方法进行详细介绍和说明。
50.参照图1,示出了本发明一实施例提供的一种语音关键词的识别方法的流程示意图。
51.其中,作为示例的,所述语音关键词的识别方法,可以包括:
52.s11、获取预设的语音数据集。
53.在本实施例中,所述预设的语音数据集为开源的数据集。具体地,开源的数据集具体可以包括:若干数量的asr语音数据集和若干数量的关键词数据集。
54.在实际操作中,可以是用于基于特定的使用场景或使用需求来采集。
55.例如,使用对象是银行客户,可以采集大量银行交易或用户业务所需的关键词数据集;又例如,使用对象是网购交易,可以采集大量网购所需的关键词数据集。
56.s12、从所述预设的语音数据集中提取fbank特征,并对所述fbank特征进行归一化处理得到归一化特征。
57.fbank(filter bank)特征,由于fbank特征更加的符合人类的听觉原理,可以通过fbank特征确定用户的语音数据对应的内容。
58.由于fbank特征包含多个数据内容,为了方便后续的训练处理,可以在获取fbank特征后对fbank特征进行归一化处理,以统一fbank特征。
59.为了准确获取fbank特征,其中,作为示例的,步骤s12可以包括以下子步骤:
60.子步骤s121、获取所述语音数据集的语音波形。
61.在实际操作中,可以对语音数据集的语音数据进行波形转换,得到语音波形。
62.子步骤s122、对所述语音波形分别进行预操作得到预操作波形,其中所述预操作包括:预加重、分帧和加窗操作。
63.预加重是将语音波形通过一个高通滤波器,来增强语音信号中的高频部分,并保持在低频到高频的整个频段中,能够使用同样的信噪比求频谱。
64.对语音波形进行预加重有以下几点好处:可以平衡频谱,因为高频通常与较低频率相比具有较小的幅度;可以避免在傅里叶变换操作操作过程中出现数值问题;也可以改善信号
‑
噪声比(snr);可以消除发声过程中声带和嘴唇的效应,来补偿语音中受到发音系统所抑制的高频部分,也突出高频的共振峰。
65.分帧是指在语音波形中,按照某一个固定的时间长度分割,分割后的每一片样本,称之为一帧。分割后的一帧是分析提取fbank的样本。
66.加窗是对语音波形分割成帧后,对每一帧乘以一个窗函数,以增加帧左端和右端的连续性,抵消fft(假设数据是无限的)并减少频谱泄漏。在其中一种可选的实施例中,所述窗函数可以是hamming窗。
67.子步骤s123、对所述预操作波形进行快速傅立叶变换得到波形绝对值。
68.子步骤s124、采用预设的梅尔滤波器组过滤所述波形绝对值得到fbank特征。
69.在获取fbank特征后,需要对fbank特征进行归一化处理,以方便后续的模型训练。其中,作为示例的,步骤s12可以包括以下子步骤:
70.子步骤s125、采用预设的iir低通滤波器对所述fbank特征进行低通滤波得到低通滤波特征。
71.子步骤s126、对所述低通滤波特征进行自动增益控制和非线性压缩,得到归一化特征。
72.对fbank特征进行归一化后,可以在寻求最优解的过程变得平缓,更容易正确的收敛到最优解,提高数据的处理效率和准确率。
73.s13、采用预设的seq2seq+attention对所述归一化特征进行不定长序列的模型训练,得到语音识别模型。
74.所述预设的seq2seq+attention为一个encoder
–
decoder结构的网络,其中encoder中将一个可变长度的信号序列变为固定长度的向量表达,decoder将这个固定长度的向量变成可变长度的目标的信号序列。
75.由于预设的seq2seq+attention网络的输入是序列,其输出也是序列,为了让归一化特征满足预设的seq2seq+attention网络的处理要求,其中,作为示例的,步骤s13可以包括以下子步骤:
76.子步骤s131、将所述归一化特征转换生成特征序列。
77.子步骤s132、将所述特征序列输入至所述预设的seq2seq+attention模型进行不定长序列的模型训练,得到语音识别模型。
78.s14、获取预设的asr模型,并采用所述预设的asr模型对所述语音识别模型进行端对端的模型训练调整得到训练模型。
79.可选地,所述预设的asr模型具体为用户预先训练且包含关于音素级别的声学特征的模型。
80.预设的asr模型可以是已经学到了很多关于音素级别的声学特征的模型。该预设的asr模型可以通过多次使用关键词训练,其目的是为了让模型更加专注于关键词的那部分声学特征,从而提高了识别率。
81.而通过asr模型对语音识别模型进行对端对端模型训练,可以让语音识别模型自动去调整之前学习到的网络参数,进一步提高识别的准确率,并且端对端的训练可以方便进行关键词识别微调,同时相比其他算法模型占用空间小,减少训练所需的空间占用率。
82.s15、采用所述训练模型进行语音识别。
83.在完成训练后,可以采用训练模型进行语音识别,以方便用户操作。
84.在本实施例中,本发明实施例提供了一种语音关键词的识别方法,其有益效果在于:本发明可以充分利用开源的数据集进行网络预训练,并通过模型训练对识别的关键词进行微调,以确保了识别率同时也可以降低误识别,从而避免了因分类思想的训练方法要设计大量垃圾词汇而导致的误识别的问题,大大提高了识别的准确率,并且本技术使用端对端的训练方式,可以大大缩小训练模型的体积,减少模型的占用空间,进一步提高识别的灵活性和实用性。
85.本发明实施例还提供了一种语音关键词的识别系统,参见图2,示出了本发明一实施例提供的一种语音关键词的识别系统的结构示意图。
86.其中,作为示例的,所述语音关键词的识别系统可以包括:
87.获取模块201,用于获取预设的语音数据集;
88.归一化模块202,用于从所述预设的语音数据集中提取fbank特征,并对所述fbank特征进行归一化处理得到归一化特征;
89.训练模块203,用于采用预设的seq2seq+attention对所述归一化特征进行不定长序列的模型训练,得到语音识别模型;
90.调整模块204,用于获取预设的asr模型,并采用所述预设的asr模型对所述语音识别模型进行端对端的模型训练调整得到训练模型;
91.识别模块205,用于采用所述训练模型进行语音识别。
92.可选地,所述归一化模块还用于:
93.获取所述语音数据集的语音波形;
94.对所述语音波形分别进行预操作,预操作波形,其中所述预操作包括:预加重、分帧和加窗操作;
95.对所述预操作波形进行快速傅立叶变换得到波形绝对值;
96.采用预设的梅尔滤波器组过滤所述波形绝对值得到fbank特征。
97.可选地,所述归一化模块还用于:
98.采用预设的iir低通滤波器对所述fbank特征进行低通滤波得到低通滤波特征;
99.对所述低通滤波特征进行自动增益控制和非线性压缩,得到归一化特征。
100.可选地,所述训练模块还用于:
101.将所述归一化特征转换生成特征序列;
102.将所述特征序列输入至所述预设的seq2seq+attention模型进行不定长序列的模型训练,得到语音识别模型。
103.可选地,所述预设的asr模型具体为用户预先训练且包含关于音素级别的声学特
征的模型。
104.可选地,所述预设的语音数据集为开源的数据集,具体包括:若干数量的asr语音数据集和若干数量的关键词数据集。
105.进一步的,本技术实施例还提供了一种电子设备,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述实施例所述的语音关键词的识别方法。
106.进一步的,本技术实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机可执行指令,所述计算机可执行指令用于使计算机执行如上述实施例所述的语音关键词的识别方法。
107.以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。