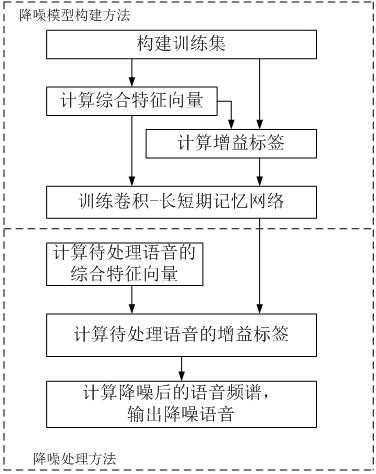
1.本发明属于人工智能技术领域,涉及语音识别,具体涉及一种降噪模型构建和降噪处理方法。
背景技术:
2.在语音通话中,语音降噪技术可以有效的抑制噪声干扰,提升听觉体验。又或者语音识别领域中,语音降噪技术可以有效的降低噪声,使得语音的特征信息更加明显。此外降噪技术可以使得语音活性检测更加准确,从而减小语音识别中解码的数据量。
3.在语音降噪技术领域,传统的降噪算法由于对噪声的估计速度上存在延时而无法很好的处理非平稳噪声,这会影响语音通话体验;在语音识别中,降噪的不彻底会影响语音特征的提取,残留噪声过多也会提高语音活性检测的难度。而对于神经网络的降噪算法,其数据集的构建对最终的效果也有较大的影响。
技术实现要素:
4.为克服现有技术存在的缺陷,本发明公开了一种降噪模型构建和降噪处理方法。
5.本发明公开了一种降噪模型构建方法,包括如下步骤:s1.对纯净语音集和噪声集中的纯净语音和噪声按照预定时长及信噪比随机单条组合并进行线性叠加,得到多个单条带噪语音,形成训练集;s2.对训练集中带噪语音的频域数据,按频率高低划分为m2个频带,计算各个频带的子带倒谱特征系数和带噪语音子带能量;计算子带倒谱特征系数的频谱稳定度stability(l) 和子带倒谱特征系数,并计算子带倒谱特征系数前m1个低频频带的一阶、二阶差分系数,m1为小于子带总数量的子带提取数;所述频谱稳定度stability(l)、子带倒谱特征系数、子带倒谱特征系数前m1个低频频带的一阶、二阶差分系数组成综合特征向量features(l),其维度为m3;l表示帧数;s3.求取带噪语音对应的纯净语音子带能量,并结合步骤s2得到的带噪语音子带能量求取增益标签;s4.构建卷积
‑
长短期记忆网络,输入步骤s2得到的综合特征向量features(l)作为输入,以步骤s3得到的增益标签为训练标签进行训练,修正模型权重系数,得到降噪模型;训练结束条件为达到设定的训练轮次或损失函数降低到设定值以下。
6.优选的,所述步骤s2具体为:s21 .对训练集中的带噪语音,逐条叠加正弦窗进行分帧加窗并进行快速傅里叶变换,得到频域数据x(k,l),k表示频点,l表示帧数。
7.所述步骤s2具体为:s22 .对频域数据x(k,l)按频率高低划分为m2个频带,计算带噪语音子带能量
band_noisy(i,l);band_h和band_l分别为频带上下端点,i表示子带编号;s23.子带倒谱特征系数sbcc(i,l)=dct(log(band_noisy(i,l)));dct表示离散余弦变换,log为取对数;s24.提取前m1个低频带的子带倒谱特征系数的差分系数,一阶差分系数diff_1(i)=sbcc(i,l)
‑
sbcc(i,l
‑
1);二阶差分系数diff_2(i)=sbcc(i,l)
‑
2*sbcc(i,l
‑
1)+sbcc(i,l
‑
2);i表示第i个子带,diff_1(i)表示第i个子带的一阶差分系数,diff_2(i)表示第i个子带的二阶差分系数;sbcc(i,l)表示第i个子带,第l帧的子带倒谱特征系数,其余以此类推;s25.计算频谱稳定度stability(l),其计算方式如下:l表示帧数,var表示求取方差。
8.优选的,所述步骤s3 中,增益标签gains(i,l)=band_clean(i,l)/band_noisy(i,l),band_clean(i,l)为纯净语音子带能量、band_noisy(i,l) 为带噪语音子带能量。
9.优选的,所述卷积
‑
长短期记忆网络从输入端到输出端包括依次连接的:一维卷积层conv1d,一维卷积层维度为m3,激活函数为tanh;所述一维卷积层还连接第四层长短期记忆网络和全连接层;节点数和输入特征维度一致;第一层长短期记忆网络,激活函数为relu函数;所述第一层长短期记忆网络还连接第三层长短期记忆网络;第二层长短期记忆网络,激活函数为relu函数;第一层和第二层长短期记忆网络的单层网络节点数量设置大于输入特征维度;第三层长短期记忆网络,激活函数为relu函数;第四层长短期记忆网络,激活函数为relu函数;节点数量设置大于第三层和一维卷积层节点数量和;全连接层,节点数为m2。
10.优选的,所述带噪语音命名与选择的纯净语音和噪声名称相关。
11.本发明还公开了一种降噪处理方法,包括如下步骤:s5.计算待降噪语音对应的综合特征向量;s6. 综合特征向量输入所述降噪模型构建方法得到的降噪模型;得到增益标签gains(i,l);i,l分别表示第i个子带和帧数;s7.则降噪后的语音频谱为x1* gains(i,l),其中x1为待处理的带噪语音的频域
数据;根据降噪后的语音频谱即可得到降噪后的语音。
12.优选的,所述步骤s6中,对增益值进行平滑处理,平滑处理后的增益标签gains1(i,l)=alpha1*gains(i,l
‑
1)*(1
‑
alpha1)*gains(i,l);alpha1为第一平滑系数;将平滑处理后的增益标签gains1(i,l)输入步骤s7。
13.优选的,所述步骤s6中,对增益值进行平滑处理,平滑处理后的增益标签:gains1(i,l)= (1
‑
alpha2(k))*gains(i,l)+alpha2(i)*gains(i+1,l)第二平滑系数alpha2(i)=(i
‑
start)/sub_band_widthi表示频带序号,start是频带的起始频点,sub_band_width为频带带宽;将平滑处理后的增益标签gains1(i,l)输入步骤s7本发明利用提取带噪语音的传统语音信号特征以及获取对应的标签和频谱增益,通过神经网络训练得到权重系数;在做语音降噪时,即可通过神经网络的权重系数计算得出实时带噪语音的频谱增益,从而实现降噪。本发明使用神经网络替代了传统算法中的计算噪声估计后求语音增益的过程,克服了噪声估计中的时延问题,在高噪声环境下几乎没有残留噪声,对类人声外的非平稳噪声也有降噪作用。
附图说明
14.图1 为本发明的一个具体实施方式流程图;图2 为本发明所述卷积
‑
长短期记忆网络的一个具体实施方式示意图。
具体实施方式
15.下面对本发明的具体实施方式作进一步的详细说明。
16.本发明所述降噪模型构建方法,如图1所示,包括如下步骤:s1. 对纯净语音集和噪声集中的纯净语音和噪声按照预定时长及信噪比随机单条组合并进行线性叠加,得到多个单条带噪语音,形成训练集;s2.对训练集中带噪语音的频域数据,按频率高低划分为m2个频带,计算各个频带的子带倒谱特征系数和带噪语音子带能量;计算子带倒谱特征系数的频谱稳定度stability(l) 和子带倒谱特征系数,并计算子带倒谱特征系数前m1个低频频带的一阶、二阶差分系数,m1为小于子带总数量的子带提取数;所述频谱稳定度stability(l)、子带倒谱特征系数、子带倒谱特征系数前m1个低频频带的一阶、二阶差分系数组成综合特征向量features(l),其维度为m3;l表示帧数;s3.求取带噪语音对应的纯净语音子带能量,并结合步骤s2得到的带噪语音子带能量求取增益标签;s4.构建卷积
‑
长短期记忆网络,输入步骤s2得到的综合特征向量features(l)作为输入,以步骤s3得到的增益标签为训练标签进行训练,修正模型权重系数,得到降噪模型;训练结束条件为达到设定的训练轮次或损失函数降低到设定值以下。
17.一个具体流程如下:
s1. 对纯净语音集和噪声集按照预定时长及信噪比随机构建训练集数据。
18.s11.从纯净语音集中随机选择一条音频,从噪声集中随机选择一条音频,按照指定时长和指定信噪比进行线性叠加得到单条带噪语音;s12.重复s11步骤直到单条带噪语音数量符合要求,例如达到设定目标1万条,且覆盖了纯净语音集和噪声集中全部音频。
19.所谓指定时长为选择相同时长的纯净语音和噪音进行组合,如果原始语音单条长度不满指定时长的,可以在剩余的纯净语音集中随机选择一条拼接成30s。噪声也采用同样的方式来满足指定时长,保证两条语音的长度一致。
20.所谓指定信噪比指随机在语音集和噪声集中根据指定的信噪比,比如
‑
15db,
‑
10db的信噪比,选择语音样本和噪声样本,并对选择的样本按照一个设定的信噪如
‑
25db的幅度来进行归一化,得到信噪比一样的语音或噪声。归一化可以参考以下方法:speech_norm = speech * 10^(
‑
2.5)/10sqrt(mean(speech^2))speech表示原始的语音或者噪声样本,mean表示取平均,sqrt表示开方。peech_norm表示归一化后的语音或者噪声。之后再对归一化后的纯净语音和噪声叠加。
21.按照叠加后单条带噪语音的信噪比分集并构建得到训练集。
22.一个具体操作如下:对采样率为16khz的wav音频文件,按照叠加后信噪比从
‑
20db到20db共分9个级别、单条语音30s总时长500小时来构建数据集。
23.带噪语音的构造具体方式为,从纯净语音集中随机选择一条纯净语音,从噪声集中随机选择一条噪声,按照指定时长指定信噪比线性叠加。
24.其中原始语音单条长度不满30s的则在剩余的纯净语音集中随机选择一条拼接成30s。噪声也采用同样的方式来凑够长度,保证两条语音的长度一致。
25.这样构建训练集数据的目的是:可以尽量的覆盖从低到高不同的信噪比区间,实现不同的纯净语音和噪声的叠加,覆盖现实的噪声情形。这种随机选择的方式增加了随机性,使得训练集的样本更加全面和丰富。
26.在构建的同时可以对生成单条带噪语音进行命名。可以参考如下:例如被加噪的纯净语音重命名为“clean10.wav”,其中clean表示纯净语音,编号10表示第10条纯净语音;噪声集中选择的音频为noisy10表示第10条噪声音频,对应的信噪比为15或20db。
27.加噪后的带噪语音根据信噪比等级可重命名为:“noisy10_clean10_
‑
20db.wav”或“noisy10_clean10_
‑
15db.wav”,这样做的目的是为了方便后续计算增益gains时方便寻找带噪语音对应的纯净语音。
28.s2. 对带噪语音提取其特征及计算其子带能量。
29.对训练集中的带噪语音,逐条叠加正弦窗进行分帧加窗并进行快速傅里叶变换,得到频域数据x(k,l),k表示频点,l表示帧数。
30.对频域数据x(k,l)逐帧计算带噪语音的子带倒谱特征系数 (sbcc)、计算子带倒谱特征系数前m1个频带的一阶、二阶差分系数。
31.m1为小于子带总数量的子带提取数,m1取值一般以能够覆盖大部分低频语音信息为原则选择,例如本实施例中,m1 =10,可以覆盖2400赫兹以下全部子带,且不会造成特征数的增加从而导致模型变大。
32.具体为:
求取带噪语音子带能量band_h和band_l分别为该频带的上下端点,i表示子带编号;求取子带倒谱特征系数sbcc(i,l)=dct(log(band_noisy(i,l)))提取前m1个频带的一阶差分系数和二阶差分系数。具体为:一阶差分系数diff_1(i)=sbcc(i,l)
‑
sbcc(i,l
‑
1)二阶差分系数diff_2(i)=sbcc(i,l)
‑
2*sbcc(i,l
‑
1)+sbcc(i,l
‑
2)i表示第i个子带,diff_1(i)表示第i个子带的一阶差分系数,diff_2(i)表示第i个子带的二阶差分系数。
33.计算频谱稳定度stability(l),其计算方式如下:var表示求取方差。
34.步骤s2的一个具体实施方式为:对训练集中的带噪语音,逐条按照帧长32ms,帧移16ms,叠加sin正弦窗进行分帧加窗并进行快速傅里叶变换,得到频域数据x(k,l),k表示频点,l表示帧数。
35.逐帧计算带噪语音的子带倒谱特征系数 (sbcc)、前m1个频带的一阶二阶差分系数。
36.可按照符合心理声学的频带将经过fft的所有频带划分为m2个较大的子带。例如将0
‑
8khz的频带划分为m2=18个子带,具体划分按照如下:0
‑
200hz,200
‑
400hz,400
‑
600hz,600
‑
800hz,0.8
‑
1khz,1
‑
1.2hz,1.2
‑
1.4khz,1.4
‑
1.6khz,1.6
‑
2khz,2
‑
2.4khz,2.4
‑
2.8khz,2.8
‑
3.2khz,3.2
‑
4khz,4
‑
4.8khz,4.8
‑
5.6khz,5.6
‑
6.4khz,6.4
‑
7.2khz,7.2
‑
8khz。
37.划分的依据是:语音的主要成分在低频部分,所以低频部分划分的比较密集,以200hz为一级;中频部分采用400hz一级;中高频部分则采用800hz一级;高频部分采用1200hz一级。如果不划分子带并提取特征,那容纳这些输入则需要更大的神经网络,导致计算量剧烈增长。
38.带噪语音子带能量:划分为18个子带后,对子带能量取对数,并作离散余弦变换(dct),可得到18维的
子带倒谱特征系数,公式如下:sbcc(i,l)=dct(log(band_noisy(i,l)))i表示子带序号,i=1,2
…
18;然后根据子带倒谱特征系数可以提取前m1个频带的一阶差分系数和二阶差分系数。求取公式为:一阶差分系数diff_1(i)=sbcc(i,l)
‑
sbcc(i,l
‑
1)二阶差分系数diff_1(i)=sbcc(n,l)
‑
2*sbcc(n,l
‑
1)+sbcc(n,l
‑
2)i表示第i个子带,diff_1(i)表示第i个子带的一阶差分系数,diff_2(i)表示第i个子带的二阶差分系数,共求取前m1 个子带的差分系数。
39.频谱稳定度stability(l)统计从第l帧起连续q帧内的波动情况,当q=8时,其计算方式如下:即对每个频点而言,当前帧的前7帧到当前帧的倒谱系数cep相加取平均,然后计算方差,其作用是可以衡量在一定帧之间的一个频谱稳定,如果是语音段,那其频谱稳定度stability(l)会比较大;如果是背景噪声段,那频谱稳定度stability(l)相对会比较小。
40.将获得的子带倒谱特征系数、前m1 个子带的一阶差分系数和二阶差分系数,及频谱稳定度stability(l)组合形成综合特征向量features(l),综合特征向量features(l)维度m3为各部分维度和。
41.例如本实施例中,子带倒谱特征系数为18维,m1=10,一阶差分系数和二阶差分系数合计20维,频谱稳定度stability(l)为1维特征,综合特征向量features(l)共计39维,即m3=39;通过上述步骤可以获得每一帧的39维的综合特征向量features(l)和18维的带噪语音子带能量band_noisy(i,l),i表示子带,l表示帧数,其中组合特征被称为sbcc
‑
v。
42.例如:以s1中生成的带噪语音“noisy10_clean10_
‑
15db.wav”为例,s2中求得该条语音的所有特征以及子带能量,如该语音一共1000帧,可获得一组1000*m3个特征和1000*m2个子带能量数据,m3=39,m2=18。
43.s3.求取纯净语音子带能量及增益标签s31.对纯净语音计算子带能量band_clean(i,l),方法与前述的带噪语音子带能量计算方式相同。
44.例如:以s1中生成的带噪语音“noisy10_clean10_
‑
15db.wav”,可通过字符串在文件路径下找到对应的纯净语音“clean10.wav”,可获得每一帧的子带能量band_clean(i,l),累计大小为1000*18的能量数据。
45.s32.求取每一帧l的增益标签gains(i,l)根据带噪语音的命名中找到对应的纯净语音,并读取其子带能量。
46.如“noisy10_clean10_
‑
15db.wav”,其子带能量在s31中已经计算为band_clean
(i,l)。
47.其具体的方式为:gains(i,l)=band_clean(i,l)/band_noisy(i,l)i表示子带,按照s2至s3的步骤可对构造的训练集中的所有语音提取特征及增益,从而形成大量拥有“特征
‑
增益”对应关系的数据gains(i,l)。
48.s4.构建卷积
‑
长短期记忆网络(conv
‑
lstm)进行训练,得到模型权重系数。
49.卷积
‑
长短期记忆网络的一个具体实施方式如图2,输入为综合特征向量features(l),其维度m3=39维,对应m2=18维增益标签gains(i,l)为该神经网络的输出。
50.一维卷积层conv1d,一维卷积层维度为m3,激活函数为tanh;所述一维卷积层还连接第四层长短期记忆网络和全连接层;一维卷积层节点数为39维,和输入特征维度保持一致,目的是增加非线性特性。
51.第一层长短期记忆网络,激活函数为relu函数;所述第一层长短期记忆网络还连接第三层长短期记忆网络;第二层长短期记忆网络,激活函数为relu函数;第一层和第二层的的网络节点设置为48,数量大于特征数,目的是能通过网络对特征进行一个较好的拟合。
52.第三层长短期记忆网络,激活函数为relu函数;节点设置为56,通过网络压缩部分特征信息。
53.第四层长短期记忆网络,激活函数为relu函数;节点设置为128,这一层的大小需要大于第三层的输出加conv1d层的输出的大小。
54.输入首先经过一维卷积层conv1d,一维卷积层的滤波器数量为对应m3=39维维度,激活函数为tanh,目的是为了提升特征的非线性特性。
55.然后39维特征为经过图2中第一层和第二层两层长短期记忆网络(lstm)输出,每一层的节点数为48,激活函数为relu函数。这两层的输出和一维卷积层conv1d的输出一起经过节点数为56的第三层长短期记忆网络,其激活函数是relu函数。
56.第三层长短期记忆网络的输出和一维卷积层conv1d的输出一起经过一个节点数为128、激活函数为relu的第四层长短期记忆网络,经过18个节点数的全连接层(dense)转换为18维的输出。
57.模型的训练流程采用keras训练框架,模型按照上述描述以及图2示意的结构去搭建。训练过程中的损失函数采用mse,优化器为adam,整个训练集中的数据会有10%作为验证集,通过keras训练框架训练可以得到模型权重系数,从而得到经过这些模型权重系数修正后的卷积
‑
长短期记忆网络。
58.训练过程中39维的综合特征向量features(l)为输入,18维的gains为标签。
59.传统算法降噪是通过噪声估计,增益求解等流程和手段求得一组增益。而本发明采用神经网络取代噪声估计和增益求解,直接通过网络根据特征去拟合出增益,训练过程是以综合特征向量作为输入,以增益作为标签(期望输出)得到模型,在降噪过程中就可以提取真实语音特征,通过预先训练好的神经网络模型输出增益,从而达到降噪的效果。
60.但语音信号快速傅里叶变换后,频点数量增大,例如有256个频点,如果不进行特征提取,直接用频点数据去做训练,会造成神经网络大小的增加,因此需要进一步提取特征
进行压缩。
61.本发明利用sbcc特征频带性质,按照语音在整个频域上的分布情况来划分sbcc特征频带,对低频段进行较细致的频谱范围划分,高频段进行较宽频谱范围的划分。提取sbcc特征首先可以实现对特征维度的压缩,其次,sbcc特征具有区分度的表征噪声和语音的特性。
62.再根据sbcc特征计算一阶、二阶差分系数以及频谱稳定度,是为了增加表征声和语音的特性特征维度,在训练中更能区分开语音和噪声。
63.得到降噪模型后,进行降噪处理的方法如下。
64.s5.待处理的带噪语音按照步骤s2和s3所述方法得到待降噪语音对应的综合特征向量;s6.综合特征向量输入本发明所述降噪模型构建方法得到的所述降噪模型;得到增益标签gains(i,l);为保证平滑,增益不会出现太大的波动,可对当前帧的增益和上一帧的做平滑处理。
65.所述步骤s6中,对增益值进行平滑处理,平滑处理后的增益标签gains1(i,l)=alpha1*gains(i,l
‑
1)*(1
‑
alpha1)*gains(i,l);alpha1为第一平滑系数; i表示子带。其中第一平滑系数alpha1可以设置为0.6,可将该增益恢复成256维。
66.将平滑处理后的增益标签gains1(i,l)输入步骤s7进行后续处理。
67.为更好的提高平滑效果,所述步骤s6中,对增益值进行平滑处理,平滑处理后的增益标签:gains1(i,l)= (1
‑
alpha2(k))*gains(i,l)+alpha2(i)*gains(i+1,l)第二平滑系数alpha2(i)=(i
‑
start)/sub_band_widthi表示频带序号,start是频带的起始频点,sub_band_width为频带带宽;将平滑处理后的增益标签gains1(i,l)输入步骤s7。
68.第二平滑系数alpha2(i)的计算可以根据频带i的划分来变化,以0
‑
200hz为例。对应0到6个频点,0是起始频点,带宽度为6,记为sub_band_width=6。
69.s7.则降噪后的语音频谱为x1* gains(i,l),其中x1为待处理的带噪语音的频域数据;根据降噪后的语音频谱即可得到降噪后的语音。
70.对降噪后的语音频谱,可做反向快速傅里叶变换(ifft)后,合窗输出,即可得到降噪后的语音。
71.前文所述的为本发明的各个优选实施例,各个优选实施例中的优选实施方式如果不是明显自相矛盾或以某一优选实施方式为前提,各个优选实施方式都可以任意叠加组合使用,所述实施例以及实施例中的具体参数仅是为了清楚表述发明人的发明验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书内容所作的等同结构变化,同理均应包含在本发明的保护范围内。