1.本发明涉及智能音箱中说话人识别技术领域,涉及到特征提取部分的多特征融合方法,特别涉及到将短时能量、线性预测倒谱系数lpcc、梅尔倒谱系数mfcc及其一阶动态特征差分系数进行有机结合的方法。
背景技术:
2.随着人们对于居家生活质量要求的逐渐提高,智能音箱走进人们的生活。但在实际生活中智能音箱容易出现被环境噪音干扰而无法准确被唤醒的情况。为了解决该问题,研究工作者提出在进行说话人识别前进行特征提取,但采用任一单独的特征分量提取来进行说话人识别都可能出现对语音的清音识别不准确,或者抗噪性很差的情况。
3.因此,本发明采取多特征融合算法,将线性预测倒谱系数lpcc、梅尔倒谱系数mfcc及其一阶动态特征差分系数进行有机结合,并将梅尔倒谱系数mfcc中第一维特征分量替换成短时能量,为解决设备容易被环境音错误激活的问题提出了切实可行的办法。
技术实现要素:
4.本发明的主要目的是提供一种多特征融合的说话人识别方法,在特征提取部分进行多特征融合的说话人识别方法。
5.多特征融合的说话人识别方法,包括以下步骤:
6.a.计算线性预测倒谱系数lpcc。
7.a1.计算出预测系数。
8.a2.将预测系数带入线性预测倒谱公式,计算出8维线性预测倒谱系数lpcc。
9.b.计算梅尔倒谱系数mfcc的特征系数。
10.b1.计算12维梅尔倒谱系数mfcc。
11.b2.将第一维梅尔倒谱系数mfcc的特征分量去掉。
12.c.计算短时能量特征系数。
13.c1.对语音信号进行取平方处理。
14.c2.对其进行归一化处理和取对数处理。
15.d.计算一阶动态差分特征系数。
16.d1.将一维短时能量与梅尔倒谱系数mfcc进行有机结合。
17.d2.将有机结合后的12维特征分量进行一阶差分,得到一组新的差分系数。
18.e.将多特征进行有机结合。
19.其优点在于:
20.本发明首先利用公式计算线性预测倒谱系数lpcc的特征系数,然后利用公式计算梅尔倒谱系数mfcc,并将1维短时能量与梅尔倒谱系数mfcc进行有机结合,之后取有机结合后的12维梅尔倒谱系数mfcc特征分量的一阶动态差分系数。最后将多特征进行有机结合来提高对说话人识别的准确率。本方法不但提出了将线性预测倒谱系数lpcc、梅尔倒谱系数
mfcc及其一阶动态特征差分系数进行有机结合的特征提取方法,还解决了设备容易被环境音错误激活的问题,降低了智能音箱的误唤醒率。
附图说明
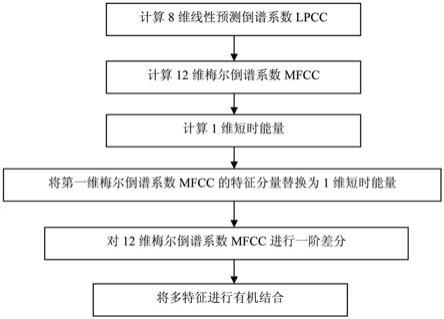
21.附图1是本发明中的多特征融合方法的总体流程图。
22.附图2是本发明中梅尔倒谱系数mfcc系数的计算过程。
具体实施方式
23.为使本发明实施例的目的、技术方案及其优点更加清楚,下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚完整的描述,整体算法流程图如图1所示:
24.a.计算线性预测倒谱系数lpcc的特征系数。
25.所述步骤a具体包含以下步骤:
26.a1.首先计算出预测系数a1~a
p
。
27.a2.然后,当线性预测倒谱系数n的阶数为1的时候,令语音信号lpc倒谱系数c
lp
(1)=a1,当线性预测倒谱系数n的阶数不为1的时候,使用进行计算。
28.当线性预测倒谱系数n的阶数不超过线性预测阶数p的时候,使用第一个公式进行计算,当线性预测倒谱系数n的阶数大于线性预测阶数p时则用第二个公式进行计算,进而得到语音信号lpc倒谱系数c
lp
(n)。本技术方案选取线性预测倒谱系数n为8,线性预测阶数p也为8。
29.b.计算梅尔倒谱系数mfcc的特征系数。
30.所述步骤b具体包含以下步骤:
31.b1.提取12维梅尔倒谱系数mfcc。首先对输入的语音信号进行预加重处理,然后对预处理之后得到的语音数据进行快速傅里叶变换(fft)。之后对每帧序列取模的平方进而得到离散功率谱。下一步将得到的离散功率谱用序列三角滤波器进行滤波处理,得到一组系数。下一步计算滤波器组输出参数的自然对数。最后对滤波器输出数据进行离散余弦变换(dct)。如图2所示,是梅尔倒谱系数mfcc的计算过程示意图。
32.b2.将获得的第一维梅尔倒谱系数mfcc的特征分量舍掉。
33.c.计算短时能量特征系数。
34.c1.对于信号{x(n)},其短时能量的定义如下:
35.其中h(n)为该线性滤波器的单位冲激响应,
h(n)=w(n)2,en表示在信号的第n个点开始加窗函数时的短时能量,窗函数w(n)为汉明窗,公式如下:
[0036][0037]
其中n为汉明窗的长度。
[0038]
c2.在语音特征中加入能量参数作为特征向量的一维分量,通常要用公式对其进行归一化处理和取对数。其中l为帧的数量,最后将得到的加入到特征向量中。
[0039]
d.计算一阶动态差分特征系数。
[0040]
d1.将1维短时能量与梅尔倒谱系数mfcc进行有机结合。
[0041]
d2.将有机结合后的12维特征分量进行一阶差分处理,差分参数的计算采用以下公式:
[0042][0043]
其中d
t
表示第t个一阶差分,c
t
表示第t个倒谱系数,n表示倒谱系数的阶数,k表示一阶导数的时间差,通常取1或2。
[0044]
e.将多特征进行有机结合。
[0045]
本方法的特征是在特征提取部分通过将短时能量、线性预测倒谱系数lpcc、梅尔倒谱系数mfcc及其一阶动态特征差分系数进行有机结合来提高说话人识别算法的识别率。首先,取8维线性预测倒谱系数lpcc;然后,取12维梅尔倒谱系数mfcc,并将梅尔倒谱系数mfcc中第一维特征分量替换成短时能量;最后,对12维梅尔倒谱系数mfcc进行一阶差分,得到一组新的梅尔倒谱差分系数,作为特征矢量的一组分量。证明本发明与采用传统特征提取方法的高斯混合模型gmm说话人识别相比能显著提高说话人识别正确率。
技术特征:
1.一种多特征融合的说话人识别方法,其特征在于包括下列步骤:a.计算线性预测倒谱系数lpcc;b.计算梅尔倒谱系数mfcc的特征系数;c.计算短时能量特征系数;d.计算一阶动态差分特征系数;e.将多特征进行有机结合。2.根据权利1所述的一种多特征融合的说话人识别方法,其特征在于包括下列步骤:所述步骤a具体包含以下步骤:a1.计算出线性预测系数;a2.将预测系数带入线性预测倒谱公式,计算出8维线性预测倒谱系数lpcc。3.根据权利1所述的一种多特征融合的说话人识别方法,其特征在于包括下列步骤:所述步骤b具体包含以下步骤:b1.计算12维梅尔倒谱系数mfcc;b2.将第一维梅尔倒谱系数mfcc的特征分量去掉。4.根据权利1所述的一种多特征融合的说话人识别方法,其特征在于包括下列步骤:所述步骤c具体包含以下步骤:c1.对语音信号进行取平方处理;c2.对其进行归一化处理和取对数处理。5.根据权利1所述的一种多特征融合的说话人识别方法,其特征在于包括下列步骤:所述步骤d具体包含以下步骤:d1.将1维短时能量与梅尔倒谱系数mfcc进行有机结合;d2.将有机结合后的12维特征分量进行一阶差分,得到一组新的差分系数。
技术总结
一种多特征融合的说话人识别方法,属于说话人识别技术领域,本方法的特征是在特征提取部分通过将短时能量、线性预测倒谱系数LPCC、梅尔倒谱系数MFCC及其一阶动态特征差分系数进行有机结合来提高说话人识别算法的识别率。首先,取8维线性预测倒谱系数LPCC;然后,取12维梅尔倒谱系数MFCC,并将梅尔倒谱系数MFCC中第一维特征分量替换成短时能量;最后,对12维梅尔倒谱系数MFCC进行一阶差分,得到一组新的梅尔倒谱差分系数,作为特征矢量的一组分量。实验证明本发明与采用传统特征提取方法的GMM说话人识别相比能显著提高说话人识别正确率。说话人识别相比能显著提高说话人识别正确率。说话人识别相比能显著提高说话人识别正确率。
技术研发人员:于玲 孙佳宁
受保护的技术使用者:辽宁工业大学
技术研发日:2021.07.28
技术公布日:2021/12/13