1.本发明涉及语音训练技术领域,尤其涉及一种语音训练方法及系统。
背景技术:
2.语音识别是一门交叉学科,近二十年来,语音识别技术取得显著进步,开始从实验室走向市场。人们预计,未来10年内,语音识别技术将进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。语音识别听写机在一些领域的应用被美国新闻界评为1997年计算机发展十件大事之一,很多专家都认为语音识别技术是2000年至2010年间信息技术领域十大重要的科技发展技术之一,语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
3.现有的语音训练系统识别方式较为传统,难以进行针对性的识别,识别效率较低,有时需要使用人员进行反复多次的重复才能进行正确识别,训练效果较差。
技术实现要素:
4.本发明的目的是为了解决现有技术中存在“难以进行针对性的识别,识别效率较低,有时需要使用人员进行反复多次的重复才能进行正确识别,训练效果较差”的缺点,而提出一种语音训练方法及系统。
5.为了实现上述目的,本发明采用了如下技术方案:
6.一种语音训练系统,包括:语音接收单元,用于接收语音信号,语音采集单元,对接收的语音信号进行采集、语音辨识单元,用于辨别语音信号、语音处理单元,用于对语音信号进行文字性编辑处理、语音输出单元,用于输出处理好的语音信号;
7.所述语音采集单元通过麦克风对待识别语音信息进行特征提取,并将输入的所述待识别语音信息进行语音识别得到识别结果;
8.连接所述语音辨识单元,用于对所述语音信号进行辨识解析,将所述语音信号与预设语句进行匹配,获取与所述预设语句匹配的且与所述语音信号对应的条件语句,及与所述语音信号对应的执行语句;
9.连接所述语音处理单元,语音处理单元首先接收到语音信号后,将所述语音信号上传至网络端或保存于本地进行备份,以避免信号的丢失和方便后期的查阅,然后对语音信号进行文字信息进行解析,将与预设语句匹配好后的语音进行文字信息的描述,获取与所述预设语句匹配的且与所述文字信息对应的条件语句;
10.连接所述语音输出单元,将经过处理后的语音信号进行文字性反馈,然后输出至显示设备进行显示。
11.优选的,所述语音辨识单元包括初始化模块、通用识别模块、识别器、识别监控模块、辨识处理模块,其中识别监控模块对识别过程进行自动实时监控,进行筛选正确语音,避免重复语音的反复识别。
12.优选的,所述语音接收单元接收到所述一名或多名中的一名学习人员的语音信
号,基于其个人账号信息的登录请求;在对该个人账号信息验证成功后,使得准确接收该学习人员的语音接收请求。
13.优选的,所述语音辨识单元从网络端、本地端的语料库获得语料,根据所述语料的预设语句对采集学习人员的的语音信号进行匹配。
14.一种语音训练系统的训练方法,包括以下步骤:
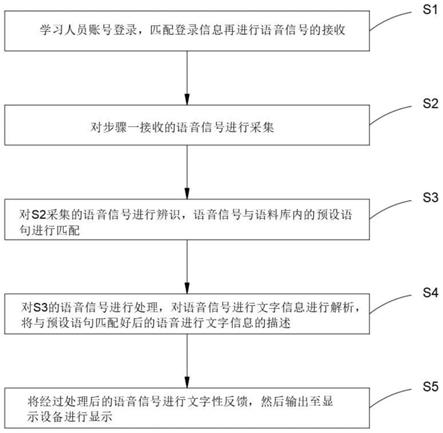
15.s1:学习人员账号登录,匹配登录信息再进行语音信号的接收;
16.s2:对s1接收的语音信号进行采集;
17.s3:对s2采集的语音信号进行辨识,语音信号与语料库内的预设语句进行匹配,获取与所述预设语句匹配的且与所述语音信号对应的条件语句;
18.s4:对s3的语音信号进行处理,对语音信号进行文字信息进行解析,将与预设语句匹配好后的语音进行文字信息的描述,获取与所述预设语句匹配的且与所述文字信息对应的条件语句;
19.优选的,在确定步骤四过程中的当前语音对应的语音识别训练结果后,根据所述语音识别训练结果,对明显的文字性错误进行修正处理。
20.优选的,在确定步骤五过程中的显示设备为计算机,所述计算机可采用分屏或投影的方式进行显示。
21.与现有技术相比,本发明的有益效果是:因为采用的语音训练系统包括;语音接收单元,用于接收语音信号,语音采集单元,对接收的语音信号进行采集、语音辨识单元,用于辨别语音信号、语音处理单元,用于对语音信号进行文字性编辑处理、语音输出单元,用于输出处理好的语音信号,针对不同登录账号进行有针对性的采集语音信号,避免出现采集偏误的问题,并且本发明采用独特的语音识别单元,通过该单元,使获取与所述预设语句匹配的且与所述语音信号对应的条件语句,可以进行筛选正确语音,避免重复语音的反复识别。
附图说明
22.图1为本发明提出的一种语音训练系统的系统框图;
23.图2为语音识别单元的处理过程示意图;
24.图3为本发明提出的一种语音训练系统的训练方法的流程示意图。
具体实施方式
25.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
26.参照图1
‑
2,一种语音训练系统,包括:语音接收单元,用于接收语音信号,语音接收单元接收到一名或多名中的一名学习人员的语音信号,基于其个人账号信息的登录请求;在对该个人账号信息验证成功后,使得准确接收该学习人员的语音接收请求,语音采集单元,对接收的语音信号进行采集、语音辨识单元,用于辨别语音信号、语音处理单元,用于对语音信号进行文字性编辑处理、语音输出单元,用于输出处理好的语音信号;
27.语音采集单元通过麦克风对待识别语音信息进行特征提取,并将输入的待识别语音信息进行语音识别得到识别结果,语音辨识单元包括初始化模块、通用识别模块、识别
器、识别监控模块、辨识处理模块,其中识别监控模块对识别过程进行自动实时监控,进行筛选正确语音,避免重复语音的反复识别;
28.连接语音辨识单元,用于对语音信号进行辨识解析,将语音信号与预设语句进行匹配,获取与预设语句匹配的且与语音信号对应的条件语句,及与语音信号对应的执行语句,语音辨识单元从网络端、本地端的语料库获得语料,根据语料的预设语句对采集学习人员的的语音信号进行匹配;
29.连接语音处理单元,语音处理单元首先接收到语音信号后,将语音信号上传至网络端或保存于本地进行备份,以避免信号的丢失和方便后期的查阅,然后对语音信号进行文字信息进行解析,将与预设语句匹配好后的语音进行文字信息的描,获取与预设语句匹配的且与文字信息对应的条件语句;
30.连接语音输出单元,将经过处理后的语音信号进行文字性反馈,然后输出至显示设备进行显示。
31.参照图3,一种语音训练系统的训练方法,包括以下步骤:
32.s1:学习人员账号登录,匹配登录信息再进行语音信号的接收;
33.s2:对s1接收的语音信号进行采集;
34.s3:对s2采集的语音信号进行辨识,语音信号与语料库内的预设语句进行匹配,获取与预设语句匹配的且与语音信号对应的条件语句;
35.s4:对s3的语音信号进行处理,对语音信号进行文字信息进行解析,将与预设语句匹配好后的语音进行文字信息的描,获取与预设语句匹配的且与文字信息对应的条件语句,在确定步骤四过程中的当前语音对应的语音识别训练结果后,根据语音识别训练结果,对明显的文字性错误进行修正处理
36.s5:将经过处理后的语音信号进行文字性反馈,然后输出至显示设备进行显示,其中显示设备为计算机,计算机可采用分屏或投影的方式进行显示。
37.本发明中,因为采用的语音训练系统包括;语音接收单元,用于接收语音信号,语音采集单元,对接收的语音信号进行采集、语音辨识单元,用于辨别语音信号、语音处理单元,用于对语音信号进行文字性编辑处理、语音输出单元,用于输出处理好的语音信号,针对不同登录账号进行有针对性的采集语音信号,避免出现采集偏误的问题,并且本发明采用独特的语音识别单元,通过该单元,使获取与预设语句匹配的且与语音信号对应的条件语句,可以进行筛选正确语音,避免重复语音的反复识别。
38.以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。