1.本技术涉及语音处理领域,尤其涉及一种语音增强方法及装置。
背景技术:
2.在语音通话或视频通话等场景中,受通话环境的影响(复杂的噪声、混响等),通话过程中的语音质量较差,采用语音增强技术能显著提升语音质量。
3.目前,一种语音增强方法是使用深度学习的方法建立一个语音增强模型(例如对抗网络),基于该语音增强模型能够同步去除待处理语音数据中的噪声和混响。
4.然而,上述语音增强方法的处理得到语音的音质较差,难以满足用户的听觉体验。
5.另外,上述用于同步去除噪声和混响的语音增强模型的结构通常比较复杂,比如网络层数过深,网络的参数量较大,使用该语音增强模型进行语音增强处理的速度较慢,实时率差;并且该语音增强模型可能无法对所有的语音数据进行有效增强,其鲁棒性有待提升。
技术实现要素:
6.本技术实施例提供一种语音增强方法及装置,能够提升语音的音质。
7.为达到上述目的,本技术实施例采用如下技术方案:
8.第一方面,本技术提供一种语音增强方法,应用于电子设备,该方法包括:电子设备基于语音增强模型,对待处理的语音数据进行处理,预测得到该待处理语音数据中的纯净语音数据;该待处理的语音数据为频域语音数据;并且基于干扰信息提取模型,对所述待处理的语音数据进行处理,预测得到所述待处理语音数据中的纯净干扰数据(包括噪声和混响);以及基于语音融合模型,对待处理的语音数据、所述待处理语音数据中的纯净语音数据以及所述待处理语音数据中的纯净干扰数据做融合处理,得到增强的语音数据。
9.本技术提供的语音增强方法,电子设备可以基于语音模型预测出纯净语音数据,基于噪音模型预测出需要排除的纯净干扰数据,并且基于语音融合模型,对待处理的语音数据、经语音模型处理得到的待处理语音数据中的纯净语音数据以及经干扰信息提取模型处理得到的待处理语音数据中的纯净干扰数据做融合处理,对这三种数据进行加权,得到更加纯净的语音数据(即增强的语音数据),可知通过本技术实施例提供的方案,能够更大程度的去除语音数据中的噪声和/或混响,得到质量较高的语音数据。
10.进一步的,与现有的用于语音增强的模型相比,本技术中的语音增强模型、干扰信息提取模型以及语音融合模型的结构简单,模型参数量较少,如此,语音增强处理过程的计算量较小,语音增强处理的速度较快,从而能够提升语音增强的实时率。
11.进一步的,本技术实施例提供的语音增强方法是通过结合时频分析以及基于多路信息融合模型(即语音融合模型)框架,能够满足流式音频去噪的需要,能够适应多种输入维度的音频。
12.进一步的,本技术实施例中的语音增强模型能够显著去除语音数据中的混响和平
稳噪音,噪音模型能够有效地去除语音数据中的非平稳噪音,可见,本技术实施例提供的语音增强方法能够对不同类型的噪音进行有效去除,可适用于对含有不同噪声的语音数据进行增强处理,其鲁棒性好。
13.在第一方面的一种实现方式中,上述语音增强模型包括依次连接的域自适应映射层、编码器层、第一自注意力层以及第一掩码生成层;其中,该域自适应映射层由两个全连接层组成,该编码器层由一个卷积层、两个因果卷积层、以及一个卷积层组成,该第一自注意力层由长短期记忆层和两个全连接层组成,该第一掩码生成层由两个长短期记忆层组成。
14.本技术中,首先,域自适应映射层用于对待处理的语音数据进行特征映射,将待处理的语音数据映射至多维度的特征空间,得到多维语音特征。其次,该编码器层用于对域自适应映射层输出的多维语音特征进行编码,得到编码信息,通过该编码器层得到的该编码信息可以理解成提取得到语音数据更丰富的多维特征。再次,第一自注意力层用于根据编码器层输出的编码信息计算自注意力矩阵。然后,第一掩码生成层用于根据自注意力矩阵生成待处理语音数据的语音掩码矩阵。最后,在语音增强模型的输出层中,将待处理的语音数据与生成的语音掩码矩阵相乘得到该待处理语音数据中的纯净语音数据。
15.在第一方面的一种实现方式中,上述干扰信息提取模型包括依次连接的特征提取层、第二自注意力层以及第二掩码生成层;其中,该特征提取层由两个因果卷积层组成,该第二自注意力层由长短期记忆层和两个全连接层组成,该第二掩码生成层由三个长短期记忆层构成。
16.在本技术中,首先,特征提取层用于对待处理的语音数据进行特征映射,将待处理的语音数据映射至多维度的特征空间,并提取得到多维语音特征。其次,第二自注意力层根据特征提取层输出的多维语音特征计算自注意力矩阵。然后,第二掩码生成层用于根据第二自注意力层输出的自注意力矩阵预测得到该待处理语音数据的干扰掩码矩阵。最后,在干扰信息提取模型的输出层中,将待处理的语音数据与生成的干扰掩码矩阵相乘得到该待处理语音数据中的纯净干扰数据。
17.在第一方面的一种实现方式中,上述语音融合模型包括依次连接的三个卷积层和一个全连接层。
18.在本技术中,基于语音融合模型对待处理的语音数据、语音增强模型输出的待处理语音数据中的纯净语音数据、干扰信息提取模型输出的待处理语音数据中的纯净干扰数据这三种数据进行特征融合,具体的,将三种数据一起输入到通过由三个卷积层构成的特征融合层,得到这三种信号的融合特征(可以理解为对三种数据进行了加权),之后在经过一个全连接层的处理得到该待处理语音数据的语音掩码矩阵,最后,在输出层中将待处理的语音数据与生成的语音掩码矩阵相乘,预测得到增强的语音数据。
19.在第一方面的一种实现方式中,上述方法还包括:电子设备对获取的语音数据进行预处理,得到预处理后的语音数据,该预处理包括无效数据去除处理和振幅分布处理,所述预处理后的语音数据为时域的语音数据;对上述预处理后的音频数据做短时傅里叶变换,得到该待处理的语音数据。
20.在第一方面的一种实现方式中,上述语音增强模型是根据多个语音数据和该多个语音数据中的真实的纯净语音数据训练得到的。
21.在第一方面的一种实现方式中,上述干扰信息提取模型是根据多个语音数据和该多个语音数据中的真实的纯净干扰数据训练得到的。
22.在第一方面的一种实现方式中,上述语音融合模型是根据多个语音数据、上述语音增强模型预测的该多个语音数据中的纯净语音数据、上述干扰信息提取模型预测的该多个语音数据中的纯净干扰数据以及该多个语音数据中的真实的纯净语音数据训练得到的。
23.第二方面,本技术提供一种语音增强装置,包括:语音增强模块、干扰信息提取模块、语音融合模块。其中,语音增强模块用于基于语音增强模型,对待处理的语音数据进行处理,预测得到该待处理语音数据中的纯净语音数据;该待处理的语音数据为频域语音数据;干扰信息提取模块用于基于干扰信息提取模型,对上述待处理的语音数据进行处理,预测得到该待处理语音数据中的纯净干扰数据;语音融合模块用于基于语音融合模型,对待处理的语音数据、上述待处理语音数据中的纯净语音数据以及上述待处理语音数据中的纯净干扰数据做融合处理,得到增强的语音数据。
24.在第二方面的一种实现方式中,上述语音增强模型包括依次连接的域自适应映射层、编码器层、第一自注意力层以及第一掩码生成层;其中,该域自适应映射层由两个全连接层组成,该编码器层由一个卷积层、两个因果卷积层、以及一个卷积层组成,该第一自注意力层由长短期记忆层和两个全连接层组成,所述第一掩码生成层由两个长短期记忆层组成。
25.在第二方面的一种实现方式中,上述干扰信息提取模型包括依次连接的特征提取层、第二自注意力层以及第二掩码生成层;其中,该特征提取层由两个因果卷积层组成,该第二自注意力层由长短期记忆层和两个全连接层组成,该第二掩码生成层由三个长短期记忆层构成。
26.在第二方面的一种实现方式中,上述语音融合模型包括依次连接的三个卷积层和一个全连接层。
27.在第二方面的一种实现方式中,上述语音增强装置还包括:语音数据预处理模块。语音数据预处理模块用于对获取的语音数据进行预处理,得到预处理后的语音数据,该预处理包括无效数据去除处理和振幅分布处理,该预处理后的语音数据为时域的语音数据。
28.在第二方面的一种实现方式中,上述语音增强装置还包括:第一训练模块。
29.第一训练模块用于基于多个语音数据和该多个语音数据中的真实的纯净语音数据对预设语音增强模型进行训练得到语音增强模型。
30.在第二方面的一种实现方式中,上述语音增强装置还包括:第二训练模块。
31.第二训练模块用于基于多个语音数据和该多个语音数据中的真实的纯净干扰数据对预设干扰信息提取模型进行训练得到干扰信息提取模型。
32.在第二方面的一种实现方式中,上述语音增强装置还包括:第三训练模块。
33.第三训练模块用于基于多个语音数据、上述语音增强模型预测的该多个语音数据中的纯净语音数据、上述干扰信息提取模型预测的该多个语音数据中的纯净干扰数据以及该多个语音数据中的真实的纯净干扰数据对预设语音融合模型进行训练得到语音融合模型。
34.第三方面,本技术提供一种电子设备,包括:处理器和与处理器耦合连接的存储器;存储器用于存储计算机指令,当电子设备运行时,处理器执行存储器存储的所述计算机
指令,以使得所述电子设备执行上述第一方面及其各实现方式中所述的方法。
35.第四方面,本技术提供一种计算机可读存储介质,该计算机可读存储介质包括计算机程序,当计算机程序在计算机上运行时,以执行上述第一方面及其各实现方式中所述的方法。
36.需要说明的是,上述第二方面至第四方面的技术效果可以参考第一方面及其各种可选的实现方式的技术效果的相关描述,此处不再赘述。
附图说明
37.图1为本技术实施例提供的语音增强的过程的示意图;
38.图2为本技术实施例提供的语音增强的方法的示意图;
39.图3为本技术实施例提供的语音增强模型的结构示意图;
40.图4为本技术实施例提供的干扰信息提取模型的结构示意图;
41.图5为本技术实施例提供的语音融合模型的结构示意图;
42.图6为本技术实施例提供的对获取的音频数据进行预处理和频域变换的方法的示意图;
43.图7为本技术实施例提供的对预设语音增强模型进行训练得到语音增强模型的过程示意图;
44.图8为本技术实施例提供的对预设干扰信息提取模型进行训练得到干扰信息提取模型的过程示意图;
45.图9为本技术实施例提供的对预设语音融合模型进行训练得到语音融合模型的过程示意图;
46.图10为本技术实施例提供的一种语音增强装置的结构示意图。
具体实施方式
47.本技术的说明书和权利要求书中的术语“第一”和“第二”等是用于区别不同的对象,而不是用于描述对象的特定顺序。例如,第一自注意力层和第二自注意力层等是用于区别不同的自注意力层,而不是用于描述自注意力层的特定顺序。
48.在本技术实施例中,“示例性的”或者“例如”等词用于表示作例子、例证或说明。本技术实施例中被描述为“示例性的”或者“例如”的任何实施例或设计方案不应被解释为比其它实施例或设计方案更优选或更具优势。确切而言,使用“示例性的”或者“例如”等词旨在以具体方式呈现相关概念。
49.在本技术的描述中,除非另有说明,“多个”的含义是指两个或两个以上。例如,多个文本是指两个或两个以上的文本。
50.下面首先对本技术实施例涉及的一些概念进行解释说明。
51.语音增强:是指当语音信号被各种各样的噪声(例如环境中的发动机、汽车、风声、飞机以及其他人声等噪音,或者电火花放电过程产生的噪音)干扰、甚至淹没后,从噪声背景中提取有用的语音信号,抑制、降低噪声干扰的技术。即从带噪语音中提取尽可能纯净的原始语音。
52.短时傅里叶变换(stft,short
‑
time fourier transform):是和傅里叶变换相关
的一种数学变换,用以确定时变信号其局部区域正弦波的频率与相位。一般情况下对语音信号的处理都是在频域上进行的,在本技术实施例中,采用短时傅里叶变换将采集的时域的语音数据变换为频域的语音数据。
53.短时傅里叶逆变换(istft,inverse short
‑
time fourier transform):是和stft相反的一种数学变换。使用本技术实施例提供的语音增强方法,对频域的语音数据进行增强处理之后,再采用短时傅里叶逆变换将语音增强处理之后的频域的语音数据变换成时域的语音数据。
54.针对背景技术中存在的现有的语音增强方法的处理得到语音的音质较差,难以满足用户的听觉体验的问题,本技术实施例提供了一种语音增强方法及装置,电子设备基于语音增强模型,对待处理的语音数据进行处理,预测得到该待处理语音数据中的纯净语音数据;该待处理的语音数据为频域语音数据;并且基于干扰信息提取模型,对该待处理的语音数据进行处理,预测得到该待处理语音数据中的纯净干扰数据;以及基于语音融合模型,对待处理的语音数据、上述待处理语音数据中的纯净语音数据以及上述待处理语音数据中的纯净干扰数据做融合处理,得到增强的语音数据。通过本技术实施例提供的技术方案,能够提升语音音质。
55.本技术实施例提供的语音增强方法可以应用于具有语音处理功能的电子设备,例如手机、耳机、音箱、智能对话机器人、智能家居设备以及可穿戴语音设备等等。
56.如图1所示,本技术实施例提供的语音增强方法的主要过程包括:基于语音增强模型提取原始带噪语音数据(以下实施例称为待处理的语音数据)中的纯净语音数据,基于干扰信息提取模型提取出原始带噪语音中纯净噪音数据,再基于语音融合模型对纯净语音数据、纯净噪音数据以及原始带噪语音数据进行融合处理,得到增强的语音数据。
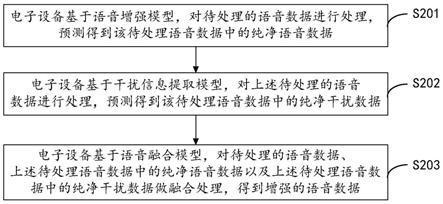
57.具体的,如图2所示,本技术实施例提供的语音增强方法包括s201
‑
s203。
58.s201、电子设备基于语音增强模型,对待处理的语音数据进行处理,预测得到该待处理语音数据中的纯净语音数据。
59.该待处理的语音数据为频域的语音数据。
60.本技术实施例中,如图3所示,语音增强模型包括依次连接的域自适应映射层、编码器层、第一自注意力层以及第一掩码生成层。
61.其中,该域自适应映射层由两个全连接层组成,每一个全连接层包括256个神经元;该编码器层由一个卷积层、两个因果卷积层、以及一个卷积层组成。该编码器层的两个卷积层均为普通的卷积层,卷积层的卷积核数量为12,卷积核的尺寸为3
×
1,步长为1,两个因果卷积层为带残差模块的因果卷积层,因果卷积层的卷积核数量为24,卷积核的尺寸为2
×
1,步长为1。该第一自注意力层由长短期记忆层和两个全连接层组成,长短期记忆层包括448个神经元,每一个全连接层包括448个神经元。该第一掩码生成层由两个长短期记忆层组成,两个长短期记忆层的神经元个数分别为448和256。
62.具体的,在本技术实施例中,首先,域自适应映射层用于对待处理的语音数据进行特征映射,将待处理的语音数据映射至多维度的特征空间,得到多维语音特征,具体的,将待处理的语音数据与两个全连接层所附带的权重参数矩阵进行相乘,以对待处理的语音数据进行非线性映射,将该待处理的语音数据映射到多维度的特征空间。
63.其次,该编码器层用于对域自适应映射层输出的多维语音特征进行编码,得到编
码信息,通过该编码器层得到的该编码信息可以理解成提取得到语音数据更丰富的多维特征。
64.再次,第一自注意力层用于根据编码器层输出的编码信息计算自注意力矩阵。
65.然后,第一掩码生成层用于根据自注意力矩阵生成待处理语音数据的语音掩码矩阵;
66.最后,在语音增强模型的输出层中,将待处理的语音数据与生成的语音掩码矩阵相乘得到该待处理语音数据中的纯净语音数据。
67.s202、基于干扰信息提取模型,对上述待处理的语音数据进行处理,预测得到该待处理语音数据中的纯净干扰数据。
68.本技术实施例中,如图4所示,干扰信息提取模型包括依次连接的特征提取层、第二自注意力层以及第二掩码生成层。
69.其中,该特征提取层由两个因果卷积层组成,因果卷积层的卷积核数量为12,卷积核的尺寸为3
×
1,步长为1。该第二自注意力层由长短期记忆层和两个全连接层组成,长短期记忆层包括448个神经元,每一个全连接层包括448个神经元。该第二掩码生成层由三个长短期记忆层构成,三个长短期记忆层分别包括448、448和256个神经元。
70.具体的,在本技术实施例中,首先,特征提取层用于对待处理的语音数据进行特征映射,将待处理的语音数据映射至多维度的特征空间,并提取得到多维语音特征。
71.其次,第二自注意力层根据特征提取层输出的多维语音特征计算自注意力矩阵。
72.然后,第二掩码生成层用于根据第二自注意力层输出的自注意力矩阵预测得到该待处理语音数据的干扰掩码矩阵。
73.最后,在干扰信息提取模型的输出层中,将待处理的语音数据与生成的干扰掩码矩阵相乘得到该待处理语音数据中的纯净干扰数据。
74.s203、基于语音融合模型,对待处理的语音数据、上述待处理语音数据中的纯净语音数据以及上述待处理语音数据中的纯净干扰数据做融合处理,得到增强的语音数据。
75.本技术实施例中,如图5所示,语音融合模型包括依次连接的三个卷积层和一个全连接层,每一个卷积层的卷积核数量均为3,像素点数为3
×
7,步长均为3,该一个全连接层包括448个神经元。其中,三个卷积层组成的网络层可以称为特征融合层。
76.具体的,在本技术实施例中,语音融合模型的作用主要是:对待处理的语音数据、语音增强模型输出的待处理语音数据中的纯净语音数据、干扰信息提取模型输出的待处理语音数据中的纯净干扰数据这三种数据进行特征融合,具体的,将三种数据一起输入到通过由三个卷积层构成的特征融合层,得到这三种信号的融合特征(可以理解为对三种数据进行了加权),之后在经过一个全连接层的处理得到该待处理语音数据的语音掩码矩阵,最后,在输出层中将待处理的语音数据与生成的语音掩码矩阵相乘,预测得到增强的语音数据。
77.综上,本技术实施例提供的语音增强方法,电子设备可以基于语音模型预测出纯净语音数据,基于噪音模型预测出需要排除的纯净干扰数据,并且基于语音融合模型,对待处理的语音数据、经语音模型处理得到的待处理语音数据中的纯净语音数据以及经干扰信息提取模型处理得到的待处理语音数据中的纯净干扰数据做融合处理,对这三种数据进行加权,得到更加纯净的语音数据(即增强的语音数据),可知通过本技术实施例提供的方案,
能够更大程度的去除语音数据中的噪声和/或混响,得到质量较高的语音数据。
78.进一步的,与现有的用于语音增强的模型相比,本技术实施例中的语音增强模型、干扰信息提取模型以及语音融合模型的结构简单,模型参数量较少,如此,语音增强处理过程的计算量较小,语音增强处理的速度较快,从而能够提升语音增强的实时率。
79.进一步的,本技术实施例提供的语音增强方法是通过结合时频分析以及基于多路信息融合模型(即语音融合模型)框架,能够满足流式音频去噪的需要,能够适应多种输入维度的音频。
80.进一步的,本技术实施例中的语音增强模型能够显著去除语音数据中的混响和平稳噪音,噪音模型能够有效地去除语音数据中的非平稳噪音,可见,本技术实施例提供的语音增强方法能够对不同类型的噪音进行有效去除,可适用于对含有不同噪声的语音数据进行增强处理,其鲁棒性好。
81.可选的,结合图2,如图6所示,在上述s201之前,本技术实施例提供的语音增强方法还包括s204。
82.s204、电子设备对获取的语音数据进行预处理,得到预处理后的语音数据,该预处理包括无效数据去除处理和振幅分布处理,该预处理后的语音数据为时域的语音数据。
83.对上述预处理后的语音数据做短时傅里叶变换,将待处理的语音数据转换到频域,得到语音数据的频谱图,即得到步骤s201中的待处理的语音数据。
84.可选的,上述待处理的语音数据可以通过电子设备的麦克风采集得到或者通过算法合成,若通过算法合成待处理的语音数据,电子设备采用预设算法在纯净语音中添加加性噪声和混响,得到合成的语音数据。
85.本技术实施例中,电子设备获取到语音数据之后,电子设备可以对语音数据进行下述两种预处理中的至少一种处理。
86.第一种预处理:无效数据去除处理
87.电子设备获取的语音数据之后,电子设备检测该语音数据中是否存在无效数据,该无效数据可以理解为语音数据中的静音片段对应的数据,若该语音数据中存在无效数据,则去除该语音数据中的无效数据。
88.第二种预处理:振幅分布处理
89.为了使得本技术实施例提供的语音增强方法在实际环境中具有更强的鲁棒性,电子设备可以对获取到的语音数据进行振幅分布处理,也可以称为样本域自适应处理。具体的,对获取到的语音数据的振幅进行正则化处理,以使得该语音数据的振幅与训练集(指的是用于训练本技术实施例中的语音增强模型、干扰信息提取模型、语音融合模型的训练集)中的语音数据的振幅处于相同尺度的分布中。本技术实施例中,电子设备可以根据训练集中的语音数据的振幅的最大值和最小值对获取到语音数据的振幅进行正则化处理。
90.可选的,结合图2,如图7所示,在上述s201(电子设备基于语音增强模型,对待处理的语音数据进行处理,预测得到该待处理语音数据中的纯净语音数据)之前,本技术实施例提供的语音增强方法还包括s205。
91.s205、电子设备根据多个语音数据和该多个语音数据中的真实的纯净语音数据对预设语音增强模型进行训练得到语音增强模型。
92.可以理解的是,多个语音数据和该多个语音数据中的真实的纯净语音数据构成语
音增强模型的训练样本集。
93.具体的,将训练样本集中的语音数据输入至预设语音增强模型中,预测得到该语音数据中的纯净语音数据,并将该预测的语音数据中的纯净语音数据和该语音数据中的真实的纯净语音数据进行对比,计算语音增强模型对应的损失值,再根据该损失值更新该预设语音增强模型的参数。电子设备循环执行上述操作,直至执行次数达到预设的训练次数,或者语音增强模型预测得到的语音数据中的纯净语音数据满足预设条件的情况下,结束模型训练,得到语音增强模型。
94.可选的,可以采用下述损失函数计算语音增强模型对应的损失值:
[0095][0096]
其中,x为真实的纯净语音数据,为语音增强模型预测出的纯净语音数据,s_num为训练样本集的样本总数,t_len为语音数据的帧长度,f_len为语音数据的频域采样点个数,为语音增强模型预测后的纯净语音数据的频谱图的像素值,x
s,i,j
为真实的纯净语音数据的频谱的图像素值。
[0097]
可选的,结合图2,如图8所示,在上述s202(基于干扰信息提取模型,对该待处理的语音数据进行处理,预测得到该待处理语音数据中的纯净干扰数据)之前,本技术实施例提供的语音增强方法还包括s206。
[0098]
s206、电子设备根据多个语音数据和该多个语音数据中的真实的纯净干扰数据训对预设干扰信息提取模型进行练得到干扰信息提取模型。
[0099]
可以理解的是,多个语音数据和该多个语音数据中的真实的纯净干扰数据构成干扰信息提取模型的训练样本集。
[0100]
具体的,将训练样本集中的语音数据输入至预设干扰信息提取模型中,预测得到该语音数据中的纯净干扰数据,并将该预测的语音数据中的纯净干扰数据和该语音数据中的真实的纯净干扰数据进行对比,计算干扰信息提取模型对应的损失值,再根据该损失值更新该预设干扰信息提取模型的参数。电子设备循环执行上述操作,直至执行次数达到预设的训练次数,或者干扰信息提取模型预测得到的该多个语音数据中的纯净干扰数据满足预设条件的情况下,结束模型训练,得到干扰信息提取模型。
[0101]
可选的,可以采用下述损失函数计算干扰信息提取模型对应的损失值:
[0102][0103]
其中,n为真是的纯净干扰数据,为干扰信息提取模型预测出的纯净干扰数据,s_num为训练样本集的样本总数,t_len为干扰数据的帧长度,f_len为干扰数据的频域采样点个数,为干扰信息提取预测后的纯净干扰数据的频谱图像素点值,n
s,i,j
为真实的纯净干扰数据的频谱图像素点值。
[0104]
可选的,结合图2,如图9所示,在上述s203(基于语音融合模型,对待处理的语音数据、该待处理语音数据中的纯净语音数据以及该待处理语音数据中的纯净干扰数据做融合
处理,得到增强的语音数据)之前,本技术实施例提供的语音增强方法还包括s207。
[0105]
s207、电子设备根据多个语音数据、上述语音增强模型预测的该多个语音数据中的纯净语音数据、上述干扰信息提取模型预测的该多个语音数据中的纯净干扰数据以及该多个语音数据中的真实的纯净干扰数据对预设语音融合模型进行训练得到语音融合模型。
[0106]
可以理解的是,多个语音数据、上述语音增强模型预测得到的该多个语音数据中的纯净语音数据、上述干扰信息提取模型预测得到的该多个语音数据中的纯净干扰数据、该多个语音数据中的真实的纯净语音数据构成语音融合模型的训练样本集。
[0107]
具体的,将上述训练样本集中的语音数据、上述语音增强模型预测得到的该语音数据中的纯净语音数据、上述干扰信息提取模型预测得到的该语音数据中的纯净干扰数据输入至预设语音融合模型中,预测得到增强的语音数据,并将该增强的语音数据和该语音数据中的真实的纯净语音数据进行对比,计算干语音融合模型对应的损失值,再根据该损失值更新该预设语音融合模型的参数。电子设备循环执行上述操作,直至执行次数达到预设的训练次数,或者语音融合模型预测得到的该增强的语音数据满足预设条件的情况下,结束模型训练,得到语音融合模型。
[0108]
可选地,可以采用下述公式计算语音融合模型对应的总损失值,该总损失值用于更新该语音融合模型:
[0109]
j=a
×
j(m)+b
×
j(n)+c
×
j(x)
[0110]
该损失函数j是多任务损失函数,其中,j(x)为上述s205中计算语音增强模型对应的损失值的损失函数,j(n)为上述s206中计算干扰信息提取模型对应的损失值的损失函数,j(m)为下述计算语音融合模型对应的损失值的损失函数。
[0111][0112]
其中,m为真实的纯净语音数据,为语音融合模型预测的增强的语音数据,s_num为训练样本集的样本总数,t_len为语音数据的帧长度,f_len为为语音数据的频域采样点个数,为语音融合模型预测后的增强的语音数据的频谱图的像素值,m
s,i,j
为真实的纯净语音数据的频谱的图像素值,其中的a、b、c为根据训练需要进行调整的权重。
[0113]
相应的,本技术实施例提供一种语音增强装置,如图10所示,该语音增强装置包括语音增强模块1001、干扰信息提取模块1002、语音融合模块1003。其中,语音增强模块1001用于基于语音增强模型,对待处理的语音数据进行处理,预测得到该待处理语音数据中的纯净语音数据;该待处理的语音数据为频域语音数据,例如执行上述方法实施例中的s201。干扰信息提取模块1002用于基于干扰信息提取模型,对上述待处理的语音数据进行处理,预测得到该待处理语音数据中的纯净干扰数据,例如执行上述方法实施例中的s202。语音融合模块1003用于基于语音融合模型,对待处理的语音数据、上述待处理语音数据中的纯净语音数据以及上述待处理语音数据中的纯净干扰数据做融合处理,得到增强的语音数据,例如执行上述方法实施例中的s203。
[0114]
可选的,本技术实施例提供的语音增强装置还包括语音数据预处理模块1004、频域转换模块1005。
[0115]
该语音数据预处理模块1004用于对获取的语音数据进行预处理,得到预处理后的
语音数据,该预处理包括无效数据去除处理和振幅分布处理,该预处理后的语音数据为时域的语音数据,例如执行上述方法实施例中的s204。
[0116]
该频域转换模块1005用于对上述预处理后的语音数据做短时傅里叶变换,得到频域的语音数据,即待处理的语音数据。
[0117]
可选的,本技术实施例提供的语音增强装置还包括第一训练模块1006。该第一训练模块1006用于基于多个语音数据和该多个语音数据中的真实的纯净语音数据对预设语音增强模型进行训练得到语音增强模型。例如执行上述方法实施例中的s205。
[0118]
可选的,本技术实施例提供的语音增强装置还包括第二训练模块1007。该第二训练模块1007用于基于多个语音数据和该多个语音数据中的真实的纯净干扰数据对预设干扰信息提取模型进行训练得到干扰信息提取模型。例如执行上述方法实施例中的s206。
[0119]
可选的,本技术实施例提供的语音增强装置还包括第三训练模块1008。该第三训练模块1008用于基于多个语音数据、上述语音增强模型预测的该多个语音数据中的纯净语音数据、上述干扰信息提取模型预测的该多个语音数据中的纯净干扰数据以及该多个语音数据中的真实的纯净语音数据对预设语音融合模型进行训练得到语音融合模型。例如执行上述方法实施例中的s207。
[0120]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的精神和范围。