1.本发明涉及语音处理和语音语料库构建技术领域,特别是方言语音数据切分及标注领域。
背景技术:
2.所谓语音数据切分和标注,是指将语音切分到音素(汉语中的音素近似于汉语拼音中的声母和韵母),即标注语音中每一个音素的开始时间和结束时间。如对于汉语词“中国”,其对应的音素分别为“zh”、“ong”、“g”、“uo”。对于内容为“中国”的语音数据,精确的标注上述每一个音素的开始时间和结束时间,即实现了语音数据切分和标注。例如,进行语音数据切分和标注后,可得到含有如下内容的标注文件,其中,前两列分别为开始时间和结束时间,单位为秒,第3列为对应的音素。
[0003][0004]
语音数据精准切分和标注,是训练高质量语音识别模型,从而建立高质量语音识别系统的基础。随着语音识别技术的发展和应用领域的扩大,方言语音识别系统的需求日趋增加。为建立高质量的方言语音识别系统,就需要精准对齐和标注的方言语音基础数据库。如果采用手工方式来制作语音基础数据库,由于语音基础数据库一般数据量非常大,需要花费大量的人力物力,很难满足大数据量的语音基础数据库的建设的需求。在标准普通话语音基础数据库建库方面,已有一些可用的方法和工具软件。当前已有的方法主要是训练一个针对普通话的语音识别声学模型,然后采用所述声学模型进行(由语音对应的汉字文本转换得到的)音素序列与语音之间的强制对齐(forced alignment),从而得到各音素的开始时间和结束时间。但这种方法难以应用于方言语音数据的切分和标注,原因在于对需要进行语音数据切分和标注的特定方言,往往缺乏关于该方言种类的高准确率的语音识别系统和语音识别模型,而如果采用准确率不高的模型,包括针对普通话的模型,将导致对齐出现偏差,从而使语音切分和标注结果都包含大量错误,难以使用。其中,当使用针对普通话的模型时,最大的困难在于:很多词在方言中与普通话中发音明显不同,如果按照普通话的发音去对齐,会导致对齐失败。这就需要在对齐之前能够获取其方言发音的音素序列,然后按照方言发音去进行对齐。而对于某一种具体方言,一般需要精通这种语言的专家来进行这种音素序列的标注,极为费时费力,基本上很难实用。
技术实现要素:
[0005]
本发明要解决的技术问题为:针对当前方言语音数据切分及标注中存在的没有可用的方言声学模型,针对普通话的声学模型和方言发音之间的不匹配会导致大量切分和标
注错误的问题,提出了一种方言语音数据切分及标注方法,该方法通过自动提取,结合少量人工校对和标注,构建一个方言词汇库,基于该方言词汇库,可以得到语音对应的方言音素序列,从而在使用针对普通话的语音识别声学模型进行语音和音素的对齐时,避免因为音素不同导致对齐偏差和错误,提高语音数据切分和标注的准确率。
[0006]
具体来说,本发明针对方言语音识别基础数据库建设的需求及当前存在的问题,提出了一种方言语音数据切分及标注方法,其中包括:
[0007]
步骤1、使用普通话语音识别模型对第一方言语音进行语音数据切分及标注,得到该第一方言语音的汉字识别结果,并基于该第一方言语音及其对应汉字文本和该汉字识别结果,构建方言词汇库;
[0008]
步骤2、获取待切分和标注的语音数据作为第二方言语音,基于该方言词汇库和该第二方言语音对应的汉字文本,得到该第二方言语音对应的音素序列,并采用音素对齐算法和该普通话语音识别模型,得到第二方言语音的语音切分标注结果;
[0009]
步骤3、基于经人工校对的语音切分标注结果及其对应的语音数据训练得到方言语音声学模型,将待语音数据切分及标注的方言语音数据输入至该方言语音声学模型,得到该待语音数据切分及标注的方言语音数据的切分和标注结果。
[0010]
所述的方言语音数据切分及标注方法,其中该步骤1包括:
[0011]
步骤11、利用该普通话语音识别模型,识别该第一方言语音,得到其对应的识别结果,利用汉语词和汉字到音素序列的对应表,得到该第一方言语音对应的汉字文本和该识别结果的音素序列;
[0012]
步骤12、基于编辑距离,将第一方言语音的汉字文本的音素序列与其对应的识别结果的音素序列进行自动对齐,对齐后对于第一方言语音汉字文本的音素序列中的每一个音素,均对应该识别结果的音素序列中的一个音素或不对应任何音素;
[0013]
步骤13、将第一方言语音的汉字文本进行分词,得到每一个词对应的汉字文本的音素序列,根据步骤12中汉字文本的音素序列与识别结果的音素序列间的对应关系,得到每一个词对应的识别结果的音素序列;其中若某个词对应的汉字文本的音素序列与该词对应的识别结果的音素序列不一致,则将这个词,连同其所对应的汉字文本的音素序列,以及其对应的识别结果的音素序列,加入候选词列表;
[0014]
步骤14、通过去重合并处理,该候选词列表中每个词仅保留一个词条,词条中包括其所对应的汉字文本中的音素序列,以及其对应的所有的识别结果中的音素序列,并采用人工对该候选词列表进行校对和标注,得到该方言词汇库。
[0015]
所述的方言语音数据切分及标注方法,其中该步骤2包括:
[0016]
步骤21、对于第二方言语音,先将其对应的汉字文本分词,判断分词结果是否存在于该方言词汇库中,若是,则获取分词结果在方言词汇库中对应的音素序列,否则利用汉语词和汉字到音素序列的对应表,得到其对应的音素序列,将第二方言语音所有词对应的音素序列连接起来,作为该第二方言语音对应的音素序列;
[0017]
步骤22、基于语音识别声学模型,将第二方言语音与其对应的音素序列进行对齐,对齐后得到音素序列中每一个音素对应的开始时间和结束时间,从而实现语音切分和标注。
[0018]
所述的方言语音数据切分及标注方法,其中该步骤3包括:
[0019]
将经人工校对的语音切分标注结果及其对应的语音数据与普通话语音数据混合在一起,共同训练基于dnn+hmm模型的声学模型,作为该方言语音声学模型;或
[0020]
使用经人工校对语音切分标注结果及其对应的语音数据对已有的面向普通话的基于gmm+hmm模型的声学模型,进行基于极大似然线性变换的声学模型自适应操作,以得到该方言语音声学模型;或
[0021]
使用经人工校对语音切分标注结果及其对应的语音数据对已有的基于变换器的深度神经网络声学模型进行微调,以得到该方言语音声学模型。
[0022]
所述的方言语音数据切分及标注方法,其中还包括步骤4:基于该方言语音声学模型输出的切分和标注结果,训练方言语音识别模型和/或方言语音合成模型,通过方言语音识别模型将方言音频转化为汉字信息,和/或通过方言语音合成模型将汉字信息转化为方言音频。
[0023]
本发明还提出了一种方言语音数据切分及标注系统,其中包括:
[0024]
模块1,用于使普通话语音识别模型对第一方言语音进行语音数据切分及标注,得到该第一方言语音的汉字识别结果,并基于该第一方言语音及其对应汉字文本和该汉字识别结果,构建方言词汇库;
[0025]
模块2,用于获取待切分和标注的语音数据作为第二方言语音,基于该方言词汇库和该第二方言语音对应的汉字文本,得到该第二方言语音对应的音素序列,并采用音素对齐算法和该普通话语音识别模型,得到第二方言语音的语音切分标注结果;
[0026]
模块3,用于基于经人工校对的语音切分标注结果及其对应的语音数据训练得到方言语音声学模型,将待语音数据切分及标注的方言语音数据输入至该方言语音声学模型,得到该待语音数据切分及标注的方言语音数据的切分和标注结果。
[0027]
所述的方言语音数据切分及标注系统,其中该模块1包括:
[0028]
模块11,用于使该普通话语音识别模型,识别该第一方言语音,得到其对应的识别结果,利用汉语词和汉字到音素序列的对应表,得到该第一方言语音对应的汉字文本和该识别结果的音素序列;
[0029]
模块12,用于基于编辑距离,将第一方言语音的汉字文本的音素序列与其对应的识别结果的音素序列进行自动对齐,对齐后对于第一方言语音汉字文本的音素序列中的每一个音素,均对应该识别结果的音素序列中的一个音素或不对应任何音素;
[0030]
模块13,用于将第一方言语音的汉字文本进行分词,得到每一个词对应的汉字文本的音素序列,根据模块12中汉字文本的音素序列与识别结果的音素序列间的对应关系,得到每一个词对应的识别结果的音素序列;其中若某个词对应的汉字文本的音素序列与该词对应的识别结果的音素序列不一致,则将这个词,连同其所对应的汉字文本的音素序列,以及其对应的识别结果的音素序列,加入候选词列表;
[0031]
模块14,用于通过去重合并处理,该候选词列表中每个词仅保留一个词条,词条中包括其所对应的汉字文本中的音素序列,以及其对应的所有的识别结果中的音素序列,并采用人工对该候选词列表进行校对和标注,得到该方言词汇库。
[0032]
所述的方言语音数据切分及标注系统,其中该模块2包括:
[0033]
模块21,用于对于第二方言语音,先将其对应的汉字文本分词,判断分词结果是否存在于该方言词汇库中,若是,则获取分词结果在方言词汇库中对应的音素序列,否则利用
汉语词和汉字到音素序列的对应表,得到其对应的音素序列,将第二方言语音所有词对应的音素序列连接起来,作为该第二方言语音对应的音素序列;
[0034]
模块22,用于基于语音识别声学模型,将第二方言语音与其对应的音素序列进行对齐,对齐后得到音素序列中每一个音素对应的开始时间和结束时间,从而实现语音切分和标注。
[0035]
所述的方言语音数据切分及标注系统,其中该模块3包括:
[0036]
将经人工校对的语音切分标注结果及其对应的语音数据与普通话语音数据混合在一起,共同训练基于dnn+hmm模型的声学模型,作为该方言语音声学模型;或
[0037]
使用经人工校对语音切分标注结果及其对应的语音数据对已有的面向普通话的基于gmm+hmm模型的声学模型,进行基于极大似然线性变换的声学模型自适应操作,以得到该方言语音声学模型;或
[0038]
使用经人工校对语音切分标注结果及其对应的语音数据对已有的基于变换器的深度神经网络声学模型进行微调,以得到该方言语音声学模型。
[0039]
所述的方言语音数据切分及标注系统,其中还包括模块4,用于基于该方言语音声学模型输出的切分和标注结果,训练方言语音识别模型和/或方言语音合成模型,通过方言语音识别模型将方言音频转化为汉字信息,和/或通过方言语音合成模型将汉字信息转化为方言音频。
[0040]
通过采用本发明提出的方言语音数据切分及标注方法,可以克服当前方言语音数据切分及标注领域存在的针对普通话的声学模型与方言发音之间的不匹配会导致大量切分和标注错误的问题。本发明提出的方法通过自动提取,结合少量人工校对和标注,构建一个方言词汇库,基于该方言词汇库,可以得到语音对应的方言音素序列,从而在使用针对普通话的语音识别声学模型时,避免因为音素不同导致对齐偏差和错误,提高语音数据切分和标注的准确率。
附图说明
[0041]
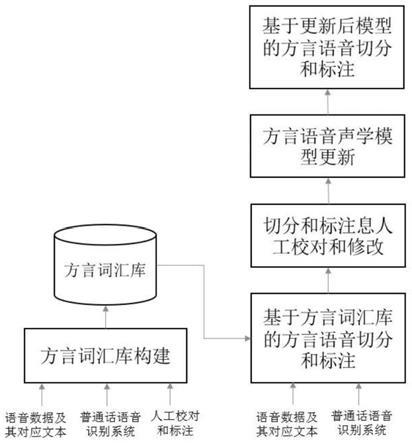
图1为本发明方言语音数据切分及标注流程图。
具体实施方式
[0042]
本发明提出的方言语音数据切分及标注方法,包括:
[0043]
1.利用已采集的方言语音数据及其对应的汉字文本,以及普通话语音识别系统对方言语音数据的识别结果,结合人工校对和标注,构建一个方言词汇库。
[0044]
步骤1.1利用已有的普通话语音识别系统,识别每一条方言语音数据,得到其对应的识别结果。注意,由于采用汉语普通话语音识别系统识别方言,识别结果不可避免地会存在错误,特别是对于某些方言发音与普通话发音不同的汉字。
[0045]
步骤1.2利用一个汉语词和汉字到音素序列的对应表,分别得到每一条方言语音数据对应的汉字文本和识别结果的音素序列。
[0046]
步骤1.3对于每一条方言语音数据,使用编辑距离方法将其对应的汉字文本的音素序列与其对应的识别结果的音素序列进行自动对齐。对齐后,对于语音数据对应的汉字文本的音素序列中的每一个音素,都会对应该语音数据对应的识别结果的音素序列中的一
个音素或不对应任何音素。
[0047]
步骤1.4对于每一条语音数据,将数据对应的汉字文本分词,获取每一个词对应的汉字文本的音素序列,根据步骤1.3中得到的语音数据对应的汉字文本的音素序列与识别结果的音素序列之间的对应关系,得到每一个词对应的识别结果的音素序列。如果某个词对应的汉字文本的音素序列与该词对应的识别结果的音素序列不一致,则将这个词,连同其所对应的汉字文本的音素序列,以及其对应的识别结果的音素序列,加入一个候选词列表中。
[0048]
步骤1.5可选地,对于候选词列表中的词进行自动筛选。自动筛选可基于该词在候选词列表中的出现的频次,以及该词在识别结果中的音素序列方面的一致性。例如,仅当一个词在候选词列表中出现的次数大于一个预先设定的值时,才保留该词,否则将该词从候选词列表中删除;又例如,仅当一个词在候选词列表中出现的次数大于一个预先设定的值,并且在这多次出现中,其所对应的识别结果中的音素序列都一致时,才保留该词,否则将该词从候选词列表中删除。
[0049]
步骤1.6将候选词列表进行去重复合并处理,即对于一个词仅保留一个词条,但在一个词条中列出其所对应的汉字文本中的音素序列,以及其对应的所有的识别结果中的音素序列。
[0050]
步骤1.7采用一个人工校对模块,由人工对候选词列表进行校对和标注,得到方言词汇库。所述人工校对模块向熟悉该种方言的校对人员呈现所有词条及其相关信息,包括每一个汉语词、该汉语词对应的汉字文本中的音素序列、该汉语词对应的所有的识别结果中的音素序列,然后提供交互界面,由校对人员进行校对和标注,主要包括:决定是否保留该词条,参考该汉语词对应的汉字文本中的音素序列标注该汉语词对应的普通话音素序列,以及参考该汉语词对应的所有的识别结果中的音素序列标注该汉语词对应的方言音素序列。最终得到的被保留的所有词条,包括汉语词、该汉语词对应的普通话音素序列、该汉语词对应的方言音素序列等信息,即构成所述方言词汇库。
[0051]
步骤1.8可选地,采用一个人工编辑模块,由人工对方言词汇库进行编辑,增补一些未出现在候选词列表中的词条。所述人工编辑模块提供相应的界面,供用户输入词条信息,包括汉语词、该汉语词对应的普通话音素序列、该汉语词对应的方言音素序列等信息。
[0052]
2.基于构建的方言词汇库和待切分和标注的语音数据对应的汉字文本,得到待切分和标注的语音数据对应的方言音素序列,然后采用面向普通话的语音识别声学模型和音素对齐算法,得到语音切分和标注结果。
[0053]
步骤2.1基于构建的方言词汇库和待切分和标注的语音数据对应的汉字文本,得到待切分和标注的语音数据对应的方言音素序列。
[0054]
步骤2.2基于得到的语音数据对应的方言音素序列,采用面向普通话的语音识别声学模型和音素对齐算法,得到语音切分和标注结果。
[0055]
3.提供相应的模块和交互界面,供用户对步骤2得到的语音切分和标注结果进行校对和修改。
[0056]
4.采用经人工校对和修改过的切分和标注信息及其对应的语音数据进行语音识别声学模型的训练,得到更新后的方言语音声学模型,采用所述更新后的方言语音声学模型进行新的方言语音数据的切分和标注。
[0057]
步骤4.1采用经人工校对和修改过的切分和标注信息及其对应的语音数据进行语音识别声学模型的训练,得到更新后的方言语音声学模型。
[0058]
具体训练的方式可以有多种,例如,可以直接采用经人工校对和修改过的切分和标注信息及其对应的语音数据进行声学模型训练,也可以将经人工校对和修改过的切分和标注信息及其对应的语音数据与已有的普通话数据进行混合后进行声学模型训练,也可以在已有的面向普通话语音的声学模型的基础上,采用经人工校对和修改过的切分和标注信息及其对应的语音数据进行增量式训练,如模型自适应(self
‑
adaptation)和微调(fine
‑
tuning)。
[0059]
步骤4.2采用所述更新后的方言语音声学模型进行新的方言语音数据的切分和标注。
[0060]
对于需要进行切分和标注的新语音数据,首先基于方言词汇库和待切分和标注的语音数据对应的汉字文本,得到待切分和标注的语音数据对应的方言音素序列,然后采用更新后的方言语音声学模型和对齐算法,将语音信号与其对应的方言音素序列进行强制对齐,对齐后可得到音素序列中每一个音素对应的开始时间和结束时间,从而实现语音切分和标注。
[0061]
为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。
[0062]
本发明提出了一种方言语音数据切分及标注方法,实现对方言语音的精确切分和标注,其具体任务是对于每一条方言语音数据,标注其中的所有汉语音素及音素的开始时间和结束时间,以形成精标注的方言语料库。精标注的方言语料库对于训练方言语音识别模型和语音合成模型,构建方言语音识别系统和语音合成系统具有重要意义。所述方言语音数据带有对应的汉字文本。所述汉字文本获取有两种方式:一是语音数据本身就是由发音人对照预先选定的汉字文本朗读得到的,此时汉字文本是先于语音存在的;二是由人工对语音数据进行转写,得到其对应的汉字文本。这些汉字文本可以认为是正确的,不含错误的汉字文本。
[0063]
本发明所提出的方言语音数据切分及标注方法流程如图1所示。具体步骤分述如下:
[0064]
1.利用已采集的方言语音数据及其对应的汉字文本,以及普通话语音识别系统对方言语音数据的识别结果,结合人工校对和标注,构建一个方言词汇库。
[0065]
步骤1.1利用已有的普通话语音识别系统(模型),识别每一条方言语音数据,得到其对应的识别结果。注意,由于采用汉语普通话语音识别系统识别方言,识别结果不可避免地会存在错误,特别是对于某些方言发音与普通话发音不同的汉字。
[0066]
步骤1.2利用一个汉语词和汉字到音素序列的对应表,分别得到每一条方言语音数据对应的汉字文本和识别结果的音素序列。其中用汉语词的好处是能比较好地处理多音字。例如,“多人参加”,分词之后是“多人参加”,直接处理“参加”,可以得到音素序列“c anj ia”,这样能够避免单独选择时不知道该选“c an”还是“sh en”的问题。
[0067]
对每一条方言语音数据对应的汉字文本和识别结果,首先采用分词工具对其进行分词操作,然后对于得到的每一个词,利用一个汉语词到音素序列的对应表,得到该词对应的音素序列,如果该词不存在于所述汉语词到音素序列的对应表中,则将该词进一步分解
为其所对应的汉字的序列,对于其中的每个汉字,利用一个汉字到音素序列的对应表得到该汉字对应的音素序列,将该词的所有汉字对应的音素序列连接作为该词对应的音素序列。将所有词对应的音素序列连接起来,可得到每一条方言语音数据对应的汉字文本和识别结果的音素序列。
[0068]
步骤1.3对于每一条方言语音数据,使用编辑距离方法将其对应的汉字文本的音素序列与其对应的识别结果的音素序列进行自动对齐。对齐后,对于语音数据对应的汉字文本的音素序列中的每一个音素,都会对应该语音数据对应的识别结果的音素序列中的一个音素或不对应任何音素。
[0069]
编辑距离(edit distance)又称莱文斯坦距离(levenshtein distance),指两个符号串之间,由一个转成另一个所需的最少编辑操作的次数。允许的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。可以采用动态规划算法计算两个符号串之间的编辑距离。根据两个符号串之间的编辑距离,可以得到两个符号串中的符号之间的对应关系。例如,对于符号串“abdef”与“bcdeg”,可以建立如下的对应关系:
[0070]
a
→
[0071]
b
→
b
[0072]
ꢀ→
c
[0073]
d
→
d
[0074]
e
→
e
[0075]
f
→
g
[0076]
这说明,由“abdef”转成“bcdeg”需要进行一次删除(删除a),一次插入(插入c)和一次替换(将f替换为g),因此两者之间的编辑距离为3。在上述对应关系中,由于存在插入或删除,“abdef”中的“a”和“bcdeg”中的“c”在另一个符号串中不存在对应的符号。
[0077]
在本发明的实施过程中,将每个音素看作上例中的“符号”进行编辑距离的计算并得到两个音素序列中音素之间的对应关系。
[0078]
步骤1.4对于每一条语音数据,将数据对应的汉字文本分词,获取每一个词对应的汉字文本的音素序列,根据步骤1.3中得到的语音数据对应的汉字文本的音素序列与识别结果的音素序列之间的对应关系,得到每一个词对应的识别结果的音素序列。如果某个词对应的汉字文本的音素序列与该词对应的识别结果的音素序列不一致,则将这个词,连同其所对应的汉字文本的音素序列,以及其对应的识别结果的音素序列,加入一个候选词列表中。
[0079]
步骤1.5可选地,对于候选列表中的词进行自动筛选。自动筛选可基于该词在候选词列表中出现的频次,以及该词在识别结果中的音素序列方面的一致性。例如,仅当一个词在候选词列表中出现的次数大于一个预先设定的值时,才保留该词,否则将该词从候选词列表中删除;又例如,仅当一个词在候选词列表中出现的次数大于一个预先设定的值,并且在这多次出现中,其所对应的识别结果中的音素序列都一致时,才保留该词,否则将该词从候选词列表中删除。
[0080]
步骤1.6将候选词列表进行去重复合并处理,即对于一个词仅保留一个词条,但在一个词条中列出其所对应的汉字文本中的音素序列,以及其对应的所有的识别结果中的音素序列。
[0081]
步骤1.7采用一个人工校对模块,由人工对候选词列表进行校对和标注,得到方言词汇库。所述人工校对模块向熟悉该种方言的校对人员呈现所有词条及其相关信息,包括每一个汉语词、该汉语词对应的汉字文本中的音素序列、该汉语对应的所有的识别结果中的音素序列,然后提供交互界面,由校对人员进行校对和标注,主要包括:决定是否保留该词条,参考该汉语词对应的汉字文本中的音素序列标注该汉语词对应的普通话音素序列,以及参考该汉语词对应的所有的识别结果中的音素序列标注该汉语词对应的方言音素序列。最终得到的被保留的所有词条,包括汉语词、该汉语词对应的普通话音素序列、该汉语词对应的方言音素序列等信息,即构成所述方言词汇库。
[0082]
步骤1.8可选地,采用一个人工编辑模块,由人工对方言词汇库进行编辑,增补一些未出现在候选词列表中的词条。所述人工编辑模块提供相应的界面,供用户输入词条信息,包括汉语词、该汉语词对应的普通话音素序列、该汉语词对应的方言音素序列等信息。
[0083]
2.基于构建的方言词汇库和待切分和标注的语音数据对应的汉字文本,得到待切分和标注的语音数据对应的方言音素序列,然后采用面向普通话的语音识别声学模型和音素对齐算法将语音数据中与其对应的方言音素序列进行对齐,得到各音素的开始时间和结束时间,从而得到语音切分和标注结果。需要注意的是,语音切分和标注结果不同于音素序列,两者的区别是音素序列只有音素,没有开始时间和结束时间。
[0084]
其中步骤1中的模型用于语音识别的,功能是配合语音识别算法进行语音识别,即对于输入的语音,给出语音识别结果(汉字文本);步骤2中的语音识别声学模型用于音素对齐,功能是配合音素对齐算法进行音素和语音信号之间的对齐,即对于输入的语音和音素序列,给出每个音素的开始和结束时间。实际应用中两者可以采用同一个模型做这两件事,只是配合模型的算法不同。但也可以不同,因为对于语音识别功能来说,还可以增加其它语言模型,使得到的汉字更准,而语音对齐只针对音素,与汉字无关,所以不需要其它语言模型。
[0085]
步骤2.1基于构建的方言词汇库和待切分和标注的语音数据对应的汉字文本,得到待切分和标注的语音数据对应的方言音素序列。
[0086]
对于每一条语音数据,先将其对应的汉字文本分词,如果该词存在于方言词汇库中,则得到该词在方言词汇库中对应的方言音素序列;如果该词不存在于方言词汇库中,则利用一个汉语词和汉字到音素序列的对应表,得到其对应的音素序列,具体方法与步骤1.2中相同。将前述步骤得到的所有词对应的方言音素序列或音素序列连接起来,作为该条语音对应的方言音素序列。
[0087]
步骤2.2基于得到的语音数据对应的方言音素序列及其对应的语音数据,采用面向普通话的语音识别声学模型和音素对齐算法进行对齐,得到各音素的开始时间和结束时间,从而得到语音切分和标注结果。
[0088]
音素对齐算法基于语音识别声学模型,将语音信号与其对应的音素序列进行强制对齐,对齐后可得到音素序列中每一个音素对应的开始时间和结束时间,从而实现语音切分和标注。
[0089]
可采用当前已有的各种语音识别声学模型及对齐算法,如语音识别声学模型可采用基于gmm(混合高斯模型)+hmm(隐马尔可夫模型)的声学模型,基于dnn(深度神经网络)+hmm的声学模型,基于rnn(循环神经网络)的声学模型,基于变换器(transformer)的声学模
型等;对齐算法可采用基于韦特比(viterbi)解码的算法等。
[0090]
通过这一方法,虽然本发明采用的是面向普通话的语音识别声学模型,但由于采用的音素序列是方言音素序列,因此对齐的时候语音中的实际发音与音素序列更为一致,对齐效果更好。避免了采用普通话音素序列时,发音不一致时导致的错误。
[0091]
3.提供相应的模块和交互界面,供用户对步骤2得到的语音切分和标注结果进行校对和修改。
[0092]
提供相应的模块和交互界面,使用户可收听语音数据、查看语音数据的波形图或语谱图、查看由步骤2得到的语音切分和标注结果,并对结果进行校对和修改。
[0093]
4.采用经人工校对和修改过的切分和标注信息及其对应的语音数据进行语音识别声学模型的训练,得到更新后的方言语音声学模型,采用所述更新后的方言语音声学模型进行新的方言语音数据的切分和标注。
[0094]
步骤4.1采用经人工校对和修改过的切分和标注信息及其对应的语音数据进行语音识别声学模型的训练,得到更新后的方言语音声学模型。
[0095]
具体训练的方式可以有多种,例如,可以直接采用经人工校对和修改过的切分和标注信息及其对应的语音数据进行声学模型训练,也可以将经人工校对和修改过的切分和标注信息及其对应的语音数据与已有的普通话数据进行混合后进行声学模型训练,也可以在已有的面向普通话语音的声学模型的基础上,采用经人工校对和修改过的切分和标注信息及其对应的语音数据进行增量式训练,如模型自适应(self
‑
adaptation)和微调(fine
‑
tuning)。
[0096]
步骤4.2采用所述更新后的方言语音声学模型进行新的方言语音数据的切分和标注。
[0097]
对于需要进行切分和标注的新语音数据,首先基于方言词汇库和待切分和标注的语音数据对应的汉字文本,得到待切分和标注的语音数据对应的方言音素序列,然后采用更新后的方言语音声学模型和对齐算法,将语音信号与其对应的方言音素序列进行强制对齐,对齐后可得到音素序列中每一个音素对应的开始时间和结束时间,从而实现语音切分和标注。
[0098]
下面结合具体的实施例进一步介绍本发明所提出的方言语音数据切分及标注方法。
[0099]
在一个实施例中,重点针对山东临沂方言语音数据进行自动切分及标注。在实施前,已获取了大量带有文本标注的方言语音。每句话存为一个wav文件,并配有标注文件,其中存有每一句话(每个wav文件)对应的汉字文本。
[0100]
按照本发明提出的方法,执行如下步骤:
[0101]
步骤1.利用已采集的方言语音数据及其对应的汉字文本,以及普通话语音识别系统对方言语音数据的识别结果,结合人工校对和标注,构建一个方言词汇库。
[0102]
步骤1.1利用一个已有的普通话语音识别系统,识别每一条方言语音数据,得到其对应的识别结果。在一个实施例中,采用一个pc(个人电脑)端本地的语音识别系统;在另一个实施例中,采用一个云端语音识别服务引擎,将wav文件上传至云端语音识别平台后,获取识别结果。识别结果为语音对应的汉字串。
[0103]
在一个实施例中,一条语音数据对应的汉字文本为:“我的脚很疼”。由于山东临沂
方言中,“脚”发音更接近于“jue”。这导致采用普通话语音识别系统可能出现识别错误。在一个实施例中,该条语音数据的识别结果为:“我的爵爷很疼”。
[0104]
步骤1.2利用一个汉语词和汉字到音素序列的对应表,分别得到每一条方言语音数据对应的汉字文本和识别结果的音素序列。
[0105]
在上文所述的实施例中,一条语音数据对应的文本、识别结果分别为:
[0106]
语音对应的文本:我的脚很疼
[0107]
语音对应的识别结果:我的爵爷很疼
[0108]
采用一个汉语分词工具分别对其进行分词,得到:
[0109]
语音对应的文本的分词结果:我的脚很疼
[0110]
语音对应的识别结果的分词结果:我的爵爷很疼
[0111]
采用一个汉语词到音素序列的对应表,以及汉字到音素序列的对应表,得到语音对应的文本和识别结果的音素序列如下:
[0112]
语音对应的文本的音素序列:w o d e j iao h en t eng
[0113]
语音对应的识别结果的音素序列:w o d e j ue ie h en t eng
[0114]
步骤1.3对于每一条方言语音数据,使用编辑距离方法将其对应的文本的音素序列与其对应的识别结果的音素序列进行自动对齐。
[0115]
在上文所述的实施例中,基于编辑距离将语音对应的文本的音素序列与语音对应的识别结果的音素序列进行对齐,计算得到两者的编辑距离为3,音素间的对应关系为:
[0116][0117][0118]
对齐后,对于语音数据对应的文本的音素序列中的每一个音素,都会对应该语音数据对应的识别结果的音素序列中的一个音素或不对应任何音素。如上例所示。
[0119]
步骤1.4对于每一条语音数据,将数据对应的汉字文本分词,获取每一个词对应的汉字文本的音素序列,根据步骤1.3中得到的语音数据对应的汉字文本的音素序列与识别结果的音素序列之间的对应关系,得到每一个词对应的识别结果的音素序列。如果某个词对应的汉字文本的音素序列与该词对应的识别结果的音素序列不一致,则将这个词,连同其所对应的汉字文本的音素序列,以及其对应的识别结果的音素序列,加入一个候选词列
表中。
[0120]
在上文所述实施例中,语音数据对应的汉字文本为:“我的脚很疼”,分词后为“我的脚很疼”,根据前述步骤,可得到每个词、该词对应的汉字文本的音素序列,以及该词对应的识别结果的音素序列,如下:
[0121]
词汉字文本的音素序列识别结果的音素序列我w ow o的d ed e脚j iaoj ue很h enh en疼t engt eng
[0122]
注意到,“脚”对应的汉字文本的音素序列与其对应的识别结果的音素序列不同,因此将下述词条(包括词,该词对应的汉字文本的音素序列,以及该词对应的识别结果的音素序列)加入候选词列表中。
[0123]
脚
ꢀꢀꢀꢀ
j
ꢀꢀ
iao
ꢀꢀꢀꢀ
j
ꢀꢀ
ue
[0124]
步骤1.5可选地,对于候选列表中的词进行自动筛选。自动筛选可基于该词在候选词列表中出现的频次,以及该词在识别结果中的音素序列方面的一致性。例如,仅当一个词在候选词列表中出现的次数大于一个预先设定的值时,才保留该词,否则将该词从候选词列表中删除;又例如,仅当一个词在候选词列表中出现的次数大于一个预先设定的值,并且在这多次出现中,其所对应的识别结果中的音素序列都一致时,才保留该词,否则将该词从候选词列表中删除。
[0125]
在上文所述实施例中,采用的规则为上述第二种规则,即:仅当一个词在候选词列表中出现的次数大于一个预先设定的值,并且在这多次出现中,其所对应的识别结果中的音素序列都一致时,才保留该词,否则将该词从候选词列表中删除。统计“脚”在语料中出现的频次,发现其频次为15,大于预先设置的值(3);同时检查这5次出现时,该词对应的识别结果的音素序列,发现都是相同的“j ue”,因此在候选词列表中保留该词条。
[0126]
步骤1.6将候选词列表进行去重复合并处理,即对于一个词仅保留一个词条,但在一个词条中列出其所对应的汉字文本中的音素序列,以及其对应的所有的识别结果中的音素序列。
[0127]
在上文所述的实施例中,将“脚”的15次出现所产生的15个词条合并为一个词条:
[0128]
脚
ꢀꢀꢀꢀ
j
ꢀꢀ
iao
ꢀꢀꢀꢀ
j
ꢀꢀ
ue
[0129]
步骤1.7采用一个人工校对模块,由人工对候选词列表进行校对和标注,得到方言词汇库。所述人工校对模块向熟悉该种方言的校对人员呈现所有词条及其相关信息,包括每一个汉语词、该汉语词对应的汉字文本中的音素序列、该汉语词对应的所有的识别结果中的音素序列,然后提供交互界面,由校对人员进行校对和标注,主要包括:决定是否保留该词条,参考该汉语词对应的汉字文本中的音素序列标注该汉语词对应的普通话音素序列,以及参考该汉语词对应的所有的识别结果中的音素序列标注该汉语词对应的方言音素序列。最终得到的被保留的所有词条,包括汉语词、该汉语词对应的普通话音素序列、该汉语词对应的方言音素序列等信息,即构成所述方言词汇库。
[0130]
在上文所述实施例中,经人工校对检查后,保留了词条:
[0131]
脚
ꢀꢀꢀꢀ
j
ꢀꢀ
iao
ꢀꢀꢀꢀ
j
ꢀꢀ
ue
[0132]
在另一个实施例中,经人工校对检查后,认为存在语音识别错误导致的音素序列错误,因此将词条
[0133]
脚
ꢀꢀꢀꢀ
j
ꢀꢀ
iao
ꢀꢀꢀꢀ
zh
ꢀꢀ
uo
[0134]
修改为
[0135]
脚
ꢀꢀꢀꢀ
j
ꢀꢀ
iao
ꢀꢀꢀꢀ
j
ꢀꢀ
ue
[0136]
步骤1.8可选地,采用一个人工编辑模块,由人工对方言词汇库进行编辑,增补一些未出现在候选词列表中的词条。所述人工编辑模块提供相应的界面,供用户输入词条信息,包括汉语词、该汉语词对应的普通话音素序列、该汉语词对应的方言音素序列等信息。
[0137]
在一个实施例中,人工增加了一个词条
[0138]
脊梁
ꢀꢀꢀꢀ
j i l iang
ꢀꢀꢀꢀ
j i n iang
[0139]
2.基于构建的方言词汇库和待切分和标注的语音数据对应的汉字文本,得到待切分和标注的语音数据对应的方言音素序列,然后采用面向普通话的语音识别声学模型和音素对齐算法,得到语音切分和标注结果。
[0140]
步骤2.1基于构建的方言词汇库和待切分和标注的语音数据对应的汉字文本,得到待切分和标注的语音数据对应的方言音素序列。
[0141]
在一个实施例中,一条待切分和标注的语音数据对应的汉字文本为“脚疼不疼”。对于这条语音,先采用一个汉语分词软件对其进行分词,得到分词后的结果为“脚疼不疼”。然后,在方言词汇库中依次搜索每一个词,本实施例中“脚”存在于方言词汇库中,因此可得到其在方言词汇库中的方言音素序列“j ue”。对于其它的词,因为不存在于方言词汇库中,因此采用汉语词和汉字到音素序列的对应表,得到其对应的音素序列。把所有词对应的方言音素序列或音素序列连接起来作为该语音对应的方言音素序列,在所述实施例中为:
[0142]
j ue t eng b u t eng
[0143]
步骤2.2基于得到的语音数据对应的方言音素序列,采用面向普通话的语音识别声学模型和音素对齐算法,得到语音切分和标注结果。
[0144]
在一个实施例中,采用基于dnn+hmm的声学模型和基于韦特比解码的对齐算法,把语音与音素进行强制对齐,可以得到每个音素的开始和结束时间,作为其语音切分和标注结果。
[0145]
在一个实施例中,一条语音数据的汉字文本为“脚疼不疼”,其方言音素序列为“j ue t eng b u t eng”。在进行对齐后,得到的语音切分和标注结果为:
[0146]
0.709 0.790 j
[0147]
0.790 0.963 ue
[0148]
1.055 1.110 t
[0149]
1.110 1.316 eng
[0150]
1.316 1.346 b
[0151]
1.346 1.459 u
[0152]
1.459 1.538 t
[0153]
1.538 1.739 eng
[0154]
可见,这一切分和标注结果中,将方言发音由其真实发音音素,而非该汉字对应的
普通话发音音素表示,有助于训练更准确的方言语音识别模型;同时,由于采用了更接近真实发音的音素序列,因此,在对齐过程中产生的对齐偏差和错误较少。相反,如果采用明显和真实发音不同的“j iao”去和“脚”字对应的语音对齐,则可能使对齐出错,从而得到错误的语音切分和标注结果。
[0155]
3.提供相应的模块和交互界面,供用户对步骤2得到的语音切分和标注结果进行校对和修改。
[0156]
在一个实施例中,提供一个运行于个人电脑(pc)上的工具软件,用户可使用该工具软件收听语音数据、查看语音数据的波形图或语谱图、查看由步骤2得到的语音切分和标注结果,并对结果进行校对和修改,例如,修改某一个音素的开始时间和结束时间。
[0157]
4.采用经人工校对和修改过的切分和标注信息及其对应的语音数据进行语音识别声学模型的训练,得到更新后的方言语音声学模型,采用所述更新后的方言语音声学模型进行新的方言语音数据的切分和标注。
[0158]
步骤4.1采用经人工校对和修改过的切分和标注信息及其对应的语音数据进行语音识别声学模型的训练,得到更新后的方言语音声学模型。
[0159]
在一个实施例中,将经人工校对和修改过的切分和标注信息及其对应的语音数据与原有的普通话语音数据混合在一起,共同训练基于dnn+hmm模型的声学模型,作为更新后的方言语音声学模型;在另一个实施例中,使用经人工校对和修改过的切分和标注信息及其对应的语音数据对已有的面向普通话的基于gmm+hmm模型的声学模型进行基于极大似然线性变换(mllr)的声学模型自适应(acoustic model adaptation)操作,以使新得到的声学模型更适应方言语音的特点;在另一个实施例中,使用经人工校对和修改过的切分和标注信息及其对应的语音数据对已有的基于变换器(transformer)的深度神经网络声学模型进行微调(fine
‑
tuning),以使新得到的声学模型更适应方言语音的特点。
[0160]
步骤4.2采用所述更新后的方言语音声学模型进行新的方言语音数据的切分和标注。
[0161]
对于需要进行切分和标注的新语音数据,首先基于方言词汇库和待切分和标注的语音数据对应的汉字文本,得到待切分和标注的语音数据对应的方言音素序列,然后采用更新后的方言语音声学模型和对齐算法,将语音信号与其对应的音素序列进行强制对齐,对齐后可得到音素序列中每一个音素对应的开始时间和结束时间,从而实现语音切分和标注。
[0162]
以下为与上述方法实施例对应的系统实施例,本实施方式可与上述实施方式互相配合实施。上述实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在上述实施方式中。
[0163]
本发明还提出了一种方言语音数据切分及标注系统,其中包括:
[0164]
模块1,用于使普通话语音识别模型对第一方言语音进行语音数据切分及标注,得到该第一方言语音的汉字识别结果,并基于该第一方言语音及其对应汉字文本和该汉字识别结果,构建方言词汇库;
[0165]
模块2,用于获取待切分和标注的语音数据作为第二方言语音,基于该方言词汇库和该第二方言语音对应的汉字文本,得到该第二方言语音对应的音素序列,并采用音素对齐算法和该普通话语音识别模型,得到第二方言语音的语音切分标注结果;
[0166]
模块3,用于基于经人工校对的语音切分标注结果及其对应的语音数据训练得到方言语音声学模型,将待语音数据切分及标注的方言语音数据输入至该方言语音声学模型,得到该待语音数据切分及标注的方言语音数据的切分和标注结果。
[0167]
所述的方言语音数据切分及标注系统,其中该模块1包括:
[0168]
模块11,用于使该普通话语音识别模型,识别该第一方言语音,得到其对应的识别结果,利用汉语词和汉字到音素序列的对应表,得到该第一方言语音对应的汉字文本和该识别结果的音素序列;
[0169]
模块12,用于基于编辑距离,将第一方言语音的汉字文本的音素序列与其对应的识别结果的音素序列进行自动对齐,对齐后对于第一方言语音汉字文本的音素序列中的每一个音素,均对应该识别结果的音素序列中的一个音素或不对应任何音素;
[0170]
模块13,用于将第一方言语音的汉字文本进行分词,得到每一个词对应的汉字文本的音素序列,根据模块12中汉字文本的音素序列与识别结果的音素序列间的对应关系,得到每一个词对应的识别结果的音素序列;其中若某个词对应的汉字文本的音素序列与该词对应的识别结果的音素序列不一致,则将这个词,连同其所对应的汉字文本的音素序列,以及其对应的识别结果的音素序列,加入候选词列表;
[0171]
模块14,用于通过去重合并处理,该候选词列表中每个词仅保留一个词条,词条中包括其所对应的汉字文本中的音素序列,以及其对应的所有的识别结果中的音素序列,并采用人工对该候选词列表进行校对和标注,得到该方言词汇库。
[0172]
所述的方言语音数据切分及标注系统,其中该模块2包括:
[0173]
模块21,用于对于第二方言语音,先将其对应的汉字文本分词,判断分词结果是否存在于该方言词汇库中,若是,则获取分词结果在方言词汇库中对应的音素序列,否则利用汉语词和汉字到音素序列的对应表,得到其对应的音素序列,将第二方言语音所有词对应的音素序列连接起来,作为该第二方言语音对应的音素序列;
[0174]
模块22,用于基于语音识别声学模型,将第二方言语音与其对应的音素序列进行对齐,对齐后得到音素序列中每一个音素对应的开始时间和结束时间,从而实现语音切分和标注。
[0175]
所述的方言语音数据切分及标注系统,其中该模块3包括:
[0176]
将经人工校对的语音切分标注结果及其对应的语音数据与普通话语音数据混合在一起,共同训练基于dnn+hmm模型的声学模型,作为该方言语音声学模型;或
[0177]
使用经人工校对语音切分标注结果及其对应的语音数据对已有的面向普通话的基于gmm+hmm模型的声学模型,进行基于极大似然线性变换的声学模型自适应操作,以得到该方言语音声学模型;或
[0178]
使用经人工校对语音切分标注结果及其对应的语音数据对已有的基于变换器的深度神经网络声学模型进行微调,以得到该方言语音声学模型。
[0179]
所述的方言语音数据切分及标注系统,其中还包括模块4,用于基于该方言语音声学模型输出的切分和标注结果,训练方言语音识别模型和/或方言语音合成模型,通过方言语音识别模型将方言音频转化为汉字信息,和/或通过方言语音合成模型将汉字信息转化为方言音频。