1.本发明涉及计算机技术领域,具体而言,涉及一种情绪识别方法、装置和电子设备。
背景技术:
2.目前,智能机器人在各行业得到了广泛应用,智能语音导航、在线机器人和金牌话术等模拟的人工智能(ai)场景包括服务场景,都是人工智能在客服领域的重要应用。
技术实现要素:
3.为解决上述问题,本发明实施例的目的在于提供一种情绪识别方法、装置和电子设备。
4.第一方面,本发明实施例提供了一种情绪识别方法,包括:
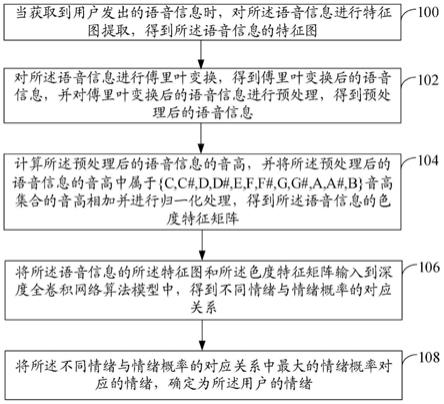
5.当获取到用户发出的语音信息时,对所述语音信息进行特征图提取,得到所述语音信息的特征图;
6.对所述语音信息进行傅里叶变换,得到傅里叶变换后的语音信息,并对傅里叶变换后的语音信息进行预处理,得到预处理后的语音信息;
7.计算所述预处理后的语音信息的音高,并将所述预处理后的语音信息的音高中属于{c,c#,d,d#,e,f,f#,g,g#,a,a#,b}音高集合的音高相加并进行归一化处理,得到所述语音信息的色度特征矩阵;
8.将所述语音信息的所述特征图和所述色度特征矩阵输入到深度全卷积网络算法模型中,得到不同情绪与情绪概率的对应关系;
9.将所述不同情绪与情绪概率的对应关系中最大的情绪概率对应的情绪,确定为所述用户的情绪。
10.第二方面,本发明实施例还提供了一种情绪识别装置,包括:
11.提取模块,用于当获取到用户发出的语音信息时,对所述语音信息进行特征图提取,得到所述语音信息的特征图;
12.处理模块,用于对所述语音信息进行傅里叶变换,得到傅里叶变换后的语音信息,并对傅里叶变换后的语音信息进行预处理,得到预处理后的语音信息;
13.第一计算模块,用于计算所述预处理后的语音信息的音高,并将所述预处理后的语音信息的音高中属于{c,c#,d,d#,e,f,f#,g,g#,a,a#,b}音高集合的音高相加并进行归一化处理,得到所述语音信息的色度特征矩阵;
14.第二计算模块,用于将所述语音信息的所述特征图和所述色度特征矩阵输入到深度全卷积网络算法模型中,得到不同情绪与情绪概率的对应关系;
15.确定模块,用于将所述不同情绪与情绪概率的对应关系中最大的情绪概率对应的情绪,确定为所述用户的情绪。
16.第三方面,本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存
储介质上存储有计算机程序,所述计算机程序被处理器运行时执行上述第一方面所述的方法的步骤。
17.第四方面,本发明实施例还提供了一种电子设备,所述电子设备包括有存储器,处理器以及一个或者一个以上的程序,其中所述一个或者一个以上程序存储于所述存储器中,且经配置以由所述处理器执行上述第一方面所述的方法的步骤。
18.本发明实施例上述第一方面至第四方面提供的方案中,通过对用户发送的语音信息的特征图进行提取后得到的语音信息,以及处理语音信息后得到的色度特征矩阵确定用户的情绪,与相关技术中只能向用户反馈无情绪的答复信息的方式相比,可以根据确定出的用户情绪,向用户反馈与其情绪向对应的答复信息,提高用户的体验。
19.为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
附图说明
20.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
21.图1示出了本发明实施例1所提供的一种情绪识别方法的流程图;
22.图2示出了本发明实施例2所提供的一种情绪识别装置的结构示意图;
23.图3示出了本发明实施例3所提供的一种电子设备的结构示意图。
具体实施方式
24.在本发明的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“长度”、“宽度”、“厚度”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”“内”、“外”、“顺时针”、“逆时针”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
25.此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,“多个”的含义是两个或两个以上,除非另有明确具体的限定。
26.在本发明中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
27.为使本技术的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本技术做进一步详细的说明。
28.实施例1
29.本实施例提出一种情绪识别方法的执行主体是可以与用户进行交互的机器人。
30.参见图1所示的一种情绪识别方法的示意图,本实施例提出一种情绪识别方法,包括以下具体步骤:
31.步骤100、当获取到用户发出的语音信息时,对所述语音信息进行特征图提取,得到所述语音信息的特征图。
32.在上述步骤100中,对所述语音信息进行特征图提取,得到所述语音信息的特征图的过程是现有技术,这里不再赘述。
33.步骤102、对所述语音信息进行傅里叶变换,得到傅里叶变换后的语音信息,并对傅里叶变换后的语音信息进行预处理,得到预处理后的语音信息。
34.在上述步骤102中,所述预处理,包括但不限于:对语音信息的长度超过1000帧的部分进行舍弃;对于长度不足1000帧的语音信息进行补零操作,使长度不足1000帧的语音信息的长度达到1000帧;以及对所述语音信息进行平滑处理。
35.步骤104、计算所述预处理后的语音信息的音高,并将所述预处理后的语音信息的音高中属于{c,c#,d,d#,e,f,f#,g,g#,a,a#,b}音高集合的音高相加并进行归一化处理,得到所述语音信息的色度特征矩阵。
36.在上述步骤104中,计算所述预处理后的语音信息的音高的具体过程是现有技术,这里不再赘述。
37.将所述预处理后的语音信息的音高中属于{c,c#,d,d#,e,f,f#,g,g#,a,a#,b}音高集合的音高相加并进行归一化处理,得到所述语音信息的色度特征矩阵的过程,是现有技术,这里不再赘述。
38.步骤106、将所述语音信息的所述特征图和所述色度特征矩阵输入到深度全卷积网络算法模型中,得到不同情绪与情绪概率的对应关系。
39.在上述步骤106中,所述深度全卷积网络算法模型,是用带有不同情绪的语音信息以及使用bi
‑
lstm学习数据中存在的时间上下文信息训练得到的,用于对所述语音信息进行处理,得到情绪与情绪概率的对应关系。
40.所述深度全卷积网络算法模型的池化方式:选择全局k最大池化,与传统最大池化不同,对于特征图中的每一行,gkmp池化方式选取前k个最大值,并将其作为这一行的特征表示。因此对于大小为f*m的特征图,经过gkmp池化方式,可以得到大小为f*k的输出,其中f表示特征的维度,m表示帧长。
41.在一个实施方式中,所述深度全卷积网络算法模型可以使用多层卷积神经网络(multiple cnn,mcnn);语音信息的所述特征图和所述色度特征矩阵先经过mcnn,所述mcnn是卷积神经网络(cnn)的一种改进,再经过bi
‑
lstm层,最后到全连接层fc,输入6个情绪(中性情绪、开心情绪、惊讶情绪、伤心情绪、生气情绪、以及厌恶情绪)的概率情况。
42.深度全卷积网络算法先使用mcnns算法学习谱图的特征表示,然后使用bi
‑
lstm学习数据中存在的时间上下文信息,在全连接层(fc)的最后一层,使用了多任务学习算法,同时使用上述6个情绪分类任务classification来加强模型对特定情绪特征的学习。
43.深度全卷积网络算法先使用mcnns算法很好的解决了输入长度不固定时训练的问题,同时可以使得特征提取方式不过于简单、模型复杂度也相对较低、特征情绪识别的准确率也得到了提高。
44.所述不同情绪,包括但不限于:中性情绪、开心情绪、惊讶情绪、伤心情绪、生气情绪以及厌恶情绪。
45.其中,所述中性情绪,就是表示所述用户处于平静的情绪中。
46.所述不同情绪与情绪概率的对应关系,就是中性情绪、开心情绪、惊讶情绪、伤心情绪、生气情绪以及厌恶情绪中的各情绪分别与情绪概率的对应关系。
47.步骤108、将所述不同情绪与情绪概率的对应关系中最大的情绪概率对应的情绪,确定为所述用户的情绪。
48.可选地,本实施例提出的情绪识别方法,还可以执行以下步骤(1)至步骤(5),确定所述用户的情绪:
49.(1)当获取到用户发出的文字信息时,确定用户使用的是打字的方式发出的文字信息;
50.(2)获取所述用户使用的移动终端上安装的文字输入法所记录的用户的输入特征信息;
51.(3)对所述输入特征信息进行处理,得到所述输入特征信息的特征向量;
52.(4)将所述输入特征信息的特征向量输入到支持向量机中,并将所述支持向量机的处理结果输入到softmax算法模型中,得到情绪与情绪概率的对应关系;
53.(5)将最大的情绪概率对应的情绪,确定为所述用户的情绪。
54.在上述步骤(2)中,所述服务器,可以向用户使用的移动终端发送输入特征信息获取请求。若用户使用的移动终端的用户的输入特征信息权限是开放的,就可以从所述用户使用的移动终端上安装的文字输入法中获取到所述用户的输入特征信息。
55.所述输入特征信息包括但不限于:预设时段内用户输入文字的停顿时间、用户输入文字的停顿次数、用户输入文字的最长停顿时间、用户输入文字的停顿位置、内容修改次数、预设时段内用户在输入过程中击键时间的最大值、预设时段内用户在输入过程中击键时间的最小值、预设时段内用户在输入过程中击键时间的平均值、预设时段内用户在输入过程中击键时间的中位数、预设时段内用户在输入过程中击键时间的方差、预设时段内第一个键释放到第二个键按下的时间、预设时段内第一个键按下到第二个键释放的时间、预设时段内输入的各句子的句子长度、预设时段内输入的各表情包的表情包含义。
56.所述用户输入文字的停顿时间,是指预设时段内用户输入两个相邻字符之间的时间间隔。
57.所述用户输入文字的停顿次数,是指预设时段内用户输入文字时停顿时间大于时间阈值的次数。
58.所述时间阈值,可以设置为1至3秒之间的任意时间长度。
59.所述用户输入文字的最长停顿时间,是指预设时段内用户输入两个相邻字符之间的最大时间间隔。
60.所述用户输入文字的停顿位置,就是用户输入文字的过程中所停顿时间超过一定时间的光标位置。
61.在一个实施方式中,所述一定时间,可以是3秒。
62.所述内容修改次数,是指预设时段内用户输入文字的过程中,点击输入法的“删除(退格)键”或者“取消键”的次数。
63.所述预设时段内用户在输入过程中击键时间的最大值,是指预设时段内,所述用户输入文字时按下输入法中按键到松开该按键的最大时间长度。
64.所述预设时段内用户在输入过程中击键时间的最小值,是指预设时段内,所述用户输入文字时按下输入法中按键到松开该按键的最小时间长度。
65.预设时段内用户在输入过程中击键时间的平均值、预设时段内用户在输入过程中击键时间的中位数、预设时段内用户在输入过程中击键时间的方差都是根据预设时段内用户在输入过程中击键时间计算得到的,具体过程是现有技术,这里不再赘述。
66.所述预设时段内第一个键释放到第二个键按下的时间,是指预设时段内,释放输入法中的一个按键到按下该按键的下一个按键的时间长度。
67.所述预设时段内第一个键按下到第二个键释放的时间,是指预设时段内,按下输入法中的一个按键到释放该按键的下一个按键的时间长度。
68.所述预设时段,可以设置为1小时到24小时之间的任意时间长度。
69.在上述步骤(3)中,所述对所述输入特征信息进行处理,得到所述输入特征信息的特征向量的过程是现有技术,这里不再赘述。
70.在上述步骤(4)中,将所述输入特征信息的特征向量输入到支持向量机中,并将所述支持向量机的处理结果输入到softmax算法模型中,得到情绪与情绪概率的对应关系的具体过程是现有技术,这里不再赘述。
71.基于文本输入过程中产生的特征使用支持向量机对用户的情绪进行推断,(池化方式选择全局k最大池化gkmp),最后使用softmax算法模型进行输出分类,判断他们的情绪属于中性情绪、开心情绪、惊讶情绪、伤心情绪、生气情绪、以及厌恶情绪这六种情绪的哪一种情绪。
72.使用支持向量机(svm)算法的主要流程如下:
73.1)给出一个7个点训练数据集d={(x1,y1),(x2,y2),......,(x7,y7)},其中,x
i
∈r
n
,y
i
∈r,i=1,2,......,7;y为对应的情绪分类;
74.2)选择恰当的核函数k(x,y)以及参数项c;
75.3)最优凸二次规划为:
[0076][0077][0078]
解得:
[0079]
可选地,本实施例提出的情绪识别方法,还可以执行以下步骤(1)至步骤(4),确定所述用户的情绪:
[0080]
(1)当采集到所述用户的面部图像时,利用xception网络对所述用户的面部图像进行处理,得到所述用户的面部图像的特征向量,并利用时空神经网络stnn对所述用户的面部图像进行处理,得到所述用户的面部图像的空间维度特征和短时间维度特征、以及长时间维度特征;
[0081]
(2)将所述用户的面部图像的特征向量输入到softmax算法模型中,得到第一情绪
与情绪概率的对应关系;
[0082]
(3)将所述用户的面部图像的空间维度特征和短时间维度特征、以及长时间维度特征输入到softmax算法模型中,得到第二情绪与情绪概率的对应关系;
[0083]
(4)利用ds融合算法对所述第一情绪与情绪概率的对应关系和所述第二情绪与情绪概率的对应关系进行处理,确定所述用户的情绪。
[0084]
在上述步骤(1)中,所述利用xception网络对所述用户的面部图像进行处理,得到所述用户的面部图像的特征向量的过程是现有技术,这里不再赘述。
[0085]
stnn网络先经过两个con3d层——在经过一个maxpooling层——再经过两个convlstm层——再经过一个平铺层——再到两个全连接层——最后到softmax函数。
[0086]
stnn中每个con3d层有32个卷积核,卷积核的尺寸为3
×3×
15,其中3
×
3为接受空间域的大小,15为时间深度。
[0087]
maxpooling层最大池化核的尺寸为:3
×3×
3,步长同样为1
×1×
1,采用有效模式valid填充。
[0088]
最后经过第二个全连接层的输出再经过一个softmax函数得到六种微表情的预测值。
[0089]
所述利用时空神经网络stnn对所述用户的面部图像进行处理,得到所述用户的面部图像的空间维度特征和短时间维度特征、以及长时间维度特征是现有技术,这里不再赘述。
[0090]
在上述步骤(2)中,所述将所述用户的面部图像的特征向量输入到softmax算法模型中,得到第一情绪与情绪概率的对应关系的具体过程是现有技术,这里不再赘述。
[0091]
在上述步骤(3)中,所述将所述用户的面部图像的空间维度特征和短时间维度特征、以及长时间维度特征输入到softmax算法模型中,得到第二情绪与情绪概率的对应关系的具体过程是现有技术,这里不再赘述。
[0092]
在上述步骤(4)中,所述利用ds融合算法对所述第一情绪与情绪概率的对应关系和所述第二情绪与情绪概率的对应关系进行处理,确定所述用户的情绪的具体过程是现有技术,这里不再赘述。
[0093]
在利用以上过程确定出用户的情绪后,所述方法还可以继续执行以下步骤(1)至步骤(2):
[0094]
(1)当所述用户的情绪属于所述中性情绪、所述开心情绪或者所述惊讶情绪时,获取答复文本集合,并利用平滑倒词频(smooth inverse frequency,sif)算法对所述答复文本集合中的各答复文本与所述用户的情绪进行匹配,从所述答复文本集合中的各答复文本中确定出与所述用户的情绪匹配度最高的答复文本反馈给所述用户;
[0095]
(2)当所述用户的情绪属于所述伤心情绪、所述生气情绪以及所述厌恶情绪时,则通知在线人工客服对所述用户进行答复。
[0096]
在上述步骤(1)中,所述答复文本集合,预先设置在所述机器人中。
[0097]
所述答复文本集合,用于记录有对用户提出的问题进行答复的答复文本。所述答复文本,可以与所述中性情绪、所述开心情绪或者所述惊讶情绪匹配。
[0098]
所述利用sif算法对所述答复文本集合中的各答复文本与所述用户的情绪进行匹配的过程是现有技术,这里不再赘述。
[0099]
本实施例提出的一种情绪识别方法,主要通过人脸面部表情识别、语音情感识别以及文本识别来实现用户的情绪识别,并且对算法进行了改进,识别效果更好,准确率更高,识别方式更全面、更合理。
[0100]
综上所述,本实施例提出一种情绪识别方法,通过对用户发送的语音信息的特征图进行提取后得到的语音信息,以及处理语音信息后得到的色度特征矩阵确定用户的情绪,与相关技术中只能向用户反馈无情绪的答复信息的方式相比,可以根据确定出的用户情绪,向用户反馈与其情绪向对应的答复信息,提高用户的体验。
[0101]
实施例2
[0102]
本实施例提出一种情绪识别装置,用于执行上述实施例1提出的情绪识别方法。
[0103]
参见图2所示的一种情绪识别装置的示意图,本实施例提出一种情绪识别装置,包括:
[0104]
提取模块200,用于当获取到用户发出的语音信息时,对所述语音信息进行特征图提取,得到所述语音信息的特征图;
[0105]
处理模块202,用于对所述语音信息进行傅里叶变换,得到傅里叶变换后的语音信息,并对傅里叶变换后的语音信息进行预处理,得到预处理后的语音信息;
[0106]
第一计算模块204,用于计算所述预处理后的语音信息的音高,并将所述预处理后的语音信息的音高中属于{c,c#,d,d#,e,f,f#,g,g#,a,a#,b}音高集合的音高相加并进行归一化处理,得到所述语音信息的色度特征矩阵;
[0107]
第二计算模块206,用于将所述语音信息的所述特征图和所述色度特征矩阵输入到深度全卷积网络算法模型中,得到不同情绪与情绪概率的对应关系;
[0108]
确定模块208,用于将所述不同情绪与情绪概率的对应关系中最大的情绪概率对应的情绪,确定为所述用户的情绪。
[0109]
可选地,本实施例提出的情绪识别装置,还包括:
[0110]
第一确定单元,用于当获取到用户发出的文字信息时,确定用户使用的是打字的方式发出的文字信息;
[0111]
获取单元,用于获取所述用户使用的移动终端上安装的文字输入法所记录的用户的输入特征信息;
[0112]
第一处理单元,用于对所述输入特征信息进行处理,得到所述输入特征信息的特征向量;
[0113]
第二处理单元,用于将所述输入特征信息的特征向量输入到支持向量机中,并将所述支持向量机的处理结果输入到softmax算法模型中,得到情绪与情绪概率的对应关系;
[0114]
第二确定单元,用于将最大的情绪概率对应的情绪,确定为所述用户的情绪。
[0115]
可选地,本实施例提出的情绪识别装置,还包括:
[0116]
第三处理单元,用于当采集到所述用户的面部图像时,利用xception网络对所述用户的面部图像进行处理,得到所述用户的面部图像的特征向量,并利用时空神经网络stnn对所述用户的面部图像进行处理,得到所述用户的面部图像的空间维度特征和短时间维度特征、以及长时间维度特征;
[0117]
第一计算单元,用于将所述用户的面部图像的特征向量输入到softmax算法模型中,得到第一情绪与情绪概率的对应关系;
[0118]
第二计算单元,用于将所述用户的面部图像的空间维度特征和短时间维度特征、以及长时间维度特征输入到softmax算法模型中,得到第二情绪与情绪概率的对应关系;
[0119]
第三确定单元,利用ds融合算法对所述第一情绪与情绪概率的对应关系和所述第二情绪与情绪概率的对应关系进行处理,确定所述用户的情绪。
[0120]
所述情绪包括:中性情绪、开心情绪、惊讶情绪、伤心情绪、生气情绪以及厌恶情绪。
[0121]
可选地,本实施例提出的情绪识别装置,还包括:
[0122]
反馈单元,用于当所述用户的情绪属于所述中性情绪、所述开心情绪或者所述惊讶情绪时,获取答复文本集合,并利用smooth inverse frequency算法对所述答复文本集合中的各答复文本与所述用户的情绪进行匹配,从所述答复文本集合中的各答复文本中确定出与所述用户的情绪匹配度最高的答复文本反馈给所述用户;
[0123]
通知单元,用于当所述用户的情绪属于所述伤心情绪、所述生气情绪以及所述厌恶情绪时,则通知在线人工客服对所述用户进行答复。
[0124]
综上所述,本实施例提出一种情绪识别装置,通过对用户发送的语音信息的特征图进行提取后得到的语音信息,以及处理语音信息后得到的色度特征矩阵确定用户的情绪,与相关技术中只能向用户反馈无情绪的答复信息的方式相比,可以根据确定出的用户情绪,向用户反馈与其情绪向对应的答复信息,提高用户的体验。
[0125]
实施例3
[0126]
本实施例提出一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器运行时执行上述实施例1描述的情绪识别方法的步骤。具体实现可参见方法实施例1,在此不再赘述。
[0127]
此外,参见图3所示的一种电子设备的结构示意图,本实施例还提出一种电子设备,上述电子设备包括总线51、处理器52、收发机53、总线接口54、存储器55和用户接口56。上述电子设备包括有存储器55。
[0128]
本实施例中,上述电子设备还包括:存储在存储器55上并可在处理器52上运行的一个或者一个以上的程序,经配置以由上述处理器执行上述一个或者一个以上程序用于进行以下步骤(1)至步骤(5):
[0129]
(1)当获取到用户发出的语音信息时,对所述语音信息进行特征图提取,得到所述语音信息的特征图;
[0130]
(2)对所述语音信息进行傅里叶变换,得到傅里叶变换后的语音信息,并对傅里叶变换后的语音信息进行预处理,得到预处理后的语音信息;
[0131]
(3)计算所述预处理后的语音信息的音高,并将所述预处理后的语音信息的音高中属于{c,c#,d,d#,e,f,f#,g,g#,a,a#,b}音高集合的音高相加并进行归一化处理,得到所述语音信息的色度特征矩阵;
[0132]
(4)将所述语音信息的所述特征图和所述色度特征矩阵输入到深度全卷积网络算法模型中,得到不同情绪与情绪概率的对应关系;
[0133]
(5)将所述不同情绪与情绪概率的对应关系中最大的情绪概率对应的情绪,确定为所述用户的情绪。
[0134]
收发机53,用于在处理器52的控制下接收和发送数据。
[0135]
其中,总线架构(用总线51来代表),总线51可以包括任意数量的互联的总线和桥,总线51将包括由处理器52代表的一个或多个处理器和存储器55代表的存储器的各种电路链接在一起。总线51还可以将诸如外围设备、稳压器和功率管理电路等之类的各种其他电路链接在一起,这些都是本领域所公知的,因此,本实施例不再对其进行进一步描述。总线接口54在总线51和收发机53之间提供接口。收发机53可以是一个元件,也可以是多个元件,比如多个接收器和发送器,提供用于在传输介质上与各种其他装置通信的单元。例如:收发机53从其他设备接收外部数据。收发机53用于将处理器52处理后的数据发送给其他设备。取决于计算系统的性质,还可以提供用户接口56,例如小键盘、显示器、扬声器、麦克风、操纵杆。
[0136]
处理器52负责管理总线51和通常的处理,如前述上述运行通用操作系统。而存储器55可以被用于存储处理器52在执行操作时所使用的数据。
[0137]
可选的,处理器52可以是但不限于:中央处理器、单片机、微处理器或者可编程逻辑器件。
[0138]
可以理解,本发明实施例中的存储器55可以是易失性存储器或非易失性存储器,或可包括易失性和非易失性存储器两者。其中,非易失性存储器可以是只读存储器(read
‑
only memory,rom)、可编程只读存储器(programmable rom,prom)、可擦除可编程只读存储器(erasable prom,eprom)、电可擦除可编程只读存储器(electrically eprom,eeprom)或闪存。易失性存储器可以是随机存取存储器(random access memory,ram),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的ram可用,例如静态随机存取存储器(static ram,sram)、动态随机存取存储器(dynamic ram,dram)、同步动态随机存取存储器(synchronous dram,sdram)、双倍数据速率同步动态随机存取存储器(double data rate sdram,ddrsdram)、增强型同步动态随机存取存储器(enhanced sdram,esdram)、同步连接动态随机存取存储器(synchlink dram,sldram)和直接内存总线随机存取存储器(direct rambus ram,drram)。本实施例描述的系统和方法的存储器55旨在包括但不限于这些和任意其它适合类型的存储器。
[0139]
在一些实施方式中,存储器55存储了如下的元素,可执行模块或者数据结构,或者它们的子集,或者它们的扩展集:操作系统551和应用程序552。
[0140]
其中,操作系统551,包含各种系统程序,例如框架层、核心库层、驱动层等,用于实现各种基础业务以及处理基于硬件的任务。应用程序552,包含各种应用程序,例如媒体播放器(media player)、浏览器(browser)等,用于实现各种应用业务。实现本发明实施例方法的程序可以包含在应用程序552中。
[0141]
综上所述,本实施例提出一种计算机可读存储介质,通过对用户发送的语音信息的特征图进行提取后得到的语音信息,以及处理语音信息后得到的色度特征矩阵确定用户的情绪,与相关技术中只能向用户反馈无情绪的答复信息的方式相比,可以根据确定出的用户情绪,向用户反馈与其情绪向对应的答复信息,提高用户的体验。
[0142]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。