1.本发明涉及音频信号处理技术领域,更具体地,涉及一种乐器演奏或演唱测评方法及系统。
背景技术:
2.随着近年来音乐教育的日益普及,越来越多的人参与到乐器演奏或者演唱的活动中来。在乐器考级、比赛、音乐教育、唱歌娱乐等很多场景中人们十分需要对自己/他人的表演或者日常练习进行评测,包含演奏中是否出现错音、节奏是否稳定、音高是否准确,演奏力度是否符合乐谱要求等一系列指标来对演奏进行评价。这些评测工作通常由音乐教师、专家评委或者陪练老师来完成,存在以下弊端:1.音乐培训费用不菲;2.绝大多数情况下仅凭人耳和记忆力是无法准确发现或记录演奏中所有出现过的错音、节奏不准、音准偏差,力度等问题;3.评价较为主观,没有经过科学的数据量化,有时难以服众。
3.现有技术中,公开号为cn201710912292.x中国发明专利公开了一种智能钢琴演奏测评方法,包括:采集用户的midi音频数字信号转换成演奏数据;将用户演奏时间序列和大师演奏时间序列在时间轴上匹配;将用户演奏的音符组和大师演奏的音符组进行音准判定;将用户演奏的音符相对时值与大师演奏的音符相对时值进行节奏判定;计算用户演奏速度和大师演奏速度的相对速度进行速度判定;将用户演奏的音符力度与大师演奏的音符力度进行力度判定;将演奏音准、演奏节奏、演奏速度和演奏力度进行综合评估;将综合评估的结果在智能终端的五线谱上进行标识。该方案是针对电钢琴场景采用蓝牙或者接线的方式采集的是电钢琴的midi信号,无法使用于更多的传统主流乐器,同时没有实现乐谱跟随(对齐)和实时音高估计。
技术实现要素:
4.本发明为克服上述现有技术中乐器演奏或个人演唱测评依靠人工效率低、测评结果不客观、不准确的缺陷,提供一种乐器演奏或演唱测评方法及系统。
5.本发明的首要目的是为解决上述技术问题,本发明的技术方案如下:
6.本发明第一方面提供了一种乐器演奏或演唱测评方法,包括以下步骤:
7.获取演奏/演唱的音频信号的特征并进行音高估计;
8.检测演奏或演唱音频信号的起始点,从起始点开始将获取的音频信号和乐谱参考信号进行实时对齐,并将实时对齐结果以光标的方式实时指示在乐谱对应音符位置上;
9.判断测评是否结束,若测评结束,则获取演奏或演唱音频同时确定演奏或演唱在乐谱上的结尾点;
10.根据演奏或演唱在乐谱上的结尾点,将已录到的演奏或演唱音频与乐谱参考信号计算离线对齐路径;
11.根据离线对齐路径统计演奏或演唱中的节奏错误;
12.根据离线对齐路径比较演奏或演唱音频中音符的音高与乐谱参考信号的音高是
否一致,统计音符不一致的结果作为音准错误;
13.根据节奏错误和音准错误进行演奏或演唱打分。
14.进一步的,所述音频信号的特征为频域特征或通过神经网络将音频信号变换到未知的域上提取的特征。
15.进一步的,通过对齐算法将音频信号和乐谱参考信号进行实时对齐,所述对齐算法为基于贝叶斯概率模型的滤波方法,具体为:卡尔曼滤波、扩展卡尔曼滤波、无迹卡尔曼滤波、粒子滤波、动态时间规整算法。
16.进一步的,所述基于贝叶斯概率模型的滤波方法包括有贝叶斯概率模型,所述贝叶斯概率模型包括状态方程和观测方程,所述状态方程为:
17.z(t)=f(z(t
‑
1),w(t))
18.所述观测方程为:
19.x(t)=h(z(t),v(t))
20.其中,x为观测数据,z对应系统的状态空间,包含当前时刻所在乐谱的位置、演奏速度;f表示系统的状态转移函数,w(t)表示系统的过程噪声;h表示观测方程,v(t)表示观测方法的测量噪声。
21.进一步的,贝叶斯概率模型的求解即利用1到t时刻所有的观测值求t时刻系统对应的状态值,即求后验概率p(z
t
|x
1:t
);
22.具体求解过程为:
23.假设状态之间的关系服从观测独立假设和高阶马尔科夫假设,所述观测独立假设表示系统当前时刻的观测值只与系统当前时刻的系统状态有关,与其他状态和观测数据无关,通常称之为发射概率,即p(x
t
|z
1:t
,x
1:t
‑1)=p(x
t
|z
t
);
24.所述高阶马尔科夫假设是指系统当前的状态只与系统当前时刻之前的n个状态有关,与其他值无关;
25.根据观测独立假设和高阶马尔科夫假设每次新进来一个新的数据就可以利用上一时刻的计算结果进行递推计算,而不需要每次都重新计算整个联合分布的概率,从而达到实时场景的计算要求;
26.基于贝叶斯概率模型的滤波过程具体为:
27.系统初始化:p(x0)
28.预测步:p(z
t
‑1|x
1:t
‑1)
→
p(z
t
|x
1:t
‑1)
29.p(z
t
|x
1:t
‑1)=∫p(z
t
|x
t
‑1)p(z
t
‑1|x
1:t
‑1)dx
t
‑130.更新步:p(z
t
|x
1:t
‑1)
→
p(z
t
|x
1:t
)
[0031][0032]
其中:k
k
=∫p(z
t
|x
t
)p(z
t
|x
1:t
‑1)dx
t
[0033]
其中,p(x0)表示初始系统状态,x0为初始参数,预测步是利用当前系统状态值,通过状态方程对下一时刻的系统状态进行预测,使用的是t
‑
1时刻的更新值p(z
t
‑1|x
1:t
‑1)和状态转移概率p(z
t
|x
t
‑1);更新步骤是当获取下一时刻的观测数据后对预测步中预测的系统状态进行校正,使用的是预测步的预测值p(z
t
|x
1:t
‑1)和发射概率p(z
t
|x
t
);
[0034]
通过预测和更新的循环步骤,直到没有了新的观测数据后结束,其中每一步计算
过程仅依赖于上一步的结果和系统状态方程和观测方程,从而实现了实时滤波的过程。
[0035]
进一步的,当系统状态方程、观测方程以及噪声是线性高斯的情况下,预测步积分和更新步积分才有解析解,此时是卡尔曼滤波也是最优滤波;
[0036]
当系统状态方程、观测方程以及噪声是非线性高斯的时候,预测步积分和更新步积分没有解析解,此时只能通过近似的手段进行求解,获得次优解。
[0037]
进一步的,所述音高估计包括有:单音的音高高估计和多音的音高估计,其中单音的音高估计采用信号处理方法或训练概率模型参数的方法进行估计;所述多音的音高估计采用训练深度神经网络模型的方法进行估计。
[0038]
进一步的,多音的音高估计采用的深度神经网络模型为卷积神经网络模型,卷积神经网络模型的处理流程为:
[0039]
对演奏或演唱的音频信号进行分帧;
[0040]
根据预设的帧长和帧跳选取采样点并进行傅里叶变换和log
‑
mel谱压缩成待输入采样点;
[0041]
将待输入采样点转化为符合卷积神经网络输入要求的特征向量并输入卷积神经网络;
[0042]
卷积神经网络的sigmoid函数将输出结果压缩至0
‑
1之间的概率值,最终输出m维向量,m维向量分别对应乐器m个音高出现的概率,当某个音的概率超过一定阈值,则认为当前音频演奏了该音。
[0043]
进一步的,利用中断控制程序判断测评是否结束,中断控制程序判断条件为:当满足n秒内没有演奏或者演奏进行到参考信号的结尾处即为测评结束。
[0044]
本发明第二方面提供了一种乐器演奏或演唱测评系统,该系统包括:存储器,存储有计算机可执行指令;
[0045]
处理器,所述处理器运行所述存储器中的计算机可执行指令,执行以下步骤:
[0046]
获取演奏/演唱的音频信号的特征并进行音高估计;
[0047]
检测演奏或演唱音频信号的起始点,从起始点开始将获取的音频信号和乐谱参考信号进行实时对齐,并将实时对齐结果以光标的方式实时指示在乐谱对应音符位置上;
[0048]
判断测评是否结束,若测评结束,则获取演奏或演唱音频同时确定演奏或演唱在乐谱上的结尾点;
[0049]
根据演奏或演唱在乐谱上的结尾点,将已录到的演奏或演唱音频与乐谱参考信号计算离线对齐路径;
[0050]
根据离线对齐路径统计演奏或演唱中的节奏错误;
[0051]
根据离线对齐路径比较演奏或演唱音频中音符的音高与乐谱参考信号的音高是否一致,统计音符不一致的结果作为音准错误;
[0052]
根据节奏错误和音准错误进行演奏或演唱打分。
[0053]
与现有技术相比,本发明技术方案的有益效果是:
[0054]
本发明通过获取演奏或演唱的音频信号特征进行音高估计,同时利用对齐算法将音频信号和乐谱参考信号实时对齐,根据演奏/演唱的结尾点回溯两个信号的对齐路径,分别统计音准和节奏错误并打分,本发明实现了演奏或演唱的自动化测评打分,提高了测评的准确度和效率。
附图说明
[0055]
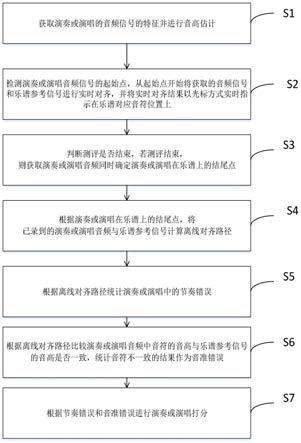
图1为本技术一种乐器演奏或演唱测评方法流程图。
[0056]
图2为本技术实施例演奏测评分数及综合结果展示图。
[0057]
图3为本技术实施例音准测评结果在乐谱上的展示图。
[0058]
图4为本技术实施例节奏测评结果在乐谱上的展示图。
具体实施方式
[0059]
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本技术的实施例及实施例中的特征可以相互组合。
[0060]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
[0061]
实施例1
[0062]
如图1所示,本发明第一方面提供了一种乐器演奏或演唱测评方法,包括以下步骤:
[0063]
s1:获取演奏或演唱的音频信号的特征并进行音高估计;
[0064]
需要说明的是,演奏的音频信号可以通过外部收音装置获取或者通过连接乐器的数字接口获取,演唱的音频可以通过麦克风获取。本发明中演奏或演唱的音频信号优选的采用麦克风获取,通过麦克风获取音频信号对于用户更加方便,无需电钢琴键盘/钢琴条等传感器以蓝牙/连线的方式来传输midi信号。在一个具体的实施例中测评的启动可以包括有多种方式,如演奏特定的音符来启动测评,也可以直接点击预设的按钮启动测评。
[0065]
进一步的,所述音频信号的特征为频域特征或通过神经网络将音频信号变换到未知的域上提取的特征。
[0066]
需要说明的是,所述音频信号的特征为频域特征时,其提取过程是将该时域信号通过分帧和加窗的操作后逐帧进行傅里叶变换,得到该音频信号的时频谱x(f,k),由x(f,k)继续生成各类特征信号,包含且不限于log
‑
mel谱,cqt等特征;所述音频信号的特征为通过神经网络将音频信号变换到未知的域上提取的特征时,所述的神经网络可以是卷积神经网络也可以是循环神经网络,可以是单层也可以多层,层数可根据实际应用场景来选定。
[0067]
s2:检测演奏或演唱音频信号的起始点,从起始点开始将获取的音频信号和乐谱参考信号进行实时对齐,并将实时对齐结果以光标方式实时指示在乐谱对应音符位置上,通过光标实时指示能够实现音符级的乐谱跟随效果;
[0068]
需要说明的是,音频信号和乐谱参考信号对齐,首先检演奏/演唱音频的起始点,从起始点开始计算音频帧和乐谱帧,利用对齐算法对齐,两路信号对齐的结果可以以光标的形式实时的输出并显示到终端设备的乐谱上,也就是说可用光标实时指出当前演奏在乐谱上对应的实际位置,所述终端设备可以为手机或平板电脑等。
[0069]
根据本发明实施例,通过对齐算法将音频信号和乐谱参考信号进行实时对齐,所述对齐算法为基于贝叶斯概率模型的滤波方法,具体包括:卡尔曼滤波、扩展卡尔曼滤波、无迹卡尔曼滤波、粒子滤波、动态时间规整算法。
[0070]
需要说明的是,从最小粒度层面,如果如果从状态角度看待帧到帧的规划过程,动态时间规整(dtw)也属于贝叶斯概率模型框架下的特例。
[0071]
根据本发明实施例,所述基于贝叶斯概率模型的滤波方法包括有贝叶斯概率模型,所述贝叶斯概率模型包括状态方程和观测方程,所述状态方程为:
[0072]
z(t)=f(z(t
‑
1),w(t))
[0073]
所述观测方程为:
[0074]
x(t)=h(z(t),v(t))
[0075]
其中,x为观测数据,z对应系统的状态空间,包含当前时刻所在乐谱的位置、演奏速度;f表示系统的状态转移函数,w(t)表示系统的过程噪声;h表示观测方程,v(t)表示观测方法(比如传感器)的测量噪声。
[0076]
贝叶斯概率模型的求解即利用1到t时刻所有的观测值求t时刻系统对应的状态值,即求后验概率p(z
t
|x
1:t
);
[0077]
具体求解过程为:
[0078]
假设状态之间的关系服从观测独立假设和高阶马尔科夫假设,所述观测独立假设表示系统当前时刻的观测值只与系统当前时刻的系统状态有关,与其他状态和观测数据无关,通常称之为发射概率,即p(x
t
|z
1:t
,x
1:t
‑1)=p(x
t
|z
t
);
[0079]
所述高阶马尔科夫假设是指系统当前的状态只与系统当前时刻之前的n个状态有关,与其他值无关;以一阶为例,当前时刻的系统状态只与上一时刻有关,p(z
t
|z
1:t
‑1,x
1:t
‑1)=p(z
t
|z
t
‑1),称之为状态转移概率。
[0080]
根据观测独立假设和高阶马尔科夫假设每次新进来一个新的数据就可以利用上一时刻的计算结果进行递推计算,而不需要每次都重新计算整个联合分布的概率,从而达到实时场景的计算要求;
[0081]
基于贝叶斯概率模型的滤波过程具体为:
[0082]
系统初始化:p(x0)
[0083]
预测步:p(z
t
‑1|x
1:t
‑1)
→
p(z
t
|x
1:t
‑1)
[0084]
p(z
t
|x
1:t
‑1)=∫p(z
t
|x
t
‑1)p(z
t
‑1|x
1:t
‑1)dx
t
‑1[0085]
更新步:p(z
t
|x
1:t
‑1)
→
p(z
t
|x
1:t
)
[0086][0087]
其中:k
k
=∫p(z
t
|x
t
)p(z
t
|x
1:t
‑1)dx
t
[0088]
其中,p(x0)表示初始系统状态,x0为初始参数,预测步是利用当前系统状态值,通过状态方程对下一时刻的系统状态进行预测,使用的是t
‑
1时刻的更新值p(z
t
‑1|x
1:t
‑1)和状态转移概率p(z
t
|x
t
‑1);更新步骤是当获取下一时刻的观测数据后对预测步中预测的系统状态进行校正,使用的是预测步的预测值p(z
t
|x
1:t
‑1)和发射概率p(z
t
|x
t
);
[0089]
通过预测和更新的循环步骤,直到没有了新的观测数据后结束,其中每一步计算过程仅依赖于上一步的结果和系统状态方程和观测方程,从而实现了实时滤波的过程。
[0090]
需要说明的是,当系统状态方程、观测方程以及噪声是线性高斯的情况下,预测步积分和更新步积分才有解析解,此时是卡尔曼滤波也是最优滤波;
[0091]
当系统状态方程、观测方程以及噪声是非线性高斯的时候,预测步积分和更新步
积分没有解析解,此时只能通过近似的手段进行求解,获得次优解。例如扩展卡尔曼滤波(ekf),原理是将非线性的的观测方程和状态方程用泰勒公式展开,得到一阶线性化的结果,这个过程抛弃了高阶项,得到的是近似解。同理无迹卡尔曼滤波(ukf)亦是一种次优的近似解。在很多实际应用中,系统都是非线性非高斯的,此时只能通过蒙特卡洛(monte carlo)采样的方法来近似求取一个连续的概率分布均值,这一类方法称为粒子滤波,它得到的也是次优解。类似近似求解概率密度的方法有很多,比如直方图滤波等。
[0092]
需要说明的是,本发明并不仅限于上述基于贝叶斯概率模型的滤波方法,凡是基于贝叶斯模型求解预测步和更新步两个积分的滤波方法均在本发明的保护范围内。
[0093]
s3:判断测评是否结束,若测评结束,则获取演奏或演唱音频同时确定演奏或演唱在乐谱上的结尾点;
[0094]
进一步的,利用中断控制程序判断测评是否结束,中断控制程序判断条件为:当满足n秒内没有演奏或者演奏进行到参考信号的结尾处即为测评结束。在一个具体的实施例中,n的取值可以为8。
[0095]
s4:根据演奏或演唱在乐谱上的结尾点,将已录到的演奏或演唱音频与乐谱参考信号计算离线对齐路径;
[0096]
s5:根据离线对齐路径统计演奏或演唱中的节奏错误;
[0097]
s6:根据离线对齐路径比较演奏或演唱音频中音符的音高与乐谱参考信号的音高是否一致,统计音符不一致的结果作为音准错误;
[0098]
需要说明的,所述音高估计用于判断用户是否正确地演奏了当前音符,所述音高估计包括有:单音的音高高估计和多音的音高估计,其中单音(例如弦乐等单音较多的乐器)的音高估计采用信号处理方法或训练概率模型参数的方法进行估计;所述多音(例如钢琴、古筝等经常存在多个音符同时演奏的乐器)的音高估计采用训练深度神经网络模型的方法进行估计。
[0099]
在一个具体的实施例中采用卷积神经网络模型对多音音高进行估计的处理流程为:
[0100]
对演奏或演唱的音频信号进行分帧;其中分帧加窗的帧长控制在50ms以内,太长会引入时延,窗函数可以选择汉明窗,海宁窗等,以降低分帧过程中频谱泄露。
[0101]
根据预设的帧长和帧跳选取采样点并进行傅里叶变换和log
‑
mel谱压缩成待输入采样点;
[0102]
在一个具体的实施例中,选取帧长为2048个采样点,帧跳为441个采样点,傅里叶变换和log
‑
mel谱压缩成成229个采样点,考虑到算法的实时性,采用7帧信号为卷积神经网络的模型输入,即输入为7*229*1维度的特征向量。
[0103]
将待输入采样点转化为符合卷积神经网络输入要求的特征向量并输入卷积神经网络;
[0104]
卷积神经网络的sigmoid函数将输出结果压缩至0
‑
1之间的概率值,最终输出m维向量,m维向量分别对应乐器m个音高出现的概率,当某个音的概率超过一定阈值,则认为当前音频演奏了该音。
[0105]
更具体的,将输入经过3x3的卷积核,最大池化后将数据摊平,最后通过全连接dense层,用sigmoid函数将输出结果压缩至0
‑
1之间的概率值,最终输出88维向量,分别对
应钢琴88个音高出现的概率,当某个音的概率超过一定阈值,则认为当前音频演奏了该音。
[0106]
s7:根据节奏错误和音准错误进行演奏或演唱打分。
[0107]
需要说明的,演奏或演唱打分数据包括:评价总分、错音数、错节奏数、以及速度等指标,如图2所示为本技术实施例演奏测评分数及综合结果展示图;更具体的,如图3所示为音准测评结果在乐谱上的展示图,当在演奏的过程中出现错音时,会在乐谱相应的音符出加以标记。比如红色表示演奏错,黄色表示没有演奏该音符等。如图4所示节奏测评结果在乐谱上的展示图,当演奏过程中出现抢拍或者滞后等节奏不稳定的情况,会在乐谱中相应的音符上显示节奏错误。比如红色表示实际演奏音符超前于该音符正常该出现的时刻,绿色表示实际演奏滞后于该音符正常出现的时刻等。
[0108]
本发明第二方面提供了一种乐器演奏或演唱测评系统,该系统包括:存储器,存储有计算机可执行指令;
[0109]
处理器,所述处理器运行所述存储器中的计算机可执行指令,执行以下步骤:
[0110]
获取演奏/演唱的音频信号的特征并进行音高估计;
[0111]
检测演奏或演唱音频信号的起始点,从起始点开始将获取的音频信号和乐谱参考信号进行实时对齐,并将实时对齐结果以光标的方式实时指示在乐谱对应音符位置上;
[0112]
判断测评是否结束,若测评结束,则获取演奏或演唱音频同时确定演奏或演唱在乐谱上的结尾点;
[0113]
根据演奏或演唱在乐谱上的结尾点,将已录到的演奏或演唱音频与乐谱参考信号计算离线对齐路径;
[0114]
根据离线对齐路径统计演奏或演唱中的节奏错误;
[0115]
根据离线对齐路径比较演奏或演唱音频中音符的音高与乐谱参考信号的音高是否一致,统计音符不一致的结果作为音准错误;
[0116]
根据节奏错误和音准错误进行演奏或演唱打分。
[0117]
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。