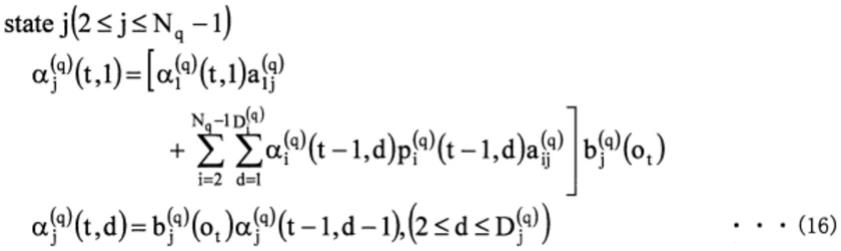
语音合成模型学习装置、语音合成模型学习方法及存储介质
1.本技术是于2015年9月16日提交的申请号为201580082427.3、名称为“语音合成装置、语音合成方法、语音合成程序、语音合成模型学习装置、语音合成模型学习方法以及语音合成模型学习程序”的专利申请的分案申请。
技术领域
2.本发明的实施方式涉及语音合成装置、语音合成方法、语音合成程序、语音合成模型学习装置、语音合成模型学习方法以及语音合成模型学习程序。
背景技术:
3.已知将任意文本变换成合成波形的语音合成技术。另外,根据对语音波形的数据库进行分析而得到的特征参数来学习统计模型的语音合成模型学习装置和在语音合成中使用所学习的统计模型的语音合成装置已众所周知。
4.现有技术文献
5.专利文献1:日本特开2002
‑
268660号公报
6.非专利文献1:h.zen,et al,“a hidden semi
‑
markov model
‑
based speech synthesis system”,ieice trans.inf.syst.,vol.e90
‑
d,no.5may 2007,p.825
‑
834
技术实现要素:
7.发明要解决的技术问题
8.以往,在使用了基于固定帧速率的语音分析而得到的音响特征参数的情况下,存在未进行精密的语音分析而会产生音质劣化这一问题。另外,在通过基音同步分析进行了语音分析的情况下,存在因学习时与合成时的基音的不一致的影响等而成为不自然的音素持续长度这一问题。本发明要解决的技术问题是,提供能够防止语音劣化和不自然的音素持续长度的语音合成装置、语音合成方法、语音合成程序、语音合成模型学习装置、语音合成模型学习方法以及语音合成模型学习程序。
9.用于解决问题的技术方案
10.实施方式的语音合成装置具有存储部、制作部、决定部、生成部以及波形生成部。存储部将具有多个状态的统计模型的各状态下的、包含基音特征参数的音响特征参数的输出分布以及基于时刻参数的持续长度分布作为统计模型信息进行存储。制作部根据与输入文本对应的上下文信息、以及统计模型信息,制作统计模型序列。决定部使用基于统计模型序列的各统计模型的各状态的持续长度分布而得到的持续时间长度、以及基于基音特征参数的输出分布而得到的基音信息,决定各状态的基音波形数。生成部基于基音波形数来生成音响特征参数的输出分布列,基于该输出分布列来生成音响特征参数。波形生成部根据生成部所生成的音响特征参数来生成语音波形。
附图说明
11.图1是表示实施方式的语音合成装置的框图。
12.图2是例示hsmm的图。
13.图3是表示hmm存储部所存储的hmm的图。
14.图4是表示实施方式的语音合成模型学习装置的框图。
15.图5是表示基于固定帧速率的分析与基音同步分析的差异的图。
16.图6是表示hmm学习部进行的处理的流程图。
17.图7是表示实施方式的语音合成装置生成参数的处理例的图。
18.图8是表示波形生成部进行的处理的图。
19.图9是表示状态占有概率的计算方法的图。
20.图10是表示实施方式的语音合成装置执行的处理的流程图。
21.图11是表示实施方式的语音合成模型学习装置执行的处理的流程图。
22.图12是表示实施方式的语音合成模型学习装置的变形例的框图。
23.图13是表示实施方式的语音合成装置的变形例的框图。
24.图14是表示选择部执行的处理的流程图。
25.图15是表示选择部的具体的构成例的图。
具体实施方式
26.首先,对完成本发明的背景进行说明。对于语音合成模型学习装置,具有为了使时间序列信号模型化而学习具有多个状态的统计模型即隐马尔科夫模型(hmm:hidden markov model)的装置。另外,对于语音合成装置,具有基于学习后的hmm来合成语音的装置。
27.在基于hmm的语音合成中,按照所输入的文本来求出分布列,根据所得到的分布列来生成特征参数,由此合成语音。例如,能够使用语音的谱信息、音响特征参数(acoustic characteristic parameter)以及韵律特征参数,根据一并使用了静态特征参数以及表示时间变化的动态特征参数而得到的特征参数列来学习模型,应用使静态以及动态特征参数的似然度最大化的参数生成算法,生成基于顺滑的特征参数序列的语音。音响特征参数表示声源信息。韵律特征参数表示语音的韵律信息即基音信息。
28.进而,通过应用hmm的说话人自适应技术、说话人插值技术等,也能够制作基于少量数据的新说话人模型和/或说话人插值模型、能够进行程度控制的感情模型等,扩展合成语音的多样性。
29.在hmm语音合成中,通常利用了使用梅尔倒谱(mel cepstrum)分析方法和/或基于straight分析的谱包络(spectrum envelope)提取方法的方法。这些方法中,在进行谱分析时,进行例如基于5ms左右的固定帧速率的语音分析,对特征参数进行分析。
30.在使用梅尔倒谱分析的情况下,不考虑帧的中心点与波形的周期性之间的对应,切取包含多个周期的比较宽的窗宽度的帧来进行参数分析。由此,进行了分析并再合成后的语音相对于原来的语音波形会产生失真,会发生音质劣化。
31.straight分析也同样地,进行基于固定帧速率的语音分析。在straight分析中,通过时间方向平滑化以及频率方向平滑化的处理,在对分析窗的中心与周期性的对应进行修
正的同时进行谱分析。由此,虽然可减低音质劣化,但破裂音和/或在无声摩擦音与有声音的边界等非稳定部位的音质劣化等、因固定帧速率分析而引起的音质劣化依然会发生。
32.另外,作为基于hmm的语音合成的扩展,存在将基于统计模型的语音合成和基于语音片段选择的语音合成进行组合而得到的混合型语音合成方法、选择特征参数的语音合成方法、以及利用了神经网络的语音合成方法等。但是,在这些方法中,在使用利用了梅尔倒谱分析的语音分析方法或利用了straight的语音分析方法的情况下,也同样地会产生会成为机器音质的问题。
33.在使用了基于固定帧速率的语音分析方法的情况下,作为特征参数的个数的帧数与持续时间长度成为线性的关系,因此能够将帧数作为持续长度分布来进行利用。即,能够将hmm的各状态的帧数直接作为持续长度分布的参数,进行学习了隐半马尔可夫模型(hsmm)的参数之后的语音合成。
34.hsmm是基于输出分布和状态持续长度分布的概率模型,是在hmm的似然计算中不使用固定的自转移概率而使用状态持续长度分布来进行似然计算的模型。该情况下,持续长度模型通过以统计的方式使各语音数据与各状态相关联的状态占有概率和与状态序列中的各状态关联的特征参数的帧数,学习持续长度分布的参数。由于时间长度通过对帧数乘以帧速率来求出,因此在使用固定帧速率的语音分析的情况下,仅根据与特征参数对应的上下文(cotext),就能够学习与时间长度具有线性关系的持续长度分布。
35.在参数生成时,追溯决策树而得到的持续长度分布直接成为帧数的分布,因此能够根据持续长度分布参数来求出帧数,按照所得到的各状态的帧数来生成分布列,进行参数生成以及波形生成处理。如此,在使用了基于固定帧速率的语音分析的情况下,虽然会发生音质劣化,但能够将特征参数的帧数作为持续长度分布进行模型化,并根据持续长度分布的参数直接确定语音合成时的帧数。
36.另一方面,作为语音的分析方法之一,也可以使用基音同步分析。在基音同步分析中,不基于固定的帧速率,而按与语音波形的各基音周期对应的间隔进行特征参数的分析。例如,制作表示语音的周期性波形的各周期的中心时刻的基音标记信息,根据基音标记位置来确定分析中心,适用依存于基音的窗宽度的窗函数来切取基音波形,对所切取出的基音波形进行分析来求出音响特征参数。
37.在此,通过将适当赋予的基音标记位置作为分析中心时刻来进行分析,能够实现与语音波形的局部变化也对应的适当分析,因此能够增加与分析合成语音的原音之间的一致性,可减低音质劣化。但是,该情况下,由于各帧的间隔并不一定,因此帧的个数即基音波形数与时刻的信息不会是线性关系,会成为在基音高的部位较多帧数而在基音低的部位较少帧数的分析。
38.如此,在使用了基音同步分析的情况下,若将语音帧的个数作为持续长度分布的参数而用于模型学习以及合成,则会产生因学习时的基音与合成时的基音的不一致的影响而成为不自然长度的合成语音的问题。由于持续长度模型与音拍(mora)和/或音素的相关性高,因此希望通过不将随着基音变化的基音同步分析的基音波形数的分布而将基于基音开始时刻与结束时刻之差的时刻参数的时间长度作为参数的方法等,使与时刻具有线性关系的参数模型化。
39.接着,参照附图对语音合成装置的实施方式进行说明。图1是表示语音合成装置的
实施方式(语音合成装置100)的框图。如图1所示,语音合成装置100具备解析部101、制作部102、决定部103、生成部104、波形生成部105以及hmm存储部106。
40.解析部101对输入文本进行词素分析,求出读音信息以及重音(accent,语调)信息等的语音合成所需的语言信息,根据所得到的语言信息来制作上下文信息。解析部101也可以接收另行制作出的与输入文本对应的已修正的读音信息以及重音信息等,制作上下文信息。
41.在此,所谓上下文信息是指音素、半音素、音节hmm等作为对语音进行分类的单位而使用的信息。在作为语音单位而使用音素的情况下,能够使用音素名的序列来作为上下文信息。进而,也可以包含如下信息来作为上下文信息:附加有先行音素、后续音素的三音子(triphone)、前后各包含2个音素的音素信息;表示基于有声音/无声音的分类、详细化后的音素类别的属性的音素类别信息;各音素在文内、换气段落内、重音句内的位置,重音句的音拍数、重音型,音拍位置,到重音核为止的位置、有无句尾升调的信息;所附加的记号信息等语言属性信息。
42.制作部102按照从解析部101输入的上下文信息,使用hmm存储部106所存储的hmm(后面使用图3来叙述),制作与输入文本对应的hmm序列。hmm是通过状态转移概率和各状态的输出分布来表示的统计模型。具体而言,制作部102根据与输入文本对应的上下文信息、以及后述的统计模型信息,制作统计模型序列。
43.对于hmm,在为从左到右(left
‑
to
‑
right)型hmm的情况下,如图2所示,通过各状态的输出分布n(o|μ
i
,σ
i
)和状态转移概率a
ij
(i、j为状态索引)进行模型化,以仅是向相邻状态的转移概率以及自转移概率具有值的形式进行模型化。在此,对于取代自转移概率a
ij
而使用持续长度分布n(d|μ
id
,σ
id
),也被称为hsmm(隐半马尔可夫模型),在持续长度的模型化中使用。以下,将hsmm也包含在内而记载为hmm。
44.决定部103基于制作部102所制作出的hmm序列,使用根据持续长度分布参数以及基音特征参数的输出分布而生成的基音参数来决定基音波形数。也就是说,决定部103使用基于制作部102所制作出的统计模型序列的各统计模型的各状态的持续长度分布而得到的持续时间长度、以及基于基音特征参数的输出分布而得到的基音信息,决定各状态的基音波形数。
45.生成部104按照决定部103所决定的基音波形数来制作分布列,根据分布列来生成音响特征参数。具体而言,生成部104基于基音波形数,生成音响特征参数的分布列,基于所生成的分布列来生成音响特征参数。
46.波形生成部105根据生成部104所生成的音响特征参数的序列来生成语音波形。
47.hmm存储部106存储有根据基于基音同步分析的音响特征参数而学习后的hmm。具体而言,hmm存储部106存储有对hmm的各状态的输出分布进行了决策树聚类(clustering)的模型。存储有用于根据hmm的各状态下的包含基音特征参数的音响特征参数的输出分布以及基于时刻参数的持续长度分布、和上下文信息来选择各状态的分布的决策树来作为统计模型信息。
48.图3是表示hmm存储部106所存储的hmm的图。如图3所示,hmm存储部106存储有例如hmm的各状态的特征参数的模型即决策树以及决策树的各叶节点的输出分布,还存储有持续长度分布用的决策树以及分布。
49.在决策树的各节点,关联有对分布进行分类的问题。例如,对于节点,关联有“是否为无声”、“是否为有声音”、“是否为重音核”这样的问题,分类成对该问题进行肯定回答时的子节点和对该问题未进行肯定回答时的子节点。也就是说,在决策树中,针对所输入的上下文信息,通过判断是否对各节点的问题进行肯定回答来进行搜索,获得叶节点。
50.也就是说,上述的制作部102通过将与所获得的叶节点关联的分布作为各状态的输出分布来使用,构建与各语音单位对应的hmm。并且,制作部102制作与所输入的上下文信息对应的hmm序列。
51.接着,对语音合成模型学习装置的实施方式进行说明。图4是表示语音合成模型学习装置的实施方式(语音合成模型学习装置200)的框图。如图4所示,语音合成模型学习装置200具有声音语料库存储部201、分析部203、特征参数存储部204、hmm学习部205以及hmm存储部106。此外,语音合成模型学习装置200所具有的hmm存储部106,对应于使用图1在上面所述的hmm存储部106。也就是说,如图4所示,hmm存储部106所存储的hmm是语音合成模型学习装置200进行使用了基音标记的基音同步分析而制作出的。
52.语音语料库存储部201存储有在模型学习中使用的语音波形(语音数据)、与各语音波形对应的上下文信息及基音标记信息。语音波形包括从说话人的收录语音中按各文切取出的数据。上下文信息根据各收录语音的说话内容来制作。
53.对于基音标记信息,针对有声音的周期性的区间,通过从语音数据中提取基音、并提取与周期对应的时刻来制作。另外,对于基音标记信息,针对无声音和/或破裂音、无声等的非周期波形的区间,通过以对有声音区间的周期波形的基音顺滑地进行插值的方式确定时刻、和/或在非周期区间按固定的帧速率确定时刻等,由此对文整体设定表示分析中心位置的时刻信息。也就是说,基音标记信息也包含非周期区间的分析时刻。如此,作为各语音波形的分析中心时刻的信息的、在周期波形区间中与基音周期对应的分析中心时刻即基音标记信息,被制作在语音语料库中。
54.分析部203根据语音波形来求出音响特征参数。音响特征参数是表示语音的谱包络的谱参数以及表示声源信息的声源参数、表示基本频率的信息的基音参数等的特征参数,从语音波形中提取。也就是说,分析部203根据语音数据来分析基音标记信息的各基音标记时刻的音响特征参数。
55.作为谱参数,能够利用梅尔倒谱、梅尔lsp、线性预测系数等谱包络参数。作为声源参数,可使用表示各谱频带的非周期成分的比例的频带噪声强度(bap:band aperiodicity)、相位信息或者群延迟信息等。
56.由此,分析部203能够适当地求出与各基音标记时刻对应的音响特征参数。图5是表示有声音的周期波形区间中的基于固定帧速率的分析与基音同步分析的差异的图。
57.图5的(a)表示基于固定帧速率的语音分析。在基于固定帧速率的语音分析中,在帧的中心时刻与波形的周期性之间没有关联,根据预先确定的间隔来进行特征分析。
58.例如,在基于固定帧速率的语音分析中,广泛使用通过25ms左右的窗函数切取出包含多个周期波形的范围的分析,但由于在语音波形的峰值位置与帧位置之间没有关联而会导致产生失真。由于该影响,基于固定帧速率的语音分析,会存在即使在稳定的语音区间中也会成为不稳定的谱包络的情况。另外,在变化剧烈的部位,因宽的窗宽度等的影响而成为被过量地进行了平滑化的分析结果,也会产生无法适当地再现发生变化的波形的问题。
59.与此相对,在基于基音同步分析的特征提取中,如图5的(b)所示,使用在语音波形的各周期的峰值时刻附近设定基音标记的方法等,例如在与基音周期相应的时刻赋予基音标记,将基音标记时刻作为分析中心,使用2个基音程度的窗宽度的汉宁窗(hanning window)等来切取波形的方法。
60.如此,在基音同步分析中,能够在适当的时刻以依存于基音的窗宽度来进行分析,根据分析出的特征参数而合成的分析合成语音,可获得与原来的语音近似的波形。
61.另外,为了减低固定帧速率分析的音质劣化,在straight分析中,通过时间方向的平滑化来进行分析时刻的位置的不定性的修正,进一步通过频率方向的平滑化来提取顺滑的谱包络。另外,即使在将通过基音同步分析而得到的参数插值到固定帧速率位置来进行分析的情况下,相比于直接使用基于基音同步分析的参数的情况,也会产生劣化,在再合成的语音波形与原来的语音波形之间会产生失真。
62.作为音响特征参数,在使用梅尔lsp、bap的情况下,对按各基音标记切取出的语音适用梅尔lsp分析来求出梅尔lsp,根据各时刻的左右的基音标记的间隔的信息等来求出基音信息并变换成对数f0,通过频带噪声强度的分析来求出bap。在频带噪声强度的分析中,例如基于pshf(pitch scaled harmonic filter,基音级谐波滤波器)方式,将语音分离成周期成分和非周期成分,求出各时刻的非周期成分比率,按预先确定的各频带进行平均化等,由此能够求出bap。
63.进而,在使用相位特征参数的情况下,将与基音同步地切取出的各基音波形的相位信息表示为参数,即使是难以进行包含多个周期的波形和/或根据中心位置而切取出的波形的形状不稳定的形状的固定帧速率的分析的相位信息,也能够通过使用基音同步分析来作为特征参数进行处理。
64.基音信息和持续长度信息是表示韵律信息的特征参数,同样地从语音语料库的各语音波形中提取。基音信息是表示各声韵的抑扬和/或高度的变化的信息。持续长度是表示音素等语音单位的长度的特征参数。作为基音特征参数,可以利用对数基本频率、基本频率、基音周期信息。作为持续长度信息,可以使用音素持续长度等。
65.在基音同步分析中,根据各基音标记时刻的左右的间隔来确定各时刻的基音,并变换成对数基本频率。基音信息是仅是有声音具有值的参数,但也可以在无声音的部分嵌入所插值的基音而设为特征参数、和/或使用表示是无声音这一情况的值。
66.对于各音素的持续长度的信息,作为音素边界时刻的信息而附加于上下文信息中,在hmm的学习时的初始模型的学习中被使用。但是,对于基于hsmm的持续长度分布的参数,由于可根据hmm的各状态与学习数据的关联而通过最大似然估计来求出,因此有时并不预先准备音素时刻来作为特征参数。如此,分析部203求出各基音标记时刻的音响特征参数,制作在hmm的学习中使用的特征参数。另外,分析部203也会求出特征参数的斜率的信息即动态特征量(图中的δ参数以及δ2参数等)并进行附加。并且,可构成图5的(b)所示那样的音响特征参数。
67.特征参数存储部204(图4)将分析部203求出的音响特征参数与其上下文信息和/或时间边界信息等一起进行存储。
68.hmm学习部205将特征参数存储部204所存储的特征参数作为hmm的学习数据来使用。hmm学习部205进行同时推定持续长度分布的参数的隐半马尔可夫模型的学习来作为
hmm的学习。也就是说,hmm学习部205在隐半马尔可夫模型的学习中,除了上下文信息以及音响特征参数之外,还为了使用基音同步分析而输入各语音数据的基音标记信息,实现基于时刻信息的持续长度分布的学习。也就是说,hmm学习部205根据分析部203分析出的音响特征参数,学习将包含基音特征参数的音响特征参数的输出分布以及基于时刻参数的持续时间长度分布包括在内的具有多个状态的统计模型。
69.图6是表示hmm学习部205进行的处理的流程图。hmm学习部205首先进行音素hmm的初始化(s101),通过hsmm的学习来进行音素hmm的最大似然估计(s102),学习作为初始模型的音素hmm。hmm学习部205在进行最大似然估计的情况下,通过连结学习来使hmm与文相对应,一边根据连结后的文整体的hmm和与文对应的音响特征参数来进行各状态与特征参数的概率性的关联,一边进行学习。
70.接着,hmm学习部205使用音素hmm对上下文依存hmm进行初始化(s103)。针对存在于学习数据中的上下文,如上所述,可使用该音素、前后的音素环境、文内/重音句内等的位置信息、重音型、是否句尾升调这样的声韵环境以及语言信息,准备以该音素进行了初始化的模型。
71.然后,hmm学习部205对上下文依存hmm适用基于连结学习的最大似然估计来进行学习(s104),适用基于决策树的状态聚类(s105)。如此,hmm学习部205针对hmm的各状态、各流以及状态持续长度分布,构建决策树。
72.更具体而言,hmm学习部205根据每个状态、每个流的分布,通过最大似然基准和/或mdl(minimum description length,最小描述长度)基准等来学习对模型进行分类的规则,构成图3所示的决策树。如此,hmm学习部205在语音合成时,即使在被输入了不存在于学习数据中的未知的上下文的情况下,也可通过追溯决策树来选择各状态的分布,能够构建对应的hmm。
73.最后,hmm学习部205对进行了聚类的模型进行最大似然估计,完成模型学习(s106)。
74.hmm学习部205在进行聚类时,通过按各特征量的每个流来构建决策树,由此构成谱信息(梅尔lsp)、声源信息(bap)、基音信息(对数基本频率)的各流的决策树。另外,hmm学习部205通过针对排列每个状态的持续长度而得到的多维分布来构建决策树,由此构建hmm单位的持续长度分布决策树。此外,hmm学习部205在各最大似然估计步骤中,在进行模型的更新时,除了上下文信息以及音响特征量之外还参照基音标记时刻信息来学习状态持续长度分布。
75.另外,hmm学习部205在使用与各音响特征量对应的时刻信息来学习持续长度分布时,不根据与各状态关联的帧数而根据与各状态关联的帧的开始点的时刻以及结束点的时刻,求出基于时刻参数的时间长度。并且,hmm学习部205能够根据所求出的时间长度来求出持续长度分布,如基音同步分析这样,即使使用按非线性的间隔进行了特征分析的参数来进行学习,也能够学习适当的持续长度分布。
76.此外,在使用了基音标记时刻的hsmm中,进行基于使用了后述的算法的连结学习而实现的最大似然估计。并且,hmm存储部106存储hmm学习部205所制作出的hmm。
77.也就是说,在语音合成装置100中,制作部102根据输入上下文和hmm存储部106所存储的hmm来制作hmm序列,决定部103决定各hmm的各状态的基音波形数。并且,语音合成装
置100按照所决定的基音波形数使各状态的分布进行反复来制作分布列,生成部104根据考虑了静态、动态特征量的参数生成算法来生成各参数。
78.图7是表示语音合成装置100生成参数的处理例的图。在图7中,例示了语音合成装置100用3个状态的hmm来合成“赤
い”
的语音的情况。
79.首先,制作部102选择输入上下文的hmm的各状态、各流的分布以及持续长度分布,构成hmm的序列。在作为上下文而使用了“先行音素_该音素_后续音素_音素位置_音素数_音拍位置_音拍数_重音型”的情况下,“赤
い”
是3音拍2型,最初的“a”的音素是先行音素“sil”、该音素为“a”、后续音素为“k”、音素位置为1、音素数为4、音拍位置为1、音拍数为3、重音型为2型,因此成为“sil_a_k_1_4_1_3_2”这样的上下文。
80.在追溯hmm的决策树的情况下,对各中间节点设定了该音素是否为a、重音型是否为2型这样的问题,通过追溯问题来选择叶节点的分布,在hmm的各状态选择梅尔lsp、bap、logf0的各流的分布以及持续长度分布,构成hmm序列。并且,决定部103通过下式(1)来决定基音波形的帧数。
[0081][0082]
在此,由于将logf0设为基音信息的分布,因此对根据模型q、状态i的对数基本频率流的静态特征量的平均值μ
lf0qi
而求出的基本频率exp(μ
lf0qi
),乘以模型q、状态i的状态持续长度分布的平均值μ
durqi
,适用基于小数舍去或四舍五入等的整数化函数int(),确定基音波形数。
[0083]
由于使用基音标记时刻的时间信息而求出的μ
durqi
为持续长度分布,因此在求出帧数的情况下需要基音信息。由于现有的方法是将帧数直接表示为持续长度分布,因此如下式(2)这样,可简单地通过进行整数化来加以确定。
[0084][0085]
如上所述,当在特征参数分析时以固定的帧速率进行分析、且与时刻具有线性关系的情况下,能够用上式(2)的形式来求出帧数。但是,在通过基音同步分析等以可变的帧速率进行了语音分析的情况下,需要将时刻用作持续长度分布的参数,需要通过上式(1)的形式来确定波形数。
[0086]
此外,在此,作为基音信息的特征参数而使用了对数基本频率,但在使用基本频率的情况下不需要exp()函数。另外,在使用基音周期来作为参数的情况下,如下式(3)这样,将会通过除法运算来进行求出。
[0087][0088]
生成部104通过利用如此确定出的基音波形数使hmm的各状态的分布进行反复来制作分布列,根据使用了静态、动态特征量的参数生成算法来生成参数序列。在使用δ和δ2来作为动态特征参数的情况下,可通过以下的方法来求出输出参数。对于时刻t的特征参数o
t
,使用静态特征参数c
t
和根据前后的帧的特征参数确定的动态特征参数δc
t
,δ2c
t
,表示为o
t
=(c
t’,δc
t’,δ2c
t’)。对于包含使p(o|j,λ)最大化的静态特征量ct的向量c=(c0’
,
…
,c
t
‑1’
)’,可通过将0
tm
作为t
×
m次的零向量并求解作为下式(4)而提供的方程式来求出。
[0089][0090]
其中,t为帧数,j为状态转移序列。若将特征参数o与静态特征参数c的关系通过计算动态特征的矩阵w来建立关系,则可表示为o=wc。o为3tm的向量,c为tm的向量,w为3tm
×
tm的矩阵。并且,在将μ=(μ
s00’,
…
,μ
sj
‑
1q
‑1’
)’、σ=diag(σ
s00’,
…
,σ
sj
‑
1q
‑1’
)’作为将各时刻的输出分布的平均向量、对角协方差全部排列而得到的文所对应的分布的平均向量以及协方差矩阵时,对于上式(4),能够通过求解作为下式(5)而提供的方程式来求出最佳的特征参数序列c。
[0091]
w
′
σ
‑1wc=w'∑
‑1u...(5)
[0092]
该方程式通过基于乔里斯基分解(cholesky decomposition)的方法来求解。另外,与在rls滤波器的时间更新算法中使用的解法同样地,既能够随着延迟时间而按时间顺序生成参数序列,也能够实现低延迟地进行生成。此外,参数生成部的处理并不限于本方法,也可以使用对平均向量进行插值的方法等其他根据分布列生成特征参数的任意方法。
[0093]
波形生成部105根据如此生成的参数序列来生成语音波形。例如,波形生成部105根据对数基本频率序列以及频带噪声强度序列来制作声源信号,适用基于梅尔lsp序列的声道滤波器来生成语音波形。
[0094]
图8是表示波形生成部105进行的处理的图。如图8所示,波形生成部105根据对数基本频率序列来生成基音标记,按照频带噪声强度(bap)序列,控制噪声成分与脉冲成分的比率并生成声源波形,适用基于梅尔lsp序列的声道滤波器来生成语音波形。另外,波形生成部105在也使用相位参数来进行模型化的情况下,根据相位参数来生成相位谱,根据谱参数来生成振幅谱,利用逆fft来生成与各基音标记对应的基音波形,通过重叠处理来进行波形生成。另外,波形生成部105也可以根据相位参数来生成声源波形,通过适用滤波器的方法来进行波形生成。
[0095]
通过上述的处理,能够使用基于基音同步分析的特征参数来构建hmm模型,并将该hmm模型利用于语音合成。另外,通过这些处理,可获得与输入上下文对应的合成语音。
[0096]
接着,对hmm学习部205进行的最大似然估计处理中的模型更新算法的详细情况进行说明。本算法是将现有的隐半马尔可夫模型学习算法以根据各特征参数的时刻信息来学习持续长度分布的方式进行扩展而导出的算法。在现有方法中,通过隐半马尔可夫模型,将在hmm的各状态滞留了几帧作为与自转移概率有关的持续长度分布来使用。与此相对,hmm学习部205不以帧数而以各帧的基音标记时刻的间隔作为单位来学习持续长度分布。由此,持续长度分布不依存于基音而成为直接表示音素以及各状态的持续时间的长度的分布,可消除在语音合成时因基音的不一致的影响而成为不自然的持续长度的问题。
[0097]
在hmm中,针对模型λ、状态转移序列q={q0,q1,
…
,q
t
‑1}、从状态i向状态j的状态转移概率a
ij
、状态i的输出分布b
i
(o
t
),观测向量序列o={o0,o1,
…
,o
t
‑1}的似然度p(o|λ)通过下式(6)而表示为所有的状态转移序列的总和。
[0098][0099]
hmm如上式(6)这样不将状态转移全部表示为状态转移概率,而在隐半马尔可夫模型hsmm中,将自转移概率表示为持续长度分布。
[0100][0101]
在此,pi(t,d)表示从时刻t到时刻t+d为止在状态i滞留d帧的概率,a
qt+dqt+d+1
表示在时刻t+d向不同的状态q
t+d+1
转移的概率。
[0102][0103]
在现有方法中,作为该时刻t而使用了观测向量的帧编号,将会对全部的状态转移序列计算在相同状态持续了d帧的情况下的概率和之后进行状态转移的概率。在使用了这样的针对hsmm的forward
‑
backward算法的输出分布参数、状态转移概率、状态持续长度分布参数的更新算法中,能够通过最大似然估计来求出模型参数。
[0104]
在hmm学习部205的基音同步分析用的hsmm中,状态持续长度p
i
(t,d)不将帧数而将时刻的信息表示为参数。并且,hmm学习部205根据与各帧对应的基音标记的时刻信息,在将各帧的基音标记时刻设为pm(t)时,从时刻t到时刻t+d的状态持续长度成为d(t,d)=pm(t+d)
‑
pm(t
‑
1),使用该基音标记时刻的间隔来作为持续长度分布的参数。
[0105][0106]
在基音同步分析的情况下,将基音标记位置作为帧的中心进行波形的分析,但在此时将帧数表示为状态持续长度分布的情况下,基音越高,则基音标记的间隔越窄,成为越多的帧数。该情况下,基音越低,则基音标记的间隔越宽,因此成为越少的帧数,成为不仅依存于时间长度还依存于基音的状态持续长度的分布。
[0107]
与此相对,hmm学习部205不依靠基音而直接对各状态的时间长度进行模型化,因此能够使各音素的长度不依存于基音而进行模型化。在进行了固定帧速率的分析的情况下,无论使用时刻信息和帧数的哪个都会成为线性关系,因此不受影响。hmm学习部205即使在帧的间隔不一定的情况下,也能够适当地计算持续长度模型。
[0108]
接着,对hmm学习部205进行最大似然估计的情况下的用于模型的连结学习的基于向前向后(forward
‑
backward)算法的更新算法进行说明。首先,通过以下式(10)~(17)来计算向前概率。向前概率α
(q)j
(t,d)是在持续了d帧之后在时刻t位于模型q、状态j的概率。首先,在时刻(t=1),通过下式(10)~(13)进行初始化。
[0109][0110][0111]
[0112][0113]
然后,通过下式(14)~(17)的递归计算,求出(2≦t≦t)的帧的向前概率α
(q)j
(t,d)。
[0114][0115][0116][0117][0118]
对于向后概率β
(q)i
(t,d),同样地,是在时刻t在状态i滞留d帧、然后在时刻t之前输出观测向量的概率,通过式(18)~(25)来计算。首先,在时刻(t=t),通过下式(18)~(21)进行初始化。
[0119][0120][0121][0122][0123]
然后,通过下式(22)~(25)的递归(t
‑
1≧t≧1)的步骤,计算β
(q)i
(t,d)。
[0124][0125][0126][0127][0128]
若使用上述各式和混合高斯分布,则在时刻t在模型q的状态j、混合m、流s滞留的概率,通过下式(26)~(28)来求出。
[0129][0130][0131][0132]
另外,在时刻t在模型q的状态j滞留的概率,通过下式(29)来求出。
[0133][0134]
上式(28)或上式(29)与以往的连结学习不同,如图9所示,成为将跨状态的转移也考虑在内的、在时刻t经过模型q的状态j的所有的状态转移序列的总和。
[0135]
另外,从时刻t0到时刻t1为止在模型q的状态j、流s滞留的概率,通过下式(30)来表示。
[0136][0137]
使用如此导出的状态转移概率、向前概率、向后概率,进行模型参数的更新,进行输出分布的参数、持续长度模型、转移概率的最大似然估计。
[0138]
持续长度分布参数的更新式通过下式(31)、(32)来表示。
[0139][0140][0141]
另外,输出分布的混合权重、平均向量以及协方差矩阵通过下式(33)~(35)来更新。
[0142][0143][0144][0145]
使用这些式(10)~(35),hmm学习部205进行模型参数的最大似然估计。
[0146]
接着,对语音合成装置100执行的语音合成的处理进行说明。图10是表示语音合成装置100执行的语音合成的处理的流程图。如图10所示,首先,解析部101对输入文本进行解析来求出上下文信息(s201)。制作部102参照hmm存储部106所存储的hmm来制作与输入上下
文对应的hmm序列(s202)。
[0147]
决定部103使用hmm序列的持续长度分布以及基音信息来决定各状态的基音波形数(s203)。生成部104按照所获得的各状态的基音波形数将输出分布进行排列来制作分布列,适用参数生成算法等并根据分布列来生成在语音合成中使用的参数序列(s204)。然后,波形生成部105生成语音波形,获得合成语音(s205)。
[0148]
此外,语音合成装置100所具有的各功能既可以通过硬件来构成,也可以通过cpu所执行的软件来构成。例如,语音合成装置100在执行语音合成程序来进行语音合成的情况下,由cpu执行图10所示的各步骤。
[0149]
接着,对语音合成模型学习装置200执行的语音合成模型学习的处理进行说明。图11是表示语音合成模型学习装置200执行的语音合成模型学习的处理的流程图。如图11所示,首先,分析部203使用语音语料库存储部201所存储的语音数据、基音标记信息,通过基音同步分析来提取基于谱参数、基音参数、声源参数的音响特征参数(s301)。特征参数存储部204存储所提取出的音响特征参数。
[0150]
接着,hmm学习部205使用音响特征参数、上下文信息以及基音标记信息来学习hmm(s302)。hmm包含基于时刻参数的持续长度分布以及基音信息的输出分布。学习得到的hmm被存储于hmm存储部106,并在语音合成中使用。
[0151]
此外,语音合成模型学习装置200所具有的各功能既可以通过硬件来构成,也可以通过cpu所执行的软件来构成。例如,语音合成模型学习装置200在执行语音合成模型学习程序来进行语音合成模型学习的情况下,由cpu执行图11所示的各步骤。
[0152]
另外,针对hmm学习部205,以使用特定说话人的语料库对说话人依存模型进行最大似然估计的情况为例进行了说明,但并不限定于此。例如,hmm学习部205也可以使用作为hmm语音合成的多样性提高技术而使用的说话人自适应技术、模型插值技术、其他聚类自适应学习等不同的结构。另外,也可以使用利用了深度神经网络的分布参数推定等不同的学习方式。即,hmm学习部205不通过基于固定帧速率的语音分析将帧数设为持续长度分布的参数,而能够使用通过基音同步分析等将时刻信息设为持续长度分布的参数的任意方式进行了学习后的模型来学习语音合成模型。
[0153]
接着,对语音合成模型学习装置200的变形例进行说明。图12是表示语音合成模型学习装置200的变形例(语音合成模型学习装置200a)的框图。如图12所示,语音合成模型学习装置200a具有声音语料库存储部201、分析部203、特征参数存储部204、说话人自适应部301、平均声hmm存储部302以及hmm存储部106,进行从平均声进行的说话人自适应,学习语音合成模型。此外,对与上述的构成部分实质上相同的部分,标注同一标号。
[0154]
说话人自适应部301使用特征参数存储部204所存储的特征参数,对平均声hmm存储部302所存储的平均声模型适用说话人自适应技术,使所获得的自适应hmm存储于hmm存储部106。
[0155]
平均声hmm是从多个说话人进行了学习后的平均声的模型,是具有平均声的特征的模型。说话人自适应部301通过将该平均声使用目标说话人的特征参数进行变换来获得自适应hmm。另外,说话人自适应部301通过使用最大似然线性回归等说话人自适应方法,即使在目标说话人数据存在少量且不足的上下文的情况下,也能够制作为了使平均声hmm的模型接近目标说话人而补充了不足上下文的模型。
[0156]
在最大似然线性回归中,通过多元回归分析对平均向量进行变换。例如,说话人自适应部301使用上式(10)~(35)所示的基于时刻参数的连结学习来进行学习数据与平均声hmm的关联,求出回归矩阵。并且,通过由多个分布共用回归矩阵,对于不存在对应的学习数据的分布的平均向量,也能够进行变换。由此,相比于仅使用少量的目标数据进行了学习后的模型,能够合成高品质的语音,能够根据使用基于基音同步分析的音响特征参数进行了说话人自适应后的模型来进行语音合成。
[0157]
接着,对语音合成装置100的变形例进行说明。图13是表示语音合成装置100的变形例(语音合成装置100a)的框图。如图13所示,语音合成装置100a具有解析部101、制作部102、决定部103、生成部104、波形生成部105、hmm存储部106、特征参数存储部204以及选择部401,进行基于特征参数序列选择的语音合成。此外,对与上述的构成部分实质上相同的部分,标注同一标号。
[0158]
语音合成装置100a中,在制作部102与决定部103之间,选择部401进行处理。具体而言,语音合成装置100a将在制作部102中得到的hmm序列作为目标,由选择部401从特征参数存储部204所存储的音响特征参数中选择参数,根据所选择的参数来合成语音波形。也就是说,选择部401基于统计模型,从音响特征参数候选中选择包含与各状态对应的持续长度参数以及基音信息的音响特征参数。如此,通过选择部401从音响特征参数中选择参数,能够抑制因hmm语音合成的过量平滑化而引起的音质劣化,可获得更接近实际发音的自然的合成语音。
[0159]
在使用了基于基音同步分析的特征参数的情况下,根据分析参数而再次生成的语音,与使用了利用固定帧速率进行了分析的以往的特征参数的情况相比,成为更接近原音的音质。因此,对于语音合成装置100a,使用了基音同步分析的效果更为显著,与使用以往的特征参数的情况相比,自然性得到改善。
[0160]
接着,对选择部401进一步进行详细说明。选择部401基于hmm来选择特征参数序列。对于特征参数选择的单位,能够利用任意的单位来进行,但在此按hmm序列的各状态来选择特征参数。
[0161]
设为:在特征参数存储部204中,存储有声音波形的各特征参数、以及附加有与状态对应的边界的信息。例如,对于hmm的各状态与语音波形的关联,预先通过维特比排列(viterbi alignment)来求出,将所获得的最大似然状态转移序列的时间边界作为状态的边界存储于特征参数存储部204。选择部401在对特征参数的选择使用目标似然以及连接似然的情况下,将hmm序列的状态作为单位,通过动态规划法来选择最佳特征参数序列。
[0162]
图14是表示选择部401执行的处理的流程图。首先,选择部401选择要合成的文章的最初的hmm的初始状态下的候选特征参数(s401),计算与初始的各候选对应的目标似然度(s402)。
[0163]
目标似然度是将与相应的区间内的目标相符合的程度进行了数值化的似然度,能够根据hmm序列的分布的似然度来求出。在使用对数似然度的情况下,作为各状态区间内的特征参数的对数似然度的和来计算。特征参数的候选是选择源的特征参数的集合,能够将在学习相应的hmm的状态下的决策树的叶节点的分布时所使用的学习数据作为候选。也可以通过将与相同状态对应的相同音素的特征参数作为候选的方法、将用声韵环境进行了筛选后的相同音素作为候选的方法、通过韵律属性的一致程度来决定候选的方法等其他方法
来决定。
[0164]
然后,选择部401使状态编号前进一个,选择与各状态对应的候选(s403),进行目标似然度以及连接似然度等的似然度计算(s404)。
[0165]
此外,在hmm的最终状态的情况下,进入到后续的hmm的初始状态。对于s403的候选选择的处理,能够与s401的处理同样地进行。连接似然度是将相应区间符合作为先行区间的后续的程度进行了数值化的似然度。对于连接似然度,能够通过高斯分布的似然度来计算,所述高斯分布的似然度是针对先行状态区间的各候选片段,使用相应状态下的各候选片段被选时的似然度,使用作为平均向量的前一个状态的各候选片段的后续区间的平均向量,使用作为方差的各状态的输出分布的方差而得到的。
[0166]
然后,选择部401为了进行回溯(back track),针对各候选片段而保存有前一个状态的最佳候选的信息。选择部401判定当前的状态是否为与输入文章对应的hmm序列的最终hmm的最终状态(s405)。选择部401如果判定为是最终状态(s405:是),则进入s406的处理。另外,选择部401如果判定为不是最终状态(s405:否),则使状态以及hmm前进一个而返回到s403的处理。
[0167]
最后,选择部401选择成为似然度最大的特征参数,依次回溯其先行状态的最佳候选,由此求出最佳特征参数序列(s406)。选择部401将如此选择出的最佳特征参数序列向决定部103输出。
[0168]
图15是表示选择部401的具体的构成例的图。选择部401例如具备候选选择部411、似然度计算部412以及回溯部413。候选选择部411从特征参数存储部204中选择候选。似然度计算部412计算目标似然度、连接似然度。选择部401将hmm序列的状态作为单位,候选选择部411以及似然计算部412反复进行处理,最后,回溯部413求出最佳特征参数序列。
[0169]
此外,在此以似然度最大化序列为例,但也可以使用基于hmm序列来选择特征参数序列的任意方法。也可以定义通过似然度的倒数、与平均向量的均方误差、和/或马氏距离(mahalanobis'distance)等而计算的成本函数,通过成本最小化来进行特征参数的选择。另外,也可以不进行基于动态规划法的特征参数选择,而仅根据音响的似然和韵律的似然度来计算成本并进行特征参数的选择。
[0170]
进而,也可以根据hmm序列来生成特征参数,根据从所生成的参数起的距离进行成本计算来进行特征参数的选择。在进行参数选择的情况下,也可以不仅是最佳参数序列,而在各区间选择多个参数序列并利用平均化后的参数。选择部401通过这些处理,能够针对所输入的hmm序列的各hmm的各状态,选择最佳特征参数,将这些信息向决定部103输出。
[0171]
决定部103根据所选择出的持续长度分布序列以及基音特征参数的序列来决定基音波形数。生成部104使用所选择出的特征参数来更新分布。通过使用hmm序列的方差并用所选择出的特征参数替换分布的平均向量来更新分布,根据更新后的分布列来生成参数,由此能够进行对所选择出的特征参数进行了反映的参数生成。波形生成部105根据所生成的参数来生成合成语音。如此,语音合成装置100a通过具备选择部401,能够根据在各区间所选择出的音响特征量来进行波形生成,可获得自然的合成语音。
[0172]
此外,对于语音合成装置100、语音合成装置100a、语音合成模型学习装置200以及语音合成模型学习装置200a,例如也可以通过将通用的计算机装置用作基本硬件来实现。即,本实施方式的语音合成装置以及语音合成模型学习装置,可以通过使上述的计算机装
置所搭载的处理器执行程序来实现。
[0173]
由语音合成装置100、语音合成装置100a、语音合成模型学习装置200以及语音合成模型学习装置200a执行的程序(语音合成程序或者语音合成模型学习程序),可预先安装于rom等来提供。
[0174]
另外,由语音合成装置100、语音合成装置100a、语音合成模型学习装置200以及语音合成模型学习装置200a执行的程序,也可以构成为以可安装形式或可执行形式的文件记录在cd
‑
rom(compact disk read only memory)、cd
‑
r(compact disk recordable)、dvd(digital versatile disk)等计算机可读取的记录介质中而作为计算机程序产品来提供。进而,也可以构成为将这些程序保存在与互联网等网络连接的计算机上并通过经由网络进行下载来提供。
[0175]
如此,根据实施方式的语音合成装置,使用基于统计模型序列的各统计模型的各状态的持续长度分布而得到的持续时间长度以及基于基音特征参数的输出分布而得到的基音信息,决定各状态的基音波形数,基于所决定的基音波形数,生成音响特征参数的分布列,基于所生成的分布列来生成音响特征参数,因此能够防止语音劣化和不自然的音素持续长度。另外,实施方式的语音合成装置能够在使用基于基音同步分析的精密的音响特征参数的同时,对作为持续长度分布而根据基音标记算出的时间长度进行模型化,在合成时基于根据相应状态的持续长度分布参数以及基音特征参数的输出分布而生成的基音信息算出基音波形数并进行语音合成。由此,实施方式的语音合成装置能够在利用精密的语音分析的同时消除因学习时与合成时的基音的不一致的影响而引起的不自然的持续长度的问题,能够进行高品质的语音合成。
[0176]
另外,通过多个组合对本发明的几个实施方式进行了说明,但是这些实施方式是作为例子提出的,并非旨在限定发明的范围。这些新的实施方式能够以其他各种方式来实施,在不偏离发明宗旨的范围内,可以进行各种省略、替换、变更。这些实施方式及其变形包含在发明的范围、宗旨中,并且包含在权利要求书所记载的发明和其等同的范围内。