1.本发明涉及语音识别技术领域,具体涉及一种基于大屏语音唤醒识别降噪混合系统及方法。
背景技术:
2.随着语音识别技术的高速发展,使用语音识别交互的产品越来越多,但是有很多产品语音控制交互功能单一,唤醒识别不能在复杂的场景下进行使用,因此急需带有唤醒识别降噪混合功能的系统,解决复杂场景下的大屏或多屏设备语音交互和语音通话。
技术实现要素:
3.针对现有技术中的缺陷,本发明提供一种基于大屏语音唤醒识别降噪混合系统,包括以下内容:
4.麦克风:所述麦克风用于获取音频信号;
5.前端分析模块:所述前端分析模块用于对获取的音频信号进行分析处理;
6.唤醒音频库:用于存储预置音频信号;
7.比对模块:用于将获取的音频信号与预置音频信号进行比对;
8.后端处理模块:用于录入预置音频信号、设置音频识别幅度值和相似度阈值,并向受控上位机输送控制信号;
9.阈值判断模块:用于判断音频信号与预置音频信号的相似度值是否达到相似度阈值;
10.上位机:用于接收控制信号,并按控制信号完成动作。
11.优选的,所述前端分析模块还包括滤波模块、唤醒识别模块、降噪模块、除杂模块,所述滤波模块用于对音频信号进行多路音频除杂滤波处理,所述唤醒识别模块用于对编码滤波处理后的音频信号进行声学分析,所述降噪模块用于对音频信号进行人声分离处理,所述除杂模块用于对音频信号进行祛混响、祛噪点处理。
12.优选的,还包括特征提取模块、agc调幅模块,所述特征提取模块用于对唤醒识别模块进行声学分析后的音频信号进行特征数据段提取,所述agc调幅模块用于对人声分离处理后的音频信号进行agc自动增益调幅。
13.优选的,还包括显示模块,所述显示模块用于接收后端处理模块传输的数据,并转换为可视信号。
14.一种基于大屏语音唤醒识别降噪混合方法,包含一种基于大屏语音唤醒识别降噪混合系统,包括以下步骤:
15.s1:通过后端处理模块设置音频识别幅度值、相似度阈值,并在唤醒音频库中录入预置音频信号;
16.s2:麦克风获取语音音频信号;
17.s3:前端分析模块对获取的音频信号进行降噪处理后,比对模块根据预存唤醒音
频库中的预置音频信号对音频信号进行匹配分析,匹配完成后再对音频信号进行缺失值填补,最后判断音频信号是否能进行唤醒动作,若是,则进入步骤s5,若否,则进入步骤s4;
18.s4:音频信号损坏,后端处理模块通过扬声器发送损坏反馈信号;
19.s5:后端处理模块向上位机输出控制信号。
20.优选的,所述步骤s3中的前端分析模块对获取的预置音频信号进行降噪处理还包括以下内容:
21.s31:将获取的语音信号传输给滤波模块,滤波模块进行对音频信号进行多路音频除杂滤波处理;
22.s32:将除杂滤波处理后的音频信号送入唤醒识别模块,唤醒识别模块对编码滤波处理后的音频信号进行声学分析,再根据唤醒音频库中的预置音频信号对音频信号进行初步特征提取,得到初筛音频信号;
23.s33:降噪模块对初筛音频信号进行人声分离处理,根据人声信号能量大小,对音频信号的幅度进行agc自动增益调幅;
24.s34:除杂模块进一步对agc自动增益调幅后的音频信号进行祛混响、祛噪点处理。
25.优选的,所述步骤s3中匹配完成后再对音频信号进行缺失值填补,最后判断音频信号是否能进行唤醒动作,还包括以下内容:
26.s35:比对模块将音频信号与唤醒数据库中的预置音频信号进行比对,判断是否存在相似的音频信号,若是,则进入步骤s36,若否,则进入步骤s4;
27.s36:阈值判断模块判断音频信号与唤醒数据库中的预置音频信号相似度是否超出相似度阈值若是,则进入步骤s5,若否,则进入步骤s37;
28.s37:判断音频信号是否进行过缺失值填补,若是,则进入步骤s36,若否,则进入步骤s39;
29.s38:判断音频信号缺失值填补次数是否小于或等于三次,若是,则进入步骤s39,若否,则进入步骤s4;
30.s39:对音频信号进行缺失值填补,并进入s37。
31.优选的,所述步骤s5中,填补模块对有损音频信号进行缺失值填补时可采用均值插补、利用同类均值插补、极大似然估计、多重插补中的一个或多个缺失值填补方法。
32.本发明的有益效果体现在:
33.该发明通过设置的前端分析模块、比对模块,能够在背景音嘈杂的环境下对接收到的音频信号进行除噪、除杂处理,且筛选出音频信号段部分缺失的音频信号,并根据自身唤醒数据库的预置数据进行智能填补,提高装置的智能化程度,增大系统的响应效率,减少重复确认的步骤,提升系统容错性。
附图说明
34.为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍。在所有附图中,类似的元件或部分一般由类似的附图标记标识。附图中,各元件或部分并不一定按照实际的比例绘制。
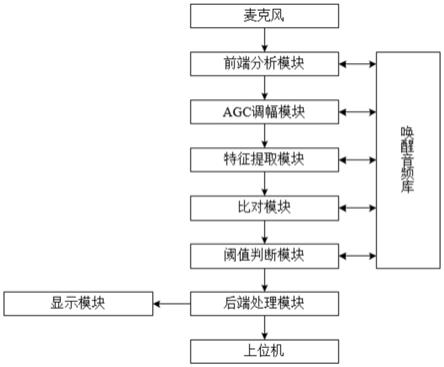
35.图1为一种基于大屏语音唤醒识别降噪混合系统的原理图;
36.图2为一种基于大屏语音唤醒识别降噪混合系统的前端分析模块的原理图;
37.图3为一种基于大屏语音唤醒识别降噪混合方法的流程图。
具体实施方式
38.下面将结合附图对本发明技术方案的实施例进行详细的描述。以下实施例仅用于更加清楚地说明本发明的技术方案,因此只作为示例,而不能以此来限制本发明的保护范围。
39.需要注意的是,除非另有说明,本技术使用的技术术语或者科学术语应当为本发明所属领域技术人员所理解的通常意义。
40.如图1所示,一种基于大屏语音唤醒识别降噪混合系统,包括以下内容:
41.麦克风:所述麦克风用于获取音频信号;
42.前端分析模块:所述前端分析模块用于对获取的音频信号进行分析处理;
43.唤醒音频库:用于存储预置音频信号;
44.比对模块:用于将获取的音频信号与预置音频信号进行比对;
45.后端处理模块:用于录入预置音频信号、设置音频识别幅度值和相似度阈值,并向受控上位机输送控制信号;
46.阈值判断模块:用于判断音频信号与预置音频信号的相似度值是否达到相似度阈值;
47.上位机:用于接收控制信号,并按控制信号完成动作。
48.麦克风接收到外部环境中的音频信号后,传输到前端分析模块中进行分析处理,分析后的音频信号传输至比对模块中,比对模块将音频信号与唤醒音频库中预置的音频信号进行处理,唤醒音频中预置的音频信号可经由后端处理模块进行录入,后端处理模块还可对唤醒音频库中预置的音频信号进行删改,若音频信号经由比对模块比对后,找出相似的一个或多个预置音频信号,再通过阈值判断模块,比较音频信号与一个或多个预置音频信号的相似度是否超过阈值,若音频信号与唤醒音频库中的一个或多个预置音频信号相似度值达到或超出预设的相似度阈值,则后端处理模块将该音频信号传输至上位机处,此时上位机接收音频信号后被唤醒,可进行上位机自身带有的识别控制功能,若上位机处还包含有调用通话、摄像功能,则上位机可向后端处理模块再反馈信号,后端处理模块接收上位机的反馈信号后,仍然开启前端分析模块,关闭比对模块,从麦克风处接收的音频信号只经由前端分析模块进行分析处理,而不经由比对模块进行比对,分析处理后直接经由后端处理模块传输至上位机处,达到与上位机进行通话的效果。
49.如图2所示,具体的,所述前端分析模块还包括滤波模块、唤醒识别模块、降噪模块、除杂模块,所述滤波模块用于对音频信号进行多路音频除杂滤波处理,所述唤醒识别模块用于对编码滤波处理后的音频信号进行声学分析,所述降噪模块用于对音频信号进行人声分离处理,所述除杂模块用于对音频信号进行祛混响、祛噪点处理。
50.前端分析模块中滤波模块、唤醒识别模块、降噪模块、除杂模块依次对麦克风处接收到的音频信号进行处理,达到对音频信号进行逐步优化的目的,使得后续对音频进行比对时,比对结果更为准确,若缺少了滤波模块、唤醒识别模块、降噪模块、除杂模块中的任意一项,则比对模块的比对结果准确性均会大幅下降。
51.如图1所示,具体的,还包括特征提取模块、agc调幅模块,所述特征提取模块用于
对唤醒识别模块进行声学分析后的音频信号进行特征数据段提取,所述agc调幅模块用于对人声分离处理后的音频信号进行agc自动增益调幅。
52.agc调幅模块对人声分离处理后的音频信号进行调幅时,需根据后端处理模块预先设置的音频识别幅度值进行调节,使音频信号的幅值与唤醒音频库中预置音频信号的幅值相同,便于特征数据段提取时能提取到较多的数据,避免存在遗漏。
53.如图1所示,具体的,还包括显示模块,所述显示模块用于接收后端处理模块传输的数据,并转换为可视信号。
54.若比对模块比对后,音频信号与唤醒音频库中预置的音频信号相似度值不能达到预设的相似度阈值,则说明该音频信号有误,不能达到语音唤醒的目的,后端处理模块此时向显示模块传输反馈数据,并由显示模块产生可视化图像或文字,提醒使用者重新输入音频信号。
55.如图3所示,一种基于大屏语音唤醒识别降噪混合方法,包含一种基于大屏语音唤醒识别降噪混合系统,包括以下步骤:
56.s1:通过后端处理模块设置音频识别幅度值、相似度阈值,并在唤醒音频库中录入预置音频信号;
57.s2:麦克风获取语音音频信号;
58.s3:前端分析模块对获取的音频信号进行降噪处理后,比对模块根据预存唤醒音频库中的预置音频信号对音频信号进行匹配分析,匹配完成后再对音频信号进行缺失值填补,最后判断音频信号是否能进行唤醒动作,若是,则进入步骤s5,若否,则进入步骤s4;
59.s4:音频信号损坏,后端处理模块通过扬声器发送损坏反馈信号;
60.s5:后端处理模块向上位机输出控制信号。
61.具体的,所述步骤s3中的前端分析模块对获取的预置音频信号进行降噪处理还包括以下内容:
62.s31:将获取的语音信号传输给滤波模块,滤波模块进行对音频信号进行多路音频除杂滤波处理;
63.s32:将除杂滤波处理后的音频信号送入唤醒识别模块,唤醒识别模块对编码滤波处理后的音频信号进行声学分析,再根据唤醒音频库中的预置音频信号对音频信号进行初步特征提取,得到初筛音频信号;
64.s33:降噪模块对初筛音频信号进行人声分离处理,根据人声信号能量大小,对音频信号的幅度进行agc自动增益调幅;
65.s34:除杂模块进一步对agc自动增益调幅后的音频信号进行祛混响、祛噪点处理。
66.步骤s32中与预置音频信号进行初步特征提取时,是将一段音频中,与唤醒数据库中预置音频信号相似度为0的音频段进行删除,以减少音频段基数,提高后续比对模块的工作效率。
67.具体的,所述步骤s3中匹配完成后再对音频信号进行缺失值填补,最后判断音频信号是否能进行唤醒动作,还包括以下内容:
68.s35:比对模块将音频信号与唤醒数据库中的预置音频信号进行比对,判断是否存在相似的音频信号,若是,则进入步骤s36,若否,则进入步骤s4;
69.s36:阈值判断模块判断音频信号与唤醒数据库中的预置音频信号相似度是否超
出相似度阈值若是,则进入步骤s5,若否,则进入步骤s37;
70.s37:判断音频信号是否进行过缺失值填补,若是,则进入步骤s36,若否,则进入步骤s39;
71.s38:判断音频信号缺失值填补次数是否小于或等于三次,若是,则进入步骤s39,若否,则进入步骤s4;
72.s39:对音频信号进行缺失值填补,并进入s37。
73.比对模块进行比对时,可将音频信号的音频段长度与预置音频信号的音频段长度进行比对,从而提高后续阈值判断模块的工作效率。
74.具体的,所述步骤s5中,填补模块对有损音频信号进行缺失值填补时可采用均值插补、利用同类均值插补、极大似然估计、多重插补中的一个或多个缺失值填补方法。
75.最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。