1.本发明涉及自动播报技术领域,尤其是涉及一种广播节目智能播报系统及方法。
背景技术:
2.目前广播电台的广播节目可分为互动类节目(如情感咨询、观点讨论等)和非互动类节目(如新闻资讯、天气预报等)。对于广播电台的非互动类节目来说,传统播报方式通常需要主持人根据文稿内容在直播间进行播报。采用该播报方式,主持人需要实时根据文稿上下文内容准确识别出字词句的关系,并做出正确的发音,因而该播报方式对主持人的语言控制能力具有较高的要求。采用该播报方式,主持人在播报文稿内容时还需要对调音台不断进行操作以控制背景音乐的播放与文稿内容的播报相协调,因而该播报方式对主持人的协调操作能力也具有较高的要求。另外,采用上述播报方式,考虑到遇到突发事件时需要主持人及时到达直播间进行播报的情况,经常还需要数名专业主持人轮岗进行播报,进一步增加了人力成本的投入。
技术实现要素:
3.有鉴于此,本发明的目的在于提供一种广播节目智能播报系统及方法,以在保证播报内容发音准确的同时自动调节背景音乐的效果,在一定程度上替代真实的主持人进行非互动类广播节目的播报,进而缓解传统播报方式对主持人要求高、人力成本高的问题。
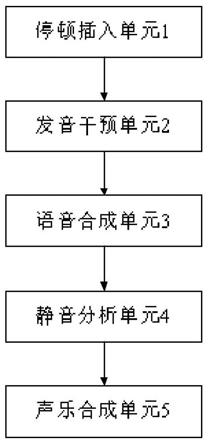
4.第一方面,本发明实施例提供了一种广播节目智能播报系统,包括:依次连接的停顿插入单元、发音干预单元、语音合成单元、静音分析单元和声乐合成单元;所述停顿插入单元,用于根据待处理文稿的内容确定所述待处理文稿中的目标位置,并为目标位置插入第一停顿,得到第一文稿;其中,所述目标位置为所述待处理文稿中换行符所在位置;所述发音干预单元,用于基于预存的标注有第二标签的参考信息和所述参考信息对应的标注所述第二标签的记录信息为所述第一文稿标注标签,得到标注有所述第二标签的第二文稿;基于预存的所述第二标签与第一标签之间的关联映射关系将所述第二文稿对应的所述第二标签转化成所述第一标签,得到标注有所述第一标签的第三文稿;其中,所述第一标签为tts服务商所提供的语音合成标记语言的标签;所述第二标签为通俗语言的标签;所述语音合成单元,用于根据所述第三文稿的内容和所述第三文稿对应的所述第一标签进行语音合成,得到所述第三文稿对应的第一语音;所述静音分析单元,用于对所述第一语音进行静音分析,并获取所述第一语音中相邻段落之间的部分对应的第一时间信息;所述声乐合成单元,用于根据所述第一时间信息对所述第一语音和初始背景音乐进行声乐合成,得到第一音频。
5.在一种实施方式中,所述发音干预单元包括标签标注单元、发音纠正数据库和发音字典映射表;所述标签标注单元用于:基于所述发音纠正数据库为所述第一文稿中的指定内容标注所述第二标签,得到所述第二文稿;其中,所述发音纠正数据库预存有所述参考信息和所述参考信息对应的标注所述第一标签的记录信息;所述指定内容至少包括以下之
一:数字、英文、汉字多音字、连续的词句、停顿;基于所述发音字典映射表将所述指定内容对应的所述第二标签转化成所述第一标签,得到所述第三文稿;其中,所述发音字典映射表预存有所述第二标签与所述第一标签之间的关联映射关系。
6.在一种实施方式中,所述标签标注单元还用于:用所述指定内容遍历所述发音纠正数据库,判断所述发音纠正数据库中是否存在与所述指定内容对应匹配的所述参考信息;如果是,调用所述参考信息对应的标注所述第二标签的记录信息为所述指定内容标注所述第二标签,得到所述第二文稿。
7.在一种实施方式中,所述停顿插入单元还用于:根据所述待处理文稿中的内容确定所述待处理文稿中的标点符号和换行符所在位置;根据所述待处理文稿中的标点符号和换行符所在位置确定所述目标位置。
8.在一种实施方式中,所述静音分析单元还用于:获取所述第一语音中所有静音段对应的时间信息,并将时长为第一预设值的静音段对应的时间信息确定为所述第一时间信息。
9.在一种实施方式中,所述声乐合成单元包括音量调整单元、淡入淡出处理单元和混音单元;所述音量调整单元,用于获取所述初始背景音乐对应的第一背景音乐和所述初始背景音乐对应的第二背景音乐;其中,所述第一背景音乐的音量高于所述第二背景音乐的音量;所述淡入淡出处理单元,用于根据所述第一时间信息对所述第一背景音乐进行淡入淡出处理,得到所述第一背景音乐对应的第一处理音乐;所述混音单元,用于根据所述第一时间信息对所述第一语音、所述第一处理音乐和所述第二背景音乐进行混音处理,得到所述第一音频。
10.在一种实施方式中,所述淡入淡出处理单元还用于:根据所述第一时间信息对所述第一背景音乐进行切分,得到所述第一背景音乐对应的第一音乐片段;对所述第一音乐片段进行淡入淡出处理,得到所述第一音乐片段对应的第二音乐片段。
11.在一种实施方式中,所述混音单元还用于:对所述第一语音、所述第二音乐片段和所述第二背景音乐进行混音处理,得到所述第一音频。
12.在一种实施方式中,所述系统还包括:音量标准化单元,用于对所述第一音频进行音量标准化处理,得到第二音频。
13.第二方面,本发明实施例还提供一种广播节目智能播报方法,应用上述系统,所述方法包括:根据待处理文稿的内容确定所述待处理文稿中的目标位置,并为目标位置插入第一停顿,得到第一文稿;其中,所述目标位置为所述待处理文稿中换行符所在位置;基于预存的标注有第一标签的参考信息和所述第一标签与第二标签之间的关联映射关系为所述第一文稿标注标签,得到标注有所述第二标签的第二文稿;其中,所述第一标签为tts服务商所提供的语音合成标记语言的标签;所述第二标签为通俗语言的标签;根据所述第二文稿的内容和所述第二标签进行语音合成,得到所述第二文稿对应的第一语音;对所述第一语音进行静音分析,并获取所述第一语音中相邻段落之间的部分对应的第一时间信息;根据所述第一时间信息对所述第一语音和初始背景音乐进行声乐合成,得到第一音频。
14.本发明实施例提供的一种广播节目智能播报系统及方法,通过为待处理文稿插入相应的停顿,以便后续通过语音合成得到带停顿的语音,能够模拟出真实主持人播报字词句的节奏感;通过预先设置标注有通俗语言的标签的参考信息和该参考信息对应的标注通
俗语言的标签的记录信息,并建立通俗语言的标签与tts服务商所提供的语音合成标记语言的标签之间的关联映射关系,以便后续可基于该参考信息和该参考信息对应的标注通俗语言的标签的记录信息为文稿标注通俗语言的标签,并基于该关联映射关系将文稿对应的通俗语言的标签转化成tts服务商所提供的语音合成标记语言的标签,进而根据tts服务商所提供的语音合成标记语言的标签进行语音合成,在保证播报内容发音准确性的同时提高了语音合成的效率;通过对语音合成后得到的语音进行静音分析来获取该语音中相邻段落之间的部分对应的时间信息,并根据该时间信息对该语音和背景音乐进行声乐合成,能够模拟出真实主持人播报时对调音台不断进行操作以控制背景音乐的播放与文稿内容的播报相协调,进一步提高了播报效果。采用上述技术,只要有文字编辑能力的任何人员都能进行节目播报而不需要专业的主持人的参与,进一步降低了节目播报所需的人力成本。
15.本发明的其他特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
16.为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
附图说明
17.为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
18.图1为本发明实施例提供的一种广播节目智能播报系统的结构示意图;
19.图2为本发明实施例提供的另一种广播节目智能播报系统的结构示意图;
20.图3为本发明实施例提供的一种广播节目智能播报方法的流程示意图;
21.图4为本发明实施例提供的一种背景音乐处理方法的示意图;
22.图5为本发明实施例提供的另一种广播节目智能播报方法的示意图;
23.图6为本发明实施例提供的一种字幕文件的生成方法的流程示意图。
具体实施方式
24.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合实施例对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
25.目前,对于广播电台的非互动类节目(如新闻资讯、天气预报等)来说,传统播报方式通常需要主持人根据文稿内容在直播间进行播报。采用该播报方式,主持人需要实时根据文稿上下文内容准确识别出字词句的关系,并做出正确的发音,这对主持人的语言控制能力是一种考验。采用该播报方式,为了保证播出效果,主持人在播报文稿内容时还需要根据播报的内容手动控制背景音乐的播放,即:在主持人开口播报文稿中连续的字词句时,主持人还需要手动操作调音台调低背景音乐的音量;而在主持人停止播报文稿内容或主持人
根据文稿内容中字词句的关系进行停顿时,特别是在主持人通过停顿实现文稿内容中不同段落之间的自然过渡时,主持人还需要手动操作调音台调高背景音乐的音量。因此,在上述播报方式中,主持人在播报文稿内容时还需要对调音台不断进行操作以控制背景音乐的播放与文稿内容的播报相协调,这对主持人的协调操作能力也是一种考验。另外,采用上述播报方式,考虑到遇到突发事件时需要主持人及时到达直播间进行播报的情况,经常还需要数名专业主持人轮岗进行播报,进一步增加了人力成本的投入。
26.基于此,本发明实施提供一种广播节目智能播报系统及方法,可以在保证播报内容发音准确的同时自动调节背景音乐的效果,在一定程度上替代真实的主持人进行非互动类广播节目的播报,进而缓解传统播报方式对主持人要求高、人力成本高的问题。
27.为便于对本实施例进行理解,首先对本发明实施例所提供的一种广播节目智能播报系统进行详细介绍,参见图1所示的一种广播节目智能播报系统的结构示意图,该系统可以包括:依次连接的停顿插入单元1、发音干预单元2、语音合成单元3、静音分析单元4和声乐合成单元5。
28.停顿插入单元1,用于根据待处理文稿的内容确定待处理文稿中的目标位置,并为目标位置插入第一停顿,得到第一文稿;其中,目标位置为待处理文稿中换行符所在位置。
29.具体地,上述待处理稿件的内容通常可以是包括多个段落的文本,上述停顿插入单元1可利用正则匹配算法确定待处理稿件中换行符所在位置,进而将换行符所在位置确定为待处理文稿中的目标位置,并为目标位置插入第一停顿,得到包含第一停顿的第一文稿;之后将第一文稿发送至发音干预单元2。第一停顿的时长可根据实际需要自行设置,例如,将第一停顿的时长设置为1秒。
30.发音干预单元2,用于基于预存的标注有第二标签的参考信息和该参考信息对应的标注第二标签的记录信息为第一文稿标注标签,得到标注有第二标签的第二文稿;基于预存的第二标签与第一标签之间的关联映射关系将第二文稿对应的第二标签转化成第一标签,得到标注有第一标签的第三文稿;其中,第一标签为tts服务商所提供的语音合成标记语言的标签;第二标签为通俗语言的标签。
31.具体地,上述参考信息可根据实际需要自行确定,例如,上述参考信息可以包括数字、英文、汉字多音字、连续的词句、停顿等。在语音合成(tts)技术中,tts服务商提供了关于发音的处理代码,即语音合成标记语言(speech synthesis markup language)。由于不同tts服务商所使用的语音合成标记语言的规范是不同的,为了提高前端标签的辨识度和通用性,可以通过富文本解释器将tts服务商所提供的语音合成标记语言的标签(即第一标签)转化成带不同色彩的通俗语言的标签(即第二标签);例如,将tts服务商所提供的代表停顿1秒的语音合成标记语言的标签[p1000]转化成带“停顿1秒”几个汉字的有色标签供前端制作使用,具体操作方式为:先把[p1000]替换为<span style=“color:white;background
‑
color:rgb(95,155,231)”>停顿1秒</span>,再利用富文本解释器识别html标签的特性把难理解的机器标签转化成容易理解的样式文本。在进行语音合成前,采用人工方式为上述参考信息标注通俗语言的标签(即第二标签),之后将标注有第二标签的参考信息和该参考信息对应的标注第二标签的记录信息保存至上述发音干预单元2。上述标注有第二标签的参考信息和该参考信息对应的标注第二标签的记录信息的保存方式(如构建数据库进行保存、以带格式的表格方式进行保存等),具体可根据实际需要自行选择,对此并
不进行限定。
[0032]
由于tts语音合成服务只能使用tts服务商所提供的语音合成标记语言进行语音合成,因而在对第二文稿进行语音合成之前,还需要将第二文稿对应的通俗语言的标签(即第二标签)转化成tts服务商所提供的语音合成标记语言的标签(即第一标签);具体操作方式可以为:采用人工方式建立第二标签与第一标签之间的关联映射关系,并将该关联映射关系保存至上述发音干预单元2。上述关联映射关系的保存方式(如构建数据库进行保存、以带格式的表格方式进行保存等),具体可根据实际需要自行选择,对此并不进行限定。
[0033]
基于此,发音干预单元2在收到停顿插入单元1发送的第一文稿后,可基于预存的标注有第二标签的参考信息和该参考信息对应的标注第二标签的记录信息为第一文稿标注标签,得到标注有第二标签的第二文稿;进而可基于第二标签与第一标签之间的关联映射关系将第二文稿对应的第二标签转化成第一标签,得到标注有第一标签的第三文稿;之后将第三文稿发送至语音合成单元3,以便后续可直接用tts语音合成服务进行语音合成。
[0034]
例如,对于示例句“遭遇紧急情况请拨打110报警电话”来说,通俗语言规定数字对应的通俗语言的标签(即第二标签)用于该示例句的呈现形式为“遭遇紧急情况请拨打110报警电话”,某tts服务商规定数字对应的tts服务商所提供的语音合成标记语言的标签(即第一标签)用于该示例句的呈现形式为“遭遇紧急情况请拨打<figure>110</figure type=digit>报警电话”首先通过富文本解释器将数字“110”对应的第一标签转化成数字“110”对应的第二标签;之后为数字“110”标注第二标签,并生成该数字“110”对应的标注第二标签的记录信息,以及将标注有第二标签的数字“110”和该数字“110”对应的标注第二标签的记录信息保存至上述发音干预单元2;之后采用人工方式建立数字“110”对应的第二标签与数字“110”对应的第一标签之间的关联映射关系,并将该关联映射关系保存至上述发音干预单元2;发音干预单元2在下一次面临包含数字“110”的文稿时,可直接基于预存的标注有第二标签的数字“110”和该数字“110”对应的标注第二标签的记录信息为文稿中的数字“110”标注第二标签,并基于预存的数字“110”对应的第二标签与数字“110”对应的第一标签之间的关联映射关系将文稿中的数字“110”对应的第二标签转化成tts语音合成服务能够使用的第一标签,以便后续可直接用tts语音合成服务进行语音合成。
[0035]
语音合成单元3,用于根据第三文稿的内容和第三文稿对应的第一标签进行语音合成,得到第三文稿对应的第一语音。
[0036]
具体地,语音合成单元3在收到发音干预单元2发送的第三文稿后,可根据第三文稿的内容和第三文稿对应的第一标签,直接通过tts服务商提供的语音合成服务(在线的或者离线的)进行语音合成,得到第三文稿对应的第一语音;之后将第一语音发送至静音分析单元4。
[0037]
静音分析单元4,用于对第一语音进行静音分析,并获取第一语音中相邻段落之间的部分对应的第一时间信息。
[0038]
具体地,上述静音分析即为检测并识别出第一语音中的所有静音部分(包含第一语音中相邻段落之间的部分),静音分析可以采用常用的静音检测算法(如vad算法等)来实现,具体实现方式可根据实际需要自行选择,对此并不进行限定。由于上述第二文稿中第一停顿所在位置是与第一语音中相邻段落之间的静音部分对应的,因而静音分析单元4在对
第一语音进行静音分析时,可直接将第一语音中满足第一停顿时长(如1秒)的静音部分确定为第一语音中相邻段落之间的部分,并提取该部分对应的时间信息(包括起止时间、时长等),该时间信息即为上述第一时间信息;之后将第一语音和第一时间信息发送至声乐合成单元5。
[0039]
声乐合成单元5,用于根据第一时间信息对第一语音和初始背景音乐进行声乐合成,得到第一音频。
[0040]
具体地,在进行声乐合成前,需要人工将声乐合成所需的初始背景音乐保存至上述声乐合成单元5。基于此,声乐合成单元5在收到静音分析单元4发送的第一语音和第一时间信息后,将第一语音和初始背景音乐进行混音合成,同时根据第一时间信息对初始背景音乐进行淡入淡出处理,进而模拟出真实主持人播报文稿内容时调节背景音乐音量的效果。上述淡入淡出处理可直接使用现有的ffmpeg程序来实现,通过ffmpeg程序对初始背景音乐中与第一时间信息对应的部分进行淡入淡出处理。具体实现方式可根据实际需要自行确定(如对现有的ffmpeg程序所提供的代码进行相应的编辑等),对此并不进行限定。
[0041]
本发明实施例提供的一种广播节目智能播报系统,通过为待处理文稿插入相应的停顿,以便后续通过语音合成得到带停顿的语音,能够模拟出真实主持人播报字词句的节奏感;通过预先设置标注有通俗语言的标签的参考信息和该参考信息对应的标注通俗语言的标签的记录信息,并建立通俗语言的标签与tts服务商所提供的语音合成标记语言的标签之间的关联映射关系,以便后续可基于该参考信息和该参考信息对应的标注通俗语言的标签的记录信息为文稿标注通俗语言的标签,并基于该关联映射关系将文稿对应的通俗语言的标签转化成tts服务商所提供的语音合成标记语言的标签,进而根据tts服务商所提供的语音合成标记语言的标签进行语音合成,在保证播报内容发音准确性的同时提高了语音合成的效率;通过对语音合成后得到的语音进行静音分析来获取该语音中相邻段落之间的部分对应的时间信息,并根据该时间信息对该语音和背景音乐进行声乐合成,能够模拟出真实主持人播报时对调音台不断进行操作以控制背景音乐的播放与文稿内容的播报相协调,进一步提高了播报效果。采用上述技术,只要有文字编辑能力的任何人员都能进行节目播报而不需要专业的主持人的参与,进一步降低了节目播报所需的人力成本。
[0042]
在上述系统的基础上,为了进一步提高标注标签的效率,参见图2所示的另一种广播节目智能播报系统的结构示意图,上述发音干预单元还可以包括标签标注单元21、发音纠正数据库22和发音字典映射表23;标签标注单元21可以用于:(1)基于发音纠正数据库22为第一文稿中的指定内容标注第二标签,得到第二文稿;其中,发音纠正数据库22预存有参考信息和参考信息对应的标注第一标签的记录信息;(2)基于上述发音字典映射表23将上述指定内容对应的第二标签转化成第一标签,得到第三文稿;其中,发音字典映射表23预存有第二标签与第一标签之间的关联映射关系。
[0043]
具体地,考虑到播报文稿的实际情况,上述指定内容至少可以包括以下之一:数字、英文、汉字多音字、连续的词句、停顿。为了保证上述指定内容发音准确,需要对该指定内容进行发音纠正。在进行发音纠正之前,可以为上述发音干预单元2构建发音纠正数据库22,可根据实际需要选择常见的数据库类型(如mysql数据库等)作为发音纠正数据库22的类型。在构建好发音纠正数据库22之后,可以采用人工手动标注的方式为上述参考信息标注第一标签,并将上述参考信息对应的标注第一标签的记录信息记录至发音纠正数据库22
中。为了便于后续可直接用tts语音合成服务进行语音合成,需要将该指定内容对应的通俗语言的标签(即第二标签)转化成tts服务商所提供的语音合成标记语言的标签(即第一标签)。在进行语音合成之前,还可以进行以下操作:采用人工的方式建立制作前端界面所使用的通俗语言的标签(即第二标签)与各tts服务商所提供的语音合成标记语言的标签(即第一标签)之间的关联映射关系,并将该关联映射关系以一定格式的表格(即发音字典映射表23)的形式保存至干预单元2。
[0044]
通过采用上述操作方式,干预单元2在面临包含上述指定内容的文稿时,可直接调用发音纠正数据库22中预存的标注有第二标签的参考信息和该参考信息对应的标注第二标签的记录信息为文稿标注第二标签,进而可读取发音字典映射表23中预存的第二标签与第一标签之间的关联映射关系以将文稿对应的第二标签转化成文稿对应的第一标签,之后将标注有第一标签的文稿发送至语音合成单元3,以便后续可直接用tts语音合成服务进行语音合成。
[0045]
通过上述操作方式,在进行语音合成前,首先选定所使用的tts语音合成服务对应的tts服务商是哪家公司,根据发音字典映射表中第二标签与第一标签之间的关联映射关系将制作前端所标注的标签转换为该公司所对应的语音合成标记语言的标签,作为语音合成的参数,调用该公司提供的语音合成接口进行语音合成。采用上述技术,在实现可直接使用tts语音合成服务进行语音合成的同时,缓解了语音合成标记语言在前端存在辨识度较低和通用性较差的问题。
[0046]
在通过上述标签标注单元21进行第二标签标注和将第二标签转化成第一标签时,为了进一步提高工作效率,可采用正则匹配算法确定文稿中所有需要标注第二标签的指定内容,为指定内容标注第二标签并将该指定内容对应的第二标签转化成第一标签。例如,如果让文稿中所有的“911”按照号码进行发音,采用正则匹配算法找出文稿中所有“911”,然后为“911”标注第二标签,并将“911”对应的第二标签转化成第一标签。
[0047]
在通过上述标签标注单元21基于发音纠正数据库22为第一文稿中的指定内容标注第二标签时,为了进一步提高第二标签标注的效率,上述标签标注单元21还可以用于:用上述指定内容遍历上述发音纠正数据库22,判断上述发音纠正数据库22中是否存在与上述指定内容对应匹配的上述参考信息;如果是(即发音纠正数据库22中存在与指定内容对应匹配的参考信息),调用该参考信息对应的标注第二标签的记录信息为该指定内容标注第二标签。
[0048]
在通过上述停顿插入单元1根据待处理文稿的内容确定待处理文稿中的目标位置时,为了便于操作,上述停顿插入单元1还可以用于:根据待处理文稿中的内容确定待处理文稿中的标点符号和换行符所在位置;根据待处理文稿中的标点符号和换行符所在位置确定上述目标位置。
[0049]
具体地,可利用正则匹配算法确定待处理稿件中的标点符号和换行符所在位置,这些不同位置便组成了一个候选位置集合;之后可进一步利用正则匹配算法确定候选位置集合中的换行符所在位置(即目标位置)。
[0050]
采用上述操作方式,利用正则匹配算法进行两次匹配以确定待处理稿件中需要插入停顿的目标位置,能够缓解利用正则匹配算法进行一次匹配有时难以准确确定出全部目标位置的问题,进一步提高了确定目标位置的准确性,进而保证后续为目标位置插入第一
停顿的准确性。此外,通过设置候选位置集合进行过渡,第二次匹配仅需要针对第一次匹配的结果进行匹配而无需重新针对待处理文稿中的全部内容进行匹配,因而第二次匹配耗时较短,仅需要进行一次全文匹配和一次局部匹配即可确定出待处理稿件中需要插入停顿的目标位置,进一步提高了确定目标位置的整体工作效率。
[0051]
在通过上述静音分析单元4获取第一语音中相邻段落之间的部分对应的第一时间信息时,为了进一步提高第一时间信息的获取效率,上述静音分析单元4还可以用于:获取第一语音中所有静音段对应的时间信息,并将时长为第一预设值的静音段对应的时间信息确定为第一时间信息。
[0052]
具体地,上述第一预设值为上述第一停顿的时长(如1秒);上述静音分析单元4在对第一语音进行静音分析时,可直接提取出时长为第一预设值的静音段对应的时间信息,该时间信息即为上述第一时间信息。
[0053]
在上述系统的基础上,为了进一步提高声乐合成的效率,参见图2所示的另一种广播节目智能播报系统的结构示意图,上述声乐合成单元5还可以包括音量调整单元51、淡入淡出处理单元52和混音单元53。
[0054]
上述音量调整单元51,用于获取初始背景音乐对应的第一背景音乐和初始背景音乐对应的第二背景音乐;其中,第一背景音乐的音量高于第二背景音乐的音量。
[0055]
具体地,上述声乐合成单元5在接收到静音分析单元4发送的第一语音和第一时间信息后,首先通过上述音量调整单元51获取初始背景音乐并对初始背景音乐进行音量检测,以确定初始背景音乐的现有音量;之后在该现有音量的基础上,按照固定比例(如现有音量的30%)分别对初始背景音乐进行音量抬高和音量降低,进而获得音量高于现有音量的第一背景音乐和音量低于现有音量的第二背景音乐;之后将淡入淡出处理单元52上述固定比例可根据主持人日常操作调音台的音量控制范围确定。
[0056]
上述淡入淡出处理单元52,用于根据第一时间信息对第一背景音乐进行淡入淡出处理,得到第一背景音乐对应的第一处理音乐。
[0057]
具体地,上述淡入淡出处理单元52可通过现有的ffmpeg程序对第一背景音乐中与第一时间信息对应的部分进行淡出处理,得到第一背景音乐对应的第一处理音乐。
[0058]
上述混音单元53,用于根据第一时间信息对第一语音、第一处理音乐和第二背景音乐进行混音处理,得到第一音频。
[0059]
具体地,作为一种可能的实施方式,上述混音单元53可通过现有的ffmpeg程序将第一语音、第一处理音乐和第二背景音乐中与第一时间信息对应的部分进行拼接,得到第一音频位置;其中,拼接的位置为第一时间信息的起止时间点。作为另一种可能的实施方式,上述混音单元53可通过现有的ffmpeg程序将第一处理音乐和第二背景音乐中与第一时间信息对应的部分进行拼接,之后将第一语音和拼接得到的音乐再次进行拼接,得到第一音频位置;其中,两次拼接的位置均为第一时间信息的起止时间点。上述两种拼接方式可根据实际需要选择其中一种,对此并不进行限定。
[0060]
在上述操作方式中,将背景音乐转换成高音量和低音量两个版本,对高音量版本的背景音乐中第一时间信息对应的部分进行淡入淡出处理,得到处理后的音乐;之后对处理后的音乐、第一语音和低音量版本的背景音乐进行混音处理,得到带背景音乐的播报音频。该操作方式能够模拟出真实主持人播报时对调音台不断进行操作以控制背景音乐的播
放与文稿内容的播报相协调,在保证声乐合成效果的同时,也提高了声乐合成效率。
[0061]
在通过上述淡入淡出处理单元52用于根据第一时间信息对第一背景音乐进行淡入淡出处理时,为了进一步提高淡入淡出处理的效率,上述淡入淡出处理单元52还可以用于:根据上述第一时间信息对第一背景音乐进行切分,得到第一背景音乐对应的第一音乐片段;对第一音乐片段进行淡入淡出处理,得到第一音乐片段对应的第二音乐片段。
[0062]
具体地,上述淡入淡出处理单元52可通过现有的ffmpeg程序将第一背景音乐中与第一时间信息对应的部分切分出来,之后对切分出来的这部分音乐片段(即第一音乐片段)单独进行淡入淡出处理,得到第一音乐片段对应的第二音乐片段。基于此,上述混音单元53还可以用于:对第一语音、第二音乐片段和第二背景音乐进行混音处理,得到第一音频。
[0063]
在上述系统的基础上,为了进一步满足广播播出标准需求,参见图2所示的另一种广播节目智能播报系统的结构示意图,上述系统还可以包括与上述声乐合成单元5连接的音量标准化单元6。
[0064]
上述音量标准化单元6,用于对第一音频进行音量标准化处理,得到第二音频。
[0065]
具体地,上述音量标准化单元6可通过现有的ffmpeg程序采用音量标准化算法对第一音频进行音量标准化处理,具体操作方式可以为:首先对第一音频进行音量检测,计算出第一音频整体音量的平均值,再参照广播的标准音量值,计算标准音量值和第一音频整体音量的平均值之间的差值,将该差值作为调整依据对第一音频的音量进行调整。现有的ffmpeg程序可参照ebu r.128等标准对音频进行音量标准化处理。
[0066]
在实际进行音量标准化处理的过程中,为了进一步提高音量标准化处理后的音频的质量,有时还需要进行峰值标注化处理作为音量标准化处理后的辅助调整手段。峰值标注化处理具体可采用峰值标准化算法对音量标准化处理后的音频的峰值进行标准化处理,具体操作方式可以为:首先对音量标准化处理后的音频进行音量检测,找到该音频中音量最大的位置以及该位置对应的最大音量(即峰值),将该峰值调整至标准大小,然后将该音频中峰值所在位置以外的其他部分的音量进行相应的调整(增/减)。
[0067]
在上述广播节目智能播报系统的基础上,本发明实施例还提供一种广播节目智能播报方法,该方法可以应用于上述广播节目智能播报系统,参见图3所示的一种广播节目智能播报方法的流程示意图,该方法可以包括以下步骤:
[0068]
步骤s302,根据待处理文稿的内容确定待处理文稿中的目标位置,并为目标位置插入第一停顿,得到第一文稿;其中,目标位置为待处理文稿中换行符所在位置。
[0069]
步骤s304,基于预存的标注有第二标签的参考信息和参考信息对应的标注第二标签的记录信息为第一文稿标注标签,得到标注有第二标签的第二文稿;
[0070]
步骤s306,基于预存的第二标签与第一标签之间的关联映射关系将第二文稿对应的第二标签转化成第一标签,得到标注有第一标签的第三文稿;其中,第一标签为tts服务商所提供的语音合成标记语言的标签;第二标签为通俗语言的标签。
[0071]
步骤s308,根据第三文稿的内容和第三文稿对应的第一标签进行语音合成,得到第三文稿对应的第一语音。
[0072]
步骤s310,对第一语音进行静音分析,并获取第一语音中相邻段落之间的部分对应的第一时间信息。
[0073]
步骤s312,根据第一时间信息对第一语音和初始背景音乐进行声乐合成,得到第
一音频。
[0074]
本发明实施例提供的一种广播节目智能播报方法,通过为待处理文稿插入相应的停顿,以便后续通过语音合成得到带停顿的语音,能够模拟出真实主持人播报字词句的节奏感;通过预先设置标注有通俗语言的标签的参考信息和该参考信息对应的标注通俗语言的标签的记录信息,并建立通俗语言的标签与tts服务商所提供的语音合成标记语言的标签之间的关联映射关系,以便后续可基于该参考信息和该参考信息对应的标注通俗语言的标签的记录信息为文稿标注通俗语言的标签,并基于该关联映射关系将文稿对应的通俗语言的标签转化成tts服务商所提供的语音合成标记语言的标签,进而根据tts服务商所提供的语音合成标记语言的标签进行语音合成,在保证播报内容发音准确性的同时提高了语音合成的效率;通过对语音合成后得到的语音进行静音分析来获取该语音中相邻段落之间的部分对应的时间信息,并根据该时间信息对该语音和背景音乐进行声乐合成,能够模拟出真实主持人播报时对调音台不断进行操作以控制背景音乐的播放与文稿内容的播报相协调,进一步提高了播报效果。采用上述技术,只要有文字编辑能力的任何人员都能进行节目播报而不需要专业的主持人的参与,进一步降低了节目播报所需的人力成本。
[0075]
上述步骤s304(即基于预存的标注有第二标签的参考信息和参考信息对应的标注第二标签的记录信息为第一文稿标注标签,得到标注有第二标签的第二文稿)可以采用如下操作方式:基于发音纠正数据库为第一文稿中的指定内容标注第二标签,得到第二文稿;其中,发音纠正数据库预存有参考信息和参考信息对应的标注所述第二标签的记录信息;上述指定内容至少可以包括以下之一:数字、英文、汉字多音字、连续的词句、停顿。
[0076]
基于此,上述基于发音纠正数据库为第一文稿中的指定内容标注第二标签可以采用以下操作方式:用上述指定内容遍历发音纠正数据库,判断发音纠正数据库中是否存在与该指定内容对应匹配的参考信息;如果是(即发音纠正数据库中存在与该指定内容对应匹配的参考信息),调用该参考信息对应的标注第二标签的记录信息为该指定内容标注第二标签,得到第二文稿。
[0077]
上述步骤s306(即基于预存的第二标签与第一标签之间的关联映射关系将第二文稿对应的第二标签转化成第一标签,得到标注有第一标签的第三文稿)可以采用如下操作方式:基于发音字典映射表将指定内容对应的第二标签转化成第一标签,得到第三文稿;其中,发音字典映射表预存有第二标签与第一标签之间的关联映射关系。
[0078]
上述步骤s302中根据待处理文稿的内容确定待处理文稿中的目标位置可以采用以下操作方式:根据待处理文稿中的内容确定待处理文稿中的标点符号和换行符所在位置;根据待处理文稿中的标点符号和换行符所在位置确定上述目标位置。
[0079]
上述步骤s310中获取第一语音中相邻段落之间的部分对应的第一时间信息可以采用以下操作方式:获取第一语音中所有静音段对应的时间信息,并将时长为第一预设值的静音段对应的时间信息确定为第一时间信息。
[0080]
上述步骤s312(即根据第一时间信息对第一语音和初始背景音乐进行声乐合成,得到第一音频)可以采用如下操作方式:
[0081]
(1)获取初始背景音乐对应的第一背景音乐和初始背景音乐对应的第二背景音乐;其中,第一背景音乐的音量高于第二背景音乐的音量。
[0082]
(2)根据第一时间信息对第一背景音乐进行淡入淡出处理,得到第一背景音乐对
应的第一处理音乐。
[0083]
(3)根据第一时间信息对第一语音、第一处理音乐和第二背景音乐进行混音处理,得到第一音频。
[0084]
上述根据第一时间信息对第一背景音乐进行淡入淡出处理可以采用以下操作方式:根据第一时间信息对第一背景音乐进行切分,得到第一背景音乐对应的第一音乐片段;对第一音乐片段进行淡入淡出处理,得到第一音乐片段对应的第二音乐片段。
[0085]
基于此,在对第一音乐片段进行淡入淡出处理,得到第一音乐片段对应的第二音乐片段之后,还可以进行以下操作:对第一语音、第二音乐片段和第二背景音乐进行混音处理,得到第一音频。
[0086]
在上述步骤s312(即根据第一时间信息对第一语音和初始背景音乐进行声乐合成,得到第一音频)之后,还可以进行以下操作:对第一音频进行音量标准化处理,得到第二音频。
[0087]
下面以某一具体应用场景对上述广播节目智能播报方法进行描述如下:
[0088]
由于在传统人工播报方式中,会先播放背景音乐的片花部分,片花播放完毕后,主持人会拉下调音台的推子降低后续背景音乐的音量,此时主播开始说话进行播报。因此,为了模拟出这样的效果,参见图4所示的一种背景音乐处理方法的示意图,该方法主要包括:根据背景音乐的片花时长信息,用音频截取软件对初始背景音乐截取片花部分,将初始背景音乐中片花后的部分进行淡出处理并将这部分的整体音量降低至
‑
20dbfs,之后将这两部分进行混音后形成片花淡出处理后的新背景音乐。
[0089]
基于此,由于在传统人工播报方式中,主持人通常在口播完文稿上一段内容后通过调音台推子拉高背景音乐的音量进行背景音乐播放,等到要开始播下一段内容时再拉低背景音乐,以形成人声和背景音乐在段落间的良好过渡效果。因此,为了模拟出这样的效果,参见图5所示的另一种广播节目智能播报方法的示意图。首先前端会利用正则匹配算法确定文稿中换行符所在位置,并为待处理稿件中换行符所在位置批量插入停顿;按照广播日常播报特点,段落间过渡一般为1秒左右,因而设置该停顿的时长为1秒;之后对插入有1秒停顿的文稿进行语音合成,得到一段人声音频;之后对该人声音频进行静音检测,采用正则匹配算法将音量为
‑
50dbfs持续时长达到或超过一秒的音频段确定为静音段,并将静音段的时间信息提取出来,以及将时长为1秒的静音段(例如图5中1分31秒至1分32秒的部分和2分1秒至2分2秒的部分)的起止时间点(例如图5中的1分31、1分32秒、2分1秒和2分2秒)记录下来;之后根据时长为1秒的静音段的起止时间点,通过音频截取软件截取初始背景音乐中与时长为1秒的静音段对应的音乐片段(例如图5中的音乐片段1和音乐片段2);之后将初始背景音乐中与时长为1秒的静音段对应的音乐片段、片花淡出处理后的新背景音乐和人声音频进行混音和淡入淡出的处理,最后形成模拟人工播报特点的声乐音频;之后根据广播音频播出标准,采用ffmpeg提供的处理算法调整该声乐音频的峰值和响度相关参数以对该声乐音频进行音量标准化处理(包括响度的标准化处理和峰值的标准化处理),最后得到可以满足节目播报要求的播出音频。
[0090]
在上述步骤s312(根据第一时间信息对第一语音和初始背景音乐进行声乐合成,得到第一音频)之后,为了进一步满足融媒体的生产需求,还可以为第一音频生成字幕文件(如srt字幕文件),本发明实施例还提供了一种字幕文件生成的方法。参见图6所示的一种
字幕文件的生成方法的流程示意图,该方法主要包括以下步骤:
[0091]
步骤s602,对第一音频进行静音检测,并获取第一音频中与第一停顿所在位置对应的部分的起止时间点信息。
[0092]
步骤s604,去除第一音频中标签化的发音干预信息。
[0093]
步骤s606,按照第一音频中第一停顿所在位置对应的部分的起止时间点信息,将音频内容分成多个音频片段;其中,每个音频片段均与待处理文稿中的一个段落相对应。
[0094]
步骤s608,获取每个音频片段的时长信息。
[0095]
步骤s610,根据待处理文稿中的标点符号,利用正则匹配算法将每个音频片段分成多句话。
[0096]
步骤s612,统计每句话的字数,并获取每个字的时长。
[0097]
步骤s614,计算出每句话的时间信息,并根据每句话的时间信息生成字幕文件。
[0098]
本发明实施例所提供的方法,其实现原理及产生的技术效果和前述系统实施例相同,为简要描述,方法实施例部分未提及之处,可参考前述系统实施例中相应内容。
[0099]
最后应说明的是:以上所述实施例,仅为本发明的具体实施方式,用以说明本发明的技术方案,而非对其限制,本发明的保护范围并不局限于此,尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,其依然可以对前述实施例所记载的技术方案进行修改或可轻易想到变化,或者对其中部分技术特征进行等同替换;而这些修改、变化或者替换,并不使相应技术方案的本质脱离本发明实施例技术方案的精神和范围,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。