1.本发明涉及控制装置、控制方法及控制程序。
背景技术:
2.在生产产品的生产线中,各种类型的机械手被利用。机械手的机构、末端执行器、工件等构成要素根据所执行的任务等而具有多种变化,难以通过人工制作与这些全部对应的机械手的动作顺序,来向机械手示教对象的任务。因此,一直以来采用如下方法:在确定机构、末端执行器、工件等构成要素的种类之后,人工移动机械手,一边记录所执行的一系列动作中的姿势,一边直接示教所执行的任务。
3.但是,在该方法中,每当机构、末端执行器、工件等构成要素变更时,都要向机械手示教所执行的任务。因此,向机械手示教所执行的任务会花费过多的成本。因此,近年来,正在研究使机械手掌握所执行的任务的方法的效率化。例如,在专利文献1中,提出了基于手及柔软物之间的相对速度来确定把持贴纸等柔软物的手的移动速度的控制方法。根据该控制方法,能够使制造或示教手的移动动作的作业中的至少一部分自动化。因此,能够降低生成或示教机械手的动作的成本。
4.现有技术文献
5.专利文献
6.专利文献1:日本特开2015-174172号公报
技术实现要素:
7.发明要解决的技术问题
8.本发明的发明人等发现,在上述那样的机械手的现有的控制方法中存在如下问题:即,在现有的控制方法中,通过传感器观测机械手的手指,根据由传感器得到的传感数据推定机械手的手指的坐标。基于该推定的结果,控制机械手的手指的坐标。
9.作为推定机械手的手指的坐标的方法的一例,存在基于正向运动学计算的方法。在该方法中,测定各关节的角度的编码器是传感器的一例。能够根据由编码器得到的各关节的角度的测定值解析地计算机械手的手指的坐标的推定值。
10.另外,作为其他方法,存在基于图像分析的方法。在该方法中,对包括机械手的手指的任务环境进行拍摄的照相机是传感器的一例。通过对由照相机得到的图像数据执行图像分析,能够推定机械手的手指的坐标。图像分析的方法可以采用模式匹配等公知的方法。
11.任一种方法都能够根据由传感器得到的传感数据推定机械手的手指的坐标。然而,从传感器得到的传感数据中有时包括噪声(noise)。另外,在分析的过程中,例如有时也包括模式匹配的允许误差等噪声。由于依赖于这些环境而产生的噪声,机械手的手指的坐标的推定值与真值之间的误差变大,由此,存在控制机械手的手指的坐标的精度恶化的可能性。
12.本发明的一方面是鉴于这样的实际情况而完成的,其目的在于提供一种用于实现
控制机械手的手指的坐标的精度的提高的技术。
13.用于解决技术问题的方案
14.为了解决上述技术问题,本发明采用以下构成。
15.即,本发明的一方面所涉及的控制装置是用于控制机械手的动作的控制装置,具备:第一数据获取部,从观测所述机械手的手指的第一传感器系统获取第一传感数据;第一推定部,利用第一推定模型,根据所获取的所述第一传感数据,计算观测空间内的所述手指的当前坐标的第一推定值;第二数据获取部,从观测所述机械手的手指的第二传感器系统获取第二传感数据;第二推定部,利用第二推定模型,根据所获取的所述第二传感数据,计算所述观测空间内的所述手指的当前坐标的第二推定值;调整部,计算所述第一推定值与所述第二推定值之间的误差的梯度,并基于计算出的梯度,调整所述第一推定模型及所述第二推定模型中的至少一方的参数的值,以使所述误差变小;指令确定部,基于所述第一推定值及所述第二推定值中的至少一方,确定赋予所述机械手的控制指令,以使所述手指的坐标接近目标值;驱动部,通过将所确定的所述控制指令赋予所述机械手来驱动所述机械手。
16.在该构成所涉及的控制装置中,根据第一传感器系统及第二传感器系统这两个路径推定机械手的手指的坐标。即,该构成所涉及的控制装置利用第一推定模型,根据由第一传感器系统得到的第一传感数据计算机械手的手指的坐标的第一推定值。另外,该构成所涉及的控制装置利用第二推定模型,根据由第二传感器系统得到的第二传感数据计算机械手的手指的坐标的第二推定值。
17.机械手的手指的坐标的真值为一个。如果在根据各传感器系统的计算过程中没有噪声,则第一推定值和第二推定值一致。与此相对,通过产生与各传感器系统相应的噪声,则第一推定值和第二推定值可能相互不同。因此,计算所得到的第一推定值与第二推定值之间的误差的梯度,并基于计算出的梯度,调整第一推定模型及第二推定模型中的至少一方的参数的值,以使误差变小。通过该调整,相互的推定结果(推定值)接近一个值,因此能够期待基于各推定模型的手指的坐标的推定精度的改善。
18.能够适当评价调整后基于各推定模型的推定值是否接近真值。作为一例,假设由各传感器系统得到的传感数据中可能包括的噪声为白噪声。因此,通过获取规定时间量的传感数据,并将所得到的传感数据平均化,能够除去或降低传感数据中包括的噪声。在该平均化的传感数据中,根据是否包括与基于各推定模型的推定值相关的向量,能够评价基于各推定模型的推定值是否接近真值。因此,根据该构成,能够改善基于各推定模型的手指的坐标的推定精度,由此,能够实现控制机械手的手指的坐标的精度的提高。
19.需要说明的是,机械手的种类也可以不特别限定,可以根据实施方式适当选择。机械手例如可以包括垂直多关节机器人、scara机械人、delta机器人、正交机器人及协调机器人等。各传感器系统具备一个以上的传感器,只要能够观测机械手的手指即可,其构成也可以不特别限定,可以根据实施方式适当选择。各传感器系统例如可以使用照相机、编码器、触觉传感器、力觉传感器、接近传感器、力矩传感器及压力传感器等。各推定模型具备用于根据传感数据计算手指坐标的参数。各推定模型的种类也可以不特别限定,可以根据实施方式适当选择。各推定模型例如可以由函数式、数据表等来表现。在由函数式来表现的情况下,各推定模型可以由神经网络、支持向量机、回归模型及决策树等机器学习模型构成。
20.在上述一方面所涉及的控制装置中,所述调整部也可以进一步在所述机械手的手指与对象物接触时,在与该对象物接触的边界面上获取所述手指的坐标的边界值,计算在所述接触时推定的所述第一推定值与所获取的所述边界值之间的第一误差的梯度,并基于计算出的所述第一误差的梯度,调整所述第一推定模型的参数的值,以使所述第一误差变小,并且计算在所述接触时推定的所述第二推定值与所获取的所述边界值之间的第二误差的梯度,并基于计算出的所述第二误差的梯度,调整所述第二推定模型的参数的值,以使所述第二误差变小。
21.由于伴随着与对象物接触这样的物理制约,因此在与对象物接触时从边界面上得到的边界值作为机械手的手指的坐标的真值是准确度高的值。在该构成中,通过基于该准确度高的值调整各推定模型的参数的值,能够提高基于各推定模型的手指的坐标的推定精度。因此,根据该构成,能够实现控制机械手的手指的坐标的精度的提高。
22.需要说明的是,得到边界值的方法也可以不特别限定,可以根据实施方式适当选择。例如,可以通过操作者的指定得到边界值。另外,例如在机械手的手指与对象物接触的边界面上,可以从接近第一推定值及第二推定值中的至少一方的点选择边界值。作为一例,可以采用最接近第一推定值及第二推定值中的至少一方的点作为赋予边界值的点。对象物的种类也可以不特别限定,可以根据实施方式适当选择。对象物例如可以是工件、成为工件的组装目的地的对象物(例如其他工件)及障碍物等。
23.在上述一方面所涉及的控制装置中,所述机械手可以具备一个以上的关节。所述第一传感器系统可以具备测定所述各关节的角度的编码器。所述第二传感器系统可以具备照相机。根据该构成,在通过编码器及照相机观测机械手的手指的场景中,能够实现控制机械手的手指的坐标的精度的提高。
24.在上述一方面所涉及的控制装置中,所述机械手也可以进一步具备用于保持工件的末端执行器。在所述末端执行器未保持所述工件的情况下,可以将所述末端执行器的关注点设定为所述手指。在所述末端执行器保持所述工件的情况下,可以将所述工件的关注点设定为所述手指。所述第一传感器系统也可以进一步具备用于推定所述工件相对于所述末端执行器的位置关系的触觉传感器。
25.根据该构成,在根据末端执行器是否保持工件来变更机械手的手指的场景中,能够实现控制机械手的手指的坐标的精度的提高。另外,通过该机械手的手指的设定,能够将末端执行器未保持工件的情况下的移动及保持工件的情况下的移动分别作为移动机械手的手指的共同的任务来把握。因此,能够简化机械手的控制处理,由此,能够降低生成或示教机械手的动作的成本。
26.需要说明的是,末端执行器及工件的种类也可以不特别限定,可以根据任务的种类等适当选择。任务只要是至少在工序的一部分伴随着机械手的手指的移动的任务即可,其种类也可以不特别限定,可以根据实施方式适当选择。使机械手执行的任务例如可以是通过末端执行器保持工件,并将所保持的工件组装到其他工件。在这种情况下,末端执行器例如可以是夹具、吸引器、螺丝刀等。工件例如可以是连接器、钉等。其他工件例如可以是插座、孔等。任务的执行可以在实际空间或虚拟空间内执行。
27.作为上述各方式所涉及的控制装置的其他方式,本发明的一方面可以是实现以上控制装置的各构成的信息处理方法,也可以是程序,也可以是存储了这样的程序的计算机
等可读取的存储介质。计算机等可读取的存储介质是通过电、磁、光、机械或化学作用存储程序等信息的介质。
28.例如,本发明的一方面所涉及的控制方法是用于控制机械手的动作的信息处理方法,是计算机执行如下步骤的信息处理方法:从观测所述机械手的手指的第一传感器系统获取第一传感数据的步骤;利用第一推定模型,根据所获取的所述第一传感数据计算观测空间内的所述手指的当前坐标的第一推定值的步骤;从观测所述机械手的手指的第二传感器系统获取第二传感数据的步骤;利用第二推定模型,根据所获取的所述第二传感数据计算所述观测空间内的所述手指的当前坐标的第二推定值的步骤;计算所述第一推定值与所述第二推定值之间的误差的梯度的步骤;基于计算出的梯度,调整所述第一推定模型及所述第二推定模型中的至少一方的参数的值,以使所述误差变小的步骤;基于所述第一推定值及所述第二推定值中的至少一方,确定赋予所述机械手的控制指令,以使所述手指的坐标接近目标值的步骤;通过将所确定的所述控制指令赋予所述机械手来驱动所述机械手的步骤。
29.另外,例如本发明的一方面所涉及的控制程序是用于控制机械手的动作的程序,是用于使计算机执行如下步骤的程序:从观测所述机械手的手指的第一传感器系统获取第一传感数据的步骤;利用第一推定模型,根据所获取的所述第一传感数据计算观测空间内的所述手指的当前坐标的第一推定值的步骤;从观测所述机械手的手指的第二传感器系统获取第二传感数据的步骤;利用第二推定模型,根据所获取的所述第二传感数据计算所述观测空间内的所述手指的当前坐标的第二推定值的步骤;计算所述第一推定值与所述第二推定值之间的误差的梯度的步骤;基于计算出的梯度,调整所述第一推定模型及所述第二推定模型中的至少一方的参数的值,以使所述误差变小的步骤;基于所述第一推定值及所述第二推定值中的至少一方,确定赋予所述机械手的控制指令,以使所述手指的坐标接近目标值的步骤;通过将所确定的所述控制指令赋予所述机械手来驱动所述机械手的步骤。
30.发明的效果
31.根据本发明,能够实现控制机械手的手指的坐标的精度的提高。
附图说明
32.图1示意性地示例了应用本发明的场景的一例。
33.图2a示意性地示例了实施方式所涉及的两个对象物之间的位置关系的一例。
34.图2b示意性地示例了实施方式所涉及的两个对象物之间的位置关系的一例。
35.图3示意性地示例了实施方式所涉及的第一模型生成装置的硬件构成的一例。
36.图4示意性地示例了实施方式所涉及的第二模型生成装置的硬件构成的一例。
37.图5示意性地示例了实施方式所涉及的控制装置的硬件构成的一例。
38.图6示意性地示例了实施方式所涉及的机械手的一例。
39.图7示意性地示例了实施方式所涉及的第一模型生成装置的软件构成的一例。
40.图8示意性地示例了实施方式所涉及的第二模型生成装置的软件构成的一例。
41.图9示意性地示例了实施方式所涉及的控制装置的软件构成的一例。
42.图10示例了实施方式所涉及的第一模型生成装置的处理顺序的一例。
43.图11示例了实施方式所涉及的第二模型生成装置的处理顺序的一例。
44.图12a示意性地示例了实施方式所涉及的任务空间的一例。
45.图12b示意性地示例了实施方式所涉及的任务空间的一例。
46.图12c示意性地示例了实施方式所涉及的任务空间的一例。
47.图13示意性地示例了实施方式所涉及的推理模型的构成及生成方法的一例。
48.图14示意性地示例了实施方式所涉及的推理模型的构成及生成方法的一例。
49.图15a示意性地示例了实施方式所涉及的学习数据的一例。
50.图15b示意性地示例了实施方式所涉及的推理模型的构成的一例。
51.图16a示例了与实施方式所涉及的基于控制装置的机械手的动作控制相关的处理顺序的一例。
52.图16b示例了与实施方式所涉及的基于控制装置的机械手的动作控制相关的处理顺序的一例。
53.图17示例了实施方式所涉及的各要素的计算过程的一例。
54.图18示意性地示例了实施方式所涉及的各对象物的位置关系。
55.图19a示意性地示出了末端执行器未保持工件时的各关节与手指的关系的一例。
56.图19b示意性地示出了末端执行器保持工件时的各关节与手指的关系的一例。
57.图20示例了与实施方式所涉及的控制装置的推定模型的参数调整相关的处理顺序的一例。
58.图21示例了与实施方式所涉及的控制装置的推定模型的参数调整相关的处理顺序的一例。
59.图22示意性地示例了在接触的边界面上获取边界值的场景的一例。
60.图23示意性地示例了控制时机与调整时机的关系的一例。
61.图24示意性地示例了按每个坐标点保持表示两个对象物是否接触的值的方式的一例。
62.图25示例了与变形例所涉及的基于控制装置的目标确定相关的子程序的处理顺序的一例。
具体实施方式
63.以下,基于附图对本发明的一方面所涉及的实施方式(以下,也表述为“本实施方式”)进行说明。其中,以下说明的本实施方式在所有方面只不过是本发明的示例而已。当然可以在不脱离本发明的范围的情况下进行各种改良和变形。即,在实施本发明时,也可以适当采用与实施方式相应的具体构成。需要说明的是,在本实施方式中,通过自然语言对所出现的数据进行了说明,更具体而言,通过计算机可识别的模拟语言、命令、参数、机器语言等进行指定。
64.§
1应用例
65.首先,使用图1对应用本发明的场景的一例进行说明。图1示意性地示例了本发明的应用场景的一例。如图1所示,本实施方式所涉及的控制系统100具备第一模型生成装置1、第二模型生成装置2及控制装置3。第一模型生成装置1、第二模型生成装置2及控制装置3可以经由网络相互连接。网络的种类例如可以从因特网、无线通信网、移动通信网、电话网及专用网等中适当选择。
66.《第一模型生成装置》
67.本实施方式所涉及的第一模型生成装置1是构成为生成用于判定在对象的位置关系中两个对象物是否相互接触的判定模型50的计算机。具体而言,本实施方式所涉及的第一模型生成装置1获取多个学习数据集121,该多个学习数据集121由表示两个对象物之间的位置关系的训练数据122及表示在该位置关系中两个对象物是否相互接触的正确数据123的组合分别构成。
68.在本实施方式中,两个对象物之间的位置关系由相对坐标来表现。相对坐标是从一个对象物观察另一个对象物时的坐标。可以将两个对象物中的任一个选择为相对坐标的基准。“坐标”可以包括位置及姿势中的至少一个。在三维空间中,位置可以由前后、左右及上下三个轴来表现,姿势可以由各轴的旋转(翻滚、俯仰、偏摆)来表现。在本实施方式中,相对坐标可以由三维的相对位置及三维的相对姿势这六维来表现。需要说明的是,相对坐标的维数可以不限于六维,可以适当削减。
69.另外,本实施方式所涉及的第一模型生成装置1使用所获取的多个学习数据集121,实施判定模型50的机器学习。实施机器学习由对于各学习数据集121训练判定模型50,以使对于训练数据122的输入,输出适合于对应的正确数据123的输出值而构成。通过该机器学习,能够构建掌握了判定在对象的位置关系中两个对象物是否相互接触的能力的学习完毕的判定模型50。
70.在本实施方式中,学习完毕的判定模型50用于在具备末端执行器t的机械手4、工件w及其他工件g存在的空间中,判定在工件w及末端执行器t之间是否产生接触、以及在工件w及其他工件g之间是否产生接触。末端执行器t、工件w及其他工件g是“对象物”的一例。末端执行器t、工件w及其他工件g的种类各种各样,也可以不特别限定,可以根据任务适当选择。末端执行器t例如可以是夹具、吸引器、螺丝刀等。工件w例如可以是连接器、钉等。其他工件g例如可以是插座、孔等。其他工件g是工件w的组装目的地的对象物的一例。通过末端执行器t保持工件w,例如可以是通过夹具把持工件,通过吸引器吸引保持工件,在螺丝刀的前端保持工件等。
71.更详细而言,作为一例,本实施方式所涉及的机械手4执行通过末端执行器t保持工件w,并将所保持的工件w组装到其他工件g的任务。该任务可以分为:通过末端执行器t保持工件w的第一任务、及将所保持的工件w搬运到其他工件g的第二任务这两个。在执行使末端执行器t移动并保持工件w的第一任务的场景中,学习完毕的判定模型50用于判定在工件w及末端执行器t之间是否产生无用的接触。另外,在保持工件w之后,在执行使末端执行器t移动并将所保持的工件w搬运到其他工件g的第二任务的场景中,学习完毕的判定模型50用于判定在工件w及其他工件g之间是否产生无用的接触。
72.即,在本实施方式中,通过学习完毕的判定模型50判定是否产生接触的两个对象物中的至少任一个是通过机械手4的动作而移动的对象。可以仅两个对象物中的任一方是通过机械手4的动作而移动的对象,或者也可以两个对象物双方都是通过机械手4的动作而移动的对象。其中,第一模型生成装置1的应用对象也可以不限于这样的例子。第一模型生成装置1可以应用于判定两个对象物的接触的所有场景。
73.需要说明的是,如上所述,在存在多个判定是否接触的对象的情况下,也可以准备判定在各个不同的对象物之间是否产生接触的多个学习完毕的判定模型50。或者,学习完
毕的判定模型50例如也可以构成为进一步接收对象物的种类、对象物的识别符等表示对象物的条件的信息的输入,来判定在与所输入的条件对应的两个对象物之间是否产生接触。也可以采用任一种方法。以下,为了便于说明,不区分学习完毕的判定模型50的判定对象而进行说明。
74.《第二模型生成装置》
75.本实施方式所涉及的第二模型生成装置2是构成为在控制机械手4的动作时,生成用于确定赋予机械手4的目标的任务状态的推理模型55的计算机。本实施方式所涉及的机械手4能够在存在第一对象物及第二对象物的环境下,执行相对于第二对象物移动第一对象物的任务。上述第一任务及第二任务是“相对于第二对象物移动第一对象物的任务”的一例。在执行第一任务的场景中,末端执行器t是第一对象物的一例,工件w是第二对象物的一例。另外,在执行第二任务的场景中,工件w是第一对象物的一例,其他工件g是第二对象物的一例。在本实施方式中,任务状态由第一对象物及第二对象物(即,两个对象物)之间的位置关系规定。
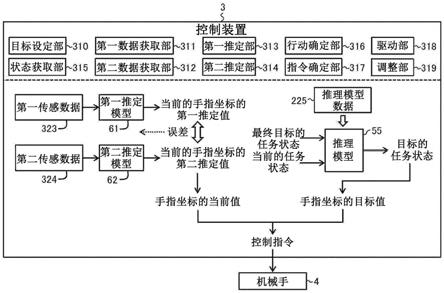
76.这里,进一步使用图2a及图2b,对由第一对象物及第二对象物之间的位置关系规定任务状态的方法的具体例进行说明。图2a示意性地示例了在执行上述第一任务的场景中的末端执行器t及工件w之间的位置关系的一例。图2b示意性地示例了在执行上述第二任务的场景中的工件w及其他工件g之间的位置关系的一例。如上所述,在本实施方式中,两个对象物之间的位置关系由相对坐标来表现。
77.在本实施方式中,如图2a所示,如执行第一任务的场景等所示,在末端执行器t未保持工件w期间,末端执行器t的关注点t0被作为机械手4的手指处理。在第一任务中,工件w是末端执行器t移动的目标物。末端执行器t与工件w之间的位置关系由工件w相对于末端执行器t的相对坐标rc1来表现。相对坐标rc1表示从将末端执行器t的关注点t0作为原点的局部坐标系ct观察的、将工件w的关注点w0作为原点的局部坐标系cw。在本实施方式中,执行第一任务的场景中的机械手4的任务状态由该相对坐标rc1规定。
78.另一方面,如图2b所示,如执行第二任务的场景等所示,在末端执行器t保持工件w期间,工件w的关注点w0被作为机械手4的手指处理。在第二任务中,其他工件g是末端执行器t移动的目标物。其他工件g是工件w的组装目的地的对象物的一例。工件w与其他工件g之间的位置关系由其他工件g相对于工件w的相对坐标rc2来表现。相对坐标rc2表示从将工件w的关注点w0作为原点的局部坐标系cw观察的、将其他工件g的关注点g0作为原点的局部坐标系cg。在本实施方式中,执行第二任务的场景中的机械手4的任务状态由该相对坐标rc2规定。
79.即,在本实施方式中,在执行第一任务及第二任务双方的场景中,任务状态由机械手4的手指及目标物之间的位置关系(在本实施方式中为相对坐标)规定。机械手4的手指相当于第一对象物,目标物相当于第二对象物。由此,能够将第一任务及第二任务一并作为相对于目标物移动机械手4的手指的任务来把握。因此,根据本实施方式,能够简化机械手4的控制处理,由此,能够降低生成或示教机械手4的动作的成本。
80.需要说明的是,各关注点(t0、w0、g0)可以任意设定。另外,相对坐标的赋予方法也可以不限于上述那样的例子,可以根据实施方式适当确定。例如,也可以反转各相对坐标(rc1、rc2)的关系,以使相对坐标rc1表示从将工件w的关注点w0作为原点的局部坐标系cw
观察的、将末端执行器t的关注点t0作为原点的局部坐标系ct等。另外,移动手指也可以不限于使手指接近目标物,可以根据实施方式适当确定。移动手指例如可以是使手指远离目标物、以目标物为基准将手指移动到规定的位置等。
81.本实施方式所涉及的第二模型生成装置2通过将表示第一对象物及第二对象物的对象的任务状态的信息赋予学习完毕的判定模型50,来判定在对象的任务状态下第一对象物与第二对象物是否相互接触。本实施方式所涉及的第二模型生成装置2利用基于该学习完毕的判定模型50的判定结果,生成构成为确定接下来要迁移的目标的任务状态,以使第一对象物不与第二对象物接触的推理模型55。
82.《控制装置》
83.本实施方式所涉及的控制装置3是构成为控制机械手4的动作的计算机。具体而言,首先,本实施方式所涉及的控制装置3从观测机械手4的手指的第一传感器系统获取第一传感数据。然后,本实施方式所涉及的控制装置3利用第一推定模型,根据所获取的第一传感数据,计算观测空间内的手指的当前坐标的第一推定值。另外,本实施方式所涉及的控制装置3从观测机械手4的手指的第二传感器系统获取第二传感数据。然后,本实施方式所涉及的控制装置3利用第二推定模型,根据所获取的第二传感数据,计算观测空间内的手指的当前坐标的第二推定值。计算手指的当前坐标的各推定值相当于推定手指的坐标(以下,也记载为“手指坐标”)的当前值。
84.各传感器系统适当构成为具备一个以上的传感器,以观测机械手4的手指。在本实施方式中,第一传感器系统由用于测定各关节的角度的编码器s2及用于测定作用于末端执行器t的力的触觉传感器s3构成。由编码器s2及触觉传感器s3得到的测定数据(角度数据、压力分布数据)是第一传感数据的一例。另外,第二传感器系统由照相机s1构成。由照相机s1得到的图像数据是第二传感数据的一例。本实施方式所涉及的控制装置3利用各推定模型,根据从各传感器系统得到的传感数据计算当前的手指坐标的各推定值。
85.机械手4的手指坐标的真值为一个。如果在根据各传感器系统的计算过程中没有噪声,并且各推定模型的参数适当,则第一推定值和第二推定值一致。与此相对,由于产生与各传感器系统相应的噪声,第一推定值和第二推定值可能相互不同。因此,本实施方式所涉及的控制装置3计算第一推定值及第二推定值之间的误差的梯度,并基于计算出的梯度,调整第一推定模型及第二推定模型中的至少一方的参数的值,以使误差变小。由此,能够期待计算出的各推定值接近真值。
86.本实施方式所涉及的控制装置3基于第一推定值及第二推定值中的至少一方,确定赋予机械手4的控制指令,以使手指的坐标接近目标值。另外,本实施方式所涉及的控制装置3通过将所确定的控制指令赋予机械手4来驱动机械手4。由此,本实施方式所涉及的控制装置3控制机械手4的动作。
87.需要说明的是,确定手指坐标的目标值的方法也可以不特别限定,可以根据实施方式适当选择。在本实施方式中,为了确定手指坐标的目标,能够利用上述推理模型55。即,本实施方式所涉及的控制装置3获取机械手4的当前的任务状态。如上所述,任务状态由机械手4的手指及目标物之间的位置关系规定。本实施方式所涉及的控制装置3利用上述推理模型55,相对于所获取的当前的任务状态来确定接下来要迁移的目标的任务状态,以接近最终目标的任务状态。然后,本实施方式所涉及的控制装置3根据接下来要迁移的目标的任
务状态计算手指坐标的目标值。由此,在本实施方式中,在执行任务的过程中,能够适当地确定手指坐标的目标值。
88.《作用效果》
89.如上所述,在本实施方式所涉及的控制装置3中,调整第一推定模型及第二推定模型中的至少一方的参数,以使相互的推定结果(推定值)接近一个值。通过该调整,能够期待基于各推定模型的手指的坐标的推定精度的改善。因此,根据该构成,能够改善基于各推定模型的手指的坐标的推定精度,由此,能够实现控制机械手的手指的坐标的精度的提高。
90.另外,在机械手的现有的控制方法中,对于所执行的任务,将赋予机械手的时间序列的控制指令直接建立关联。即,在现有的控制方法中,通过控制指令的序列直接记述所执行的任务。因此,在执行任务的环境及对象物中的至少一方稍微变化的情况下,学习结果无法应对该变化,存在无法适当地执行该任务的可能性。
91.例如,假设向机械手示教通过末端执行器保持工件的任务的场景。在这种情况下,如果工件正确地配置在对象地点,则机械手基于学习结果,能够通过末端执行器保持工件。另一方面,在工件的姿势与学习时不同,或者工件配置在与学习时不同的位置的情况下,通过末端执行器保持工件的坐标发生变化。由此,机械手在该场景中应该执行的任务的内容实质上发生变化。因此,在根据学习结果得到的控制指令的序列中,机械手存在无法通过末端执行器适当地保持工件的可能性。
92.如此,在现有的控制方法中,存在如下问题:在执行任务的环境及对象物中的至少一方稍微变化的情况下,学习结果无法应对该变化,如果不新学习该任务,则存在机械手无法适当地执行该任务的可能性。起因于此,为了使机械手通用地进行动作,即使是相同的任务,也要针对每个不同的状态学习控制指令,向机械手示教任务所需的成本依然高。
93.与此相对,在本实施方式中,通过机械手4执行的任务的状态由末端执行器t、工件w、其他工件g等对象物之间的相对关系,具体而言,由对象物间的位置关系来表现。由此,赋予机械手4的控制指令不是与任务直接建立关联,而是与对象物间的相对位置关系的变化量建立关联。即,能够不依赖于任务的内容,对于使对象物的相对位置关系发生变化,来生成或示教赋予机械手4的时间序列的控制指令。例如,在上述例子中,即使工件的坐标发生变化,在把握末端执行器与工件之间的位置关系时,也考虑该工件的坐标的变化。因此,机械手能够基于学习结果适当地保持工件。因此,根据本实施方式,能够提高执行所掌握的任务的能力的通用性,由此,能够降低向机械手4示教任务所需的成本。
94.进而,本实施方式所涉及的第一模型生成装置1通过机器学习生成用于判定在对象的位置关系中两个对象物是否接触的判定模型50。根据通过机器学习生成的学习完毕的判定模型50,即使以连续值赋予对象的位置关系(在本实施方式中为相对坐标),也能够不随着判定模型50的数据量的大幅增加,而以该位置关系判定两个对象物是否相互接触。因此,根据本实施方式,能够大幅降低表现两个对象物接触的边界的信息的数据量。
95.§
2构成例
96.[硬件构成]
[0097]
《第一模型生成装置》
[0098]
下面,使用图3对本实施方式所涉及的第一模型生成装置1的硬件构成的一例进行说明。图3示意性地示例了本实施方式所涉及的第一模型生成装置1的硬件构成的一例。
[0099]
如图3所示,本实施方式所涉及的第一模型生成装置1是与控制部11、存储部12、通信接口13、外部接口14、输入装置15、输出装置16及驱动器17电连接的计算机。需要说明的是,在图3中,将通信接口及外部接口记载为“通信i/f”及“外部i/f”。
[0100]
控制部11包括作为硬件处理器的cpu(central processing unit:中央处理单元)、ram(random access memory:随机存取存储器)、rom(read only memory:只读存储器)等,构成为基于程序及各种数据执行信息处理。存储部12是存储器的一例,例如由硬盘驱动器、固态驱动器等构成。在本实施方式中,存储部12存储模型生成程序81、cad(computer-aided design:计算机辅助设计)数据120、多个学习数据集121及学习结果数据125等各种信息。
[0101]
模型生成程序81是用于使第一模型生成装置1执行与判定模型50的机器学习相关的后述的信息处理(图10)的程序。模型生成程序81包括该信息处理的一系列命令。cad数据120包括表示各对象物(末端执行器t、工件w、其他工件g)的模型(例如三维模型)等的几何学构成的构成信息。cad数据120可以由公知的软件生成。多个学习数据集121用于判定模型50的机器学习。学习结果数据125表示与通过机器学习生成的学习完毕的判定模型50相关的信息。学习结果数据125作为执行模型生成程序81的结果而得到。详细情况将在后面叙述。
[0102]
通信接口13例如是有线lan(local area network:局域网)模块、无线lan模块等,是用于进行经由网络的有线或无线通信的接口。第一模型生成装置1通过利用该通信接口13,能够与其他信息处理装置(例如第二模型生成装置2、控制装置3)进行经由网络的数据通信。
[0103]
外部接口14例如是usb(universal serial bus:通用串行总线)端口、专用端口等,是用于与外部装置连接的接口。外部接口14的种类及数量可以根据所连接的外部装置的种类及数量适当选择。第一模型生成装置1为了判定在实际空间中对象物是否接触,也可以经由外部接口14与机械手4及照相机s1连接。
[0104]
输入装置15例如是用于进行鼠标、键盘等的输入的装置。另外,输出装置16例如是用于进行显示器、扬声器等的输出的装置。操作者通过利用输入装置15及输出装置16,能够操作第一模型生成装置1。
[0105]
驱动器17例如是cd驱动器、dvd驱动器等,是用于读入存储在存储介质91中的程序的驱动装置。驱动器17的种类可以根据存储介质91的种类适当选择。上述模型生成程序81、cad数据120及多个学习数据集121中的至少任一个也可以存储在存储介质91中。
[0106]
存储介质91是以计算机及其他装置、机械等能够读取所存储的程序等信息的方式,通过电、磁、光、机械或化学作用存储该程序等信息的介质。第一模型生成装置1也可以从该存储介质91获取上述模型生成程序81、cad数据120及多个学习数据集121中的至少任一个。
[0107]
这里,在图3中,作为存储介质91的一例,示例了cd、dvd等盘型的存储介质。但是,存储介质91的种类并不限于盘型,也可以是盘型以外的类型。作为盘型以外的存储介质,例如可列举闪存等半导体存储器。
[0108]
需要说明的是,关于第一模型生成装置1的具体的硬件构成,能够根据实施方式适当地进行构成要素的省略、替换及追加。例如,控制部11也可以包括多个硬件处理器。硬件
处理器可以由微处理器、fpga(field-programmable gate array:现场可编程门阵列)、dsp(digital signal processor:数字信号处理器)等构成。存储部12也可以由控制部11中包括的ram及rom构成。也可以省略通信接口13、外部接口14、输入装置15、输出装置16及驱动器17中的至少任一个。第一模型生成装置1也可以由多台计算机构成。在这种情况下,各计算机的硬件构成可以一致,也可以不一致。另外,第一模型生成装置1除了是设计为所提供的服务专用的信息处理装置以外,也可以是通用的服务器装置、pc(personal computer:个人计算机)等。
[0109]
《第二模型生成装置》
[0110]
下面,使用图4对本实施方式所涉及的第二模型生成装置2的硬件构成的一例进行说明。图4示意性地示例了本实施方式所涉及的第二模型生成装置2的硬件构成的一例。
[0111]
如图4所示,本实施方式所涉及的第二模型生成装置2是与控制部21、存储部22、通信接口23、外部接口24、输入装置25、输出装置26及驱动器27电连接的计算机。需要说明的是,在图4中,与图3同样地,将通信接口及外部接口记载为“通信i/f”及“外部i/f”。
[0112]
第二模型生成装置2的控制部21~驱动器27可以分别与上述第一模型生成装置1的控制部11~驱动器17同样地构成。即,控制部21包括作为硬件处理器的cpu、ram、rom等,构成为基于程序及数据执行各种信息处理。存储部22例如由硬盘驱动器、固态驱动器等构成。存储部22存储模型生成程序82、cad数据220、学习结果数据125、学习数据223、推理模型数据225等各种信息。
[0113]
模型生成程序82是用于使第二模型生成装置2执行与用于推理目标的任务状态的推理模型55的生成相关的后述的信息处理(图11)的程序。模型生成程序82包括该信息处理的一系列命令。cad数据220与上述cad数据120同样地,包括表示各对象物(末端执行器t、工件w、其他工件g)的模型等的几何学构成的构成信息。学习结果数据125用于学习完毕的判定模型50的设定。学习数据223用于推理模型55的生成。推理模型数据225表示与所生成的推理模型55相关的信息。推理模型数据225作为执行模型生成程序82的结果而得到。详细情况将在后面叙述。
[0114]
通信接口23例如是有线lan模块、无线lan模块等,是用于进行经由网络的有线或无线通信的接口。第二模型生成装置2通过利用该通信接口23,能够与其他信息处理装置(例如第一模型生成装置1、控制装置3)进行经由网络的数据通信。
[0115]
外部接口24例如是usb端口、专用端口等,是用于与外部装置连接的接口。外部接口24的种类及数量可以根据所连接的外部装置的种类及数量适当选择。第二模型生成装置2为了在实际空间中再现任务状态,也可以经由外部接口24与机械手4及照相机s1连接。
[0116]
输入装置25例如是用于进行鼠标、键盘等的输入的装置。另外,输出装置26例如是用于进行显示器、扬声器等的输出的装置。操作者通过利用输入装置25及输出装置26,能够操作第二模型生成装置2。
[0117]
驱动器27例如是cd驱动器、dvd驱动器等,是用于读入存储在存储介质92中的程序的驱动装置。存储介质92的种类与上述存储介质91同样地,可以是盘型,或者也可以是盘型以外的类型。上述模型生成程序82、cad数据220、学习结果数据125及学习数据223中的至少任一个也可以存储在存储介质92中。另外,第二模型生成装置2也可以从存储介质92中获取上述模型生成程序82、cad数据220、学习结果数据125及学习数据223中的至少任一个。
[0118]
需要说明的是,关于第二模型生成装置2的具体的硬件构成,能够根据实施方式适当地进行构成要素的省略、替换及追加。例如,控制部21也可以包括多个硬件处理器。硬件处理器可以由微处理器、fpga、dsp等构成。存储部22也可以由控制部21中包括的ram及rom构成。也可以省略通信接口23、外部接口24、输入装置25、输出装置26及驱动器27中的至少任一个。第二模型生成装置2也可以由多台计算机构成。在这种情况下,各计算机的硬件构成可以一致,也可以不一致。另外,第二模型生成装置2除了是设计为所提供的服务专用的信息处理装置以外,也可以是通用的服务器装置、通用的pc等。
[0119]
《控制装置》
[0120]
下面,使用图5对本实施方式所涉及的控制装置3的硬件构成的一例进行说明。图5示意性地示例了本实施方式所涉及的控制装置3的硬件构成的一例。
[0121]
如图5所示,本实施方式所涉及的控制装置3是与控制部31、存储部32、通信接口33、外部接口34、输入装置35、输出装置36及驱动器37电连接的计算机。需要说明的是,在图5中,与图3及图4同样地,将通信接口及外部接口记载为“通信i/f”及“外部i/f”。
[0122]
控制装置3的控制部31~驱动器37可以分别与上述第一模型生成装置1的控制部11~驱动器17同样地构成。即,控制部31包括作为硬件处理器的cpu、ram、rom等,构成为基于程序及数据执行各种信息处理。存储部32例如由硬盘驱动器、固态驱动器等构成。存储部32存储控制程序83、cad数据320、机器人数据321、推理模型数据225等各种信息。
[0123]
控制程序83是用于使控制装置3执行与机械手4的动作的控制相关的后述的信息处理(图16a、图16b、图20及图21)的程序。控制程序83包括该信息处理的一系列命令。cad数据320与上述cad数据120同样地,包括表示各对象物(末端执行器t、工件w、其他工件g)的模型等的几何学构成的构成信息。机器人数据321包括各关节的参数等表示机械手4的构成的构成信息。推理模型数据225用于所生成的推理模型55的设定。详细情况将在后面叙述。
[0124]
通信接口33例如是有线lan模块、无线lan模块等,是用于进行经由网络的有线或无线通信的接口。控制装置3通过利用该通信接口33,能够与其他信息处理装置(例如第一模型生成装置1、第二模型生成装置2)进行经由网络的数据通信。
[0125]
外部接口34例如是usb端口、专用端口等,是用于与外部装置连接的接口。外部接口34的种类及数量可以根据所连接的外部装置的种类及数量适当选择。控制装置3可以经由外部接口34与照相机s1及机械手4连接。在本实施方式中,机械手4具备测定各关节的角度的编码器s2、以及测定作用于末端执行器t的力的触觉传感器s3。
[0126]
照相机s1、编码器s2及触觉传感器s3各自的种类也可以不特别限定,可以根据实施方式适当确定。照相机s1例如可以是构成为获取rgb图像的一般的数码照相机、构成为获取深度图像的深度照相机、构成为将红外线量图像化的红外线照相机等。触觉传感器s3例如可以是触觉传感器(tactile sensor)等。
[0127]
控制装置3能够经由外部接口34从各传感器(照相机s1、各编码器s2、触觉传感器s3)获取传感数据。需要说明的是,与照相机s1及机械手4的连接方法也可以不限于这样的例子。例如,在照相机s1及机械手4具备通信接口的情况下,控制装置3也可以经由通信接口33与照相机s1及机械手4连接。
[0128]
输入装置35例如是用于进行鼠标、键盘等的输入的装置。另外,输出装置36例如是用于进行显示器、扬声器等的输出的装置。操作者通过利用输入装置35及输出装置36,能够
操作控制装置3。
[0129]
驱动器37例如是cd驱动器、dvd驱动器等,是用于读入存储在存储介质93中的程序的驱动装置。存储介质93的种类与上述存储介质91同样地,可以是盘型,或者也可以是盘型以外的类型。上述控制程序83、cad数据320、机器人数据321及推理模型数据225中的至少任一个也可以存储在存储介质93中。另外,控制装置3也可以从存储介质93中获取上述控制程序83、cad数据320、机器人数据321及推理模型数据225中的至少任一个。
[0130]
需要说明的是,关于控制装置3的具体的硬件构成,能够根据实施方式适当地进行构成要素的省略、替换及追加。例如,控制部31也可以包括多个硬件处理器。硬件处理器可以由微处理器、fpga、dsp等构成。存储部32也可以由控制部31中包括的ram及rom构成。也可以省略通信接口33、外部接口34、输入装置35、输出装置36及驱动器37中的至少任一个。控制装置3也可以由多台计算机构成。在这种情况下,各计算机的硬件构成可以一致,也可以不一致。另外,控制装置3除了是设计为所提供的服务专用的信息处理装置以外,也可以是通用的服务器装置、通用的pc、plc(programmable logic controller:可编程逻辑控制器)等。
[0131]
《机械手》
[0132]
下面,使用图6对本实施方式所涉及的机械手4的硬件构成的一例进行说明。图6示意性地示例了本实施方式所涉及的机械手4的硬件构成的一例。
[0133]
本实施方式所涉及的机械手4是六轴的垂直多关节型的工业用机器人,具有底座部40及六个关节部41~46。各关节部41~46通过内置伺服电机(未图示)而构成为能够以各轴为中心旋转。第一关节部41与底座部40连接,使前端侧的部分绕底座的轴旋转。第二关节部42与第一关节部41连接,使前端侧的部分沿前后方向旋转。第三关节部43经由连杆491与第二关节部42连接,使前端侧的部分沿上下方向旋转。第四关节部44经由连杆492与第三关节部43连接,使前端侧的部分绕连杆492的轴旋转。第五关节部45经由连杆493与第四关节部44连接,使前端侧的部分沿上下方向旋转。第六关节部46经由连杆494与第五关节部45连接,使前端侧的部分绕连杆494的轴旋转。在第六关节部46的前端侧与触觉传感器s3一并安装有末端执行器t。
[0134]
在各关节部41~46中进一步内置有编码器s2。各编码器s2构成为测定各关节部41~46的角度(控制量)。各编码器s2的测定数据(角度数据)能够用于各关节部41~46的角度的控制。另外,触觉传感器s3构成为检测作用于末端执行器t的力。触觉传感器s3的测定数据(压力分布数据)可以用于推定通过末端执行器t保持的工件w的位置及姿势,或者检测是否有异常的力作用于末端执行器t。
[0135]
需要说明的是,机械手4的硬件构成也可以不限于这样的例子。关于机械手4的具体的硬件构成,能够根据实施方式适当地进行构成要素的省略、替换及追加。例如,为了观测控制量或其他属性,机械手4也可以具备编码器s2及触觉传感器s3以外的传感器。例如,机械手4也可以进一步具备力矩传感器。在这种情况下,机械手4可以通过力矩传感器测定作用于末端执行器t的力,并基于力矩传感器的测定值进行控制,以使过剩的力不作用于末端执行器t。另外,机械手4的轴数也可以不限于六轴。机械手4可以采用公知的工业用机器人。
[0136]
[软件构成]
[0137]
《第一模型生成装置》
[0138]
下面,使用图7对本实施方式所涉及的第一模型生成装置1的软件构成的一例进行说明。图7示意性地示例了本实施方式所涉及的第一模型生成装置1的软件构成的一例。
[0139]
第一模型生成装置1的控制部11将存储在存储部12中的模型生成程序81在ram中展开。然后,控制部11通过cpu解释及执行在ram中展开的模型生成程序81中包括的命令,来控制各构成要素。由此,如图7所示,本实施方式所涉及的第一模型生成装置1作为具备数据获取部111、机器学习部112及保存处理部113作为软件模块的计算机进行动作。即,在本实施方式中,第一模型生成装置1的各软件模块由控制部11(cpu)实现。
[0140]
数据获取部111获取多个学习数据集121。各学习数据集121由表示两个对象物之间的位置关系的训练数据122及表示在该位置关系中两个对象物是否相互接触的正确数据123的组合构成。训练数据122被用作机器学习的输入数据。正确数据123被用作机器学习的监督信号(标签)。训练数据122及正确数据123的形式也可以不特别限定,可以根据实施方式适当选择。例如,在训练数据122中,可以直接利用两个对象物之间的相对坐标,或者也可以利用通过将相对坐标变换为特征量而得到的值。根据cad数据120,能够判定在对象的位置关系中对象的两个对象物是否相互接触。因此,通过利用cad数据120,能够生成各学习数据集121。
[0141]
机器学习部112利用所获取的多个学习数据集121,实施判定模型50的机器学习。实施机器学习由对于各学习数据集121训练判定模型50,以使对于训练数据122的输入,输出适合于对应的正确数据123的输出值而构成。通过该机器学习,能够构建掌握了判定两个对象物是否相互接触的能力的学习完毕的判定模型50。保存处理部113生成与所构建的学习完毕的判定模型50相关的信息作为学习结果数据125,并将所生成的学习结果数据125保存在规定的存储区域中。
[0142]
(判定模型的构成)
[0143]
下面,对判定模型50的构成的一例进行说明。本实施方式所涉及的判定模型50由用于深度学习的多层结构的神经网络构成。在图7的例子中,判定模型50由三层结构的全连接型神经网络构成。判定模型50具备输入层501、中间(隐藏)层502及输出层503。其中,判定模型50的结构也可以不限于这样的例子,可以根据实施方式适当确定。例如,判定模型50具备的中间层的数量也可以不限于一个,也可以是两个以上。或者,也可以省略中间层502。
[0144]
各层501~503中包括的神经元(节点)的数量可以根据实施方式适当确定。例如,输入层501的神经元的数量可以根据表现两个对象物之间的位置关系的相对坐标的维数来确定。另外,输出层503的神经元的数量可以根据表现两个对象物是否相互接触的方法来确定。例如,在由一个数值来表现两个对象物是否相互接触(例如由[0、1]的范围的数值来表现)的情况下,输出层503的神经元的数量可以是一个。另外,例如在由表示接触的概率的第一数值及表示不接触的概率的第二数值这两个数值来表现两个对象是否相互接触的情况下,输出层503的神经元的数量可以是两个。
[0145]
相邻的层的神经元之间适当连接。在本实施方式中,各神经元与相邻的层的所有神经元连接。但是,各神经元的连接关系也可以不限于这样的例子,可以根据实施方式适当设定。各连接设定有权重(连接权重)。各神经元设定有阈值,基本上根据各输入与各权重之积的和是否超过阈值来确定各神经元的输出。阈值也可以由激活函数来表现。在这种情况
下,通过将各输入与各权重之积的和输入到激活函数,并执行激活函数的运算,来确定各神经元的输出。激活函数的种类也可以不特别限定,可以根据实施方式适当选择。各层501~503中包括的各神经元间的连接的权重及各神经元的阈值是判定模型50的运算参数的一例。
[0146]
在本实施方式中,机器学习部112使用多个学习数据集121实施由上述神经网络构成的判定模型50的机器学习。具体而言,机器学习部112通过调整判定模型50的运算参数的值,来训练判定模型50的运算参数,以使对于各学习数据集121,当将训练数据122输入到输入层501时,从输出层503输出适合于正确数据123的输出值。因此,机器学习部112能够生成掌握了判定两个对象物是否相互接触的能力的学习完毕的判定模型50。
[0147]
保存处理部113生成表示所构建的学习完毕的判定模型50的结构及运算参数的信息作为学习结果数据125。然后,保存处理部113将所生成的学习结果数据125保存在规定的存储区域中。需要说明的是,学习结果数据125的内容只要能够再现学习完毕的判定模型50即可,也可以不限于这样的例子。例如,在各装置间使判定模型50的结构共同化的情况下,在学习结果数据125中可以省略表示判定模型50的结构的信息。
[0148]
《第二模型生成装置》
[0149]
下面,使用图8对本实施方式所涉及的第二模型生成装置2的软件构成的一例进行说明。图8示意性地示例了本实施方式所涉及的第二模型生成装置2的软件构成的一例。
[0150]
第二模型生成装置2的控制部21将存储在存储部22中的模型生成程序82在ram中展开。然后,控制部21通过cpu解释及执行在ram中展开的模型生成程序82中包括的命令,来控制各构成要素。由此,如图8所示,本实施方式所涉及的第二模型生成装置2作为具备接触判定部211、数据收集部212、模型生成部213及保存处理部214作为软件模块的计算机进行动作。即,在本实施方式中,与上述第一模型生成装置1同样地,第二模型生成装置2的各软件模块由控制部21(cpu)实现。
[0151]
接触判定部211通过保持学习结果数据125而具备学习完毕的判定模型50。接触判定部211参照学习结果数据125,进行学习完毕的判定模型50的设定。学习完毕的判定模型50通过上述机器学习掌握判定第一对象物与第二对象物是否相互接触的能力。接触判定部211通过将表示第一对象物及第二对象物的对象的任务状态的信息赋予学习完毕的判定模型50,来判定在对象的任务状态下第一对象物与第二对象物是否相互接触。
[0152]
数据收集部212及模型生成部213利用基于学习完毕的判定模型50的判定结果,生成构成为根据最终目标的任务状态及当前的任务状态来确定接下来要迁移的目标的任务状态,以使第一对象物不与第二对象物接触的推理模型55。即,数据收集部212利用学习完毕的判定模型50的判定结果,收集用于推理模型55的生成的学习数据223。在学习数据223的收集中,可以进一步利用cad数据220。模型生成部213使用所收集的学习数据223生成推理模型55。学习数据223及推理模型55的详细情况将在后面叙述。保存处理部214生成与所生成的推理模型55相关的信息作为推理模型数据225,并将所生成的推理模型数据225保存在规定的存储区域中。
[0153]
《控制装置》
[0154]
下面,使用图9对本实施方式所涉及的控制装置3的软件构成的一例进行说明。图9示意性地示例了本实施方式所涉及的控制装置3的软件构成的一例。
[0155]
控制装置3的控制部31将存储在存储部32中的控制程序83在ram中展开。然后,控制部31通过cpu解释及执行在ram中展开的控制程序83中包括的命令,来控制各构成要素。由此,如图9所示,本实施方式所涉及的控制装置3作为具备目标设定部310、第一数据获取部311、第二数据获取部312、第一推定部313、第二推定部314、状态获取部315、行动确定部316、指令确定部317、驱动部318及调整部319作为软件模块的计算机进行动作。即,在本实施方式中,与上述第一模型生成装置1同样地,控制装置3的各软件模块由控制部31(cpu)实现。
[0156]
目标设定部310根据所执行的任务来设定最终目标的任务状态。在本实施方式中,任务状态由所执行的任务中的第一对象物及第二对象物,更详细而言,由机械手4的手指与目标物之间的位置关系规定。在本实施方式中,位置关系由上述相对坐标来表现。“最终目标”是终点(终点),在完成任务的执行的时刻实现。
[0157]
目标物可以根据所执行的任务适当设定。作为一例,在机械手4(末端执行器t)未保持工件w的情况下,目标物可以是工件w。另一方面,在机械手4(末端执行器t)保持工件w的情况下,目标物可以是工件w的组装目的地的对象物(在本实施方式中为其他工件g)。
[0158]
第一数据获取部311从观测机械手4的手指的第一传感器系统获取第一传感数据323。在本实施方式中,第一数据获取部311从各编码器s2及触觉传感器s3获取测定数据作为第一传感数据323。第二数据获取部312从观测机械手4的手指的第二传感器系统获取第二传感数据324。在本实施方式中,第二数据获取部312从照相机s1获取图像数据作为第二传感数据324。
[0159]
第一推定部313利用第一推定模型61,根据所获取的第一传感数据323,计算观测空间内的手指的当前的坐标的第一推定值。第二推定部314利用第二推定模型62,根据所获取的第二传感数据324,计算观测空间内的手指的当前的坐标的第二推定值。调整部319计算第一推定值与第二推定值之间的误差的梯度,并基于计算出的梯度,调整第一推定模型61及第二推定模型62中的至少一方的参数的值,以使误差变小。
[0160]
状态获取部315获取表示机械手4的当前的任务状态的信息。“当前”是控制机械手4的动作的时刻,是确定赋予机械手4的控制指令之前的时刻。
[0161]
行为确定部316对于由所获取的信息表示的当前的任务状态,确定接下来要迁移的目标的任务状态,以接近最终目标的任务状态。“目标”包括最终目标,可以为了实现任务的执行而适当设定。到最终目标为止所设定的目标的数量可以是一个(在这种情况下,仅设定最终目标),也可以是多个。最终目标以外的目标是从任务的起点到到达终点为止经由的经由点。因此,也可以将最终目标简称为“目标(终点)”,将最终目标以外的目标称为“下位目标(子终点)”。下位目标也可以称为“经由点”。“接下来要迁移的目标”是从当前的任务状态起接下来作为目标的任务状态(如果是最终目标以外的目标,则是暂定的任务状态),例如是朝向最终目标,最接近当前的任务状态的目标。
[0162]
在本实施方式中,行动确定部316通过保持推理模型数据225而具备所生成的推理模型55。行动确定部316利用所生成的推理模型55,根据最终目标的任务状态及当前任务状态来确定接下来要迁移的目标的任务状态。
[0163]
指令确定部317基于第一推定值及第二推定值中的至少一方,确定赋予机械手4的控制指令,以使手指的坐标接近目标值。驱动部318通过将所确定的控制指令赋予机械手4
来驱动机械手4。
[0164]
在本实施方式中,控制指令由针对各关节的指令值构成。指令确定部317基于第一推定值及第二推定值中的至少一方,认定机械手4的手指坐标的当前值。另外,指令确定部317根据所确定的接下来要迁移的目标的任务状态,计算手指坐标的目标值。接着,指令确定部317根据手指坐标的当前值及目标值的差分来计算各关节的角度的变化量。然后,指令确定部317基于计算出的各关节的角度的变化量,确定针对各关节的指令值。驱动部318根据所确定的指令值驱动各关节。通过这些处理,本实施方式所涉及的控制装置3控制机械手4的动作。
[0165]
《其他》
[0166]
关于第一模型生成装置1、第二模型生成装置2及控制装置3的各软件模块,在后述的动作例中进行详细说明。需要说明的是,在本实施方式中,对第一模型生成装置1、第二模型生成装置2及控制装置3的各软件模块均由通用的cpu实现的例子进行说明。但是,以上软件模块的一部分或全部也可以由一个或多个专用的处理器实现。另外,关于第一模型生成装置1、第二模型生成装置2及控制装置3各自的软件构成,也可以根据实施方式适当地进行软件模块的省略、替换及追加。
[0167]
§
3动作例
[0168]
[第一模型生成装置]
[0169]
下面,使用图10对第一模型生成装置1的动作例进行说明。图10是示出与基于本实施方式所涉及的第一模型生成装置1的判定模型50的机器学习相关的处理顺序的一例的流程图。以下说明的处理顺序是用于生成判定模型50的模型生成方法的一例。其中,以下说明的各处理顺序只不过是一例而已,各步骤可以尽可能地变更。进而,对于以下说明的各处理顺序,能够根据实施方式适当地进行步骤的省略、替换及追加。
[0170]
(步骤s101)
[0171]
在步骤s101中,控制部11作为数据获取部111进行动作,获取用于判定模型50的机器学习的多个学习数据集121。各学习数据集121由表示两个对象物之间的位置关系的训练数据122及表示在该位置关系中两个对象物是否相互接触的正确数据123的组合构成。
[0172]
生成各学习数据集121的方法也可以不特别限定,可以根据实施方式适当选择。例如,利用cad数据120,在虚拟空间上以各种位置关系配置两个对象物。在本实施方式中,位置关系由相对坐标来表现。另外,在本实施方式中,两个对象物中的至少任一个是通过机械手4的动作而移动的对象。在假设执行上述第一任务的场景的情况下,末端执行器t及工件w分别是各对象物的一例。另外,在假设执行上述第二任务的场景的情况下,通过末端执行器t保持的工件w及其他工件g分别是各对象物的一例。两个对象物中的一个是机械手4的手指,另一个是目标物。各对象物的配置可以由操作者指定,也可以随机确定。或者,也可以通过固定一个对象物的位置且按照规则变更另一个对象物的位置,来实现各种位置关系。赋予另一个对象物的配置的规则可以适当设定。由此,能够获取各位置关系中的相对坐标作为各学习数据集121的训练数据122。另外,在cad数据120中包括各对象物的模型。因此,根据cad数据120,能够判定在对象的位置关系中对象的两个对象物是否相互接触。利用cad数据120,将在各位置关系中判定两个对象物是否相互接触的结果作为正确数据123与对应的训练数据122建立关联。由此,能够生成各学习数据集121。需要说明的是,生成各学习数据
集121的方法也可以不限于这样的例子。也可以通过在实际空间上利用各对象物的实物来生成各学习数据集121。
[0173]
各学习数据集121可以通过计算机的动作自动地生成,也可以通过至少部分地包括操作者的操作来手动地生成。另外,各学习数据集121的生成可以由第一模型生成装置1进行,也可以由第一模型生成装置1以外的其他计算机进行。在由第一模型生成装置1生成各学习数据集121的情况下,控制部11通过自动地或者通过操作者经由输入装置15的操作手动地执行上述一系列处理,来获取多个学习数据集121。另一方面,在由其他计算机生成各学习数据集121的情况下,控制部11例如经由网络、存储介质91等获取由其他计算机生成的多个学习数据集121。在这种情况下,cad数据120也可以从第一模型生成装置1中省略。也可以由第一模型生成装置1生成一部分学习数据集121,由一个或多个其他计算机生成其他学习数据集121。
[0174]
所获取的学习数据集121的份数也可以不特别限定,可以根据实施方式适当选择。当获取多个学习数据集121时,控制部11使处理进入下一步骤s102。
[0175]
(步骤s102)
[0176]
在步骤s102中,控制部11作为机器学习部112进行动作,使用所获取的多个学习数据集121,实施判定模型50的机器学习。在本实施方式中,控制部11通过机器学习训练判定模型50,以使对于各学习数据集121,当将训练数据122输入到输入层501时,从输出层503输出适合于对应的正确数据123的输出值。由此,控制部11构建掌握了判定在对象的位置关系中两个对象物是否相互接触的能力的学习完毕的判定模型50。
[0177]
机器学习的处理顺序可以根据实施方式适当确定。作为一例,控制部11首先准备成为处理对象的判定模型50。所准备的判定模型50的结构(例如层的数量、各层中包括的神经元的数量、邻接的层的神经元之间的连接关系等)、各神经元间的连接的权重的初始值以及各神经元的阈值的初始值可以通过模板赋予,也可以通过操作者的输入赋予。另外,在进行再学习的情况下,控制部11也可以基于通过进行过去的机器学习而得到的学习结果数据来准备判定模型50。
[0178]
接着,控制部11将各学习数据集121中包括的训练数据122用作输入数据,将正确数据123用作监督信号,执行判定模型50(神经网络)的学习处理。在该学习处理中,可以使用批量梯度下降法、随机梯度下降法、小批量梯度下降法等。
[0179]
例如,在第一步骤中,控制部11对于各学习数据集121,将训练数据122输入到判定模型50,执行判定模型50的运算处理。即,控制部11将训练数据122输入到输入层501,从输入侧开始依次进行各层501~503中包括的各神经元的发火判定(即,进行正向传播的运算)。通过该运算处理,控制部11从判定模型50的输出层503获取与判定在由训练数据122所示的位置关系中两个对象物是否接触的结果对应的输出值。
[0180]
在第二步骤中,控制部11基于损失函数计算从输出层503获取的输出值与正确数据123的误差(损失)。损失函数是评价学习模型的输出与正确的差分(即,差异的程度)的函数,从输出层503获取的输出值与正确数据123的差分值越大,通过损失函数计算出的误差的值越大。用于误差的计算的损失函数的种类也可以不特别限定,可以根据实施方式适当选择。
[0181]
在第三步骤中,控制部11通过误差反向传播(back propagation)法,使用计算出
的输出值的误差的梯度,计算判定模型50的各运算参数(各神经元间的连接的权重、各神经元的阈值等)的值的误差。在第四步骤中,控制部11基于计算出的各误差,更新判定模型50的运算参数的值。更新运算参数的值的程度可以通过学习率进行调节。学习率可以通过操作者的指定赋予,也可以作为程序内的设定值赋予。
[0182]
控制部11通过重复上述第一~第四步骤来调整判定模型50的运算参数的值,以使对于各学习数据集121,从输出层503输出的输出值与正确数据123的误差之和变小。例如,控制部11也可以重复上述第一~第四步骤的处理,直到该误差之和变为阈值以下为止。阈值可以根据实施方式适当设定。根据该机器学习的结果,控制部11能够构建训练为对于各学习数据集121,当将训练数据122输入到输入层501时,从输出层503输出适合于对应的正确数据123的输出值的学习完毕的判定模型50。该“适合”也可以包括根据阈值等在输出层503的输出值与监督信号(正确数据123)之间产生可允许的差异。当判定模型50的机器学习完成时,控制部11使处理进入下一步骤s103。
[0183]
(步骤s103)
[0184]
在步骤s103中,控制部11作为保存处理部113进行动作,将与通过机器学习构建的学习完毕的判定模型50相关的信息作为学习结果数据125保存在规定的存储区域中。在本实施方式中,控制部11生成表示通过步骤s102构建的学习完毕的判定模型50的结构及运算参数的信息作为学习结果数据125。然后,控制部11将所生成的学习结果数据125保存在规定的存储区域中。
[0185]
规定的存储区域例如可以是控制部11内的ram、存储部12、外部存储装置、存储介质或它们的组合。存储介质例如可以是cd、dvd等,控制部11也可以经由驱动器17在存储介质中存储学习结果数据125。外部存储装置例如可以是nas(network attached storage:网络附属存储)等数据服务器。在这种情况下,控制部11也可以利用通信接口13,经由网络将学习结果数据125存储在数据服务器中。另外,外部存储装置例如也可以是与第一模型生成装置1连接的外置的存储装置。
[0186]
由此,当学习结果数据125的保存完成时,控制部11结束与学习完毕的判定模型50的生成相关的一系列处理。
[0187]
需要说明的是,所生成的学习结果数据125可以在任意的时机向第二模型生成装置2提供。例如,作为步骤s103的处理或与步骤s103的处理不同地,控制部11也可以将学习结果数据125转发给第二模型生成装置2。第二模型生成装置2也可以通过接收该转发来获取学习结果数据125。另外,例如第二模型生成装置2也可以利用通信接口23,通过经由网络访问第一模型生成装置1或数据服务器,来获取学习结果数据125。另外,例如第二模型生成装置2也可以经由存储介质92来获取学习结果数据125。另外,例如学习结果数据125也可以预先嵌入在第二模型生成装置2中。
[0188]
进而,控制部11也可以通过定期或不定期地重复上述步骤s101~步骤s103的处理,来更新或新生成学习结果数据125。在该重复时,可以适当执行多个学习数据集121中的至少一部分的变更、修正、追加、删除等。另外,控制部11也可以通过每当执行学习处理时向第二模型生成装置2提供更新或新生成的学习结果数据125,来更新第二模型生成装置2保持的学习结果数据125。
[0189]
[第二模型生成装置]
[0190]
下面,使用图11对与基于第二模型生成装置2的推理模型55的生成相关的动作例进行说明。图11是示出与本实施方式所涉及的第二模型生成装置2的推理模型55的生成相关的处理顺序的一例的流程图。需要说明的是,以下说明的各处理顺序只不过是一例而已,各步骤可以尽可能地变更。进而,对于以下说明的各处理顺序,能够根据实施方式适当地进行步骤的省略、替换及追加。
[0191]
(步骤s201)
[0192]
在步骤s201中,关于机械手4执行的任务,控制部21接收最终目标的任务状态的指定。任务状态由第一对象物及第二对象物,更详细而言,由机械手4的手指及目标物之间的位置关系来表现。在本实施方式中,位置关系由相对坐标来表现。
[0193]
指定最终的任务状态下的相对坐标的方法也可以不特别限定,可以根据实施方式适当选择。例如,最终的任务状态下的相对坐标也可以通过经由输入装置25的操作者的输入来直接指定。另外,例如也可以通过操作者的输入来选择所执行的任务,并根据所选择的任务来指定最终的任务状态下的相对坐标。另外,例如也可以利用cad数据220,通过在虚拟空间上将各对象物的模型配置成最终目标位置关系,来指定最终目标中的相对坐标。各对象物的模型的配置可以通过模拟器自动地进行,也可以通过操作者的输入手动地进行。当最终目标的任务状态被指定时,控制部21使处理进入下一步骤s202。
[0194]
(步骤s202~步骤s204)
[0195]
在步骤s202中,控制部21将任意的任务状态设定为起点。设定为起点的任务状态相当于开始执行任务的时刻的任务状态。成为起点的任务状态可以随机设定,或者也可以通过操作者的输入指定。基于操作者的起点的指定方法可以与上述最终目标的指定方法相同。另外,成为起点的任务状态可以通过任意的算法确定。作为一例,也可以通过将各对象物的实物配置在实际空间中,通过照相机对各对象物进行拍摄,来获取拍摄了各对象物的图像数据。然后,也可以通过对得到的图像数据进行图像处理(例如基于cad数据220的匹配),来确定成为起点的任务状态。另外,成为起点的任务状态也可以利用cad数据220来适当确定。
[0196]
在步骤s203中,控制部21作为接触判定部211进行动作,利用学习完毕的判定模型50,判定在设定为起点的任务状态下两个对象物是否相互接触。具体而言,控制部21参照学习结果数据125,进行学习完毕的判定模型50的设定。接着,控制部21将通过步骤s202设定的任务状态的相对坐标输入到学习完毕的判定模型50的输入层501。然后,作为学习完毕的判定模型50的运算处理,控制部21从输入侧开始依次进行各层501~503中包括的各神经元的发火判定。由此,控制部21从学习完毕的判定模型50的输出层503获取与判定在设定为起点的任务状态下两个对象物是否相互接触的结果对应的输出值。
[0197]
在步骤s204中,控制部21基于步骤s203的判定结果,确定处理的分支目的地。在步骤s203中,在判定为在设定为起点的任务状态下两个对象物相互接触的情况下,控制部21将处理返回到步骤s202,再次设定起点的任务状态。另一方面,在判定为在设定为起点的任务状态下两个对象物不相互接触的情况下,控制部21将所设定的起点的任务状态认定为机械手4的当前的任务状态,使处理进入下一步骤s205。
[0198]
图12a示意性地示例了在任务空间sp中通过上述步骤s201~步骤s204的处理设定了起点及最终目标的任务状态的场景的一例。任务空间sp表现规定任务状态的相对坐标的
集合。表示任务空间sp的信息可以保持在第二模型生成装置2中,也可以不保持。属于任务空间sp的各节点(点)与两个对象物之间的相对坐标对应。在图12a的例子中,节点ns与起点的任务状态下的相对坐标对应,节点ng与最终目标的任务状态下的相对坐标对应。在本实施方式中,任务空间sp中的两个对象物是否接触的边界面(接触边界面)基于学习完毕的判定模型50的判定结果导出。
[0199]
(步骤s205~步骤s207)
[0200]
在步骤s205中,控制部21确定相对于当前的任务状态接下来要迁移的目标的任务状态,以接近最终目标的任务状态。
[0201]
确定目标的任务状态的方法也可以不特别限定,可以根据实施方式适当选择。例如,目标的任务状态下的相对坐标也可以通过操作者的输入确定。与成为起点的任务状态的设定同样地,目标的任务状态下的相对坐标可以通过任意的算法确定,也可以利用cad数据220适当确定。另外,例如控制部21也可以通过随机地变更起点的任务状态下的相对坐标,来确定目标的任务状态下的相对坐标。另外,例如控制部21也可以在任务空间sp内选择从节点ns仅相隔规定距离的节点,以接近节点ng。控制部21也可以获取与所选择的节点对应的任务状态作为目标的任务状态。另外,例如在通过后述的强化学习生成推理模型55的情况下,可以利用强化学习的过程中的推理模型55,来确定目标的任务状态。
[0202]
另外,例如在目标的任务状态的确定中,可以采用路径规划等公知的方法。作为一例,控制部21也可以在任务空间sp中设定成为目标的任务状态的候补的节点。节点的设定可以通过随机采样等方法自动地进行,也可以通过操作者的输入手动地进行。也可以自动地进行一部分节点的设定,手动地进行剩余的节点的设定。在进行成为目标的任务状态的候补的节点的设定之后,控制部21可以适当选择可迁移的节点的组合。在选择可迁移的节点的组合的方法中,例如可以采用最邻近法等。在任务空间sp内,可迁移的节点的组合可以由连结节点的边来表现。接着,控制部21搜索从起点的节点ns到最终目标的节点ng的路径。路径搜索的方法可以采用戴克斯特拉(dijkstra)算法等。控制部21也可以获取与通过搜索得到的路径中包括的节点对应的任务状态作为目标的任务状态。
[0203]
在步骤s206中,控制部21作为接触判定部211进行动作,利用学习完毕的判定模型50,判定在所确定的目标的任务状态下两个对象物是否相互接触。除了判定的对象从起点的任务状态替换为目标的任务状态这一点以外,控制部21可以与上述步骤s203同样地执行步骤s206的处理。即,控制部21将目标的任务状态的相对坐标输入到学习完毕的判定模型50,执行学习完毕的判定模型50的运算处理。由此,控制部21从学习完毕的判定模型50中获取与判定在目标的任务状态下两个对象物是否相互接触的结果对应的输出值。
[0204]
在步骤s207中,控制部21基于步骤s206的判定结果,确定处理的分支目的地。在步骤s207中,在判定为在目标的任务状态下两个对象物相互接触的情况下,控制部21将处理返回到步骤s205,再次确定目标的任务状态。另一方面,在判定为在目标的任务状态下两个对象物不相互接触的情况下,控制部21使处理进入下一步骤s208。
[0205]
需要说明的是,步骤s207中的分支目的地也可以不限于这样的例子。例如,在判定为在目标的任务状态下两个对象物相互接触的情况下,控制部21也可以将处理返回到步骤s202,从起点的设定开始重新进行处理。另外,例如在多次确定目标的任务状态之后,在判定为在最后确定的目标的任务状态下两个对象物相互接触的情况下,控制部21也可以将处
理返回到步骤s205,从起点开始再次进行接下来要迁移的目标的任务状态的确定。直到接触为止确定的目标的任务状态的序列,也可以作为不能到达最终目标的任务状态的失败事例而收集。
[0206]
图12b示意性地示例了在任务空间sp中通过上述步骤s205~步骤s207的处理确定了目标的任务状态的场景的一例。在图12b的例子中,节点n1与作为从起点的任务状态(节点ns)接下来要迁移的目标的任务状态而确定的任务状态下的相对坐标对应。需要说明的是,在图12b的例子中,假设在步骤s205中确定了一次迁移的量的目标的任务状态。其中,在步骤s205中确定的目标的任务状态的数量也可以不限于一个。在步骤s205中,控制部21也可以朝向最终目标的任务状态,确定多次迁移的量的目标的任务状态(目标的任务状态的序列)。
[0207]
(步骤s208)
[0208]
在步骤s208中,控制部21使机械手4的当前的任务状态迁移到通过步骤s205确定的目标的任务状态。然后,控制部21判定机械手4的任务状态是否到达最终目标的任务状态,即迁移目的地的任务状态是否为最终目标的任务状态。任务状态的迁移可以通过模拟在虚拟空间上进行。在判定为到达了最终目标的任务状态的情况下,控制部21使处理进入下一步骤s209。另一方面,在判定为没有到达最终目标的任务状态的情况下,控制部21将处理返回到步骤s205,确定进一步的目标的任务状态。
[0209]
图12c示意性地示例了在任务空间sp中,通过直到上述步骤s208为止的处理确定了从起点的任务状态迁移到最终目标的任务状态的任务状态的序列的场景的一例。各节点n1~n4在从起点的节点ns到达最终目标节点ng为止,与作为目标的任务状态确定的任务状态下的相对坐标对应。节点n(k+1)表示从节点n(k)接下来要迁移的目标的任务状态(k为1~3)。如图12c所示例的那样,通过直到步骤s208为止的处理,控制部21能够得到从起点迁移到最终目标的目标的任务状态的序列。
[0210]
(步骤s209)
[0211]
在步骤s209中,控制部21判定是否重复步骤s202~步骤s208的处理。重复处理的基准可以根据实施方式适当确定。
[0212]
例如,也可以设定重复处理的规定次数。规定次数例如可以通过设定值赋予,也可以通过操作者的指定赋予。在这种情况下,控制部21判定执行步骤s202~步骤s208的处理的次数是否达到规定次数。在判定为执行次数未达到规定次数的情况下,控制部21将处理返回到步骤s202,重复步骤s202~步骤s208的处理。另一方面,在判定为执行次数达到了规定次数的情况下,控制部21使处理进入下一步骤s210。
[0213]
另外,例如控制部21也可以询问操作者是否重复处理。在这种情况下,控制部21根据操作者的回答,判定是否重复步骤s202~步骤s208的处理。在操作者回答重复处理的情况下,控制部21将处理返回到步骤s202,重复步骤s202~步骤s208的处理。另一方面,在操作者回答不重复处理的情况下,控制部21使处理进入下一步骤s210。
[0214]
通过直到步骤s209为止的处理,能够得到图12c所示例的从起点迁移到最终目标的目标的任务状态的一个以上的序列。控制部21作为数据收集部212进行动作,收集从该起点迁移到最终目标的目标的任务状态的一个以上的序列。然后,控制部21根据所收集的序列生成学习数据223。控制部21可以直接获取所收集的序列作为学习数据223,也可以通过
对所收集的序列执行某些信息处理来生成学习数据223。学习数据223的构成可以根据生成推理模型55的方法适当确定。关于学习数据223的构成,将在后面叙述。
[0215]
(步骤s210及步骤s211)
[0216]
在步骤s210中,控制部21作为模型生成部213进行动作。即,控制部21使用基于学习完毕的判定模型50的判定结果而得到的学习数据223,生成用于根据当前的任务状态及最终目标的任务状态推理接下来要迁移的目标的任务状态的推理模型55,以使第一对象物不与第二对象物接触。关于生成推理模型55的方法,将在后面叙述。
[0217]
在步骤s211中,控制部21作为保存处理部214进行动作。即,控制部21生成与所生成的推理模型55相关的信息作为推理模型数据225,并将所生成的推理模型数据225保存在规定的存储区域中。规定的存储区域例如可以是控制部21内的ram、存储部22、外部存储装置、存储介质或它们的组合。存储介质例如可以是cd、dvd等,控制部21也可以经由驱动器27在存储介质中存储推理模型数据225。外部存储装置例如可以是nas等数据服务器。在这种情况下,控制部21也可以利用通信接口23,经由网络将推理模型数据225存储在数据服务器中。另外,外部存储装置例如也可以是与第二模型生成装置2连接的外置的存储装置。
[0218]
由此,当推理模型数据225的保存完成时,控制部21结束与推理模型55的生成相关的一系列处理。
[0219]
需要说明的是,所生成的推理模型数据225可以在任意的时机向控制装置3提供。例如,作为步骤s211的处理或与步骤s211的处理不同地,控制部21也可以将推理模型数据225转发给控制装置3。控制装置3也可以通过接收该转发来获取推理模型数据225。另外,例如控制装置3也可以利用通信接口33,通过经由网络访问第二模型生成装置2或数据服务器,来获取推理模型数据225。另外,例如控制装置3也可以经由存储介质93来获取推理模型数据225。另外,例如推理模型数据225也可以预先嵌入在控制装置3中。
[0220]
进而,控制部21也可以通过定期或不定期地重复上述步骤s201~步骤s211的处理,来更新或新生成推理模型数据225。在该重复时,可以适当执行学习数据223中的至少一部分的变更、修正、追加、删除等。另外,控制部21也可以通过每当执行学习处理时向控制装置3提供更新或新生成的推理模型数据225,来更新控制装置3保持的推理模型数据225。
[0221]
《推理模型的生成方法》
[0222]
接着,对上述步骤s210中的推理模型55的生成方法的具体例进行说明。在本实施方式中,控制部21能够通过以下两个方法中的至少任一个方法来生成推理模型55。
[0223]
(1)第一方法
[0224]
在第一方法中,控制部21通过实施机器学习生成推理模型55。在这种情况下,推理模型55由机器学习模型构成。机器学习模型的种类也可以不特别限定,可以根据实施方式适当选择。推理模型55例如可以由函数式、数据表等来表现。在由函数式来表现的情况下,推理模型55例如可以由神经网络、支持向量机、回归模型及决策树等构成。另外,机器学习的方法也可以不特别限定,可以根据推理模型55的构成适当选择。推理模型55的机器学习的方法例如可以采用有监督学习、强化学习等。以下,对构成推理模型55的机器学习模型及机器学习的方法各自的两个例子进行说明。
[0225]
(1-1)第一例
[0226]
图13示意性地示出了构成推理模型55的机器学习模型及机器学习的方法的第一
例。在第一例中,推理模型55采用神经网络,机器学习的方法采用有监督学习。另外,在图13的例子中,为了便于说明,将推理模型55、学习数据223及推理模型数据225各自的一例表述为推理模型551、学习数据2231及推理模型数据2251。
[0227]
(1-1-1)推理模型的构成例
[0228]
在第一例中,推理模型551由三层结构的递归型神经网络构成。具体而言,推理模型551具备输入层n51、lstm(长短期记忆:long short-term memory)块n52及输出层n53。lstm块n52与中间层对应。
[0229]
lstm块n52具备输入门及输出门,是构成为能够学习信息的存储及输出的时机的块(s.hochreiter and j.schmidhuber,“long short-term memory”neural computation,9(8):1735-1780,november 15,1997)。lstm块n52也可以进一步具备调节信息的遗忘的时机的遗忘门(felix a.gers,jurgen schmidhuber and fred cummins,“learning to forget:continual prediction with lstm”neural computation,pages 2451-2471,october 2000)。lstm块n52的构成可以根据实施方式适当设定。
[0230]
需要说明的是,推理模型551的结构也可以不限于这样的例子,可以根据实施方式适当确定。推理模型551也可以由不同结构的递归型神经网络构成。或者,推理模型551也可以不由递归型,而与上述判定模型50同样地由全连接型神经网络或卷积神经网络构成。或者,推理模型551也可以由多种神经网络的组合构成。另外,推理模型551具备的中间层的数量也可以不限于一个,也可以是两个以上。或者,也可以省略中间层。另外,推理模型551的构成可以与上述判定模型50相同。
[0231]
(1-1-2)学习数据的构成例
[0232]
用于推理模型551的有监督学习的学习数据2231由包括训练数据(输入数据)及正确数据(监督信号)的组合的多个学习数据集l30构成。训练数据可以由训练用的当前的任务状态l31下的相对坐标及训练用的最终目标的任务状态l32下的相对坐标构成。正确数据可以由训练用的目标的任务状态l33下的相对坐标构成。需要说明的是,训练数据及正确数据的形式也可以不特别限定,可以根据实施方式适当选择。例如,训练数据可以直接利用相对坐标,或者也可以利用通过将相对坐标变换为特征量而得到的值。
[0233]
控制部21能够根据通过直到步骤s209为止的处理得到的目标的任务状态的一个以上的序列生成各学习数据集l30。例如,能够将由节点ng所示的最终目标的任务状态用作训练用的最终目标的任务状态l32。另外,控制部21在将由节点ns所示的起点的任务状态设定为训练用的当前的任务状态l31的情况下,可以将由节点n1所示的任务状态设定为对应的正确数据中的训练用的目标的任务状态l33。同样地,控制部21在将由节点n(k)所示的任务状态设定为训练用的当前的任务状态l31的情况下,可以将由节点n(k+1)所示的任务状态设定为对应的正确数据中的训练用的目标的任务状态l33。控制部21在将由节点n4所示的任务状态设定为训练用的当前的任务状态l31的情况下,可以将由节点ng所示的最终目标的任务状态设定为对应的正确数据中的训练用的目标的任务状态l33。由此,能够根据所得到的目标的任务状态的一个以上的序列生成各学习数据集l30。
[0234]
(1-1-3)关于步骤s210
[0235]
在上述步骤s210中,控制部21使用所获取的多个学习数据集l30,实施推理模型551的机器学习(有监督学习)。在第一例中,控制部21通过机器学习训练推理模型551,以使
对于各学习数据集l30,当将训练数据输入到输入层n51时,从输出层n53输出适合于正确数据的输出值。由此,能够生成获得了根据当前的任务状态及最终目标的任务状态推理接下来要迁移的目标的任务状态的能力的学习完毕的推理模型551。
[0236]
推理模型551的机器学习的方法可以与上述判定模型50的机器学习的方法相同。即,在第一步骤中,控制部21对于各学习数据集l30,向推理模型551的输入层n51输入训练数据,执行推理模型551的运算处理。由此,控制部21从推理模型551的输出层l53获取与推理相对于当前的任务状态接下来要迁移的目标的任务状态的结果对应的输出值。在第二步骤中,控制部21基于损失函数计算输出层l53的输出值与正确数据的误差。
[0237]
接着,在第三步骤中,控制部21通过误差反向传播法,使用计算出的输出值的误差的梯度,计算推理模型551的各运算参数的值的误差。控制部21使用计算出的误差的梯度,计算推理模型551的各运算参数(例如各神经元间的连接的权重、各神经元的阈值等)的值的误差。在第四步骤中,控制部21基于计算出的各误差,更新推理模型551的运算参数的值。更新的程度可以通过学习率进行调节。学习率可以通过操作者的指定赋予,也可以作为程序内的设定值赋予。
[0238]
控制部21通过重复上述第一~第四步骤来调整推理模型551的运算参数的值,以使对于各学习数据集l30,从输出层n53输出的输出值与正确数据的误差之和变小。例如,控制部21也可以重复上述第一~第四步骤的处理,直到误差之和变为阈值以下为止。阈值可以根据实施方式适当设定。或者,控制部21也可以重复上述第一~第四步骤规定次数。重复调整的次数例如可以通过程序内的设定值指定,也可以通过操作者的输入指定。
[0239]
根据该机器学习(有监督学习)的结果,控制部21能够构建训练为对于各学习数据集l30,当将训练数据输入到输入层n51时,从输出层n53输出适合于对应的正确数据的输出值的学习完毕的推理模型551。即,能够构建获得了根据当前的任务状态及最终目标的任务状态推理接下来要迁移的目标的任务状态的能力的学习完毕的推理模型551。
[0240]
在步骤s211中,控制部21生成表示通过有监督学习构建的学习完毕的推理模型551的结构及运算参数的信息作为推理模型数据2251。然后,控制部21将所生成的推理模型数据2251保存在规定的存储区域中。需要说明的是,推理模型数据2251的内容只要能够再生学习完毕的推理模型551即可,也可以不限于这样的例子。例如,在各装置间使推理模型551的结构共同化的情况下,在推理模型数据2251中可以省略表示推理模型551的结构的信息。
[0241]
(1-1-4)其他
[0242]
需要说明的是,在机器学习的方法采用有监督学习的情况下,推理模型551的构成可以不限于神经网络。也可以采用神经网络以外的机器学习模型作为推理模型551。构成推理模型551的机器学习模型例如也可以采用支持向量机、回归模型及决策树等。有监督学习的方法可以不限于上述例子,可以根据机器学习模型的构成适当选择。
[0243]
(1-2)第二例
[0244]
图14示意性地示出了构成推理模型55的机器学习模型及机器学习的方法的第二例。在第二例中,机器学习的方法采用强化学习。需要说明的是,在图14的例子中,为了便于说明,将推理模型55、学习数据223及推理模型数据225各自的一例表述为推理模型552、学习数据2232及推理模型数据2252。
[0245]
(1-2-1)推理模型的构成例
[0246]
在第二例中,推理模型552可以采用基于价值、基于策略或其双方。在采用基于价值的情况下,推理模型552例如可以由状态价值函数、行动价值函数(q函数)等价值函数构成。状态价值函数构成为输出所赋予的状态的价值。行动价值函数构成为对所赋予的状态输出各行动的价值。在采用基于策略的情况下,推理模型552例如可以由策略函数构成。策略函数构成为对所赋予的状态输出选择各行动的概率。在采用双方的情况下,推理模型552例如可以由价值函数(critic)及策略函数(actor)构成。各函数例如可以由数据表、函数式等来表现。在由函数式来表现的情况下,各函数可以由神经网络、线性函数及决策树等构成。需要说明的是,通过由存在多个中间(隐藏)层的多层结构的神经网络构成各函数,可以实施深度强化学习。
[0247]
(1-2-2)学习数据的构成例
[0248]
在强化学习中,假设基本上通过按照策略进行行动而与学习环境相互作用的代理。代理的实体例如是cpu。推理模型552根据上述构成,作为确定行动的策略进行动作。代理在所赋予的学习环境内观测与所强化的行动相关的状态。在本实施方式中,成为观测对象的状态是由相对坐标规定的任务状态,所执行的行动是从当前的任务状态向目标的任务状态的迁移。策略构成为根据当前的任务状态及最终目标的任务状态确定(推理)接下来要迁移的目标的任务状态。
[0249]
代理可以将所观测的当前的任务状态(输入数据)赋予推理模型552,来推理接下来要迁移的目标的任务状态。代理也可以基于该推理的结果来确定目标的任务状态。或者,目标的任务状态可以随机确定。由此,代理能够确定所采用的行动。当代理执行向所确定的目标的任务状态迁移的行动时,所观测的任务状态向接下来的任务状态迁移。根据情况,代理可以从学习环境得到即时奖励。
[0250]
在重复该行动的确定及执行的试行错误的同时,代理更新推理模型552,以使即时奖励的总和(即价值)最大化。由此,最佳行动,即能够期待获取高价值的行动被强化,能够得到使这样的行动的选择成为可能的策略(学习完毕的推理模型552)。
[0251]
因此,在强化学习中,学习数据2232是通过该试行错误得到的状态迁移数据,由表示通过所执行的行动从当前的任务状态向接下来的任务状态迁移,并根据情况得到即时奖励的状态迁移的状态迁移数据构成。一份状态迁移数据可以由表示一个片段全部的状态迁移轨迹的数据构成,或者也可以由表示规定次数(一次以上)的量的状态迁移的数据构成。在上述步骤s202~步骤s209的处理过程中,控制部21利用训练中的推理模型552,通过执行上述试行错误,能够获取上述状态迁移数据。
[0252]
另外,可以使用奖励函数来根据状态迁移计算即时奖励。奖励函数可以由数据表、函数式或规则来表现。在由函数式来表现的情况下,奖励函数可以由神经网络、线性函数及决策树等构成。奖励函数也可以由操作者等手动设定。
[0253]
或者,奖励函数也可以设定为:根据由上述学习完毕的判定模型50判定在要迁移的对象的任务状态下第一对象物及第二对象物是否相互接触的结果、以及该对象的任务状态及最终目标的任务状态之间的距离来赋予即时奖励。具体而言,第一对象物及第二对象物不相互接触,并且对象的任务状态及最终目标的任务状态之间的距离越短,即时奖励可以设定得越多,第一对象物及第二对象物相互接触,或者该距离越长,则可以设定得越少。
以下的式1示例了如此赋予即时奖励的奖励函数的一例。
[0254][0255]
sc表示由策略确定的目标的任务状态。sg表示最终目标的任务状态。f(sc)表示由学习完毕的判定模型50判定在任务状态sc下第一对象物及第二对象物是否相互接触的结果。在判定为相互接触的情况下,f(sc)的值变小(例如0),在判定为不相互接触的情况下,f(sc)的值变大(例如1)。在学习完毕的判定模型50的输出值与该设定对应的情况下,学习完毕的判定模型50的输出值也可以直接作为f(sc)使用。
[0256]
或者,奖励函数可以根据由专家得到的事例数据通过逆强化学习来推定。事例数据可以由表示基于专家的演示(的轨迹)的数据构成。在本实施方式中,事例数据例如可以由表示以从任意的起点的任务状态到达最终目标的任务状态的方式实际移动第一对象物的路径的数据构成。生成事例数据的方法也可以不特别限定,可以根据实施方式适当选择。事例数据例如可以通过由传感器等记录专家的演示的轨迹来生成。
[0257]
逆强化学习的方法可以不特别限定,可以根据实施方式适当选择。逆强化学习例如可以使用基于最大熵原理的方法、基于相对熵的最小化的方法、利用了生成对抗网络的方法(例如,justin fu,et al.,“learning robust rewards with adversarial inverse reinforcement learning”,arxiv:1710.11248,2018)等。在通过逆强化学习得到奖励函数的情况下,学习数据2232可以进一步具备用于逆强化学习的事例数据。
[0258]
(1-2-3)关于步骤s210
[0259]
在上述步骤s210中,控制部21基于所得到的状态迁移数据,更新推理模型552的运算参数的值,以使价值最大化。调整推理模型552的运算参数的值的方法可以根据推理模型552的构成适当选择。例如,在推理模型552由神经网络构成的情况下,推理模型552的运算参数的值可以通过误差反向传播法等,通过与上述第一例相同的方法进行调整。
[0260]
控制部21调整推理模型552的运算参数的值,以使所得到的价值(的期望值)最大化(例如直到更新量变为阈值以下为止)。即,训练推理模型552包括重复构成推理模型552的运算参数的值的修正,以使直到满足规定的条件(例如更新量变为阈值以下)为止时得到多的奖励。由此,控制部21能够生成获得了根据当前的任务状态及最终目标的任务状态推理接下来要迁移的目标的任务状态的能力的学习完毕的推理模型552。
[0261]
需要说明的是,控制部21也可以在通过步骤s202~步骤s209的处理收集完学习数据2232之后,执行上述推理模型552的运算参数的值的调整。或者,控制部21也可以在重复步骤s202~步骤s210的处理的同时,执行上述推理模型552的运算参数的值的调整。
[0262]
在推理模型552由基于价值构成的情况下,上述强化学习的方法可以使用td(temporal difference:时序差分)法、td(λ)法、蒙特卡洛(monte carlo)法及动态规划法等。试行错误中的行动的确定可以是同策略(on-policy),也可以是异策略(off-policy)。作为具体例,强化学习的方法可以使用q学习、sarsa等。在试行错误时,也可以以概率ε采用随机的行动(ε-贪心算法)。
[0263]
另外,在机器学习模型552由基于策略构成的情况下,上述强化学习的方法可以使用策略梯度法、trpo(trust region policy optimization:信任域策略优化)、ppo(proximal policy optimization:近端策略优化)等。在这种情况下,控制部21在所得到的
价值增加的方向上计算策略函数的运算参数的梯度,并基于计算出的梯度更新策略函数的运算参数的值。例如,策略函数的梯度的计算可以使用reinforce(强化)算法等。
[0264]
另外,在推理模型55由双方构成的情况下,上述强化学习的方法可以使用actor critic法、a2c(advantage actor critic)、a3c(asynchronous advantage actor critic)等。
[0265]
进而,在实施逆强化学习的情况下,在执行上述强化学习的处理之前,控制部21进一步获取事例数据。事例数据可以由第二模型生成装置2生成,也可以由其他计算机生成。在由其他计算机生成的情况下,控制部21也可以经由网络、存储介质92等获取由其他计算机生成的事例数据。接着,控制部21利用所获取的事例数据,通过执行逆强化学习,来设定奖励函数。然后,控制部21利用通过逆强化学习设定的奖励函数,来执行上述强化学习的处理。由此,控制部21利用通过逆强化学习设定的奖励函数,能够生成获得了根据当前的任务状态及最终目标的任务状态推理接下来要迁移的目标的任务状态的能力的学习完毕的推理模型552。
[0266]
在步骤s211中,控制部21生成表示通过强化学习构建的学习完毕的推理模型552的信息作为推理模型数据2252。在表示学习完毕的推理模型552的信息中,例如可以包括表示数据表的各项目的值、函数式的系数的值等运算参数的信息。然后,控制部21将所生成的推理模型数据2252保存在规定的存储区域中。根据第二例,能够生成能够确定目标的任务状态,以避免第一对象物及第二对象物的无用的接触,并且使机械手4的任务状态尽早到达最终目标的任务状态的推理模型55。
[0267]
(1-3)总结
[0268]
在本实施方式中,在由机器学习模型构成推理模型55的情况下,推理模型55的构成也可以采用上述两个例子中的至少任一个。控制部21通过采用上述两个机器学习的方法中的至少任一个,能够生成获得了根据当前的任务状态及最终目标的任务状态来推理接下来要迁移的目标的任务状态的能力,以使第一对象物不与第二对象物接触的学习完毕的推理模型55。因此,根据第一方法,能够适当地生成可用于任务的执行的推理模型55。
[0269]
(2)第二方法
[0270]
图15a示意性地示例了第二方法中的学习数据223的一例。图15b示意性地示例了第二方法中的推理模型55的构成的一例。在第二方法中,推理模型55由规定表现任务状态的集合的任务空间sp内的各坐标的电势的势场构成。需要说明的是,在图15a及图15b中,为了便于说明,将推理模型55、学习数据223及推理模型数据225各自的一例表述为推理模型553、学习数据2233及推理模型数据2253。
[0271]
控制部21通过上述步骤s202~步骤s209的处理,在任务空间sp内,利用学习完毕的判定模型50实施路径规划,以使第一对象物不与第二对象物接触。由此,如图15a所示,控制部21能够生成表示从分别作为起点(节点ns)赋予的多个任务状态分别到最终目标的任务状态的路径hb的学习数据2233。各起点(节点ns)可以随机赋予。
[0272]
在上述步骤s210中,控制部21通过根据由所生成的学习数据2233所示的各路径hb的通过频度来设定各坐标的电势,从而生成势场。导出势场的方法也可以不特别限定,可以根据实施方式适当选择。控制部21例如也可以通过核密度推定、使用混合高斯模型(gmm:gaussian mixture model)的推定,来根据学习数据3233导出势场。由此,能够得到图15b所
示例的势场(推理模型553)。
[0273]
势场中的各坐标的电势表示相对于到达最终目标的各坐标中的第一对象物及第二对象物的位置关系的评价值。即,电势越高,表示该坐标中的位置关系到达最终目标的可能性越高,电势越低,表示该坐标中的位置关系到达最终目标的可能性越低。因此,通过向电势的梯度高的一方迁移,能够从成为起点的任意的任务状态适当地到达最终目标的任务状态。因此,根据第二方法,能够适当地生成可用于任务的执行的推理模型55。
[0274]
在步骤s211中,控制部21生成表示所生成的势场的信息作为推理模型数据2253。势场可以由数据表、函数式等来表现。然后,控制部21将所生成的推理模型数据2253保存在规定的存储区域中。
[0275]
(3)总结
[0276]
在本实施方式中,作为生成推理模型55的方法,可以采用上述两个方法中的至少任一个。控制部21通过采用上述两个方法中的至少任一个,能够生成构成为根据当前的任务状态及最终目标的任务状态推理接下来要迁移的目标的任务状态,以使第一对象物不与第二对象物接触的推理模型55。
[0277]
需要说明的是,推理目标的任务状态以使第一对象物不与第二对象物接触是指,避免在第一对象物及第二对象物之间产生不希望的接触而确定目标的任务状态,例如,也可以包括将末端执行器t保持工件w等第一对象物与第二对象物适当地接触的任务状态确定为目标的任务状态。即,成为避免对象的“接触”状态例如是在第一对象物及第二对象物之间作用有过度的力、在第一对象物及第二对象物中的一方以正确的姿势组装到另一方以外的状态下接触等不适当地接触的状态。因此,“第一对象物不与第二对象物接触”可以替换为“避免第一对象物与第二对象物以不适当的状态下接触”。
[0278]
[控制装置]
[0279]
(a)动作控制
[0280]
下面,使用图16a、图16b及图17对与本实施方式所涉及的控制装置3的机械手4的动作控制相关的动作例进行说明。图16a及图16b是示出与本实施方式所涉及的控制装置3的机械手4的动作控制相关的处理顺序的一例的流程图。图17示出了动作控制的过程中的各要素的运算处理的流程的一例。其中,以下说明的各处理顺序只不过是一例而已,各步骤可以尽可能地变更。进而,对于以下说明的各处理顺序,能够根据实施方式适当地进行步骤的省略、替换及追加。需要说明的是,以下说明的机械手4的动作的控制可以在实际空间上实施,或者也可以在虚拟空间上实施。
[0281]
(步骤s301及步骤s302)
[0282]
在步骤s301中,控制部31接收所执行的任务的指定。接收任务的指定的方法也可以不特别限定,可以根据实施方式适当选择。例如,控制部31也可以通过经由输入装置35的任务的名称的输入,来接收所执行的任务的指定。另外,例如控制部31也可以将表示所执行的任务的候补的列表输出到输出装置36,通过使操作者从列表中选择所执行的任务,来接收所执行的任务的指定。
[0283]
在本实施方式中,控制部31在存在第一对象物及第二对象物的环境下,接收相对于第二对象物移动第一对象物的任务的执行。具体而言,驱动机械手4,通过末端执行器t保持工件w,并将所保持的工件w组装到其他工件g的一系列作业是所指定的任务的一例。在本
实施方式中,在进行保持工件w的第一任务的过程中,末端执行器t的关注点t0被处理作为机械手4的手指,工件w是手指移动的目标物。另一方面,在保持工件w之后,在将工件w组装到其他工件g的第二任务的过程中,通过末端执行器t保持的工件w的关注点w0被处理作为机械手4的手指,作为工件w的组装目的地的其他工件w是手指移动的目标物。在各任务中,机械手4的手指相当于第一对象物,目标物相当于第二对象物。
[0284]
在步骤s302中,控制部31作为目标设定部310进行动作,根据所指定的任务设定最终目标的任务状态sg。如上所述,在本实施方式中,任务状态由机械手4的手指及目标物之间的位置关系规定。另外,位置关系由相对坐标来表现。最终目标的任务状态sg下的相对坐标可以通过cad等模拟器赋予,也可以通过操作者的指定赋予。最终目标的任务状态sg下的相对坐标可以通过与上述步骤s201相同的方法来设定。当设定最终目标的任务状态sg时,控制部31使处理进入下一步骤s303。
[0285]
(步骤s303)
[0286]
在步骤s303中,控制部31作为第一数据获取部311进行动作,从第一传感器系统获取第一传感数据323。另外,控制部31作为第二数据获取部312进行动作,从第二传感器系统获取第二传感数据324。
[0287]
在本实施方式中,第一传感器系统由测定各关节(关节部41~46)的角度的编码器s2及测定作用于末端执行器t的力的触觉传感器s3构成。控制部31能够从各编码器s2获取机械手4中的各关节的角度的当前值q
(j)
(即,当前的测定值)作为第一传感数据323。进而,控制部31能够从触觉传感器s3获取作用于末端执行器t的力的测定数据作为第一传感数据323。另外,在本实施方式中,第二传感器系统由照相机s1构成。控制部31能够从照相机s1中获取拍摄了执行任务的环境的图像数据作为第二传感数据324。需要说明的是,以下,为了便于说明,在特别区分“当前”等时机的情况下,附加(j)等表示时机的符号,在不是这样的情况下,省略该符号。
[0288]
控制部31可以从各传感器(照相机s1、编码器s2、触觉传感器s3)直接获取各传感数据(323、324),或者,例如也可以经由其他计算机等间接获取各传感数据(323、324)。照相机s1及触觉传感器s3分别是观测工件w相对于末端执行器t的状态的观测传感器的一例。当获取各传感数据(323、324)时,控制部31使处理进入下一步骤s304。
[0289]
(步骤s304)
[0290]
在步骤s304中,控制部31基于通过步骤s303得到的上述观测传感器的传感数据,判定末端执行器t是否保持工件w。判定方法也可以不特别限定,可以根据传感数据适当确定。
[0291]
例如,在本实施方式中,能够从照相机s1获取拍摄了任务环境的图像数据作为第二传感数据324。因此,控制部31也可以利用cad数据320,对所获取的图像数据匹配末端执行器t及工件w的模型。另外,控制部31也可以根据通过该匹配结果而确定的末端执行器t及工件w的位置关系,来判定末端执行器t是否保持工件w。匹配的方法可以使用公知的图像处理方法。
[0292]
另外,例如在本实施方式中,能够获取作用于末端执行器t的力的测定数据作为第一传感数据323。因此,控制器31也可以基于由测定数据表示的力的分布来判定末端执行器t是否保持工件w。在根据测定数据推定出认为末端执行器t保持工件w的力作用于末端执行
器t的情况下,控制器31也可以判定为末端执行器t保持工件w。另一方面,在不是这样的情况下,控制器31也可以判定为末端执行器t未保持工件w。
[0293]
当基于传感数据完成末端执行器t是否保持工件w的判定时,控制部31使处理进入下一步骤s305。
[0294]
(步骤s305)
[0295]
在步骤s305中,控制部31基于步骤s304的判定结果,设定机械手4的动作模式。具体而言,在判定为末端执行器t未保持工件w的情况下,控制部31将末端执行器t的关注点t0设定为机械手4的手指,将动作模式设定为执行通过末端执行器t保持工件w的第一任务的模式。另一方面,在判定为末端执行器t保持工件w的情况下,控制部31将工件w的关注点w0设定为机械手4的手指,将动作模式设定为执行将通过末端执行器t保持的工件w组装到其他工件g的第二任务的模式。当动作模式的设定完成时,控制部31使处理进入下一步骤s306。
[0296]
(步骤s306)
[0297]
在步骤s306中,控制部31作为状态获取部315进行动作,获取机械手4的当前的任务状态s
(j)
。
[0298]
如上所述,在本实施方式中,在末端执行器t未保持工件w的情况下,任务状态s由工件w相对于末端执行器t的相对坐标规定。另一方面,在末端执行器t保持工件w的情况下,任务状态s由其他工件g相对于工件w的相对坐标规定。在本实施方式中,控制部31利用cad数据320,对由照相机s1得到的图像数据匹配各对象物。控制部31能够根据该匹配结果获取当前的任务状态s
(j)
。
[0299]
这里,进一步使用图18对获取当前的任务状态s
(j)
的方法的一例进行说明。图18示意性地示例了各对象物的位置关系的一例。在图18的例子中,在机械手4的底座部40上设定有观测空间的原点。其中,原点的位置也可以不限于这样的例子,可以根据实施方式确定。照相机s1相对于原点的齐次坐标(tc)能够由以下的式2来表现。
[0300][0301]rrc
表示从原点的坐标系观察照相机s1的坐标系的旋转向量,t
rc
表示平行移动向量。以下,为了便于说明,假设校准照相机s1以使原点的齐次坐标(tr)满足以下的式3。
[0302][0303]
i表示单位矩阵。在图18的例子中,末端执行器t的关注点t0相对于原点的相对坐标是末端执行器t的坐标(t
t
)。工件w的关注点w0相对于原点的相对坐标是工件w的坐标(tw)。其他工件g的关注点g0相对于原点的相对坐标是其他工件g的坐标(tg)。控制部31通过利用cad数据320对图像数据匹配各对象物的模型,能够得到各坐标(t
t
、tw、tg)的推定值。控制部31能够将在处理时机得到的各坐标的推定值用作各坐标的当前值。
[0304]
s=t
w-1
·
t
t
…
(式4)
[0305]
在末端执行器t未保持工件w的情况下,任务状态s与末端执行器t及工件w的各坐标(t
t
、tw)的关系能够由上述式4来表现。因此,控制部31通过将根据匹配结果推定的末端执
行器t及工件w的各坐标的当前值(t
t(j)
、t
w(j)
)代入上述式4,并执行上述式4的运算处理,能够计算当前的任务状态s
(j)
的推定值。计算当前的任务状态s
(j)
的推定值相当于获取当前的任务状态s
(j)
。
[0306]
s=t
g-1
·
tw…
(式5)
[0307]
另一方面,在末端执行器t保持工件w的情况下,任务状态s与工件w及其他工件g的各坐标(tw、tg)的关系能够由上述式5来表现。因此,控制部31通过将根据匹配结果推定的工件w及其他工件g的各坐标的当前值(t
w(j)
、t
g(j)
)代入上述式5,通过执行上述式5的运算处理,能够计算当前的任务状态s
(j)
的推定值。需要说明的是,各坐标(t
t
、tw、tg)的表现可以适当选择。各坐标(t
t
、tw、tg)的表现例如可以使用齐次坐标系。以下也同样。
[0308]
在照相机s1未校准的情况下,控制部31也可以进一步在由照相机s1得到的图像数据内计算原点的坐标(tr)的推定值。原点的检测可以使用记号等标记。即,可以通过在图像数据内匹配标记来计算原点的坐标(tr)的推定值。控制部31通过将计算出的原点的坐标(tr)的推定值应用于上述各运算,能够计算当前的任务状态s
(j)
的推定值。在以后的步骤中,执行基于cad数据320的匹配的情况也可以同样地处理。
[0309]
当获取当前的任务状态s
(j)
时,控制部31使处理进入下一步骤s307。需要说明的是,执行步骤s306的处理的时机也可以不限于这样的例子。步骤s306的处理可以在执行后述的步骤s308之前的任意的时机执行。例如,在上述步骤s304中也进行基于cad数据320的匹配的情况下,该步骤s306的处理可以与上述步骤s304的处理一并执行。
[0310]
(步骤s307)
[0311]
在步骤s307中,控制部31作为第一推定部313进行动作,利用第一推定模型61,根据所获取的第一传感数据323,计算观测空间内的手指的当前坐标的第一推定值。另外,控制部31作为第二推定部314进行动作,利用第二推定模型62,根据所获取的第二传感数据324,计算观测空间内的手指的当前坐标的第二推定值。
[0312]
(1)第一推定值的计算过程
[0313]
首先,对第一推定值的计算过程的一例进行说明。如图17所示,控制部31通过正向运动学计算,根据由各编码器s2得到的关节空间中的机械手4的各关节的角度的当前值q
(j)
(第一传感数据323),计算观测空间中的机械手4的手指坐标的第一推定值(换言之,推定当前值x
(j)
)。下面,分别对末端执行器t未保持工件w的情况和末端执行器t保持工件w的情况进行说明。
[0314]
(1-1)未保持工件w的场景
[0315]
在末端执行器t未保持工件w的情况下,将末端执行器t的关注点t0设定为手指。在这种情况下,控制部31通过将根据各关节的第一齐次变换矩阵导出的第一变换矩阵组用作变换函数的正向运动学计算,计算根据各关节的角度的当前值q
(j)
设定的手指坐标的第一推定值。
[0316]
x
t
=φ(q)
…
(式6)
[0317]
φ(q)=0t1·
…
·
0-1
tn…
(式7)
[0318]
具体而言,根据正向运动学,末端执行器t的关注点t0的坐标(x
t
)与各关节的角度(q)的关系能够由上述式6来表现。角度(q)是具有与关节数相应的维数的变量。另外,各关
节的第一齐次变换矩阵(
m-1
tm)与第一变换矩阵组的关系由上述式7赋予(m为0~n。n为关节数)。第一齐次变换矩阵表示从比对象的关节更靠近手边侧的坐标系观察的对象的关节的坐标系的相对坐标,用于将坐标从手边侧的坐标系变换为对象的关节的坐标系。
[0319]
各关节的第一齐次变换矩阵的参数的值除了各关节的角度以外是已知的,在本实施方式中,包括在机器人数据321中。该参数可以通过dh(denavit-hartenberg)表示法、修正dh表示法等公知的方法来设定。控制部31通过参照机器人数据321,来导出上述式7所示的第一变换矩阵组然后,控制部31如上述式6所示,将各关节的角度的当前值q
(j)
代入所导出的第一变换矩阵组执行第一变换矩阵组的运算处理。根据该正向运动学计算的结果,控制器31能够计算末端执行器t(的关注点t0)的当前坐标的推定值(换言之,推定坐标的当前值x
t(j)
)。控制部31获取计算出的推定值作为当前的手指坐标的第一推定值。
[0320]
(1-2)保持工件w的情况
[0321]
另一方面,在末端执行器t保持工件w的情况下,将工件w的关注点w0设定为手指。在这种情况下,首先,控制部31获取用于将坐标从末端执行器t的关注点t0的坐标系变换为工件w的关注点w0的坐标系的第二齐次变换矩阵(
t
tw)。
[0322]
获取第二齐次变换矩阵(
t
tw)的方法也可以不特别限定,可以根据实施方式适当选择。例如,当通过末端执行器t保持工件w时,存在工件w相对于末端执行器t的位置及姿势恒定的情况。因此,第二齐次变换矩阵(
t
tw)也可以通过常数赋予。
[0323]
或者,控制部31也可以根据在步骤s303中获取的传感数据推定第二齐次变换矩阵(
t
tw)。作为推定方法的一例,控制部31也可以利用cad数据320,对由照相机s1得到的图像数据匹配末端执行器t及工件w的模型。控制部31根据该匹配结果,能够得到末端执行器t的坐标(t
t
)及工件w的坐标(tw)的推定值。与上述同样地,当假设照相机s1被校准时,控制部31能够通过以下的式8,根据末端执行器t的坐标(t
t
)及工件w的坐标(tw)各自的推定值推定第二齐次变换矩阵(
t
tw)。
[0324]
tw=t
t-1
·
tw…
(式8)
[0325]
基于cad数据320的匹配也可以在通过上述正向运动学计算而计算出的末端执行器t的关注点t0的坐标(x
t
)附近实施。另外,控制部31也可以将通过正向运动学计算而计算出的坐标(x
t
)的推定值用作坐标(t
t
)的推定值。由此,控制部31能够推定第二齐次变换矩阵(
t
tw)。需要说明的是,上述步骤s306的上述式4的运算处理也同样地,可以使用通过正向运动学计算推定的坐标的当前值(x
t(j)
)来代替通过匹配推定的末端执行器t的坐标的当前值(t
t(j)
)。
[0326]
另外,作为推定方法的其他例子,由触觉传感器s3测定的作用于末端执行器t的力的分布可能依赖于工件w相对于末端执行器t的位置及姿势。因此,控制部31也可以基于由触觉传感器s3得到的测定数据(第一传感数据323),推定工件w相对于末端执行器t的相对坐标(相对位置及相对姿势)。控制部31能够根据该推定结果推定第二齐次变换矩阵(
t
tw)。
[0327]
需要说明的是,根据传感数据322推定第二齐次变换矩阵(
t
tw)的方法也可以不限于上述解析的方法。第二齐次变换矩阵(
t
tw)的推定例如也可以与判定模型50、推理模型551等同样地,利用通过机器学习掌握了根据传感数据322推定第二齐次变换矩阵(
t
tw)的能力
的学习完毕的机器学习模型。在这种情况下,控制部31将所获取的传感数据322赋予学习完毕的机器学习模型,并执行学习完毕的机器学习模型的运算处理。由此,控制部31能够从学习完毕的机器学习模型获取与推定第二齐次变换矩阵(
t
tw)的结果对应的输出值。
[0328]
接着,控制部31通过将所得到的第二齐次变换矩阵(
t
tw)与第一变换矩阵组相乘,计算第二变换矩阵组第二变换矩阵组能够由以下的式9来表现。需要说明的是,第一齐次变换矩阵是第一变换式的一例,第二齐次变换矩阵是第二变换式的一例。第一变换矩阵组是第一变换式组的一例,第二变换矩阵组是第二变换式组的一例。各变换式的形式只要能够用于手指坐标的运算,则也可以不特别限定。例如,各变换式可以由齐次坐标系以外的形式的变换矩阵来表现,或者也可以由矩阵以外的形式的数学式来表现。
[0329]
φ(q)
·
t
tw=x
t
·
t
tw…
(式9)
[0330]
控制部31通过将计算出的第二变换矩阵组用作变换函数的正向运动学计算,计算根据各关节的角度的当前值q
(j)
设定的手指坐标的第一推定值。即,控制部31将各关节的角度的当前值q
(j)
代入第二变换矩阵组代入第二变换矩阵组执行第二变换矩阵组的运算处理。根据该正向运动学计算的结果,控制部31能够计算工件w(的关注点w0)的当前坐标的推定值(换言之,推定坐标的当前值)。控制部31获取计算出的工件w的当前坐标的推定值作为当前的手指坐标的第一推定值。
[0331]
需要说明的是,在上述中,通过根据传感数据推定第二齐次变换矩阵(
t
tw),即使末端执行器t中的工件w的保持状态变动,也能够获取反映了该变动的第二齐次变换矩阵(
t
tw)。由此,即使在末端执行器t中的工件w的保持状态可能变动的情况下,也能够适当地推定工件w的坐标的当前值,即,机械手4的手指坐标的当前值。
[0332]
(1-3)总结
[0333]
如上所述,在上述各场景中,控制部31通过使用了所导出的变换函数的正向运动学计算,能够根据各关节的角度的当前值q
(j)
计算机械手4的当前的手指坐标的第一推定值。用于正向运动学计算的变换函数是第一推定模型61的一例。即,在末端执行器t未保持工件w的场景中,第一变换矩阵组相当于第一推定模型61的一例。另外,在末端执行器t保持工件w的场景中,第二变换矩阵组相当于第一推定模型61的一例。各变换函数的各参数相当于第一推定模型61的参数的一例。
[0334]
(2)第二推定值的计算过程
[0335]
接着,对第二推定值的计算过程的一例进行说明。控制部31利用cad数据320,对由照相机s1得到的图像数据(第二传感数据324)匹配各对象物的模型。由此,控制部31能够计算机械手4的当前的手指坐标的第二推定值(换言之,推定当前值x
(j)
)。在这种情况下,控制部31也可以根据通过上述步骤s306在任务空间中推定的当前的任务状态s(j),来计算机械手4的当前的手指坐标的第二推定值。
[0336]
x=φ(s)=tw·s…
(式10)
[0337]
基于图18所示的各对象物的位置关系,在末端执行器t未保持工件w的情况下的任务状态s及手指的坐标x之间的关系能够由上述式10来表现。在这种情况下,从任务空间到
观测空间的变换函数(ψ)通过工件w的坐标(tw)赋予。控制部31通过将通过上述步骤s306获取的当前任务状态s
(j)
及通过匹配推定的工件w的坐标的当前值(t
w(j)
)代入式10,并执行上述式10的运算处理,能够计算机械手4的当前的手指坐标的第二推定值。
[0338]
x=φ(s)=tg·s…
(式11)
[0339]
同样地,在末端执行器t保持工件w的情况下的任务状态s及手指的坐标x之间的关系能够由上述式11来表现。在这种情况下,从任务空间到观测空间的变换函数(ψ)通过其他工件g的坐标(tg)赋予。控制部31通过将通过上述步骤s306获取的当前的任务状态s
(j)
及通过匹配推定的其他工件g的坐标的当前值(t
g(j)
)代入式11,并执行上述式11的运算处理,能够计算机械手4的当前的手指坐标的第二推定值。
[0340]
上述式10及式11的变换函数(ψ)是第二推定模型62的一例。各变换函数(ψ)的各参数相当于第二推定模型62的参数。需要说明的是,通过使用了cad数据320的匹配来推定机械手4的手指坐标的当前值x
(j)
的方法也可以不限于这样的例子。在末端执行器t未保持工件w的情况下,控制部31也可以通过上述匹配来推定末端执行器t的坐标的当前值(t
t(j)
),并获取推定的当前值(t
t(j)
)作为当前的手指坐标的第二推定值。同样地,在末端执行器t保持工件w的情况下,控制部31也可以通过上述匹配来推定工件w的坐标的当前值(t
w(j)
),并获取推定的当前值(t
w(j)
)作为当前的手指坐标的第二推定值。即,控制部31也可以通过上述匹配直接导出机械手4的当前的手指坐标的第二推定值。在这种情况下,各坐标(t
t
、tw)是第二推定模型62的一例。另外,各坐标(t
t
、tw)的各项是第二推定模型62的参数的一例。
[0341]
(3)总结
[0342]
由此,控制部31能够计算机械手4的当前的手指坐标的第一推定值及第二推定值。控制部31基于第一推定部及第二推定部中的至少一方,认定机械手4的手指坐标的当前值x
(j)
。该认定可以适当进行。例如,控制部31也可以直接采用第一推定值及第二推定值中的任一个作为手指坐标的当前值x
(j)
。另外,例如控制部31也可以计算第一推定值及第二推定值的平均值,并获取计算出的平均值作为手指坐标的当前值x
(j)
。在这种情况下,平均值可以通过加权平均来计算。可以进行各推定值的加权,以使假设推定精度高的推定值优先。作为一例,假设基于正向运动学计算的手指坐标的推定精度比基于对照相机s1的图像数据的匹配的手指坐标的推定精度高。在这种情况下,也可以进行各推定值的加权,以使第一推定值比第二推定值优先。当获取手指坐标的当前值x
(j)
时,控制部31使处理进入下一步骤s308。
[0343]
需要说明的是,在不执行后述的调整处理的情况下,可以省略第一推定值及第二推定值中的任一个的计算处理。另外,执行步骤s307的处理的时机也可以不限于这样的例子。步骤s307的处理可以在执行后述的步骤s310的处理之前的任意的时机执行。例如,步骤s307的处理可以在上述步骤s306之前执行。另外,例如在进行使用了cad数据320的匹配的情况下,步骤s307的处理可以与上述步骤s306或步骤s304的处理一并执行。
[0344]
(步骤s308)
[0345]
在步骤s308中,控制部31作为行动确定部316进行动作,确定相对于所获取的当前的任务状态s
(j)
接下来要迁移的目标的任务状态s
s(j)
,以接近最终目标的任务状态sg。在本实施方式中,控制部31参照推理模型数据225,利用通过上述步骤s210的处理生成的推理模型55,确定相对于当前的任务状态s
(j)
接下来要迁移的目标的任务状态s
s(j)
。
[0346]
用于推理接下来要迁移的目标的任务状态s
s(j)
的推理模型55的运算处理可以根据该推理模型55的构成适当执行。在通过上述第一方法生成推理模型55,推理模型55由函数式构成的情况下,控制部31将当前的任务状态s
(j)
及最终目标的任务状态sg代入函数式,执行该函数式的运算处理。在推理模型55由神经网络构成的情况下,控制部31将当前的任务状态s
(j)
及最终目标的任务状态sg输入到输入层,从输入侧开始依次进行各层中包括的各神经元的发火判定。在推理模型55由数据表构成的情况下,控制部31将当前的任务状态s
(j)
及最终目标的任务状态sg与数据表进行对照。由此,控制部31获取推理接下来要迁移的目标的任务状态s
s(j)
的结果作为推理模型55的输出。控制部31根据该推理结果,能够确定接下来要迁移的目标的任务状态s
s(j)
。
[0347]
另外,在通过上述第二方法生成推理模型55,即推理模型55由势场构成的情况下,控制部31参照设定为所生成的势场中的与当前的任务状态s
(j)
对应的坐标的电势的值。然后,控制部31根据设定为与当前的任务状态s
(j)
对应的坐标的电势的梯度,确定接下来要迁移的目标的任务状态s
(j)
。具体而言,控制部31确定目标的任务状态s
s(j)
,以使向电势的梯度高的一方迁移(例如向梯度最高的一方仅迁移规定的距离)。
[0348]
所确定的目标的任务状态的数量也可以不限于一个。在步骤s308中,控制部31也可以将所确定的目标的任务状态用作当前的任务状态,来确定接下来进一步要迁移的目标的任务状态。控制部31也可以通过重复该处理,来多次确定目标的任务状态。当确定接下来要迁移的目标的任务状态s
s(j)
时,控制部31使处理进入下一步骤s309。
[0349]
(步骤s309)
[0350]
在步骤s309中,控制部31作为指令确定部317进行动作,根据所确定的目标的任务状态s
s(j)
计算手指坐标的目标值x
s(j)
。如图17所示,控制部31通过利用上述变换函数(ψ),能够将任务空间中的目标的任务状态s
s(j)
变换为观测空间中的手指坐标的目标值x
s(j)
。
[0351]
即,在末端执行器t未保持工件w的情况下的从任务空间到观测空间的变换函数(ψ)通过上述式10赋予。控制部31通过将所确定的目标的任务状态s
s(j)
代入上述式10,并执行上述式10的运算处理,能够计算手指坐标的目标值x
s(j)
。另一方面,在末端执行器t保持工件w的情况下的从任务空间到观测空间的变换函数(ψ)通过上述式11赋予。控制部31通过将所确定的目标的任务状态s
s(j)
代入上述式11,并执行上述式11的运算处理,能够计算手指坐标的目标值x
s(j)
。当计算出手指坐标的目标值x
s(j)
时,控制部31使处理进入下一步骤s310。
[0352]
(步骤s310)
[0353]
在步骤s310中,控制部31作为指令确定部317进行动作,根据手指坐标的当前值x
(j)
及手指坐标的目标值x
s(j)
确定手指坐标的变化量(δx
(j)
)。具体而言,如图17所示,控制部31基于手指坐标的当前值(x
(j)
)及目标值(x
s(j)
)的偏差确定手指坐标的变化量(δx
(j)
)。例如,手指坐标的当前值及目标值的偏差(x
s-x)与变化量(δx)的关系可以通过以下的式12赋予。需要说明的是,手指坐标的变化量(δx)是手指坐标的当前值及目标值的差分的一例。
[0354]
δx=α
×
(x
x
…
x)
…
(式12)
[0355]
α是任意的系数。例如,α的值可以在1以下且超过0的范围内适当确定。α可以省略。控制部31通过将通过步骤s307及步骤s309得到的手指坐标的当前值x
(j)
及手指坐标的目标
值x
s(j)
代入上述式12,并执行上述式12的运算处理,能够确定手指坐标的变化量(δx
(j)
)。当确定手指坐标的变化量(δx
(j)
)时,控制部31使处理进入到下一步骤s311。
[0356]
(步骤s311)
[0357]
在步骤s311中,控制部31作为指令确定部317进行动作,通过使用了上述正向运动学计算中的变换函数的反函数的反向运动学计算,根据所确定的手指坐标的变化量(δx
(j)
)计算各关节的角度的变化量(δq
(j)
)。具体而言,手指坐标的变化量(δx)和各关节的角度的变化量(δq)能够由以下的式13来表现。
[0358][0359]
j是根据上述正向运动学计算中的变换函数导出的雅可比矩阵。ji表示第i个关节的矩阵向量,δqi表示第i个关节的变化量。
[0360]
这里,进一步使用图19a及图19b对雅可比矩阵的计算方法的一例进行说明。图19a示意性地示例了末端执行器t未保持工件w时的各关节与手指的关系的一例。图19b示意性地示例了末端执行器t保持工件w时的各关节与手指的关系的一例。
[0361]
如图19a所示,当末端执行器t未保持工件w时,雅可比矩阵的各关节的向量基于各关节与末端执行器t的位置关系来计算。例如,控制部31能够通过以下的式14计算各关节的向量。另一方面,如图19b所示,当末端执行器t保持工件w时,雅可比矩阵的各关节的向量基于各关节与工件w的位置关系来计算。例如,控制部31能够通过以下的式15计算各关节的向量。
[0362][0363][0364]
zi表示第i个关节的齐次坐标中的旋转轴的向量,ai表示第i个关节的齐次坐标中的平行移动向量。zi及ai从第i个关节的第一齐次变换矩阵中提取。a
t
表示末端执行器t的齐次坐标中的平行移动向量。aw表示工件w的齐次坐标中的平行移动向量。a
t
从末端执行器t的坐标(t
t
)中提取。aw从工件w的坐标(tw)中提取。雅可比矩阵的各向量ji表示各关节的第一齐次变换矩阵的微分向量。
[0365]
控制部31按照上述式14及式15,根据动作模式计算雅可比矩阵。需要说明的是,在本实施方式中,在末端执行器t未保持工件w的情况与末端执行器t保持工件w的情况之间,只不过是在雅可比矩阵的各向量中替换末端执行器t的向量(a
t
)及工件w的向量(aw)而已。因此,控制部31能够通过简单的计算处理来计算各个情况下的雅可比矩阵。
[0366]
接着,控制部31计算所计算出的雅可比矩阵的逆矩阵(j-1
)。控制部31使用计算出的逆矩阵(j-1
)执行反向运动学计算。具体而言,各变化量(δx、δq)与逆矩阵(j-1
)的关系根据上述式13如以下的式16所示导出。
[0367]
δq=j-1
·
δx
…
(式16)
[0368]
控制部31通过将计算出的逆矩阵(j-1
)及手指坐标的变化量(δx
(j)
)代入式16,并
执行上述式16的运算处理,能够计算各关节的角度的变化量(δq
(j)
)。当计算出各关节的角度的变化量(δq(i))时,控制部31使处理进入下一步骤s312。
[0369]
(步骤s312)
[0370]
在步骤s312中,控制部31作为指令确定部317进行动作,基于计算出的各关节的角度的变化量,确定针对各关节的指令值。确定指令值的方法例如可以采用pid(proportional-integral-differential:比例-积分-微分)控制、pi控制等公知的方法。针对各关节的指令值是赋予机械手4的控制指令的一例。在本实施方式中,控制部31通过步骤s309~步骤s312的处理,能够确定赋予机械手4的控制指令,以使手指坐标接近目标值(进而,使机械手4的任务状态从当前的任务状态s
(j)
向目标的任务状态s
(j)
变化)。当确定控制指令时,控制部31使处理进入下一步骤s313。
[0371]
(步骤s313)
[0372]
在步骤s313中,控制部31作为驱动部318进行动作,通过将所确定的控制指令赋予机械手4来驱动机械手4。在本实施方式中,控制部31根据所确定的各指令值来驱动机械手4的各关节。需要说明的是,驱动方法也可以不特别限定,可以根据实施方式适当选择。例如,控制部31也可以直接驱动机械手4的各关节。或者,机械手4也可以具备控制器(未图示)。在这种情况下,控制部31也可以通过将针对各关节的指令值赋予控制器来间接驱动机械手4的各关节。当按照所确定的控制指令驱动机械手4时,控制部31使处理进入下一步骤s314。
[0373]
(步骤s314~步骤s316)
[0374]
步骤s314~步骤s316的处理除了循环从(j)进入(j+1)这一点以外,与上述步骤s303、步骤s306及步骤s307的处理相同。即,在步骤s314中,控制部31从各传感器系统获取各传感数据(323、324)。在步骤s315中,控制部31作为状态获取部315进行动作,获取机械手4的当前的任务状态s
(j+1)
。在步骤s316中,控制部31作为各推定部(313、314)进行动作,根据所获取的各传感数据(323、324)计算机械手4的当前的手指坐标的各推定值。控制部31基于计算出的第一推定值及第二推定值中的至少一方,认定手指坐标的当前值x
(j+1)
。由此,当获取手指坐标的当前值x
(i+1)
时,控制部31使处理进入下一步骤s317。
[0375]
(步骤s317)
[0376]
在步骤s317中,控制部31判定步骤s313的驱动结果,即机械手4的任务状态是否迁移到了目标的任务状态s
s(j)
。
[0377]
判定方法也可以不特别限定,可以根据实施方式适当选择。例如,如图17所示,驱动后的各关节的角度(q
(j+1)
)与驱动前的各关节的角度(q
(j)
)的关系能够由以下的式17来表现。
[0378]q(j+1)
…q(j)
+δq
(j)
…
(式17)
[0379]
因此,控制部31也可以判定在步骤s314中由各编码器s2得到的各关节的角度的值是否与在驱动前由各编码器s2得到的各关节的角度的值(q
(j)
)及在步骤s311中计算出的变化量(δq
(j)
)之和一致。在驱动后的各关节的角度与驱动前的各关节的角度及计算出的变化量之和(q
(j)
+δq
(j)
)一致的情况下,控制部31也可以判定为机械手4的任务状态迁移到了目标的任务状态s
s(j)
。另一方面,在不是这样的情况下,控制部31也可以判定为机械手4的任务状态没有迁移到目标的任务状态s
s(j)
。
[0380]
另外,例如与正向运动学计算中的变换函数同样地,关于变换函数(ψ),也可以导
出雅可比矩阵j
ψ
。雅可比矩阵j
ψ
表示变换函数(ψ)的微分向量。可以根据所导出的雅可比矩阵j
ψ
计算逆矩阵(j
ψ-1
)。手指坐标的变化量(δx)及任务状态的变化量(δs)与逆矩阵(j
ψ-1
)的关系可以由以下的式18来表现。
[0381]
δs=j
φ-1
·
δx
…
(式18)
[0382]
控制部31通过将计算出的逆矩阵(j
ψ-1
)及手指坐标的变化量(δx
(j)
)代入式18,并执行上述式18的运算处理,能够计算任务状态的变化量(δs
(j)
)。驱动后的任务状态s
(j+1)
与驱动前的任务状态s
(j)
的关系,与上述式17同样地,能够由以下的式19来表现。
[0383]s(j+1)
=s
(j)
+δs
(j)
…
(式19)
[0384]
因此,控制部31也可以判定:通过步骤s315在驱动后得到的当前的任务状态是否与通过步骤s306在驱动前得到的当前的任务状态s
(j)
及通过上述计算出的变化量(δs
(j)
)之和一致。在驱动后得到的当前的任务状态与驱动前得到的当前的任务状态及计算出的变化量之和(s
(j)
+δs
(j)
)一致的情况下,控制部31也可以判定为机械手4的任务状态迁移到了目标的任务状态s
s(j)
。另一方面,在不是这样的情况下,控制部31也可以判定为机械手4的任务状态没有迁移到目标的任务状态s
s(j)
。需要说明的是,在本实施方式中,由于任务空间由两个对象物之间的相对坐标规定,因此任务空间及观测空间能够由相互共同的维度来表现。因此,根据情况,也可以将式18的逆矩阵(j
ψ-1
)替换为单位矩阵,将手指坐标的变化量(δx)直接作为任务状态的变化量(δs)处理。作为一例,在由从其他工件g观察的工件w的相对坐标来规定任务状态的情况下,式18的逆矩阵(j
ψ-1
)可以替换为单位矩阵。
[0385]
或者,控制部31也可以判定通过步骤s315得到的当前的任务状态是否与通过步骤s308确定的目标的任务状态s
s(j)
一致。在所得到的当前的任务状态与目标的任务状态s
s(j)
一致的情况下,控制部31也可以判定为机械手4的任务状态迁移到了目标的任务状态s
s(j)
。另一方面,在不是这样的情况下,控制部31也可以判定为机械手4的任务状态没有迁移到目标的任务状态s
s(j)
。
[0386]
另外,例如驱动后的手指坐标的当前值(x
(j+1)
)与驱动前的手指坐标的当前值(x
(j)
)的关系与上述式17同样地,能够由以下的式20来表现。
[0387]
x
(j+1)
…
x
(j)
+δx
(j)
…
(式20)
[0388]
因此,控制部31也可以判定:通过步骤s316获取的驱动后的手指坐标的当前值是否与通过步骤s307获取的驱动前的手指坐标的当前值(x
(j)
)及通过步骤s310确定的变化量(δx
(j)
)之和一致。在驱动后的手指坐标的当前值与驱动前的手指坐标的当前值及计算出的变化量之和(x
(j)
+δx
(j)
)一致的情况下,控制部31也可以判定为机械手4的任务状态迁移到了目标的任务状态s
s(j)
。另一方面,在不是这样的情况下,控制部31也可以判定为机械手4的任务状态没有迁移到目标的任务状态s
s(j)
。
[0389]
或者,控制部31也可以判定:通过步骤s316获取的手指坐标的当前值是否与通过步骤s309计算出的手指坐标的目标值(x
s(j)
)一致。在驱动后的手指坐标的当前值与驱动前计算出的手指坐标的目标值(x
s(j)
)一致的情况下,控制部31也可以判定为机械手4的任务状态迁移到了目标的任务状态s
s(j)
。另一方面,在不是这样的情况下,控制部31也可以判定为机械手4的任务状态没有迁移到目标的任务状态s
s(j)
。
[0390]
通过以上的任一个方法,控制部31能够判定机械手4的任务状态是否迁移到了目标的任务状态s
s(j)
。需要说明的是,在以上的各判定中,“一致”除了两者的值完全一致以
外,也可以包括两者的值的差分在阈值(允许误差)以下。在判定为机械手4的任务状态迁移到了目标的任务状态s
s(j)
的情况下,控制部31使处理进入下一步骤s318。另一方面,在不是这样的情况下,控制部31返回到步骤s310,再次执行机械手4的驱动。此时,控制部31也可以将通过步骤s316计算出的手指坐标的当前值用作当前值x
(j)
,执行步骤s310以后的处理。
[0391]
(步骤s318)
[0392]
在步骤s318中,控制部31判定是否能够实现最终目标任务状态sg。
[0393]
判定方法也可以不特别限定,可以根据实施方式适当选择。例如,控制部31可以判定通过步骤s315得到的当前的任务状态s
(j+1)
是否与最终目标的任务状态sg一致。在当前的任务状态s
(j+1)
与最终目标的任务状态sg一致的情况下,控制部31判定为能够实现最终目标的任务状态sg。另一方面,在不是这样的情况下,控制部31判定为不能实现最终目标的任务状态sg。与上述同样地,该判定中的“一致”除了两者的值完全一致以外,也可以包括两者的值的差分在阈值(允许误差)以下。
[0394]
在判定为能够实现最终目标的任务状态sg的情况下,控制部31结束与机械手4的动作控制相关的一系列处理。另一方面,在判定为不能实现最终目标的任务状态sg的情况下,控制部31将处理返回到步骤s308。然后,控制部31利用步骤s315及步骤s316的结果,再次执行步骤s308~步骤s313的处理。控制部31通过重复上述一系列处理来实现最终目标的任务状态sg。由此,本实施方式所涉及的控制装置3能够控制机械手4的动作,以执行所指定的任务。
[0395]
需要说明的是,判定为不能实现最终目标的任务状态sg的情况下的分支目的地也可以不限于上述步骤s308。例如,在使机械手4执行由多个任务构成的一系列任务的情况下,可以在最终目标的任务状态sg中设定最后执行的任务中的最终目标的任务状态。在本实施方式中,在执行通过末端执行器t保持工件w,并将所保持的工件w组装到其他工件g的任务的情况下,在最终目标的任务状态sg中,可以采用将工件w组装到其他工件g的状态。在这种情况下,一系列任务的执行可以从最初的任务的起点开始。与此相应地,判定为不能实现最终目标的任务状态sg的情况下的分支目的地可以不是上述步骤s308,而是上述步骤s303。由此,控制部31通过步骤s304及步骤s305的处理,能够在确认动作模式的同时驱动机械手4。其结果,能够在顺利地进行各任务的切换的同时执行一系列任务。在本实施方式中,在通过末端执行器t保持工件w时,能够将动作模式顺利地切换为将工件w搬运到其他工件g的任务。
[0396]
(b)调整处理
[0397]
接着,使用图20对与本实施方式所涉及的控制装置3的上述各推定模型(61、62)的参数调整相关的动作例进行说明。图20是示出与本实施方式所涉及的控制装置3的各推定模型(61、62)的参数调整相关的处理顺序的一例的流程图。在本实施方式中,第一推定模型61是用于上述正向运动学计算的变换函数(第一变换矩阵组或第二变换矩阵组)。另外,第二推定模型62是将任务空间的值变换为观测空间的值的变换函数(ψ)或各坐标(t
t
、tw)。与该参数调整相关的信息处理可以和与上述机械手4的动作控制相关的信息处理一并执行,或者也可以单独执行。包括与上述动作控制相关的处理顺序在内,以下说明的处理顺序是本发明的“控制方法”的一例。其中,以下说明的各处理顺序只不过是一例而已,各步骤可以尽可能地变更。进而,对于以下说明的各处理顺序,可以根据实施方式适当地进行步骤的省
略、替换及追加。
[0398]
(步骤s401及步骤s402)
[0399]
在步骤s401中,控制部31作为各数据获取部(311、312)进行动作,从各传感器系统获取各传感数据(323、324)。步骤s401的处理与上述步骤s303及步骤s314的处理相同。在步骤s402中,控制部31作为各推定部(313、314)进行动作,利用各推定模型(61、62),根据所获取的各传感数据(323、324)计算当前的手指坐标的各推定值。步骤s402的处理与上述步骤s307及步骤s316的处理相同。当计算出各推定值时,控制部31使处理进入下一步骤s403。
[0400]
需要说明的是,在与本参数调整相关的信息处理和与上述动作控制相关的信息处理一并执行的情况下,步骤s401的执行相当于上述步骤s303或步骤s314的执行。另外,步骤s402的执行相当于上述步骤s307或步骤s316的执行。在这种情况下,在执行步骤s307或步骤s316之后,控制部31也可以在任意的时机执行接下来的步骤s403的处理。
[0401]
(步骤s403及步骤s404)
[0402]
在步骤s403中,控制部31作为调整部319进行动作,计算所计算出的第一推定值与第二推定值之间的误差的梯度。误差的计算可以使用误差函数等的函数式。例如,控制部31通过计算第一推定值与第二推定值的差分,并计算所计算出的差分的乘方(例如平方),能够获取所得到的值作为误差。另外,控制部31通过对计算出的误差计算偏微分,能够计算与各推定模型(61、62)的各参数相关的误差的梯度。
[0403]
在步骤s404中,控制部31作为调整部319进行动作,基于计算出的梯度,调整第一推定模型61及第二推定模型62中的至少一方的参数的值,以使第一推定值及第二推定值之间的误差变小。作为一例,控制部31通过从各参数的值中减去针对各参数计算出的梯度,来更新各参数的值。由此,控制部31能够基于计算出的梯度来调整各参数的值。
[0404]
也可以调整双方的推定模型(61、62)的参数的值。或者,也可以仅调整推定模型(61、62)中的任一方的参数的值。在双方都可能产生噪声的情况下,或者可能在双方的推定模型(61、62)的参数都不适当的情况下,优选调整双方的推定模型(61、62)的参数。当参数的调整完成时,控制部31使处理进入下一步骤s405。
[0405]
(步骤s405)
[0406]
在步骤s405中,控制部31判断是否结束调整各推定模型(61、62)的参数的处理。结束参数调整的处理的基准可以根据实施方式适当确定。
[0407]
例如,也可以设定直到结束为止重复参数调整的规定次数。规定次数例如可以通过设定值赋予,也可以通过操作者的指定赋予。在这种情况下,控制部31判定执行步骤s401~步骤s404的处理的次数是否达到规定次数。在判定为执行次数未达到规定次数的情况下,控制部31将处理返回到步骤s401,重复步骤s401~步骤s404的处理。另一方面,在判定为执行次数达到了规定次数的情况下,控制部31结束与基于第一推定值及第二推定值的误差的梯度的参数调整相关的一系列处理。
[0408]
另外,例如控制部31也可以询问操作者是否重复处理。在这种情况下,控制部31根据操作者的回答,判定是否重复与参数调整相关的处理。在操作者回答重复处理的情况下,控制部31将处理返回到步骤s401,重复步骤s401~步骤s404的处理。另一方面,在操作者回答不重复处理的情况下,控制部31结束与基于第一推定值及第二推定值的误差的梯度的参数调整相关的一系列处理。
[0409]
《接触发生时的调整处理》
[0410]
接着,使用图21对与本实施方式所涉及的控制装置3的其他方法的各推定模型(61、62)的参数调整相关的动作例进行说明。图21是示出与其他方法的各推定模型(61、62)的参数调整相关的处理顺序的一例的流程图。
[0411]
本实施方式所涉及的控制装置3除了上述图20所示例的方法的参数调整以外,在机械手4的手指与某对象物接触时,执行图21所示例的参数调整的处理。在本实施方式中,在末端执行器t未保持工件w的情况下,末端执行器t是机械手4的手指,工件w是机械手4的手指接触的对象物的一例。另一方面,在末端执行器t保持工件w的情况下,工件g是机械手4的手指,其他工件g是机械手4的手指接触的对象物的一例。
[0412]
与该图21所示例的方法的参数调整相关的信息处理也与上述同样地,可以和与机械手4的动作控制相关的信息处理一并执行,或者也可以单独执行。包括与上述动作控制相关的处理顺序在内,以下说明的处理顺序是本发明的“控制方法”的一例。其中,以下说明的各处理顺序只不过是一例而已,各步骤可以尽可能地变更。进而,对于以下说明的各处理顺序,可以根据实施方式适当地进行步骤的省略、替换及追加。
[0413]
(步骤s411及步骤s412)
[0414]
在步骤s411中,控制部31作为各数据获取部(311、312)进行动作,从各传感器系统获取各传感数据(323、324)。步骤s411的处理与上述步骤s401的处理相同。在步骤s412中,控制部31作为各推定部(313、314)进行动作,利用各推定模型(61、62),根据所获取的各传感数据(323、324)计算当前的手指坐标的各推定值。步骤s412的处理与上述步骤s402的处理相同。当计算出各推定值时,控制部31使处理进入下一步骤s413。
[0415]
(步骤s413)
[0416]
在步骤s413中,控制部31作为调整部319进行动作,在与对象物接触的边界面上获取手指坐标的边界值。获取手指坐标的边界值的方法也可以不特别限定,可以根据实施方式适当选择。例如,手指坐标的边界值也可以通过经由输入装置35的操作者的指定来得到。另外,在本实施方式中,由机械手4的手指及目标物之间的相对坐标规定任务状态。也可以利用表现该任务状态(相对坐标)的集合的任务空间sp来得到手指坐标的边界值。
[0417]
这里,使用图22对利用任务空间sp获取手指坐标的边界值的方法的一例进行说明。图22示意性地示例了在任务空间sp中在接触的边界面上获取边界值的场景的一例。首先,控制部31通过将通过步骤s412计算出的手指坐标的各推定值输入到变换函数(ψ)的逆函数,并执行该逆函数的运算处理,来计算与各推定值对应的任务空间sp内的坐标。在图22的例子中,节点ne1表示与第一推定值对应的坐标,节点ne2表示与第二推定值对应的坐标。
[0418]
接着,控制部31导出任务空间sp中的接触的边界面。接触的边界面的导出可以使用学习完毕的判定模型50。在这种情况下,控制装置3(存储部32)也可以通过保持学习结果数据125而具备学习完毕的判定模型50。或者,控制部31也可以通过经由网络访问第二模型生成装置2,来从第二模型生成装置2获取边界面的导出结果。
[0419]
接着,控制部31在所导出的接触的边界面上,选择与第一推定值对应的坐标(节点ne1)及与第二推定值对应的坐标(节点ne2)中的至少一方接近的节点nb。例如,控制部31也可以选择与双方的节点(ne1、ne2)最接近的节点作为节点nb。控制部31通过将所选择的节点nb的坐标输入到变换函数(ψ),并执行该变换函数(ψ)的运算处理,能够计算手指坐标的
边界值。
[0420]
通过以上的任一个方法,控制部31能够获取手指坐标的边界值。当获取手指坐标的边界值时,控制部31使处理进入下一步骤s414。需要说明的是,获取手指坐标的边界值的方法也可以不限于这些例子。例如,控制部31也可以在观测空间中直接导出接触的边界面。控制部31也可以在所导出的接触的边界面上,选择与第一推定值的坐标及第二推定值的坐标中的至少一方接近的点。另外,控制部31也可以获取所选择的点的坐标作为边界值。
[0421]
(步骤s414及步骤s415)
[0422]
在步骤s414中,控制部31作为调整部319进行动作,计算接触时推定的第一推定值与所获取的边界值之间的第一误差的梯度。另外,控制部31计算接触时推定的第二推定值及所获取的边界值之间的第二误差的梯度。计算各梯度的方法可以与上述步骤s403相同。
[0423]
在步骤s415中,控制部31作为调整部319进行动作,并基于计算出的第一误差的梯度,调整第一推定模型61的参数值,以使第一误差变小。另外,控制部31基于计算出的第二误差的梯度,调整第二推定模型62的参数的值,以使第二误差变小。调整参数的值的方法可以与上述步骤s404相同。当参数的调整完成时,控制部31结束与利用了边界值的参数调整相关的一系列处理。
[0424]
《处理时机》
[0425]
下面,使用图23对上述动作控制的时机与参数调整的时机的关系的一例进行说明。图23示意性地示例了动作控制的时机与参数调整的时机的关系的一例。
[0426]
第一传感器系统及第二传感器系统各自的处理周期,换言之,获取各传感数据(323、324)的周期并不一定相同。在各个处理周期不同的情况下,也可以在能够从第一传感器系统及第二传感器系统中的至少一方得到传感数据的时机,执行与上述机械手4的动作控制相关的信息处理。与此相对,控制部31也可以在能够获取双方的传感数据(323、324)的时机,执行上述参数调整。
[0427]
在图23的例子中,假设由各编码器s2及触觉传感器s3构成的第一传感器系统的处理周期比由照相机s1构成的第二传感器系统的处理周期短。作为一例,假设第一传感器系统的处理周期为10ms(毫秒),第二传感器系统的处理周期为30ms。在这种情况下,在由第二传感器系统获取一次第二传感数据324期间,能够由第一传感器系统获取三次第一传感数据323。
[0428]
在该图23的例子中,在能够从第一传感器系统仅获取第一传感数据323的时机,控制部31也可以利用根据第一传感数据323计算出的当前的手指坐标的第一推定值,来控制机械手4的动作。另一方面,在能够从第一传感器系统及第二传感器系统获取双方的传感数据(323、324)的时机,控制部31也可以利用分别计算出的当前的手指坐标的第一推定值及第二推定值中的至少一方,来控制机械手4的动作。另外,在该时机,控制部31也可以执行上述图20所示的参数调整的信息处理。
[0429]
进而,在机械手4的手指与某对象物接触的情况下,控制部31也可以停止机械手4的动作控制,待机到能够从第一传感器系统及第二传感器系统获取双方的传感数据(323、324)的时机。然后,在能够获取双方的传感数据(323、324)的时机,控制部31也可以执行上述图21所示的参数调整的信息处理。除此以外,控制部31也可以一并执行上述图20所示的参数调整的信息处理。在执行上述图20及图21所示的双方的参数调整的情况下,上述步骤
s401可以作为与步骤s411共同的处理来执行,上述步骤s402可以作为与步骤s412共同的处理来执行。由此,能够控制机械手4的动作,并且在适当的时机调整各推定模型(61、62)的参数的值。
[0430]
需要说明的是,也可以在通过图20及图21所示的各方法调整各推定模型(61、62)的参数的值之后,适当评价各推定模型(61、62)的各推定值是否接近真值。作为一例,假设由各传感器系统得到的各传感数据(323、324)中可能包括的噪声为白噪声。因此,通过获取至少任一个规定时间量的传感数据,并将所得到的传感数据平均化,能够除去或降低传感数据中包括的噪声。在该平均化的传感数据中,根据是否包括与各推定模型(61、62)的各推定值相关的向量,能够评价各推定模型(61、62)的各推定值是否接近真值。
[0431]
例如,假设利用深度照相机作为照相机s1,获取了深度图(包括深度信息的图像数据)作为第二传感数据324。在这种情况下,控制部31将各推定值描绘在深度图上,对与各推定值对应的坐标和深度图上的机械手4的手指坐标进行比较。在该比较结果是相互的坐标一致(或者近似)的情况下,控制部31能够评价为各推定模型(61、62)的各推定值接近真值。另一方面,在相互的坐标背离的情况下,各推定模型(61、62)的各推定值可能不接近真值。在这种情况下,控制部31也可以重复基于上述图20及图21中的至少任一个方法的参数调整,直到能够评价为上述各推定值接近真值为止。
[0432]
[特征]
[0433]
如上所述,在本实施方式中,在上述步骤s404中,调整第一推定模型61及第二推定模型62中的至少一方的参数的值,以使相互的推定结果(推定值)接近一个值。另外,在机械手4的手指与对象物接触时,在上述步骤s415中,调整各推定模型(61、62)的参数的值,以使各推定值接近接触的边界值。通过这些调整,能够期待各推定模型(61、62)的手指坐标的推定精度的改善。特别是,根据步骤s415,由于伴随着与对象物接触这样的物理制约,因此通过基于准确度高的信息(边界值)调整各推定模型(61、62)的参数的值,能够改善各推定模型(61、62)的手指坐标的推定精度。因此,根据本实施方式,能够实现控制机械手4的手指坐标的精度的提高。
[0434]
另外,在本实施方式中,在上述步骤s307及步骤s316中,通过正向运动学计算,能够计算机械手4的当前的手指坐标的第一推定值。在末端执行器t未保持工件w的情况下,将末端执行器t设定为手指,在正向运动学计算中,由各关节(关节部41~46)的第一齐次变换矩阵导出的第一变换矩阵组被用作变换函数。另一方面,在末端执行器t保持工件w的情况下,将工件w设定为手指,扩展用于正向运动学计算的变换函数。具体而言,在正向运动学计算中,通过将用于将坐标从末端执行器t的坐标系变换为工件w的坐标系的第二齐次变换矩阵(
t
tw)与第一变换矩阵组相乘而得到的第二变换矩阵组被用作变换函数。即,在本实施方式中,在通过末端执行器t保持工件w时,将运动学的基准点从末端执行器t变更为工件w。
[0435]
由此,在末端执行器t未保持工件w的情况与保持工件w的情况下,能够大致同样地处理步骤s307及步骤s316的正向运动学计算、以及步骤s311的反向运动学计算。即,能够将通过末端执行器t保持工件w的第一任务及将通过末端执行器t保持的工件w组装到其他工件g的第二任务作为“相对于目标物移动机械手4的手指”的共同的任务来处理。因此,根据
本实施方式,能够不区分末端执行器t未保持工件w的情况和末端执行器t保持工件w的情况而通用且统一地规定控制处理。因此,能够简化控制处理,由此,能够降低生成或示教机械手4的动作的成本。在上述实施方式中,能够降低生成或示教通过末端执行器t保持工件w并将所保持的工件w组装到其他工件g的一系列动作的成本。
[0436]
另外,在本实施方式中,通过机械手4执行的任务状态由末端执行器t(末端执行器)、工件w、其他工件g等对象物间的相对位置关系来表现。由此,控制指令不是与任务直接建立关联,而与对象物间的相对位置关系的变化量建立关联。即,能够不依赖于任务的内容,对于使对象物的相对位置关系发生变化,来生成或示教赋予机械手4的时间序列的控制指令。例如,即使工件w的坐标发生变化,在上述步骤s306及步骤s315中,在把握末端执行器t与工件w之间的位置关系(任务状态)时,也考虑该工件w的坐标的变化。因此,机械手4能够基于学习结果,通过末端执行器t适当地保持工件w。因此,根据本实施方式,能够提高执行所掌握的任务的能力的通用性,由此,能够降低向机械手4示教任务所需的成本。
[0437]
另外,在本实施方式中,对象物间的位置关系由相对坐标来表现。由此,能够适当且简单地表现两个对象物之间的位置关系。因此,能够容易地把握两个对象物之间的位置关系(在控制的场景中,为任务状态)。
[0438]
另外,本实施方式所涉及的第一模型生成装置1通过上述步骤s101及步骤s102的处理,通过实施机器学习,来生成用于判定在对象的位置关系中两个对象物是否接触的判定模型50。根据通过机器学习生成的学习完毕的判定模型50,即使以连续值赋予对象的位置关系,也能够不伴随着判定模型50的数据量的大幅增加,而以该位置关系判定两个对象物是否相互接触。因此,根据本实施方式,能够大幅降低表现两个对象物接触的边界的信息的数据量。
[0439]
这里,进一步使用图24对该作用效果的具体例进行说明。图24示意性地示例了按每个坐标点保持表示两个对象物是否相互接触的值的方式的一例。白点表示在与该坐标对应的位置关系中两个对象物不相互接触,黑点表示在与该坐标对应的位置关系中两个对象物相互接触。在图24中,用二维表现各坐标点,但在上述六维的相对坐标的空间中,各坐标点用六维表现。在这种情况下,如果提高空间的分辨率(分辨率),则数据量以六次方的数量级增加。例如,当以能够用于实际空间中的运用的分辨率设定坐标点时,该信息的数据量能够简单地成为千兆字节单位。
[0440]
与此相对,在本实施方式中,通过学习完毕的判定模型50保持表示在对象的位置关系中两个对象物是否相互接触的信息。该学习完毕的判定模型50的运算参数的数量虽然能够依赖于相对坐标的维数,但能够不增加该运算参数的数量而处理连续值。因此,例如如后所述,在由三层结构的神经网络构成判定模型50的情况下,能够将学习完毕的判定模型50的数据量抑制为几兆字节左右。因此,根据本实施方式,能够大幅降低表现两个对象物接触的边界的信息的数据量。
[0441]
另外,在本实施方式中,机械手4的手指及目标物是通过学习完毕的判定模型50判定是否产生接触的两个对象物。因此,在规定机械手4的动作的场景中,能够大幅降低表现两个对象物接触的边界的信息的数据量。在第二模型生成装置2中,即使ram、rom及存储部22的容量比较小,也能够利用学习完毕的判定模型50,由此,能够生成用于确定目标的任务状态以使手指不会无用地接触目标物的推理模型55。
[0442]
另外,本实施方式所涉及的第二模型生成装置2通过步骤s201~步骤s210的处理,利用学习完毕的判定模型50,生成用于确定目标的任务状态以使第一对象物不与第二对象物接触的推理模型55。本实施方式所涉及的控制装置3在步骤s308中,利用所生成的推理模型55,确定目标的任务状态。由此,本实施方式所涉及的控制装置3即使不伴随着学习完毕的判定模型50的运算处理,也能够确定目标的任务状态,以使第一对象物不与第二对象物接触,即机械手4的手指不会无用地与目标物接触。因此,能够降低机械手4的动作控制的运算成本。
[0443]
§
4变形例
[0444]
以上,对本发明的实施方式进行了详细说明,但到上述为止的说明在所有方面都只不过是本发明的示例而已。当然能够在不脱离本发明的范围的情况下进行各种改良或变形。例如,能够进行以下变更。需要说明的是,以下对于与上述实施方式相同的构成要素使用相同的符号,对于与上述实施方式相同的方面适当省略说明。以下的变形例能够适当组合。
[0445]
《4.1》
[0446]
在上述实施方式中,末端执行器t、工件w及其他工件g分别是对象物的一例。特别是,其他工件g是工件w的组装目的地的对象物的一例。在末端执行器t未保持工件w的情况下,工件w是机械手4的手指接触的对象物的一例,在末端执行器t保持工件w的情况下,其他工件g是机械手4的手指接触的对象物的一例。其中,对象物也可以不限于这样的例子。对象物也可以包括在实际空间或虚拟空间内能够处理的所有种类的物体。对象物除了上述末端执行器t、工件w及其他工件g以外,例如也可以是障碍物等可能与机械手的动作关联的物体。
[0447]
需要说明的是,一个对象物可以由一个物体构成,或者也可以由多个物体构成。在存在三个以上的物体的情况下,判定模型50也可以构成为将多个物体视为一个对象物,判定在多个物体与其他物体之间是否产生接触。或者,判定模型50也可以构成为将各个物体视为一个对象物,判定在各个物体间是否产生接触。
[0448]
另外,在上述实施方式中,两个对象物中的至少任一个是通过机械手的动作而移动的对象。通过机械手的动作而移动的对象物例如可以是末端执行器等机械手的构成要素,也可以是机械手自身,例如也可以是通过末端执行器保持的工件等机械手的构成要素以外的物体。其中,对象物的种类也可以不限于这样的例子。两个对象物也可以都是通过机械手的动作而移动的对象以外的物体。
[0449]
另外,在上述实施方式中,机械手4是垂直多关节型机器人。但是,在根据由编码器s2得到的各关节的角度的当前值来推定机械手4的手指坐标的情况下,机械手4只要具备一个以上的关节即可,则其种类也可以不特别限定,可以根据实施方式适当选择。在其他情况下,机械手4也可以具备关节以外的构成要素。机械手4除了上述垂直多关节机器人以外,可以包括scara机器人、并联连杆机器人、正交机器人及协调机器人等。另外,在上述实施方式中,控制指令由针对各关节的角度的指令值构成。但是,控制指令的构成也可以不限于这样的例子,可以根据机械手4的种类适当确定。
[0450]
另外,在上述实施方式中,通过末端执行器t保持工件w的作业及将所保持的工件w组装到其他工件g的作业分别是机械手执行的任务的一例。任务只要是至少在工序的一部
分伴随着机械手的手指的移动的任务即可,其种类可以不特别限定,可以根据实施方式适当选择。任务除了上述工件w的保持及工件w的搬运以外,例如也可以是部件嵌合、螺丝旋转等。任务例如可以是工件的保持、工件的释放等简单的工作。任务例如可以是保持对象的工件、并将对象的工件配置在指定的坐标(位置及姿势)等变更对象的工件的坐标。任务例如可以是使用喷雾器作为末端执行器,通过该喷雾器从指定的相对坐标向工件喷雾涂料。另外,任务例如也可以是将安装在末端执行器上的照相机配置在指定的坐标。任务可以预先赋予,也可以通过操作者的指定赋予。
[0451]
另外,在上述实施方式中,第一传感器系统由各编码器s2及触觉传感器s3构成。另外,第二传感器系统由照相机s1构成。但是,各传感器系统只要能够观测机械手4的手指即可,用于各传感器系统的传感器的种类也可以不限于这样的例子,可以根据实施方式适当选择。可以在第一传感器系统与第二传感器系统之间共用至少一部分传感器。传感器除了照相机、编码器及触觉传感器以外,可以使用例如接近传感器、力觉传感器、力矩传感器及压力传感器等。接近传感器可以配置在能够观测末端执行器t的周围的范围内,用于观测接近末端执行器t的物体的有无。另外,力觉传感器、力矩传感器及压力传感器与上述触觉传感器s3同样地,可以配置在能够测定作用于末端执行器t的力的范围内,用于观测作用于末端执行器t的力。接近传感器、力觉传感器、力矩传感器及压力传感器中的至少任一个可以用作观测工件w相对于末端执行器t的状态的传感器。需要说明的是,照相机s1可以构成为通过机械手4或其他机器人装置能够任意移动。在这种情况下,照相机s1的坐标可以适当校准。由此,能够任意地控制由照相机s1观测的范围。
[0452]
在上述实施方式中,可以从第一传感器系统省略触觉传感器s3。在省略触觉传感器s3的情况下,第二齐次变换矩阵(
t
tw)的推定可以使用触觉传感器s3以外的传感器(例如照相机s1)。第一传感器系统可以具备用于观测工件w相对于末端执行器t的状态的其他传感器。或者,第二齐次变换矩阵(
t
tw)可以通过常数赋予。另外,在上述实施方式中,可以省略与是否保持工件w相应的机械手4的手指的设定。在这种情况下,机械手4的手指可以适当设定。例如,与是否保持工件w无关地,末端执行器t可以设定在机械手4的手指。
[0453]
《4.2》
[0454]
在上述实施方式中,在第二模型生成装置2中生成推理模型55时,利用学习完毕的判定模型50。但是,学习完毕的判定模型50的利用方式也可以不限于这样的例子。上述实施方式所涉及的控制装置3在控制机械手4的动作时,也可以利用学习完毕的判定模型50。在这种情况下,学习结果数据125与上述同样地,可以在任意的时机提供给控制装置3。另外,控制装置3构成为进一步具备接触判定部作为软件模块。
[0455]
图25示例了与本变形例所涉及的目标的任务状态的确定相关的子程序的处理顺序的一例。上述步骤s308的确定目标的任务状态的处理也可以替换为图25所示例的子程序的处理。
[0456]
在步骤s501中,控制部31作为行动确定部316进行动作,确定相对于所获取的当前的任务状态接下来要迁移的目标的任务状态,以接近最终目标的任务状态。步骤s501可以与上述步骤s308同样地处理。
[0457]
在步骤s502中,控制部31作为接触判定部进行动作,利用学习完毕的判定模型50,判定在所确定的目标的任务状态下两个对象物是否相互接触。步骤s502可以与上述步骤
s203及步骤s206同样地处理。
[0458]
在步骤s503中,控制部31基于步骤s502的判定结果,确定处理的分支目的地。在步骤s502中判断为在目标的任务状态下两个对象物相互接触的情况下,控制部31将处理返回到步骤s501,再次确定目标的任务状态。另一方面,在判定为在目标的任务状态下两个对象物不相互接触的情况下,控制部31执行接下来的步骤s309的处理。由此,控制装置3在控制机械手4的动作时,能够利用学习完毕的判定模型50来确定机械手4的动作,以使机械手4的手指不会无用地接触目标物。
[0459]
《4.3》
[0460]
在上述实施方式中,控制装置3在上述步骤s308中,利用推理模型55确定目标的任务状态。但是,确定目标的任务状态的方法也可以不限于这样的例子。目标的任务状态的确定也可以不利用推理模型55。例如,在上述步骤s308中,可以与上述步骤s205同样地确定目标的任务状态。作为一例,控制部31也可以通过路径规划等公知的方法来确定目标的任务状态。另外,例如也可以预先赋予目标的任务状态的系列。在这种情况下,在上述步骤s308中,控制部31也可以通过参照表示该序列的数据来确定接下来要迁移的目标的任务状态。上述步骤s501也同样。
[0461]
另外,在上述实施方式中,推理模型55的生成(步骤s201~步骤s211)可以省略。或者,在上述实施方式中,控制装置3也可以包括第二模型生成装置2的各构成。由此,控制装置3可以构成为进一步执行生成上述推理模型55的一系列处理(步骤s201~步骤s211)。在这些情况下,也可以从控制系统100省略第二模型生成装置2。
[0462]
另外,在上述实施方式中,为了收集学习数据223而利用学习完毕的判定模型50的判定结果。但是,学习数据223的收集也可以不限于这样的例子。例如,可以利用各对象物的实物等,不利用学习完毕的判定模型50而收集学习数据223。由此,推理模型55可以不利用学习完毕的判定模型50而生成。
[0463]
另外,在上述实施方式中,直到步骤s201~步骤s209为止的与学习数据223的收集相关的处理也可以由其他计算机进行。在这种情况下,上述实施方式所涉及的第二模型生成装置2也可以获取由其他计算机生成的学习数据223,使用所获取的学习数据223来执行步骤s210及步骤s211。
[0464]
《4.4》
[0465]
在上述实施方式中,两个对象物之间的位置关系由相对坐标来表现。但是,表现位置关系的方法也可以不限于这样的例子。例如,也可以由两个对象物各自的绝对坐标来表现位置关系。在这种情况下,也可以将各绝对坐标变换为相对坐标,来执行上述各信息处理。
[0466]
《4.5》
[0467]
另外,在上述实施方式中,控制装置3在步骤s309中根据目标的任务状态计算手指坐标的目标值。但是,获取手指坐标的目标值的方法也可以不限于这样的例子。手指坐标的目标值可以适当确定,以接近最终目标的任务状态。
[0468]
例如,手指坐标的目标值可以根据手指坐标的当前值及最终目标的任务状态下的手指坐标的值直接确定。作为一例,手指坐标的目标值的确定可以利用数据表等参照数据。在这种情况下,控制部31通过将手指坐标的当前值及最终目标的任务状态下的手指坐标的
值与参照数据进行对照,能够根据参照数据获取手指坐标的目标值。作为其他例子,例如控制部31也可以通过最邻近法等确定手指坐标的目标值,以使以最短距离从手指坐标的当前值到达最终目标的任务状态下的手指坐标的值。进而,作为其他例子,例如也可以与判定模型50、推理模型551等同样地,利用通过机器学习掌握了根据手指坐标的当前值及最终目标的任务状态下的手指坐标的值确定手指坐标的目标值的能力的学习完毕的机器学习模型。在这种情况下,控制部31将手指坐标的当前值及最终目标的任务状态下的手指坐标的值赋予学习完毕的机器学习模型,执行学习完毕的机器学习模型的运算处理。由此,控制部31能够从学习完毕的机器学习模型获取与确定了手指坐标的目标值的结果对应的输出值。
[0469]
在这种情况下,步骤s306、步骤s308、步骤s309及步骤s315可以从控制装置3的处理顺序中省略。另外,状态获取部315及行动确定部316可以从控制装置3的软件构成中省略。
[0470]
另外,在上述实施方式中,例如在预先设定了最终目标的任务状态的情况等,通过其他方法设定了最终目标的任务状态的情况下,可以从控制装置3的处理顺序中省略步骤s301及步骤s302的处理。在这种情况下,可以从控制装置3的软件构成中省略目标设定部310。
[0471]
另外,在上述实施方式中,可以从控制系统100中省略第一模型生成装置1。在这种情况下,也可以采用通过学习完毕的判定模型50以外的方法保持表示两个对象物是否相互接触的信息的方式。例如,也可以采用按每个坐标点保持表示两个对象物是否相互接触的值的方式。
[0472]
《4.6》
[0473]
在上述实施方式中,判定模型50由全连接型神经网络构成。但是,构成判定模型50的神经网络的种类也可以不限于这样的例子。判定模型50除了全连接型神经网络以外,例如也可以由卷积神经网络、递归型神经网络等构成。另外,判定模型50也可以由多种神经网络的组合构成。
[0474]
另外,构成判定模型50的机器学习模型的种类也可以不限于神经网络,可以根据实施方式适当选择。除了神经网络以外,判定模型50例如可以采用支持向量机、回归模型及决策树等的机器学习模型。可以以实际空间或虚拟空间为对象来判定两个对象物是否相互接触。
[0475]
在上述实施方式中,推理模型55可以按机械手4执行的任务的种类来准备。即,可以准备训练为推理各个不同的任务中的目标的任务状态的多个推理模型55。在这种情况下,控制装置3的控制部31也可以根据通过上述步骤s305设定的动作模式,从所准备的多个推理模型55中选择用于推理的推理模型55。由此,控制部31也可以根据动作模式切换推理模型55。或者,推理模型55也可以构成为例如进一步接收对象物的种类、对象物的识别符、任务的识别符、任务的种类等表示任务的条件的信息的输入,推理与所输入的条件对应的任务中的目标的任务状态。在这种情况下,控制部31在确定接下来要迁移的目标的任务状态时,也可以将表示通过上述步骤s305设定的动作模式的信息进一步输入到推理模型55,来执行上述步骤s308的运算处理。
[0476]
另外,在上述实施方式中,对判定模型50及推理模型55的输入及输出的形式也可以不特别限定,可以根据实施方式适当确定。例如,判定模型50也可以构成为进一步接收表
示任务状态的信息以外的信息的输入。同样地,推理模型55也可以构成为进一步接收当前的任务状态及最终目标的任务状态以外的信息的输入。在最终目标的任务状态恒定的情况下,可以从推理模型55的输入中省略表示最终目标的任务状态的信息。判定模型50及推理模型55的输出形式也可以是识别及回归中的任一种。
[0477]
另外,在上述实施例中,用于上述正向运动学计算的变换函数(第一变换矩阵组或第二变换矩阵组)是第一推定模型61的一例。另外,将任务空间的值变换为观测空间的值的变换函数(ψ)或各坐标(t
t
、tw)是第二推定模型62的一例。各推定模型(61、62)的构成也可以不限于这样的例子。各推定模型(61、62)可以适当构成为能够根据各传感数据(323、324)计算机械手4的手指坐标。
[0478]
各推定模型(61、62)具备用于根据各传感数据(323、324)计算手指坐标的参数。各推定模型(61、62)的种类也可以不特别限定,可以根据实施方式适当选择。各推定模型(61、62)例如可以由函数式、数据表等表现。在由函数式来表现的情况下,各推定模型(61、62)可以由神经网络、支持向量机、回归模型及决策树等机器学习模型构成。
[0479]
《4.7》
[0480]
在上述实施方式中,控制装置3构成为能够执行图20及图21双方的参数调整的信息处理。但是,控制装置3的构成也可以不限于这样的例子。在上述实施方式中,控制装置3可以构成为仅执行图20及图21中的任一方。例如,控制装置3可以构成为省略与图20所示的参数调整相关的信息处理的执行,在机械手4的手指与对象物接触时,执行与图21所示的参数调整相关的信息处理。
[0481]
符号说明
[0482]
1:第一模型生成装置;11:控制部;12:存储部;13:通信接口;14:外部接口;15:输入装置;16:输出装置;17:驱动器;91:存储介质;81:模型生成程序;111:数据获取部;112:机器学习部;113:保存处理部;120:cad数据;121:学习数据集;122:训练数据;123:正确数据;125:学习结果数据;2:第一模型生成装置;21:控制部;22:存储部;23:通信接口;24:外部接口;25:输入装置;26:输出装置;27:驱动器;92:存储介质;82:模型生成程序;211:接触判定部;212:数据收集部;213:模型生成部;214:保存处理部;220:cad数据;223:学习数据;225:推理模型数据;3:控制装置;31:控制部;32:存储部;33:通信接口;34:外部接口;35:输入装置;36:输出装置;37:驱动器;93:存储介质;83:控制程序;310:目标设定部;311:第一数据获取部;312:第二数据获取部;313:第一推定部;314:第二推定部;315:状态获取部;316:行动确定部;317:指令确定部;318:驱动部;319:调整部;320:cad数据;321:机器人数据;323:第一传感数据;324:第二传感数据;4:机械手;40:底座部;41~46:关节部;491~494:连杆;t:末端执行器;t0:关注点;ct:局部坐标系;w:工件;w0:关注点;cw:局部坐标系;g:其他工件;cg:局部坐标系;rc1
·
rc2:相对坐标;s1:照相机;s2:编码器;s3:触觉传感器;50:判定模型;501:输入层;502:中间(隐藏)层;503:输出层;55:推理模型;61:第一推定模型;62:第二推定模型。