1.本发明属于信息技术领域,涉及食源性疾病暴发识别技术,具体涉及一种基于链接预测的食源性疾病暴发识别方法和系统。
背景技术:
2.食源性疾病是指食物中致病因素进入人体引起的感染性、中毒性等疾病,包括食物中毒、疑似食源性异常疾病和食源性传染病。食源性疾病每年威胁着人们的健康,并在全球范围内造成经济损失。2015年,世界卫生组织指出,食源性疾病在全球范围内造成了沉重负担。全世界每年发生约6亿例食源性疾病,造成42万人死亡。因此,研究食源性疾病的监测和预防是必要的。食源性疾病暴发事件识别作为食源性疾病监测和预防的重要环节,合理应用数据挖掘与机器学习方法将有效提高食源性疾病暴发识别的准确率,达到监测与预防食源性疾病的目的。
3.现有技术与本发明直接相关的实现方法无论在科研论文还是专利中都较为少见。相关方法大致可以分为两类,一类研究根据食源性疾病发病率的变化来监测食源性疾病暴发事件的发生。当某地区或出现食源性疾病暴发事件时,医院就诊人数将产生极大的波动。因此,一些异常检测方法被用来根据发病率的变化来检测疾食源性病的暴发。此类方法需要发病率的历史基线作为依据(wong w k, moore a, cooper g, et al. rule-based anomaly pattern detection for detecting disease outbreaks[c]//aaai/iaai. 2002: 217-223.)。由于食源性疾病在时间与空间维度都呈现出明显的聚集性,另一类研究把疾病的暴发识别定义为聚类问题,在现有聚类问题的基础上进行改进以适应特定的问题场景。neil(neill d b, moore a w. rapid detection of significant spatial clusters[c]//proceedings of the tenth acm sigkdd international conference on knowledge discovery and data mining. 2004: 256-265.)等人使用时空扫描的统计学方式对流行病学的暴发进行了检测。基于已有的时空聚类疾病簇的监测方法,daniel等人(neill d b, moore a w, sabhnani m, et al. detection of emerging space-time clusters[c]//proceedings of the eleventh acm sigkdd international conference on knowledge discovery in data mining. 2005: 218-227.)也提出了一种针对新兴时空聚类的监测方法,用于新兴时空聚类的快速检测,发现由新出现的疾病暴发导致的疾病病例的时空群集。文中提出时空扫描统计的方法,通过时间与空间维度的建模,找到给定的空间区域集进行搜索,判断这些区域是产生的新型聚类还是长期存在的与疾病监测无关的聚类。这些方法在快速完成监测任务和准确检测新兴疾病流行方面取得了成功。xiao等人(xiao x, ge y, guo y, et al. automated detection for probable homologous foodborne disease outbreaks[c]//pacific-asia conference on knowledge discovery and data mining. springer, cham, 2015: 563-575.)提出了一种用于在线系统的同源食源性疾病暴发自动监测方法。文中将预测疾病暴发的任务分为聚集性食源性疾病暴发(lfdo)与散发性食源性疾病暴发(sfdo)两类。作者采用dbscan进行聚集性暴发
(lfdo)检测,并解决了dbscan中的参数自适应问题,提出k-cps (模式相似的k-means聚类)方法来检测散发性食源性疾病暴发(sfdo)。
[0004]
现有方法存在以下几方面的问题:1. 在一类以食源性疾病发病率作为观测指标来识别食源性疾病暴发事件的方法中,需要发病率的历史基线作为依据,历史数据的质量直接影响到暴发事件识别的效果。此外,食源性疾病具有实时性和突发性,食源性疾病发病率的统计需要依赖省市县各个级别的医院,不同医院之间发病率的上报需要时间,这也导致了该方法具有一定的时间滞后性。
[0005]
2. 直接相关的现有方法较少,且其中大部分方法都是应用在其他具有传染性的流行病暴发识别中,例如流感等等。传染性疾病与食源性疾病具有明显的特征差异,所以这些方法并不完全适用于食源性疾病暴发的识别。
[0006]
3. 现有的食源性疾病暴发识别方法并不适用于当前需要解决的问题。现有方法直接将食源性疾病暴发识别问题直接转化为聚类发现的问题。但是暴发识别与聚类仍然存在不同之处:在聚类问题场景中,聚类类别需要预先设定,并且所有样本都会被归属于某一类,而在暴发识别的问题场景下,真实数据中的类别(暴发事件)不可预知,而且可能包含不确定比例的离群点,所谓离群点即不属于任何一起暴发事件的病例。除此之外,不同暴发事件所包含的病例数变化范围较大,以上特点均增加了直接使用传统聚类算法解决当前问题的难度。
技术实现要素:
[0007]
本发明将食源性疾病暴发识别问题定义抽象为一个类似聚类的任务,构建一种端到端的模型,以病例样本的集合为输入,输出多个病例聚集而成的食源性疾病暴发事件,达到暴发事件识别的目的。
[0008]
目前我国食源性疾病监测报告系统通过使用人工定义筛选条件的方法来获得疑似食源性疾病暴发事件,人工筛选得到的疑似暴发事件具有准确率不高的问题。本发明设计实现的模型不再依赖于食源性疾病检测报告系统生成的疑似暴发事件,直接从病例维度出发,以病例作为输入,输出为包含病例的食源性疾病暴发事件集合,完成了端到端的食源性疾病暴发识别任务。如前文所述,直接使用传统聚类算法在该问题场景下效果不佳。本发明针对当前具体问题场景,将传统聚类问题转化为病例间关联关系预测与图网络中社区发现的问题,从而取得了比传统聚类算法更好的暴发事件识别效果。
[0009]
本发明的一种基于链接预测的食源性疾病暴发识别方法,包括以下步骤:对食源性疾病暴发事件数据进行数据处理,获取暴发事件维度和病例维度的相关信息;对数据处理之后的病例数据进行采样,得到正负样本对集合;对正负样本对集合中的各个正负样本对进行特征提取;将特征提取后的正负样本对输入基于神经网络构建的链接预测模型,以学习病例与病例之间的关联关系;根据链接预测模型得到的病例与病例之间的关联关系构建病例关系网络,病例关系网络中的节点表示病例实体,边表示病例之间的关联关系,边权值反映病例间关联强度;根据病例关系网络,采用社区发现算法得到食源性疾病暴发事件。
[0010]
进一步地,所述获取暴发事件维度和病例维度的相关信息,其中暴发事件维度包含病例编号、病例数、暴发产生地点、暴发产生时间等,病例维度包含病例基本信息、进食信息、病例症状、初步诊断、就诊时间等。
[0011]
进一步地,所述对数据处理之后的病例数据进行采样,得到正负样本对集合,包括:采样的全集为全体病例样本集,由正采样与负采样组成;正采样每次从同一暴发事件中采样两个病例作为一个病例对,正采样病例对标签为1,表示两个病例间联系密切,属于同一暴发事件;负采样包含两种采样方法,第一种采样方法每次从不属于任意暴发事件的病例样本集合中采样两个病例作为负样本对,第二种采样方法每次从某一暴发事件的病例集合以及不属于任意暴发事件的病例集合分别采样一个病例作为负样本对;负采样的病例组合标签为0,表示两个病例间无联系,不属于同一暴发事件。
[0012]
进一步地,所述对正负样本对集合中的各个正负样本对进行特征提取,其提取的特征包括病例自身基本信息特征和病例的互特征,所述互特征包含食品特征、时间特征、空间特征。
[0013]
进一步地,所述病例自身基本信息特征包括患者职业代码、初步诊断代码、症状代码,采用one-hot编码方法提取特征;所述空间特征包括病例住址、食品购买地点和就餐地点,将字符串表示的地区和县转换为相应的纬度和经度坐标,并计算病例之间的欧氏距离;所述时间特征包括进食时间、发病时间和就诊时间,将年、月和日格式的日期转换为时间戳,使用差值来表示两病例间时间维度的差异;所述食品特征包括食物名称,采用字符串匹配的思想,提取食物名称的字符串的特征,返回0-100之间的值表示两个字符串之间的相似程度,取值越大,相关性越高。
[0014]
进一步地,所述链接预测模型表示为:进一步地,所述链接预测模型表示为:进一步地,所述链接预测模型表示为:进一步地,所述链接预测模型表示为:其中,x是所述链接预测模型的输入,x1与x2分别为两个病例的病例自身基本信息特征,z为病例间的食品特征、时间特征、空间特征;,,,为神经网络模型参数,在训练过程中通过梯度后向传播更新,y表示病例间存在联系的可能性,y(0,1);为经bagging方法模型集成后最终的输出,n为基模型总数,为第i个基模型。
[0015]
进一步地,所述根据病例关系网络,采用社区发现算法得到食源性疾病暴发事件,是采用并查集算法得到食源性疾病暴发事件,并应用路径压缩与合并优化对所述并查集算法进行优化;路径压缩是在查找父节点的操作时将父节点设置为树的根节点从而限制树的深度;合并优化是记录每个节点作为根节点时树的深度,在合并操作中将深度较小的树合
并到深度较大的树,从而使树的结构更加合理。
[0016]
本发明还提供一种采用上述方法的基于链接预测的食源性疾病暴发识别系统,其包括:数据处理模块,用于对食源性疾病暴发事件数据进行数据处理,获取暴发事件维度和病例维度的相关信息;病例样本采样模块,用于对数据处理之后的病例数据进行采样,得到正负样本对集合;特征提取模块,用于对正负样本对集合中的各个正负样本对进行特征提取;链接预测模块,用于将特征提取后的正负样本对输入基于神经网络构建的链接预测模型,以学习病例与病例之间的关联关系;暴发生成模块,用于根据链接预测模型得到的病例与病例之间的关联关系构建病例关系网络,病例关系网络中的节点表示病例实体,边表示病例之间的关联关系,边权值反映病例间关联强度;进而根据病例关系网络,采用社区发现算法得到食源性疾病暴发事件。
[0017]
本发明的关键点和有益效果如下:1. 针对食源性疾病时间维度与空间维度特征,提出了一套有效可行的特征提取方法,基于上述特征提取工作,构建了基于神经网络与集成学习的链接预测模型和基于图上的并查集算法的暴发生成模型,该模型对于食源性疾病暴发识别问题取得了显著的效果。
[0018]
2. 首次将图(graph)的概念引入食源性疾病暴发识别问题,借鉴图神经网络中链接预测的思想,对食源性疾病样本构建图网络,节点表示病例样本,边表示病例之间的潜在关联关系。由此将食源性疾病暴发识别任务转化为链接预测与有权图的社区发现问题。
[0019]
3. 提出了基于并查集思想的暴发生成算法,实现有权图暴发事件的识别。将链接预测模型与暴发生成算法相结合,相比于直接应用传统机器学习聚类算法,效果得到了极大提升。
[0020]
4. 链接预测模型引入病例互特征(mutual feature)的思路对模型效果提升明显。bagging集成学习、drop-out机制的应用对模型效果提升明显。
附图说明
[0021]
图1是模型方法流程图。
[0022]
图2是病例样本采样示意图。
[0023]
图3是链接预测模型示意图。
[0024]
图4是基于并查集思想的暴发生成算法示意图。
[0025]
图5是附加特征对比实验结果图。
[0026]
图6模型集成对比实验结果图。
具体实施方式
[0027]
下面通过具体实施例和附图,对本发明做进一步详细说明。
[0028]
1. 方法流程本发明的流程如图1所示,包括数据处理、病例样本采样、病例特征提取、链接预
测、暴发生成等步骤。本方法引入链接预测的思想,在数据处理之后,对病例数据进行两两正负采样,得到病例对集合作为正负样本。将特征提取后的正负训练样本输入基于神经网络构建的链接预测模型,该模型可以学习到病例与病例之间的关联关系。此后暴发生成模型根据链接预测模型的输出构建病例关系网络,网络中节点表示病例实体,边表示病例间的关联关系,边权值反映了病例间关联强度,即两个病例有多大的可能来自于同一暴发事件。在构建病例关系网络后,尝试应用社区发现等算法最终得到食源性疾病暴发事件。
[0029]
2. 数据处理本发明首先对食源性疾病暴发事件数据进行数据处理。在暴发事件维度,包含病例编号、病例数、暴发产生地点、暴发产生时间等;在病例维度,包含病例基本信息、进食信息、病例症状、初步诊断、就诊时间等。对于特征缺失的处理,首先计算特征缺失数据所占比例,当缺失数据超过数据总量的一定比例时删除该特征,其余情况采用默认值填补缺失部分。对于数值型数据的处理包含数据归一化处理(最大-最小归一化)与离散化处理(等宽法分箱操作)。对于文本数据,采用jieba分词及去停用词技术对文本数据进行初步清洗。
[0030]
3. 病例样本采样由于在链接预测模型需要学习病例间的关联关系,以病例两两组合的形式作为模型的输入,所以在数据处理后,对病例样本集进行采样,得到链接预测模型的输入。采样的全集为全体病例样本集,由正采样与负采样组成,采样过程如图2所示。正采样每次从同一暴发事件中采样两个病例作为一个病例对,正采样病例对标签为1,表示两个病例间联系密切,属于同一暴发事件;负采样包含两种采样方法,第一种采样方法每次从不属于任意暴发事件的病例样本集合中采样两个病例作为负样本对,第二种采样方法每次从某一暴发事件的病例集合以及不属于任意暴发事件的病例集合分别采样一个病例作为负样本对。这样的病例组合标签为0,表示两个病例间无联系,不属于同一暴发事件。
[0031]
4. 特征提取在经过病例样本采样得到正负样本对集合之后,需要对各个样本对进行特征提取,构造下游模型输入。通过调研领域文献以及与领域专家沟通后,本方法将特征主要分为病例自身基本信息特征、食品特征、时间特征、空间特征四类。下游链接预测模型的输入由两部分组成,其中一部分是两个病例的病例自身基本信息特征的向量表示,另外一部分则是样本对中两个病例的互特征(mutual feature),其中包含了食品特征、时间特征、空间特征。
[0032]
对于病例自身基本信息特征,如患者职业代码、初步诊断代码、症状代码,采用one-hot编码方法提取特征。例如“其他人是否患病”等特征,使用1表示是,0表示否。
[0033]
对于空间特征,如病例住址、食品购买地点和就餐地点,本方法将字符串表示的地区和县转换为相应的纬度和经度坐标,并计算病例之间的欧氏距离。该值越大,空间距离越大。如下为两点之间欧氏距离计算公式。 [0034]
对于进食时间、发病时间和就诊时间等时间特征,本方法将年、月和日格式的日期转换为时间戳,使用差值来表示两病例间时间维度的差异。值越大,时间差越大。、为两个病例的时间格式表示,abs表示绝对值函数,time_stamp为时间戳转化函数,将时间格式
表示转化为时间戳。
[0035]
对于以字符串表示的食物名称等食品特征,本实验采用字符串匹配的思想,利用python中fuzzywzzy库文件的token_set_ratio函数提取字符串的特征。token_set_ratio函数返回0-100之间的值表示两个字符串之间的相似程度。取值越大,相关性越高。
[0036]
5. 链接预测模型图3是链接预测模型示意图。链接预测模型整体采用了集成学习中的bagging方法,集成学习通过将多个弱分类器组成一个强分类器,对数据进行预测,从而提高整体分类器的泛化能力。bagging 算法又称为装袋算法,可与其他分类或回归算法结合,提高其准确率和稳定性,并且通过降低结果的方差避免过拟合的发生。对于分类与回归任务,最终模型结果为多个模型的集成平均。基模型采用的是两层前馈神经网络,在基模型中加入drop-out层从而增强神经网络模型的泛化性。drop-out层在训练时,随机选择一部分神经元使其失活,不参与本次训练过程。因为神经元在训练时会以一定概率而被随机失活,使得每个神经元不能过分依赖于某些神经元,从而降低神经元之间的依赖程度,增强神经元提取特征的鲁棒性。
[0037]
基模型的输入为经过前述采样过程得到的正负病例对的向量表示,将两病例向量拼接的同时,融入病例间附加特征,包括病例间的食品特征、时间特征、空间特征。如公式x,输入可以表示为,其中x1与x2分别为两个病例的特征表示(即病例自身基本信息特征),z为附加特征(即病例间的食品特征、时间特征、空间特征),表示将特征向量拼接。基模型最终输出y的计算过程可表示为公式y,,,,为神经网络模型参数,在训练过程中通过梯度后向传播更新,函数将神经网络的输出转化为概率形式。y表示病例间存在联系的可能性,y(0,1),作为下游暴发生成模型中图网络的边权重。经bagging方法模型集成后最终的输出可表示为,其中n为基模型总数,为第i个基模型。链接预测模型的基模型神经网络选择交叉熵(binary crossentropy)作为损失函数,选择均方根优化(rmsprop)作为优化器,drop-out比例为0.2,模型训练迭代轮次(epoch)为10,实验中基模型个数为10时取得最好模型效果。(epoch)为10,实验中基模型个数为10时取得最好模型效果。(epoch)为10,实验中基模型个数为10时取得最好模型效果。(epoch)为10,实验中基模型个数为10时取得最好模型效果。
[0038]
6. 暴发生成模型通过链接预测模型得到的病例间关联关系可用于构建图网络,即病例关系网络,图网络中节点表示病例实体,边为链接预测模型输出的概率值。由此,本发明将暴发事件识
别的问题转化为图结构中的社区发现问题。
[0039]
本发明采用了一种基于并查集思想的暴发生成算法,并查集算法常用于解决元素分组的问题,具体来讲,并查集算法将所有有关联的元素分为一组,从而达到分组的目的。在本发明的问题场景下,基于神经网络实现的链接预测模型充分学习到了病例与病例间的关联关系,神经网络模型的输出可以表示两个病例之间的关联程度。我们把有关联的两个病例表示为两个病例间有边连接。由此暴发事件识别模型可以采用并查集算法的思想得以解决。在算法实现部分,主要涉及到两个重要的操作,分别为查找操作与合并操作。并查集算法实现了一种树状结构,并为每个元素引入父节点的概念。查找操作递归地寻找元素的父节点,合并操作先找到需要合并的两个元素的父节点,将其中一个元素的父节点设置为另一个元素。合并的过程可以认为是构建树的过程,因此通过设置合并规则可以对树进行优化,使得树的结构更加合理,使得算法更加高效。本方法应用路径压缩与合并优化两种方法优化并查集算法。路径压缩在查找父节点的操作时将父节点设置为树的根节点从而限制树的深度,合并优化记录每个节点作为根节点时树的深度,在合并操作中将深度较小的树合并到深度较大的树,从而使树的结构更加合理。
[0040]
图4是基于并查集思想的暴发生成算法示意图。其中a~f表示需要合并的六个元素,浅色节点为根节点,深色节点为非根节点。首先,六个元素的父节点指向自身。元素b与元素a属于同一集合,元素c与元素b属于同一集合,所以将元素b的父节点设置为元素a,由于路径压缩方法将父节点设置为根节点,所以元素c的父节点为a而不是b。其次,元素e与元素d属于同一集合,元素d与元素f属于同一集合,所以将元素e,元素f的父节点设置为元素d。最后,元素d与元素a属于同一集合,由于合并优化方法规定将深度较小的树合并至深度较大的树,将元素d的父节点设置为元素a时树深度最小,所以将元素d的父节点设置为元素a而不是元素b或元素c。
[0041]
7. 本发明的优点、有益效果此部分比较本发明提出的模型方法与传统方法的效果比较。实验验证使用同一验证数据,并对多种算法模型进行参数调优以获得当前模型下的最佳效果。
[0042]
1)评价指标本发明的评价指标采用类似聚类分析的评价指标。聚类性能度量根据训练数据是否包含标记数据分为两类,一类是将聚类结果与标记数据进行比较,称为外部指标;另一类是直接分析聚类结果,称为内部指标。由于本发明的数据集是有标记的数据,采用选择外部指标评价模型的效果。
[0043]
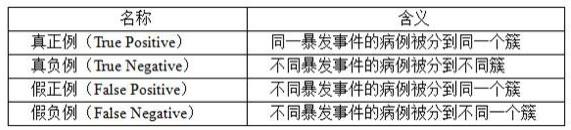
具体地,对真正例(true positive)、真负例(true negative)、假正例(false positive)、假负例(false negative)做出如下定义(表1),使得评价指标更加合理并具有实际意义。最终的评价指标召回率(recall)、精确率(precision)、f1-score由上述经过重新定义的真正例(true positive)、真负例(true negative)、假正例(false positive)、假负例(false negative)计算得到。召回率、精确率、f1-score的计算方式如下:score的计算方式如下:
表 1. 评价指标定义2)模型效果比较实验在验证集上将不同的社区发现算法与本发明中提出的暴发生成模型进行比较,所采用指标为f1-score。对比中用到的社区发现算法有louvain算法、givan newman以及标签传播算法(label propagation)。除此之外,也将提取到的病例向量直接经过归一化,采用传统机器学习聚类算法进行聚类,得到聚类结果。对传统机器学习聚类算法,对于需要预先设定类别的方法,聚类的类别设置为验证集中真实包含的暴发事件数目,并对其他参数进行调优,确保实验结果为当前模型下的最佳结果。实验结果如表2所示,采用链接预测模型与暴发识别算法的思路模型效果比直接使用传统聚类算法更好。其中,使用链接预测模型与基于并查集思想的暴发生成模型f1-score得分最高为0.9540。结果表明将聚类任务转化为链接预测并构建病例图网络的想法取得显著成效,神经网络实现的链接预测模型从数据中学习到了病例之间的关联关系,并且对后续暴发生成算法奠定了基础。
[0044]
表2模型结果对比3)特征提取效果链接预测模型的输入处将两个病例的向量拼接组合外,还拼接了其他互特征(mutual feature)。这些特征为根据先验知识提取到的包含食物、时间、地点在内的病例间相互特征。实验在保留链接预测模型的结构和参数等其他因素不变的前提下,对比了在验证集上各种互特征对模型最终暴发事件识别效果的影响。如图5所示,不加入附加特征以及加入单一附加特征的模型最终效果普遍较差,食品、时间、空间维度的附加特征都对提升模型效果起到了正向的影响,其中食物特征的添加对模型效果的正向影响更大,使用全部食品、时间、空间特征的模型在特定阈值下具有最高的得分。一方面反映了本发明中特征提取方法的有效性,另一方面也反映了先验领域知识的重要性以及食源性疾病在时间空间上的
聚集性特点。
[0045]
4)模型集成效果链接预测模型在整体上采用了bagging的模型集成方法。实验部分在保证其他因素不变的前提下,比较了单模型与集成模型在不同阈值取值下的f1-score得分变化曲线。如图6所示,模采用型集成思想的链接预测模型效果优于单模型的链接预测模型。
[0046]
基于同一发明构思,本发明的另一个实施例提供一种采用上述方法的基于链接预测的食源性疾病暴发识别系统,其包括:数据处理模块,用于对食源性疾病暴发事件数据进行数据处理,获取暴发事件维度和病例维度的相关信息;病例样本采样模块,用于对数据处理之后的病例数据进行采样,得到正负样本对集合;特征提取模块,用于对正负样本对集合中的各个正负样本对进行特征提取;链接预测模块,用于将特征提取后的正负样本对输入基于神经网络构建的链接预测模型,以学习病例与病例之间的关联关系;暴发生成模块,用于根据链接预测模型得到的病例与病例之间的关联关系构建病例关系网络,病例关系网络中的节点表示病例实体,边表示病例之间的关联关系,边权值反映病例间关联强度;进而根据病例关系网络,采用社区发现算法得到食源性疾病暴发事件。
[0047]
其中各模块的具体实施过程参见前文对本发明方法的描述。
[0048]
基于同一发明构思,本发明的另一实施例提供一种电子装置(计算机、服务器、智能手机等),其包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行本发明方法中各步骤的指令。
[0049]
基于同一发明构思,本发明的另一实施例提供一种计算机可读存储介质(如rom/ram、磁盘、光盘),所述计算机可读存储介质存储计算机程序,所述计算机程序被计算机执行时,实现本发明方法的各个步骤。
[0050]
以上公开的本发明的具体实施例,其目的在于帮助理解本发明的内容并据以实施,本领域的普通技术人员可以理解,在不脱离本发明的精神和范围内,各种替换、变化和修改都是可能的。本发明不应局限于本说明书的实施例所公开的内容,本发明的保护范围以权利要求书界定的范围为准。