基于spark streaming实时检测锅炉壁温超限报警的方法
技术领域
1.本发明涉及计算机应用领域,工业电站生产运行领域,特别涉及一种基于spark streaming实时检测锅炉壁温超限报警的方法。
背景技术:
2.目前,火电厂发电机组已进入大容量、高参数的发展阶段,600mw、1000mw等级的超临界、超超临界机组相继投运。随着机组参数的不断提高,特别是主蒸汽温度的升高,引发锅炉管壁内氧化垢引起的超温问题更为突出;有统计表明,锅炉故障引起发电机组事故停机约占80%,其中70%的故障是由受热面损坏造成的。受热面管路的损坏直接或间接地与运行过程中受热面的超温有关。当管壁金属温度超过所用钢材在承受力水平下的容许温度时,会引起管子的高温蠕变,严重时造成爆管事故,不但会造成巨大的直接经济损失,而且由于爆管区域附近大片管子受损,埋下了连续爆管的隐患,严重影响锅炉的安全运行,降低了设备的可用率,造成了发电机组事故停机直接增加了发电成本。
技术实现要素:
3.为了克服上述现有技术存在的问题,本发明的目的在于提供一种基于spark streaming实时检测锅炉壁温超限报警的方法,该方法利用离散化流dstream实现不间断7*24工作,将锅炉壁受热面金属监测的测点数据按批次间隔(60秒)形成各个rdd,通过“map”转化操作过滤出超限测点,再由“reduce”行动操作进行聚合输出到消息系统进行实时报警的目的,对预防超温引发机组停机、提高发电设备可靠性和间接降低发电成本有着显著的作用。
4.首先对本发明中出现的技术名词作以下说明:
5.rdd:是弹性分布式数据集(resilient distributed datasets,简称rdd),就是一个不可变的分布式对象集合。rdd支持两种操作:转化操作和行动操作。
6.dstream:是随着时间推移而收到的数据序列,每个时间区间收到的数据都作为rdd存在,由这些离散化rdd所组成的序列称不离散化流(discretized stream)。
7.转化操作:是通过map()或者filter()等返回一个新的rdd,转化操作针对rdd数据集中各个元素。
8.行动操作:是通过reduce()或者count()等返回新的数据类型,最终求得结果生成实际的输出。
9.spark,是大数据处理和计算框架,一个用来实现快速而通用的集群计算的平台。扩展了广泛使用的mapreduce计算模型,而且高效地支持更多的计算模式,包括交互式查询和流处理。在处理大规模数据集的时候,速度是非常重要的。spark的一个重要特点就是能够在内存中计算,因而更快。
10.为了实现上述目的,本发明采用的技术方案是:
11.一种基于spark streaming实时检测锅炉壁温超限报警的方法,包括以下步骤:
12.步骤1、在分布式流媒体平台kafka中创建“锅炉壁温超限”主题;
13.步骤2、从分布式流媒体平台kafka中订阅“锅炉壁温超限”主题,构建streamingcontext上下文环境,实列化针对这个主题的接收器线程数据的映射表;
14.步骤3、按批次间隔读取数据,形成的一个持续rdd序列,即离散化流也就是dstream;
15.步骤4、通过转化操作过滤出锅炉壁温超限的测点形成一个新的持续rdd序列即新的dstream;
16.步骤5、定义状态检测点,开启checkpoint机制,通过有状态的行动操作整合多个批次的结果形成一个含时长和步长窗口,对每个窗口更高效地进行归约操作统计出测点超限结果;
17.步骤6、根据最后窗口实时统计结果,进行dstream输出操作将内容编排在kafka中创建“超限报警”主题,发布消息至手机或者业务系统,达到报警提示目的。
18.有益效果
19.采用本发明,实现检测锅炉壁温超限报警有着显著优势:1、实时性;流式大数据不仅是实时产生的,也能够实时给出反馈结果。有快速响应能力,在短时间内体现出数据报警的价值,超过有效时间后数据的价值就会极速降低。2、吞吐量;数据的流入速率和顺序并不确定,甚至会有较大的差异。采用spark分布式计算框架有较高的吞吐量,能快速处理大数据流量。3、无限性;数据会持续不断产生并流入,能够持久、稳定地不间断7*24工作运行下去。
附图说明
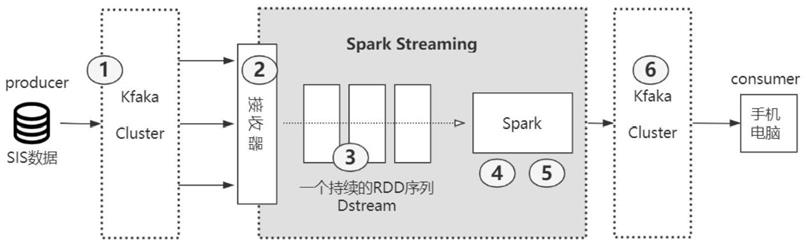
20.图1为本发明一种基于spark streaming实时检测锅炉壁温超限报警的方法架构图。
21.图2为转化操作流程图。
22.图3为窗口操作流程图。
具体实施方式
23.下面结合附图对本发明的技术方案做进一步详细说明。
24.如图1所示,一种基于spark streaming实时检测锅炉壁温超限报警的方法,包括以下步骤:
25.第一步、首先在分布式流媒体平台kafka中创建“锅炉壁温超限”主题(名称为“n1-olm”),复制系数(主题复本数量),分区数(主题的分区数量),分布式流媒体平台kafka集群会根据主题名称key为每个分区创建指定数量的复本;主题内容由sis运行实时数据库提供数据源,通过定义锅炉壁受热面金属监测的所有测点对象(包括测点名称、测点描述、单位、时间、质量、数值、超温限值、超温级别)转为以逗号隔开换行符分行的文本信息进行消息传输。如下所示:n1.gwzrq_01,高温再热器右侧01点,℃,1633421667,0,526.6,550,l1
26.n1.gwzrq_02,高温再热器右侧02点,℃,1633421667,0,511.6,550,l1
27.……
28.第二步、从分布式流媒体平台kafka中订阅“锅炉壁温超限”主题,构建
streamingcontext上下文环境,实列化针对这个主题的接收器线程数据的映射表。通过spark api创建一个从“锅炉壁温超限”主题接收器线的主要代码如下:
29.map《string,integer》topics=new hashmap《string,integer》();
30.topics.put(“n1-olm”,1);
31.javastreamingcontext jssc=new javastreamingcontext(conf,second(60));
32.javaparidstream《string,string》input=kafkautils.creatstream(jssc,topics)
33.其中:second(60)表示一次新数据的批次间隔为60秒,从kafka中采集数据;kafkautils.creatstream(jssc,topics)实现了kafka与spark数据传输的链路。
34.第三步、按批次间隔(60s)读取数据,形成的一个持续rdd序列,即离散化流也就是dstream。spark streaming使用微批次的架构,将流式计算当作一系列连续的小规模批处理来对待,每次新批次按均匀的时间间隔创建出来,时间区间的大小由批次间隔(本方案中采用60s)这个参数决定。每个批次都形成一个rdd,每个rdd代表数据流中一个时间片内的数据,一个个持续rdd序列最终抽象为离散化流dstream。如图2中“原始数据dstream”所示。
35.第四步、通过转化操作过滤出锅炉壁温超限的测点形成一个新的持续rdd序列即新的dstream。如图2转化操作流程图所示,在spark的驱动器程序一工作节点的执行map/filter转化操作,将rdd中的每个测点实时值对应超限限值进行比较,将大于超限限值的测点,重新由测点名称、描述、单位、时间、超温限值、实际值、级别组成新的rdd内容返回各测点有超限记录的元素所组成新的持续的rdd序列即新的dstream,随时间不间断进行数据转换每个小批次的超限判断操作。
36.第五步、定义状态检测点,开启checkpoint机制,通过有状态的行动操作整合多个批次的结果形成一个含时长和步长窗口,对每个窗口更高效地进行归约操作统计出测点超限结果。
37.第1步:定义状态检测点,目的允许dstream维护任意状态,同时不断地用新信息更新它;对于有状态行动操作,要不断的把当前和历史的时间切片的rdd累加计算,函数:updatestatebykey定义为:将锅炉壁温超限的测点超限信息按超限时间进行累计,并实时更新超限的结束时间;作用主要用来保障工作节点容错性的主要机制,一方面,用来控制发生失败时需要重新计算状态数。另一方面,流式计算spark驱动程序发生崩溃时,驱动程序会用检测点恢复并继续运行下去。
38.第2步:进行滑动窗口操作,spark streaming采用一种有状态转化操作,是跨时间区间跟踪数据的操作也就是说,一些先前批次的数据也被用来在新批次中计算结果;主要是通过滑动窗口实现。滑动窗口操作需要两个参数,窗口时长以及滑动步长,两者都必须是批次间隔(60s)的整数倍。如图3窗口操作流程图所示。窗口时长为3个批次,滑动步长为2个批次;每隔2个批次就对前3个批次数据进行一次计算。具体实现如下:
39.javadstream《apachaccesslog》accesslogwindow=accesslogstream.window(seconds(180),second(120));
40.accesslogwindow.countbywindow(new updaterunolm(),seconds(180),second(120));
41.其中updaterunolm()是对测点是否超限并累计超限时长的业务方法。
42.第六步、根据最后窗口实时统计结果,进行dstream输出操作将内容编排在分布式流媒体平台kafka中创建“超限报警”(n1-olm-report)主题,发布消息至手机或者业务系统,达到报警提示目的。
43.第1步:汇总超限结果,定义数据结构体:主题内容按计算结果编排为包括超限明细对象(测点名称、描述、单位、时间、超温限值、实际值、级别、时长)和超限汇总对象(测点名称、描述、单位、超温次数、超温时长)两对象转为以逗号隔开换行符分行的文本信息进行消息传输。
44.第2步:创建报警主题并输出,dstream输出操作将超限汇总对象(测点名称、描述、单位、超温次数、超温时长)编排在分布式流媒体平台kafka中以主题名称“超限报警”(n1-olm-report)、复制系数(主题复本数量),分区数(主题的分区数量)创建“超限报警”(n1-olm-report)消息主题,发布消息至手机或者业务系统,达到报警提示目的。