1.本技术涉及娱乐设备技术领域,尤其是一种音乐文件处理方法和装置、音乐演唱设备、计算机设备、计算机可读存储介质。
背景技术:
2.现代社会属于快节奏的数字化时代,欣赏一首音乐,不仅仅是为了听歌而听歌,还会去感受歌曲中的内容,包括歌曲精髓,歌曲表达的意思等,不仅如此,更多用户甚至加入歌曲创作的过程,用歌曲表达目前的生活状态和心情,抒发个人情感,这使得个性化歌曲的制作变得尤为重要。
3.目前,对于音乐播放设备,智能终端,ktv设备等等,所播放的音乐文件一般都是由专业人士进行编辑的,并不能很好地适应于用户个性化需求。虽然在pc应用或者移动应用上也提供了一些音频编辑器等软件,用户使用音频编辑器可以编辑个人喜好音乐,但操作复杂,效果不佳;无法便捷和智能为用户制作个性化音乐,难以满足市场需求。
技术实现要素:
4.针对于上述技术缺陷之一,本技术提供一种音乐文件处理方法和装置、音乐演唱设备、计算机设备、计算机可读存储介质,从而可以便捷和智能地为用户制作个性化歌曲。
5.第一方面:
6.本技术提供一种音乐文件处理方法,包括:
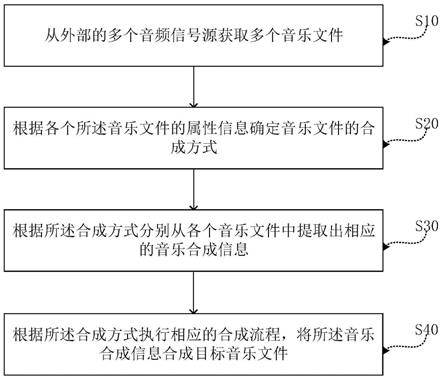
7.从外部的多个音频信号源获取多个音乐文件;
8.根据各个所述音乐文件的属性信息确定音乐文件的合成方式;
9.根据所述合成方式分别从各个音乐文件中提取出相应的音乐合成信息;
10.根据所述合成方式执行相应的合成流程,将所述音乐合成信息合成目标音乐文件。
11.在一个实施例中,从外部的多个音频信号源获取多个音乐文件,包括:
12.建立与多个数据源之间的通信连接;
13.采用时分工作方式接收各个数据源基于私有协议封装的音频数据包;
14.根据所述私有协议解析各个音频数据包得到多份音乐文件。
15.在一个实施例中,根据各个所述音乐文件的属性信息确定音乐文件的合成方式,包括:
16.根据各个音乐文件的属性信息计算音乐文件之间的相似度;
17.若相似度高于第一阈值,则确定相应的音乐文件为同一首音乐的多乐器合成方式;
18.若相似度低于第二阈值,则确定相应的音乐文件为不同音乐的歌曲串烧合成方式。
19.在一个实施例中,所述合成方式为多乐器合成方式;
20.根据所述合成方式分别从各个音乐文件中提取出相应的音乐合成信息,包括:
21.分别从各个音乐文件中分别提取同一首音乐的不同乐器演奏的多个乐器伴奏信息以及人声信息;
22.根据所述合成方式执行相应的合成流程,将所述音乐合成信息合成目标音乐文件,包括:
23.采用线性混音方式将各个所述音乐文件的乐器伴奏信息进行合成,并结合所述人声信息得到目标音乐文件。
24.在一个实施例中,采用线性混音方式将各个所述音乐文件的乐器伴奏信息进行合成,并结合所述人声信息得到目标音乐文件,包括:
25.根据所述人声信息计算音乐文件的段落相似度,并根据所述相似度获取各个音乐文件的歌曲段落偏差;
26.选择音质最优的音乐文件作为第一合成音乐文件,根据所述歌曲段落偏差计算各个其他音乐文件相对于所述第一合成音乐文件的每一段的偏差值,并依据所述偏差值修正各个音乐文件对应的乐器伴奏信息;
27.将各个乐器伴奏信息进行加乘合成,然后进入低通滤波器进行滤波,将滤波后的乐器伴奏信息与所述人声信息进行合成,得到目标音乐文件。
28.在一个实施例中,所述合成方式为歌曲串烧合成方式;
29.根据所述合成方式分别从各个音乐文件中提取出相应的音乐合成信息,包括:
30.分别对各个音乐文件进行人声和伴奏分离,提取不同音乐的乐器伴奏信息以及人声信息;
31.根据所述乐器伴奏信息以及人声信息定位相应音乐文件的主歌部分和副歌部分;
32.根据所述合成方式执行相应的合成流程,将所述音乐合成信息合成目标音乐文件,包括:
33.截取各个音乐文件的主歌部分和副歌部分,并将所述音乐文件的主歌部分和/或副歌部分进行串烧合成目标音乐文件。
34.在一个实施例中,根据所述乐器伴奏信息以及人声信息定位相应音乐文件的主歌部分和副歌部分,包括:
35.利用所述人声信息结合旋律分析所述音乐文件;
36.采用隐马尔可夫模型和色度特征并基于维特比解码获得对应的音乐文件的主歌和副歌的结构段落;
37.根据所述乐器伴奏信息计算相应的音乐文件的每一段音乐的节奏、旋律轮廓曲线以及情感信息;
38.根据所述节奏、旋律轮廓曲线以及情感信息对所述主歌和副歌的结构段落进行多重判定得到所述主歌部分和副歌部分的位置。
39.在一个实施例中,采用隐马尔可夫模型和色度特征并基于维特比解码获得对应的音乐文件的主歌和副歌的结构段落,包括:
40.根据各个所述音乐文件的有效电平值确定伴奏的缩放倍数,并根据缩放倍数将所述音乐文件进行线性压缩目标音乐文件的声音大小;
41.计算所述音乐文件的每一帧的有效电平值及对应的梅尔倒频谱;
42.根据所述有效电平值和梅尔倒频谱的峰值曲线定位基音的位置和音高,获取对应的音符;
43.计算所述音符的持续时间,将所述音符转化为对应的色度特征;其中,所述色度特征包括色度向量和色度图谱;
44.采用隐马尔可夫模型计算所述音乐文件的每一帧的相似度,获得主歌和副歌的结构段落的边界值。
45.在一个实施例中,将所述音乐文件的主歌部分和/或副歌部分进行串烧合成目标音乐文件,包括:
46.获取用户选择的主歌串烧或副歌串烧方式;
47.对各个所述音乐文件进行响度归一化处理;
48.分别将各个所述音乐文件的主歌部分和/或副歌部分进行合并串烧;
49.采用幂指数的淡入淡出算法对各个音乐文件之间的连接位置进行渐变处理。
50.第二方面:
51.本技术提供一种音乐文件处理装置,包括:
52.传输模块,用于从外部的多个音频信号源获取多个音乐文件;
53.确定模块,用于根据各个所述音乐文件的属性信息确定音乐文件的合成方式;
54.提取模块,用于根据所述合成方式分别从各个音乐文件中提取出相应的音乐合成信息;
55.合成模块,用于根据所述合成方式执行相应的合成流程,将所述音乐合成信息合成目标音乐文件。
56.第三方面:
57.本技术提供一种音乐演唱设备,包括:主板,以及分别与所述主板连接的音响系统和显示设备;其中,所述主板还连接麦克风;
58.所述主板用于执行上述的音乐文件处理方法的步骤;
59.所述音响系统用于播放音频数据;
60.所述麦克风用于拾取用户的演唱声音;
61.所述显示设备用于在演唱歌曲文件时显示图像内容。
62.第四方面:
63.本技术提供一种计算机设备,其包括:
64.一个或多个处理器;
65.存储器;
66.一个或多个应用程序,其中所述一个或多个应用程序被存储在所述存储器中并被配置为由所述一个或多个处理器执行,所述一个或多个程序配置用于:执行上述的音乐文件处理方法。
67.第五方面:
68.本技术提供一种计算机可读存储介质,所述存储介质存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并执行上述的音乐文件处理方法。
69.上述音乐文件处理方法和装置、音乐演唱设备、计算机设备以及计算机可读存储
介质,可以通过外部多个音频信号源获取多个音乐文件,根据各个音乐文件的属性信息确定音乐文件的合成方式,并从各个音乐文件中提取出相应的音乐合成信息,执行相应的合成流程将所述音乐合成信息合成目标音乐文件;该技术方案,用户可以从多个不同音频信号源导入音乐文件,从而可以智能化、便捷地制作合成音乐,满足用户个性化需求,提升用户应用体验。
70.进一步的,基于私有协议封装的音频数据包传输,提升了传输效率,可以边传边处理,同时,在传输过程中采用时分工作方式从多个音频信号源导入数据,实现并行接收处理,从而可以提升处理效率和流畅度。
71.进一步的,合成方式采用同一首音乐的多乐器合成方式,分别提取同一首音乐的不同乐器演奏的多个乐器伴奏信息以及人声信息,采用线性混音方式将各个音乐文件的乐器伴奏信息和人声信息合成得到目标音乐文件;该技术方案,将多个音频信号源导入的同一首音乐自动合成一首多乐器类型的音乐,可用于在线演唱会,多个不同用户在不同地区演唱同一首歌曲,对歌曲进行混音处理,模拟现场合唱的效果,对乐器伴奏采用线性混音方式进行合成,可以保证声音的包络方向一致性,且不会因为声音过大而产生破音,也不会因为声音过少而降低了音乐质量。
72.另外,通过计算各个音乐文件之间的偏差值,利用偏差值修正每个音乐文件的乐器伴奏对应的音符的位置,提升了乐器伴奏的合成效果。
73.进一步的,合成方式采用不同音乐的歌曲串烧合成方式,分别对各个音乐文件进行人声和伴奏分离,提取不同音乐的乐器伴奏信息以及人声信息;根据乐器伴奏信息以及人声信息定位相应音乐文件的主歌部分和副歌部分;截取各个音乐文件的主歌部分和副歌部分,并将所述音乐文件的主歌部分和/或副歌部分进行串烧合成目标音乐文件;该技术方案,实现了用户自主制作对不同音乐合成主歌或副歌串烧,从而一次性满足用户多歌曲同时演唱的目的,特别是在ktv场景中,用户可以根据需求从多个不同的音频数据源导入多首歌曲,自动化生成一首串烧歌曲,满足用户个性化制作串烧音乐的需求。
74.另外,结合隐马尔可夫模型,采用乐器伴奏计算色度特征,采用音符拟合成包络曲线作为音乐旋律轮廓线,判定主歌和副歌部分的区分,可以实现更好段落划分。
75.再者,在串烧合成前对各个音乐文件进行响度归一化处理,保证串烧音乐的响度一致,采用幂指数的淡入淡出算法对各个音乐文件之间的连接位置进行渐变处理,确保不同音乐串烧合成的音量平稳自然过渡。
76.本技术附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变得明显,或通过本技术的实践了解到。
附图说明
77.本技术上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
78.图1是一个示例的音乐文件处理技术方案的结构框架图;
79.图2是一个实施例的音乐文件处理方法流程图;
80.图3是一个示例的多个音乐文件合成目标音乐文件的流程图
81.图4-7是一个示例的主歌与副歌的曲谱示意图;
82.图8是计算音乐文件的音符流程图;
83.图9是一个实施例的划分主歌部分和副歌部分的流程图;
84.图10是一个实施例的音乐文件处理装置的结构示意图。
具体实施方式
85.下面详细描述本技术的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本技术,而不能解释为对本技术的限制。
86.本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“所述”和“该”也可包括复数形式。应该进一步理解的是,本技术的说明书中使用的措辞“包括”是指存在所述特征、整数、步骤、操作,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作。
87.本技术的音乐文件处理方案,可以应用于音乐演唱设备上,如智能音箱设备、ktv设备;另外也可以是智能手机、平板、个人电脑等智能终端上;音乐演唱设备可以通过网络连接到后台的服务器,并可以通过wifi、蓝牙或者数据网络连接与音频信号源1-n(n≥1)连接,对于音频信号源,可以是智能手机、平板、个人电脑、存储介质或者网络设备等等;本技术提供的音乐文件处理方法可以通过软件形式部署在终端设备,也可以部署在服务器上,或者以不同功能模块分别部署在音乐演唱设备上;如图1所示,图1是一个示例的音乐文件处理方案网络拓扑图;图中终端设备可以分别与多种音频信号源连接,传输音乐文件,音乐演唱设备为用户提供了便捷和智能化的音乐文件处理功能,可以为用户实时合成所需要的个性化歌曲,同时用户也可以将自己的个性化曲库的歌曲文件分享给其他用户进行使用;当然,本技术提供的音乐文件处理方法也可以通过软件程序在个人电脑上,通过app方式安装在智能手机上,通过蓝牙并采用私有协议与多个其他终端设备进行通讯传输音乐文件,实时合成所需要的个性化歌曲。
88.下面以音乐演唱设备为例,结合阐述音乐文件处理方法的实施例,参考图2所示,图2是一个实施例的音乐文件处理方法流程图,主要包括如下步骤:
89.步骤s10:从外部的多个音频信号源获取多个音乐文件。
90.此步骤中,音乐演唱设备可以用户可通过蓝牙从智能手机,本地传输(如cd、蓝光、dvd、u盘等),网盘,wifi,同轴光纤,fm等音频信号源传入多个音乐文件,用户可根据个人喜好,选择合适的方式传输音乐文件,可以传入不同的音乐文件,也可以传入同一首音乐的不同版本的音乐文件。
91.在传输音乐文件后,音乐演唱设备可以获取音乐文件的编码格式、码率、采样率、位数、声道数、歌曲名、歌手名、歌词、歌曲数据、文件大小、歌曲时长以及歌曲风格等属性信息,同时判定音乐文件的质量是有损音质(320kbps以下,如mp3、wma、ogg等)还是无损音质(wave、flac、aiff、ape、wav、wavpack、lpac、ttk等)。
92.在一个实施例中,以智能手机传输音乐文件到音乐演唱设备为例,步骤s10的流程可以包括如下:
93.s101,建立与多个数据源之间的通信连接。
94.例如,多个用户的智能手机可以通过蓝牙或者wifi传输方式与音乐演唱设备建立
通信连接。以蓝牙为例,由于蓝牙是一种标准的通信协议,为了更好地传输音乐文件,因此,可以设计私有协议并在蓝牙协议上传输音乐文件的数据,智能手机端可以利用传输模块,基于私有协议来封装音乐文件的音频数据,然后通过蓝牙方式传输到音乐演唱设备上。
95.s102,采用时分工作方式接收各个数据源基于私有协议封装的音频数据包。
96.在传输过程中,采用时分工作方式从多个音频信号源进行传输数据,从而可以将音频数据包边接收边进行后续处理,从而可以提升处理效率和流畅度。
97.s103,根据所述私有协议解析各个音频数据包得到多份音乐文件。
98.示例性的,音乐演唱设备接收到各个音频数据包后,可以分别对各个音频数据包进行解析得到多份音乐文件然后存入缓存中,并由后续处理流程实时进行读取和处理。
99.上述实施例,基于私有协议封装的音频数据包传输,提升了传输效率,可以边传边处理,同时,在传输过程中采用时分工作方式从多个音频信号源导入数据,实现并行接收处理,从而可以提升处理效率和流畅度。
100.步骤s20:根据各个所述音乐文件的属性信息确定音乐文件的合成方式。
101.此步骤中,基于传入音乐文件之间的属性信息判断音乐文件之间的关系,用户可以选择不同的合成方式进行合成音乐文件。
102.在一个实施例中,步骤s20的确定音乐文件的合成方式流程,包括如下:
103.首先,可以根据各个音乐文件的属性信息计算音乐文件之间的相似度;例如,通过歌手名、歌曲名及歌曲相似度计算来判断多个音频信号源为同一首音乐或者是明显不同的音乐。
104.然后,根据相似度进行判断,若相似度高于第一阈值,则确定相应的音乐文件为同一首音乐的多乐器合成方式;若相似度低于第二阈值,则确定相应的音乐文件为不同音乐的歌曲串烧合成方式。
105.示例性的,当音频信号源传输的数据为同一首音乐时,则合并时根据每首音乐上的不同乐器伴奏合并为一首多乐器伴奏音乐;若该音频信号源传输的属性信息为不同音乐名称、不同类型、不同风格或不同歌手的情况时,则认为用户传输的是不同的音乐,此时可以进行歌曲串烧操作。
106.上述实施例的方案,当传入的音乐文件中包含同一首的音乐文件可以进行乐器伴奏合成,传入了不同的音乐文件时,可以进行音乐文件的串烧合成。
107.步骤s30:根据所述合成方式分别从各个音乐文件中提取出相应的音乐合成信息。
108.此步骤中,根据合成方式不同,从音乐文件中提取不同部分内容进行合成操作;下面以多乐器伴奏合成和串烧合成为例进行阐述,参考图3所示,图3是一个示例的多个音乐文件合成目标音乐文件的流程图。
109.(一)对于多乐器合成方式;则可以分别从各个音乐文件中进行人声伴奏分离,把人声和伴奏部分分离获得对应的乐器伴奏后,将同一首音乐的不同乐器演奏的多个乐器伴奏信息以及人声信息。
110.(二)对于歌曲串烧合成方式;则分别对各个音乐文件进行人声和伴奏分离,提取不同音乐的乐器伴奏信息以及人声信息;根据所述乐器伴奏信息以及人声信息定位相应音乐文件的主歌部分和副歌部分,为了更好的连接每首音乐的感兴趣部分,将歌曲类型分为主歌串烧和副歌串烧部分。
111.对于人声伴奏分离的技术方案,可以根据音乐文件的质量来选择分离方式,对于无损音质的音乐文件,可以直接采用人声分离技术提取人声信息、伴奏信息和乐器组音轨信息等,对于有损音质的音乐文件,可以采用音质提升技术,把有损音乐文件尽可能的提升为高质量的伴奏音乐。
112.步骤s40:根据所述合成方式执行相应的合成流程,将所述音乐合成信息合成目标音乐文件。
113.此步骤,根据合成方式对音乐合成信息执行相应的合成流程,将音乐合成信息合成目标音乐文件。
114.在一个实施例中,如上所述,对于多乐器合成方式;可以采用线性混音方式将各个所述音乐文件的乐器伴奏信息进行合成,并结合所述人声信息得到目标音乐文件;
115.在一个实施例中,如上所述,对于歌曲串烧合成方式;则可以截取各个音乐文件的主歌部分和副歌部分,并将所述音乐文件的主歌部分和/或副歌部分进行串烧合成目标音乐文件。
116.作为实施例,获取用户选择的主歌串烧或副歌串烧方式;对各个所述音乐文件进行响度归一化处理;分别将各个所述音乐文件的主歌部分和/或副歌部分进行合并串烧;采用幂指数的淡入淡出算法对各个音乐文件之间的连接位置进行渐变处理。
117.示例性的,截取每一首音乐文件的主歌和副歌部分后,分别进行合并串烧,用户可以根据个人喜好选择主歌串烧或者副歌串烧,每首音乐文件之间的连接采用淡入淡出算法处理,该算法在开始阶段很慢,然后迅速移到音乐文件尾部,适合放置于两个音乐片段之间渐变以保持音量的自然过渡;另外,为了实现串烧歌曲的响度一致,合唱之前,对每一首歌曲进行响度归一化处理,比如归一化到-6~0db。
118.综合上述实施例,音乐演唱设备通过外部多个音频信号源获取多个音乐文件,根据各个音乐文件的属性信息确定音乐文件的合成方式,并从各个音乐文件中提取出相应的音乐合成信息,执行相应的合成流程将所述音乐合成信息合成目标音乐文件;由此,用户可以从多个不同音频信号源导入音乐文件,从而可以智能化、便捷地制作合成音乐,满足用户个性化需求,提升用户应用体验。
119.上述实施例的方案中,多个用户可以通过智能手机将一首音乐传输到音乐演唱设备上,音乐演唱设备提取高潮片段拼接成一份串烧音乐文件,从而可以提升用户应用体验;在传输音乐文件后,可以保存为音质格式(dts、wav、ape、flac、mp3、aac、mp4、avi、mkv、mpg音频、视频mtv音乐等)。音乐演唱设备可以执行如下操作:在音乐演唱设备上直接进行音乐文件的合成处理得到目标音乐文件;或者将音乐文件上传服务器,由服务器驱动执行合成操作并返回目标音乐文件。
120.为了更加清晰本技术的技术方案,下面结合附图进行详细阐述。
121.在一个实施例中,步骤s40的采用线性混音方式合成得到目标音乐文件的技术方案,可以包括如下:
122.s401,根据所述人声信息计算音乐文件的段落相似度,并根据所述相似度获取各个音乐文件的歌曲段落偏差。
123.示例性的,通过歌手名、歌曲名、及歌曲相似度计算来判断多个信号源在传输同一首音乐;如信号源1传输《《青花瓷》-钢琴奏乐》,信号源2传输《《青花瓷》-大提琴奏乐》,信号
源3传输《《青花瓷》-古筝》。
124.s402,选择音质最优的音乐文件作为第一合成音乐文件,根据所述歌曲段落偏差计算各个其他音乐文件相对于所述第一合成音乐文件的每一段的偏差值,并依据所述偏差值修正各个音乐文件对应的乐器伴奏信息。
125.示例性的,对各个音乐文件进行人声伴奏分离,获得对应的乐器伴奏;如信号源1钢琴伴奏,信号源2大提琴伴奏和信号源3古筝伴奏。
126.根据人声部分进行dp段落相似度计算获得每首音乐的歌曲段落偏差,选择3个音乐文件中音质较高(96k、128kps、wave、flac、aiff、ape、wav、wavpack、lpac或ttk)的作为主要合成对象;对每一段计算其偏差,用于修正对应信号源中的伴奏。
127.s403,将各个乐器伴奏信息进行加乘合成,然后进入低通滤波器进行滤波,将滤波后的乐器伴奏信息与所述人声信息进行合成,得到目标音乐文件。
128.示例性的,根据主要合成对象及其他的信号源的音乐文件进行加乘合成,合成后进入低通滤波器,减少因合成过程产生的高频噪声,最后获得一首《青花瓷》的钢琴大提琴古筝合奏版的音乐。
129.上述技术方案,采用线性混音方式将各个音乐文件的乐器伴奏信息和人声信息合成得到目标音乐文件;该技术方案,将多个音频信号源导入的同一首音乐自动合成一首多乐器类型的音乐,可用于在线演唱会,多个不同用户在不同地区演唱或演奏同一首歌曲,对歌曲进行混音处理,模拟现场合唱或多人合奏的效果,对乐器伴奏采用线性混音方式进行合成,可以保证声音的包络方向一致性,且不会因为声音过大而产生破音,也不会因为声音过少而降低了音乐质量。
130.在一个实施例中,步骤s40的截取各个音乐文件的主歌部分和副歌部分进行串烧合成目标音乐文件的技术方案,可以包括如下:
131.s411,采用隐马尔可夫模型和色度特征并基于维特比(viterbi)解码获得对应的音乐文件的主歌和副歌的结构段落;其中,主歌是歌曲一般开始或者中间比较平淡的铺垫部分,即使是重复也大多会转变歌词;副歌是歌曲的高潮以及精华的所在。
132.具体的,根据人声分离获得纯人声部分和伴奏部分,再利用人声部分结合旋律分析,采用隐马尔可夫模型和色度特征,利用viterbi解码获得对应的音乐结构段落,即主歌部分和副歌部分;该技术方案中,通过隐马尔可夫模型可计算出每一段音乐之间的相似度,从而精准获得每段边界值,达到划分主歌部分和副歌部分的目的。
133.s412,根据所述乐器伴奏信息计算相应的音乐文件的每一段音乐的节奏、旋律轮廓曲线以及情感信息(悲伤,愉悦、欢快、愤怒或者性感等)。
134.具体的,根据伴奏信息计算音乐文件上每一段的节奏、旋律轮廓曲线和情感变化,从而可以判定主歌部分和副歌部分。
135.s413,根据所述节奏、旋律轮廓曲线以及情感信息对所述主歌和副歌的结构段落进行多重判定得到所述主歌部分和副歌部分的位置。
136.具体的,主歌部分相对比较柔和,平稳性较大,副歌部分为凸显主歌情感,高潮情绪较为激烈,其旋律轮廓线较为明显,且节奏相对较主歌部分要快一些,主歌到副歌之间的切换存在情感逐渐增强的气氛,副歌一般比主歌所占比例较多,因此,通过节奏、旋律轮廓曲线以及情感信息等多方判定可精确定位主歌和副歌的位置。
137.下面列举一个示例来阐述主歌和副歌的划分过程,例如,音乐文件为《平凡之路》歌曲,目前的歌曲一般都是采用以下的结构:前奏、主歌、副歌、间奏、尾奏;参考图4-7所示,图4-7是一个示例的主歌与副歌的曲谱示意图,将预设数据片段划分为多个子片段,在主歌段落中找到多个反复咏唱的相似性比较高的子片段,从而进行主歌与副歌的划分,比如歌曲《平凡之路》其主歌部分与副歌部分如下:
138.如图4,第一段主歌部分为:“徘徊着的在路上的你要走吗易碎的骄傲着那也曾是我的模样热腾着的不安着的你要去哪谜一样的沉默着的事你在听吗”。
139.如图5,第一段副歌部分为:“我曾经跨过山和大海也穿过人山人海我曾经拥有着的一切转眼都飘散如烟我曾失落失望失掉所有方向直到平凡才是唯一的答案”。
140.如图6,第二段主歌部分为:“当你仍然还在幻想你的明天她会好吗还是更烂对我而言是另一天”。
141.如图7,第二段副歌部分为:“我曾经毁了我的一切只想永远的离开我曾经坠入无边黑暗想挣扎无法自拔我曾经像你像他像那野草野花绝望着也渴望着也哭也笑也平凡着”。
142.通过上述示例可以看到,主歌部分和副歌部分明显是两个子段落,每个段落会有明显的边界,且每个段落的旋律是一致的,通过步骤s411~s413的处理后,可以精确地划分主歌部分和副歌部分。
143.为了更加清晰本技术中的主歌部分和副歌部分划分方案,对于其划分方法,本技术提供了如下实施例的划分方案。
144.在一个实施例中,步骤s411的划分主歌和副歌的结构段落的技术方案,可以包括如下:
145.(1)根据各个所述音乐文件的有效电平值确定伴奏的缩放倍数,并根据缩放倍数将所述音乐文件进行线性压缩目标音乐文件的声音大小。
146.具体的,计算每首音乐的rms(有效电平值)值,最大rms值,根据每首音乐的rms值来确定每一首音乐中伴奏需要缩放的倍数,动态平滑系数为:
147.gsmoth=factor*fsmoth+(1-factor)*gsmoth
148.fsmoth=rmstarget-rms
149.通过计算静态压缩值,将音乐进行线性压缩至需合成的音乐的声音大小。
150.(2)计算所述音乐文件的每一帧的有效电平值及对应的梅尔倒频谱。
151.示例性的,基于ssm(self-similarity matrix,自相似矩阵)技术处理,对音乐文件进行stft(short-time fourier transform,短时傅立叶变换)频谱分析,并计算每一帧的rms及对应的梅尔倒频谱,梅尔倒频谱符合人的听觉效应,能很好的反映音乐中的音符所在及其对应的音高。
152.(3)根据所述有效电平值和梅尔倒频谱的峰值曲线定位基音的位置和音高,获取对应的音符。
153.如图8所示,图8是计算音乐文件的音符流程图,根据rms和梅尔倒频谱的峰值曲线可定位到基音的位置和音高,从而得到音乐文件对应的音符。
154.(4)计算所述音符的持续时间,将所述音符转化为对应的色度特征;其中,所述色度特征包括色度向量和色度图谱。
155.利用持续时间可计算出对应的音符的持续时间,根据音符转化为对应的色度特征(chroma),色度特征包含色度向量和色度图谱,其中,色度向量是一个含有12个元素的向量v,每个元素代表一个音级(c、c#/db、d、d#/eb、e、f、f#/gb、g、g#/ab、a、a#/bb、b),一个音级代表一个八度,其中,持续时间计算公式如下:
[0156][0157]
相似度计算公式如下:
[0158][0159]
其中,v1、v2分别代表两帧信号的色度向量值,d的范围为0-1。
[0160]
(5)采用隐马尔可夫模型计算所述音乐文件的每一帧的相似度,获得主歌和副歌的结构段落的边界值。
[0161]
参考图9所示,图9是一个实施例的划分主歌部分和副歌部分的流程图,通过隐马尔可夫模型计算每一帧的相似度,以确定最佳的音乐段落结构划分,为了更好的实现段落划分,采用音乐伴奏的计算出对应的色度特征后,采用音符拟合成包络曲线作为音乐旋律轮廓线判定主歌和副歌部分,同时结合隐马尔可夫模型寻找歌曲中重复部分。
[0162]
其中,高斯密度函数计算方式如下;
[0163][0164]
tem2=-2
×
std2[0165][0166]
式中,scale约为0.01*samplerate,step为44100/512根据高斯密度函数,对应每个色度值,可获得对应的马尔可夫矩阵:
[0167][0168]
根据所得的高斯值a,获得多个色度马尔可夫矩阵mat。
[0169]
对马尔可夫矩阵进行viterbi解码,对每个色度值加乘高频权重,即
[0170][0171]
使得每一帧的色度向量得到较高的分配后求和,当和值比较小时,其音高位于低
位,当和值较大时,和值位于高位,把每一帧的色度和值计算后,通过归一化后作为其高音概率p和低音概率值(1-p)),计算解析马尔可夫矩阵:
[0172]
cost(i)=oldcos(i-1)+mat(i),i>1
[0173]
cost(0)=p+beatpath
[0174]
diffval=oldcost-mat(0),
[0175]
beatpath=diffval(min(diffval))
[0176]
经过反馈查找,寻找相似的结构段落即为主歌部分和副歌部分,根据其旋律变化和情感变化,可判定其结构段落为主歌部分还是副歌部分。
[0177]
上述实施例的方案,采用梅尔倒频谱及rms联合判定基音位置,实现精准定位当前音高,利用色度向量来判定其相似部分,通过粗略计算有助于降低算法的复杂性,在使用马尔可夫模型可准确判定主歌和副歌部分,增加判定的准确性,实现更好段落划分。
[0178]
下面阐述音乐文件处理装置的实施例。
[0179]
参考图10所示,图10是一个实施例的音乐文件处理装置的结构示意图,包括:
[0180]
传输模块10,用于从外部的多个音频信号源获取多个音乐文件;
[0181]
确定模块20,用于根据各个所述音乐文件的属性信息确定音乐文件的合成方式;
[0182]
提取模块30,用于根据所述合成方式分别从各个音乐文件中提取出相应的音乐合成信息;
[0183]
合成模块40,用于根据所述合成方式执行相应的合成流程,将所述音乐合成信息合成目标音乐文件。
[0184]
本实施例的音乐文件处理装置可执行本公开的实施例所提供的一种音乐文件处理方法,其实现原理相类似,本公开各实施例中的音乐文件处理装置中的各模块所执行的动作是与本公开各实施例中的音乐文件处理方法中的步骤相对应的,对于音乐文件处理装置的各模块的详细功能描述具体可以参见前文中所示的对应的音乐文件处理方法中的描述,此处不再赘述。
[0185]
下面阐述音乐演唱设备的实施例。
[0186]
本技术提供的音乐演唱设备,其可以进行音乐播放,图像播放和音乐演唱等功能,具体的,其结构可以包括:主板,以及分别与主板连接的音响系统和显示设备等等;其中,主板还连接麦克风;
[0187]
在使用中,主板用于执行上述的音乐文件处理方法的步骤;音响系统用于播放音频数据;如音乐文件,用户演唱的歌声;麦克风用于拾取用户的演唱声音;显示设备用于在演唱歌曲文件时显示图像内容,对于显示设备,可以采用大型触摸屏系统。
[0188]
下面阐述本技术的计算机设备的实施例,该计算机设备,其包括:
[0189]
一个或多个处理器;
[0190]
存储器;
[0191]
一个或多个应用程序,其中所述一个或多个应用程序被存储在所述存储器中并被配置为由所述一个或多个处理器执行,所述一个或多个程序配置用于:执行根据上述任意实施例的音乐文件处理方法。
[0192]
下面阐述本技术的计算机可读存储介质的实施例,,所述存储介质存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码
集或指令集由所述处理器加载并执行上述任意实施例的的音乐文件处理方法。
[0193]
上述音乐文件处理装置、音乐演唱设备、计算机设备、计算机可读存储介质的技术方案中,用户可以从多个不同音频信号源导入音乐文件,从而可以智能化、便捷地制作合成音乐,满足用户个性化需求,提升用户应用体验。
[0194]
以上所述仅是本技术的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本技术原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本技术的保护范围。