1.本发明属于信号处理技术领域,尤其涉及一种语音信号去噪方法。
背景技术:
2.语音信号在采集和传输的过程中不可避免的会受到各种各样的干扰,这会使采集到的语音信号准确度低,不利于后续分析,因此语音去噪成为语音信号处理过程中最为关键的一步。
3.传统进行语音去噪的方法有很多,基于谱减法的语音去噪是假定语音信号是短时平稳的,然而语音信号本身是一种非线性非平稳信号,使用谱减法有一定的局限性,且会产生一种新的背景噪声。基于小波阈值的语音去噪的关键在于阈值函数的选取,然而硬阈值的重构信号会产生振荡,软阈值的重构信号会产生失真。经验模态分解(emd)是由huang等人提出的一种处理非线性非平稳信号的方法,将信号分解成有限个本征模态函数分量(imf)与一个残差,频率由高到低排列下来,我们可以根据所处理信号的特点,把不符合信号特征的分量去除,对符合信号特征的其他分量进行处理,将最终剩余且处理完成的分量叠加重构,获得去噪后的信号。常规emd分解法得到的imf模态分量的选取没有统一的标准,通常是认为高频imf模态分量中以噪声信号为主导并舍弃,然而这会导致有效信号被剔除,使得重构后的信号失真,同时,emd分解法中极值点和包络线无法精确的确定,这就会产生包含虚假频率成分的imf模态分量,这部分分量如果得不到剔除会使重构后的信号不准确。
技术实现要素:
4.针对现有技术的不足,本发明提出了一种改进的语音信号去噪方法,是一种变分模态分解法(vmd)和主成分分析法(pca)相结合的技术。
5.本发明通过向原信号中添加高斯白噪声的方法消除vmd分解后重构信号中残留噪声的问题,采用vmd完成对原语音信号的分解,计算各个模态分量与原信号的相关系数并画相关系数分布图,通过模态分量判断准则将模态分量分为无效分量、信号分量、噪声分量三个类别。其中,无效分量直接剔除,信号分量予以保留,噪声分量经过后续pca降噪后与信号分量进行重构,得到最终去噪后的语音信号。
6.术语解释:
7.1、vmd分解,即变分模态分解,是一种自适应、完全非递归的模态变分和信号处理的方法。该技术具有可以确定模态分解个数的优点,其自适应性表现在根据实际情况确定所给序列的模态分解个数,随后的搜索和求解过程中可以自适应地匹配每种模态的最佳中心频率和有限带宽,并且可以实现固有模态分量(imf)的有效分离、信号的频域划分、进而得到给定信号的有效分解成分,最终获得变分问题的最优解。
8.2、emd,经验模态分解,是由黄锷(n.e.huang)等人于1998年创造性地提出的一种新型自适应信号时频处理方法,特别适用于非线性非平稳信号的分析处理。
9.本发明的技术方案为:
10.一种基于改进变分模态分解和主成分分析的语音信号去噪方法,包括步骤如下:
11.s1:选取一段带噪语音信号y(t)作为样本;
12.s2:使用改进的vmd方法对带噪语音信号y(t)进行分解,得到k个imf模态分量;
13.s3:计算每个imf模态分量与原带噪语音信号的相关系数,画出相关系数分布图,依据虚假分量判断原则从相关系数分布图中确定虚假分量,依据噪声分量判断原则从相关系数分布图中确定噪声主导的imf模态分量;
14.s4:去除虚假分量和噪声主导的imf模态分量后,剩余的imf模态分量记为信号主导的imf模态分量;
15.s5:对于噪声主导的imf模态分量,采取主成分分析(pca)法,根据累计贡献率选择一定数目的主成分分量进行重构,去除噪声主导的imf模态分量中的残余噪声;
16.s6:将经过主成分分析(pca)后的噪声主导的imf模态分量的主成分分量与信号主导的imf模态分量进行重构,得到去除噪声的语音信号。
17.根据本发明优选的,步骤s2的具体实现过程包括:
18.s2
‑
1:设定vmd分解参数,包括最佳分解层数和模态分量频率带宽控制参数α;
19.s2
‑
2:构造约束变分模型,引入拉格朗日函数,构造增广拉格朗日方程;
20.s2
‑
3:求解增广拉格朗日方程,初始化分量的频率,得到初始分量频率u^
k1
,与u^
k1
对应的初始中心频率ω^
k1
,初始拉格朗日乘数λ^
k1
;
21.s2
‑
4:根据vmd算法公式更新分量频率u^
k
,中心频率ω^
k
;
22.s2
‑
5:在每次更新完分量频率u^
k
、中心频率ω^
k
之后,更新拉格朗日乘数λ^;
23.s2
‑
6:判断迭代更新后的分量频率是否满足收敛方程,如果不满足,则继续迭代,同时加入噪声强度逐渐递减的高斯白噪声,继续执行步骤s2
‑
s5;如果满足收敛方程,则结束迭代,获得完成vmd分解的模态分量。
24.进一步优选的,步骤s2
‑
1中,设定最佳分解层数的方法如下:
25.对原带噪语音信号进行emd分解,设某一次分解的层数为k,分解后得到k个模态分量,计算各个模态分量与原带噪语音信号的相关系数,选相关系数最大的模态分量imf
max
,计算其峭度并记为λ,之后每一次分解的层数都加1,且分解层数为k+1时相关系数最大的模态分量的峭度记为λ’,不断迭代,直至某一次出现一个λ<λ’,这时λ对应的分解的层数为最佳分解层数;峭度h计算公式如式(ⅰ)所示:
[0026][0027]
式(ⅰ)中,imf
i
(t)为第i个模态分量,μ
i
为第i个模态分量的均值,σ
i
为第i个模态分量的标准差。
[0028]
进一步优选的,设定模态分量频率带宽控制参数α为2000。
[0029]
进一步优选的,步骤s2
‑
2中,约束变分模型即vmd约束模型表达式如式(ⅱ)所示:
[0030][0031]
式(ⅱ)中,δ(t)为单位冲激函数,k是vmd分解层数,{u
k
}={u1,u2,......,u
k
}是所
有imf分量的集合,{ω
k
}={ω1,ω2,......,ω
k
}是各个模态分量中心频率的集合,j为虚数单位。
[0032]
进一步优选的,步骤s2
‑
3中,增广拉格朗日方程l如式(ⅲ)所示:
[0033][0034]
式(ⅲ)中,α为模态分量频率带宽控制参数,λ为拉格朗日乘数,ω
k
为第k个模态分量的中心频率。
[0035]
进一步优选的,步骤s2
‑
4中,模态分量频率的更新公式如式(ⅳ)所示:
[0036][0037]
式(ⅳ)中,x(ω)是信号x(t)的频域形式,λ^(ω)为拉格朗日算子λ(t)的频域形式,上标^均表示共轭形式,n为迭代次数;
[0038]
imf分量对应的中心频率的更新公式如式(
ⅴ
)所示:
[0039][0040]
式(
ⅴ
)中,u^
k
(ω)为第k个imf模态分量频率。
[0041]
进一步优选的,步骤s2
‑
5中,拉格朗日乘数λ的更新公式如式(
ⅵ
)所示:
[0042][0043]
式(
ⅵ
)中,τ为拉格朗日乘数的更新参数,τ=10
‑3。
[0044]
进一步优选的,步骤s2
‑
6中,收敛方程如式(
ⅶ
)所示:
[0045][0046]
式(
ⅶ
)中,ε为收敛准则容差值,ε为10
‑6;步骤s2
‑
6中,得到的分解后的模态分量记为imf1,imf2,......,imf
m
。
[0047]
进一步优选的,步骤s2
‑
6中,加入噪声强度逐渐递减的高斯白噪声的具体方法是:向分量频率不满足收敛方程的模态分量加入幅度分布服从高斯分布、功率谱密度分布服从均匀分布的噪声,且噪声强度要按照逐渐递减的原则,即后一次添加的噪声强度要比前一次添加的噪声强度要低。
[0048]
根据本发明优选的,步骤s2
‑
1、步骤s3中,相关系数ρ
xy
计算公式如式(
ⅷ
)所示:
[0049]
[0050]
式(
ⅷ
)中,x(i)为待计算相关系数的信号,y(i)为原始信号。
[0051]
根据本发明优选的,步骤s3中,依据虚假分量判断原则从相关系数分布图中确定虚假分量,具体是指:从相关系数分布图中找到第一个相关系数小于h的点,将这个点对应的模态分量记作imf
h
,h是指相关系数,取值范围为0.10~0.15,将imf
h+1
~imf
k
记为虚假分量。
[0052]
进一步优选的,h=0.15。
[0053]
根据本发明优选的,步骤s3中,依据噪声分量判断原则从相关系数分布图中确定噪声主导的imf模态分量,具体是指:去除虚假分量后重新绘制相关系数分布曲线,找到曲线上的第一个转折点记作p,此点对应的imf模态分量记作imf
p
,将imf1~imf
p
记为噪声主导的imf模态分量。
[0054]
进一步地,步骤s5的具体实现过程如下:
[0055]
s5
‑
1:从一个噪声主导的模态分量中提取m个特征值m
i
,i=1,2,...,m特征值m
i
的维度为n{m
i1
,m
i2
,...,m
ij
},j=1,2,...,n;
[0056]
s5
‑
2:为特征值建立样本矩阵a
mn
,即由组成的标准化m
×
n矩阵a
mn
作为样本矩阵,的求取公式如式(
ⅷ
)所示:
[0057][0058]
式(
ⅷ
)中,为m
ij
的标准化值,μ
j
为第j个分量的样本均值,s
j
为第j个分量的样本标准差,
[0059]
s5
‑
3:根据计算标准化矩阵的协方差矩阵b,如式(ix)所示:
[0060][0061]
式(ix)中,协方差矩阵b也称为矩阵a
mn
的相关系数矩阵;
[0062]
s5
‑
4:计算协方差矩阵b的特征值λ与特征值对应的特征向量p,将特征值重新按照从大到小的顺序排列为λ1≥λ1≥...≥λ
a
,与其相对应的特征向量为p
i
,i=1,2,...,a,特征向量之间彼此正交,由特征向量构成一个矩阵p=(p1,p2,......,p
n
);
[0063]
s5
‑
5:令y=p
t
b,y=(y1,y2,...,y
n
)
t
,其中y1,y2,...,y
i
,...彼此不相关,称y1,y2,...,y
n
分别为第1、第2、...、第i...个主成分变量;
[0064]
s5
‑
6:选择前p个主成分变量,通过它们对应的特征值计算主成分累计贡献率,如式(
ⅹ
)所示:
[0065][0066]
式(
ⅹ
)中,α
p
为前p个主成分变量的累计贡献率;
[0067]
s5
‑
7:选择累计贡献率达到85%以上的主成分变量重构得到一个新的模态分量imf
pca
,与步骤s4得到的信号主导的imf模态分量进行重构,生成新的信号,这个新的信号就是去除噪声的语音信号。
[0068]
重构公式如式(
ⅺ
)所示:
[0069]
d(t)=imf
信号
(t)+imf
pca
(t)(
ⅺ
)
[0070]
式(
ⅺ
)中,imf
信号
(t)为信号主导的模态分量,imf
pca
(t)为累计贡献率达到85%以上的主成分变量重构得到的模态分量。
[0071]
本发明的有益效果为:
[0072]
1、本发明采用了vmd(变分模态分解)法来处理语音信号这种非线性非平稳信号,相比于其他方法,vmd分解法的自适应性更强,它可以降低信号的复杂度以及非平稳性,对语音信号的处理有显著的效果
[0073]
2、本发明改进了最佳分解层数的确定方法,相比于传统方法,提高了vmd分解的精度,使得分解的结果更加准确,减少了分解的时间,提高了分解效率。
[0074]
3、本发明采用相关系数分布图的来确定噪声主导分量、信号主导分量以及无效分量,相比于其他方法,本发明不会使得有用的分量被误去除。
[0075]
4、本发明通过加入高斯白噪声来消除了vmd分解法产生的端点效应以及模态混叠,相比于其他方法,本发明模态分量的分解更加准确。
[0076]
5、本发明使用主成分分析(pca)方法对噪声主导的分量降噪,并将降噪后的信号用于信号重构,相比于其他方法,本发明重构后的信号更加准确。
附图说明
[0077]
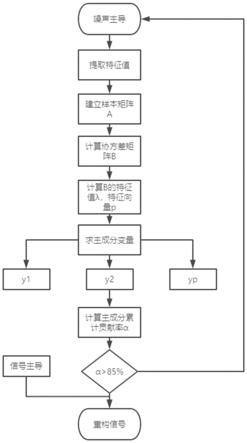
图1是本发明vmd分解以及模态分量分类的流程图。
[0078]
图2是本发明主成分分析过程的流程图。
[0079]
图3是原始语音信号的波形图。
[0080]
图4是加入的噪声波形图。
[0081]
图5是加入噪声后的语音信号波形图。
[0082]
图6是去噪后语音信号的波形图。
具体实施方式
[0083]
下面结合说明书附图和具体实施示例对本发明做进一步说明,但不限于此。
[0084]
实施例1
[0085]
一种基于改进变分模态分解和主成分分析的语音信号去噪方法,包括步骤如下:
[0086]
s1:选取一段带噪语音信号作为样本;
[0087]
s2:使用改进的vmd方法对带噪语音信号进行分解,得到k个imf模态分量;
[0088]
s3:计算每个imf模态分量与原带噪语音信号的相关系数,画出相关系数分布图,依据虚假分量判断原则从相关系数分布图中确定虚假分量,依据噪声分量判断原则从相关系数分布图中确定噪声主导的imf模态分量;
[0089]
s4:去除虚假分量和噪声主导的imf模态分量后,剩余的imf模态分量记为信号主导的imf模态分量;
[0090]
s5:对于噪声主导的imf模态分量,采取主成分分析(pca)法,根据累计贡献率选择一定数目的主成分分量进行重构,去除噪声主导的imf模态分量中的残余噪声;
[0091]
s6:将经过主成分分析后的噪声主导的imf模态分量的主成分分量与信号主导的imf模态分量进行重构,得到去除噪声的语音信号。
[0092]
如图1所示,是本发明的原理流程图,其中,x(t)是采集到的语音信号,该语音信号含有噪声,经vmd分解后,得到n个模态分量,其中n是大于等于2的整数。计算各个imf模态分量与x(t)的相关系数,画出相关系数分布图,并按照判断准则将imf模态分量归为噪声主导和信号主导两类,其中噪声主导的分量进一步经pca法进行分解,取其中贡献率大的主元分量进行重构,得到去噪后的分量,最终将去噪后的噪声主导imf模态分量与信号主导imf模态分量进行重构,得到去噪后的语音信号y(t)。
[0093]
图3是原始语音信号的波形图。图4是加入的噪声波形图。图5是加入噪声后的语音信号波形图。图6是本发明去噪后语音信号的波形图。
[0094]
图5和图6比对,可知,大部分噪声干扰已经被去除。图3和图6比对,可知,去噪后的信号在最初始的位置存有部分噪声,其他位置已经接近原始信号,去噪效果较好。
[0095]
实施例2
[0096]
根据实施例1所述的一种基于改进变分模态分解和主成分分析的语音信号去噪方法,其区别在于:
[0097]
步骤s2的具体实现过程包括:
[0098]
如图2所示,s2
‑
1:设定vmd分解参数,包括最佳分解层数和模态分量频率带宽控制参数α;
[0099]
步骤s2
‑
1中,本发明中vmd分解法的改进在于改进了最佳分解层数的确定方法,设定最佳分解层数的方法如下:
[0100]
对原带噪语音信号进行emd分解,设某一次分解的层数为k,分解后得到k个模态分量,计算各个模态分量与原带噪语音信号的相关系数,选相关系数最大的模态分量imf
max
,计算其峭度并记为λ,之后每一次分解的层数都加1,且分解层数为k+1时相关系数最大的模态分量的峭度记为λ’,不断迭代,直至某一次出现一个λ<λ’,这时λ对应的分解的层数为最佳分解层数;峭度h计算公式如式(ⅰ)所示:
[0101][0102]
式(ⅰ)中,imf
i
(t)为第i个模态分量,μ
i
为第i个模态分量的均值,σ
i
为第i个模态分量的标准差。由于是语音信号,设定模态分量频率带宽控制参数α为2000。
[0103]
s2
‑
2:构造约束变分模型,引入拉格朗日函数,构造增广拉格朗日方程;
[0104]
步骤s2
‑
2中,vmd分解过程可以看作约束变分问题的构造与求解,约束变分模型即vmd约束模型表达式如式(ⅱ)所示:
[0105][0106]
式(ⅱ)中,δ(t)为单位冲激函数,k是vmd分解层数,{u
k
}={u1,u2,......,u
k
}是所有imf模态分量的集合,{ω
k
}={ω1,ω2,......,ω
k
}是各个模态分量中心频率的集合,j
为虚数单位。
[0107]
s2
‑
3:求解增广拉格朗日方程,初始化分量的频率,得到初始分量频率u^
k1
,与u^
k1
对应的初始中心频率ω^
k1
,初始拉格朗日乘数λ^
k1
;
[0108]
步骤s2
‑
3中,增广拉格朗日方程l如式(ⅲ)所示:
[0109][0110]
式(ⅲ)中,α为模态分量频率带宽控制参数,λ为拉格朗日乘数,ω
k
为第k个模态分量的中心频率。
[0111]
s2
‑
4:根据vmd算法公式更新分量频率u^
k
,中心频率ω^
k
;
[0112]
步骤s2
‑
4中,模态分量频率的更新公式如式(ⅳ)所示:
[0113][0114]
式(ⅳ)中,x(ω)是信号x(t)的频域形式,λ^(ω)为拉格朗日算子λ(t)的频域形式,上标^均表示共轭形式,n为迭代次数;
[0115]
imf分量对应的中心频率的更新公式如式(
ⅴ
)所示:
[0116][0117]
式(
ⅴ
)中,u^
k
(ω)为第k个imf模态分量频率。
[0118]
s2
‑
5:在每次更新完分量频率u^
k
、中心频率ω^
k
之后,更新拉格朗日乘数λ^;
[0119]
步骤s2
‑
5中,拉格朗日乘数λ的更新公式如式(
ⅵ
)所示:
[0120][0121]
式(
ⅵ
)中,τ为拉格朗日乘数的更新参数,τ=10
‑3。
[0122]
s2
‑
6:判断迭代更新后的分量频率是否满足收敛方程,如果不满足,则继续迭代,同时加入噪声强度逐渐递减的高斯白噪声,继续执行步骤s2
‑
s5;如果满足收敛方程,则结束迭代,获得完成vmd分解的模态分量。
[0123]
步骤s2
‑
6中,收敛方程如式(
ⅶ
)所示:
[0124][0125]
式(
ⅶ
)中,ε为收敛准则容差值,ε为10
‑6;步骤s2
‑
6中,得到的分解后的模态分量记为imf1,imf2,......,imf
m
。
[0126]
步骤s2
‑
6中,加入噪声强度逐渐递减的高斯白噪声的具体方法是:向分量频率不满足收敛方程的模态分量加入幅度分布服从高斯分布、功率谱密度分布服从均匀分布的噪声,且噪声强度要按照逐渐递减的原则,即后一次添加的噪声强度要比前一次添加的噪声
强度要低。
[0127]
实施例3
[0128]
根据实施例2所述的一种基于改进变分模态分解和主成分分析的语音信号去噪方法,其区别在于:
[0129]
步骤s2
‑
1、步骤s3中,相关系数ρ
xy
计算公式如式(
ⅷ
)所示:
[0130][0131]
式(
ⅷ
)中,x(i)为待计算相关系数的信号,y(i)为原始信号。
[0132]
步骤s3中,依据虚假分量判断原则从相关系数分布图中确定虚假分量,具体是指:从相关系数分布图中找到第一个相关系数小于h的点,将这个点对应的模态分量记作imf
h
,h是指相关系数,h=0.15,将imf
h+1
~imf
k
记为虚假分量。
[0133]
步骤s3中,依据噪声分量判断原则从相关系数分布图中确定噪声主导的imf模态分量,具体是指:去除虚假分量后重新绘制相关系数分布曲线,找到曲线上的第一个转折点记作p,此点对应的imf模态分量记作imf
p
,将imf1~imf
p
记为噪声主导的imf模态分量。
[0134]
实施例4
[0135]
根据实施例2或3所述的一种基于改进变分模态分解和主成分分析的语音信号去噪方法,其区别在于:
[0136]
步骤s5的具体实现过程如下:
[0137]
s5
‑
1:从一个噪声主导的模态分量中提取m个特征值m
i
,i=1,2,...,m特征值m
i
的维度为n{m
i1
,m
i2
,...,m
ij
},j=1,2,...,n;
[0138]
s5
‑
2:为特征值建立样本矩阵a
mn
,即由组成的标准化m
×
n矩阵a
mn
作为样本矩阵,的求取公式如式(
ⅷ
)所示:
[0139][0140]
式(
ⅷ
)中,为m
ij
的标准化值,μ
j
为第j个分量的样本均值,s
j
为第j个分量的样本标准差,
[0141]
s5
‑
3:根据计算标准化矩阵的协方差矩阵b,如式(ix)所示:
[0142][0143]
式(ix)中,协方差矩阵b也称为矩阵a
mn
的相关系数矩阵;
[0144]
s5
‑
4:计算协方差矩阵b的特征值λ与特征值对应的特征向量p,在matlab中使用eig函数求特征值及特征向量,具体步骤为,在命令行窗口中输入矩阵a
mn
,然后输入[x,y]=eig(a
mn
),计算得到x,y两个矩阵,其中x的每一列值表示矩阵a的一个特征向量,y的对角元
素值代表a矩阵的特征值。将特征值重新按照从大到小的顺序排列为λ1≥λ1≥...≥λ
a
,与其相对应的特征向量为p
i
,i=1,2,...,a,特征向量之间彼此正交,由特征向量构成一个矩阵p=(p1,p2,......,p
n
);
[0145]
s5
‑
5:令y=p
t
b,y=(y1,y2,...,y
n
)
t
,其中y1,y2,...,y
i
,...彼此不相关,称y1,y2,...,y
n
分别为第1、第2、...、第i...个主成分变量;
[0146]
s5
‑
6:选择前p个主成分变量,通过它们对应的特征值计算主成分累计贡献率,如式(
ⅹ
)所示:
[0147][0148]
式(
ⅹ
)中,α
p
为前p个主成分变量的累计贡献率;
[0149]
s5
‑
7:选择累计贡献率达到85%以上的主成分变量与步骤s4得到的信号主导的imf分量进行重构,生成新的信号,这个新的信号就是去除噪声的语音信号。
[0150]
重构公式如式(
ⅺ
)所示:
[0151]
d(t)=imf
信号
(t)+imf
pca
(t)(
ⅺ
)
[0152]
式(
ⅺ
)中,imf
信号
(t)为信号主导的模态分量,imf
pca
(t)为累计贡献率达到85%以上的主成分变量重构得到的模态分量。