1.本发明属于机器学习技术领域,尤其涉及一种基于语音识别与机器学习的抑郁症自动识别方法和装置。
背景技术:
2.截至2014年,我国抑郁症患病率为2.1%,截至2017年底,全国已登记在册的严重精神障碍患者581万人,抑郁症会对患者以及家庭和社会造成严重的伤害。2020年9月发布了关于探索开展抑郁症防治特色服务工作的通知以及工作方案,工作方案中指出我国公众对于抑郁症防治知识的知晓率、就诊率、治疗率较低,就诊率只有全部抑郁症患者的十分之一,并且抑郁症的确诊及治疗依赖于精神专科医院的医生,我国正在加大非精神专科医院医生的培训。因此自动化对抑郁症进行早期诊断显得尤为重要。
技术实现要素:
3.本发明要解决的技术问题是,提供一种基于语音识别与机器学习的抑郁症自动识别方法和装置,通过设计问答记录普通人群的语音数据,然后使用机器学习算法对于语音数据进行识别和分类,有效地解决抑郁症患者早期难以发现的问题,降低抑郁症患者就诊门槛。
4.为实现上述目的,本发明采用如下的技术方案:
5.一种基于语音识别与机器学习的抑郁症自动识别方法,包括以下步骤:
6.步骤s1、获取患者的语音数据;
7.步骤s2、对所述语音数据进行特征选择,并对选择后的特征进行重新组合,生成长期特征;
8.步骤s3、根据随机森林算法对所述长期特征进行抑郁程度的识别。
9.作为优选,步骤s2包括:
10.步骤2.1、采用分帧加窗处理对所述语音数据进行特征提取;
11.步骤2.2、根据决策树对提取的特征进行选择;
12.步骤2.3、对选择后的特征进行重新组合,生成长期特征。
13.作为优选,步骤2.1中提取特征为时域特征和频域特征,所述时域特征包含:短时能量、过零率以及能量熵,频域特征包含:谱熵、基频和质心。
14.作为优选,步骤2.3中,将短时特征进行离散化处理,根据每个特征值的上下三分之一位点设置阈值,将每一个特征分为低值、中值、高值三个离散特征,再对离散化后的特征以共同出现的方式进行特征组合;特征组合后采用统计一帧语音信号内特征出现的频数来生成长期特征。
15.作为优选,步骤s3中,长期特征中每一个特征值代表语音数据多个特征特定的离散值在一帧中共同出现的频数,当根据特征值进行分类的时候,则是根据一帧语音数据的离散特征共同出现的频数来进行分类。
16.本发明还提供一种基于语音识别与机器学习的抑郁症自动识别装置,包括:
17.获取模块,用于获取患者的语音数据;
18.组合模块,用于对所述语音数据进行特征选择,并对选择后的特征进行重新组合,生成长期特征;
19.识别模块,用于根据随机森林算法对所述长期特征进行抑郁程度的识别。
20.作为优选,组合模块包括:
21.提取单元,用于采用分帧加窗处理对所述语音数据进行特征提取;
22.选择单元,用于根据决策树对提取的特征进行选择;
23.组合单元,用于对选择后的特征进行重新组合,生成长期特征。
24.作为优选,提取特征为时域特征和频域特征,所述时域特征包含:短时能量、过零率以及能量熵,频域特征包含:谱熵、基频和质心。
25.作为优选,组合单元包括:
26.离散化组件,用于将短时特征进行离散化处理,根据每个特征值的上下三分之一位点设置阈值,将每一个特征分为低值、中值、高值三个离散特征;
27.组合组件,用于对离散化后的特征以共同出现的方式进行特征组合;
28.生成组件,用于对组合特征采用统计一帧语音信号内特征出现的频数来生成长期特征。
29.作为优选,识别模块中长期特征中每一个特征值代表语音数据多个特征特定的离散值在一帧中共同出现的频数,当根据特征值进行分类的时候,则是根据一帧内语音数据的离散特征共同出现的频数来进行分类。
30.本发明通过采集语音信号,对于语音信号的特征进行特征选择,再重新组合为新的长期特征,联合机器学习中的随机森林算法对语音片段进行抑郁程度的识别,能够帮助人们通过更加简单的方式对抑郁症进行早期的检测、诊断。
附图说明
31.图1本发明基于语音识别与机器学习技术的抑郁症自动识别方法流程图;
32.图2语音数据采集与记录示意图;
33.图3阈值点示意图;
34.图4组合长期特征机器学习分类示意图;
35.图5本发明基于语音识别与机器学习技术的抑郁症自动识别装置结构图示意图。
具体实施方式
36.下面通过具体实施方式结合附图对本发明作进一步详细说明。
37.如图1所示,本发明提供一种基于语音识别与机器学习技术的抑郁症自动识别方法,包括以下步骤:
38.步骤s1、获取患者的语音数据;
39.步骤s2、对所述语音数据进行特征选择,并对选择后的特征进行重新组合,生成长期特征;
40.步骤s2、根据随机森林算法对所述长期特征进行抑郁程度的识别。
entropy)简记ee,能量熵计算如下式所示。
56.ee=
‑
∑p
i
log(p
i
)
57.其中,p
i
为语音片段中,某个值的能量与所有能量总和的比值。
58.基频:
59.语音信号可以认为是由不同频率的正弦波组成,频率最低的正弦波为基音,基频代表了基音的频率。
60.质心:
61.质心可以反映语音信号的不平稳性,设质心(spectral centroid,sc),计算如下式所示。
[0062][0063]
其中,f(n)为信号频率,e(n)为语音信号a(n)经过短时傅里叶变换后对应频率的谱能量
[0064]
谱熵:
[0065]
与能量熵不同,谱熵在频域中进行计算,语音信号通过短时傅里叶变换后计算,谱熵为(spectral entropy,se),计算如下式所示。
[0066]
se=
‑
∑p
i
log(p
i
)
[0067]
其中,p
i
代表某个采样点的值和采样点总和的比。
[0068]
步骤2.2、对提取的特征进行选择
[0069]
语音信号经过特征提取共得到时域和频域中6个特征,本发明将特征进行组合,为避免组合后特征数量过大,所以对提取的特征根据决策树进行选择,选择最重要的4个特征进行研究,不局限于4个特征。
[0070]
步骤2.3、对选择后的特征进行重新组合
[0071]
通过分帧加窗提取短时的特征,短时特征对应于10
‑
50ms的语音片段特征,每一个窗口的短时特征代表的信息不够丰富,差异较大,每一帧的特征值由所有窗口的平均值生成,一帧的长度约为2
‑
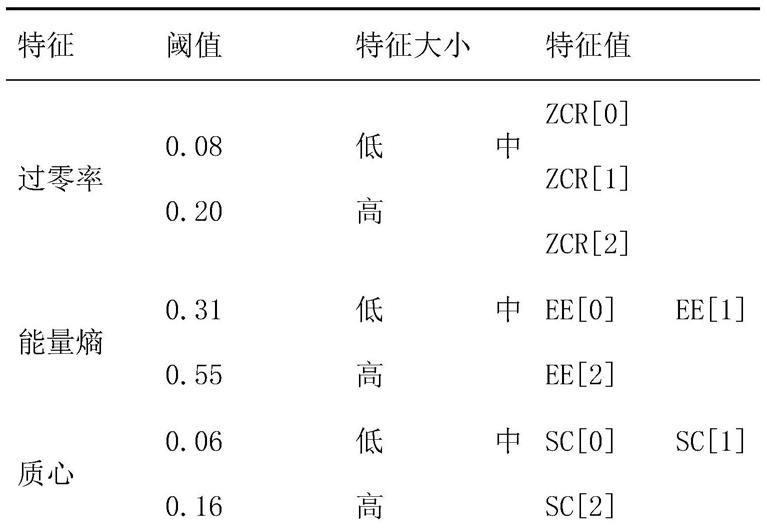
4s,但是长期特征也不能很好地反映短时特征的信息,使用短时特征和长期特征直接分类效果并不理想。因此本发明采用了特征组合的方法,首先将短时特征进行离散化处理,根据每个特征值的上下三分之一位点设置阈值,将每一个特征分为低值、中值、高值三个特征,再对这些离散化后的特征进行特征组合。首先将所选择的4个的特征,根据阈值离散化为低值、中值、高值三类,所使用的阈值为该特征值的上下三分之一位点,选择使用三分之一位点作为阈值能够在一定程度上减少异常值对数据的影响,各特征的阈值如表1所示,表1中阈值一列的两个值分别为下三分之一位点和上三分之一位点,特征值中的“[0],[1],[2]”与特征大小中的低、中、高对应。离散化示意图如图3所示。
[0072]
表1
[0073][0074][0075]
特征组合的方法将任意两个短期特征的某个特征值以共同出现的方式组合成新的短期特征,以能量熵和过零率为例,能量熵ee离散化后分为三个特征ee(0)、ee(1)、ee(2),分别代表着离散化后的低值、中值和高值,特征组合后,能量熵和过零率生成了一个9维的特征向量,如表2所示。特征组合的方式不局限于两两组合,也可以三种或者四种短期特征组合生成新的特征向量。
[0076]
表2
[0077][0078]
特征组合后,生成的特征向量仍为短时特征,为了解决短时特征和长期特征中的不足,本发明采用统计一帧语音信号内特征出现的频数来生成信息更加丰富的长期特征,计算如下式所示。
[0079][0080]
[0081]
其中,zcr(s)和ee(s)表示t时刻过零率和能量熵的特征值,a1、a2、b1、b2分别为过零率和能量熵的上下两个阈值,w
zcr*ee
为t时刻组合特征向量。v
zcr*ee
为计算δt时间长度的过零率和能量熵共现的组合长期特征。上述特征的数量级上有着很大的差异,为了比较不同语音片段因为抑郁程度造成的差异,并且创建一个更加稳定的模型,将得到的组合后的特征进行归一化处理,不改变数据的原始分布,只对数据进行伸缩。
[0082]
进一步,步骤s3中采用基于组合特征的机器学习分类算法,随机森林算法(random forests algorithm)是一种集成学习,由多个决策树组成,属于强分类器,根据多个决策树的预测结果,通过多数投票的方法输出预测结果。单个决策树属于弱分类器,意味着单个决策树的分类结果略强于随机分类,根据大数定律,由多棵决策树多数投票的结果明显优于单个决策树。在随机森林算法中,设总的样本数为n,特征数量为m,单个决策树的建立是选择n(n<n)个样本,并且选择m(m<m)个特征,在单个决策树中选择一个最优的特征来进行左右子树的划分,共进行t次抽样,生成t棵决策树来组成随机森林,最终由这t棵决策树的多数投票来生成随机森林的预测结果。在生成单个决策树的过程中,选择随机抽样的方法,是为了保证每一棵决策树的样本不同,这样每一棵决策树的预测结果才会不同,并且采用放回的抽样(bagging),是为了保证每棵决策树中的样本有交集,防止每棵树训练后差异过大,随机选取特征是为了避免过拟合问题。单个决策树的特征重要性是通过计算特征在树节点基尼系数(gini index)减少程度来衡量的,基尼系数计算如下式所示。
[0083][0084]
其中,p(c|n)是属于c类的样本数在节点n中所占的比例,c为类的总数,若所有节点n都是同一类样本,则基尼系数值为0,若所有类别的样本在节点n中占有相同的比例,则基尼系数取最小值,基尼系数越小,说明类别的划分越清晰。多个随机森林通过计算所有树中该特征的基尼系数减少值的平均值来表示特征重要性。因此随机森林算法不仅能够处理复杂的分类任务,还能够对于特征重要性进行排序,而且随机森林算法可以很方便地并行训练,对于硬件要求不高,可以在cpu上实现,也适合于各种具有录音功能的智能设备,鉴于此,本发明采用随机森林算法。在本发明创建的组合长期特征中,每一个特征值不再单一的表示语音数据的某一个特征,而是代表了语音数据多个特征特定的离散值在一帧中共同出现的频数,当决策树根据特征值进行分类的时候,则是根据一帧内语音数据的组合长期特征的特征值进行分类,相较于长期特征或短时特征,组合后的长期特征有着更加丰富的信息,能够判断不同特征值大小对于分类器的贡献,特征值的大小也对应着一定的声学特性。
本发明通过对于一帧的语音数据生成一个长期特征,能够对于短期的语音片段进行分类,从而使人们在日常生活中就可以通过简短的对话对抑郁进行识别,及早的发现抑郁症,从而降低抑郁患者的求助门槛。具体的组合特征随机森林分类框架如图4所示。
[0085]
本发明将抑郁类别标记为1,即正类,非抑郁类别标记为0,即负类。系统分类性能评估,包含有精确度、敏感性、特异性与f1分数,其评价计算基于以下公式:
[0086][0087][0088][0089][0090]
其中,tp表示被模型预测为正的正样本,tn表示被模型预测为负的负样本,fp表示被模型预测为正的负样本,fn表示被模型预测为负的正样本,r为召回率,其等同于敏感性,p为精确率。
[0091]
如图5所示,本发明还提供一种基于语音识别与机器学习的抑郁症自动识别装置,包括:
[0092]
获取模块,用于获取患者的语音数据;
[0093]
组合模块,用于对所述语音数据进行特征选择,并对选择后的特征进行重新组合,生成长期特征;
[0094]
识别模块,用于根据随机森林算法对所述长期特征进行抑郁程度的识别。
[0095]
进一步,组合模块包括:
[0096]
提取单元,用于采用分帧加窗处理对所述语音数据进行特征提取;
[0097]
选择单元,用于根据决策树对提取的特征进行选择;
[0098]
组合单元,用于对选择后的特征进行重新组合,生成长期特征。
[0099]
进一步,提取特征为时域特征和频域特征,所述时域特征包含:短时能量、过零率以及能量熵,频域特征包含:谱熵、基频和质心。
[0100]
进一步,组合单元包括:
[0101]
离散化组件,用于将短时特征进行离散化处理,根据每个特征值的上下三分之一位点设置阈值,将每一个特征分为低值、中值、高值三个特征;
[0102]
组合组件,用于对离散化后的特征进行特征组合;
[0103]
生成组件,用于对组合特征采用统计一帧语音信号内特征出现的频数来生成长期特征。
[0104]
进一步,识别模块中长期特征中每一个特征值代表语音数据多个特征特定的离散值在一帧中共同出现的频数,当根据特征值进行分类的时候,则是根据一帧内语音数据的离散特征共同出现的频数来进行分类。
[0105]
抑郁症患者的语音数据较为容易获取,可以通过手环、手机等设备获取语音数据,且语音数据包含丰富的情感信息,抑郁症患者相较于正常人群的语音有着较大的差异,例
如抑郁症患者语速偏慢、语调单一、嘶哑程度增加且有着更多的气声发声,因此可以通过分析语音数据的信息特征来实现抑郁症的早期诊断。为此,此发明对语音信号进行处理,提取语音信号的多个特征,结合机器学习算法,提出了一个可用于识别抑郁症的新方法。此方法可根据人们较为简短的对话识别抑郁,识别过程中需要对提取的短期语音信号特征进行特征组合,再进行有效地分类判决。该发明采用结合机器学习理论与特征组合技术,对人群日常的抑郁程度进行有效的精确的判读。
[0106]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。